
SQL Azure provides a relational database technology to the Windows Azure platform. However, sometimes the data becomes so vast that it could not be handled using a relational database. Even sometimes, the data that needs to be analyzed is not relational at all. Hadoop is a new technology that has been introduced recently to help in analyzing Big Data problems.
Hadoop is an Apache-based open source project. This technology stores data in Hadoop Distributed File System (HDFS) and then lets the developers create MapReduce jobs to analyze that data. The main advantages of a Hadoop filesystem is that it stores data in multiple servers, and then allows to run chunks of MapReduce jobs, letting Big Data be processed in parallel.
HDInsight is the name of the Windows Azure Apache Hadoop-based service. HDInsight lets HDFS to store data in clusters and distribute it across multiple virtual machines. It also spreads the MapReduce job across VMs. HDInsight uses Windows Azure Storage Vault to store data in Blobs. The use of ASV allows you to save money, as you can delete your HDInsight cluster when not in use and still have data in the cloud in the form of Blob storage.
To get ready to use HDInsight, let's understand a few basic concepts:
- Pig: This is a high-level platform for processing data in Hadoop clusters. Pig consists of a data-flow language called Pig Latin, which supports queries over large datasets. The Pig Latin program consists of a dataset transformation series that is converted to a MapReduce program series under the covers.
- Hive: This is a Hadoop query engine built for data warehouse summarization queries. Hive is used for analysis and gives a SQL-like interface and a relational data model. Hive uses a language called HiveQL, a dialect for SQL. Just like Pig, Hive is also an abstraction on top of MapReduce.
- Sqoop: This transfers data from Hadoop to relational, structured data storages such as SQL as efficiently as possible.
To run this sample, you need to install Azure PowerShell as well.
Now let's try to see how you can leverage the Azure portal to create a Hadoop job to count the number of occurrences of the words with parallel nodes running on files:
- Open the Windows Azure management portal and create a storage account. Take a note of the credentials to access it.
- Create an HDInsight data service with four nodes and a password to access the service. You also need to specify a storage account information that you have just created.
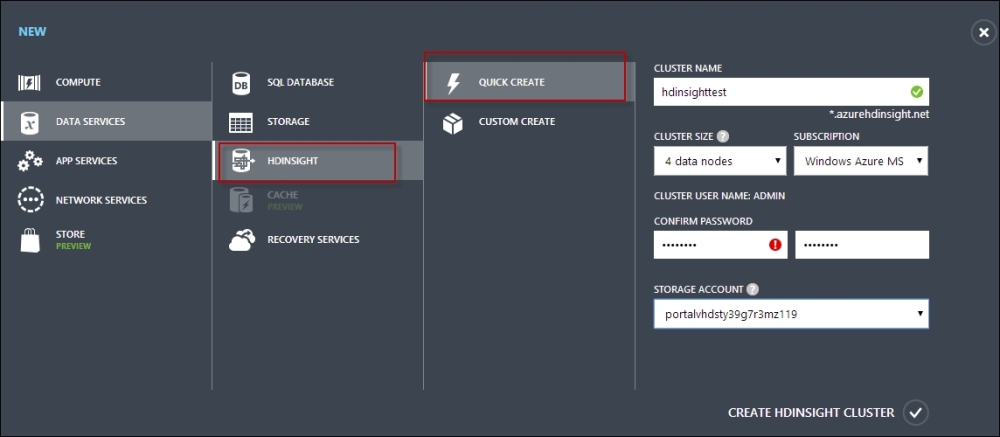
- This will create an HDInsight node with four clusters. The storage account once selected cannot be changed later, and if the storage account is removed, the clusters would no longer be available for use.
- Once the HDInsight nodes are created, it will be time to run some sample code to demonstrate MapReduce algorithms. Let's try to run the MapReduce job on
WordCount. - Open Windows Azure PowerShell and run the following command:
$subscriptionName = "<YourSubscriptionName>" $clusterName = "<YourHDInsightClusterName>"
- The following command creates a MapReduce job description. The
hadoop-examples.jarfile comes with an HDInsight cluster distribution and can be used for testing MapReduce on the clusters:$wordCountJobDefinition = New-AzureHDInsightMapReduceJobDefinition -JarFile "wasb:///example/jars/hadoop-examples.jar" -ClassName "wordcount" -Arguments "wasb:///example/data/gutenberg/davinci.txt", "wasb:///example/data/WordCountOutput" - Once the MapReduce job is created from the
hadoop-examples.jarfile, you can start running the job. To submit the job, run the following command:Select-AzureSubscription $subscriptionName $wordCountJob = Start-AzureHDInsightJob -Cluster $clusterName -JobDefinition $wordCountJobDefinition
Here, you can see that in addition to
SubscriptionName, you also need to pass inClusternamewhere the MapReduce operation needs to run. - You can ask the portal to check the completion of a MapReduce job using the
Wait-AzureHDInsightJobcommand, as follows:Wait-AzureHDInsightJob -Job $wordCountJob -WaitTimeoutInSeconds 3600This command will wait with a timeout of 60 minutes. To see the job output, you can use the following command:
Get-AzureHDInsightJobOutput -Cluster $clusterName -JobId $wordCountJob.JobId –StandardError - When the job is finished, Windows Azure stores the result in the Blob storage. So, to retrieve the storage, you need a container name for the reference. Let's create another variable for
$containerName. - We run the following command to create the Windows Azure context object:
Select-AzureSubscription $subscriptionName $storageAccountKey = Get-AzureStorageKey $storageAccountName | %{ $_.Primary } $storageContext = New-AzureStorageContext –StorageAccountName $storageAccountName –StorageAccountKey $storageAccountKey
The
Select-AzureSubscriptioncommand is used to set the default subscription for the entire command. - Once the context is set up, you can download the job result from the Blob storage. We can use
Get-AzureStorageBlobContentand pass in the container name to get the Blob content, as follows:Get-AzureStorageBlobContent -Container $ContainerName -Blob example/data/WordCountOutput/part-r-00000 -Context $storageContext -ForceThe default filename for the MapReduce job is
part-r-00000, and in this example, the file gets downloaded to thec:exampledataWordCountOutputfolder. - Finally, to print the MapReduce job, you can run the following command in the PowerShell window:
cat ./example/data/WordCountOutput/part-r-00000 | findstr "there"The preceding command will list all the words that have the word
therein it with the count of number of occurrences of each word.
Hadoop is a technology that allows you to process Big Data into multiple machines simultaneously and thereby solve the problem of Big Data. The Hadoop for WordCount parses the document in parts in different clusters and provides a key value collection where the key specifies the word and the value specifies the total number of occurrences.
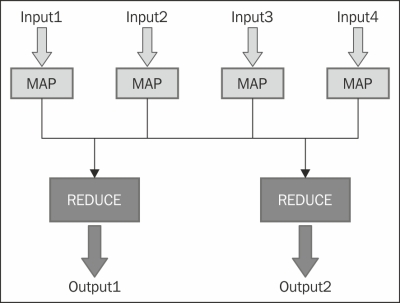
In the preceding diagram, you can see the input divided into four parts, and each of them is sent to an individual cluster to invoke mapping. Following the WordCount example, the mapper takes each line from the input text and breaks it into words; it then breaks each word into a KeyValue pair and follows it up by 1. The reducer then sums up the individual counters for each word and emits a single KeyValue pair containing the word, followed by the sum of occurrences.
Let's see what the WordCount Java code looks like:
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer st = new StringTokenizer(value.toString());
while (st.hasMoreTokens()) {
word.set(st.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount argument mismatch");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}In the preceding code, you can see that there are two methods: one is map and another is reduce. The map method breaks each word into a set and initializes the output with 1, while the reduce method sums up all the similar words and increases the counter. From the Main page, the job is created and the classes are set. Finally, the job result is sent to the output path.
The New-AzureHDInsightMapReduceJobDefinition method takes a classname and runs the class from the .jar file with the arguments specified:
$wordCountJobDefinition = New-AzureHDInsightMapReduceJobDefinition -JarFile "wasb:///example/jars/hadoop-examples.jar" -ClassName "wordcount" -Arguments "wasb:///example/data/gutenberg/davinci.txt", "wasb:///example/data/WordCountOutput"
The preceding code calls the WordCount class with the argument davinci.txt and the output file to be written to WordCountOutput.
- Refer to the HDInsight tutorials at http://bit.ly/hdinsightch7