
Appendix B. More about the workings of HDFS
Hadoop Distributed File System (HDFS) is the underlying distributed file system that is the most common choice for running HBase. Many HBase features depend on the semantics of the HDFS to function properly. For this reason, it’s important to understand a little about how the HDFS works. In order to understand the inner working of HDFS, you first need to understand what a distributed file system is. Ordinarily, the concepts at play in the inner workings of a distributed file system can consume an entire semester’s work for a graduate class. But in the context of this appendix, we’ll briefly introduce the concept and then discuss the details you need to know about HDFS.
B.1. Distributed file systems
Traditionally, an individual computer could handle the amount of data that people wanted to store and process in the context of a given application. The computer might have multiple disks, and that sufficed for the most part—until the recent explosion of data. With more data to store and process than a single computer could handle, we somehow needed to combine the power of multiple computers to solve these new storage and compute problems. Such systems in which a network of computers (also sometimes referred to as a cluster) work together as a single system to solve a certain problem are called distributed systems. As the name suggests, the work is distributed across the participating computers.
Distributed file systems are a subset of distributed systems. The problem they solve is data storage. In other words, they’re storage systems that span multiple computers.
Tip
The data stored in these file systems is spread across the different nodes automatically: you don’t have to worry about manually deciding which node to put what data on. If you’re curious to know more about the placement strategy of HDFS, the best way to learn is to dive into the HDFS code.
Distributed file systems provide the scale required to store and process the vast amount of data that is being generated on the web and elsewhere. Providing such scale is challenging because the number of moving parts causes more susceptibility to failure. In large distributed systems, failure is a norm, and that must be taken into account while designing the systems.
In the sections that follow, we’ll examine the challenges of designing a distributed file system and how HDFS addresses them. Specifically, you’ll learn how HDFS achieves scale by separating metadata and the contents of files. Then, we’ll explain the consistency model of HDFS by going into details of the HDFS read and write paths, followed by a discussion of how HDFS handles various failure scenarios. We’ll then wrap up by examining how files are split and stored across multiple nodes that make up HDFS.
Let’s get started with HDFS’s primary components—NameNode and DataNode—and learn how scalability is achieved by separating metadata and data.
B.2. Separating metadata and data: NameNode and DataNode
Every file that you want to store on a file system has metadata attached to it. For instance, the logs coming in from your web servers are all individual files. The meta-data includes things like filename, inode number, block location, and so on; the data is the actual content of the file.
In traditional file systems, metadata and data are stored together on the same machine because the file systems never span beyond that. When a client wants to perform any operation on the file and it needs the metadata, it interacts with that single machine and gives it the instructions to perform the operation. Everything happens at a single point. For instance, suppose you have a file Web01.log stored on the disk mounted at /mydisk on your *nix system. To access this file, the client application only needs to talk to the particular disk (through the operating system, of course) to get the metadata as well as the contents of the file. The only way this model can work with data that’s more than a single system can handle is to make the client aware of how you distribute the data among the different disks, which makes the client stateful and difficult to maintain.
Stateful clients are even more complicated to manage as the number grows, because they have to share the state information with each other. For instance, one client may write a file on one machine. The other client needs the file location in order to access the file later, and has to get the information from the first client. As you can see, this can quickly become unwieldy in large systems and is hard to scale.
In order to build a distributed file system where the clients remain simple and ignorant of each other’s activities, the metadata needs to be maintained outside of the clients. The easiest way to do this is to have the file system itself manage the metadata. But storing both metadata and data together at a single location doesn’t work either, as we discussed earlier. One way to solve this is to dedicate one or more machines to hold the metadata and have the rest of the machines store the file contents. HDFS’s design is based on this concept. It has two components: NameNode and DataNode. The metadata is stored in the NameNode. The data, on the other hand, is stored on a cluster of DataNodes. The NameNode not only manages the metadata for the content stored in HDFS but also keeps account of things like which nodes are part of the cluster and how many copies of a particular file exist. It also decides what needs to be done when nodes fall out of the cluster and replicas are lost.
This is the first time we’ve mentioned the word replica. We’ll talk about it in detail later—for now, all you need to know is that every piece of data stored in HDFS has multiple copies residing on different servers. The NameNode essentially is the HDFS Master, and the DataNodes are the Slaves.
B.3. HDFS write path
Let’s go back to the example with Web01.log stored on the disk mounted at /mydisk. Suppose you have a large distributed file system at your disposal, and you want to store that file on it. It’s hard to justify the cost of all those machines otherwise, isn’t it? To store data in HDFS, you have various options. The underlying operations that happen when you write data are the same regardless of what interface you use to write the data (Java API, Hadoop command-line client, and so on).
Note
If you’re like us and want to play with the system as you learn about the concepts, we encourage you to do so. But it’s not required for this section, and you don’t need to do so to understand the concepts.
Let’s say you’re using the Hadoop command-line client and you want to copy a file Web01.log to HDFS. You write the following command:
$ hadoop fs –copyFromLocal /home/me/Web01.log /MyFirstDirectory/
It’s important that you understand what happens when you write this command. We’ll go over the write process step by step while referring to figures B.1–B.4. Just to remind you, the client is simple and doesn’t know anything about the internals of HDFS and how the data is distributed.
Figure B.1. Write operation: client’s communication with the NameNode
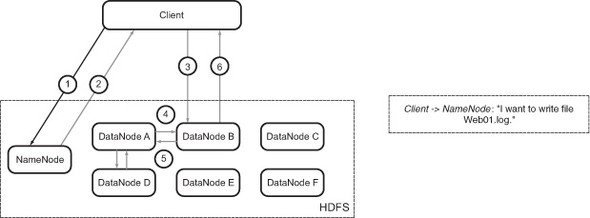
Figure B.2. Write operation: Name-Node acknowledges the write operation and sends back a DataNode list

Figure B.3. Write operation: client sends the file contents to the DataNodes
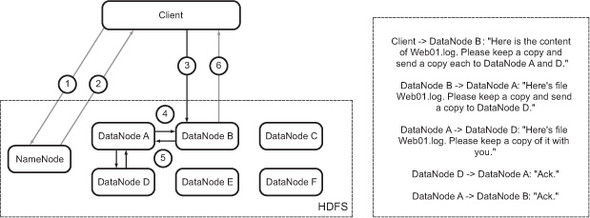
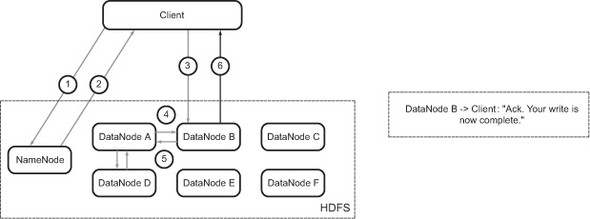
Figure B.4. Write operation: DataNode acknowledges completion of the write operation
The client does, however, know from the configuration files which node is the NameNode. It sends a request to the NameNode saying that it wants to write a file Web01.log to HDFS (figure B.1). As you know, the NameNode is responsible for managing the metadata about everything stored in HDFS. The NameNode acknowledges the client’s request and internally makes a note about the filename and a set of DataNodes that will store the file. It stores this information in a file-allocation table in its memory.
It then sends this information back to the client (figure B.2). The client is now aware of the DataNodes to which it has to send the contents of Web01.log.
The next step for it is to send the contents over to the DataNodes (figure B.3). The primary DataNode streams the contents of the file synchronously to other DataNodes that will hold the replicas of this particular file. Once all the DataNodes that have to hold replicas of the file have the contents in memory, they send an acknowledgement to the DataNode that the client connected to. The data is persisted onto disk asynchronously later. We’ll cover the topic of replication in detail later in the appendix.
The primary DataNode sends a confirmation to the client that the file has been written to HDFS (figure B.4). At the end of this process, the file is considered written to HDFS and the write operation is complete.
Note that the file is still in the DataNodes’ main memory and hasn’t yet been persisted to disk. This is done for performance reasons: committing all replicas to disk would increase the time taken to complete a write operation. Once the data goes into the main memory, the DataNode persists it to disk as soon as it can. The write operation doesn’t block on it.
In distributed file systems, one of the challenges is consistency. In other words, how do you make sure the view of the data residing on the system is consistent across all nodes? Because all nodes store data independently and don’t typically communicate with each other, there has to be a way to make sure all nodes contain the same data. For example, when a client wants to read file Web01.log, it should be able to read exactly the same data from all the DataNodes. Looking back at the write path, notice that the data isn’t considered written unless all DataNodes that will hold that data have acknowledged that they have a copy of it. This means all the DataNodes that are supposed to hold replicas of a given set of data have exactly the same contents before the write completes—in other words, consistency is accomplished during the write phase. A client attempting to read the data will get the same bytes back from whichever DataNode it chooses to read from.
B.4. HDFS read path
Now you know how a file is written into HDFS. It would be strange to have a system in which you could write all you want but not read anything back. Fortunately, HDFS isn’t one of those. Reading a file from HDFS is as easy as writing a file. Let’s see how the file you wrote earlier is read back when you want to see its contents.
Once again, the underlying process that takes place while reading a file is independent of the interface used. If you’re using the command-line client, you write the following command to copy the file to your local file system so you can use your favorite editor to open it:
$ hadoop fs –copyToLocal /MyFirstDirectory/Web01.log /home/me/
Let’s look at what happens when you run this command. The client asks the Name-Node where it should read the file from (figure B.5).
The NameNode sends back block information to the client (figure B.6).
The block information contains the IP addresses of the DataNodes that have copies of the file and the block ID that the DataNode needs to find the block on its local storage. These IDs are unique for all blocks, and this is the only information the DataNodes need in order to identify the block on their local storage. The client examines this information, approaches the relevant DataNodes, and asks for the blocks (figure B.7).
The DataNodes serve the contents back to the client (figure B.8), and the connection is closed. That completes the read step.
This is the first time we’ve mentioned the word block in the context of files in HDFS. In order to understand the read process, consider that a file is made up of blocks that are stored on the DataNodes. We’ll dig deeper into this concept later in the appendix.
Figure B.5. Read operation: client’s communication with the NameNode
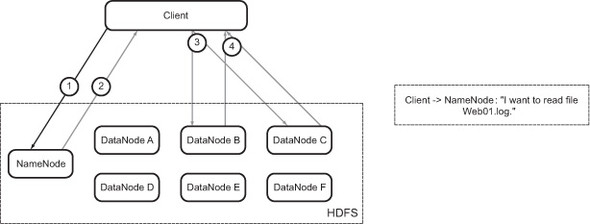
Figure B.6. Read operation: Name-Node acknowledges the read and sends back block information to the client
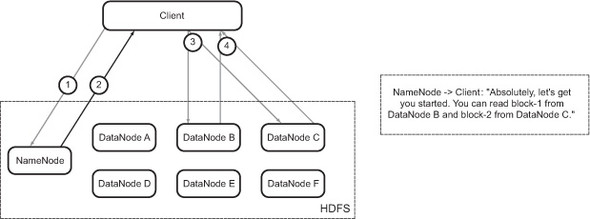
Figure B.7. Read operation: client contacts the relevant DataNodes and asks for the contents of the blocks
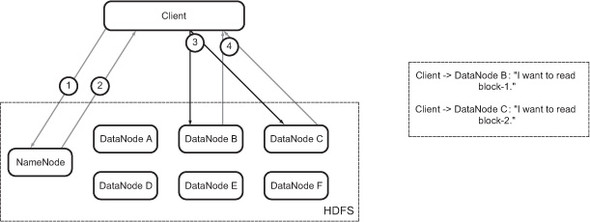
Figure B.8. Read operation: DataNodes serve the block contents to the client. This completes the read step.
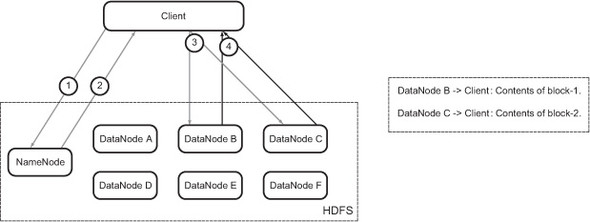
Note that the client gets separate blocks for a file in parallel from different Data-Nodes. The client joins these blocks to make the full file. The logic for this is in the client library, and the user who’s writing the code doesn’t have to do anything manually. It’s all handled under the hood. See how easy it is?
B.5. Resilience to hardware failures via replication
In large distributed systems, disk and network failures are commonplace. In case of a failure, the system is expected to function normally without losing data. Let’s examine the importance of replication and how HDFS handles failure scenarios. (You may be thinking that we should have covered this earlier—hang on for a bit and it will make sense.)
When everything is working fine, DataNodes periodically send heartbeat messages to the NameNode (by default, every three seconds). If the NameNode doesn’t receive a heartbeat for a predefined time period (by default, 10 minutes), it considers the DataNode to have failed, removes it from the cluster, and starts a process to recover from the failure. DataNodes can fall out of the cluster for various reasons—disk failures, motherboard failures, power outages, and network failures. The way HDFS recovers from each of these is the same.
For HDFS, losing a DataNode means losing replicas of the blocks stored on that disk. Given that there is always more than one replica at any point in time (the default is three), failures don’t lead to data loss. When a disk fails, HDFS detects that the blocks that were stored on that disk are under-replicated and proactively creates the number of replicas required to reach a fully replicated state.
There could be a situation in which multiple disks failed together and all replicas of a block were lost, in which case HDFS would lose data. For instance, it’s theoretically possible to lose all the nodes that are holding replicas of a given file because there is a network partition. It’s also possible for a power outage to take down entire racks. But such situations are rare; and when systems are designed that have to store mission-critical data that absolutely can’t be lost, measures are taken to safeguard against such failures—for instances, multiple clusters in different data centers for backups.
From the context of HBase as a system, this means HBase doesn’t have to worry about replicating the data that is written to it. This is an important factor and affects the consistency that HBase offers to its clients.
B.6. Splitting files across multiple DataNodes
Earlier, we examined the HDFS write path. We said that files are replicated three ways before a write is committed, but there’s a little more to that. Files in HDFS are broken into blocks, typically 64–128 MB each, and each block is written onto the file system. Different blocks belonging to the same file don’t necessarily reside on the same DataNode. In fact, it’s beneficial for different blocks to reside on different DataNodes. Why is that?
When you have a distributed file system that can store large amounts of data, you may want to put large files on it—for example, outputs of large simulations of subatomic particles, like those done by research labs. Sometimes, such files can be larger than the size of a single hard drive. Storing them on a distributed system by breaking them into blocks and spreading them across multiple nodes solves that problem.
There are other benefits of distributing blocks to multiple DataNodes. When you perform computations on these files, you can benefit from reading and processing different parts of the files in parallel.
You may wonder how the files are split into blocks and who determines which DataNodes the various blocks should go to. When the client is writing to HDFS and talks to the NameNode about where it should write the files, the NameNode tells it the DataNodes where it should write the blocks. After every few blocks, the client goes back to the NameNode to get a fresh list of DataNodes to which the next few blocks should be written.
Believe it or not, at this point, you know enough about HDFS to understand how it functions. You may not win an architectural argument with a distributed systems expert, but you’ll be able to understand what they’re talking about. Winning the argument wasn’t the intention of the appendix anyway!