
Until now, we have been more focused about the search and data analytics capabilities of Elasticsearch. Now is the time to learn about taking Elasticsearch clusters in production while focusing on best practices.
In this chapter, we will cover the following topics:
- Node types in Elasticsearch
- Introducing Zen-Discovery
- Best Elasticsearch practices in production
- Cluster creation
- Scaling your clusters
In Elasticsearch, you can configure three types of nodes, as shown in the following cluster:
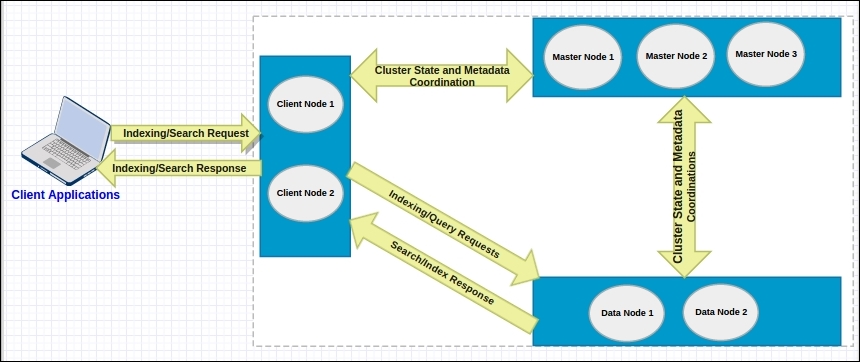
In the preceding cluster diagram, there are two client nodes, three master nodes, and two data nodes. Let's understand how these node types differ in Elasticsearch and how to configure them.
A client node in Elasticsearch acts as a query router and a load balancer. It does not hold any data. A client node can be used to query as well as index processes. It takes queries and distributes the search to data nodes. Once the data nodes return their respective results, the client node combines all the data to give the final results. Similarly, when you send the data to a client node for indexing, it calculates the sharding key for each document and sends the documents for the respective shards.
A client node can be configured by adding the following lines to the elasticsearch.yml file:
node.data: falsenode.master: false
A data node in the Elasticsearch is responsible for holding the data, merging segments, and executing queries. Data nodes are the real work horses of your cluster and need a higher configuration than any other type of node in the cluster.
A data node can be configured by adding the following lines to the elasticsearch.yml file:
node.data: truenode.master: false
A master node is responsible for the management of the complete cluster. It holds the states of all the nodes and periodically distributes the cluster state to all the other nodes in the cluster to make them aware of any new node that has joined the cluster and which nodes have left. A master node periodically sends a ping to all the other nodes to see whether they are alive (other nodes also send pings to the master node). The final major task of the master node is configuration management. It holds the complete meta-data and the mapping of all the indexes in the cluster. If a master leaves, a new master node is chosen from the rest of the master-eligible nodes. If there is no master-eligible node left, the cluster cannot operate at all.
A master node can be configured by adding the following lines to the elasticsearch.yml file.