
Chapter 8. Delimited consistency
One possible definition of a distributed system is a system whose parts can fail independently.[1] Reactive design is distributed by its very nature: you want to model components that are isolated from each other and interact only via location-transparent message passing in order to create a resilient supervisor hierarchy. This means the resulting application layout will suffer the consequences of being distributed. In a stateless system, the consequences relate primarily to failure handling, and recovery is handled as described in the previous chapter. When the system has state, it is not so simple. Even when each part of the system works perfectly, time is a factor. As you learned in chapter 2, a consequence of being distributed is that strong consistency cannot be guaranteed. In this chapter, you will learn about delimited consistency, which is the next-best alternative.
A more humorous one by Leslie Lamport is as follows: “A distributed system is one in which the failure of a computer you didn’t even know existed can render your own computer unusable.” (Email message, May 28, 1987, http://research.microsoft.com/en-us/um/people/lamport/pubs/distributed-system.txt.)
This can be illustrated by the example of the mail functionality of our example Gmail application. Because the number of users is expected to be huge, you will have to split the storage of all mail across many different computers located in multiple data centers distributed across the world. Assuming that a person’s folders can be split across multiple computers, the act of moving an email from one folder to another may imply that it moves between computers. It will be either copied first to the destination and then deleted at the origin, or placed in transient storage, deleted at the origin, and then copied to the destination.
In either case, the overall count of emails for that person should stay constant throughout the process; but if you count the emails by asking the computers involved in their storage, you may see the email “in flight” and count it either twice or not at all. Ensuring that the count is consistent would entail excluding the act of counting while the transfer was in progress. The cost of strong consistency is therefore that otherwise independent components of the distributed system need to coordinate their actions by way of additional communication, which means taking more time and using more network bandwidth. This observation is not specific to the Gmail example but holds true in general for the problem of having multiple distributed parties agree on something. This is also called distributed consensus.
8.1. Encapsulated modules to the rescue
Fortunately, these consequences are not as severe as they may seem at first. Pat Helland,[2] a pioneer and long-time contributor to the research on strong consistency, argues that once a system’s scale grows to a critical size, it can no longer be strongly consistent. The cost of coordinating a single global order of all changes that occur within it would be forbiddingly high, and adding more (distributed) resources at that point will only diminish the system’s capacity instead of increasing it. Instead, we will be constructing systems from small building blocks—entities[3]—that are internally consistent but interact in an eventually consistent fashion.
See his paper “Life Beyond Distributed Transactions,” CIDR (2007), http://www.ics.uci.edu/~cs223/papers/cidr07p15.pdf.
In the context of domain-driven design, these would be called aggregate roots; the different uses of the word entity are owed to its intrinsic generality.
The dataset contained within such an entity can be treated in a fully consistent fashion, applying changes such that they occur—or at least appear to occur—in one specific order. This is possible because each entity lives within a distinct scope of serializability, which means the entity itself is not distributed and the datasets of different entities cannot overlap. The behavior of such a system is strongly consistent—transactional—only for operations that do not span multiple entities.
Helland goes on to postulate that we will develop platforms that manage the complexity of distributing and interacting with these independent entities, allowing the expression of business logic in a fashion that does not need to concern itself with the deployment details as long as it obeys the transaction bounds. The entities he talks about are very similar to the encapsulated modules developed in this book so far. The difference is mainly that he focuses on managing the data stored within a system, whereas we have concerned ourselves foremost with decomposing the functionality offered by a complex application. In the end, both are the same: as viewed by a user, the only thing that matters is that the obtained responses reflect the correct state of the service at the time of the request, where state is nothing more than the dataset the service maintains internally. A system that supports Reactive application design is therefore a natural substrate for fulfilling Pat Helland’s prediction.
8.2. Grouping data and behavior according to transaction boundaries
The example problem of storing a person’s email folders in a distributed fashion can be solved by applying the strategy outlined in the previous section. If you want to ensure that emails can be moved without leading to inconsistent counts, then each person’s complete email dataset must be managed by one entity. The example application decomposition would have a module for this purpose and would instantiate it once for every person using the system. This does not mean all mail would be literally stored within that instance. It only means all access to a person’s email content would be via this dedicated instance.
In effect, this acts like a locking mechanism that serializes access, with the obvious restriction that an individual person’s email cannot be scaled out to multiple managers in order to support higher transaction rates. This is fine, because a human is many orders of magnitude slower than a computer when it comes to processing email, so you will not run into performance problems by limiting scalability in this direction. What is more important is that this enables you to distribute the management of all users’ mailboxes across any number of machines, because each instance is independent of all others. The consequence is that it is not possible to move emails between different people’s accounts while maintaining the overall email count, but that is not a supported feature anyway.
To formalize what we just discussed, the trick is to slice the behavior and accompanying dataset in such a way that each slice offers the desired features in isolation and no transactions are necessary that span multiple slices. This technique is applied and discussed in great detail in the literature on domain-driven design (DDD).[4]
See, for example, Eric Evans, Domain-Driven Design, Addison-Wesley (2003); or Vaughn Vernon, Implementing Domain-Driven Design, Addison-Wesley (2013).
8.3. Modeling workflows across transactional boundaries
The way in which the dataset is sliced accommodates performing a certain set of operations in a strongly consistent manner but precludes this quality of behavior for all other conceivable operations. In most cases, there will be operations that are desirable but not supported. Slicing the data in another way is not an option, because that would break more important use cases. In this situation, the design must fall back to an eventually consistent way of performing those other operations, meaning that although it keeps the atomicity of the transaction, it abandons complete consistency and isolation.
To illustrate this, consider the case of moving an email from Alice’s mailbox to that of another person named Bob, possibly stored in a data center on another continent. Although this operation cannot occur such that both the source and destination mailboxes execute this operation at the same time, it can ensure that the email eventually will be present only in Bob’s mailbox. You can facilitate this by creating an instance of a module that represents the transfer procedure. This module will communicate with the mailbox instances for Alice and Bob to remove the email from one and store it in the other. This so-called Saga pattern is known in the transactional database world as a mitigation strategy for long-running transactions. It is shown in figure 8.1 and discussed in detail in chapter 14.
Figure 8.1. A sketch of the Saga pattern for moving an email from Alice’s account to Bob’s account, not including the cases for handling timeouts when communicating with the two accounts
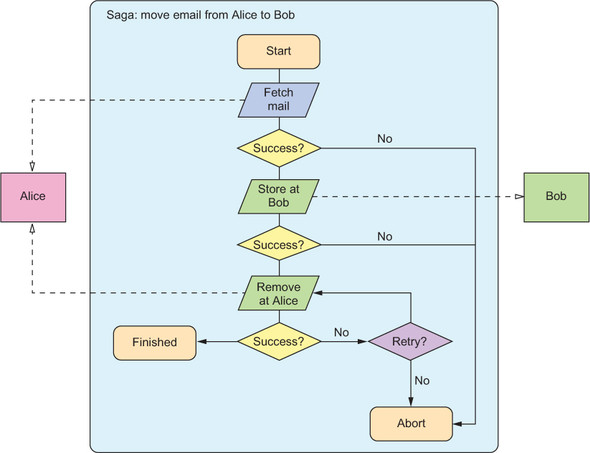
Just as the mailbox modules will persist their state to survive failures, the Saga module also can be persistent. This ensures that even if the transfer is interrupted by a service outage, it will eventually complete when the mailboxes for Alice and Bob are back online.
8.4. Unit of failure = unit of consistency
Coming back to the initial definition of a distributed system at the beginning of this chapter, distributed entities are characterized by their ability to fail independently. Therefore, the main concern of grouping data according to transactional boundaries is to ensure that everything that must be consistent is not distributed. A consistent unit must not fail partially; if one part of it fails, then the entire unit must fail.
In the example of the transfer of an email between Alice’s and Bob’s mailboxes, the Saga that performs this task is one such unit. If one part of it fails, then the whole transfer must fail; otherwise, the email could be duplicated or vanish completely. This does not preclude the different subtasks being performed by submodules of the Saga, but it requires that if one of the submodules fails, the Saga must fail as a whole.
Pat Helland’s entities and our units of consistency therefore match up with the modules of the supervisor hierarchy developed earlier in this chapter. This is another helpful property that can guide and validate the hierarchical decomposition of a system.
8.5. Segregating responsibilities
We have postulated that the process of breaking a problem into smaller pieces repeats iteratively until the remaining parts are bite-sized and can be efficiently specified, implemented, and tested. But what exactly is the right size? The criteria so far are as follows:
- A module does one job and does it well.
- The scope of a module is bounded by the responsibility of its parent.
- Module boundaries define the possible granularity of horizontal scaling by replication.
- Modules encapsulate failure, and their hierarchy defines supervision.
- The lifecycle of a module is bounded by that of its parent.
- Module boundaries coincide with transaction boundaries.
You have seen along the way that these criteria go hand in hand and are interrelated; abiding by one of them is likely to satisfy the others as well. You have a choice as to how big to make your modules. During the process of implementing and testing them—or, with experience, even during the design process—you may find that you did not choose wisely.
In the case of a too-fine-grained split, you will notice the need to use messaging patterns like Saga excessively often, or have difficulty achieving the consistency guarantees you require. The cure is relatively simple. The act of combining the responsibilities of two modules means you compose their implementations, which is unlikely to lead to new conflicts because the modules previously were completely independent and isolated from each other.
If the split is too coarse, you will suffer from complicated interplay of different concerns within a module. Supervision strategies will be difficult to identify or will inhibit necessary scalability. This defect is not as simple to repair, because separating out different parts of the behavior entails introducing new transaction boundaries between them. If the different parts become descendant modules, this may not have grave consequences because the parent module can still act as the entry point that serializes operations. If the issue that prompted the split was insufficient scalability, then this will not work because the implied synchronization cost by way of going through a single funnel was precisely the problem.
Segregating the responsibilities of such an object will necessarily require that some operations be relegated to eventually consistent behavior. One possibility that often applies is to separate the mutating operations (the commands) from the read operations (the queries). Greg Young coined the term Command and Query Responsibility Segregation (CQRS) describing this split, which allows the write side of a dataset to be scaled and optimized independently from its read side. The write side will be the only place where modifications to the data are permitted, allowing the read side to act as a proxy that only passively caches the information that can be queried.
Changes are propagated between modules by way of events, which are immutable facts that describe state changes that have already occurred. In contrast, the commands that are accepted at the write side merely express the intent that a change shall happen.
Comparing CQRS to a database view
Relational databases have the concept of a view, which is similar to the query side of CQRS. The difference lies in when the query is executed. Database implementations typically force the administrator to decide ahead of time. A traditional, pure implementation always defers execution until the data is requested, which can cause a significant performance impact on reads. In response to that, some implementations allow the result of the query to be stored physically in a snapshot. This typically moves the cost of updating the query result to the time the data is written, so the write operations are delayed until all the snapshots are also updated. CQRS sacrifices consistency guarantees in exchange for more flexibility about when the updates appear in the query results.
In the Gmail example, you might implement the module that generates the overview of all folders and their unread email counts such that it accesses the stored folder data whenever it is asked for a summary to be displayed in the user’s browser. The storage module will have to perform several functions:
- Ingest new email as it arrives from the filtering module
- List all emails in a folder
- Offer access to the raw data and metadata for individual emails
The state of an email—for example, whether it has been read or not—will reside naturally with the message itself, in the raw email object storage. One initial design may be to store the folders to which it belongs together with each message; consequently you obtain one fully consistent dataset for each user into which all emails are stored. This dataset is then queried in order to get the overview of read and unread message counts per folder. The corresponding query must traverse the metadata of all stored emails and tally them according to folder name and status.
Doing that is costly, because the most frequent operation—checking for new email—will need to touch all the metadata, including old emails that were read long ago. An additional downside is that ingesting new email will suffer from this merely observer function, because both kinds of activities typically will be executed by the storage module one after the other in order to avoid internal concurrency and thereby nondeterminism.
This design can be improved by separating the responsibilities for updating and querying the email storage, as shown in figure 8.2. Changes to the storage contents—such as the arrival of new email, adding and removing folder membership from messages, and removing the “unread” flag—are performed by the write side, which persists these changes into the binary object storage. Additionally, the write side informs the read view about relevant metadata changes so that this view can keep itself up to date about the read and unread email counts in each folder. This allows overview queries to be answered efficiently without having to traverse the metadata storage. In case of a failure, the read view can always be regenerated by performing this traversal once. The view itself does not need to be persistent.
Figure 8.2. Per-user storage segregated into command and query responsibilities. New emails are written to the storage, informing the read view about changes to the metadata. Summary queries can be answered by the read view, whereas raw email contents are retrieved directly from shared binary storage.

8.6. Persisting isolated scopes of consistency
The topic of achieving persistence in systems designed for scalability is discussed in detail in chapter 17, but the application design described in this chapter has implications for the storage layer that deserve further elaboration. In a traditional database-centric application, all data are held in a globally consistent fashion in a transactional data store. This is necessary because all parts of the application have access to the entire dataset, and transactions can span various parts of it. Effort is required to define and tune the transactions at the application level as well as to make the engine efficient at executing these complex tasks at the database level.
With encapsulated modules that each fully own their datasets, these constraints are solved during the design phase. You would need one database per module instance, and each database would support modifications only from a single client. Almost all the complexity of a traditional database would go unused with such a use case because there would be no transactions to schedule or conflicts to resolve.
Coming back to CQRS, we note that there is logically only one flow of data from the active instances to the storage engine: The application module sends information about its state changes in order to persist them. The only information it needs from the storage is confirmation of successful execution of this task, upon which the module can acknowledge reception of the data to its clients and continue processing its tasks. This reduces the storage engine’s requirements to just act as an append-only log of the changes—events—that the application modules generate. This scheme is called event sourcing because the persisted events are the source of truth from which application state can be recovered as needed.
An implementation with this focus is much simpler and more efficient than using a transactional database, because it does not need to support mutual exclusion of concurrent updates or any form of altering persisted data. In addition, streaming consecutive writes is the operation for which all current storage technologies achieve the highest possible throughput. Logging a stream of events for each module has the additional advantage that these streams contain useful information that can be consumed by other modules: for example, updating a dedicated read view onto the data or providing monitoring and alerting functionality, as discussed in chapter 17.
8.7. Summary
In this chapter, you saw that strong consistency is not achievable across a distributed system. It is limited to smaller scopes and to units that fail as a whole. This has led to adding a new facet of the component structure: the recommendation that you consider the business domain of the application in order to determine bounded contexts that are fully decoupled from each other. The terminology here is taken from domain-driven design.
The driving force behind this search for a replacement for traditional transactionality and serializability stems from the nondeterminism that is inherent in distributed systems. The next chapter places this finding into the larger context of the full range from logic programming and deterministic dataflow to full-on nondeterminism experienced with threads and locks.