
What do you do when you decide to write a program?
If you're like a lot of people, you think about the program; perhaps you and a team will write up a spec or requirements document, and then you'll get to coding. Sometimes, there will be a drawing representing some facsimile of the way the application will work.
Quite often, the best way to nail down the architecture and the inner workings of an application is to put pencil to paper and visually represent the way the program will work. For a lot of linear or serial applications, this is often an unnecessary step as things will work in a predictable fashion that should not require any specific coordination within the application logic itself (although coordinating third-party software likely benefits from specification).
You may be familiar with some logic that looks something like the following diagram:
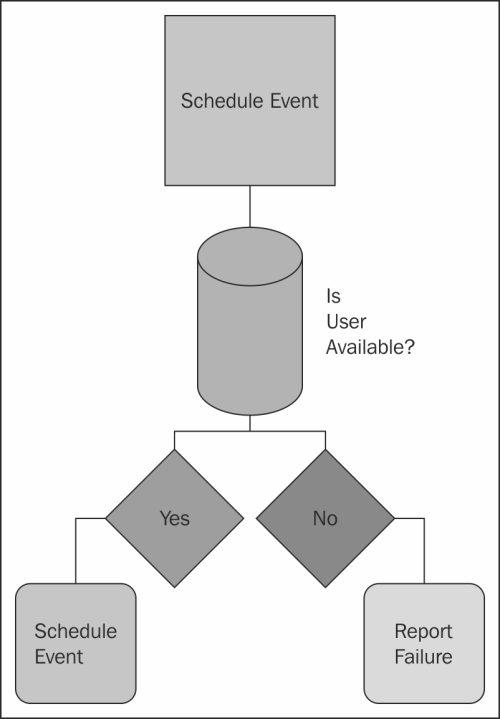
The logic here makes sense. If you remember from our Preface, when humans draw out processes, we tend to serialize them. Visually, going from step one to step two with a finite number of processes is easy to understand.
However, when designing a concurrent application, it's essential that we at least account for innumerable and concurrent requests, processes, and logic to make sure our application ends where we want, with the data and results we expect.
In the previous example, we completely ignore the possibility that "Is User Available" could fail or report old or erroneous data. Does it make more sense to address such problems if and when we find them, or should we anticipate them as part of a control flow? Adding complexity to the model can help us reduce the odds of data integrity issues down the road.
Let's visualize this again, taking into account availability pollers that will request availability for a user with any given request for a time/user pair.
As we have already discussed, we wish to create a basic blueprint of how our application should function as a starting point. Here, we'll implement some control flow, which relates to user activity, to help us decide what functionality we'll need to include. The following diagram illustrates how the control flow may look like:
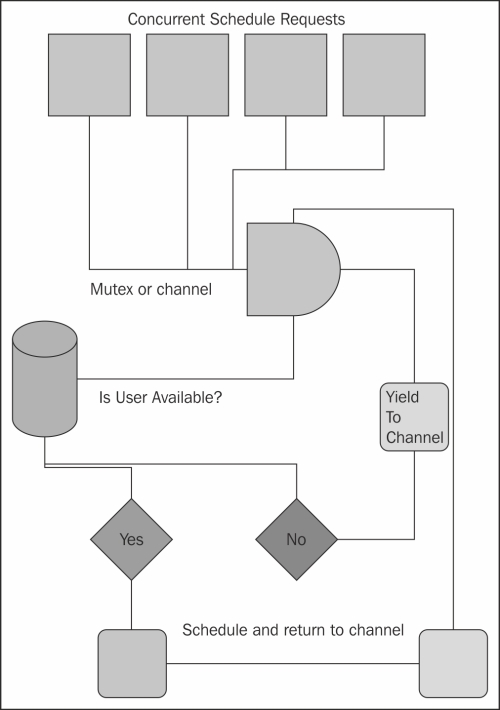
In the previous diagram, we anticipate where data can be shared using concurrent and parallel processes to locate points of failure. If we design concurrent applications in such graphical ways, we're less likely to find race conditions later on.
While we talked about how Go helps you to locate these after the application has completed running, our ideal development workflow is to attempt to cut these problems off at the start.
Now that we have an idea of how the scheduling process should work, we need to identify components that our application will need. In this case, the components are as follows:
- A web server handler
- A template for output
- A system for determining dates and times
In our visualizing concurrency example from the previous chapter, we used Go's built-in http package, and we'll do the same here. There are a number of good frameworks out there for this, but they primarily extend the core Go functionality rather than reinventing the wheel. The following are a few of these functionalities, listed from lightest to heaviest:
- Web.go: http://webgo.io/
Web.go is very lightweight and lean, and it provides some routing functionality not available in the
net/httppackage. - Gorilla: http://www.gorillatoolkit.org/
Gorilla is a Swiss army knife to augment the
net/httppackage. It's not particularly heavy, and it is fast, utilitarian, and very clean. - Revel: http://robfig.github.io/revel/
Revel is the heaviest of the three, but it focuses on a lot of intuitive code, caching, and performance. Look for it if you need something mature that will face a lot of traffic.
In Chapter 6, C10K – A Non-blocking Web Server in Go, we'll roll our own web server and framework with the sole goal of extreme high performance.
For this application, we'll partially employ the Gorilla web toolkit. Gorilla is a fairly mature web-serving platform that fulfills a few of our needs here natively, namely the ability to include regular expressions in our URL routing. (Note: Web.Go also extends some of this functionality.) Go's internal HTTP routing handler is rather simplistic; you can extend this, of course, but we'll take a shortcut down a well-worn and reliable path here.
We'll use this package solely for ease of URL routing, but the Gorilla web toolkit also includes packages to handle cookies, sessions, and request variables. We'll examine this package a little closer in Chapter 6, C10K – A Non-blocking Web Server in Go.
As Go is intended as a system language, and as system languages often deal with the creation of servers with clients, some care was put into making it a well-featured alternative to create web servers.
Anyone who's dealt with a "web language" will know that on top of that you'll need a framework, ideally one that handles the presentation layer for the web. While it's true that if you take on such a project you'll likely look for or build your own framework, Go makes the templating side of things very easy.
The template package comes in two varieties: text and http. Though they both serve different end points, the same properties—affording dynamism and flexibility—apply to the presentation layer rather than strictly the application layer.
These templating paradigms are all too common these days; if you look at the http/template package, you'll find some very strong similarities to Mustache, one of the more popular variants. While there is a Mustache port in Go, there's nothing there that isn't handled by default in the template package.
Note
For more information on Mustache, visit http://mustache.github.io/.
One potential advantage to Mustache is its availability in other languages. If you ever feel the need to port some of your application logic to another language (or existing templates into Go), utilizing Mustache could be advantageous. That said, you sacrifice a lot of the extended functionality of Go templates, namely the ability to take out Go code from your compiled package and move it directly into template control structures. While Mustache (and its variants) has control flows, they may not mirror Go's templating system. Take the following example:
<ul>
{{range .Users}}
<li>A User </li>
{{end}}
</ul>Given the familiarity with Go's logic structures, it makes sense to keep them consistent in our templating language as well.
Note
We won't show all the specific templates in this thread, but we will show the output. If you wish to peruse them, they're available at mastergoco.com/chapters/3/templates.
We're not doing a whole lot of math here; time will be broken into hour blocks and each will be set to either occupied or available. At this time, there aren't a lot of external date/time packages for Go. We're not doing any heavy-date math, but it doesn't really matter because Go's time package should suffice even if we were.
In fact, as we have literal hour blocks from 9 a.m. to 5 p.m., we just set these to the 24-hour time values of 9-17, and invoke a function to translate them into linguistic dates.
We'll want to identify the REST endpoints (via GET requests) and briefly describe how they'll work. You can think of these as modules or methods in the model-view-controller architecture. The following is a list of the endpoint patterns we'll use:
entrypoint/register/{name}: This is where we'll go to add a name to the list of users. If the user exists, it will fail.entrypoint/viewusers: Here, we'll present a list of users with their timeslots, both available and occupied.entrypoint/schedule/{name}/{time}: This will initialize an attempt to schedule an appointment.
Each will have an accompanying template that will report the status of the intended action.
We'll deal with users and responses (web pages), so we need two structs to represent each. One struct is as follows:
type User struct {
Name string
email string
times[int] bool
}The other struct is as follows:
type Page struct {
Title string
Body string
}We will keep the page as simple as possible. Rather than doing a lot of iterative loops, we will produce the HTML within the code for the most part.
Our endpoints for requests will relate to our previous architecture, using the following code:
func users(w http.ResponseWriter, r *http.Request) {
}
func register(w http.ResponseWriter, r *http.Request) {
}
func schedule(w http.ResponseWriter, r *http.Request) {
}