
Luckily, there are some non-core Go solutions and strategies that we can utilize to improve our ability to control data consistency.
Let's briefly look at a few consistency models that we can employ to manage our data in distributed systems.
On its own, a Distributed Shared Memory (DSM) system does not intrinsically prevent race conditions, as it is merely a method for more than one system to share real or partitioned memory.
In essence, you can imagine two systems with 1 GB of memory, each allocating 500 MB to a shared memory space that is accessible and writable by each. Dirty reads are possible as are race conditions unless explicitly designed. The following figure is a visual representation of how two systems can coordinate using shared memory:
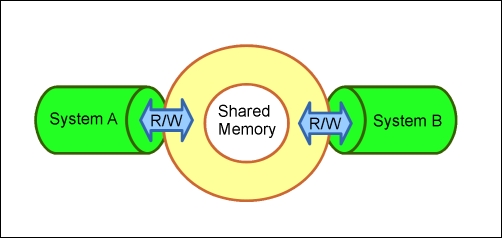
We'll look at one prolific but simple example of DSM shortly, and play with a library available to Go for test driving it.
Pipelined RAM (PRAM) consistency is a form of first-in-first-out methodology, in which data can be read in order of the queued writes. This means that writes read by any given, separate process may be different. The following figure represents this concept:
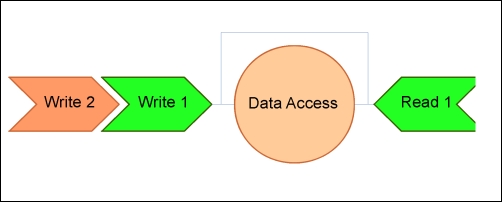
The master-slave consistency model is similar to the leader/follower model that we'll look at shortly, except that the master manages all operations on data and broadcasts rather than receiving write operations from a slave. In this case, replication is the primary method of transmission of changes to data from the master to the slave. In the following diagram, you will find a representation of the master-slave model with a master server and four slaves:
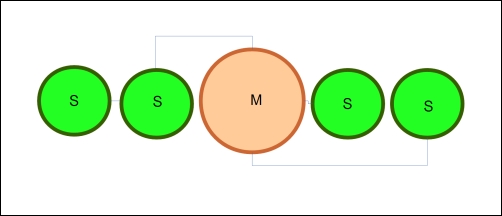
While we can simply duplicate this model in Go, we have more elegant solutions available to us.
In the classic producer-consumer problem, the producer writes chunks of data to a conduit/buffer, while a consumer reads chunks. The issue arises when the buffer is full: if the producer adds to the stack, the data read will not be what you intend. To avoid this, we employ a channel with waits and signals. This model looks a bit like the following figure:
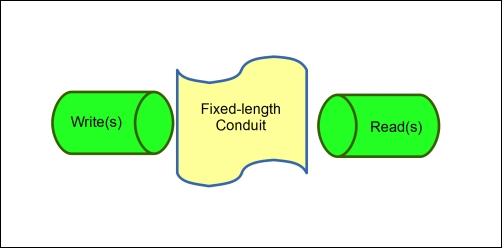
If you're looking for the semaphore implementation in Go, there is no explicit usage of the semaphore. However, think about the language here—fixed-size channels with waits and signals; sounds like a buffered channel. Indeed, by providing a buffered channel in Go, you give the conduit here an explicit length; the channel mechanism gives you the communication for waits and signals. This is incorporated in Go's concurrency model. Let's take a quick look at a producer-consumer model as shown in the following code:
package main
import(
"fmt"
)
var comm = make(chan bool)
var done = make(chan bool)
func producer() {
for i:=0; i< 10; i++ {
comm <- true
}
done <- true
}
func consumer() {
for {
communication := <-comm
fmt.Println("Communication from producer
received!",communication)
}
}
func main() {
go producer()
go consumer()
<- done
fmt.Println("All Done!")
}In the leader/follower model, writes are broadcasted from a single source to any followers. Writes can be passed through any number of followers or be restricted to a single follower. Any completed writes are then broadcasted to the followers. This can be visually represented as the following figure:
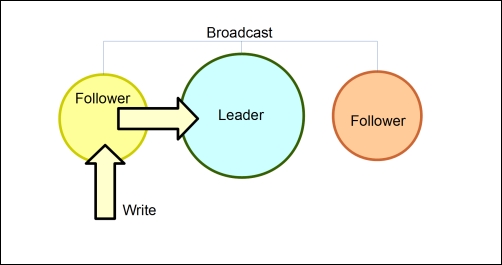
We can see a channel analog here in Go as well. We can, and have, utilized a single channel to handle broadcasts to and from other followers.
We've looked at atomic consistency quite a bit. It ensures that anything that is not created and used at essentially the same time will require serialization to guarantee the strongest form of consistency. If a value or dataset is not atomic in nature, we can always use a mutex to force linearizability on that data.
Serial or sequential consistency is inherently strong, but can also lead to performance issues and degradation of concurrency.
Atomic consistency is often considered the strongest form of ensuring consistency.
The release consistency model is a DSM variant that can delay a write's modifications until the time of first acquisition from a reader. This is known as lazy release consistency. We can visualize lazy release consistency in the following serialized model:
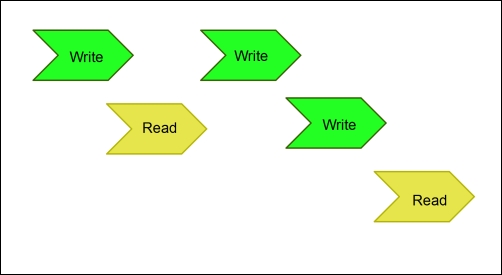
This model as well as an eager release consistency model both require an announcement of a release (as the name implies) when certain conditions are met. In the eager model, that condition requires that a write would be read by all read processes in a consistent manner.
In Go, there exists alternatives for this, but there are also packages out there if you're interested in playing with it.