
Cython programs look quite similar to Python ones, mostly with added type information. Let's have a look at a simple program that computes the n
th Fibonacci number given n:
defcompute_fibonacchi(n):
"""
Computes fibonacchi sequence
"""
a = 1
b = 1
intermediate = 0
for x in xrange(n):
intermediate = a
a = a + b
b = intermediate
return a
Let's study this program to understand what is going on under the hood when you call this function with some numeric output; let's say compute_fibonacchi(3).
As we know, Python is an interpreted and dynamic language, which means you do not need to declare variables before using them. This means that, at the start of a function call, the Python interpreter is agnostic about the type of value that n will hold. When you call the function with some integral value, Python does the type inference automatically for you by a procedure called boxing and unboxing.
In Python, everything is an object. So when you type, say, 1 or hello, the Python interpreter will internally convert it into objects. This process is also referred to as boxing in a lot of online material. The process could be visualized as:

So what happens when you apply functions to objects? The Python interpreter has to do some extra work to infer the type and apply the functions. In a general sense, the following diagram explains the application of the add function in Python. Python being an interpreted language, it does not do a great job in optimizing the function calls, but they can be optimized quite nicely with C or Cython:
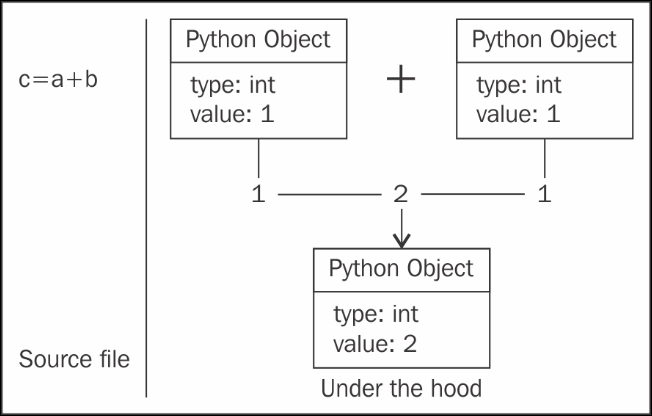
This boxing and unboxing does not come free and takes valuable computing time. The effect becomes more significant when such an operation is performed multiple times in loops.
The following program takes around 1.8 micro seconds per loop on my IPython notebook when run for n = 20:

Now let's rewrite this program into Cython:
defcompute_fibonacchi_cython(int n):
cdefint a, b, intermediate, x
a, b= 1, 1
intermediate, x = 0, 0
for x in xrange(n):
intermediate = a
a = a+b
b = intermediate
return a
This program takes 64.5 nanoseconds per loop:

Tip
Although the speed boost is quite significant in this example code, this is not real-world code that you will encounter, so you should always remember to first run a profiler on the code and identify the sections that require optimization. Also while using Cython, the developer should consider the tradeoff between using static types and flexibility. Using types can cut down flexibility and sometimes readability.
This code could be further improved by removing xrange and using a for loop instead. Once you are satisfied that all the components/functions of the module are properly working and bug-free, the user can store these functions/procedures in a file with a .pyx extension. This is the extension used by Cython. The next step towards integrating this code with your application is to add the information in your setup file.
Here, for illustration purposes, we have stored the code in a file called fib.pyx and created a setup file that builds this module:
from distutils.core import setup, Extension
from Cython.Build import cythonize
from Cython.Distutils import build_ext
setup(
ext_modules=[Extension('first', ['first.pyx'])],
cmdclass={'build_ext': build_ext}
)
Here, note that the name of the extension first exactly matches the name of the module. If you fail to maintain the same name, then you will get a cryptic error:
