
Chapter 8. Evolutionary Architecture Pitfalls and Antipatterns
We’ve spent a lot of time discussing appropriate levels of coupling in architectures. However, we also live in the real world, and see lots of coupling that harms a project’s ability to evolve.
We identify two kinds of bad engineering practices that manifest in software projects—pitfalls and antipatterns. Many developers use the word antipattern as jargon for “bad,” but the real meaning is more subtle. A software antipattern has two parts. First, an antipattern is a practice that initially looks like a good idea but turns out to be a mistake. Second, better alternatives exist for most antipatterns. Architects notice many antipatterns only in hindsight, so they are hard to avoid. A pitfall looks superficially like a good idea but immediately reveals itself to be a bad path. We cover both pitfalls and antipatterns in this chapter.
Technical Architecture
In this section, we focus on common practices in the industry that specifically harm a team’s ability to evolve the architecture.
Antipattern: Last 10% Trap and Low Code/No Code
Neal once was the CTO of a consulting firm that built projects for clients in a variety of 4GLs, including Microsoft Access. He assisted in the decision to eliminate Access and eventually all the 4GLs from the business after observing that every Access project started as a booming success but ended in failure, and he wanted to understand why. He and a colleague observed that, in Access and other 4GLs popular at the time, 80% of what the client wanted was quick and easy to build. These environments were modeled as rapid application development tools, with drag-and-drop support for UIs and other niceties. However, the next 10% of what the client wanted was, while possible, extremely difficult—because that functionality wasn’t built into the tool, framework, or language. So clever developers figured out a way to hack tools to make things work: adding a script to execute where static things were expected, chaining methods, and other hacks. The hack only gets you from 80% to 90%. Ultimately the tool can’t solve the problem completely—a phrase we coined as the Last 10% Trap—leaving every project a disappointment. While 4GLs made it easy to build simple things fast, they didn’t scale to meet the demands of the real world. Developers returned to general-purpose languages.
The Last 10% Trap manifests periodically in waves of tools meant to remove the complexity of software development while (allegedly) allowing full-featured development, with predictable results. The current manifestation of this trend lies with low-code/no-code development environments, ranging from full-stack development to specialized tools like orchestrators.
While there is nothing wrong with low-code environments, they are almost universally oversold as a panacea for software development, one that business stakeholders are eager to embrace for perceived speed of delivery. Architects should consider them for specialized tasks but realize up front that limitations exist and try to determine what impacts those limitations will have in their ecosystem.
Generally, when experimenting with a new tool or framework, developers create the simplest “Hello, World” project possible. With low-code environments, easy things should be incredibly easy. Instead, what the architect needs to know is what the tool cannot do. Thus, instead of simple things, try to find the limits early, to allow building alternatives for what the tool cannot handle.
Tip
For low-code/no-code tools, evaluate the hardest problems first, not the easiest ones.
Case Study: Reuse at PenultimateWidgets
PenultimateWidgets has highly specific requirements for data input in a specialized grid for its administration functionality. Because the application required this view in multiple places, PenultimateWidgets decided to build a reusable component, including UI, validation, and other useful default behaviors. By using this component, developers can build new, rich administration interfaces easily.
However, virtually no architecture decision comes without some trade-off baggage. Over time, the component team has become their own silo within the organization, tying up several of PenultimateWidgets’ best developers. Teams that use the component must request new features through the component team, which is swamped with bug fixes and feature requests. Worse, the underlying code hasn’t kept up with modern web standards, making new functionality hard or impossible.
While the PenultimateWidgets architects achieved reuse, it eventually resulted in a bottleneck effect. One advantage of reuse is that developers can build new things quickly. Yet, unless the component team can keep up with the innovation pace of the dynamic equilibrium, technical architecture component reuse is doomed to eventually become an antipattern.
We’re not suggesting teams avoid building reusable assets, but rather that they evaluate them continually to ensure they still deliver value. In the case of PenultimateWidgets, once architects realized that the component was a bottleneck, they broke the coupling point. Any team that wants to fork the component code to add their own new features is allowed to do so (as long as the application development team supports the changes), and any team that wants to opt out to use a new approach is unshackled from the old code entirely.
Two pieces of advice emerge from PenultimateWidgets’ experience. First, when coupling points impede evolution or other important architectural characteristics, break the coupling by forking or duplication.
In PenultimateWidgets’ case, they broke the coupling by allowing teams to take ownership of the shared code themselves. While adding to their burden, it released the drag on their ability to deliver new features. In other cases, perhaps some shared code can be abstracted from the larger piece, allowing more selective coupling and gradual decoupling.
Second, architects must continually evaluate the fitness of the “-ilities” of the architecture to ensure they still add value and haven’t become antipatterns.
All too often architects make a decision that is the correct decision at the time but becomes a bad decision over time because of changing conditions like dynamic equilibrium. For example, architects design a system as a desktop application, yet the industry herds them toward a web application as users’ habits change. The original decision wasn’t incorrect, but the ecosystem shifted in unexpected ways.
Antipattern: Vendor King
Some large enterprises buy enterprise resource planning (ERP) software to handle common business tasks like accounting, inventory management, and other common chores. This works if companies are willing to bend their business processes and other decisions to accommodate the tool, and it can be used strategically when architects understand limitations as well as benefits.
However, many organizations become overambitious with this category of software, leading to the Vendor King antipattern, an architecture built entirely around a vendor’s product that pathologically couples the organization to a tool. Companies that buy vendor software plan to augment the package via its plug-ins to flesh out the core functionality to match their business. However, a lot of the time ERP tools can’t be customized enough to fully implement what is needed, and developers find themselves hamstrung by the limitations of the tool and the fact that they have centered the architectural universe on it. In other words, architects have made the vendor the king of the architecture, dictating future decisions.
To escape this antipattern, treat all software as just another integration point, even if it initially has broad responsibilities. By assuming integration at the outset, developers can more easily replace behavior that isn’t useful with other integration points, dethroning the king.
By placing an external tool or framework at the heart of the architecture, developers severely restrict their ability to evolve in two key ways, both technically and from a business process standpoint. Developers are technically constrained by choices the vendor makes in terms of persistence, supported infrastructure, and a host of other constraints. From a business standpoint, large encapsulating tools ultimately suffer from the problems discussed in “Antipattern: Last 10% Trap and Low Code/No Code”. From a business process standpoint, the tool simply can’t support the optimal workflow; this is a side effect of the Last 10% Trap. Most companies end up knuckling under the framework, modifying their processes rather than trying to customize the tool. The more companies do that, the fewer differentiators exist between companies, which is fine as long as that differentiation isn’t a competitive advantage. Companies often choose the alternative, discussed in “Pitfall: Product Customization”, which is another trap.
The Let’s Stop Working and Call It a Success principle is one developers commonly encounter when dealing with ERP packages in the real world. Because they require huge investments of both time and money, companies are reluctant to admit when they don’t work. No CTO wants to admit they wasted millions of dollars, and the tool vendor doesn’t want to admit to a bad multiyear implementation. Thus, each side agrees to stop working and call it a success, with much of the promised functionality unimplemented.
Tip
Don’t couple your architecture to a vendor king.
Rather than fall victim to the Vendor King antipattern, treat vendor products as just another integration point. Developers can insulate vendor tool changes from impacting their architecture by building anticorruption layers between integration points.
Pitfall: Leaky Abstractions
All nontrivial abstractions, to some degree, are leaky.
Joel Spolsky
Modern software resides in a tower of abstractions: operating systems, frameworks, dependencies, and a host of other pieces. As developers, we build abstractions so that we don’t have to perpetually think at the lowest levels. If developers were required to translate the binary digits that come from hard drives into text to program, they would never get anything done! One of the triumphs of modern software is how well we can build effective abstractions.
But abstractions come at a cost because no abstraction is perfect—if it were, it wouldn’t be an abstraction; it would be the real thing. As Joel Spolsky put it, all nontrivial abstractions leak. This is a problem for developers because we come to trust that abstractions are always accurate, but they often break in surprising ways.
Increased tech stack complexity has made the abstraction distraction problem worse recently. Consider the typical technology stack, circa 2005, shown in Figure 8-1.
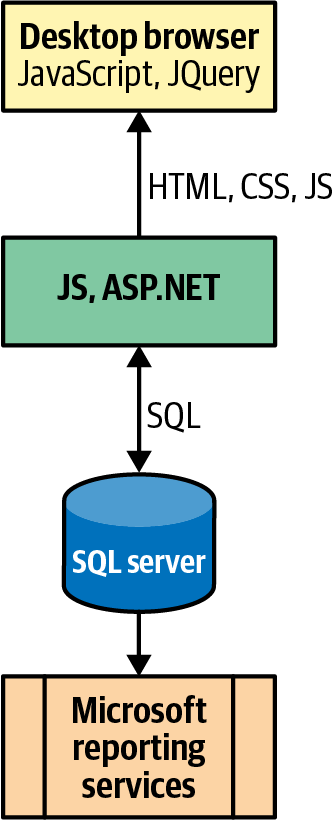
Figure 8-1. A typical technology stack in 2005
In the software stack depicted in Figure 8-1, the vendor names on the boxes change depending on local conditions. Over time, as software has become increasingly specialized, our technology stack has become more complex, as illustrated in Figure 8-2.
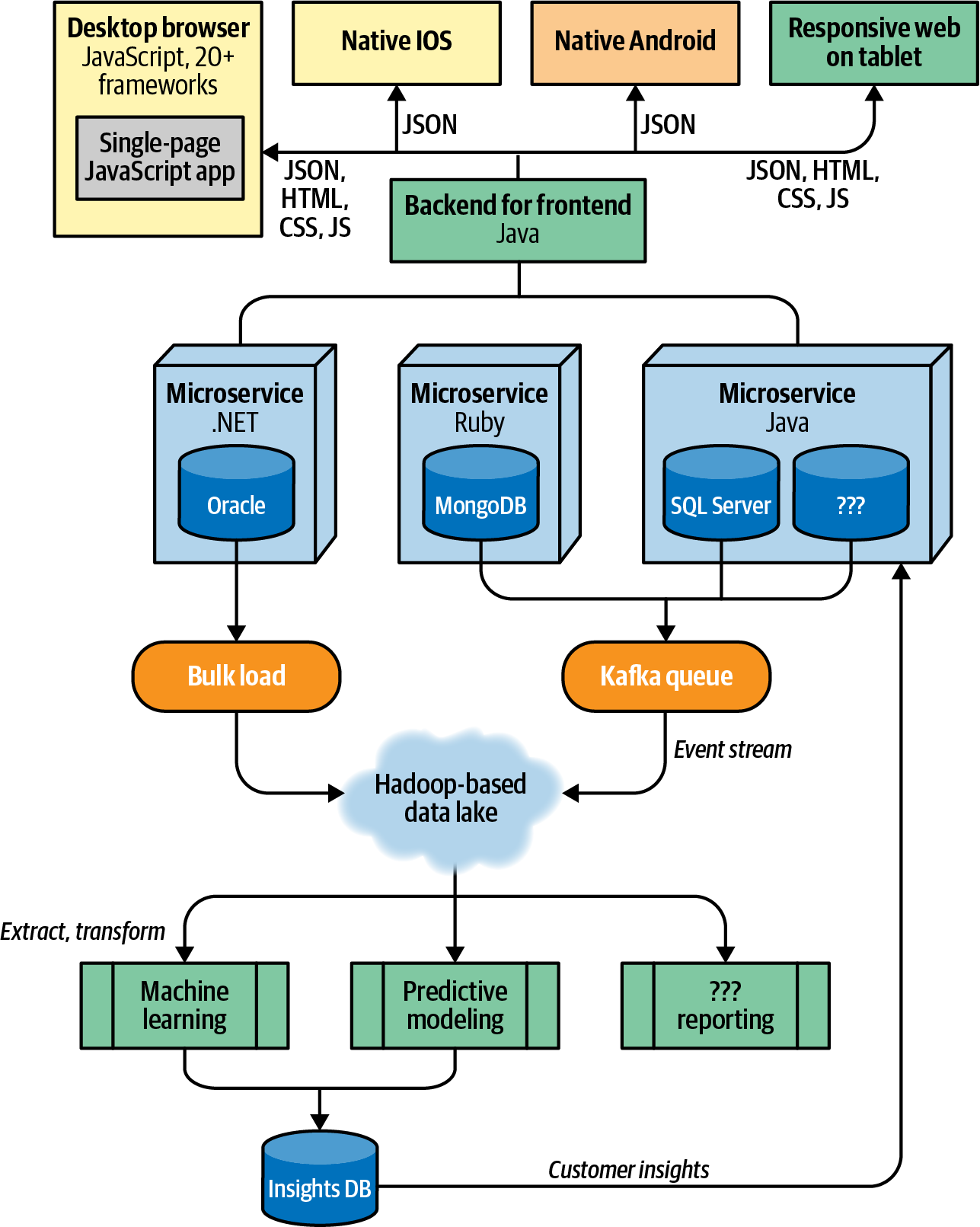
Figure 8-2. A typical software stack from the last decade, with lots of moving parts
As seen in Figure 8-2, every part of the software ecosystem has expanded and become more complex. As the problems developers face have become more complex, so have their solutions.
Primordial abstraction ooze, where a breaking abstraction at a low level causes unexpected havoc, is one of the side effects of increasing complexity in the technology stack. What if one of the abstractions at the lowest level exhibits a fault—for example, some unexpected side effect from a seemingly harmless call to the database? Because so many layers exist, the fault will wind its way to the top of the stack, perhaps metastasizing along the way, manifesting in a deeply embedded error message at the UI. Debugging and forensic analysis become more difficult as the complexity of the technology stack increases.
Always fully understand at least one abstraction layer below the one you normally work in.
Many software sages
While understanding the layer below is good advice, this becomes more difficult as the software becomes more specialized and therefore more complex.
Increased technology stack complexity is an example of the dynamic equilibrium problem. Not only does the ecosystem change, but the constituent parts become more complex and intertwined over time as well. Our mechanism for protecting evolutionary change—fitness functions—can protect the fragile join points of architecture. Architects define invariants at key integration points as fitness functions, which run as part of a deployment pipeline, ensuring abstractions don’t start to leak in undesirable ways.
Pitfall: Resume-Driven Development
Architects become enamored of exciting new developments in the software development ecosystem and want to play with the newest toys. However, to choose an effective architecture, they must look closely at the problem domain and choose the most suitable architecture that delivers the most desired capabilities with the fewest damaging constraints. Unless, of course, the goal of the architecture is the resume-driven development pitfall—utilizing every framework and library possible to tout that knowledge on a resume.
Tip
Don’t build architecture for the sake of architecture—you are trying to solve a problem.
Always understand the problem domain before choosing an architecture rather than the other way around.
Incremental Change
Many factors in software development make incremental change difficult. For many decades, software wasn’t written with the goal of agility in mind but rather around goals like cost reduction, shared resources, and other external constraints. Consequently, many organizations don’t have the building blocks in place to support evolutionary architectures.
As discussed in the book Continuous Delivery (Addison-Wesley), many modern engineering practices support evolutionary architecture.
Antipattern: Inappropriate Governance
Software architecture never exists in a vacuum; it is often a reflection of the environment in which it was designed. A decade ago, operating systems were expensive, commercial offerings. Similarly, database servers, application servers, and the entire infrastructure for hosting applications was commercial and expensive. Architects responded to these real-world pressures by designing architectures to maximize shared resources. Many architecture patterns like SOA flourished in that era. A common governance model evolved in that environment to maximize shared resources as a cost-saving measure. Many of the commercial motivations for tools like application servers grew from this tendency. However, packing multiple resources on machines is undesirable from a development standpoint because of inadvertent coupling. No matter how effective the isolation is between shared resources, resource contention eventually rears its head.
Over the past decade, changes have occurred to the dynamic equilibrium of the development ecosystem. Now developers can build architectures where components have a high degree of isolation (like microservices), eliminating the accidental coupling exacerbated by shared environments. But many companies still adhere to the old governance playbook. A governance model that values shared resources and homogenized environments makes less sense because of recent improvements such as the DevOps movement.
Every company is now a software company.
Forbes Magazine, Nov. 30, 2011
What Forbes means in that famous quote is that if an airline company’s iPad application is terrible, it will eventually impact the company’s bottom line. Software competency is required for any cutting-edge company, and increasingly for any company that wishes to remain competitive. Part of that competency includes how it manages development assets like environments.
When developers can create resources like virtual machines and containers for no cost (either monetary or time), a governance model that values a single solution becomes innappropriate governance. A better approach appears in many microservices environments. One common characteristic of microservices architectures is the embrace of polyglot environments, where each service team can choose a suitable technology stack to implement their service rather than try to homogenize on a corporate standard. Traditional enterprise architects cringe when they hear that advice, which is the polar opposite of the traditional approach. However, the goal in most microservices projects isn’t to pick different technologies cavalierly to right-size the technology choice for the size of the problem.
In modern environments, it is inappropriate governance to homogenize on a single technology stack. This leads to the inadvertent overcomplication problem, where governance decisions add useless multipliers to the effort required to implement a solution. For example, standardizing on a single vendor’s relational database is a common practice in large enterprises, for obvious reasons: consistency across projects, easily fungible staff, and so on. However, a side effect of that approach is that most projects suffer from overengineering. When developers build monolithic architectures, governance choices affect everyone. Thus, when choosing a database, the architect must look at the requirements of every project that will use this capability and make a choice that will serve the most complex case. Unfortunately, many projects won’t have the most complex case or anything like it. A small project may have simple persistence needs yet must take on the full complexity of an industrial-strength database server for consistency.
With microservices, because none of the services are coupled via technical or data architecture, different teams can choose the right level of complexity and sophistication required to implement their service. The ultimate goal is simplification, to align service stack complexity to technical requirements. This partitioning tends to work best when the team wholly owns their service, including the operational aspects.
From a practical governance standpoint in large organizations, we find the “just enough” governance model works well: pick three technology stacks for standardization—simple, intermediate, and complex—and allow individual service requirements to drive stack requirements. This gives teams the flexibility to choose a suitable technology stack while still providing the company some benefits of standards.
Case Study: “Just Enough” Governance at PenultimateWidgets
For years, architects at PenultimateWidgets tried to standardize all development on Java and Oracle. However, as they built more granular services, they realized that this stack imposed a great deal of complexity on small services. But they didn’t want to fully embrace the “every project chooses their own technology stack” approach of microservices because they still wanted some portability of knowledge and skills across projects. In the end, they chose the “just enough” governance route with three technology stacks:
- Small
-
For very simple projects without stringent scalability or performance requirements, they chose Ruby on Rails and MySQL.
- Medium
-
For medium projects, they chose GoLang and either Cassandra, MongoDB, or MySQL as the backend, depending on the data requirements.
- Large
-
For large projects, they stayed with Java and Oracle, as they work well with variable architecture concerns.
Pitfall: Lack of Speed to Release
The engineering practices in Continuous Delivery address the factors that slow down software releases, and those practices should be considered axiomatic for evolutionary architecture to be successful. While the extreme version of Continuous Delivery, continuous deployment, isn’t required for an evolutionary architecture, a strong correlation exists between the ability to release software and the ability to evolve that software design.
If companies build an engineering culture around continuous deployment, expecting that all changes will make their way to production only if they pass the gauntlet laid out by the deployment pipeline, developers become accustomed to constant change. On the other hand, if releases are a formal process that require a lot of specialized work, the chances of being able to leverage evolutionary architecture diminish.
Continuous Delivery strives for data-driven results, employing metrics to learn how to optimize projects. Developers must be able to measure things to understand how to make them better. One of the key metrics Continuous Delivery tracks is cycle time, a metric related to lead time: the time between the initiation of an idea and that idea manifesting in working software. However, lead time includes many subjective activities, such as estimation, prioritization, and others, making it a poor engineering metric. Instead, Continuous Delivery tracks cycle time: the elapsed time between the initiation and completion of a unit of work, which in this case is software development. The cycle time clock starts when a developer starts working on a new feature and expires when that feature is running in a production environment. The goal of cycle time is to measure engineering efficiency; the reduction of cycle time is one of the key goals of Continuous Delivery.
Cycle time is critical for evolutionary architecture as well. In biology, fruit flies are commonly used in experiments to illustrate genetic characteristics partially because they have a rapid life cycle—new generations appear fast enough to see tangible results. The same is true in evolutionary architecture—faster cycle time means the architecture can evolve more quickly. Thus, a project’s cycle time determines how fast the architecture can evolve. In other words, evolution speed is proportional to cycle time, as expressed by
where
Cycle time is therefore a critical metric in evolutionary architecture projects—faster cycle time implies a faster ability to evolve. In fact, cycle time is an excellent candidate for an atomic, process-based fitness function. For example, developers set up a project with a deployment pipeline with automation, achieving a cycle time of three hours. Over time, the cycle time gradually increases as developers add more verifications and integration points to the deployment pipeline. Because time to market is an important metric on this project, they establish a fitness function to raise an alarm if the cycle time creeps beyond four hours. Once it has hit the threshold, developers may decide to restructure how their deployment pipeline works or decide that a four-hour cycle time is acceptable. Fitness functions can map to any behavior developers want to monitor on projects, including project metrics. Unifying project concerns as fitness functions allows developers to set up future decision points, also known as the last responsible moment, to reevaluate decisions. In the previous example, developers now must decide which is more important: a three-hour cycle time or the set of tests they have in place. On most projects, developers make this decision implicitly by never noticing a gradually rising cycle time and thus never prioritizing conflicting goals. With fitness functions, they can install thresholds around anticipated future decision points.
Tip
Speed of evolution is a function of cycle time; faster cycle time allows faster evolution.
Good engineering, deployment, and release practices are critical to success with an evolutionary architecture, which in turn allows new capabilities for the business via hypothesis-driven development.
Business Concerns
Finally, we talk about inappropriate coupling driven by business concerns. Most of the time, business people aren’t nefarious characters trying to make things difficult for developers; rather, they have priorities that drive inappropriate decisions from an architectural standpoint, which inadvertently constrain future options. We cover a handful of business pitfalls and antipatterns.
Pitfall: Product Customization
Salespeople want options to sell. The caricature of salespeople has them selling any requested feature before determining whether their product actually contains that feature. Thus, salespeople want infinitely customizable software to sell. However, that capability comes at a cost along a spectrum of implementation techniques:
- Unique build for each customer
-
In this scenario, salespeople promise unique versions of features on a tight time scale, forcing developers to use techniques like version control branches and tagging to track versions.
- Permanent feature toggles
-
Feature toggles, which we introduced in Chapter 3, are sometimes used strategically to create permanent customizations. Developers can use feature toggles to either build different versions for different clients or create a “freemium” version of a product—a free version that allows users to unlock premium features for a cost.
- Product-driven customization
-
Some products go so far as to add customization via the UI. Features in this case are permanent parts of the application and require the same care as all other product features.
With both feature toggles and customization, the testing burden increases significantly because the product contains many permutations of possible pathways. Along with testing scenarios, the number of fitness functions developers need to develop likely increases as well, to protect possible permutations.
Customization also impedes evolvability, but this shouldn’t discourage companies from building customizable software; rather, they should realistically assess the associated costs.
Antipattern: Reporting Atop the System of Record
Most applications have different uses depending on the business function. For example, some users need order entry, while others require reports for analysis. Organizations struggle to provide all the possible perspectives (e.g., order entry versus monthly reporting) required by businesses, especially if everything must come from the same monolithic architecture and/or database structure. Architects struggled in the service-oriented architecture era trying to support every business concern via the same set of “reusable” services. They found that the more generic the service was, the more developers needed to customize it to be of use.
Reporting is a good example of inadvertent coupling in monolithic architectures. Architects and DBAs want to use the same database schema for both system of record and reporting, but they encounter problems because a design to support both is optimized for neither. A common pitfall developers and report designers conspire to create in layered architecture illustrates the tension between concerns. Architects build layered architecture to cut down on incidental coupling, creating layers of isolation and separation of concerns. However, reporting doesn’t need separate layers to support its function, just data. Additionally, routing requests through layers adds latency. Thus, many organizations with good layered architectures allow report designers to couple reports directly to database schemas, destroying the ability to make changes to the schema without wrecking reports. This is a good example of conflicting business goals subverting the work of architects and making evolutionary change extremely difficult. While no one set out to make the system hard to evolve, it was the cumulative effect of decisions.
Many microservices architectures solve the reporting problem by separating behavior, where the isolation of services benefits separation but not consolidation. Architects commonly build these architectures using event streaming or message queues to populate domain “system of record” databases, each embedded within the architectural quantum of the service, using eventual consistency rather than transactional behavior. A set of reporting services also listens to the event stream, populating a denormalized reporting database optimized for reporting. Using eventual consistency frees architects from coordination—a form of coupling from an architectural standpoint—allowing different abstractions for different uses of the application.
For a more modern approach to reporting specifically and analytical data more broadly, see “Data Mesh: Orthogonal Data Coupling”.
Pitfall: Excessively Long Planning Horizons
Budgeting and planning processes often drive the need for assumptions and early decisions as the basis for those assumptions. However, the larger the planning horizon is without an opportunity to revisit the plan means many decisions (or assumptions) are made with the least amount of information. In the early planning phases, developers spend significant effort on activities like research, often in the form of reading, to validate their assumptions. Based on their studies, what is “best practice” or “best in class” at that time forms part of the basic fundamental assumptions before developers write any code or release software to end users. More and more effort put into the assumptions, even if they turn out to be false in six months, leads to a strong attachment to them. The sunk cost fallacy describes decisions affected by emotional investment. Put simply, the more someone invests time or effort into something, the harder it becomes to abandon it. In software, this is seen in the form of the irrational artifact attachment—the more time and effort you invest in planning or a document, the more likely you will protect what’s contained in the plan or document even in the face of evidence that it is inaccurate or outdated.
Tip
Don’t become irrationally attached to handcrafted artifacts.
Beware of long planning cycles that force architects into irreversible decisions and find ways to keep options open. Breaking large programs of work into smaller, early deliverables tests the feasibility of both the architectural choices and the development infrastructure. Architects should avoid following technologies that require a significant up-front investment before software is actually built (e.g., large licenses and support contracts) and before they have validated through end-user feedback that the technology actually fits the problem they are trying to solve.
Summary
As in any architecture practice, evolutionary architecture embraces many trade-offs: technical, business, operational, data, integration, and many more. Patterns (and antipatterns) appear so much in architecture because they provide not only advice but—critically—the context where that advice makes sense. Reusing software assets is an obvious organizational goal, but architects must evaluate what trade-offs that might entail: often, too much coupling is more harmful than duplication.
We discuss patterns but not best practices, which are virtually nonexistent in software architecture. Best practice implies that an architect can turn their brain off whenever they encounter a particular situation—after all, this is the best way to handle this practice. However, everything in software architecture is a trade-off, meaning that architects must evaluate trade-offs anew for virtually every decision. Patterns and antipatterns can help identify contextualized advice and which antipatterns to avoid.