
In this chapter, we will look at ways to make our upper-case routine more efficient. We look at some design patterns for more efficient conditional statements, as well as some new ARM instructions that can simplify our code.
Optimizing code often involves thinking outside the box and going beyond finding ways to remove one or two instructions in a loop; we’ll look at a couple of novel ways to greatly improve the upper-case routine.
First of all, we’ll look at a trick to simplify the main if statement.
Optimizing the Upper-Case Routine
This code implements the reverse logic of branching around the SUB instruction if W5 < ‘a’ or W5 > ‘z’. This was fine for a chapter teaching branch instructions, since it demonstrated two of them. However, in this chapter, we look at eliminating branches entirely, so let’s see how we can improve this code one step at a time.
Simplifying the Range Comparison
If we treat W6 as an unsigned integer, then the first comparison does nothing, since all unsigned integers are greater than 0. In this case, we simplified our range from two comparisons to one comparison that W6 <= (‘z’-’a’). To understand why we use two registers here, see Exercise 1 in this chapter.
Upper-case routine with simplified range comparison
Makefile for the upper-case routine version in this chapter
This is an improvement and a great optimization to use when you need range comparisons. Let's use a conditional instruction to remove another branch.
Using a Conditional Instruction
CSEL Xd, Xn, Xm, cond
You can use either W or X registers with the CSEL instruction, but all the registers must be the same type.
CSINC Xd, Xn, Xm, cond
Next, we’ll use CSEL to replace another branch instruction.
Example with CSEL
Upper-case routine using a conditional CSEL instruction
This places W6 into W5 if the LS condition is true—the character is an alphabetic lower-case character, else it puts W5 into W5—the original character.
This code is more structured; it isn’t a spaghetti of branch instructions. Once you are used to using these operators, following the logic is easier. This sequence is easier on the execution pipeline, since branch prediction isn’t required to keep things moving.
Restricting the Problem Domain
The best optimizations of code arise from restricting the problem domain. If we are only dealing with alphabetic characters, we can eliminate the range comparison entirely. In Appendix D, “ASCII Character Set,” the only difference between upper- and lower-case letters is that lower-case letters have the 0x20 bit set, whereas upper-case letters do not. This means we convert a lower-case letter to upper-case by performing a bit clear (BIC) operation on that bit. If we do this to special characters, it will corrupt the bits of quite a few of them.
Often in computing, we want code to be case insensitive, meaning that you can enter any combination of case. The Assembler does this, so it doesn’t care if we enter MOV or mov. Similarly, many computer languages are case insensitive, so you can enter variable names in any combination of upper- and lower-case and it means the same thing. Machine learning algorithms that process text always convert them into a standard form, usually throwing away all punctuation and converting them to all one case. Forcing this standardization saves a lot of extra processing later.
Upper-case routine as a macro, using BIC for alphabetic characters only
There are a few special characters at the end of the string showing how some are converted correctly and some aren’t.
Besides using this BIC instruction to eliminate all conditional processing, we implement the toupper routine as a macro to eliminate the overhead of calling a function. We change the register usage, so we only use the first four registers in the macro, so we don’t need to save any registers around the call.
This is typical of many optimizations, showing how we can save instructions if we narrow our problem domain, in this case to just working on alphabetic characters rather than all ASCII characters.
Using Parallelism with SIMD
In Chapter 13, “Neon Coprocessor,” we looked at performing operations in parallel and mentioned that this coprocessor processes characters, as well as integers and floats. Let’s see if we can use NEON instructions to process 16 characters at a time (16 characters fit in a 128-bit V register).
Let’s look at the code in upper4.s shown in Listing 14-5.
This code won’t run until we make an adjustment to main.s at the end of this section in Listing 14-6.
Upper-case routine using the NEON Coprocessor
This routine uses 128-bit registers to process 16 characters at a time. There are more instructions than some of our previous routines, but the parallelism makes it worthwhile. We start by loading our constants into registers. You can’t use immediate constants with NEON instructions, so these must be in registers. Additionally, they need to be duplicated 16 times, so there is one for each of our 16 lanes.
We then load 16 characters to process into Q0 with an LDR instruction. We use post-indexed addressing, so the pointer is left pointing to the next block of characters for when we loop.
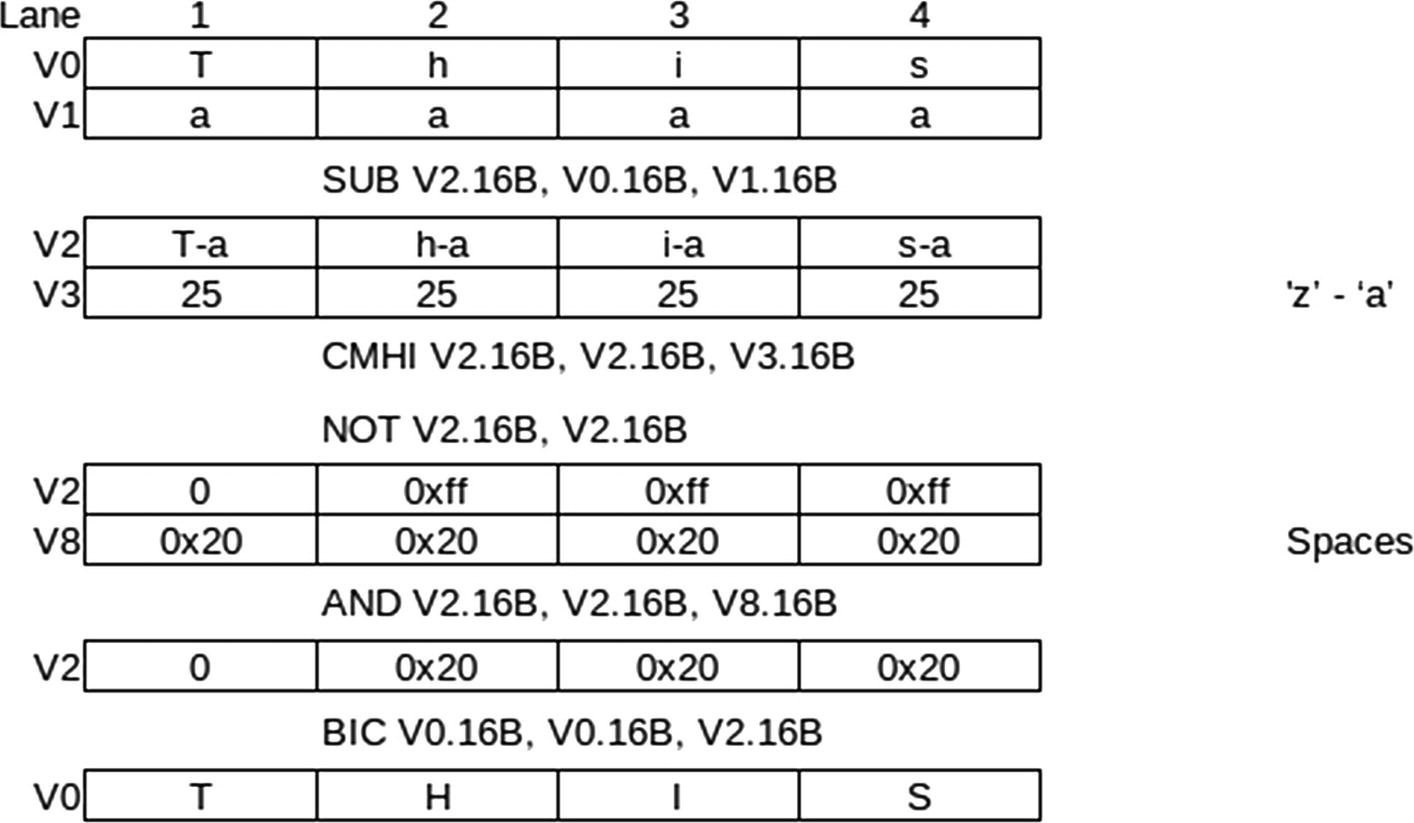
The parallel processing steps to convert to upper-case
The CMHI is our first encounter with a NEON comparison instruction. It compares all 16 lanes at once. It places all 1s in the destination lane if the comparison is true, otherwise 0. All 1s are 0xFF hex. We really want CMLO, but there is no such instruction, so we need to do a CMHI followed by a NOT. With this, we can AND it with a register full of 0x20s. Any lanes that don’t have a lower-case alphabetic character will result in 0.
This means in lanes with 0, there are no bits for BIC to clear. Then the lanes that still have 0x20 will clear that one bit doing the conversion.
Changes required in main.s
I also added edge case characters to the end of the string; this ensures we don’t have any off-by-one errors in our code.
Don’t use NULL-terminated strings. Use a length field followed by the string. Or use fixed length strings, for example, every string is just 256 characters and contains spaces beyond the last character.
Pad all strings to use data storage in multiples of 16. This way you won’t ever have to worry about NEON processing past the end of your buffer.
Make sure all the strings are word aligned.
We’ve looked at several techniques to optimize our upper-case routine; let’s look at why we concentrate so much on eliminating branch instructions as well as provide a few other tips.
Tips for Optimizing Code
The first rule of optimizing code is to time and test everything. The designers of the ARM processor are always incorporating improvements to their hardware designs. Each year, the ARM processors get faster and more optimized. Improving performance though optimizing Assembly Language code isn’t always intuitive. The processor can be quite smart at some things and quite dumb at others. If you don’t set up tests to measure the results of your changes, you could well be making things worse.
With that said, let’s look at some general Assembly Language optimization techniques.
Avoiding Branch Instructions
- 1.
Throw away any work it has done on instructions after the branch instruction.
- 2.
Make an educated guess as to which way the branch is likely to go and proceed in that direction; then it only needs to discard the work if it guessed wrong.
- 3.
Start processing instructions in both directions of the branch at once; perhaps it can’t do as much work, but it accomplishes something until the direction of the conditional branch is decided.
CPUs were getting quite good at predicting branches and keeping their pipelines busy. This was until the Spectre and Meltdown security exploits figured out how to access this work and exploit it. That caused CPU vendors, including ARM, to reduce some of this functionality.
As a result, conditional branch instructions can still be expensive. They also lead to hard to maintain spaghetti code that should be avoided. So reducing conditional branches helps performance and leads to more maintainable code.
Avoiding Expensive Instructions
Instructions like multiplication and division take multiple clock cycles to execute. If you can accomplish them through additions or subtractions in an existing loop, that can help. Also, consider using bit manipulation instructions like shifting left to multiply by 2. If these instructions are necessary for your algorithm, then there isn’t much you can do.
One trick is to execute the multiplication or division on the FPU or NEON Coprocessor; this will allow other regular ARM instructions to continue in parallel.
Don’t Be Afraid of Macros
Calling a function can be costly if a lot of registers need to be saved to the stack and then restored before returning. Don’t be afraid of using macros to eliminate the function call and return instructions along with all the register saving/restoring.
Loop Unrolling
We’ll see an example of loop unrolling in Chapter 15, “Reading and Understanding Code.” This is repeating the code the number of times of the loop, saving the overhead of the instructions that do the looping. We did this in the NEON version of 3x3 matrix multiplication where we inserted calls to a macro three times rather than write a loop.
Keeping Data Small
Even though the ARM process can mostly process instructions involving the 64-bit X registers in the same time as involving the 32-bit W registers, it puts strain on the memory bus moving all that data. Remember the memory bus is moving your data, along with loading instructions to execute and doing all that for all the processing cores. Reducing the quantity of data you move to and from memory can help speed things up.
Beware of Overheating
A single ARM processor typically has four or more processing cores, each of these with an FPU and NEON Coprocessor. If you work hard, you can get all these units working at once, theoretically processing a huge amount of data in parallel. The gotcha is that the more circuitry you involve in processing, the more heat is produced.
If you do this, beware that a single board computer, like the Raspberry Pi, can overheat. Similarly, smartphones overheat when they need to sustain too much processing. Often there are guidelines as to how busy you can keep the processor before it starts to overheat.
You won’t damage the processor; it will detect the overheating and slow itself down, undoing all the great work you’ve done.
Summary
- 1.
Simplifying range comparisons
- 2.
Using conditional instructions
- 3.
Simplifying the domain and using bit manipulations
- 4.
Upper-casing 16 characters at once using the NEON Coprocessor
We then provided several hints to consider when optimizing your code.
In Chapter 15, “Reading and Understanding Code,” we will examine how the C compiler generates code and talk about understanding compiled programs.
Exercises
- 1.
In our first optimization, consider this alternate pseudo-code:
- 2.
Think back to the loops we developed in Chapter 4, “Conditional Program Flow.” Construct a FOR loop using a CSINC statement to do the increment and test for loop end.
- 3.
Each generation of ARM CPU adds a few more instructions, especially to the NEON Coprocessor. List the pros and cons of utilizing newer instructions to optimize your code.
- 4.
Set up a way to run each of the programs in this chapter in a large loop, and time how long each one takes. Which technique is fastest and why? Consider using the Linux gettimeofday service.