
Chapter 15. Message flow patterns
In this chapter, we will explore some of the most basic patterns of communication that occur between Reactive components: specifically, we will talk about how messages flow between them. We discussed the theoretical background in chapter 10, noting that the design of communication paths within a system is crucial to its success—the same holds for real-world organizations as well as Reactive applications.
Most of the patterns we will encounter are extremely generic, starting with the Request–Response pattern. They can be applied in a variety of cases and come in many forms. The examples are therefore less specific than in other chapters, but we will use the front-end façade of a larger service as a problem setting. You can think of this as a more detailed look at the client interface component of the batch job service, our running example. The particular patterns we will cover are as follows:
- The Request–Response pattern
- The Self-Contained Message pattern
- The Ask pattern
- The Forward Flow pattern
- The Aggregator pattern
- The Saga pattern
- The Business Handshake pattern
15.1. The Request–Response pattern
Include a return address in the message to receive a response.
This is the most basic interaction pattern we know; it is the foundational building block for all natural communication, deeply ingrained in human training. A parent will say something to their infant child, who will initially gesture or make some sounds in response; later, the child will articulate words and sentences. Request–response is the way you learn how to speak, and it underlies all sophisticated forms of communication that you develop later. Although the response can be nonverbal (in particular, facial expressions, but also the deliberate absence thereof), in most cases you require a response before successfully concluding a conversation. The response can be a piece of information that you asked for or an acknowledgment of receipt for a command that was given.
In all these cases, there is one commonality that you need to make explicit when translating this basic means of communication into a programming pattern: the process begins with two participants A and B, where A knows how to address B; when receiving requests, B will need to learn or deduce how to address A in order to send back a response. Captured in a diagram, this looks like figure 15.1.
Figure 15.1. Process A sends a message to process B, including its own address (as symbolized by the dashed line), so that in step 2, the response can be conveyed in the opposite direction.
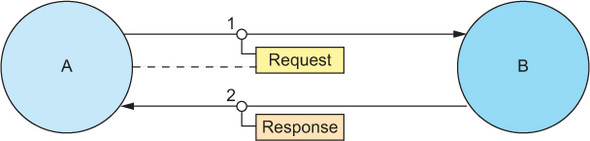
In real life, the inclusion of the sender address is implicit: when someone starts talking to you, you turn your head in the direction of the sound to identify its source, which provides all the information you need in order to respond. This scheme has intuitively been built into numerous commonly used computer protocols, a selection of which we will explore in this section.
15.1.1. The problem setting
Consider two components A and B, where A knows the address of B but not vice versa. This is the prototypical initial condition of a client–server setup, where the client is required to take the first step—the server cannot know which clients require its services at any given time. In the running example, you might be looking at the client interface component of the batch job service: in particular, the relationship between an external client and an entry point into the service. The client submits a request to initiate an action (such as starting a batch job), query for information (like a list of all currently running jobs), or both. The service will carry out the desired action or retrieve the requested information and then reply.
The task: Your mission is to implement a request–response exchange between two processes over a User Datagram Protocol (UDP)[1] network (or any other datagram--oriented transport mechanism of your choosing).
Whereas TCP transports streams of bytes (also called octets) across the network, leaving the encoding of messages to the layers above it, UDP transports delimited datagrams of up to a maximum size of about 64 KB; see also https://en.wikipedia.org/wiki/User_Datagram_Protocol.
15.1.2. Applying the pattern
We will start with process B (called Server), which will receive a request and send back a response. The procedure is defined by the operating system and therefore follows roughly the same path in most programming languages: a socket needs to be opened and bound to a UDP port; then, a datagram needs to be received from this socket; and finally, a datagram needs to be sent via this socket. This basic process is shown in Java in the following listing.
Listing 15.1. Server responding to the address that originated the request
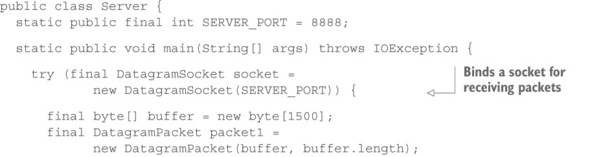

If you run this program, nothing will happen—the process will patiently wait at the socket.receive() call for a UDP packet to arrive. In order to send this packet, you need to write the mirror image of this process, Client (process A), which will first send a packet and then receive one.
Listing 15.2. Client sending a request and then blocking until the server responds


Running this process sets the exchange in motion. You will see that the server receives a packet:
server: received hello server: sender was /127.0.0.1:55589
And the client receives a packet as well:
client: received got it! client: sender was /127.0.0.1:8888
Why does this work? The crucial piece to this message exchange is that a UDP packet traveling over a network carries not only the IP address and port of its intended receiver, but also the IP address and port of the socket it was sent from. This “return address” is extracted in the server’s code using the getSocketAddress() method of DatagramPacket. After logging the information to the console, you inject it into the second packet in order to describe its intended destination—you copy the return address from the received request letter onto the envelope of the response letter.
The other crucial precondition for success is that the client knows beforehand how to reach the server. Although this is intuitive and barely feels worthy of mention, it is essential. In summary:
- The client sends the request in a UDP datagram to the server using an already-known destination address.
- The server sends the response in a UDP datagram to the client using the address information contained in the previously received request datagram.
15.1.3. Common instances of the pattern
The Request–Response pattern may be built into a protocol. The client sends a request, and it is assumed that a response will be returned to the same client. The pattern then can be used to provide the illusion of synchronous behavior: a function makes a call and returns the result to the caller. Believing the illusion is at your peril, because there is no guarantee that the response will ever arrive. Alternatively, the pattern may be implemented using two explicit asynchronous messages.
HTTP
The most commonly—in fact, ubiquitously—used implementation of the request-response pattern is HTTP, which has the pattern built in. This protocol builds on a stream transport layer that conveys requests as streams of bytes from client to server and responses in the opposite direction; this transport layer is almost exclusively provided in the form of TCP over IPv4 or IPv6 at the time of writing, with the option of adding encryption by sandwiching Transport Layer Security (TLS)[2] between HTTP and TCP.
The successor to the Secure Socket Layer (SSL) that was the first widely used encryption layer on top of TCP until its deprecation in 2015 (see https://tools.ietf.org/html/rfc7568).
An HTTP connection is established from the client to the server, and these roles also determine the roles within the conversation: the client sends requests and the server sends responses, exactly one for each request. This model is popular because it fits the majority of use cases: the client wants the server to do something. In the example problem setting, you might formulate the following request:
GET /request?msg=hello HTTP/1.1 Host: client-interface.our.application.domain Accept: application/json
The server might then respond with a message like this (the uninteresting part is replaced with an ellipsis):
HTTP/1.1 200 OK
...
Content-Type: application/json
Content-Length: 22
{"response":"got it!"}
There is a wealth of literature about how to structure the contents of these requests and responses, with representational state transfer (REST)[3] resource representation being a popular pattern, but we are currently more interested in how HTTP implements the Request–Response pattern. While applying the pattern to a simple UDP exchange, you have seen that the client’s address needs to be conveyed to the server in order to allow the response to be communicated. This is easy because UDP already caters to this need: the sending port’s address is included in the network packet by which the datagram travels over the network. TCP also includes the sender as well as the receiver address in all network packets that make up a connection. This allows it to transport bytes not only from client to server but also in the opposite direction, and that is exactly how the HTTP response is sent back to the HTTP client.
Actors
In the Actor model, the only defined means of communication is by way of sending single messages: no connections, responses, or similar are defined. Using the Akka implementation of this model, you might solve the task posed initially in the following fashion.
Listing 15.3. Untyped Akka Actors modeling request–response
object RequestResponseActors {
case class Request(msg: String)
case class Response(msg: String)
class Responder extends Actor {
def receive = {
case Request(msg) =>
println(s"got request: $msg")
sender() ! Response("got it!")
}
}
class Requester(responder: ActorRef) extends Actor {
responder ! Request("hello")
def receive = {
case Response(msg) =>
println(s"got response: $msg")
context.system.terminate()
}
}
def main(args: Array[String]): Unit = {
val sys = ActorSystem("ReqRes")
val responder = sys.actorOf(Props[Responder], "responder")
val requester = sys.actorOf(Props(new Requester(responder)), "requester")
}
}
You first define the message types for the request and the response, and you formulate a Responder actor that, given a request, replies with a response, printing a message to the console so you can see that something happens. Then you define a second actor—Requester—that is instantiated with the ActorRef of a responder. This requester actor first sends a request and then reacts to the reception of a response by printing a message to the console and shutting down the entire process. The main program starts up first a responder and then an associated requester. When you run this program, you will see the expected output:
got request: hello got response: got it!
This formulation of the Request–Response pattern is enabled by an Akka-specific feature: when sending the request message, the requester’s own ActorRef is implicitly picked up by the ! (tell) operator, and the Request message is placed in an Akka-internal envelope that also carries this sender ActorRef. This is how the sender() method can access the return address within the Responder actor to send back the response. The envelopes used behind the scenes are an implementation detail that has been introduced specifically because request–response is such a widely used communication pattern.
Looking at the Akka Typed module—which was introduced about six years after the initial untyped Actor implementation—you can see that the sender() feature is no longer present. The reasons behind this change are manifold, and a full discussion is out of scope for this book, but the main reason can be summarized by saying that it was proven infeasible to maintain this feature while also providing fully type-checked Actor messaging.
Without the sender() feature, the return address needs to be explicitly included in the message that is sent. As an illustration, the following listing describes the same Actor program as listing 15.3, but with fully typed Actors and ActorRefs.
Listing 15.4. Including the response explicitly in the request message
object RequestResponseTypedActors {
case class Request(msg: String, replyTo: ActorRef[Response])
case class Response(msg: String)
val responder: Behavior[Request] =
Static {
case Request(msg, replyTo) =>
println(s"got request: $msg")
replyTo ! Response("got it!")
}
def requester(responder: ActorRef[Request]): Behavior[Response] =
SelfAware { self =>
responder ! Request("hello", self)
Total {
case Response(msg) =>
println(s"got response: $msg")
Stopped
}
}
def main(args: Array[String]): Unit = {
ActorSystem("ReqResTyped", Props(ContextAware[Unit] { ctx =>
val res = ctx.spawn(Props(responder), "responder")
val req = ctx.watch(ctx.spawn(Props(requester(res)), "requester"))
Full {
case Sig(ctx, Terminated(`req`)) => Stopped
}
}))
}
}
You start again with the definition of the two message types, this time including the return address as the replyTo field in the request. Also note that you do not need to include a return address in the Response message type, because the client already knows how to contact the server if it needs to do so again—unconditionally capturing a return address is a waste of effort.
The Responder actor is described by way of its behavior, which is to react to the receipt of requests by logging them and sending a response; this is a static actor that does not change its behavior. The Requester actor needs to be instantiated with the ActorRef of a responder—now precisely typed, in contrast to the untyped actor example, where any message was permissible—and the first thing it does after being started is send a request. The return address must be extracted from the context in which the behavior is executed, and that is done using the SelfAware behavior decorator. In good object-oriented tradition,[4] you call the actor’s ActorRef self and use it when constructing the Request to be sent to the responder. Afterward, the requester begins a behavior in which it reacts to the reception of a Response message by logging it and terminating itself.
Referring to the Smalltalk language created by Alan Kay et al., father of object orientation.
The main program consists only of creating an ActorSystem whose guardianActor creates first a responder and then an associated requester. The latter’s lifecycle is monitored using the watch command; when termination is signaled, the entire system shuts down.
AMQP
In the previous examples, the Request–Response pattern is supported at least to some degree directly within the communication mechanism. Advanced Message Queueing Protocol (AMQP)[5] can serve as an example of a message transport that does not natively support this pattern: messages are conveyed by being placed in queues, and neither the sender nor the recipient has an address of their own. The recipient is just the one that pulls messages out of a given queue. This means in order to send back a response, the original sender also needs to have a queue on which it can receive messages. Once that is established, you can apply the Request–Response pattern by including the address of this queue in the request message. The response will then be delivered to this queue, from which the requester can retrieve it.
See also https://www.amqp.org.
Examples of how to perform such a request–response exchange are part of the RabbitMQ tutorials;[6] we show the JavaScript version here due to its conciseness. It begins again with the responder, which reacts to requests by logging them and sending back a response.
In particular, rpc_server.js and rpc_client.js in the directory http://mng.bz/m8Oh.
Listing 15.5. Request–response based on a one-way messaging protocol
var amqp = require('amqplib/callback_api');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
var q = 'rpc_queue';
ch.assertQueue(q, {durable: false});
ch.prefetch(1);
ch.consume(q, function reply(msg) {
console.log("got request: %s", msg.content.toString());
ch.sendToQueue(msg.properties.replyTo,
new Buffer('got it!'),
{correlationId: msg.properties.correlationId});
ch.ack(msg);
});
});
});
The responder first establishes a connection with the local AMQP message broker, and then it creates a channel named rpc_queue and installs a message handler that will send back responses. One new aspect in comparison to the previous implementations is that the queues used for communication may not be used exclusively by a single requester and responder. Therefore, each request comes with a correlation ID that is carried over to the associated response. You can see how this is used by looking at the requester’s implementation, shown next.
Listing 15.6. Listening for a response with the same correlation ID as the original request
var uuid = require('node-uuid');
amqp.connect('amqp://localhost', function(err, conn) {
conn.createChannel(function(err, ch) {
ch.assertQueue('responses', {}, function(err, q) {
var corr = uuid.v1();
ch.consume(q.queue, function(msg) {
if (msg.properties.correlationId == corr) {
console.log('got response: %s', msg.content.toString());
setTimeout(function() { conn.close(); process.exit(0) }, 500);
}
}, {noAck: true});
ch.sendToQueue('rpc_queue',
new Buffer('hello'),
{ correlationId: corr, replyTo: q.queue });
});
});
});
The requester uses a queue named responses from which it expects to receive the reply. It installs a message handler that first verifies the correlation ID and, if it matches, logs the response and terminates. Once the handler is in place, the request is sent to rpc_queue.
15.1.4. The pattern, revisited
The Request–Response pattern is deeply ingrained in human nature, and it is also natively supported by many popular network protocols and higher-level message-transport mechanisms. Therefore, it is easy to miss the two important properties that make it work:
- The requester sends the request to the responder using an already-known destination address.
- The responder sends the response to the requester using the address information contained in the corresponding request.
The basis on which this pattern is founded is that addressing information can be conveyed in a location-transparent fashion: the requester’s address is still valid and usable after being transported to the responder. You will think about this most often when you are trying to figure out why a particular response was not delivered to the requester.
Another consideration that will frequently come up when using this pattern is that between long-lived participants, requests and responses need to be matched up reliably: the requester must be able to correlate a received response with the corresponding request. Although this is in some cases implicit by virtue of using a dedicated communication channel (such as HTTP), it is crucial when both participants are addressable on their own, as seen in the AMQP example in listings 15.5 and 15.6. Including a unique identifier like a universally unique identifier (UUID)[7] achieves this and also allows the request to be resent without risking a duplication of its effects: the recipient can use the UUID to determine whether it has already performed the requested action if it keeps track of these identifiers.
See also RFC 4122 (https://tools.ietf.org/html/rfc4122).
15.1.5. Applicability
This pattern is applied ubiquitously, and rightfully so—for most requests you formulate, a response is needed in order to conclude that the request has been received or acted on. There are a few things to keep in mind, though:
- As in real life, computers need to be able to give up on waiting for a response after some time; otherwise, a communication error can bring the application to a halt. Thus, you need to consider a timeout duration appropriate for each such exchange.
- When the target component is unavailable—overloaded, failed, or otherwise—you should back off and give it some time to recover. Fortunately, request-response is precisely what CircuitBreakers need in order to fulfill their function; see chapter 12.
- When receiving the response, you need to remember the context of the corresponding request so that you can resume and complete the overall process that called for the request–response cycle. We will discuss this aspect further in the following patterns.
15.2. The Self-Contained Message pattern
Each message will contain all information needed to process a request as well as to understand its response.
We touched on this at the end of the previous section: when sending a request, you need to remember what you want to do with the response that will eventually come back. In other words, you need to manage the state of the larger operation that this exchange is a part of while the request and response travel between components. This state management can be done entirely by the requester—storing contextual information—or it can be pushed out of it by having the entire context travel with the request and response across the network. In practice, this responsibility is usually shared, leaving part of the state in the requester and having part of it travel with the message. The point of this pattern is that you should strive to include sufficient information in the message so the state that is relevant to the current request is fully represented—removing and relocating relevant information should be considered a premature optimization until proven otherwise.
15.2.1. The problem setting
Imagine a service that acts as an email gateway, providing other components of the system with the functionality of sending email notifications to customers. A protocol is defined for transporting email across computer networks: the Simple Mail Transfer Protocol (SMTP).[8] This is one of the oldest protocols used on the internet, built on top of TCP and designed to be human readable. An example session for sending an email from Alice to Bob might look like this (with C being the client and S being the server):
S: 220 mailhost.example.com ESMTP Postfix C: HELO alice-workstation.example.com S: 250 Hello alice-workstation.example.com C: MAIL FROM:<[email protected]> S: 250 Ok C: RCPT TO:<[email protected]> S: 250 Ok C: DATA S: 354 End data with <CR><LF>.<CR><LF> C: From: "Alice" <[email protected]> C: To: "Bob" <[email protected]> C: Date: Fri, 23 October 2015 10:34:12 +0200 C: Subject: lunch C: C: Hi Bob, C: C: sorry, I cannot make it, something else came up. C: C: Regards, Alice C: . S: 250 Ok, queued as 4567876345 C: QUIT S: 221 Bye
In the course of this session, 13 messages are exchanged between client and server, with both sides tracking the progressing state of the session.
The task: Your mission is to sketch the data types and protocol sequence for transmitting an email to the email gateway service such that the client receives an acceptance confirmation from the service and the session state between client and service is minimized.
15.2.2. Applying the pattern
You need to transmit information both ways between client and server, and the minimal protocol shape for such an interaction is the Request–Response pattern discussed previously. The information you need to send to the service is as follows:
- Sender email address
- Recipient(s) email address(es)
- Email body
- Correlation ID so the client can recognize a subsequent confirmation
The service will then reply with, at the very least, a status code and the correlation ID. The following listing sketches the request and response data types using the Scala language, due to its convenient case class feature.
Listing 15.7. Encapsulated information needed for multiple SMTP exchanges
case class SendEmail(sender: String, recipients: List[String],
body: String, correlationID: UUID,
replyTo: ActorRef[SendEmailResult])
case class SendEmailResult(correlationID: UUID, status: StatusCode,
explanation: Option[String])
The inclusion of the email addresses of sender and recipients would probably be represented using a more specific class than a plain String that ensures a valid address syntax, but we leave out such details in order to concentrate on the data exchange.
Does this protocol fulfill the requirements? The client transmits all information the service needs in a single message: the sequence of protocol steps performed by SMTP is collapsed into a single request–response cycle. This enables the email gateway service to begin the further processing of the email immediately after having received the single request message. This means the gateway does not need to maintain any session state pertaining to this exchange beyond the processing of this single message; it only needs to send the response, and the session is completed. Depending on the reliability guarantees the gateway provides, the response may have to be deferred until the intention of sending an email has been recorded in persistent storage—or even until after the email has been relayed to the target mail system—in which case, the return address and correlation ID must be retained until finished. But this extension of the session lifetime is not dictated by the protocol; it is inherent in those stronger guarantees. From the client’s perspective, this approach also achieves all that is needed: sending the email takes just one message, and the client then retains the correlation ID in order to continue its own processing as soon as the email has been sent.
If this simple approach fulfills all of your requirements, a question presents itself: why is the SMTP exchange so much more complex? Back in the 1970s, it took a very long time to send data across a network connection; the protocol therefore performs the exchange in many small steps, allowing the server to reject an email as early as needed (for example, after the sender or recipient address has been transmitted—the latter is done in case the target address does not exist). Today, sending a few kilobytes of text between continents is not a concern, but you still may want to avoid sending a very large email body—possibly including large file attachments—in a single request message. The reason might be so you could handle rejection without sending a potentially large number of useless bytes, but it is also important to consider resource usage in terms of how much bandwidth is taken up during the process. Receiving a large message at its own pace is the recipient’s prerogative, and the line-based exclusive TCP connection handling used for SMTP allows this to be done naturally.
You do not need to change the shape of the protocol beyond request–response, though, in order to give the recipient some control over whether and how to consume the email body. The only feature required is that the bulk data transfer happens out of band: for example, if the framework supports sending parts of the message as on-demand streams.
Listing 15.8. Separating the body so it can be delivered on demand
case class SendEmail(sender: String, recipients: List[String],
correlationID: UUID, replyTo: ActorRef[SendEmailResult])
(body: Source[String]) extends StreamedRequest {
override def payload = body
}
This sketch hints at a hypothetical microservice framework that would handle the streaming of the designated message parts transparently, serializing only the data elements in the first argument list (up to replyTo) eagerly in the request message and transferring the payload data on demand. Another way to achieve this is to include in the message the location (for example, by way of a URL such as http://example.com/emails/12) where the email body can be obtained; then, the gateway service can contact that location on its own if and when it needs to.
Listing 15.9. Enabling the body to be pulled by the recipient
case class SendEmail(sender: String, recipients: List[String],
bodyLocation: URL, correlationID: UUID,
replyTo: ActorRef[SendEmailResult])
15.2.3. The pattern, revisited
In the previous section, you collapsed a 13-step protocol session into 2 steps: sending one message in either direction is the minimum you can do while still allowing the client to ascertain that the email has in fact been relayed to the gateway service. As a variation, we considered how you can split out one part—the transmission of the email body—into a separate subprotocol that is transparently handled by the used framework or into a secondary conversation between the service and another endpoint. The variation does not complicate the client-service conversation in principle.
The advantages of this change are manifold. We started with the postulated desire of minimizing the session state that needs to be maintained between client and service throughout the conversation. This is an important aspect in that the service can now become stateless in this sense: it can react to the request with a response while not retaining any more information about the client, and the conversation does not need to continue. If the service wants to recognize subsequently re-sent requests, it only needs to store the UUID; it does not need to track the individual clients.
A possibly even greater advantage is that removing the need to store conversational state makes it possible to distribute the processing of the requests in space or time: a SendMail message can be enqueued, serialized to disk, replayed, and routed to one of many email gateway service instances; it can even be automatically retried by the framework if the correspondence with its SendEmailResult is suitably represented, and so on. Shortening the conversation to its minimum affords you a lot of freedom in how you handle and possibly transform the message.
This goes hand in hand with easier recovery procedures. Because the request contains everything needed to process it, it also is fully sufficient to reprocess it after a failure. In contrast, a lengthy, stateful conversation would have to be reestablished—and, in most cases, begun by the client—which calls for specific recovery procedures to be in place among all participants.
15.2.4. Applicability
This pattern is universally applicable in the sense of striving to keep the conversation protocols as simple as feasible. You may not always be able to reduce the interaction to a single request–response pair, but when that is possible, it greatly increases your freedom in handling the protocol. Where multiple steps are necessary to achieve the desired goal, it still is preferable to keep the messages that are exchanged as complete and self-contained as can be afforded, because relying on implicitly shared session state complicates the implementation of all communication partners and makes their communication more brittle.
The main reason for not applying this pattern is that the amount of state is larger than can reasonably be transmitted.
15.3. The Ask pattern
Delegate the handling of a response to a dedicated ephemeral component.
This pattern can be arrived at by two trains of thought:
- In a purely message-driven system such as the Actor model, it frequently occurs that after performing a request–response cycle
with another Actor, the current business process needs to continue with further steps. Toward this end, the Actor could keep
a map of correlation IDs and associated continuation information (such as the details of the ongoing business transaction
started by an earlier received message), or it could spawn an ephemeral child Actor, give its address as the return address
for the response, and thereby delegate the continuation of the process. The latter is the approach described in Gul Agha’s
thesis:[9] it is the Actor way of thinking. Because this pattern occurs frequently, it may receive special support from libraries or
frameworks.
Gul Agha, “ACTORS: A Model of Concurrent Computation in Distributed Systems,” 1985, https://dspace.mit.edu/handle/1721.1/6952.
- Traditional RPC systems are exclusively based on the premise of request-response calls, pretending the same semantics as a local procedure call. Their synchronous presentation results in distributed systems coupled in undesirable ways, as discussed throughout the first part of this book. In order to decouple caller and callee, the locally returned type is changed from a strict result value to a Future—a container for a result value that may arrive later. The continuation of the caller’s business process then needs to be lifted into the Future as well, using transformation combinators to perform the successive steps. This Future is an ephemeral component whose purpose is the reception of the eventual response and the initiation of follow-up actions, exactly like the child Actor in the previous bullet point.
15.3.1. The problem setting
Recall the previous section’s example: a client exchanges a request–response pair with an email gateway service in order to send an email. This happens in the course of another business transaction: perhaps an account-verification process during which the account holder is sent a link via which the process will continue. After the email has been sent on its way, you may want to update the website, saying that the user should check their in-box and offering a link to send the email again in case it was lost.
The task: Your mission is to implement an Actor that, upon receiving a StartVerificationProcess command, contacts the email gateway service (represented by an ActorRef) to send the verification link. After receiving the response, the Actor should respond to the command received previously with a Verification-ProcessStarted or VerificationProcessFailed message, depending on the outcome of the email request.
15.3.2. Applying the pattern
The following listing sets the stage by defining the message types you will need in addition to the SendEmail protocol defined in the previous section.
Listing 15.10. Simple protocol to request starting the verification process
case class StartVerificationProcess(userEmail: String,
replyTo: ActorRef[VerificationProcessResponse])
sealed trait VerificationProcessResponse
case class VerificationProcessStarted(userEmail: String)
extends VerificationProcessResponse
case class VerificationProcessFailed(userEmail: String)
extends VerificationProcessResponse
The Actor can then be written in Akka Typed, as shown next.
Listing 15.11. An anonymous child actor forwards results
def withChildActor(emailGateway: ActorRef[SendEmail]):
Behavior[StartVerificationProcess] =
ContextAware { ctx: ActorContext[StartVerificationProcess] =>
val log = Logging(ctx.system.eventStream, "VerificationProcessManager")
Static {
case StartVerificationProcess(userEmail, replyTo) =>
val corrID = UUID.randomUUID()
val childRef = ctx.spawnAnonymous(Props(FullTotal[SendEmailResult] {
case Sig(ctx, PreStart) =>
ctx.setReceiveTimeout(5.seconds)
Same
case Sig(_, ReceiveTimeout) =>
log.warning("verification process initiation timed out for {}",
userEmail)
replyTo ! VerificationProcessFailed(userEmail)
Stopped
case Msg(_, SendEmailResult(`corrID`, StatusCode.OK, _)) =>
log.debug("successfully started the verification process for {}",
userEmail)
replyTo ! VerificationProcessStarted(userEmail)
Stopped
case Msg(_, SendEmailResult(`corrID`, StatusCode.Failed, expl)) =>
log.info("failed to start the verification process for {}: {}",
userEmail, expl)
replyTo ! VerificationProcessFailed(userEmail)
Stopped
case Msg(_, SendEmailResult(wrongID, _, _)) =>
log.error("received wrong SendEmailResult for corrID {}", corrID)
Same
}))
val request = SendEmail("[email protected]", List(userEmail),
constructBody(userEmail, corrID), corrID,
childActor)
emailGateway ! request
}
}
Given the ActorRef representing the email gateway service, you construct a behavior that will keep serving StartVerificationProcess messages; hence, it uses the Static behavior constructor. You extract the enclosing ActorContext (the type ascription is given merely for clarity) because you will need to use it to create child Actors as well as to emit logging information. For every command you receive, you create a new UUID that serves as an identifier for the email sent subsequently. Then you create an anonymous[10] Actor whose ActorRef is used as the return address for the SendEmail request you finally send to the email gateway service.
That is, unnamed—the library will compute a unique name for it.
The created child Actor uses the FullTotal behavior constructor because it will need to receive a system notification: the receive-timeout feature is used to abort the process if the email gateway does not respond within the allotted time. If a response is received before this timeout expires, you distinguish three cases:
- A successful result with the correct correlation ID leads to a successful response to the original request.
- A failure result with the correct correlation ID is translated to a failure response.
- A response with a nonmatching correlation ID is logged and ignored.[11]Receiving the nonmatching response will reset the receive timeout, though. We do not correct for this potential lengthening of the response timeout in this case in order to not complicate the example too much; it could well be argued that a wrongly dispatched response should be a rare occurrence, if it happens at all.
In all cases leading to a response sent to the original client, the child Actor terminates itself after the response has been sent—the purpose of this ephemeral component is fulfilled, and there is nothing left to be done.
This pattern is so widely applicable that Akka provides special support for it: when expecting a request–response conversation, the response message can be captured in a Future where it is then further processed. The example can be reformulated as follows.
Listing 15.12. Future produced by the Ask pattern and mapped

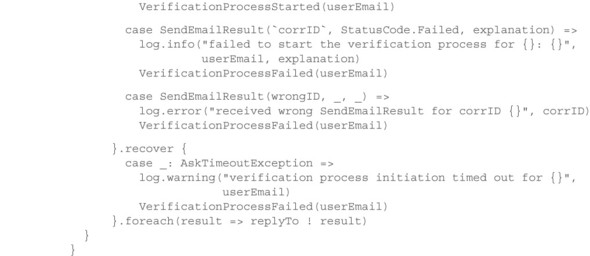
The execution of Future transformations requires the designation of an execution context: you use the actor’s dispatcher to perform these tasks. The handling of the response timeout is an inherent feature of the AskPattern support implemented in Akka; it is configured via the implicitly declared timeout value. Use of the pattern implementation proceeds via the ? operator that is made available by importing akka.typed.AskPattern._. This operator takes as its argument not the message but a function that injects the internally created PromiseActorRef into the message. Under the hood, a lightweight, ephemeral actor is created, just as in the previous implementation, but this actor’s sole purpose is to place any received message into the Future that the ? operator returns.
It comes as no surprise that you need to handle all the same cases when interpreting the contents of the Future, although the timeout surfaces not as a Receive-Timeout signal but as a failed Future. One difference is that a Future can only be completed exactly once; therefore, the reception of a response with the wrong correlation ID can no longer be ignored. The asker will have to abort the process instead.
15.3.3. The pattern, revisited
Implementing this process without the Ask pattern might have looked like the following.
Listing 15.13. Implementing the Ask pattern without using built-in support
def withoutAskPattern(emailGateway: ActorRef[SendEmail]):
Behavior[StartVerificationProcess] =
ContextAware[MyCommands] { ctx =>
val log = Logging(ctx.system.eventStream, "VerificationProcessManager")
var statusMap = Map.empty[UUID,
(String, ActorRef[VerificationProcessResponse])]
val adapter = ctx.spawnAdapter((s: SendEmailResult) =>
MyEmailResult(s.correlationID, s.status, s.explanation))
Static {
case StartVerificationProcess(userEmail, replyTo) =>
val corrID = UUID.randomUUID()
val request = SendEmail("[email protected]", List(userEmail),
constructBody(userEmail, corrID), corrID, adapter)
emailGateway ! request
statusMap += corrID -> (userEmail, replyTo)
ctx.schedule(5.seconds, ctx.self, MyEmailResult(corrID,
StatusCode.Failed, "timeout"))
case MyEmailResult(corrID, status, expl) =>
statusMap.get(corrID) match {
case None =>
log.error("received result for unknown corrID {}", corrID)
case Some((userEmail, replyTo)) =>
status match {
case StatusCode.OK =>
log.debug("successfully started verification process for {}",
userEmail)
replyTo ! VerificationProcessStarted(userEmail)
case StatusCode.Failed =>
log.info("failed to start verification process for {}: {}",
userEmail, expl)
replyTo ! VerificationProcessFailed(userEmail)
}
statusMap -= corrID
}
}
}.narrow[StartVerificationProcess]
In comparison to the solutions given in listing 15.12, this has several disadvantages:
- The Actor needs to incorporate the foreign protocol of the email gateway (in particular, the SendEmailResult message type) into its own repertoire of messages. Toward this end, Akka Typed provides the facility of spawning an adapter ActorRef that turns SendEmailResult messages into MyEmailResult objects; such an adapter is used in listing 15.13 as the return address for the SendEmail request.
- The Actor needs to explicitly maintain the sum of the status information for all currently open transactions. You implement this in listing 15.13 by maintaining a mapping from correlation IDs to the eventually needed parameters—the user’s email and the original requester’s ActorRef, in this case. Maintaining this mapping requires more discipline than with the Ask pattern in that you need to take care to properly remove stale state when transactions end; this cleanup is conveniently bundled with the ephemeral actor’s lifecycle when using the Ask pattern.
- Handling timeouts requires notification of this Actor while retaining enough identifying information. In this example, it needs to track the correlation ID of each transaction. In the example case, this can be trivially mapped to a failed SendEmailResult, but in general this may necessitate the addition of yet another message type to the Actor’s internal protocol.
- The Actor needs to respond to more messages than it would otherwise need, opening up the possibility of wrong messages being sent to this exposed service more easily and with greater reach than would be the case if handling these other types of messages were delegated to ephemeral endpoints as with the Ask pattern.
In listing 15.13, the sketched verification-management service confers with only one other service, and handling the associated status information amounts to roughly the same number of lines as when using the Ask pattern. If you imagine a service that needs to communicate with several other services as well, it becomes clear that consistent management of all associated state will pile up—it will become intertwined in nontrivial ways and be more difficult to evolve and maintain. Using the Ask pattern, on the other hand, allows you to separate out the subconversations that occur while processing a larger business transaction; it helps you to decouple the handling of session state by segregating it for each conversation and delegating it to a subcomponent.
15.3.4. Applicability
The Ask pattern is applicable wherever a request–response cycle needs to be performed before continuing with the further processing of an enclosing business transaction. This holds only for non-ephemeral components, though: if the enclosing transaction is already handled by a dedicated ephemeral component, then usually no complexity overhead is incurred by keeping the state management for the request-response cycle within that component.
One consequence of using the Ask pattern is that the parent component is not automatically aware of the progress of the subconversation; it must be informed explicitly if it needs to stay in the loop. This can be relevant if the number of concurrently outstanding requests needs to be limited, whether in order to protect the target service from being overwhelmed with a sudden onslaught of requests or in order to not overwhelm local computing and network resources with too many concurrent conversations. Using the Ask pattern indiscriminately can easily be equivalent to employing an unbounded queue, with all the negative effects on response latency that are discussed in section 2.1.3, plus ample opportunity to exhaust all available memory.
15.4. The Forward Flow pattern
Let the information and the messages flow directly toward their destination where possible.
This pattern sounds intuitive, maybe even trivial: why would you deliberately send messages via detours when that is not required? The answer is that this rarely occurs consciously; it is the result of applying a convenient, well-known pattern overeagerly. The pattern in question is your good friend the Request–Response pattern, with or without the Ask pattern’s sugar coating. Overusing this pattern leads to unnecessary consumption of network bandwidth and increased response latency; thinking about forward flow lets you recognize these cases and improve your service quality.
15.4.1. The problem setting
Imagine a message router that dispatches incoming file streaming requests to a pool of service instances that host these files. They could be video files that are sent to clients for streaming display on users’ screens.
The task: Your mission is to sketch the sequence of messages sent among client, router, and file server such that the router does not become a bottleneck in the streaming video dissemination process.
15.4.2. Applying the pattern
Starting from naïve request–response communication, you might foresee that the client sends to the router, the router embodies the client from the perspective of the file server, and thus responses flow via the router back to the client. This is shown in figure 15.2.
Figure 15.2. Flow of messages when nesting the Ask pattern: all responses travel via the intermediate router component.

In this scheme, the router must be able to forward all the streams coming from the file servers back to all the clients, meaning its network interface’s bandwidth will place an upper limit on how many bytes per second can be streamed by the entire system. Network links are becoming faster and faster, but if this streaming service is intended to serve customers on the internet, then it will reach its limit fairly soon. Therefore, you must think a bit more about the meaning of request and response in this scenario: the client sends a request, and the logical destination is the file server, not the router. The response is a video stream whose source is the file server and whose destination is the client. Although you need the router as an intermediary for the request—balancing the load across a pool of replicated file servers hosting the particular video file that is requested—you do not need to involve it in handling the response. The resulting message-flow diagram is shown in figure 15.3.
Figure 15.3. Flow of messages when applying forward flow: although the request needs to pass through the router for load balancing, the (large) response does not need to take the same route. It can travel back directly from file server to client.

Here, the requests flow toward their destination via the shortest possible path, and the responses also do not waste any time on their way back. Because the file servers communicate directly with the clients, you are free to scale up the available computing and network resources without limit.
15.4.3. The pattern, revisited
We have analyzed the initial draft of applying the Request–Response pattern individually for each step along a request’s path and found that responses profit from not taking the same path; instead, they may take a more direct route. By cutting out the middleman, you gain the freedom to scale the available response bandwidth without being limited by what a single router can provide.
The same applies to a file-upload service in reverse: the uploaded data streams go directly to the file servers, but the response may be routed via another service to update the file catalog or otherwise perform accounting tasks. Sending the voluminous data streams via the accounting system would require that the system be scaled such that it can handle the resulting load, but this is a purely incidental concern because the accounting system is not interested in the data bytes.
Another aspect is that removing intermediate hops from a message’s path reduces the time it takes for the message to reach its final destination. Every time it is enqueued and dispatched again, there is a latency cost.
15.4.4. Applicability
Using forward flow to optimize the overall resource consumption or response-latency time requires participating services to allow for these shortcuts. Either they need to know about each other—as demonstrated by the router that is intimately aware of the file server pool—or the message protocol needs to include the possibility to specify the target route a message will take so that the middleman can remain ignorant of its location within the message flow. Applying this pattern hence involves an assessment of how big the gains in service quality are in relation to the additional complexity or coupling the pattern introduces. In the example of the video-streaming service, it is evident that the performance requirements of the system dictate this approach; but in other cases, it may not be as clear. As with all optimizations, the application must be predicated on having measured the performance of the simpler alternative solution and found the results to be inadequate.
15.5. The Aggregator pattern
Create an ephemeral component if multiple service responses are needed to compute a service call’s result.
We have introduced the Ask pattern for the case of requiring a request–response cycle before a service call can be answered. There are cases, though, where a larger number of these cycles need to be completed, and none of the requests depend on the responses of the others—in other words, the request–response cycles can be made in parallel. Disregarding this opportunity for parallelism means prolonging the time until the overall response can be sent back to the client, thus leaving an opportunity for latency reduction unused.
15.5.1. The problem setting
Imagine a personalized front page for a news site. In order to render the page, you need multiple inputs:
- Theme the user has configured to be used for styling the site
- News items to be displayed as per the user’s topic selection
- Top news items that are displayed to all users
Each of these inputs is provided by a different service by way of a request–response protocol.
The task: Your mission is to formulate an Actor that, upon receiving a GetFrontPage request, creates an ephemeral component that retrieves the three inputs in parallel and, when ready, sends their composition back to the original requester.
15.5.2. Applying the pattern
Using the Ask pattern, you can decompose the task into two steps: first, you initiate three ask operations, one for each of the needed inputs; and then, you combine their result using Future combinators. In other words, you use a Future’s facilities as the ephemeral component that oversees this entire process. The full code is available with the book’s downloads; we omit the message definitions here because they are trivial and intuitive. The code looks like the following listing.
Listing 15.14. Using a for-comprehension to aggregate the result of three Future expressions


This code defines an actor that, for each GetFrontPage request, creates three Futures, each based on the Ask pattern with a value transformation for extracting the desired piece of information and a recovery step that defines the replacement value to be used in case of a timeout. We present here only the aspects that are directly relevant; in a complete program, you would of course take care to install circuit breakers as appropriate and also ensure that you limit the total number of outstanding ask requests in order to prevent unbounded resource usage. As the second step, the actor uses a for-comprehension to tie together the three individual Futures in order to compute the full result that is finally sent back to the return address provided with the initial request.
Another way to implement the same process would be to create an ephemeral child Actor instead of using Future combinators, as shown next.
Listing 15.15. Using a child Actor in place of Future combinators


The structure of the ephemeral child Actor consists of two aspects: first, any new piece of information is incorporated into the current set of knowledge as managed by a mutable builder (shown in listing 15.15), and then the builder is queried as to whether the answer is now complete, in which case the process is completed by sending the result back to the original requester. The process is set in motion by sending the three requests to their respective providers while giving the child Actor’s reference as the return address.
Listing 15.16. Using a builder to express the domain more directly
class FrontPageResultBuilder(user: String) {
private var css: Option[String] = None
private var personalNews: Option[List[String]] = None
private var topNews: Option[List[String]] = None
def addCSS(css: String): Unit = this.css = Option(css)
def addPersonalNews(news: List[String]): Unit =
this.personalNews = Option(news)
def addTopNews(news: List[String]): Unit = this.topNews = Option(news)
def timeout(): Unit = {
if (css.isEmpty) css = Some("default.css")
if (personalNews.isEmpty) personalNews = Some(Nil)
if (topNews.isEmpty) topNews = Some(Nil)
}
def isComplete: Boolean =
css.isDefined && personalNews.isDefined && topNews.isDefined
def result: FrontPageResult = {
val topSet = topNews.get.toSet
val allNews = topNews.get ::: personalNews.get.filterNot(topSet.contains)
FrontPageResult(user, css.get, allNews)
}
}
This builder adds more lines of code to the weight of the program than the Future-based solution requires, but it also lets you express the domain of your problem natively and unencumbered: the Ask pattern and its underlying Future API place the focus on the eventual availability or failure of each single value, making it more difficult to formulate actions or reactions that affect multiple aspects at once. An example appears in listing 15.16’s timeout handling: the Actor-based approach allows the more natural formulation of an overall timeout that is handled in one place only, whereas AskTimeoutException’s recovery logic must be repeated for each of the three individual Futures.
Another use case that illustrates this point is a mechanism that can override the front page’s contents and style in case of special events. In the Actor-based implementation, this could be done by sending a request to a fourth service; for a given reply, you could override fields of the builder as appropriate, completing the result right away. This can be implemented by adding a single line to the message-reception cases. In the Future-based approach, you would need to formulate these as two competing operations, because adding a fourth input to the current scheme would require you to wait for the irrelevant responses to the other three requests in case of an override. The resulting code becomes less readable, as shown in the following listing.
Listing 15.17. Adding a fourth service, making the code less readable


Although this is not a major change in terms of lines added, it makes it more difficult to reason about the behavior of this code. In particular, an important hidden constraint is only expressed in the annotations: the execution is bifurcated, and only the careful treatment of OverrideResult ensures that the overall result is deterministic.
15.5.3. The pattern, revisited
You extended the Ask pattern to include more than one request–response pair in the calculation of an overall result. While doing so, you found Future combinators to express this in a straightforward way as long as all individual results can be treated independently—as soon as the aggregation process involves decisions that affect the aggregation logic, it becomes preferable to create an explicit ephemeral component that bundles this process. The reason is that Futures are limited in that they do not have a name or an identity that can be spoken to after their creation; their input value is fixed as soon as the combinator that produces them has been invoked. This is their greatest strength, but it can also be a weakness.
In contrast, the ephemeral component that the Aggregator pattern gives rise to—modeled as an Actor in listing 15.15—can easily express any process of arriving at the aggregation result, independent of which inputs are needed and which scope they affect. This is an advantage particularly in cases where the aggregation process conditionally chooses different computations to be applied based on some of the inputs it collects.
15.5.4. Applicability
The Aggregator pattern is applicable wherever a combination of multiple Ask pattern results is desired and where straightforward Future combinators cannot adequately or concisely express the aggregation process. Whenever you find yourself using multiple layers of Futures or using nondeterministic “racy” combinators like Future.firstCompletedOf(), you should sketch out the equivalent process with Actors (or other named, addressable components) and see whether the logic can be simplified. One concern that frequently drives this is the need for complex, layered handling of timeouts or other partial failures.
15.6. The Saga pattern
Divide long-lived, distributed transactions into quick local ones with compensating actions for recovery.
In other words: Create an ephemeral component to manage the execution of a sequence of actions distributed across multiple components.
The term saga was coined by Hector Garcia-Molina.[12] His paper describes a scheme for breaking up long-lived business transactions in order to shorten the time period during which databases need to hold locks—these locks are needed to ensure atomicity and consistency of the transaction, the downside of which is that other transactions touching the same data cannot proceed concurrently.
Hector Garcia-Molina, “Sagas,” ACM, 1987 (http://dl.acm.org/citation.cfm?id=38742).
In a distributed system, you need to break up transactions involving multiple participants for other reasons: obtaining a shared lock is an expensive operation that can even be impossible in the face of certain failures like network partitions. As we discussed in chapter 8, the key to scalability and loose coupling is to consider each component an island of delimited consistency. But how do you model business transactions that require inputs from multiple components while also effecting modifications to multiple components? It turns out the research topic of sagas provides an effective, robust solution for many use cases.
Note
This section gives only a brief overview; a full book could be written on this topic alone. A very similar concept is the process manager in the CQRS literature[13]—the main difference is that a saga focuses on transactional aspects (atomicity and consistency), whereas a process manager is primarily seen as factoring out the description of a particular process from the components that participate in it.
See “CQRS Journey” (July 2012) on MSDN, reference 6: “A Saga on Sagas,” https://msdn.microsoft.com/en-us/library/jj591569.aspx.
15.6.1. The problem setting
The prototypical example of a business transaction that affects more than one consistent entity (or aggregate in domain-driven design [DDD] terms) is a money transfer from one bank account to another. Questions of this kind arise immediately when scaling out the application state managed previously by a single RDBMS instance onto a distributed cluster of machines, whether for elasticity or resilience reasons. The code of the nondistributed system would tie the update to both accounts in a single transaction, relying on the RDBMS to uphold the guarantees of atomicity, consistency, isolation, and durability. In the distributed system, there is no such mechanism, requiring the use of the Saga pattern.
The task: Your mission is to sketch the conversation between an ephemeral saga component and the two bank account components in order to perform a money transfer, considering that individual steps can fail permanently (for example, because the source account does not have sufficient funds or the destination account is closed after the process begins). Unreliable communication will be considered in the following pattern. You may then also implement the saga component in code: for example, as a persistent actor.
15.6.2. Applying the pattern
When designing a communication protocol between multiple parties, one natural analogy is to envision a conversation among a group of people. Here, you want to describe how Sam—the saga—confers with Alice and Bob to transfer part of Alice’s budget to Bob. The analogy works best if the essential properties of the process are represented: in this case, handing over the money in cash would not be possible, because that kind of fully synchronous process is not how distributed systems work. Therefore, you will reallocate $10,000 of budget between them.
Before we consider various failure scenarios, we will sketch the nominal successful case, which might go like the following:
- Sam: “Alice, please reduce your budget by $10,000 if possible.”
- Alice: “OK. I’ve done so.”
- Sam: “Bob, please increase your budget by $10,000.”
- Bob: “Thanks, Sam; it’s done.”
- Sam: “Thanks everyone; transfer finished!”
There is no need for Alice and Bob to talk to each other, because Sam coordinates the transfer. Given this scenario, we might as well have let both subconversations occur in parallel to each other. Now we will consider some failure modes—for example, if Alice does not have sufficient budget:
- Sam: “Alice, please reduce your budget by $10,000 if possible.”
- Alice: “Sorry, Sam, my budget is too low already.”
- Sam: “Listen up, everyone—this transfer is aborted!”
This case is simple. The first step of the process fails in a nontransient fashion, so no harm is done and an abort is immediately possible. A more complicated case occurs if Bob is unable to receive the increased budget amount:
- Sam: “Alice, please reduce your budget by $10,000 if possible.”
- Alice: “OK. I’ve done so.”
- Sam: “Bob, please increase your budget by $10,000.”
- Bob: “Sorry, Sam, my project was just canceled—I no longer have a budget.”
- Sam: “Alice, please increase your budget by $10,000.””
- Alice: “Thanks, Sam; it’s done.”
- Sam: “Listen up, everyone—this transfer is aborted!”
In this case, the second step that Sam wants to perform cannot be carried out. At this point, Alice has already reduced her budget, so logically Sam holds $10,000 in his hands—but he has no budget to manage for himself. The solution for this dilemma is that Sam gives the $10,000 back to Alice. This is called a compensating transaction. Using this trick, we can also make the entire transfer opportunistically parallel and still remain correct:
- Sam: “Alice, please reduce your budget by $10,000 if possible. Bob, please increase your budget by $10,000.”
- Bob: “Thanks, Sam. It’s done.””
- Alice: “Sorry, Sam, my budget is too low already.”
- Sam: “Bob, please reduce your budget by $10,000.”
- Bob: “OK. I’ve done so.”
- Sam: “Listen up, everyone—this transfer is aborted!”
Of course, we have assumed here that the compensating transactions always succeed; but what if that is not the case? What if in the last example Bob had already—and surprisingly quickly—spent the $10,000 while Sam was waiting for Alice to respond? In this case, the system would be in an inconsistent state that Sam could not fix without external help. The moral of this gedankenexperiment is that computers and algorithms cannot be held responsible for dealing with all possible corner cases, especially when it comes to distributed systems where the convenient simplifications of a fully sequential local execution cannot be applied. In such cases, inconsistencies must be recognized as possible system states and signaled upward: for example, to be decided by the humans who operate the system. For further reading on this topic, please see Pat Helland’s “Memories, Guesses, and Apologies.”[14]
MSDN blog, 2007, http://blogs.msdn.com/b/pathelland/archive/2007/05/15/memories-guesses-and--apologies.aspx.
15.6.3. The pattern, revisited
Given two accounts—symbolized by Alice and Bob—we have introduced another process: a saga whose role was played by Sam in order to orchestrate the transfer of budget from one account to the other. Getting Alice and Bob to agree directly on this transfer would be a costly process during which both would be unavailable for other requests, because those could invalidate the current state of the consensus-building conversation; this would be the analogous solution using a distributed transaction in the ACID sense (a transaction like the ones we are used to from relational database management systems [RDBMSs]). Instead, we have placed the responsibility for leaving the system in a consistent state with the new external process that runs this process.
You have seen that in order to do this, you have to not only describe the individual transactions that are done on each account but also provide compensating transactions that come into play if the saga needs to be aborted. This is the same as performing a transaction rollback on a RDBMS; but because you are no longer dealing with a single realm of consistency, the system can no longer automatically deduce what constitutes a rollback. Hector Garcia-Molina notes that writing the compensating transactions is not a black art, though; it is usually of the same difficulty as encoding the transactions.
One property of compensating transactions that we have glossed over so far requires a bit of formalism: where transaction T1 takes the component from state S0 to state S1, the compensating transaction C1 takes it from S1 back to S0. We are applying these transactions within the consistency boundaries of several different components—Alice and Bob, in the earlier example—and within one of these components an execution of a sequence of transactions T1..Tn would take that component from state S0 to Sn. Because transactions do not, in general, commute with each other, taking the system back from state Sn to S0 would require the application of the compensating transactions Cn..C1: the compensating transactions would be applied in reverse order, and this order matters. We have played with the thought of parallelizing parts of the two subconversations (Sam-Alice and Sam-Bob), but you must always be careful to maintain a deterministic and thus reversible order for all transactions that are performed with Alice and Bob individually. For an in-depth discussion of compensation semantics, please refer to Garcia-Molina’s “Sagas” paper.
At the beginning of this pattern’s description, we mentioned the term process manager from CQRS terminology. This term refers to another property of the pattern we have described: in order to carry out the budget transfer, neither Alice nor Bob needed to know how it worked; they only needed to be able to manage their own budget and respond to requests to reduce or increase it. This is an important benefit in that it allows the description of complex business processes to be decoupled from the implementation of the affected components both at runtime and during development. The process manager is the single place that holds all knowledge about this business process: if changes are required, they are made only to this software module.
In Reactive systems, the need to factor out this process into its own ephemeral component arises from both sides: we need to model workflows that affect multiple components while maintaining eventual consistency, and we need to factor out cross-component activities such that we do not strongly couple the development or execution of these components. The “Sagas” paper was not written with distributed systems in mind, but it does offer a solution to both these problems. It also predates the CQRS terminology by nearly two decades; and because we like the concise and metaphorical name of the proposed abstraction, we call this pattern the Saga pattern.
Coming back to the example, Sam has one quality we have not yet discussed: when you model a process this way, you expect that the transfer will eventually be finished or aborted, no matter what happens. You do not expect Sam to be distracted and forget about the whole thing. Not only would that be pushing the analogy too far, but it is also a property that you do not wish your computer systems to have—you want them to be reliable. In computer terms, the state the saga manages must be persistent. If the machine that runs the saga fails, you need the ability to restart the process elsewhere and have it resume its operations. Only then can you be sure the process will eventually complete, assuming that you keep providing computing resources.
The Aggregator pattern describes a simple form of a workflow—the retrieval of information from multiple sources and its subsequent conversion into an overall result—whereas the Saga pattern allows arbitrary processes to be formulated. The Aggregator pattern is a simple, special case, whereas the Saga pattern describes service composition in general.
15.6.4. Applicability
The astute reader will have grown increasingly impatient, waiting for the discussion of the elephant in the room: if this pattern is presented as a solution in place of distributed transactions, then how do we reconcile this with the fact that sagas are not isolated from each other? Going back to the example, you could easily imagine another process that tallies all allocated budgets across the company by interrogating all project leads, including Alice and Bob: if this tally process asks during the transfer such that Alice has already reduced her budget but Bob has not yet increased his, the tally will come up $10,000 short because the money is “in flight.” Running the tallying process during a quiescent period when no transfers are ongoing would lead to the correct result, but otherwise there would always be a risk of errors.
In some systems this is not acceptable. These systems cannot tolerate being distributed in the sense of splitting them into multiple autonomous, decoupled components. Sagas cannot be used to fix this problem in general.
The Saga pattern is applicable wherever a business process needs to be modeled that involves multiple independent components: in other words, wherever a business transaction spans multiple regions of delimited consistency. In these cases, the pattern offers atomicity (the ability to roll back by applying compensating transactions) and eventual consistency (in the sense that application-level consistency is restored by issuing apologies; see Pat Helland’s aforementioned blog article), but it does not offer isolation.
15.7. The Business Handshake pattern (a.k.a. Reliable Delivery pattern)
Include identifying and/or sequencing information in the message, and keep retrying until confirmation is received.
While discussing the previous pattern, we made the implicit assumption that communication between the saga and the affected components is reliable. We pictured a group of people standing in the same office and discussing the process without external disturbances. This is a useful way to begin, because it allows you to focus on the essential parts of a conversation; but we know that life does not always work like that—in particular in distributed systems, where messages can be lost or delayed due to unforeseeable, inexorable subsystem failures.
Fortunately, we can treat the two concerns on separate levels: imagining that the conversation occurs in a busy, noisy office does not invalidate the basic structure of the business process we are modeling. All that is needed is to deliver every message more carefully, transmitting it again if it is overshadowed by some other event. This second level is what the Business Handshake pattern is all about.
15.7.1. The problem setting
In the previous example, we assumed that Sam—the saga—conveyed the message “Please reduce your budget by $10,000 if possible” to Alice, who replied with either an affirmative or a negative response. In a setting where communication becomes unreliable, it may happen that either the message to Alice or the response is not heard—in technical terms, it is lost. If this happens, the process will be stuck, because without further provisions, Sam will wait indefinitely to hear back from Alice. In real life, impatience and social conventions would solve this conflict, but computers are dumb and cannot figure this out without help.
The task: Your mission is to describe the process of conveying the request and response in a reliable fashion, considering that every single message could be lost undetectably. You should write this down from the perspectives of both Sam and Alice, using your message-driven communication tool kit of choice, but without exploiting the potential reliable-delivery guarantees of such a tool kit.
15.7.2. Applying the pattern
As a general working principle, we will again begin from a real-world example. Imagine Sam and Alice sitting at their desks, several meters apart, in a noisy office—so noisy that both need to shout to have a chance of hearing what the other is saying. Sam shouts, “Please reduce your budget if possible!” and then listens intently for Alice’s response. If none is forthcoming, Alice may not have heard, so Sam shouts again until a reaction comes back from Alice. Alice, on the other hand, sits there working on other things until she hears Sam shouting; she has no clue how often Sam may have shouted previously. Having heard the request, Alice brings up the budget spreadsheet, takes out $10,000 for Sam, and then shouts that she has done so. From Alice’s perspective, everything is finished—but Sam may not have heard her reply, in which case he’ll shout again. In fact, he has to keep shouting until Alice responds again so he has another chance to hear the response. When Alice hears Sam make the same request again, she will naturally shout back, “Hey, I already did that!” After some time, Sam will finally hear her, and the exchange will be complete.
Implementing this using Actors looks like the following listing (the full source code can be found with the book’s downloads).
Listing 15.18. Implementing the exchange using Actors
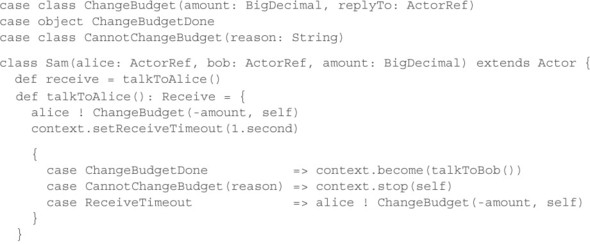

First, note that Sam includes identifying information with the ChangeBudget command in the form of his own ActorRef—this is a token that is guaranteed to be unique, and it identifies exactly one budget change for Alice because Sam is a short-lived saga. Second, note how Sam keeps resending the same command using the Receive-Timeout mechanism until the reply from Alice has been received. If the budget reduction fails, the saga terminates; otherwise, it continues by talking with Bob in the same fashion it did with Alice.
On the receiving end, you see that Alice validates the incoming command: if you have already seen a command with the same return address, then there is nothing to be done apart from confirming that it has already been done, whereas in the case of insufficient funds, you must send a negative response. But if the command is new and valid, you execute its effect—changing the budget—and reply to the requester that you have done so. In addition, you must keep track of what you have done. Here, you store the return address in a set so that you can later recognize it in case of a retransmitted command. This set would grow indefinitely over time unless you clean it up; for this, you use the DeathWatch mechanism. When the saga ends, its Actor is terminated, and you can remove the reference from the set because there cannot be any more retransmissions with this return address.
What we have sketched so far is the volatile in-memory version of performing the business handshake. If the execution must be reliable across machine failures and restarts, you have to make Sam and Alice persistent. The following listing shows how this changes Sam.
Listing 15.19. Adding persistence to the budget messages


This Actor is very similar to the Sam actor presented in listing 15.18, but instead of sending to Alice and Bob via their ActorRef, you now can only use their ActorPath—the difference is that the latter stays valid across machine restarts whereas the former does not. PersistentSam also needs to store its state changes by emitting events to its persistent journal, identified by the persistenceId. The AtLeastOnceDelivery mixin provides the deliver() and confirmDelivery() methods that implement the persistent version of the retransmission scheme previously based on the Receive-Timeout mechanism: delivery is retried periodically until the confirmation is registered. During recovery, all previously persisted events from the journal are replayed, and the persistent actor goes through the same state transitions and delivers and confirms the same messages it previously did. Thus, after recovery it will have reached the same state as before the (forceful) restart.
One noteworthy detail is that the state progression toward talking to Bob is effected only after having successfully persisted Alice’s confirmation, as shown in listing 15.20. If the machine crashes after that message is delivered but before it is written to persistent storage, the effect is as if the message were lost on the way—which is exactly the right semantics, because the confirmation must reach Sam’s memory and not only his ears.
Listing 15.20. The persistent version of Alice
case class BudgetChanged(amount: BigDecimal, persistenceId: String)
case object CleanupDoneList
case class ChangeDone(persistenceId: String)
class PersistentAlice extends PersistentActor with ActorLogging {
def persistenceId: String = "Alice"
implicit val mat = ActorMaterializer()
import context.dispatcher
var alreadyDone: Set[String] = Set.empty
var budget: BigDecimal = 10
val cleanupTimer =
context.system.scheduler.schedule(1.hour, 1.hour, self, CleanupDoneList)
def receiveCommand = {
case ChangeBudget(amount, replyTo, id) if alreadyDone(id) =>
replyTo ! ChangeBudgetDone
case ChangeBudget(amount, replyTo, id) if amount + budget > 0 =>
persist(BudgetChanged(amount, id)) { ev =>
budget += ev.amount
alreadyDone += ev.persistenceId
replyTo ! ChangeBudgetDone
}
case ChangeBudget(_, replyTo, _) =>
replyTo ! CannotChangeBudget("insufficient budget")
case CleanupDoneList =>
val journal = PersistenceQuery(context.system)
.readJournalFor[LeveldbReadJournal](LeveldbReadJournal.Identifier)
for (persistenceId <- alreadyDone) {
val stream = journal
.currentEventsByPersistenceId(persistenceId)
.map(_.event)
.collect {
case AliceConfirmedChange(_) => ChangeDone(persistenceId)
}
stream.runWith(Sink.head).pipeTo(self)
}
case ChangeDone(id) =>
persist(ChangeDone(id)) { ev =>
alreadyDone -= ev.persistenceId
}
}
def receiveRecover = {
case BudgetChanged(amount, id) =>
budget += amount
alreadyDone += id
case ChangeDone(id) =>
alreadyDone -= id
}
override def postStop(): Unit = cleanupTimer.cancel()
}
The main difference between the persistent and the transient versions of Alice lies in how you recognize commands that have already been executed. Here, you again use the uniqueness of the requesting saga’s name: in this case, you use the persistenceId that is included in the message for this purpose. Triggering the cleanup of the set of known identities by using DeathWatch is not the correct answer here, because sagas can be restarted after a crash: reception of the Terminated notification does not signal the completion of the saga but rather that its current actor ceased to exist—which might be caused by a machine failure or network outage. Instead, you use the events that the saga persists. Once per hour, Alice asks the journal for all currently stored events for all sagas it knows: every saga that has persisted an AliceConfirmedChange event clearly will not retransmit that command, so you can safely remember that this saga’s change is finished and remove its identity from the stored set.
This example uses a specific event that Alice knows Sam persists. This may be too close a coupling between the code modules of the saga and the account entity; instead it may be preferable to emit a known, well-documented event at the end of the saga’s lifecycle so that all affected components can hook their cleanup actions to that event. This minimizes the shared knowledge that the teams developing either module must have, and it simplifies writing tests that mock out the saga from the affected component’s viewpoint.
15.7.3. The pattern, revisited
The reliable execution of transactions across components and thereby across consistency boundaries requires four things:
- The requester must keep resending the request until a matching response is received.
- The requester must include identifying information with the request.
- The recipient must use the identifying information to prevent multiple executions of the same request.
- The recipient must always respond, even for retransmitted requests.
We call this the Business Handshake pattern because it is crucial that the response implies successful processing of the request. This is what enables the pattern to ensure exactly-once execution of the desired effects. It would not be enough to merely confirm the delivery of the request to the recipient; this would not allow the conclusion that the recipient also performed the requested work. The distinction is naturally clear in cases where a response carries desired information as part of the business process, but the same applies to requests that just result in a state change for the recipient and where the requester does not need any resulting values in order to continue. For this reason, reliable communication cannot be delegated to a transport mechanism or middleware software product—you must foresee the necessary confirmations on the business level in order to achieve reliable processing.
The example uses a saga as the source of the requests. This makes it necessary to track the individual identities of commands (by using the uniqueness of the saga’s identity), which presents a burden in that cleaning up the memory of what has been done can be nontrivial. If the sender and recipient of reliable communication are both long-lived, and the exchange spans a large number of messages, it is more efficient to use sequence numbers, instead. With this simplification, a single counter is sufficient within the sender and recipient to track the number of the next message (in the sender) and the youngest message’s number that has successfully been received (in the recipient). The recipient then expects the sequence number to increase monotonically and contiguously, enabling the recipient to detect missing messages and thereby maintain the correct order of processing even when messages are retransmitted out of order.
15.7.4. Applicability
The Business Handshake pattern is applicable wherever requests must be conveyed and processed reliably. In situations where commands must not be lost even across machine failures, you need to use the persistent form of the pattern; if losses due to unforeseen failures can be tolerated, you can use the nonpersistent form. It is important to note that persistent storage is a costly operation that significantly reduces the throughput between two components.
One noteworthy aspect is that this pattern can be applied between two components that are communicating via intermediaries: if handling of requests and/or responses along the path between the business handshake partners is idempotent, then the intermediaries can forgo the use of expensive persistence mechanisms and instead rely on at-least-once delivery that the exchange between the handshake partners gives them.
15.8. Summary
In this chapter, you learned the elementary building blocks for modeling information flows in Reactive systems:
- We familiarized you with the superficially trivial pattern of request and response, taking note of the benefits of complete and self-contained messages.
- We presented the Ask pattern as a shrink-wrapped request–response pair, in contrast with the performance advantages of forward message flow.
- For more-complex relations between components, we explored the Aggregator and Saga patterns. The latter provides a way to distribute systems that would otherwise be difficult to separate due to transaction boundaries.
- We added reliability to peer-to-peer communications using the Business Handshake pattern.
Many other specialized patterns are relevant to building message-driven applications. For further reading, we recommend Vaughn Vernon’s Reactive Messaging Patterns with the Actor Model (Addison-Wesley, 2015) and Enterprise Integration Patterns by Gregor Hohpe and Bobby Woolf (Addison-Wesley, 2003).