
One of the biggest concessions with using NoSQL is, obviously, the lack of standardization when it comes to CRUD operations (create, read, update, and delete). SQL has been standardized since 1986 and is pretty airtight across a number of databases—from MySQL to SQL Server and from Microsoft and Oracle all the way down to PostgreSQL.
Note
You can read more about NoSQL and various NoSQL platforms at http://nosql-database.org/.
Martin Fowler has also written a popular introduction to the concept and some use cases in his book NoSQL Distilled at http://martinfowler.com/books/nosql.html.
Depending on the NoSQL platform, you can also lose ACID compliance and durability. This means that your data is not 100 percent secure—there can be transactional loss if a server crashes, if reads happen on outdated or non-existent data, and so on. The latter of which is known as a dirty read.
This is all noteworthy as it applies to our application and with concurrency specifically because we've talked about one of those big potential third-party bottlenecks in the previous chapters.
For our file-sharing application in Go, we will utilize NoSQL to store metadata about files as well as the users that modify/interact with those files.
We have quite a few options when it comes to a NoSQL data store to use here, and almost all of the big ones have a library or interface in Go. While we're going to go with Couchbase here, we'll briefly talk about some of the other big players in the game as well as the merits of each.
The code snippets in the following sections should also give you some idea of how to switch out Couchbase for any of the others without too much angst. While we don't go deeply into any of them, the code for maintaining the file and modifying information will be as generic as possible to ensure easy exchange.
MongoDB is one of the most popular NoSQL platforms available. Written in 2009, it's also one of the most mature platforms, but comes with a number of tradeoffs that have pushed it somewhat out of favor in the recent years.
Even so, Mongo does what it does in a reliable fashion and with a great deal of speed. Utilizing indices, as is the case with most databases and data stores, improves query speed on reads greatly.
Mongo also allows for some very granular control of guarantees as they apply to reads, writes, and consistency. You can think of this as a very vague analog to any language and/or engine that supports syntactical dirty reads.
Most importantly, Mongo supports concurrency easily within Go and is implicitly designed to work in distributed systems.
Note
The biggest Go interface for Mongo is mgo, which is available at: http://godoc.org/labix.org/v2/mgo.
Should you wish to experiment with Mongo in Go, it's a relatively straightforward process to take your data store record and inject it into a custom struct. The following is a quick and dirty example:
import
(
"labix.org/v2/mgo"
"labix.org/v2/mgo/bson"
)
type User struct {
name string
}
func main() {
servers, err := mgo.Dial("localhost")
defer servers.Close()
data := servers.DB("test").C("users")
result := User{}
err = c.Find(bson.M{"name": "John"}).One(&result)
}One downside to Mongo compared to other NoSQL solutions is that it does not come with any GUI by default. This means we either need to tie in another application or web service, or stick to the command line to manage its data store. For many applications, this isn't a big deal, but we want to keep this project as compartmentalized and provincial as possible to limit points of failure.
Mongo has also gotten a bit of a bad rap as it pertains to fault tolerance and data loss, but this is equally true of many NoSQL solutions. In addition, it's in many ways a feature of a fast data store—so often catastrophe recovery comes at the expense of speed and performance.
It's also fair to say this is a generally overblown critique of Mongo and its peers. Can something bad happen with Mongo? Sure. Can it also happen with a managed Oracle-based system? Absolutely. Mitigating massive failures in this realm is more the responsibility of a systems administrator than the software itself, which can only provide the tools necessary to design such a contingency plan.
All that said, we'll want something with a quick and highly-available management interface, so Mongo is out for our requirements but could easily be plugged into this solution if those are less highly valued.
Redis is another key/value data store and, as of recently, took the number one spot in terms of total usage and popularity. In an ideal Redis world, an entire dataset is held in memory. Given the size of many datasets, this isn't always possible; however, coupled with Redis' ability to eschew durability, this can result in some very high performance results when used in concurrent applications.
Another useful feature of Redis is the fact that it can inherently hold different data structures. While you can make abstractions of such data by unmarshalling JSON objects/arrays in Mongo (and other data stores), Redis can handle sets, strings, arrays, and hashes.
There are two major accepted libraries for Redis in Go:
- Radix: This is a minimalist client that's barebones, quick, and dirty. To install Radix, run the following command:
go get github.com/fzzy/radix/redis - Redigo: This more robust and a bit more complex, but provides a lot of the more intricate functionality that we'll probably not need for this project. To install Redigo, run the following command:
go get github.com/garyburd/redigo/redis
We'll now see a quick example of getting a user's name from the data store of Users in Redis using Redigo:
package main
import
(
"fmt"
"github.com/garyburd/redigo/redis"
)
func main() {
connection,_ := dial()
defer connection.Close()
data, err := redis.Values(connection.Do("SORT", "Users", "BY", "User:*->name",
"GET", "User:*->name"))
if (err) {
fmt.Println("Error getting values", err)
}
for i:= range data {
var Uname string
data,err := redis.Scan(data, &Uname)
if (err) {
fmt.Println("Error getting value",err)
}else {
fmt.Println("Name Uname")
}
}
}Looking over this, you might note some non programmatic access syntax, such as the following:
data, err := redis.Values(connection.Do("SORT", "Users", "BY", "User:*->name",
"GET", "User:*->name"))This is indeed one of the reasons why Redis in Go will not be our choice for this project—both libraries here provide an almost API-level access to certain features with some more detailed built-ins for direct interaction. The Do command passes straight queries directly to Redis, which is fine if you need to use the library, but a somewhat inelegant solution across the board.
Both the libraries play very nicely with the concurrent features of Go, and you'll have no problem making non-blocking networked calls to Redis through either of them.
It's worth noting that Redis only supports an experimental build for Windows, so this is mostly for use on *nix platforms. The port that does exist comes from Microsoft and can be found at https://github.com/MSOpenTech/redis.
If you've worked a lot with NoSQL, then the preceding engines all likely seemed very familiar to you. Redis, Couch, Mongo, and so on are all virtual stalwarts in what is a relatively young technology.
Tiedot, on the other hand, probably isn't as familiar. We're including it here only because the document store itself is written in Go directly. Document manipulation is handled primarily through a web interface, and it's a JSON document store like several other NoSQL solutions.
As document access and handling is governed via HTTP, there's a somewhat counterintuitive workflow, shown as follows:
As that introduces a potential spot for latency or failure, this keeps from being an ideal solution for our application here. Keep in mind that this is also a feature of a few of the other solutions mentioned earlier, but since Tiedot is written in Go, it would be significantly easier to connect to it and read/modify data using a package. While this book was being written, this did not exist.
Unlike other HTTP- or REST-focused alternatives such as CouchDB, Tiedot relies on URL endpoints to dictate actions, not HTTP methods.
You can see in the following code how we might handle something like this through standard libraries:
package main
import
(
"fmt"
"json"
"http"
)
type Collection struct {
Name string
}This, simply, is a data structure for any record you wish to bring into your Go application via data selects, queries, and so on. You saw this in our previous usage of SQL servers themselves, and this is not any different:
func main() {
Col := Collection{
Name: ''
}
data, err := http.Get("http://localhost:8080/all")
if (err != nil) {
fmt.Println("Error accessing tiedot")
}
collections,_ = json.Unmarshal(data,&Col)
}While not as robust, powerful, or scalable as many of its peers, Tiedot is certainly worth playing with or, better yet, contributing to.
Note
You can find Tiedot at https://github.com/HouzuoGuo/tiedot.
CouchDB from Apache Incubator is another one of the big boys in NoSQL big data. As a JSON document store, CouchDB offers a great deal of flexibility when it comes to your data store approach.
CouchDB supports ACID semantics and can do so concurrently, which provides a great deal of performance benefit if one is bound to those properties. In our application, that reliance on ACID consistency is somewhat flexible. By design, it will be failure tolerant and recoverable, but for many, even the possibility of data loss with recoverability is still considered catastrophic.
Interfacing with CouchDB happens via HTTP, which means there is no need for a direct implementation or Go SQL database hook to use it. Interestingly, CouchDB uses HTTP header syntax to manipulate data, as follows:
These are, of course, what the header methods were initially intended in HTTP 1.1, but so much of the Web has focused on GET/POST that these tend to get lost in the fray.
Couch also comes with a convenient web interface for management. When CouchDB is running, you're able to access this at http://localhost:5984/_utils/, as shown in the following screenshot:
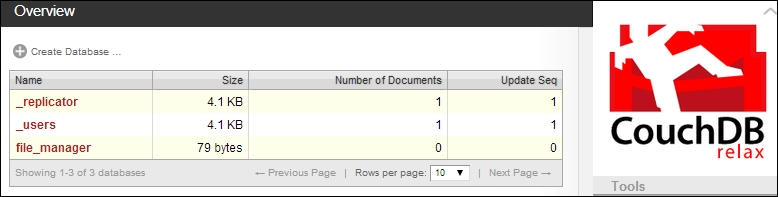
That said, there are a few wrappers that provide a level of abstraction for some of the more complicated and advanced features.
Cassandra, another Apache Foundation project, isn't technically a NoSQL solution but a clustered (or cluster-able) database management platform.
Like many NoSQL applications, there is a limitation in the traditional query methods in Cassandra, for example, subqueries and joins are generally not supported.
We're mentioning it here primarily because of its focus on distributed computing as well as the ability to programmatically tune whether data consistency or performance is more important. Much of that is equally expressed in our solution, Couchbase, but Cassandra has a deeper focus on distributed data stores.
Cassandra does, however, support a subset of SQL that will make it far more familiar to developers who have dabbled in MySQL, PostgreSQL, or the ilk. Cassandra's built-in handling of highly concurrent integrations makes it in many ways ideal for Go, although it is an overkill for this project.
The most noteworthy library to interface with Cassandra is gocql, which focuses on speed and a clean connection to the Cassandra connection. Should you choose to use Cassandra in lieu of Couchbase (or other NoSQL), you'll find a lot of the methods that can be simply replaced.
The following is an example of connecting to a cluster and writing a simple query:
package main
import
(
"github.com/gocql/gocql"
"log"
)
func main() {
cass := gocql.NewCluster("127.0.0.1")
cass.Keyspace = "filemaster"
cass.Consistency = gocql.LocalQuorum
session, _ := cass.CreateSession()
defer session.Close()
var fileTime int;
if err := session.Query(`SELECT file_modified_time FROM filemaster
WHERE filename = ? LIMIT 1`, "test.txt").Consistency(gocql.One).Scan(&fileTime); err != nil {
log.Fatal(err)
}
fmt.Println("Last modified",fileTime)
}Cassandra may be an ideal solution if you plan on rapidly scaling this application, distributing it widely, or are far more comfortable with SQL than data store / JSON access.
For our purposes here, SQL is not a requirement and we value speed over anything else, including durability.
Couchbase is a relative newcomer in the field, but it was built by people from both CouchDB and memcached. Written in Erlang, it shares many of the same focuses on concurrency, speed, and non-blocking behavior that we've come to expect from a great deal of our Go applications.
Couchbase also supports a lot of the other features we've discussed in the previous chapters, including easy distribution-based installations, tuneable ACID compliance, and low-resource consumption.
One caveat on Couchbase is it doesn't run well (or at all) on some lower-resourced machines or VMs. Indeed, 64-bit installations require an absolute minimum of 4 GB of memory and four cores, so forget about launching this on tiny, small, or even medium-grade instances or older hardware.
While most NoSQL solutions presented here (or elsewhere) offer performance benefits over their SQL counterparts in general, Couchbase has done very well against its peers in the NoSQL realm itself.
Couchbase, such as CouchDB, comes with a web-based graphical interface that simplifies the process of both setup and maintenance. Among the advanced features that you'll have available to you in the setup include your base bucket storage engine (Couchbase or memcached), your automated backup process (replicas), and the level of read-write concurrency.
In addition to configuration and management tools, it also presents some real-time monitoring in the web dashboard as shown in the following screenshot:
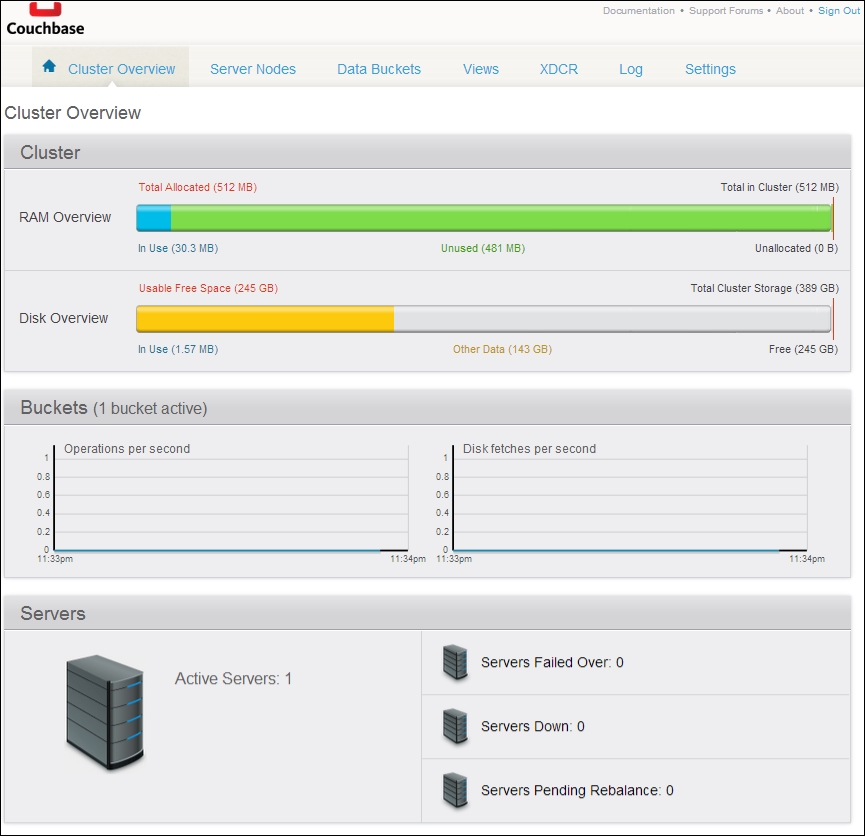
While not a replacement for full-scale server management (what happens when this server goes down and you have no insight), it's incredibly helpful to know exactly where your resources are going without needing a command-line method or an external tool.
The vernacular in Couchbase varies slightly, as it tends to in many of these solutions. The nascent desire to slightly separate NoSQL from stodgy old SQL solutions will pop its head from time to time.
With Couchbase, a database is a data bucket and records are documents. However, views, an old transactional SQL standby, bring a bit of familiarity to the table. The big takeaway here is views allow you to create more complex queries using simple JavaScript, in some cases, replicating otherwise difficult features such as joins, unions, and pagination.
Each view created in Couchbase becomes an HTTP access point. So a view that you name select_all_files will be accessible via a URL such as http://localhost:8092/file_manager/_design/select_all_files/_view/Select%20All%20Files?connection_timeout=60000&limit=10&skip=0.
The most noteworthy Couchbase interface library is Go Couchbase, which, if nothing else, might save you from some of the redundancy of making HTTP calls in your code to access CouchDB.
Note
Go Couchbase can be found at https://github.com/couchbaselabs/go-couchbase.
Go Couchbase makes interfacing with Couchbase through a Go abstraction simple and powerful. The following code connects and grabs information about the various data pools in a lean way that feels native:
package main
import
(
"fmt"
"github.com/couchbaselabs/go-couchbase"
)
func main() {
conn, err := couchbase.Connect("http://localhost:8091")
if err != nil {
fmt.Println("Error:",err)
}
for _, pn := range conn.Info.Pools {
fmt.Printf("Found pool: %s -> %s
", pn.Name, pn.URI)
}
}After installing Couchbase, you can access its administration panel by default at localhost and port 8091.
You'll be given an opportunity to set up an administrator, other IPs to connect (if you're joining a cluster), and general data store design.
After that, you'll need to set up a bucket, which is what we'll use to store all information about individual files. Here is what the interface for the bucket setup looks like:
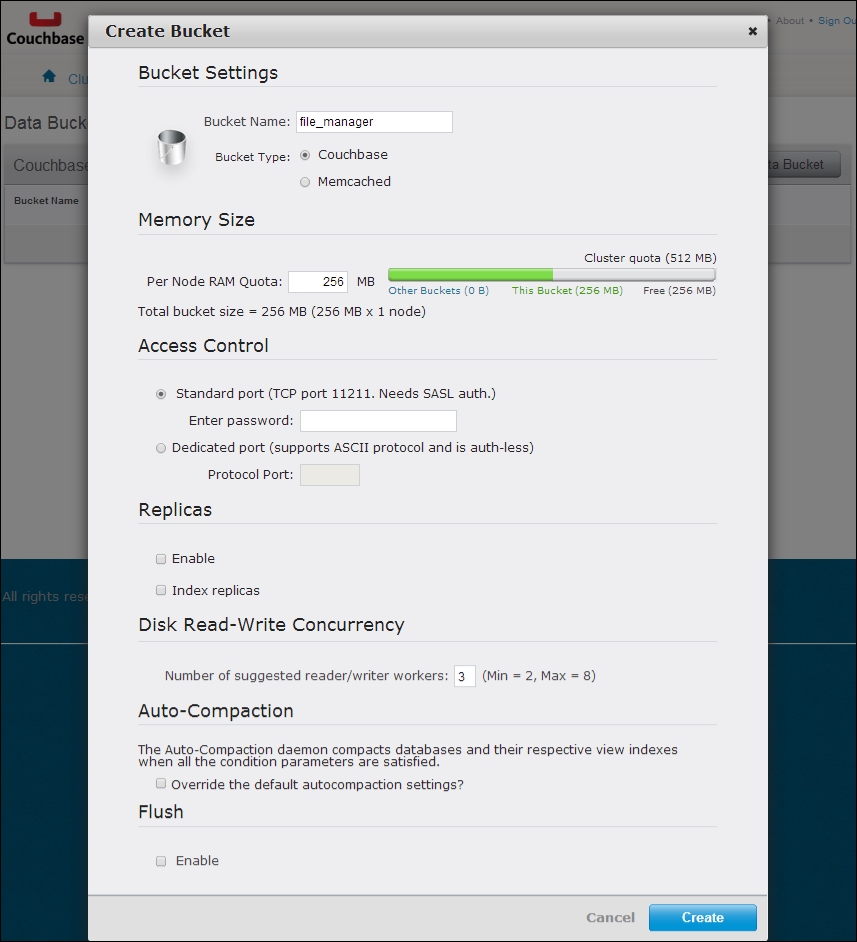
In our example, we're working on a single machine, so replicas (also known as replication in database vernacular) are not supported. We've named it file_manager, but this can obviously be called anything that makes sense.
We're also keeping our data usage pretty low—there's no need for much more than 256 MB of memory when we're storing file operations and logging older ones. In other words, we're not necessarily concerned with keeping the modification history of test.txt in memory forever.
We'll also stick with Couchbase for a storage engine equivalent, although you can flip back and forth with memcache(d) without much noticeable change.
Let's start by creating a seed document: one we'll delete later, but that will represent the schema of our data store. We can create this document with an arbitrary JSON structured object, as shown in the following screenshot:
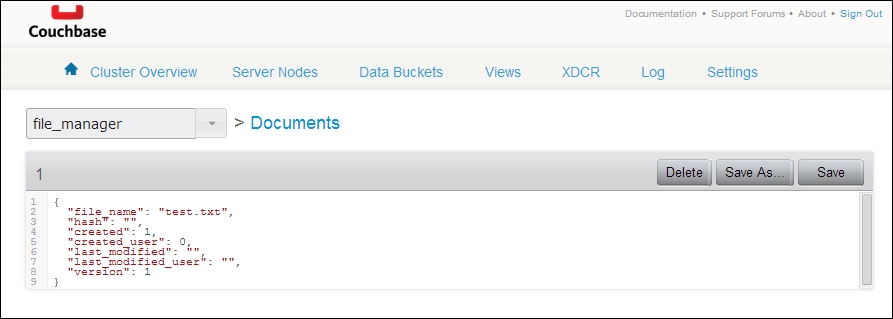
Since everything stored in this data store should be valid JSON, we can mix and match strings, integers, bools, arrays, and objects. This affords us some flexibility in what data we're using. The following is an example document:
{
"file_name": "test.txt",
"hash": "",
"created": 1,
"created_user": 0,
"last_modified": "",
"last_modified_user": "",
"revisions": [],
"version": 1
}