
We've certainly covered a lot about concurrent and parallel Go, but one of the biggest infrastructure challenges for developers and system architects today has to do with cooperative computing.
Some of the applications and designs that we've mentioned previously scale from parallelism to distributed computing.
Memcache(d) is a form of in-memory caching, which can be used as a queue among several systems.
Our master-slave and producer-consumer models we presented in Chapter 4, Data Integrity in an Application, have more to do with distributed computing than single-machine programming in Go, which manages concurrency idiomatically. These models are typical concurrency models in many languages, but can be scaled to help us design distributed systems as well, utilizing not just many cores and vast resources but also redundancy.
The basic premise of distributed computing is to share, spread, and best absorb the various burdens of any given application across many systems. This not only improves performance on aggregate, but provides some sense of redundancy for the system itself.
This all comes at some cost though, which are as follows:
- Potential for network latency
- Creating slowdowns in communication and in application execution
- Overall increase in complexity both in design and in maintenance
- Potential for security issues at various nodes along the distributed route(s)
- Possible added cost due to bandwidth considerations
This is all to say, simply, that while building a distributed system can provide great benefits to a large-scale application that utilizes concurrency and ensures data consistency, it's by no means right for every example.
Distributed computing recognizes a slew of logical topologies for distributed design. Topology is an apt metaphor, because the positioning and logic of the systems involved can often represent physical topology.
Out of the box, not all of the accepted topologies apply to Go. When we design concurrent, distributed applications using Go, we'll generally rely on a few of the simpler designs, which are as follows.
The star topology (or at least this particular form of it), resembles our master-slave or producer-consumer models as outlined previously.
The primary method of data passing involves using the master as a message-passing conduit; in other words, all requests and commands are coordinated by a single instance, which uses some routing method to pass messages. The following diagram shows the star topology:
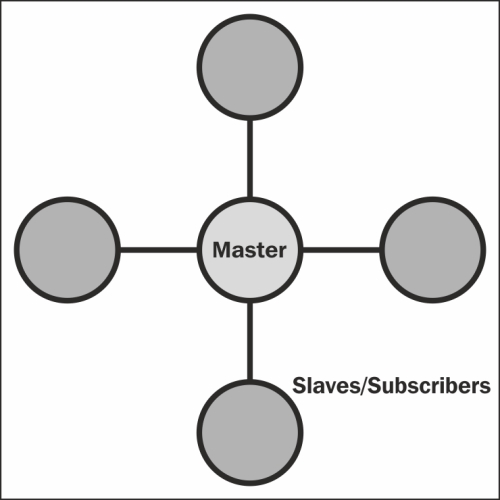
We can actually very quickly design a goroutine-based system for this. The following code is solely the master's (or distributed destination's) code and lacks any sort of security considerations, but shows how we can parlay network calls to goroutines:
package main import ( "fmt" "net" )
Our standard, basic libraries are defined as follows:
type Subscriber struct {
Address net.Addr
Connection net.Conn
do chan Task
}
type Task struct {
name string
}These are the two custom types we'll use here. A Subscriber type is any distributed helper that comes into the fray, and a Task type represents any given distributable task. We've left that undefined here because it's not the primary goal of demonstration, but you could ostensibly have Task do anything by communicating standardized commands across the TCP connection. The Subscriber type is defined as follows:
var SubscriberCount int
var Subscribers []Subscriber
var CurrentSubscriber int
var taskChannel chan Task
func (sb Subscriber) awaitTask() {
select {
case t := <-sb.do:
fmt.Println(t.name,"assigned")
}
}
func serverListen (listener net.Listener) {
for {
conn,_ := listener.Accept()
SubscriberCount++
subscriber := Subscriber{ Address: conn.RemoteAddr(),
Connection: conn }
subscriber.do = make(chan Task)
subscriber.awaitTask()
_ = append(Subscribers,subscriber)
}
}
func doTask() {
for {
select {
case task := <-taskChannel:
fmt.Println(task.name,"invoked")
Subscribers[CurrentSubscriber].do <- task
if (CurrentSubscriber+1) > SubscriberCount {
CurrentSubscriber = 0
}else {
CurrentSubscriber++
}
}
}
}
func main() {
destinationStatus := make(chan int)
SubscriberCount = 0
CurrentSubscriber = 0
taskChannel = make(chan Task)
listener, err := net.Listen("tcp", ":9000")
if err != nil {
fmt.Println ("Could not start server!",err)
}
go serverListen(listener)
go doTask()
<-destinationStatus
}This essentially treats every connection as a new Subscriber, which gets its own channel based on its index. This master server then iterates through existing Subscriber connections using the following very basic round-robin approach:
if (CurrentSubscriber+1) > SubscriberCount {
CurrentSubscriber = 0
}else {
CurrentSubscriber++
}As mentioned previously, this lacks any sort of security model, which means that any connection to port 9000 would become a Subscriber and could get network messages assigned to it (and ostensibly could invoke new messages too). But you may have noticed an even bigger omission: this distributed application doesn't do anything. Indeed, this is just a model for assignment and management of subscribers. Right now, it doesn't have any path of action, but we'll change that later in this chapter.
The mesh is very similar to the star with one major difference: each node is able to communicate not just through the master, but also directly with other nodes as well. This is also known as a complete graph. The following diagram shows a mesh topology:
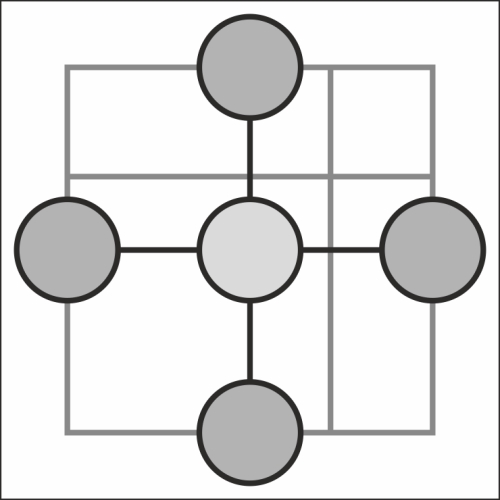
For practical purposes, the master must still handle assignments and pass connections back to the various nodes.
This is actually not particularly difficult to add through the following simple modification of our previous server code:
func serverListen (listener net.Listener) {
for {
conn,_ := listener.Accept()
SubscriberCount++
subscriber := Subscriber{ Address: conn.RemoteAddr(),
Connection: conn }
subscriber.awaitTask()
_ = append(Subscribers,subscriber)
broadcast()
}
}Then, we add the following corresponding broadcast function to share all available connections to all other connections:
func broadcast() {
for i:= range Subscribers {
for j:= range Subscribers {
Subscribers[i].Connection.Write
([]byte("Subscriber:",Subscriber[j].Address))
}
}
}In both the previous topologies, we've replicated a Publish and Subscribe model with a central/master handling delivery. Unlike in a single-system, concurrent pattern, we lack the ability to use channels directly across separate machines (unless we use something like Go's Circuit as described in Chapter 4, Data Integrity in an Application).
Without direct programmatic access to send and receive actual commands, we rely on some form of API. In the previous examples, there is no actual task being sent or executed, but how could we do this?
Obviously, to create tasks that can be formalized into non-code transmission, we'll need a form of API. We can do this one of two ways: serialization of commands, ideally via JSONDirect transmission, and execution of code.
As we'll always be dealing with compiled code, the serialization of commands option might seem like you couldn't include Go code itself. This isn't exactly true, but passing full code in any language is fairly high on lists of security concerns.
But let's look at two ways of sending data via API in a task by removing a URL from a slice of URLs for retrieval. We'll first need to initialize that array in our main function as shown in the following code:
type URL struct {
URI string
Status int
Assigned Subscriber
SubscriberID int
}Every URL in our array will include the URI, its status, and the subscriber address to which it's been assigned. We'll formalize the status points as 0 for unassigned, 1 for assigned and waiting, and 2 for assigned and complete.
Remember our CurrentSubscriber iterator? That represents the next-in-line round robin assignment which will fulfill the SubscriberID value for our URL struct.
Next, we'll create an arbitrary array of URLs that will represent our overall job here. Some suspension of incredulity may be necessary to assume that the retrieval of four URLs should require any distributed system; in reality, this would introduce significant slowdown by virtue of network transmission. We've handled this in a purely single-system, concurrent application before:
URLs = []URL{ {Status:0,URL:"http://golang.org/"},
{Status:0,URL:"http://play.golang.org/"},
{Status:0,URL:"http://golang.org/doc/"},
{Status:0,URL:"http://blog.golang.org/"} }In our first option in the API, we'll send and receive serialized data in JSON. Our master will be responsible for formalizing its command and associated data. In this case, we'll want to transmit a few things: what to do (in this case, retrieve) with the relevant data, what the response should be when it is complete, and how to address errors.
We can represent this in a custom struct as follows:
type Assignment struct {
command string
data string
successResponse string
errorResponse string
}
...
asmnt := Assignment{command:"process",
url:"http://www.golang.org",successResponse:"success",
errorResponse:"error"}
json, _ := json.Marshal(asmnt )
send(string(json))The remote code execution option is not necessarily separate from serialization of commands, but instead of structured and interpreted formatted responses, the payload could be code that will be run via a system command.
As an example, code from any language could be passed through the network and executed from a shell or from a syscall library in another language, like the following Python example:
from subprocess import call call([remoteCode])
The disadvantages to this approach are many: it introduces serious security issues and makes error detection within your client nearly impossible.
The advantages are you do not need to come up with a specific format and interpreter for responses as well as potential speed improvements. You can also offload the response code to another external process in any number of languages.
In most cases, serialization of commands is far preferable over the remote code execution option.
There exist quite a few topology types that are more complicated to manage as part of a messaging queue.
The following diagram shows the bus topology:
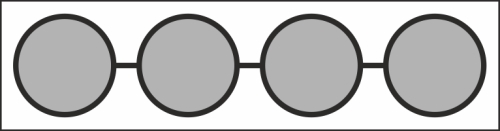
The bus topology network is a unidirectional transmission system. For our purposes, it's neither particularly useful nor easily managed, as each added node needs to announce its availability, accept listener responsibility, and be ready to cede that responsibility when a new node joins.
The advantage of a bus is quick scalability. This comes with serious disadvantages though: lack of redundancy and single point of failure.
Even with a more complex topology, there will always be some issue with potentially losing a valuable cog in the system; at this level of modular redundancy, some additional steps will be necessary to have an always-available system, including automatic double or triple node replication and failovers. That's a bit more than we'll get into here, but it's important to note that the risk will be there in any event, although it would be a little more vulnerable with a topology like the bus.
The following diagram shows the ring topology:
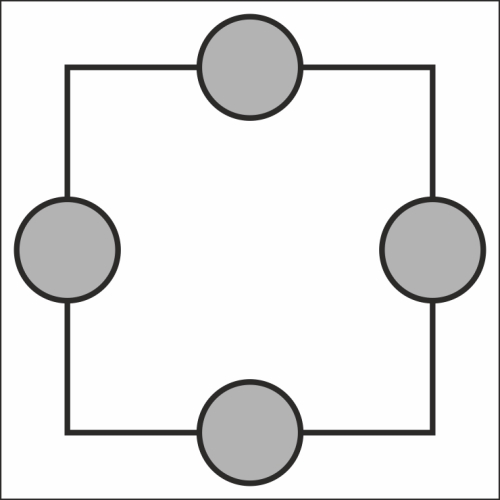
The ring topology looks similar to our mesh topology, but lacks a master. It essentially requires the same communication process (announce and listen) as does a bus. Note one significant difference: instead of a single listener, communication can happen between any node without the master.
This simply means that all nodes must both listen and announce their presence to other nodes.
There exists a slightly more formalized version of what we built previously, called Message Passing Interface. MPI was borne from early 1990s academia as a standard for distributed communication.
Originally written with FORTRAN and C in mind, it is still a protocol, so it's largely language agnostic.
MPI allows the management of topology above and beyond the basic topologies we were able to build for a resource management system, including not only the line and ring but also the common bus topology.
For the most part, MPI is used by the scientific community; it is a highly concurrent and analogous method for building large-scale distributed systems. Point-to-point operations are more rigorously defined with error handling, retries, and dynamic spawning of processes all built in.
Our previous basic examples lend no prioritization to processors, for example, and this is a core effect of MPI.
There is no official implementation of MPI for Go, but as there exists one for both C and C++, it's entirely possible to interface with it through that.
Note
There is also a simple and incomplete binding written in Go by Marcus Thierfelder that you can experiment with. It is available at https://github.com/marcusthierfelder/mpi.
You can read more about and install OpenMPI from http://www.open-mpi.org/.
Also you can read more about MPI and MPICH implementations at http://www.mpich.org/.