
Chapter 11. SRE Patterns Loved by DevOps People Everywhere
Note
This is an edited excerpt from The DevOps Handbook by Gene Kim, Jez Humble, John Willis, and Patrick Debois (O’Reilly, 2016).
When David Blank-Edelman asked me to contribute a chapter on the SRE body of knowledge and the impact it has had on the DevOps community, I gave a very enthusiastic “Yes!”
Although some might argue that SRE and DevOps are mutually exclusive, I argue the opposite. In my opinion, it is difficult to overstate the impact that SRE has had on framing how the operations community can best contribute to organizational goals and improving the productivity of developers. As Ben Treynor Sloss, VP of SRE at Google, famously said in his 2014 SREcon presentation: “I define SRE as what happens when software engineers create an operations group.”
In that famous presentation, Treynor Sloss introduces the breathtaking concept of a truly self-balancing system, where an organization first decides on an acceptable error budget, which then guides the prioritization of nonfunctional requirements and gates the decision to deploy and release.
During the research and writing of The DevOps Handbook (along with my coauthors Jez Humble, John Willis, and Patrick Debois), I couldn’t help but notice how many of the DevOps patterns that we love and now can take for granted were pioneered at Google.
Here are three of my favorite patterns, excerpted from The DevOps Handbook, that can be traced to the SRE body of knowledge. Almost any organization can integrate them into its daily work.
Pattern 1: Birth of Automated Testing at Google
Automated testing addresses a truly significant and unsettling problem. Gary Gruver observes that “without automated testing, the more code we write, the more time and money is required to test our code—in most cases, this is a totally unscalable business model for any technology organization.”
Although Google now undoubtedly exemplifies a culture that values automated testing at scale, this wasn’t always the case. In 2005, when Mike Bland joined the organization, deploying to Google.com was often extremely problematic, especially for the Google Web Server (GWS) team. As Bland explains:
The GWS team had gotten into a position in the mid-2000s where it was extremely difficult to make changes to the web server, a C++ application that handled all requests to Google’s home page and many other Google web pages. As important and prominent as Google.com was, being on the GWS team was not a glamorous assignment—it was often the dumping ground for all the different teams who were creating various search functionality, all of whom were developing code independently of each other. They had problems such as builds and tests taking too long, code being put into production without being tested, and teams checking in large, infrequent changes that conflicted with those from other teams.
The consequences of this were large—search results could have errors or become unacceptably slow, affecting thousands of search queries on google.com. The potential result was loss not only of revenue, but customer trust.
Bland describes how it affected developers deploying changes: “Fear became the mind-killer. Fear stopped new team members from changing things because they didn’t understand the system. But fear also stopped experienced people from changing things because they understood it all too well.”1 Bland was part of the group that was determined to solve this problem.
GWS team lead Bharat Mediratta believed automated testing would help. As Bland describes:
They created a hard line: no changes would be accepted into GWS without accompanying automated tests. They set up a continuous build and religiously kept it passing. They set up test coverage monitoring and ensured that their level of test coverage went up over time. They wrote up policy and testing guides and insisted that contributors both inside and outside the team follow them.
The results were startling. As Bland notes:
GWS quickly became one of the most productive teams in the company, integrating large numbers of changes from different teams every week while maintaining a rapid release schedule. New team members were able to make productive contributions to this complex system quickly, thanks to good test coverage and code health. Ultimately, their radical policy enabled the Google.com home page to quickly expand its capabilities and thrive in an amazingly fast-moving and competitive technology landscape.
But GWS was still a relatively small team in a large and growing company. The team wanted to expand these practices across the entire organization. Thus, the Testing Grouplet was born, an informal group of engineers who wanted to elevate automated testing practices across the entire organization. Over the next five years, they helped replicate this culture of automated testing across all of Google.2
Now when any Google developer commits code, it is automatically run against a suite of hundreds of thousands of automated tests. If the code passes, it is automatically merged into trunk, ready to be deployed into production. Many Google properties build hourly or daily, then pick which builds to release; others adopt a continuous “Push on Green” delivery philosophy.
The stakes are higher than ever—a single code deployment error at Google can take down every property, all at the same time (such as a global infrastructure change or when a defect is introduced into a core library that every property depends upon).
Eran Messeri, an engineer in the Google Developer Infrastructure group, notes, “Large failures happen occasionally. You’ll get a ton of instant messages and engineers knocking on your door. [When the deployment pipeline is broken,] we need to fix it right away, because developers can no longer commit code. Consequently, we want to make it very easy to roll back.”
What enables this system to work at Google is engineering professionalism and a high-trust culture that assumes everyone wants to do a good job as well as the ability to detect and correct issues quickly. Messeri explains:
There are no hard policies at Google, such as, “If you break production for more than 10 projects, you have an SLA to fix the issue within 10 minutes.” Instead, there is mutual respect between teams and an implicit agreement that everyone does whatever it takes to keep the deployment pipeline running. We all know that one day, I’ll break your project by accident; the next day, you may break mine.
What Mike Bland and the Testing Grouplet team achieved has made Google one of the most productive technology organizations in the world. By 2013, automated testing and continuous integration at Google enabled more than 4,000 small teams to work together and stay productive, all simultaneously developing, integrating, testing, and deploying their code into production. All their code is in a single, shared repository, made up of billions of files, all being continuously built and integrated, with 50% of their code being changed each month. Some other impressive statistics on their performance include the following:
40,000 code commits/day
50,000 builds/day (on weekdays, this can exceed 90,000)
120,000 automated test suites
75 million test cases run daily
100-plus engineers working on the test engineering, continuous integration, and release engineering tooling to increase developer productivity (making up 0.5% of the R&D workforce)
Pattern 2: Launch and Handoff Readiness Review at Google
Even when developers are writing and running their code in production-like environments in their daily work, operations can still experience disastrous production releases because it is the first time we actually see how our code behaves during a release and under true production conditions. This result occurs because operational learnings often happen too late in the software life cycle.
When this is left unaddressed, the result is often production software that is difficult to operate. As an anonymous ops engineer once said, “In our group, most system administrators lasted only six months. Things were always breaking in production, the hours were insane, and application deployments were painful beyond belief—the worst part was pairing the application server clusters, which would take us six hours. During each moment, we all felt like the developers personally hated us.”
This can be an outcome of not having enough ops engineers to support all the product teams and the services we already have in production, which can happen in both functionally and market-oriented teams.
One potential countermeasure is to do what Google does, which is have development groups self-manage their services in production before they become eligible for a centralized ops group to manage. By having developers be responsible for deployment and production support, we are far more likely to have a smooth transition to operations.
To prevent the possibility of problematic, self-managed services going into production and creating organizational risk, we can define launch requirements that must be met in order for services to interact with real customers and be exposed to real production traffic. Furthermore, to help the product teams, ops engineers should act as consultants to help them make their services production-ready.
By creating launch guidance, we help ensure that every product team benefits from the cumulative and collective experience of the entire organization, especially operations. Launch guidance and requirements will likely include the following:
- Defect counts and severity
Does the application actually perform as designed?
- Type/frequency of pager alerts
Is the application generating an unsupportable number of alerts in production?
- Monitoring coverage
Is the coverage of monitoring sufficient to restore service when things go wrong?
- System architecture
Is the service loosely coupled enough to support a high rate of changes and deployments in production?
- Deployment process
Is there a predictable, deterministic, and sufficiently automated process to deploy code into production?
- Production hygiene
Is there evidence of enough good production habits that would allow production support to be managed by anyone else?
Superficially, these requirements might appear similar to traditional production checklists we have used in the past. However, the key differences are that we require effective monitoring to be in place, deployments to be reliable and deterministic, and an architecture that supports fast and frequent deployments.
If any deficiencies are found during the review, the assigned ops engineer should help the feature team resolve the issues or even help re-engineer the service if necessary so that it can be easily deployed and managed in production.
At this time, we might also want to learn whether this service is subject to any regulatory compliance objectives or if it is likely to be in the future:
Does the service generate a significant amount of revenue? (For example, if it is more than 5% of total revenue of a publicly held US corporation, it is a “significant account” and in-scope for compliance with Section 404 of the Sarbanes-Oxley Act of 2002 [SOX].)
Does the service have high user traffic or have high outage/impairment costs (i.e., do operational issues risk creating availability or reputational risk)?
Does the service store payment cardholder information such as credit card numbers, or personally identifiable information such as Social Security numbers or patient care records? Are there other security issues that could create regulatory, contractual obligation, privacy, or reputation risk?
Does the service have any other regulatory or contractual compliance requirements associated with it, such as US export regulations, PCI-DSS, HIPAA, and so forth?
This information helps to ensure that we effectively manage not only the technical risks associated with this service, but also any potential security and compliance risks. It also provides essential input into the design of the production control environment. See examples of the launch and handoff readiness reviews in Figures 11-1 and 11-2.
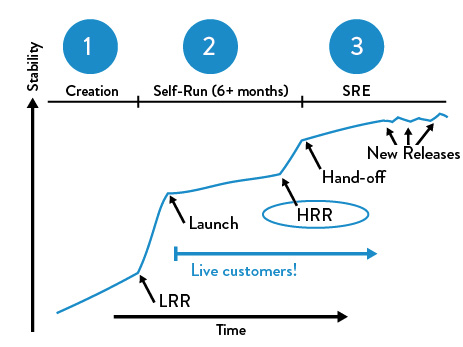
Figure 11-1. The launch readiness review at Google (source: “SRE@Google: Thousands of DevOps Since 2004”, YouTube video, 45:57, posted by USENIX, January 12, 2012)
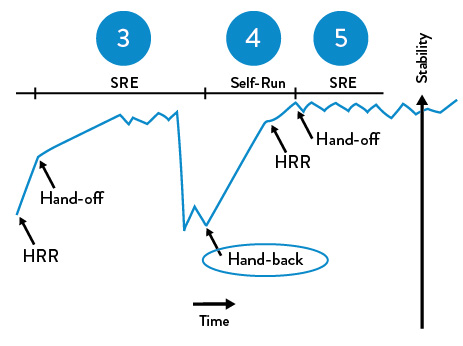
Figure 11-2. The handoffs readiness review at Google (source: “SRE@Google: Thousands of DevOps Since 2004”, YouTube video, 45:57, posted by USENIX, January 12, 2012)
As Tom Limoncelli, coauthor of The Practice of Cloud System Administration (Addison-Wesley, 2002) and a former site reliability engineer at Google, mentions in one of his talks, “In the best case, product teams have been using the LRR checklist as a guideline, working on fulfilling it in parallel with developing their service, and reaching out to SREs to get help when they need it.” Furthermore, Limoncelli once told me in 2016:
The teams that have the fastest HRR production approval are the ones that worked with SREs earliest, from the early design stages up until launch. And the great thing is, it’s always easy to get an SRE to volunteer to help with your project. Every SRE sees value in giving advice to project teams early and will likely volunteer a few hours or days to do just that.
The practice of SREs helping product teams early is an important cultural norm that is continually reinforced at Google. Limoncelli explained, “Helping product teams is a long-term investment that will pay off many months later when it comes time to launch. It is a form of ‘good citizenship’ and ‘community service’ that is valued; it is routinely considered when evaluating engineers for SRE promotions.”
Further Reading and Source Material
DevOps Enterprise Summit 2015 talk by Mike Bland: “Pain Is Over, If You Want It”, Slideshare.net, posted by Gene Kim, November 18, 2015.
GOTO Conference talk by Eran Messeri, “What Goes Wrong When Thousands of Engineers Share the Same Continuous Build?” Aarhus, Denmark, October 2, 2013.
Tom Limoncelli, “SRE@Google: Thousands Of DevOps Since 2004”, YouTube video of USENIX Association Talk, NYC, posted by USENIX, 45:57, posted January 12, 2012.
Ben Treynor, “Keys to SRE” (presentation, Usenix SREcon14, Santa Clara, CA, May 30, 2014).
Cade Metz, “Google Is 2 Billion Lines of Code—and It’s All in One Place”, Wired, September 16, 2015.
Eran Messeri, “What Goes Wrong When Thousands of Engineers Share the Same Continuous Build?” (2013).
Tom Limoncelli, “Yes, you can really work from HEAD”, EverythingSysAdmin.com, March 15, 2014.
Tom Limoncelli, “Python is better than Perl6”, EverythingSysAdmin.com, January 10, 2011.
“Which programming languages does Google use internally?,” Quora.com forum, accessed May 29, 2016; “When will Google permit languages other than Python, C++, Java and Go to be used for internal projects?”, Quora.com forum, accessed May 29, 2016.
Tom Limoncelli, Strata Chalup, and Christina Hogan, The Practice of Cloud System Administration (Addison-Wesley: 2002).
Contributor Bio
Gene Kim is a multiple award-winning CTO, researcher, and coauthor of The Phoenix Project, The DevOps Handbook, and Accelerate (IT Revolution). He is the organizer of the DevOps Enterprise Summit conferences.
1 Bland described that at Google, one of the consequences of having so many talented developers was that it created “imposter syndrome,” a term coined by psychologists to informally describe people who are unable to internalize their accomplishments. Wikipedia states that “despite external evidence of their competence, those exhibiting the syndrome remain convinced that they are frauds and do not deserve the success they have achieved. Proof of success is dismissed as luck, timing, or a result of deceiving others into thinking they are more intelligent and competent than they believe themselves to be.”
2 They created training programs, pushed the famous Testing on the Toilet newsletter (which they posted in the bathrooms), developed the Test Certified roadmap and certification program, and led multiple “fix-it” days (i.e., improvement blitzes), which helped teams improve their automated testing processes so that they could replicate the amazing outcomes that the GWS team was able to achieve.
3 The Chrome and Android projects reside in a separate source-code repository, and certain algorithms that are kept secret, such as PageRank, are available only to certain teams.