
Chapter 4. Message passing
The fundamental notion on which message passing is built is that of an event: the fact that a certain condition has occurred (the event) is bundled together with contextual information—like who did what when and where—and is signaled by the producer as a message. Interested parties are informed by the producer using a common transport mechanism and consume the message.
In this chapter, we will discuss in detail the main aspects of message passing:
- The difference between focusing on messages or events
- Whether to do it synchronously or asynchronously
- How messages can be transmitted without overwhelming the recipient and with varying degrees of reliability
You will also see how message passing enables vertical scalability. Finally, we will discuss the correspondence between events and messages—or how to model one in terms of the other.
4.1. Messages
In the real world, when you mail a letter to someone, you do not expect the contents of the letter to change after it is sent. You expect the letter that arrives to be the same as the one that was sent, and after it arrives you do not expect it to change into a different letter. This is true regardless of whether the letter is sent around the world and takes days or weeks to arrive, or is sent across town, or even is handed to the recipient in person. Immutability is important.
In the first part of chapter 3, we touched on Erlang and an early implementation of the Actor model. In that model, Actors communicate by sending messages to each other. Those messages are between processes, but that doesn’t always have to be the case. Messages may be sent to other computers, to other processes in the same computer, or even within the same process. You have to ensure that a message can be serialized for transmission, unless you know for sure that it will never leave the current process. Ideally, you should never make that assumption. Message passing often provides an excellent boundary to scale an application horizontally by moving the receiver to a different process.
You can conceive of a simple method call as consisting of two messages: a message containing all the input parameters and a return message containing the result. This may seem a bit extreme, but languages going back more than three decades to Smalltalk-80 have demonstrated that it is a useful approach.[2] If there is no return message, the language may refer to it as a procedure or perhaps say that the method returns a void value.
4.2. Vertical scalability
Imagine a busy post office in Manhattan back when computers and machines were not yet capable of sorting letters. Multiple clerks might sort letters in parallel, speeding up the process as shown in figure 4.1. The same idea applies to Reactive applications wherever the order of requests is not crucial (see chapter 14 for specifics).
Figure 4.1. Two clerks sorting mail in parallel at a post office

Imagine a piece of code that performs an expensive calculation (prime factorization, graph search, XML transformation, or the like). If this code is accessible only by synchronous method calls, the onus is on the caller to provide for parallel execution in order to benefit from multiple CPUs—say, by using Futures to dispatch the method calls onto a thread pool. One problem with this is that only the implementer of the called code knows if it can be run in parallel without concurrency issues. A typical problem occurs when the calculation stores and reuses auxiliary data structures within its enclosing class or object without proper internal synchronization.
Message passing solves this problem by decoupling sender and receiver. The implementation of the calculation can distribute incoming messages across several execution units without the sender needing to know.
The beauty of this approach is that the semantics of message passing do not depend on how a receiver will process a message. Scaling a computation vertically on dozens of processor cores can be realized transparently, hidden from the calling code as an implementation detail or a configuration option.
4.3. Event-based vs. message-based
There are two models for connecting data consumers with data producers: event-based and message-based. Event-based systems provide a way to attach responses to specific events. The system then becomes responsible for executing the correct response to an event whenever that event occurs. Event-based systems are typically organized around an event loop. Whenever something happens, the corresponding event is appended to a queue. The event loop continually pulls events from this queue and executes the callbacks that have been attached to them. Each callback is typically a small, anonymous procedure that responds to a specific event such as a mouse click. It may generate new events, which are then also appended to the queue and processed when their turn comes. This model is employed by single-threaded runtimes like Node.js and by the GUI toolkits for most graphical operating systems.
In contrast, message-based systems provide a way to send messages to specific recipients. The anonymous callback is replaced by an active recipient that consumes messages received from potentially anonymous producers. Whereas in an event-based system, event producers are addressable so that callbacks can be registered with them, in a message-based system the consumers are addressable so they can be given responsibility for processing certain messages. Neither the message producer nor the messaging system need concern itself with the correct response to a message; the current configuration of consumers determines that. For example, when some part of a system produces a log event, it does not worry about whether log events are being consumed by the network, a database, or the file system, or whether log files are rotated every 6 or 24 hours. The logger, which receives the log event, is responsible for doing the right thing with it.
Making the consumer responsible for processing its own incoming messages has several advantages:
- It allows processing to proceed sequentially for individual consumers, enabling stateful processing without the need for synchronization. This translates well at the machine level because consumers will aggregate incoming events and process them in one go, a strategy for which current hardware is highly optimized.
- Sequential processing enables the response to an event to depend on the current state of the consumer. So, previous events can have an influence on the consumer’s behavior. A callback-based scheme, in contrast, requires the consumer to decide what its response will be when it subscribes to the event, not when the event occurs.
- Consumers can choose to drop events or short-circuit processing during system overload. More generally, explicit queueing allows the consumer to control the flow of messages. We will explain more about flow control in section 4.5.
- Last but not least, it matches how humans work in that we also process requests from our coworkers sequentially.
The last point may be surprising to you, but we find familiar mental images helpful for visualizing how a component behaves. Take a moment to imagine an old-fashioned post office, as shown in figure 4.2, where the clerk sorts letters from an incoming pile into different boxes for delivery. The clerk picks up an envelope, inspects the address label, and makes a decision. After throwing the letter into the right box, the clerk turns back to the pile of unsorted mail and either picks up the next letter or notices that the time is already past noon and takes a lunch break. With this picture in mind, you already have an intuitive understanding of a message router. Now you only need to dump that into code. This task is a lot easier than it would have been before this little mental exercise.
Figure 4.2. A clerk in the back room of a post office sorts mail from an incoming pile into addressee boxes.

The similarity between message passing and human interaction goes beyond sequential processes. Instead of directly reading (and writing) each others’ thoughts, we exchange messages: we talk, we write notes, we observe facial expressions, and so on. We express the same principle in software design by forming encapsulated objects that interact by passing messages. These objects are not the ones you know from languages like Java, C#, or C++, because communication in those languages is synchronous and the receiver has no say in whether or when to handle the request. In the anthropomorphic view, that corresponds to your boss calling you on the telephone and insisting that you find out the answer to a question on the spot. We all know that this kind of call should be the exception rather than the rule, lest no work get done. We prefer to answer, “Yes, I will get back to you when I have the result”; or, even better, the boss should send an email instead of making a disruptive telephone call, especially if finding the answer may take some time. The “I will get back to you” approach corresponds to a method that returns a Future. Sending email is equivalent to explicit message passing.
Now that we have established that message passing is a useful abstraction, we need to address two fundamental problems that arise while handling messages, whether in a postal service or in a computer:
- Sometimes we must be able to guarantee the delivery of a certain very important letter.
- If messages are sent faster than they can be delivered, they will pile up somewhere, and eventually either the system will collapse or mail will be lost.
We will look at the issue of delivery guarantees later in this chapter. Next, we will take a peek at how Reactive systems control the flow of messages to ensure that requests can be handled in a timely fashion and without overwhelming the receiver.
4.4. Synchronous vs. asynchronous
The communication from producer to consumer can be realized in two ways:
- In synchronous communication, both parties need to be ready to communicate at the same time.
- In asynchronous communication, the sender can send whether the recipient is ready or not.
Figure 4.3 illustrates synchronous message passing at a post office. A customer, Jill, has run out of postage stamps, so she needs to ask the clerk, James, for assistance. Luckily, there is no queue in front of the counter, but James is nowhere to be seen. He is somewhere in the back, stowing away a parcel that he just accepted from the previous customer. While James works, Jill is stuck at the counter waiting for him. She cannot go to work or shop for groceries or do whatever else she wants to do next. If she waits too long, she will give up on mailing the letter for now and try again later, perhaps at a different post office.
Figure 4.3. A message that a customer is seeking assistance is passed to the clerk using a bell.

In real life, we deal gracefully with situations where a receiver is unavailable for too long. In programming, the corresponding timeouts and their proper handling are often considered only as an afterthought.
In contrast, asynchronous message passing means that Jill posts the letter by placing it in the mailbox. She can then immediately be on her way to her next task or appointment. The clerk will empty the mailbox some time later and sort the letters into their correct outboxes. This is much better for everyone involved: Jill does not need to wait for the clerk to have time for her, and the clerk gets to do things in batches, which is a much more efficient use of his time. Hence, we prefer this mode of operation whenever we have a choice.
When there are multiple recipients, the superiority of asynchronous message passing is even clearer. It would be very inefficient to wait until all the recipients of a message are ready to communicate at the same time, or even to pass the message synchronously to one recipient at a time. In the human metaphor, the former would mean the producer would have to arrange a full team meeting and notify everybody at the same time; the latter would mean walking around, patiently waiting at each recipient’s desk until they’re available. It would be far preferable to send an asynchronous message instead—a letter in the old days, probably an email today. So, for convenience, when we say message passing we will always mean asynchronous communication between a producer and any number of consumers using messages.
The Actor toolkit Akka was built to express message passing from the very beginning; this is what the Actor model is all about. But before version 2.0, this principle was not pervasive throughout Akka. It was only present at the surface, in the user-level API. Under the covers, we used locks for synchronization and called synchronously into the supervisor’s strategy when a supervised Actor failed. Consequently, remote supervision was not possible with this architecture. In fact, everything concerning remote Actor interactions was a little quirky and difficult to implement. Users began to notice that the creation of an Actor was executed synchronously on the initiator’s thread, leading to a recommendation to refrain from performing time-consuming tasks in an Actor’s constructor and send an initialization message instead.
When the list of these and similar issues grew too long, we sat down and redesigned the entire internal architecture of Akka to be based purely on asynchronous message passing. Every feature that was not expressible under this rule was removed, and the inner workings were made fully nonblocking. As a result, all the pieces of the puzzle clicked into place: with the removal of tight coupling between the individual moving parts, we were able to implement supervision, location transparency, and extreme scalability at an affordable engineering price. The only downside is that certain parts—for example, propagating failure up a supervisor hierarchy—do not tolerate message loss, which now requires more effort to implement for remote communication.
To put this another way, asynchronous message passing means the recipient will eventually learn about a new incoming message and then consume it as soon as appropriate. There are two ways in which the recipient can be informed: it can register a callback describing what should happen in case of a certain event, or it can receive the message in a mailbox (also called a queue) and decide on a case-by-case basis what to do with it.
4.5. Flow control
Flow control is the process of adjusting the transmission rate of a stream of messages to ensure that the receiver is not overwhelmed. Whenever this process informs the sender that it must slow down, the sender is said to experience back pressure.
Direct method invocations, such as are common in languages from the C family, by their nature include a specific kind of flow control: the sender of a request is blocked by the receiver until processing is finished. When multiple senders compete for a receiver’s resources, processing is commonly serialized through some form of synchronization like locks or semaphores, which additionally blocks each sender until previous senders’ messages have been serviced. This implicit back pressure may sound convenient at first, but as systems grow and nonfunctional requirements become more important, it turns into an impediment. Instead of implementing the business logic, you find yourself debugging performance bottlenecks.
Message passing gives you a wider range of options for flow control because it includes the notion of queueing. For example, as discussed in chapter 2, if you use a bounded queue, you have options for how to respond when the queue is full: you can drop the newest message, the oldest message, or all the messages, according to what best suits the requirements. A case where you might drop all messages would be a real-time system aimed at displaying the latest data. You might include a small buffer to smooth out processing or latency jitter, but moving new messages through the queue quickly is more important than processing backlogged messages. Because the consuming process reads from the message queue, it can make whatever decision is appropriate when it finds itself backlogged.
Another option is that you can sort incoming messages into multiple queues based on priorities and dequeue them according to specific bandwidth allocations. You can also generate an immediate negative reply to a sender when dropping messages, if desired. We will discuss these and other possibilities in chapter 15.
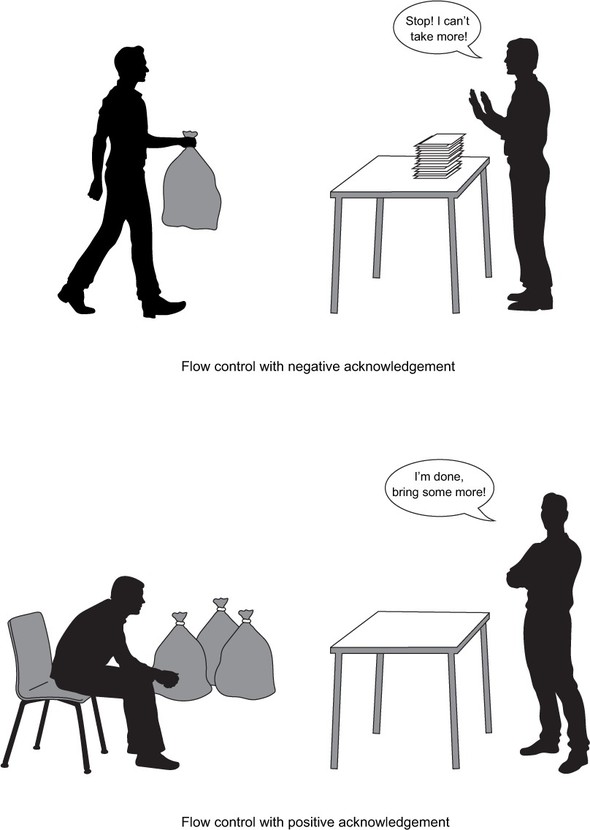
Two basic flow-control schemes are depicted in figure 4.4: the left clerk tries to deliver sacks full of letters to the right clerk, who sorts them at a table. In negative acknowledgment(NACK), the right clerk rejects a new delivery when the table is full. In positive acknowledgment(ACK), the left clerk waits to be informed by the right clerk that the right clerk has run out of letters to sort. There are many variations on this scheme, some of which are presented in chapter 15. The subject lends itself well to human metaphors like the one given here; feel free to let your mind roam and discover some of them in everyday life.
Figure 4.4. Two basic flow-control schemes
In essence, message passing unbundles the implied flow control from common object-oriented programming languages and allows customized solutions. This choice does not come without a cost, of course: at the least, you need to think about which flow-control semantics you want, and, hence, you must choose the granularity at which to apply message passing and below which direct method calls and object--oriented composition are preferable. To illustrate, imagine a service-oriented architecture with asynchronous interfaces. The services themselves might be implemented in traditional synchronous style and communicate among each other via message passing. When refactoring one of the service implementations, you might find it appropriate to apply more fine-grained flow control within it, thus lowering the granularity level. This choice can be made differently depending on the service’s requirements as well as how the responsible development team likes to work.
With a basic understanding of how to avoid overloading a message-delivery system, we can now turn our attention to the issue of how to ensure delivery of certain important messages.
4.6. Delivery guarantees
Despite every postal clerk’s best efforts, sometimes a letter gets lost. The probability may be low, but still it happens—several times per year. What happens then? The letter might have contained birthday wishes, in which case it will hopefully be discovered by the sender and receiver when they meet for the next time. Or it might have been an invoice, in which case it will not be paid, and a reminder will be sent. The important theme to note here is that humans normally follow up on interactions, allowing the detection of message loss. In some cases, there are unpleasant consequences when a message is lost, but life goes on and we do not stop our entire society because one letter was not delivered. In this section, we will show you how Reactive applications work the same way, but we will start at the opposite end: with synchronous systems.
When we write down a method call, we can be pretty certain that it will be executed when the program reaches the corresponding line; we are not used to losses between lines. But strictly speaking, we need to take into account the possibility that the process will terminate or the machine will die; or it could overflow the call stack or otherwise raise a fatal signal. As you saw earlier, it is not difficult to think of a method call as a message sent to an object, and with this formulation we could say that even in a synchronous system, we have to address the possibility that a message—a method invocation—can get lost. We could thus take the extreme standpoint that there can never be an unbreakable guarantee that a request will be processed or result in a response.
Very few people, however, would deem such a stance constructive, because we reasonably accept limitations and exceptions to rules. We apply common sense and call those who don’t pedantic. For example, human interaction usually proceeds under the implicit assumption that neither party dies. Instead of dwelling on the rare cases, we concern ourselves more with managing our inherent unreliability, making sure communications were received, and reminding colleagues of important work items or deadlines. But when transforming a process into a computer program, we expect it to be completely reliable: to perform its function without fail. It is our nature to loathe the hassle of countering irregularities, and we turn to machines to be rid of it. The sad fact is that the machines we build may be faster and more reliable, but they are not perfect, and we must therefore continue to worry about unforeseen failures.
Everyday life again provides a good model to borrow from. Whenever one person requests a service from another, they have to deal with the possibility that there will be no reply. The other person may be busy, or the request or reply may get lost along the way—for example, if a letter (or email) is lost. In these cases, the person who made the request needs to try again until they get a response or the request becomes irrelevant, as illustrated in figure 4.5. Analogous activity in the realm of computer programming is obvious: a message sent from one object to another may be lost, or the receiving object may be unable to handle the request because something it depends on is currently unavailable—the disk may be full or a database may be down—and so the sending object will need to either retry until the request is successful or give up.
Figure 4.5. The Retry pattern in daily life

With synchronous method calls, there is usually no way to recover from a “lost message.” If a procedure doesn’t return, usually it is because of something catastrophic like abnormal program continuation; there is no way for the caller to try to recover and continue. Message passing makes it feasible to persist the request and retry it whenever the failure condition is corrected. Even if an entire computing center goes down because of a power outage, a program can continue after the power comes back on as long as the needed messages were held in nonvolatile storage. As with flow control, you need to choose an appropriate granularity at which to apply message passing, based on each application’s requirements.
With this in mind, it becomes natural to design an application based on reduced message-delivery guarantees. Building in this knowledge from the beginning makes the resulting application resilient against message loss, no matter whether it is caused by network interruption, a back-end service outage, excessive load, or even programming errors.
Implementing a runtime environment with very strong delivery guarantees is expensive in that extra mechanisms need to be built in—for example, resending network messages until receipt is confirmed—and these mechanisms degrade performance and scalability even when no failures occur. The cost rises dramatically in a distributed system, mostly because confirmations require network round trips having latencies orders of magnitude larger than on a local system (for example, between two cores on a single CPU). Providing weaker delivery guarantees allows you to implement the common cases much more simply and quickly, and pay the price for stronger guarantees only where truly needed. Note the correspondence with how the postal service charges for normal and registered mail.
The principal choices for delivery guarantees are as follows:
- At-most-once delivery— Each request is sent once and never retried. If it is lost or the recipient fails to process it, there is no attempt to recover. Therefore, the desired function may be invoked once or not at all. This is the most basic delivery guarantee. It has the lowest implementation overhead, because neither sender nor receiver is required to maintain information on the state of their communication.
- At-least-once delivery— Trying to guarantee that a request is processed requires two additions to at-most-once semantics. First, the recipient must acknowledge receipt or execution (depending on the requirements) by sending a confirmation message. Second, the sender must retain the request in order to resend it if the sender doesn’t receive the confirmation. Because a resend can be the result of a lost confirmation, the recipient may receive the message more than once. Given enough time and the assumption that communication will eventually succeed, the message will be received at least once.
- Exactly once delivery— If a request must be processed but must not be processed twice, then, in addition to at-least-once semantics, the recipient must deduplicate messages: that is, they must keep track of which requests have already been processed. This is the most costly scheme because it requires both sender and receiver to track communication state. If, in addition, requests must be processed in the order they were sent, then throughput may be further limited by the need to complete confirmation round trips for each request before proceeding with the next—unless flow-control requirements are compatible with buffering on the receiver side.
Implementations of the Actor model usually provide at-most-once delivery out of the box and allow the other two layers to be added on top for communication paths that require them. Interestingly, local method calls also provide at-most-once delivery, albeit with a tiny probability for nondelivery.
Consideration of flow-control and message-delivery guarantees is important because message passing makes limitations of communication explicit and clearly exposes inconvenient corner cases. In the next section, we will focus on the natural match between messages and real-world events and how this promotes a simple consistency across layers in an application.
4.7. Events as messages
In hard real-time systems, the foremost concern is keeping the maximal response time to external events within strict limits—that is, to enforce a tight temporal coupling between each event and its response. At the other end of the spectrum, a high-volume storage system for archiving log messages needs high throughput much more than it needs short latency: how long it takes to store a log message matters little as long as the message eventually gets stored. Requirements for responding to events may vary enormously, but interactions with computers always boil down to this: raising events and responding to them.
Messages naturally represent events, and message passing naturally represents event-driven interactions. An event propagating through a system can also be seen as a message being forwarded along a chain of processing units. Representing events as messages enables the trade-off between latency and throughput to be adjusted on a case-by-case basis or even dynamically. This is useful in cases where response times usually need to be short, but the system also needs to degrade gracefully when the input load increases.
The reception and processing of network packets illustrates varying latency requirements within one sequence of interactions, as shown in figure 4.6. First, the network interface controller (NIC) informs the CPU of the availability of data using a synchronous interrupt, which needs to be handled as quickly as possible. The operating system kernel takes the data from the NIC and determines the right process and socket to transfer them to. From this point on, the latency requirements are more relaxed, because the data are safe and sound in the machine’s memory—although of course you would still like the user-space process responsible for replying to the incoming request to be informed as quickly as possible. The availability of data on the socket is then signaled—say, by waking up a selector—and the application requests the data from the kernel.
Figure 4.6. Steps of a web request from packet reception to calling the web framework

Notice a fundamental pattern here: within one computer, data received over the wire propagate as a series of events upward through successively higher software layers. Each successfully received packet eventually reaches the user-level program in a representation that bears the same information (possibly combined with other packets for efficiency). At the lowest level, interactions between computers take the form of messages in which a physical representation of data propagates from one computer to another; reception of each message is signaled as an event. It is therefore natural to model network I/O at all layers as a stream of events, reified as a stream of messages. We picked this example because we recently reimplemented the network I/O layer in Akka in this fashion, but opportunities for exploiting the correspondence between messages sent at different levels are ubiquitous. All the lowest-level inputs to a computer are event-based (keyboard and mouse, camera and audio frames, and so on) and can be conveniently passed around as messages. In this way, message passing is the most natural form of communication between independent objects of any kind.
4.8. Synchronous message passing
Explicit message passing often provides a convenient way for isolated parts of an application to communicate, or helps delineate source code components, even when there is no need for asynchronous communication. But if asynchrony is not needed, using asynchronous message passing to decouple components introduces an unnecessary cost: the administrative runtime overhead of dispatching tasks for asynchronous execution as well as extra scheduling latency. In this case, synchronous message passing is usually a wiser choice.
We mention this because synchronous message propagation is often useful for stream processing. For example, fusing a series of transformations together keeps the transformed data local to one CPU core and thereby makes better use of its associated caches. Synchronous messaging thus serves a different purpose than decoupling parts of a Reactive application, and our derivation of the necessity of asynchrony in section 4.4 does not apply.
4.9. Summary
In this chapter, we have discussed in detail the motivation for message passing, especially in contrast to synchronous communication. We have illuminated the difference between addressable event sources in event-driven systems and addressable message recipients in message-driven systems. We have examined the greater variety of forms of flow control that message passing affords, and you have learned about the different levels of message-delivery guarantees.
We briefly touched on the correspondence between events and messages, and you have seen how message passing enables vertical scalability. In the following chapter, we will show how location transparency complements this by enabling horizontal scalability.