
Validation beyond XML Schema
In this chapter we look over the fence of pure structural document validation. Although XML Schema does allow us to define constraints that refer to the content of elements of attributes in the form of simple data types, there are many aspects of semantic integrity that cannot be covered in this way.
The chapter discusses various methods for modeling and implementing advanced semantic constraints, such as cross-field and cross-document constraints. The classical method is to hard-code constraints using imperative programming with programming languages such as Java, C++, or Perl. Alternatively, it is possible to soft-code constraints as rules in the form of XSLT stylesheets or as Schematron schemata.
In all these methods, XPath plays a pivotal role as a common language to formulate constraints, one reason to adopt XPath for the conceptual model as well. In particular, the emerging XPath 2.0 specification [Berglund2002], with its support for XML Schema data types, looks very promising.
With this abundance of schema languages and validation methods, we analyze the individual steps during the validation of a document and how the various schema languages cover them. The last section discusses a current standardization effort for the integration of these diverse approaches to schema validation.
9.1 ABOUT MEANING
When XML became popular, one naïve opinion was that—in contrast to HTML—XML documents would express meaning, which would allow semantic processing of documents. This opinion was based on the fact that tags in XML documents are like spoken language—that is, they transfer the meaning of an element to the human reader. However, nothing stops a schema author from naming a field for body height with a <salary> tag. No XML processor would complain, and human readers would be completely misled. This is in contrast to HTML or XML-based application languages, such as SVG, SMIL, and many others, where the meaning of tags is clearly described in the language definition, and processors implement the desired behavior. In HTML, for example, the tag <B>has a clear meaning: The content of the element is to be printed in bold typeface. Tags in XML do not have predefined semantics—actually, the XML specification does not define specific tags at all. The same applies for attribute names, with a few exceptions. There are a few predefined attribute names in XML, such as xml :lang and xmlns, that, indeed, have clearly defined semantics.
To attribute XML tags with meaning requires extra effort beyond the definition of XML schemata. The buzzword is ontologies. An ontology is composed of a vocabulary and additional formal means to describe the semantic relationships between the members of the vocabulary, such as thesauri, semantic networks, constraint systems, and axioms. Ontologies are one subject of the standardization efforts of the W3C activity “Semantic Web” but also of standardization efforts such as ebXML. Here, the discussion will be restricted to constraints. For a detailed discussion of ontologies, see [Daum2002].
The fact that an XML schema does not associate individual tags with a specific meaning should not lead us to the conclusion that the same is true for the whole document. The next section will show that an XML schema imposes a set of constraints on the set of instance documents, and thus indeed defines a limited amount of formal semantics for those documents. Additional semantics can be specified for documents by using methods for constraint definition beyond XML Schema, such as the Schematron (see Section 9.4.3). And, of course, general semantics can be specified via XML processing instructions (see Section 4.2.5) or appinfo elements (see Section 6.3.7), which bind a document to a given application.
9.2 CONSTRAINTS
Apart from the definition of vocabularies and thesauri that can provide a base for understanding the meaning of tags, constraints are an important concept in the definition of formal semantics. This can be explained with a concrete example. Assume that we have a document containing the attribute duration in an element track:
![]()
A human reader (who is acquainted with the ISO notation of time periods) can indeed derive some meaning from this element instance. For a nonvalidating XML parser, however, this element instance does not transmit any meaning. All the parser can recognize is that “track” is the element name, “duration” is an attribute name, and “PT5M33.3S” is a string value associated with this attribute name.
The picture changes when we define a schema for this element and make this schema accessible to an XML processor:

A validating processor that has access to this schema might gain some intelligence from it:
![]() First, it learns that the attribute value is of type duration and can interpret it accordingly. Because duration values are ordered, it can compare the duration values of document instances with each other.
First, it learns that the attribute value is of type duration and can interpret it accordingly. Because duration values are ordered, it can compare the duration values of document instances with each other.
![]() Second, it learns the upper and lower bounds of the duration value and can come to the conclusion that the value in the instance is not exceedingly small or exceedingly large.
Second, it learns the upper and lower bounds of the duration value and can come to the conclusion that the value in the instance is not exceedingly small or exceedingly large.
The concept of constraints is not restricted to single values. In fact, a schema is nothing but a huge constraint itself. It constrains the set of valid documents to a subset of the alphabet’s powerset (see Section 1.5. Even if the schema only imposed structural constraints, we could still get certain useful semantic information from this. Take for example the following schema definition:

This schema allows elements a, b, and c to appear in any order within doc. Now compare it with the following structure:

From this schema we can learn that the elements a and b obviously have a closer relationship with each other than a and c or b and c. We are also told that sequence matters: b must follow a, and c must follow d, which unites a and b into a substructure. This schema does not inform us about the concrete semantics of the document instances; however, given that schema, we learn some semantic aspects about the document instances, such as the relationships between document elements. It is exactly this semantic aspect that gets lost when we flatten a complex structure into the relational First Normal Form to store it in a relational database.
Section 9.2.2 gives a practical example of how such structural constraints can be used to express semantic relationships between two document nodes.
9.2.1 Constraints in XML Schema
Apart from document structure, XML Schema allows us to define additional constraints for document instances:
![]() Data types. In contrast to DTDs, which provide only a few basic data types for attributes, XML Schema allows us to constrain both leaf elements and attributes with a large variety of simple data types. A hierarchy of built-in data types and a rich set of facets to construct additional data types with the help of constraining facets, list extension, and type union allow us to constrain element and attribute content in nearly any imaginable way (see Section 5.2.5).
Data types. In contrast to DTDs, which provide only a few basic data types for attributes, XML Schema allows us to constrain both leaf elements and attributes with a large variety of simple data types. A hierarchy of built-in data types and a rich set of facets to construct additional data types with the help of constraining facets, list extension, and type union allow us to constrain element and attribute content in nearly any imaginable way (see Section 5.2.5).
![]() Uniqueness and cross-references. XML Schema refines and extends the cross-referencing concept found in DTDs. The unique, key, and keyref constructs complement the ID and IDREF data types known from DTDs (see Section 4.4.4). The cross-reference constraints are cross-field constraints, because they relate the contents of one document node instance to the contents of another.
Uniqueness and cross-references. XML Schema refines and extends the cross-referencing concept found in DTDs. The unique, key, and keyref constructs complement the ID and IDREF data types known from DTDs (see Section 4.4.4). The cross-reference constraints are cross-field constraints, because they relate the contents of one document node instance to the contents of another.
As an example, we look again at the schema album from Section 8.2.7, along with its diagram, in Figure 9.1 (page 328). This schema already defines some cross-references, but it has been extended with additional constraints.
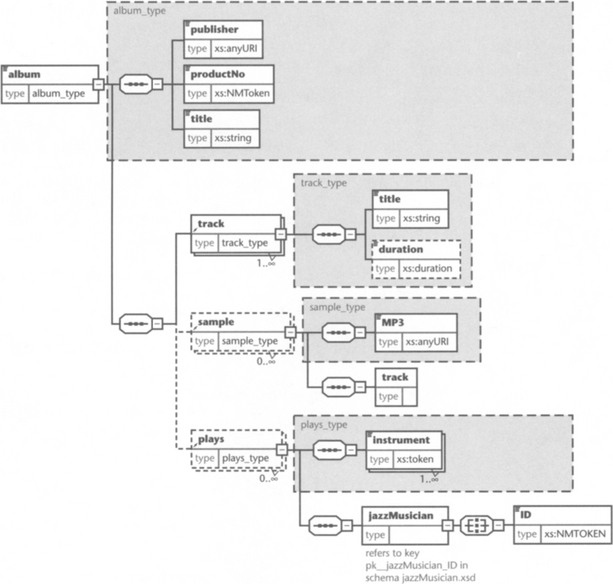


This schema defines a cross-field constraint by means of XML Schema. For each track referenced in a sample/track/@trackNo attribute, there must exist a track element with a corresponding album/track/@trackNo attribute. As shown above, this sort of constraint can be easily implemented with XML Schema. Note that we have applied this constraint to derived types. The definition of sample/track/@trackNo is contained in sample_type, while the definition of album/track/@trackNo is contained in track_type. The introduction of such a cross-field constraint to the album schema effectively sub-types the album element type.
We have added another constraint, too. We wanted to ensure that every track has a different title. We can define this constraint with the help of the unique clause as shown above. Note that this is a cross-field constraint, too, as it relates different album/track/title element instances to each other.
9.2.2 Constraints beyond XML Schema
The constraining power of XML Schema ends when it comes to general cross-field constraints or even cross-document constraints.
Cross-Field Constraints
Let’s return to our jazz example. There are a few properties that are good candidates for cross-field constraints. Take for example the definition of type period-Type, which is used in several schemata:

What immediately springs to mind is that the value of the from element must be smaller than or equal to the value of the to element if it exists. However, there is no way to define this in XML Schema.
For another example let’s return for a moment to our album schema from the previous section. There is one more thing that we want to constrain: the total duration of an album. We want to restrict the sum of all track durations by an upper limit, let’s say 240 minutes. Again, this constraint is impossible to express in XML Schema. (Section 9.4 discusses how we can validate such constraints.) But beware. Sometimes it is possible to express a constraint in XML Schema when it is not so obvious. Take for example the schema jazzMusician. During the modeling process we introduced a constraint: If a jazz musician is an instrumentalist, he or she must play at least one instrument (see Section 3.6. In Section 8.2.4 we arrived at the following type definition for jazzMusician:

This schema, of course, does not implement the above constraint. But we can try to express this constraint by means of XML Schema.
We duplicate the sequence clause and place it into a choice clause. Within the first choice branch we restrict the possible values of kind to instrumentalist and set minOccurs=“1” for element instrument (we could also just drop the minOccurs clause). In the second branch we restrict the values of kind to jazzComposer and jazzSinger.


Well, this failed. Expressing the constraint
![]()
by means of type restriction and structure resulted in a nondeterministic schema—the schema does not satisfy XML Schema’s Unique Particle Attribution constraint. Each branch of the choice clause begins with an element named kind. To decide which branch to take, the parser would have to look ahead into the content of each kind element and check the content against the respective type definition. So this schema is wrong!
The same schema translated to Relax NG, however, would be correct. Relax NG does not require nondeterministic content models:


In XML Schema a solution for this problem would be to define the type jazzMusician_type as abstract, to derive types intrumentalist_type,jazzComposer_type, and jazzSinger_type from this abstract type, and to use the xsi:type mechanism (see Section 6.2.4) to instantiate the abstract type in the document instance:

Document instances of jazz musicians must now specify a concrete type using the xsi:type notation. This is also the reason why we were able to omit the element kind: The kind of jazz musician is sufficiently described via the xsi:type attribute.

Cross-Document Constraints
Cross-document constraints are constraints that involve multiple documents, even documents from different document types. Typically we have four types:
![]() Uniqueness constraints. A document that has an identifying primary key may have the constraint that there is only one document with that key value. For example, if we have a jazzMusician document with an ID value of “Bley-Carla,” we don’t want to have other documents with the same ID value around.
Uniqueness constraints. A document that has an identifying primary key may have the constraint that there is only one document with that key value. For example, if we have a jazzMusician document with an ID value of “Bley-Carla,” we don’t want to have other documents with the same ID value around.
![]() Referential integrity constraints. A document can rely on the fact that other documents to which it refers exist. For example, a band document “ArtEnsembleOfChicago” may rely on the presence of jazzMusician documents for the musicians collaborating in the band: “BowieLester,” “Mitchell-Roscoe,” “JarmanJoseph,” “FavorsMalachi,” and “MoyeDon.”
Referential integrity constraints. A document can rely on the fact that other documents to which it refers exist. For example, a band document “ArtEnsembleOfChicago” may rely on the presence of jazzMusician documents for the musicians collaborating in the band: “BowieLester,” “Mitchell-Roscoe,” “JarmanJoseph,” “FavorsMalachi,” and “MoyeDon.”
![]() Cardinality constraints. Given that a document relies on the existence of other documents, it may require that a certain number of those documents exist. Take for example the documents band, jamSession, project. All these collaborations refer to at least two jazzMusician documents. Otherwise we could hardly speak of collaboration
Cardinality constraints. Given that a document relies on the existence of other documents, it may require that a certain number of those documents exist. Take for example the documents band, jamSession, project. All these collaborations refer to at least two jazzMusician documents. Otherwise we could hardly speak of collaboration
However, this constraint type can be expressed with a normal cardinality constraint for the document node that implements the foreign key. Thus, we can express the cardinality constraint by means of XML Schema, and referential integrity does the rest. In Section 8.2.8 the above relationship was expressed with

What remains is to check the referential integrity for each jazzMusician element.
![]() General constraints. There may be additional semantic relationships between different documents. For example, the period/from date in the band or project document or the time date in a jamSession document should not be smaller than the birth date of the jazz musicians collaborating in such a band, project, or jam session.
General constraints. There may be additional semantic relationships between different documents. For example, the period/from date in the band or project document or the time date in a jamSession document should not be smaller than the birth date of the jazz musicians collaborating in such a band, project, or jam session.
While cross-field constraints are relatively easy to validate (as we will see in Section 9.4, the same cannot be said for cross-document constraints. In relational databases, in contrast, constraints across multiple tables are not a big issue. SQL provides the necessary means to check these constraints, such as integrity rules and triggers (see Section 11.9.
That the situation with XML documents is different has nothing to do with the inherent properties of XML. What makes the validation of cross-document constraints difficult is not XML by itself but the fact that XML is used in a different scenario. In general, we cannot make a closed world assumption for a set of XML documents as we can for a relational database. Instead, we can expect that the documents will be distributed across several servers, even the whole Internet. Some of these servers may be mobile, and not all may be accessible at a given time. This makes it practically impossible to maintain referential integrity and other cross-document constraints at all times. The all too familiar 404-response code for dangling hyperlinks in HTML documents illustrates this situation. So, in many cases it will be necessary to replace the traditional cross-document constraint validation, which is executed before a document is stored or updated, with a process of synchronization and repair that is applied after a document has been stored.
9.3 CONSTRAINTS IN CONCEPTUAL MODELS
Defining constraints in a conceptual model requires a constraint definition language. Several formal constraint definition languages have been defined in the past. Most of these languages never left the academic sphere. Adoption in the industry has been poor because the formalism of these languages makes them difficult for industry programmers and designers to read. A specification language that is not understood by programmers is worse than an informal specification of constraints in natural language.
This is one reason for the definition of the Object Constraint Language (OCL), which has been part of the Unified Modeling Language (UML) since UML 1.1.
There is a need to describe additional constraints about the objects in the model. Such constraints are often described in natural language. Practice has shown that this will always result in ambiguities. In order to write unambiguous constraints, so-called formal languages have been developed. The disadvantage of traditional formal languages is that they are useable to persons with a strong mathematical background, but difficult for the average business or system modeler to use. [OCL1997]
However, OCL is also not widely adopted. The tool support for OCL is patchy at best. One notable exception is a recent open source CASE tool, ArgoUML (argouml.tigris.org), and its commercial offspring, Poseidon (www.gentleware.com). Both include an OCL-to-Java compiler.
What makes the situation even more difficult for our purposes is that OCL is designed for object-oriented design methods and object-oriented implementations. OCL was not really designed with the document data model in mind.
That can make the definition of constraints for document-centric models difficult. Therefore, the following sections concentrate on the use of XPath [Clark1999] as a constraint language. This choice has several advantages:
![]() Document designers, stylesheet editors, and programmers familiar with XML know XPath well.
Document designers, stylesheet editors, and programmers familiar with XML know XPath well.
![]() XPath constraints can be easily translated into XSLT stylesheets or Schematron schemata (see Section 9.4.2), which can be used to validate documents.
XPath constraints can be easily translated into XSLT stylesheets or Schematron schemata (see Section 9.4.2), which can be used to validate documents.
![]() XPath is sufficiently powerful to express arbitrary constraints. Although XPath 1.0 does not support XML Schema data types (for example, comparison of date and time values), XPath 2.0 will offer full support.
XPath is sufficiently powerful to express arbitrary constraints. Although XPath 1.0 does not support XML Schema data types (for example, comparison of date and time values), XPath 2.0 will offer full support.
The following example shows how to formulate constraints with XPath in an AOM conceptual model. AOM (see Chapter 2) is not limited to a single constraint language but allows the use of arbitrary constraint languages, even mixed within one model.
Now, let’s see how we define a constraint for an asset property in AOM:
![]() Properties in an asset are addressed with an XPath expression consisting of the name of the property. Subproperties specify the path of the subproperty relative to the asset, for example, name/last.
Properties in an asset are addressed with an XPath expression consisting of the name of the property. Subproperties specify the path of the subproperty relative to the asset, for example, name/last.
![]() Properties in other assets are addressed by including the arc leading to this asset in the XPath expression. If the arc has a role name, we include the role name in the path, too. For example, if we want to address the property publisher in asset album from asset project, we write result/album/publisher.
Properties in other assets are addressed by including the arc leading to this asset in the XPath expression. If the arc has a role name, we include the role name in the path, too. For example, if we want to address the property publisher in asset album from asset project, we write result/album/publisher.
Take for example the asset jamSession. We want to express the constraint that a jam session must not start before the birth date of a participating musician. We define the constraint within asset jamSession and do not specify an explicit context:
![]()
So, the context of this constraint defaults to jamSession, and time addresses property jamSession/time. The expression jazzMusician/birthDate addresses property birthDate in asset jazzMusician, which can be reached via an arc from asset jamSession. This arc has the cardinality constraint [2..*], and consequently this constraint must hold for at least two jazzMusician instances referred to by jamSession.
Let’s briefly discuss the various constraints defined in the example, shown in Figure 9.2. First, the asset period contains the constraint
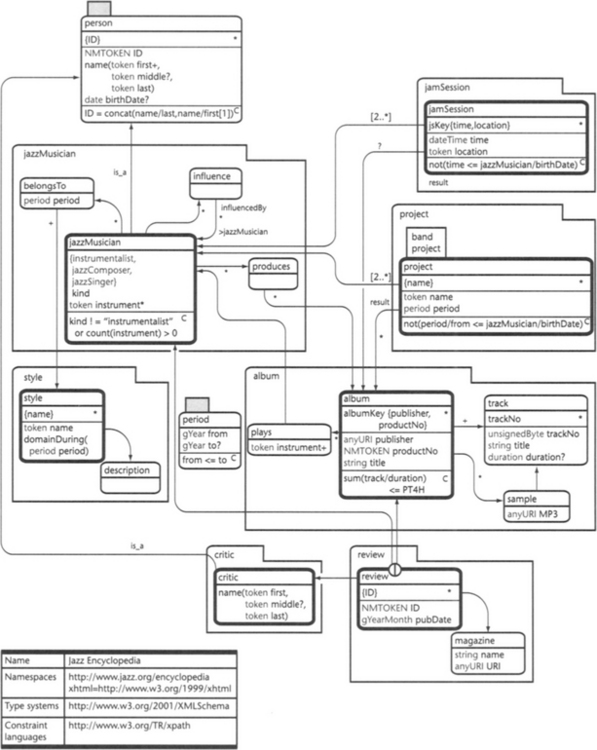
![]()
which defines that the beginning of a period must be smaller than or equal to the end. This constraint applies to the assets belongsTo, style, project, and band because asset period is used in these assets as the type.
Asset person contains the constraint
![]()
This constraint postulates that the ID of a person must be obtained from the concatenation of its last name with the first occurrence of a first name. This constraint applies to both assets critic and jazzMusician because both inherit from person via the is_a relationship.
Next, the asset jazzMusician contains the constraint
![]()
This constraint specifies that an instrumentalist must play at least one instrument. As already pointed out in Section 9.2.2, it is possible to model this constraint completely by means of structure and type constraints. The conceptual model could reflect this by defining asset jazzMusician as

However, the original definition with the added constraint has advantages in terms of readability.
The two assets band and project contain the constraint
![]()
This constraint makes sure that the beginning of the period during which a band or project exists is greater than the birth date of each participating musician. period/from refers to the subproperty from of property period. This subproperty is defined in the asset type period. Note that the simpler expression
![]()
![]()
which we have already discussed.
Finally, the asset album contains the constraint
![]()
This constraint states that the sum of all track/duration properties must be less than or equal to four hours.
9.4 VALIDATION OF GENERAL CONSTRAINTS
This section covers how constraints, as discussed in Section 9.3, can be implemented. By formulating constraints in XPath, we have the advantage of choices among several implementation options.
9.4.1 Hard-Coded Constraint Checks
One of the most commonly used methods for validating general constraints (which often appear in the form of Business Rules) is hard-coding them into the application logic. For example, in a Java application, the application code would parse the document instances into DOM trees, and then would test the DOM nodes for compliance with the constraints.
An advantage to using XPath for constraint expressions is that these expressions can be used directly with newer DOM APIs, which can save a substantial amount of coding effort. The current working draft of the “Document Object Model (DOM) Level 3 XPath Specification” [Whitmer2002] defines an (optional) access layer to the document node via XPath expressions. This would allow us to address document elements directly with their path specification and formulate constraints as XPath filter expressions. For example, the constraint
![]()
could be tested with the following Java DOM call,

where jazzMusician represents the root node of a jazzMusician document. Note that this code is hypothetical, as the specification mentioned above is still a working draft.
Current XPath processors usually come packaged within XSLT processors (because XPath was once a part of the XSL specification). However, there are also standalone XPath processors available, such as Jaxen (www.jaxen.org). An interesting development is also JXPath, which is part of Apache’s Jakarta project. JXPath allows the use of XPath expressions to access Java data structures (www.apache.org).
Things get a bit more complicated when we want to check cross-document constraints. The following Java code illustrates how the constraint
![]()
which checks between jamSession and jazzMusician, can be validated by using standard DOM Level 2 API access methods:

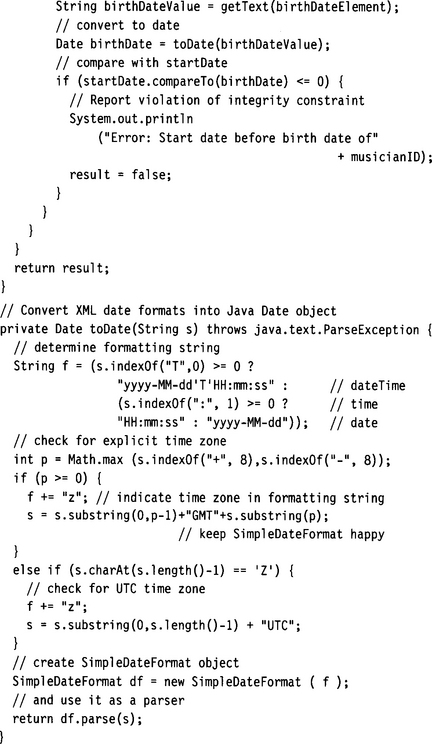
The method toDate() is required to convert the xs:date or xs:dateTime formats into java.util.Date objects.
What is not shown here is the implementation of the method perform-Query (). This method is used to fetch documents by key. The implementation of this method depends, as a matter of fact, on the storage medium: relational database, native XML database, file system, and so on.
9.4.2 XSLT
The advantage of such hard-coded constraints lies in performance benefits. The disadvantage, however, is that the change of a constraint requires rebuilding the application (at least to recompile all classes that implement this constraint). The alternative is to soft-code constraints. This can be done by writing an XSLT stylesheet [Clark1999a] that validates the document instances. Again, the use of XPath for constraint expressions has an advantage here: XSLT is based on XPath—both were once parts of the XSL specification. Running such an XSLT stylesheet against a document instance could result in another XML document containing an error report on which constraints have been violated.
The following stylesheet checks instances of the album schema (see Section 8.2.7) for the constraint
![]()
I have deliberately chosen this constraint because it presents a problem. PT4H is an expression that is not understood by XPath 1.0 or XSLT 1.0, as neither specification supports XML Schema data types. We have the option of either using an XSLT extension—for example, one provided by EXSLT (www.exslt.org)—or waiting for the first XPath/XSLT processors supporting XML Schema data types. XPath 2.0 [Berglund2002] will support XML Schema data types, and so will XSLT 2.0 [Kay2002].
The other option would be to fall back to pre-XML Schema times and express the duration in seconds. Then the constraint would look like this:
![]()
But let’s assume we already have an XSLT 2.0 processor. We create a little stylesheet to implement the above constraint. (For an introduction to XSLT, see [Kay2001].) First, we set up the namespaces for XSLT and for the Jazz model. For the Jazz model namespace we use j: as a prefix. We have also set up a namespace prefix xf: for XPath and XQuery Functions, which are needed to define a literal of type xs:duration.


The first template is the document node template and simply directs template processing to its child elements (which is the album element).
The second rule matches the context album—that is, the root element of album instances. It contains an <xsl : if> clause, which checks the constraint. Because we want to produce output when the constraint fails, the test clause contains the Boolean negation of the constraint:
![]()
The expression xf:duration(’PT4H’) constructs a literal of type xs:duration with the specified value. The rest is just producing meaningful output.
Now we run the following document through this stylesheet:


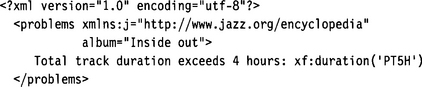
If our document instance contains tracks with a total duration longer than four hours, the following output document is produced:
The next example shows how to check constraints across documents. To do this, we make use of the XSLT document() function. We use XSLT 1.0 here despite the fact that XML Schema data types are involved. But first we have to explain how to address a document by key. When our documents are stored in a database system, retrieving a document by key is usually an efficient operation. Database systems can construct indexes and allow for searching data objects by key via an index.
The way such a query is passed to the database system—in particular within the parameter of the document() function—depends on the database system used. For example, a database system may require that the database is specified by URL and the document type and key are specified in the query part of the string. A query may consist of the following URL:
![]()
However, the format of database access is currently not standardized in any way, and different database systems may use different formats. The format used here is that of the native XML database Tamino (www.softwareag.com). Here, we assume that all XML files are stored in a plain file system, and that the file name is constructed from the name of the document type and the key, such as
![]()
and this is what we pass to the document() function.
The constraint, which we implement in the following stylesheet, is
![]()
Again, we first set up the namespaces and write the template for the document node:


In the second template we prepare the output document and then apply templates to all child elements. This has the advantage of allowing us to process each jazzMusician element individually, thus producing a detailed error report. The third template contains the actual constraint check. First, in the <xsl:choose> clause, we make sure that the referenced jazzMusician file really exists (we do a check for referential integrity). If not, we give an error message.
Note that this does not work with all XSLT processors. Some processors may just throw an exception when the referenced document does not exist. When the document() function fails, an XSLT processor is free to throw an exception or to return an empty node list. The purpose of the <xsl:choose> clause is to catch the case of empty node lists.
In case of success, the <xsl:if> clause performs the actual constraint check. Because the period/from element only contains the year, we also extract the year from the birth date delivered by the document() function. Since XPath 1.0 is not type aware, we use the number() function to convert both strings into a number before we compare them. The final template is used to override the built-in default clause and does nothing.
9.4.3 Schematron
The technique discussed in the previous section has been sophisticated by Schematron (http://www.ascc.net/xml/schematron). Schematron can be used independently or in conjunction with DTDs, XML Schema, and Relax NG. With Schematron, schema authors do not need to dig deep into XSLT but can formulate constraints with XPath and a few additional statements. A Schematron schema can be formulated as a separate standalone document, or it can be embedded into XML Schema or Relax NG in the form of annotations. Validators that are not Schematron aware will ignore these statements, while Schematron processors can extract the embedded Schematron statements to process them. An interesting development is the Sun Multi-Schema XML Validator Schematron Add-on, which can process Relax NG schemata with embedded Schematron statements in one step.
In the standalone form, the Schematron compiler translates the Schematron schema into an XSLT stylesheet and then utilizes the stylesheet to validate document instances. The Schematron compiler is actually implemented as an XSLT stylesheet, too. A Windows front end that streamlines this process is available at www.topologi.com.
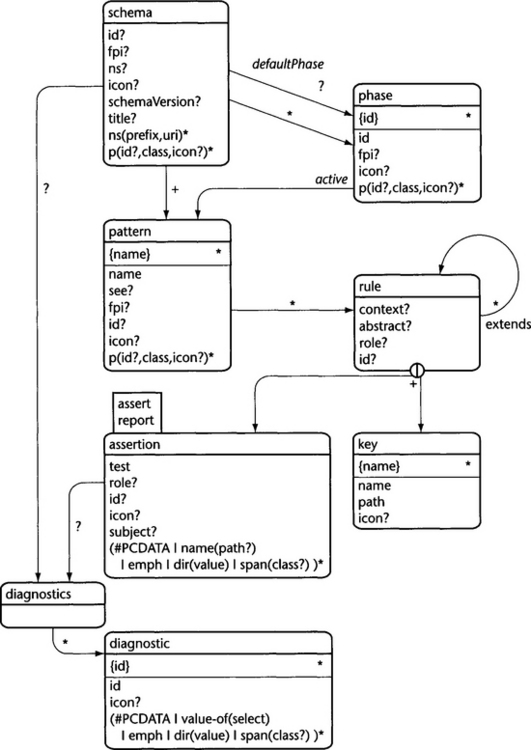
Schematron introduces a few of its own declarations: schema, phase, pattern, rule, assert, report, key, and diagnostics. Figure 9.3 (page 350) shows the metamodel of Schematron with all language elements. The clauses assert and report define single tests (a single constraint). These can be grouped together with the pattern clause. The phase clause is used to organize the workflow within a validation suite. These declarations are covered briefly in the following pages.
Schema
The schema clause defines a Schematron schema.

Within the schema declaration, the definition of phase and pattern is essential. Patterns combine one or several assertion rules to a group. There must be at least one pattern group defined in a schema. Patterns are referenced by phases. Each phase element may refer to one or several patterns via child elements named active. Which phases are executed during a validation can be specified via parameters (such as command line parameters) when the validation sheet is executed against document instances. If no such phase is specified, the phase defined in attribute defaultPhase is executed. If no such attribute is specified, all phases in the schema are executed. If no phases are defined in a schema, all patterns are executed.
The functions of other child elements and attributes are as follows:
![]() The child elements title and p serve documentation purposes, title contains the schema title, while p elements may contain marked-up content for further description.
The child elements title and p serve documentation purposes, title contains the schema title, while p elements may contain marked-up content for further description.
![]() The ns child elements can be used to declare namespaces used in the document instance. The syntax is <ns prefix=“prefix “uri=”uri”/>.
The ns child elements can be used to declare namespaces used in the document instance. The syntax is <ns prefix=“prefix “uri=”uri”/>.
![]() The ns attribute can define a namespace for the vocabulary defining role values (see “Rule” section).
The ns attribute can define a namespace for the vocabulary defining role values (see “Rule” section).
![]() The icon attribute may specify a URI pointing to an icon such as a GIF file. This will appear in the output document.
The icon attribute may specify a URI pointing to an icon such as a GIF file. This will appear in the output document.
![]() The fpi attribute allows specifying an SGML Formal Public Identifier.
The fpi attribute allows specifying an SGML Formal Public Identifier.
![]() Finally, there is a group of diagnostics. This is a set of detailed descriptions that explain the reason why a rule has produced a message. These diagnostics are referred to by assert and report clauses (explained below). The output of diagnostics is optional and can be set with a parameter before execution.
Finally, there is a group of diagnostics. This is a set of detailed descriptions that explain the reason why a rule has produced a message. These diagnostics are referred to by assert and report clauses (explained below). The output of diagnostics is optional and can be set with a parameter before execution.
Phase
The organization into phases allows various validation sequences that are executed on different occasions to be combined into a single schema. The patterns to be checked in a phase are specified via the active child elements.

Phases are used to organize the workflow. For example, we could have a phase that is executed when a new document instance is created, and another phase that is executed when a document instance is deleted. Another application for phases is to combine validation sequences for different purposes. One phase could check document instances for structure violations, another phase could check for best practices or corporate standards, and another could check for accessibility. Or, we could have different phases for new documents, draft documents, and final documents.
Pattern
pattern clauses combine one or several rules into one group. Patterns are referred to by phases.

Patterns are named; the name is displayed with the produced message in the output document. The id attributes may be used to identify a pattern. This value is specified by phase clauses via their active child elements to list a pattern as active. The see attribute may point to additional documentation via a URL.
Each pattern may list several rules to be executed. Which rule is executed depends on its context attribute (see “Rule”). The first rule with a matching context expression is executed; thereafter, the execution of the pattern stops. The context attribute consists of an XPath expression (XPath with the extensions defined in XSLT).
Rule
Rule clauses organize one or several constraints into one group. The context attribute controls the execution of the rule.

Rules can be declared as abstract. In this case they are not executed but are only referred to by other rules to inherit their properties. This is done via the extends clause: <extends rule=“rule-id”>. Abstract rules cannot define a context attribute; the context is defined by the inheriting rules.
The role attribute can be used by schema authors to classify or annotate the rule. The schema author may specify arbitrary values; a vocabulary can be defined with the ns attribute in the schema clause. The role attribute has no influence on the validation process.
Each rule contains one or several assert, report, key, or extends clauses.
Assert and Report
Both assert and report clauses are structurally identical:

The test attribute contains the XPath expression to be checked by the rule within the specified context. An assert rule will fire when the test fails, while a report rule will fire when the test succeeds. The effect is that the message specified in the body of the clause is written to the output document. This message can be marked up with several tags (name, emph, dir, span):
Key
The key clause exploits the key mechanism of XSLT within rules to check for cross-reference constraints.

The attribute name specifies the name of the key. path specifies an XPath expression identifying the document node constituting the key. Defined keys can be referred to from XPath expressions within a rule via the XSLT function key(name,value). But beware: Only a few XSLT processors, such as Saxon and MSXML, support the key construct.
Diagnostics
The diagnostics attribute may specify one or several IDs of diagnostic messages (see “Assert and Report”) that further explain the reason why the rule fired.
| Name | Attributes | Contains |
| diagnostics | diagnostic* |
| Name | Attributes | Contains |
| diagnostic | id | (#PCDATA | value-of | emph | dir | span)* |
| icon? |
The diagnostics section contains a set of diagnostic messages. These are identified by their id and referred to by assert or report clauses. The body of a diagnostic message contains text that can be marked up with value-of, emph, dir, or span. (value-of has the same meaning as in XSLT.)
Schematron Example 1
The following example implements the constraint
![]()
Again, we specify the duration in seconds (integers) because XSLT 1.0, on which Schematron relies, does not support XML Schema data types.
The schema contains only a single pattern and a set of diagnostics. There are no phases defined, so the only pattern is always executed when a document is validated by the schema. First, we declare the Schematron namespace as the default namespace, and a namespace prefix for our Jazz model. The latter is also defined in an ns child element. The xmlns:j attribute defines the namespace for the schema, while the ns child element defines the same namespace for the validation sheet generated from the schema.

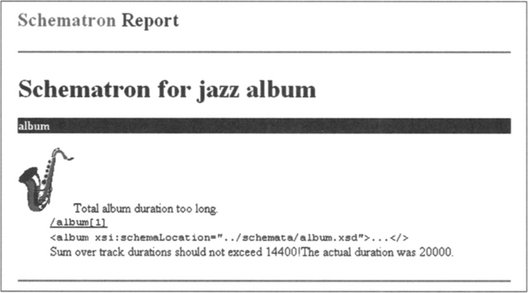
The pattern contains a single rule with an assert clause. This clause sets up the context (root element album) and test for the constraint sum(track/duration) <= 14400. If this test fails, the message “Total album duration too long.” is written to the output document. Since this assert clause refers to the diagnostic elements dur1 and dur2, the messages defined in these elements will be written to the output document if the output of diagnostics was not suppressed. Also, an image pointer will be generated there because we have specified an icon.
The output is produced as an HTML file and should look like Figure 9.4.
Schematron Example 2
The next example is our cross-document constraint:
![]()
The implementation with Schematron makes use of the fact that Schematron accepts the XSLT extensions to XPath, in particular the document() function.
We have implemented two phases. The first phase checks only for referential integrity—that the jazzMusician document, to which band/jazzMusician/ID refers, exists. Note that, as above, depending on the XSLT processor used, an unresolved reference may abort the validation with an exception.
The second phase checks the actual constraint.


Also in this case, it would be possible to embed the Schematron instructions into the XML Schema file for band, as discussed in the next section.
Embedding Schematron into XML Schema
One of the nice things about Schematron is that we can include the above constraints as annotations in an XML Schema file. When this file is processed with the Schematron compiler, it will automatically harvest the Schematron statements from the annotation/appinfo elements. Here is the album schema from Section 8.2.7 with Schematron statements included:


To be consistent with the rest of the schema definition, we have here prefixed all Schematron element names with sch:. The default namespace is set to our jazz target namespace. However, the prefix j: must still be specified with an ns element to identify the jazz namespace to the resulting validation sheet.
Embedding Schematron into Relax A/G
Embedding Schematron declarations into Relax NG is even simpler, and using the multi-schema validator mentioned earlier allows us to validate the combined schema in one step. The validator currently only supports the Schematron declarations rule, assert, and report.


Here, it is not necessary to use a rule clause to specify the context of the assert clause. The context is simply defined by the location where the assert clause is specified (the album element).
9.5 AN XML PROCESSING MODEL
In this book we have looked at three different schema definition languages: DTDs (the legacy), the “object-oriented” XML Schema, and grammar-based Relax NG. Each has its merits and its weaknesses. The reader will have noticed that, for example, XML Schema and Relax NG do not cover external entities, so many applications will have to continue using DTDs. DTDs, on the other hand, cannot handle namespaces; and Relax NG has no concept of default and fixed values, and for cross-references, it relies on DTD logic.
We have also looked at several techniques to implement semantic constraints, which allow us to test not only if a document is valid but also if it is meaningful—an important topic as we move toward the Semantic Web. One of these techniques is Schematron, a schema language based on assertions.
For the implementer, this raises the question of how this all fits together. Which schema language is the correct one to use? Do we need to use a second schema language in addition to the first choice? What does the parser do, and what part of the implementation must be customized? In Figure 9.5, the document parsing process has been divided into sharply defined minitasks. This is in part based on Simon St. Laurent’s analysis in “Toward a Layered Model for XML” [St.Laurent1999].
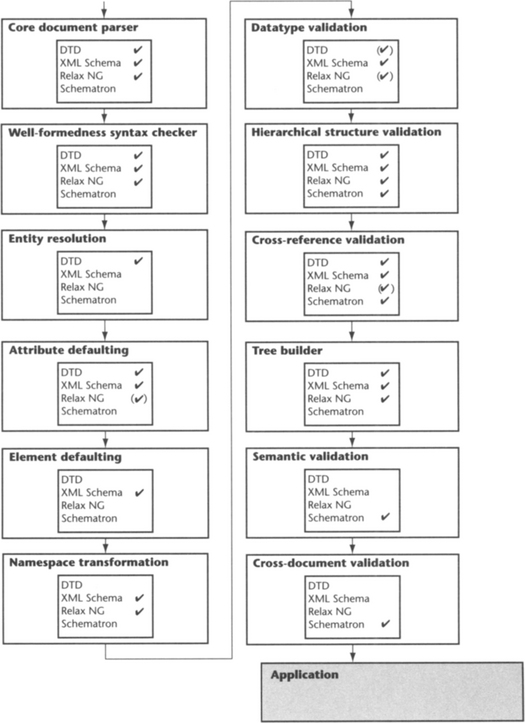
Figure 9.5 Tasks during the validation of an XML document. There is actually only one task (hierarchical structure validation) that is fully supported by all schema languages. (Checkmarks in parentheses denote partial support for a task.)
Most parsers handle several steps in this process. As mentioned in Section 9.4.3, there is actually a parser that does it all (Sun Microsystem’s multi-schema validator with Schematron add-on). However, in other cases, it may be necessary to run a document through several parsers and passes, and combine the output from these passes.
9.6 A FRAMEWORK FOR SCHEMA LANGUAGES
The multitude of schema languages indicates that there is not a single schema language fit for all purposes. XML Schema is best suited where XML is used in connection with databases and application-to-application messaging, such as electronic business and the integration of heterogeneous data formats. The traditional SGML community would probably like to stay with DTDs, enhanced by namespace support, or might migrate to Relax NG. In areas where documents need to be checked for complex structural constraints and for semantic constraints, Schematron shines.
A current standardization effort at ISO/IEC tries to combine the concepts of all of these schema languages into a modular framework. The Document Schema Definition Language (DSDL) [Holman2001] is “a multipart International Standard defining a modular set of specifications for describing the document structures, data types, and data relationships in structured information resources.”
DSDL identifies six regions relevant to schema definitions:
![]() Grammar-oriented schema languages, naming Relax NG as an example.
Grammar-oriented schema languages, naming Relax NG as an example.
![]() Primitive data type semantics, naming Part Two (data types) of the XML Schema Recommendation as an initial basis.
Primitive data type semantics, naming Part Two (data types) of the XML Schema Recommendation as an initial basis.
![]() Path-based integrity constraints, with Schematron as an initial basis.
Path-based integrity constraints, with Schematron as an initial basis.
![]() Object-oriented schema languages. This part is initially based on Part One (structure) of the XML Schema Recommendation and the sections of Part Two of W3C XML Schema describing the derivation of new simple types and the syntax for referring to primitive data types.
Object-oriented schema languages. This part is initially based on Part One (structure) of the XML Schema Recommendation and the sections of Part Two of W3C XML Schema describing the derivation of new simple types and the syntax for referring to primitive data types.
![]() Information item manipulation such as default values (as in DTDs), synonyms, and the eliding of information items.
Information item manipulation such as default values (as in DTDs), synonyms, and the eliding of information items.
![]() Namespace-aware processing with DTD syntax, basically covering the XML V1.0 specification plus XML namespaces.
Namespace-aware processing with DTD syntax, basically covering the XML V1.0 specification plus XML namespaces.
Such a framework could help to gain a clearer understanding of the various schema languages and how they relate to each other. It could do the same for schema validation as the ISO layer model has done for communication.