
Appendix B. Lucene index format
In this book we’ve treated the Lucene index more or less as a black box and have concerned ourselves only with its logical view. Although you don’t need to understand index structure details in order to use Lucene, you may be curious about the “magic.” Lucene’s index structure is a case study in itself of highly efficient data structures to maximize performance and minimize resource usage. You may see it as a purely technical achievement, or you can view it as a masterful work of art. There’s something innately beautiful about representing rich structure in the most efficient manner possible. (Consider the information represented by fractal formulas or DNA as nature’s proof.)
In this appendix, we’ll first review the logical view of a Lucene index, where we’ve fed documents into Lucene and retrieved them during searches. Then, we’ll expose the inner structure of Lucene’s inverted index.
B.1. Logical index view
Let’s first take a step back and start with a review of what you already know about Lucene’s index. Consider figure B.1. From the perspective of a software developer using Lucene’s API, an index can be considered a black box represented by the abstract Directory class. When indexing, you create instances of the Lucene Document class and populate it with Fields that consist of name and value pairs. The Document is then indexed by passing it to IndexWriter.addDocument(Document). When searching, you again use the abstract Directory class to represent the index. You pass that Directory to the IndexSearcher class and then find Documents that match a given query by passing search terms encapsulated in the Query object to one of IndexSearcher’s search methods. The results are matching Documents represented by the ScoreDoc object.
Figure B.1. The logical, black-box view of a Lucene index
B.2. About index structure
When we described Lucene’s Directory class in section 1.5.2, we pointed out that one of its concrete subclasses, SimpleFSDirectory, stores the index in a file system directory. We’ve also used Indexer, a program for indexing text files, shown in listing 1.1. Recall that we specified several arguments when we invoked Indexer from the command line and that one of those arguments was the directory in which we wanted Indexer to create a Lucene index. What does that directory look like once Indexer is done running? What does it contain? In this section, we’ll peek into a Lucene index and explain its structure.
Before we start, you should know that the index file format often changes between releases. It’s free to change without breaking backward compatibility because the classes that access the index can detect when they’re interacting with an older format index and act accordingly. The current format is always documented with each release, for example here, for the 3.0.1 release:
http://lucene.apache.org/java/3_0_1/fileformats.html
Lucene supports two index structures: multifile and compound. Multifile indexes use quite a few files to represent the index, whereas compound indexes use a special file, much like an archive such as a zip file, to hold multiple index files in a single file. Let’s look at each type of index structure, starting with multifile.
B.2.1. Understanding the multifile index structure
If you look at the index directory created by our Indexer, you’ll see a number of files whose names may seem random at first. These are index files, and they look similar to those shown here:
-rw-rw-rw- 1 mike users 12327579 Feb 29 05:29 _2.fdt -rw-rw-rw- 1 mike users 6400 Feb 29 05:29 _2.fdx -rw-rw-rw- 1 mike users 33 Feb 29 05:29 _2.fnm -rw-rw-rw- 1 mike users 1036074 Feb 29 05:29 _2.frq -rw-rw-rw- 1 mike users 2404 Feb 29 05:29 _2.nrm -rw-rw-rw- 1 mike users 2128366 Feb 29 05:29 _2.prx -rw-rw-rw- 1 mike users 14055 Feb 29 05:29 _2.tii -rw-rw-rw- 1 mike users 1034353 Feb 29 05:29 _2.tis -rw-rw-rw- 1 mike users 5829 Feb 29 05:29 _2.tvd -rw-rw-rw- 1 mike users 10227627 Feb 29 05:29 _2.tvf -rw-rw-rw- 1 mike users 12804 Feb 29 05:29 _2.tvx -rw-rw-rw- 1 mike users 20 Feb 29 05:29 segments.gen -rw-rw-rw- 1 mike users 53 Feb 29 05:29 segments_3
Notice that some files share the same prefix. In this example index, most of the files start with the prefix _2, followed by various extensions. This leads us to the notion of segments.
Index Segments
A Lucene index consists of one or more segments, and each segment is made up of several index files. Index files that belong to the same segment share a common prefix and differ in the suffix. In the previous example index, the index consisted of a single segment whose files started with _2.
The following example shows an index with two segments, _0 and _1:
-rw-rw-rw- 1 mike users 7743790 Feb 29 05:28 _0.fdt -rw-rw-rw- 1 mike users 3200 Feb 29 05:28 _0.fdx -rw-rw-rw- 1 mike users 33 Feb 29 05:28 _0.fnm -rw-rw-rw- 1 mike users 602012 Feb 29 05:28 _0.frq -rw-rw-rw- 1 mike users 1204 Feb 29 05:28 _0.nrm -rw-rw-rw- 1 mike users 1337462 Feb 29 05:28 _0.prx -rw-rw-rw- 1 mike users 10094 Feb 29 05:28 _0.tii -rw-rw-rw- 1 mike users 737331 Feb 29 05:28 _0.tis -rw-rw-rw- 1 mike users 2949 Feb 29 05:28 _0.tvd -rw-rw-rw- 1 mike users 6294227 Feb 29 05:28 _0.tvf -rw-rw-rw- 1 mike users 6404 Feb 29 05:28 _0.tvx -rw-rw-rw- 1 mike users 4583789 Feb 29 05:28 _1.fdt -rw-rw-rw- 1 mike users 3200 Feb 29 05:28 _1.fdx -rw-rw-rw- 1 mike users 33 Feb 29 05:28 _1.fnm -rw-rw-rw- 1 mike users 405527 Feb 29 05:28 _1.frq -rw-rw-rw- 1 mike users 1204 Feb 29 05:28 _1.nrm -rw-rw-rw- 1 mike users 790904 Feb 29 05:28 _1.prx -rw-rw-rw- 1 mike users 7499 Feb 29 05:28 _1.tii -rw-rw-rw- 1 mike users 548646 Feb 29 05:28 _1.tis -rw-rw-rw- 1 mike users 2884 Feb 29 05:28 _1.tvd -rw-rw-rw- 1 mike users 3933404 Feb 29 05:28 _1.tvf -rw-rw-rw- 1 mike users 6404 Feb 29 05:28 _1.tvx -rw-rw-rw- 1 mike users 20 Feb 29 05:28 segments.gen -rw-rw-rw- 1 mike users 78 Feb 29 05:28 segments_3
You can think of a segment as a subindex, although each segment isn’t a fully independent index.
As you’ll see in the next section, each segment contains one or more Lucene Documents, the same ones we add to the index with the addDocument(Document) method in the IndexWriter class. By now you may be wondering what function segments serve in a Lucene index; what follows is the answer to that question.
Incremental Indexing
Using segments lets you quickly add new Documents to the index by adding them to newly created index segments and only periodically merging them with other, existing segments. This process makes additions efficient because it minimizes physical index modifications. Figure B.2 shows an index that holds 24 Documents. This figure shows an unoptimized index—it contains multiple segments. If this index were to be optimized using the default Lucene indexing parameters, all 24 of its documents would be merged into a single segment.
Figure B.2. Unoptimized index with three segments, holding 24 documents
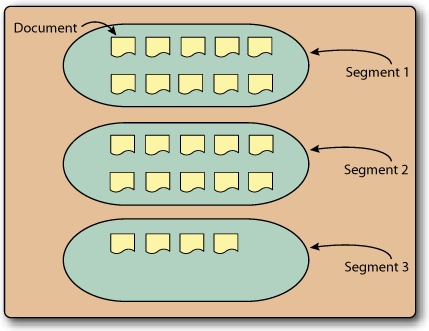
One of Lucene’s strengths is that it supports incremental indexing, which isn’t something every IR library is capable of. Whereas some IR libraries need to reindex the whole corpus when new data is added, Lucene doesn’t. After a document has been added to an index, its content is immediately made searchable. In IR terminology, this important feature is called incremental indexing. The fact that Lucene supports incremental indexing makes Lucene suitable for environments that deal with large bodies of information where complete reindexing would be unacceptable.
Because new segments are created as new Documents are indexed, the number of segments, and hence index files, varies while indexing is in progress. Once an index is fully built, the number of index files and segments remains steady.
A Closer Look at Index Files
Each index file carries a certain type of information essential to Lucene. If any index file is modified or removed by anything other than Lucene itself, the index becomes corrupted, and the only option is to run the CheckIndex tool (described in section 11.5.2) or perform a complete reindexing of the original data. On the other hand, you can add random files to a Lucene index directory without corrupting the index. For instance, if we add a file called random.txt to the index directory, as shown here, Lucene ignores that file, and the index doesn’t become corrupted:
-rw-rw-rw- 1 mike users 12327579 Feb 29 05:29 _2.fdt -rw-rw-rw- 1 mike users 6400 Feb 29 05:29 _2.fdx -rw-rw-rw- 1 mike users 33 Feb 29 05:29 _2.fnm -rw-rw-rw- 1 mike users 1036074 Feb 29 05:29 _2.frq -rw-rw-rw- 1 mike users 2404 Feb 29 05:29 _2.nrm -rw-rw-rw- 1 mike users 2128366 Feb 29 05:29 _2.prx -rw-rw-rw- 1 mike users 14055 Feb 29 05:29 _2.tii -rw-rw-rw- 1 mike users 1034353 Feb 29 05:29 _2.tis -rw-rw-rw- 1 mike users 5829 Feb 29 05:29 _2.tvd -rw-rw-rw- 1 mike users 10227627 Feb 29 05:29 _2.tvf -rw-rw-rw- 1 mike users 12804 Feb 29 05:29 _2.tvx -rw-rw-rw- 1 mike users 17 Mar 30 03:34 random.txt -rw-rw-rw- 1 mike users 20 Feb 29 05:29 segments.gen -rw-rw-rw- 1 mike users 53 Feb 29 05:29 segments_3
The secret to this is the segments file (segments_3). As you may have guessed from its name, the segments file stores the name and certain details of all existing index segments. Every time an IndexWriter commits a change to the index, the generation (the _3 in the previous code snippet) of the segments file is incremented. For example, a commit to this index would write segments_4 and remove segments_3 as well as any now unreferenced files. Before accessing any files in the index directory, Lucene consults this file to figure out which index files to open and read. Our example index has a single segment, _2, whose name is stored in this segments file, so Lucene knows to look only for files with the _2 prefix. Lucene also limits itself to files with known extensions, such as .fdt, .fdx, and other extensions shown in our example, so even saving a file with a segment prefix, such as _2.txt, won’t throw Lucene off. Of course, polluting an index directory with non-Lucene files is strongly discouraged.
The exact number of files that constitute a Lucene index and each segment varies from index to index and depends how the fields were index (for example, indexing term vectors adds three files per segment). But every index contains one segments file per commit and a single segments.gen file. The segments.gen file is always 20 bytes and contains the suffix (generation) of the current segments as a redundant way for Lucene to determine the most recent commit.
Creating a Multifile Index
By now you should have a good grasp of the multifile index structure; but how do you use the API to instruct Lucene to create a multifile index and not the default compound-file index? Here’s the answer:
IndexWriter writer = new IndexWriter(indexDir, new StandardAnalyzer(Version.LUCENE_30), true, IndexWriter.MaxFieldLength.UNLIMITED); writer.setUseCompoundFile(false);
Because the compound-file index structure is the default, we disable it and switch to a multifile index by calling setUseCompoundFile(false) on an IndexWriter instance.
B.2.2. Understanding the compound index structure
A multifile index stores many separate files per segment. Furthermore, because new segments are created whenever documents are added to the index, there will be a variable and possibly large number of files in an index directory. Although the multifile index structure is straightforward and works for most scenarios, it can result in too many open files when an index has many segments, or when many indexes are open within a single JVM. Section 11.3.2 provides more details on understanding Lucene’s use of file descriptors.
Modern OSs limit the number of files in the system, and per process, that can be opened at one time. Recall that Lucene creates new segments as new documents are added, and every so often it merges them to reduce the number of index files. But while the merge procedure is executing, the number of index files temporarily increases. If Lucene is used in an environment with lots of indexes that are being searched or indexed simultaneously, it’s possible to hit the limit of open files set by the OS. This can also happen with a single Lucene index if the index isn’t optimized or if other applications are running simultaneously and keeping many files open. Lucene’s use of open file handles depends on the structure and state of an index. Section 11.3.2 describes approaches to control the number of open files.
Compound Index Files
The only visible difference between the compound and multifile indexes is the contents of an index directory. Here’s an example of a compound index:
-rw-rw-rw- 1 mike users 12441314 Mar 30 04:27 _2.cfs -rw-rw-rw- 1 mike users 15 Mar 30 04:27 segments_4 -rw-rw-rw- 1 mike users 20 Mar 30 04:27 segments.gen
Instead of having to open and read 13 files from the index, as in the multifile index, Lucene must open only three files when accessing this compound index, thereby consuming fewer system resources. The compound index reduces the number of index files, but the concept of segments, documents, fields, and terms still applies. The difference is that a compound index contains a single .cfs file per segment, whereas each segment in a multifile index consists of seven different files. The compound structure encapsulates individual index files in a single .cfs file.
Creating a Compound Index
Because the compound index structure is the default, you don’t have to do anything to specify it. But if you like explicit code, you can call the setUseCompoundFile(boolean) method, passing in true:
IndexWriter writer = new IndexWriter(indexDir, new StandardAnalyzer(Version.LUCENE_30), true, IndexWriter.MaxFieldLength.UNLIMITED); writer.setUseCompoundFile(true);
You aren’t locked into the multifile or compound format. After indexing, you can still switch from one format to another, although this will only affect newly written segments. But there is a trick!
B.2.3. Converting from one index structure to the other
It’s important to note that you can switch between the two described index structures at any point during indexing. All you have to do is call the IndexWriter’s setUseCompoundFiles(boolean) method at any time during indexing; the next time Lucene merges index segments, it will write the new segment in the format you specified.
Similarly, you can convert the structure of an existing index without adding more documents. For example, you may have a multifile index that you want to convert to a compound one, to reduce the number of open files used by Lucene. To do so, open your index with IndexWriter, specify the compound structure, optimize the index, and close it:
IndexWriter writer = new IndexWriter(indexDir, new StandardAnalyzer(Version.LUCENE_30), IndexWriter.MaxFieldLength.UNLIMITED); writer.setUseCompoundFile(true); writer.optimize(); writer.close();
We discussed optimizing indexes in section 2.9. Optimizing forces Lucene to merge index segments, thereby giving it a chance to write them in a new format specified via the setUseCompoundFile(boolean) method.
B.3. Inverted index
Lucene uses a well-known index structure called an inverted index. Quite simply, and probably unsurprisingly, an inverted index is an inside-out arrangement of documents in which terms take center stage. Each term refers to the documents that contain it. Let’s dissect our sample book data index to get a deeper glimpse at the files in an index Directory.
Regardless of whether you’re working with a RAMDirectory, an FSDirectory, or any other Directory implementation, the internal structure is a group of files. In a RAMDirectory, the files are virtual and live entirely within RAM. FSDirectory literally represents an index as a file system directory, as described earlier in this appendix.
The compound file mode adds an additional twist regarding the files in a Directory. When an IndexWriter is set for compound file mode, the “files” are written to a single .cfs file, which alleviates the common issue of running out of file handles. See section B.2.2 for more information on the compound file mode.
Our summary glosses over most of the intricacies of data compression used in the actual data representations. This extrapolation is helpful in giving you a feel for the structure instead of getting caught up in the minutiae (which, again, are detailed on the Lucene website).
Figure B.3 represents a slice of our sample book index. The slice is of a single segment (in this case, we had an optimized index with only a single segment). A segment is given a unique filename prefix (_c in this case).
Figure B.3. Detailed look inside the Lucene index format

The following sections describe each of the files shown in figure B.3 in more detail.
Field Names (.FNM)
The .fnm file contains all the field names used by documents in the associated segment. Each field is flagged to indicate options that were used while indexing:
The order of the field names in the .fnm file is determined during indexing and isn’t necessarily alphabetical. Each field is assigned a unique integer, the field number, according to the order in this file. That field number, instead of the string name, is used in other Lucene files to save space.
Term Dictionary (.TIS, .TII)
All terms (tuples of field name and value) in a segment are stored in the .tis file. Terms are ordered first alphabetically, according to the UTF 16 Java character, by field name and then by value within a field. Each term entry contains its document frequency: the number of documents that contain this term within the segment.
Figure B.3 shows only a sampling of the terms in our index, one or more from each field. Not shown is the .tii file, which is a cross-section of the .tis file designed to be kept in physical memory for random access to the .tis file. For each term in the .tis file, the .frq file contains entries for each document containing the term.
In our sample index, two books have the value “junit” in the contents field: JUnit in Action, Second Edition (document ID 6), and Ant in Action (document ID 5).
Term Frequencies
Term frequencies in each document are listed in the .frq file. In our sample index, Ant in Action (document ID 5) has the value junit once in the contents field. JUnit in Action, Second Edition has the value junit twice, provided once by the title field and once by the subject field. Our contents field is an aggregation of title, subject, and author. The frequency of a term in a document factors into the score calculation (see section 3.3) and typically boosts a document’s relevance for higher frequencies.
For each document listed in the .frq file, the positions (.prx) file contains entries for each occurrence of the term within a document.
Term Positions
The .prx file lists the position of each term within a document. The position information is used when queries demand it, such as phrase queries and span queries. Position information for tokenized fields comes directly from the token position increments designated during analysis. This file also contains the payloads, if any.
Figure B.3 shows three positions, for each occurrence of the term junit. The first occurrence is in document 5 (Ant in Action) in position 9. In the case of document 5, the field value (after analysis) is ant action apache jakarta ant build tool java development junit erik hatcher steve loughran. We used the StandardAnalyzer; thus stop words (in in Ant in Action, for example) are removed. Document 6, JUnit in Action, Second Edition, has a contents field containing the value junit twice, once in position 1 and again in position 3: junit action junit unit testing mock objects vincent massol ted husted.[1]
1 We’re indebted to Luke, the fantastic index inspector, for allowing us to easily gather some of the data provided about the index structure.
Stored Fields
When you request that a field be stored (Field.Store.YES), it’s written into two files: the .fdx file and the .fdt file. The .fdx file contains simple index information, which is used to resolve document number to exact position in the .fdt file for that document’s stored fields. The .fdt file contains the contents of the fields that were stored.
Term Vectors
Term vectors are stored in three files. The .tvf file is the largest and stores the specific terms, sorted alphabetically, and their frequencies, plus the optional offsets and positions for the terms. The .tvd file lists which fields had term vectors for a given document and indexes byte offsets into the .tvf file so specific fields can be retrieved. Finally, the .tvx file has index information, which resolves document numbers into the byte positions in the .tvf and .tvd files.
Norms
The .nrm file contains normalization factors that represent the boost information gathered during indexing. Each document has one byte in this file, which encodes the combination of the document’s boost, that field’s boost, and a normalization factor based on the overall length of the content in that field. Section 2.5.3 describes norms in more detail.
Deletions
If any deletions have been committed to the index against documents contained in the segment, there will be a .del file present, named _X_N.del, where X is the name of the segment and N is an integer that increments every time new deletes are committed. This file contains a bit vector that’s set for any deleted documents.
B.4. Summary
The rationale for the index structure is twofold: maximum performance and minimum resource utilization. For example, if a field isn’t indexed it’s a quick operation to dismiss it entirely from queries based on the indexed flag of the .fnm file. The .tii file, cached in RAM, allows for rapid random access into the term dictionary .tis file. Phrase and span queries need not look for positional information if the term itself isn’t present. Streamlining the information most often needed, and minimizing the number of file accesses during searches is of critical concern. These are just some examples of how well thought out the index structure design is. If this sort of low-level optimization is of interest, refer to the Lucene index file format details on the Lucene website, where you’ll find details we’ve glossed over here.