
Chapter 10. Using Lucene from other programming languages
- Accessing Lucene from other programming languages
- Different styles of ports
- Comparing ports’ APIs, features, and performance
Today, Lucene is the de facto standard open source IR library. Although Java is certainly a popular programming language, not everyone uses it. Many people prefer dynamic languages (such as Python, Ruby, Perl, or PHP). What do you do if you love Lucene but not Java? Fear not: you’re in good company! Luckily, a number of options are available for accessing Lucene functionality from different programming languages, and we discuss them in this chapter.
Before we get started, let’s discuss what we mean by the word port, as we’re definitely taking liberty in broadening its usual meaning. We use the word port to mean any software that makes it possible to access Lucene’s functionality from programming languages other than Java. Although port traditionally means a complete translation of the source code from one programming language to another, for this chapter we’ve been forced to modernize this definition. Many creative ways now exist for interacting with software from alternative programming languages. We’ll first detail the four types of ports, and then we’ll step through the popular Lucene ports we’re aware of, in order by port type. In each case, we’ll show which programming language(s) the port enables, and briefly describe the history, status, and trade-offs of that port. Please keep in mind that each port is an independent project with its own mailing lists, documentation, tutorials, user, and developer community that will be able to provide more detailed information.
10.1. Ports primer
Table 10.1 lists the different types of ports we’ll see in this chapter.
Table 10.1. Types of Lucene ports
|
Port type |
Description |
Ports |
Pros |
Cons |
|---|---|---|---|---|
| Native port | All of Lucene’s sources are ported to the target environment. | Lucene.Net CLucene KinoSearch Ferret Lucy Zend Framework | Lightweight runtime. Direct access to full native environment. | Port is costly, so high release delay. Possibly higher chance of bugs. May be less compatible with Lucene Java (depends on port). |
| Reverse native port | The target language runs on a JVM. | Jython, JRuby | Lightweight runtime. 100% compatibility with Lucene. | Target language may lose some features, such as native extensions. |
| Local wrapper | A JVM is embedded into the native language’s runtime, and a wrapper is used to expose Lucene’s API. | PyLucene | Port is fast, so lower release delay, because only Lucene’s APIs need to be exposed. 100% compatibility with Lucene. | Heavier, because two runtime environments are running side by side. |
| Client-server | A separate process, perhaps on a separate machine, runs Lucene Java and exposes a standard protocol for access. Clients in the target language are then created. | Solr + clients PHP Bridge Beagle | Clients are very fast to build. Solr provides functionality beyond Lucene and is actively developed. 100% compatibility with Lucene. | Much heavier weight since you now have a whole server to manage. |
A native port translates all of Lucene’s sources into the target run time environment. This port type matches the traditional definition of the word port. Lucene.Net, which rewrites all of Lucene in C#, is a good example. Another example is KinoSearch, which provides Lucene-like functionality with a C core and Perl bindings. Because C or C++ is the accepted extensions language for many dynamic languages, such as Perl and Python, we count this as a native port. A native port can be a loose port, which means it doesn’t precisely match all APIs of Lucene but retains the same general approach.
A reverse native port is the mirror image of a native port: the target runtime environment has been ported to run on a JVM. You write programs in your target language, such as Ruby, but the environment that runs your programs runs on a JVM and therefore has full access to any Java APIs, including Lucene. JRuby and Jython are good examples of this type of port. Such projects have nothing to do with Lucene; they simply enable access to any Java libraries from the target language, so none of the particular projects we discuss here are reverse native ports.
The local wrapper port runs a JVM under the hood, side by side with the “normal” runtime for the target language, and then only the APIs that need exposing are wrapped to the target environment. PyLucene is a good example.
In the client-server port, Lucene is running in a separate process, perhaps on another computer, and is accessible using a standard network-based protocol. The server could be just the JVM, as is the case with the PHP Bridge, or it may be a full server like Solr, which implements an XML over HTTP API for accessing Lucene and provides additional functionality beyond Lucene such as distributed search and faceted navigation. Clients are then developed, in multiple programming languages, to interact with the server over the network, using the target language.
Numerous differences exist between these types of ports, which we delve into next.
10.1.1. Trade-offs
Each type of port has important trade-offs, also summarized in table 10.1. The native port has the advantage of running only code for the target environment, within a single process. It’s perhaps the cleanest, technically, and most lightweight approach, because a single runtime environment is running all code. But the downside is the cost of maintaining this port as Lucene’s sources improve with time, which means longer release delay, higher chances that the port will differ from Lucene in API and index file format, and a higher risk that the project will be abandoned, as the efforts to continuously port source changes are significant. The native port is also likely to have substantially different performance characteristics, depending on whether the target environment is faster or slower than the JVM.
The reverse native port is a compelling option, assuming the runtime environment itself doesn’t have problems running the target language. By using JRuby, you write Ruby code that has access to any Java code, but will generally lose access to Ruby extensions that are implemented in C. This option is also lightweight at runtime, because it runs in a single process and with a single (JVM) runtime environment.
The wrapper port is similarly a single process, but it embeds a JVM (to run the compiled Java bytecode from Lucene) as well as running the target environment’s runtime, side by side, so it’s somewhat heavier weight. The important trade-off is that much less work is required to stay current with Lucene’s releases: only the API changes need to be ported, and not Lucene’s entire implementation, so the work is in proportion to the net API “surface area” and the release delay can be much less. With PyLucene in particular, which autogenerates the wrapper code using the Java C Compiler (JCC), the delay is essentially zero because the computer does all the work! If only other wrappers could use JCC.
Finally, the client-server port is the most strongly decoupled. Because a separate server runs and exposes Lucene’s APIs via a standard network protocol, you can now share this server among multiple clients, possibly with different programming languages. But one potential downside is you now must manage a new standalone process or server, entirely different from your main application.
10.1.2. Choosing the right port
Having so many different types of ports may seem daunting at first, but in reality this gives a lot of flexibility to people who create the ports, which in turn gives you more options to choose from. If your application is already server-centric, and you’re in love with PHP, then the client-server model (Solr as server and SolrPHP as client) is a no-brainer. In fact, server-based applications often require a client-server search architecture so that multiple front-end computers can share access to the search server(s). At the other end of the spectrum, if you’re coding up a C++ desktop application and you can’t afford a separate server, let alone a separate process, choose a native port like CLucene.
Ports have a tendency to come and go. Often it’s one person driving the port, and if that person loses interest or can’t afford the ongoing time, the port slowly dies. New ports, with new approaches, may surface and attract more interest. This is the natural evolution in the open source world. Although we do our best to describe the popular Lucene’s ports, today, likely by the time you read this there will be other compelling options. We also mention briefly some other Lucene ports that aren’t popular enough to merit full coverage. Be sure to do your due diligence, by searching the web and asking questions on users lists, before making your final decision.
Although each port tries to remain in sync with the latest Lucene version, they all necessarily lag behind Lucene’s releases. Furthermore, most of the ports are relatively young, and from what we could gather, there’s little developer community overlap. Each port takes some and omits some of the concepts from Lucene, but they all mimic its architecture. Each port has its own website, mailing lists, and everything else that typically goes along with open source projects. Each port also has its own group of founders and developers. There’s also little communication between the ports’ developers and Lucene’s developers, although we’re all aware of each project’s existence.
With this said, let’s look at each port, starting with CLucene.
10.2. CLucene (C++)
Contributed by BEN VAN KLINKEN and ITAMAR SYN-HERSHKO
CLucene is an open source native port of Lucene to C++, created by Ben van Klinken in 2003. Since then, many other developers have contributed to the project. The library’s API and index file format are guaranteed to match those of the Java Lucene version it is based on. Table 10.2 shows its current status.
Table 10.2. CLucene summary
|
Port feature |
Port status |
|---|---|
| Port type | Native port |
| Programming languages | C++ |
| Website | http://clucene.sourceforge.net/ |
| Development status | Stable |
| Activity | Active development, active users |
| Last stable release | 0.9.21b |
| Matching Lucene release | 1.9.1 |
| Compatible index format | Yes, 1.9.1 |
| Compatible APIs | Yes |
| License | LGPL or Apache License 2.0 |
In its latest stable release, CLucene conforms to Lucene 1.9.1’s API and index format, but ongoing development is active toward fixing issues and supporting more recent Lucene releases. As of this writing, development is proceeding on a source code branch toward full compatibility with Lucene’s 2.3.2 release. Despite being officially marked unstable, the 2.3.2 branch seems quite stable and is already commonly used, although the APIs are still likely to change.
Adobe and Nero are believed to use CLucene in their products, as do other well-known open-source projects like Strigi, ht://Dig and kio-clucene.
10.2.1. Motivation
Many companies and developers use C/C++ exclusively and cannot take advantage of Lucene because it requires Java. CLucene offers the benefits of the Lucene world, while allowing those companies and developers to keep with the platforms and development tools they are most familiar with.
C++ developers are the main audience of CLucene. Since it is written in native code and has no prerequisites, it is also fairly easy to use the library from various highlevel or scripting languages. Thanks to its flexible build system, native code, and small memory footprint, CLucene can also be used on embedded systems and mobile devices, where resources are tight and a JVM is usually not an option.
The project also aims to be attractive to people who like to use Lucene but want to increase performance or remove the overhead of using a JVM. Although the Java platform is constantly improving, basic operations like file handling and memory management will always be faster for C++ compiled code, since no underlying framework or Garbage Collection processes are involved. CLucene is guaranteed to provide better performance, even without the periodic code optimizations by its core team.
Although no current benchmarks are available to show this, those made with previous versions of Lucene and CLucene showed CLucene performed 5–10 times better than an equivalent version of Lucene, in terms of memory usage and execution speeds of indexing and searching operations. Both Lucene and CLucene have changed substantially since then.
10.2.2. API and index compatibility
The CLucene API is similar to Lucene’s; code written in Java can be converted to C++ fairly easily. The drawback is that CLucene doesn’t follow the generally accepted C++ coding standards. But due to the number of classes that would have to be redesigned and the difficulty it will pose for the process of keeping up with the original Lucene project, CLucene continues to follow a “Javaesque” coding standard. This approach also allows much of the user’s code to be converted using macros and scripts.
Thanks to a full index-format compatibility, indexes built with Lucene are also searchable using CLucene and vice versa, as long as their index format version is supported by both. For example, as of this writing CLucene can read and write to indexes created by Lucene 2.3.2, but it will not work with indexes created or merged by Lucene 3+. Because backward compatibility is preserved in Lucene, even the most recent versions of Lucene can read indexes built with any version of CLucene, and those will still be readable by CLucene as long as they are not being written to by a more recent Lucene version.
Listing 10.1 shows a command-line program to perform basic indexing and searching. This program first indexes several documents with a single contents field. Following that, it runs a few searches against the generated in-memory index and prints the search results for each query.
Listing 10.1. Using CLucene’s IndexWriter and IndexSearcher API


10.2.3. Supported platforms
Initially developed in Microsoft Visual Studio, CLucene also compiles in GCC, MinGW32, and the Borland C++ compiler. In addition to the Microsoft Windows platform, it has been successfully built on various Linux distributions (Red Hat, Ubuntu, and more), FreeBSD, Mac OS X and Debian. The code supports both 32- and 64-bit versions of these platforms.
Today, CLucene comes with CMake build scripts which simplify the build process, and allow it to be run on almost every platform. Both Unicode and non-Unicode builds are supported through it.
The CLucene team has made use of SourceForge’s multiplatform compile farm to ensure that CLucene compiles and runs on as many platforms as possible. However, SourceForge has now closed its compile farm, so most cross-platform testing is done by contributors having physical access to various machines (even the rare ones), and by using virtual machines.
10.2.4. Current and future work
As part of the effort of being compatible with Java Lucene, the distribution package of CLucene includes many of the same components as Lucene, such as tests, contrib folder, and a demo application. This is the case also with the development repositories. Unfortunately, Lucene’s rapid growth makes it very hard to keep up with it in real time, therefore many classes and tests may be missing.
CLucene once had several wrappers that allowed it to be used with other programming languages, such as Perl, Python, .NET and PHP. Most were made for previous versions of the library, and haven’t been updated in some time. It is possible to bring them up to speed, or to use tools like SWIG to create one simple interface for many languages at once, should one needed to use them again.
Following a decision made during early development, no external libraries were incorporated for string handling, threading, and reference counting. The core team has begun to replace the custom code and macros used for those operations with Boost’s C++ libraries. This update will make CLucene much more robust, and allow its developers to focus solely on porting more Lucene code, instead of worrying about platform-specific issues. Also, introduction of concepts like smart-pointers will make building of wrappers much easier.
10.3. Lucene.Net (C# and other .NET languages)
Contributed by GEORGE AROUSH, creator of Apache Lucene.Net
Apache Lucene.Net started as a project at SourceForge in 2004, as dotLucene. In April 2006, it was incubated into Apache, and by October 2009 it graduated as a subproject under Apache Lucene. As its main home page states:
Lucene.Net sticks to the APIs and classes used in the original Java implementation of Lucene. The API names as well as class names (including documentation and comments) are preserved with the intention of giving Lucene.Net the look and feel of the C# language and the .NET Framework. For example, the method IndexSearcher.search in the Java implementation now reads IndexSearcher.Search in the C# port.
In addition to the APIs and classes ported to C#, the algorithm of Java Lucene is ported to C# Lucene. This means an index created with Java Lucene is back-and-forth compatible with the C# Lucene; both at reading, writing and updating. In fact a Lucene index can be concurrently searched and updated using Lucene Java and Lucene.Net processes.
Lucene.Net’s current status is summarized in table 10.3. Although the last official Apache release is 2.0, the trunk of the Lucene.Net subversion repository matches Lucene 1.4 up to 2.9.1 and all are quite stable and are used in a number of well-known environments such as MySpace and Beagle.
Table 10.3. Lucene.Net summary
|
Port feature |
Port status |
|---|---|
| Port type | Native port |
| Programming languages | C# |
| Website | http://lucene.apache.org/lucene.net/ |
| Development status | Stable |
| Activity | Active development, active users |
| Last stable release | 2.9.1 |
| Matching Lucene release | 2.9.1 |
| Compatible index format | Yes, 2.9.1 |
| Compatible APIs | Yes |
| License | Apache License 2.0 |
Beagle (http://beagle-project.org/Main_Page), a tool for searching your personal information space, including local files, email, images, calendar entries, and address book entries, is an interesting use case of Lucene.Net. Beagle is a large project in itself. Its design is just like Solr: there’s a dedicated daemon process that exposes a network API, and then clients are available in various programming languages (currently at least C#, C, and Python). Beagle seems to be well adopted by Linux desktop environments as their standard local search implementation, running under Mono, the open source implementation of the .NET Framework.
Performance of Lucene.Net compares favorably with Lucene Java. The most recent testing, based on Lucene’s 2.3.1 release, shows Lucene.Net to be about 5 percent faster than Lucene Java. The developers of Lucene.Net don’t have any more recent performance numbers at this time. It would be safe to assume that Lucene.Net’s performance is equal to that of Lucene Java.
The distribution package of Lucene.Net consists of the same components as the distribution package of Lucene. It includes the source code, tests, and the demo examples. In addition, some of the contrib components have been ported to C#.
10.3.1. API compatibility
As stated earlier, although it’s written in C#, Lucene.Net exposes an API that’s virtually identical to that of Lucene. Consequently, code written for Lucene can be ported to C# with minimal effort. This compatibility also allows .NET developers to use documentation for the Java version, such as this book.
The difference is limited to the Java and C# naming styles. Whereas Java’s method names begin with lowercase letters, the .NET version uses the C# naming style in which method names typically begin with uppercase letters. Listing 10.2 shows how to create an index using Lucene.Net.
Listing 10.2. C# code for indexing *.txt files with Lucene.Net

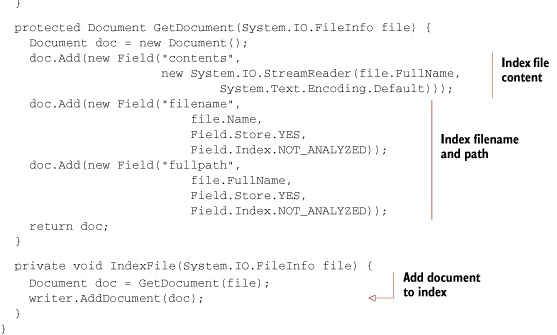
As you can see, the source code is nearly identical to the corresponding indexing source code for Lucene java. The searching example, shown in listing 10.3, is also nearly identical. Both of these listings are extracted from the demo code that’s included with Lucene.Net.
Listing 10.3. Searching an index with Lucene.Net

10.3.2. Index compatibility
Lucene.Net is fully compatible with Lucene at the index level: an index created by Lucene can be read by Lucene.Net, and vice versa. Of course, as Lucene evolves, indexes between versions of Lucene itself may not be portable, so this compatibility is currently limited to Lucene version 2.9.
10.4. KinoSearch and Lucy (Perl)
Perl is a popular programming language. Larry Wall, creator of Perl, has stated one of his goals in Perl is to offer many ways to accomplish a given task. Larry would be proud; there are quite a few choices for accessing Lucene’s functionality from Perl.
We’ll first visit the most popular choice, KinoSearch. After that we touch on Lucy, which is still under active development and hasn’t had any releases yet but is nevertheless interesting. We finish with Solr’s two Perl clients and CLucene’s Perl bindings.
10.4.1. KinoSearch
KinoSearch, created and actively maintained by Marvin Humphrey, is a C and Perl loose native port of Lucene. This means its approach, at a high level, is similar to Lucene, but the architecture, APIs, and index file format aren’t identical. The summary of its current status is shown in table 10.4. Marvin took the time to introduce interesting innovations to KinoSearch while porting to Perl and C; some of these innovations have inspired corresponding improvements back to Lucene, which is one of the delightful and natural “cross-fertilization” effects of open source development.
Table 10.4. KinoSearch summary
|
Port feature |
Port status |
|---|---|
| Port type | Native port |
| Programming languages | C, Perl |
| Website | http://www.rectangular.com/kinosearch/ |
| Development status | Alpha (though widely used and quite stable) |
| Activity | Active development, active users |
| Last stable release | 0.163 |
| Matching Lucene release | N/A (loose port) |
| Compatible index format | No |
| Compatible APIs | No |
| License | Custom |
KinoSearch is technically in the alpha stage of its development, but in practice is nevertheless extremely stable, bug free, and widely used in the Perl community. Development and users lists are active, and developers (mostly Marvin) are working toward the 1.0 first stable release. It’s hard to gauge usage, but at least two well-known websites, Slashdot.org and Eventful.com, use it. When users find issues and post questions to the mailing lists, Marvin is always responsive.
KinoSearch also learned important lessons from an earlier port of Lucene to Perl, PLucene. PLucene, which has stopped development, suffered from performance problems, likely because it was implemented entirely in Perl; KinoSearch instead wraps Perl bindings around a C core. This allows the C core to do all the “heavy lifting,” which results in much better performance. Early testing of KinoSearch showed its indexing performance to be close to Lucene’s 1.9.1 release. But both KinoSearch and Lucene have changed quite a bit since then, so it’s not clear how they compare today.
Probably the largest architectural difference is that KinoSearch requires you to specify field definitions up front when you first create the index (similarly to how you create a database table). The fields in documents then must match this preset schema. This allows KinoSearch to make internal simplifications, which gain performance, but at the cost of the full document flexibility that’s available in Lucene.
There are also a number of API differences. For example, there’s only one class, InvIndexer, for making changes to an index (whereas Lucene has two classes for doing so, IndexWriter and, somewhat confusingly, IndexReader). The index file format is also different, though similar. Listings 10.4 and 10.5 show examples for creating and search an index.
Listing 10.4. Creating an index with KinoSearch
use KinoSearch::InvIndexer;
use KinoSearch::Analysis::PolyAnalyzer;
my $analyzer
= KinoSearch::Analysis::PolyAnalyzer->new( language => 'en' );
my $invindexer = KinoSearch::InvIndexer->new(
invindex => '/path/to/invindex',
create => 1,
analyzer => $analyzer,
);
$invindexer->spec_field(
name => 'title',
boost => 3,
);
$invindexer->spec_field( name => 'bodytext' );
while ( my ( $title, $bodytext ) = each %source_documents ) {
my $doc = $invindexer->new_doc;
$doc->set_value( title => $title );
$doc->set_value( bodytext => $bodytext );
$invindexer->add_doc($doc);
}
$invindexer->finish;
use KinoSearch::Searcher;
use KinoSearch::Analysis::PolyAnalyzer;
my $analyzer
= KinoSearch::Analysis::PolyAnalyzer->new( language => 'en' );
my $searcher = KinoSearch::Searcher->new(
invindex => '/path/to/invindex',
analyzer => $analyzer,
);
my $hits = $searcher->search( query => "foo bar" );
while ( my $hit = $hits->fetch_hit_hashref ) {
print "$hit->{title}
";
}
Next we look at Lucy, a follow-on to KinoSearch.
10.4.2. Lucy
Lucy, at http://lucene.apache.org/lucy, is a new Lucene port. It plans to be a loose native port of Lucene to C, with a design that makes it simple to wrap the C code with APIs in different dynamic languages, with the initial focus on Perl and Ruby. Table 10.5 shows the summary of Lucy’s current status.
Table 10.5. Lucy summary
|
Port feature |
Port status |
|---|---|
| Port type | Native port |
| Programming languages | C with Perl, Ruby (and eventually others) bindings |
| Website | http://lucene.apache.org/lucy/ |
| Development status | Design (no code/releases yet) |
| Activity | Active development |
| Last stable release | N/A |
| Matching Lucene release | N/A (loose port) |
| Compatible index format | No |
| Compatible APIs | No |
| License | Unknown |
Lucy was started by the creator of KinoSearch, Marvin Humphrey, and the creator of Ferret (see section 10.5), David Balmain. Unfortunately, David became unavailable to work on the project, but Marvin and others have continued to actively work toward an initial release. Like Ferret and KinoSearch, Lucy is inspired by Lucene and derives much of its design from those two projects, aiming to achieve the best of both. Eventually other programming languages should be able to wrap Lucy’s C core. Perl still offers more options.
10.4.3. Other Perl options
There are other ways to access Lucene’s functionality from Perl. At least two clients are available for Solr: Solr.pm (see http://search.cpan.org/perldoc?Solr), which is separately developed from the Solr effort, and SolPerl, which is developed and distributed with Solr. Solr is a client-server port. If you have a strong preference for API- and index-compatible ports, and don’t like that KinoSearch is a “loose” port, have a look at the Perl bindings in CLucene, which is also a native port of Lucene but with matching APIs and index file formats.
10.5. Ferret (Ruby)
The Ruby programming language, another dynamic language, has become quite popular recently. Fortunately, you can access Lucene from Ruby in various ways. The most popular port is Ferret, summarized in table 10.6.
Table 10.6. Ferret summary
|
Port status |
|
|---|---|
| Port type | Native local wrapper |
| Programming languages | C, Ruby |
| Website | http://ferret.davebalmain.com/ |
| Development status | Stable, though some serious bugs remain |
| Activity | Development stopped but users are active |
| Last stable release | 0.11.6 |
| Matching Lucene release | N/A (loose port) |
| Compatible index format | No |
| Compatible APIs | No |
| License | MIT-style license |
Although independently developed, Ferret takes the same approach as KinoSearch, as a loose port of Lucene to C and Ruby. The C core does the heavy lifting, whereas the Ruby API exposes access to that core. Ferret was created by David Balmain, who has written a dedicated book about Ferret. There is also an acts_as_ferret plug-in for Ruby on Rails. Unfortunately, ongoing development on Ferret has ended.
User reports have shown Ferret’s performance to be quite good, comparable at least to Lucene’s 1.9 release. Even though development appears to have ended, usage of Ferret is still strong, especially for acts_as_ferret, (although there are reports of still open serious issues on the most recent release, so you should tread carefully).
Besides Ferret, you have a few other options for accessing Lucene from Ruby. solr-ruby, Solr’s Ruby client, allows you to add, update, and delete documents as well as issue queries. Just install it with the command gem install solr-ruby. Here’s a quick example:
require 'solr'
# connect to the solr instance
conn = Solr::Connection.new('http://localhost:8983/solr', :autocommit => :on)
# add a document to the index
conn.add(:id => 123, :title_text => 'Lucene in Action, Second Edition')
# update the document
conn.update(:id => 123, :title_text => Ant in Action')
# print out the first hit in a query for 'action'
response = conn.query('action')
print response.hits[0]
# iterate through all the hits for 'action'
conn.query('action') do |hit|
puts hit.inspect
end
# delete document by id
conn.delete(123)
Solr also provides a Ruby response format that produces valid Ruby Hash structure as the string response, which can be directly eval’d in Ruby even without the solr-ruby client. This enables a compact search solution. There’s also an independently developed Rails plug-in, acts_as_solr, as well as Solr Flare (developed by Erik Hatcher), which is a feature-rich Rails plug-in that provides even more functionality than acts_as_solr. Finally, RSolr is a separately developed Solr Ruby client, available at http://github.com/mwmitchell/rsolr. It features transparent JRuby DirectSolrConnection support and a simple hash-in, hash-out architecture.
Note
There’s even a Common Lisp port called Montezuma, at http://code.google.com/p/montezuma. Development seems to have stopped after an initial burst of activity. In fact, Montezuma is a port of Ferret.
Another compelling option is to use JRuby, which is a reverse port of the Ruby language to run on a JVM. You still write Ruby code, but it’s a JVM that’s running your Ruby code, and thus any JAR, including Lucene, is accessible from Ruby. JRuby can access Lucene Java directly, and also work with Solr via solr-ruby, RSolr, or the native SolrJ library. The one downside to JRuby is that it can’t run any Ruby extensions that are implemented in C (Lucene is entirely Java, so this would only affect apps that rely on other C-based Ruby extensions).
10.6. PHP
You have several interesting options if you’d like to use PHP. The first option is to use Solr with its PHP client, SolPHP, which is a client-server solution. As is the case for Ruby, Solr has a response format that produces valid PHP code, which can simply be eval’d in PHP.
The second option is CLucene’s PHP bindings, included with CLucene’s release, which is a pure native port. Another pure native port is Zend Framework.
10.6.1. Zend Framework
Zend Framework, summarized in table 10.7, is far more than a port of Lucene: it’s a full open source object-oriented web application framework, implemented entirely in PHP 5. It includes a pure native port of Lucene to PHP 5 (described at http://framework.zend.com/manual/en/zend.search.lucene.html), and enables you to easily add full search to your web application.
Table 10.7. Zend Framework summary
|
Port feature |
Port status |
|---|---|
| Port type | Pure native port |
| Programming languages | PHP 5 |
| Website | http://framework.zend.com/ |
| Development status | Stable |
| Activity | Active development and active users |
| Last stable release | 1.7.3 |
| Matching Lucene release | 2.1 |
| Compatible index format | Yes |
| Compatible APIs | Yes |
| License | BSD-style License |
There are some reports of slow performance during indexing (though this issue may have been resolved by more recent releases, so you should certainly test for yourself). Earlier releases didn’t support Unicode content, but this has since been fixed.
Zend Framework may be a good fit for your application if you want a pure PHP solution, but if you don’t require a native port and you’d like a lighter-weight solution instead, then PHP Bridge may be a good option.
10.6.2. PHP Bridge
The PHP/Java Bridge, hosted at http://php-java-bridge.sourceforge.net/pjb/index.php, is technically a client-server solution. Normal Java Lucene runs in a standalone process, possibly on a different computer, and then the PHP runtime can invoke methods on Java classes through the PHP Bridge. It can also bridge to a running .NET process, so you could also use PHP to access Lucene.Net, for example. The release web archive (WAR) that you download from the website includes examples of indexing and searching with Lucene. For example, this is how you create an IndexWriter:
$tmp = create_index_dir();
$analyzer = new java("org.apache.lucene.analysis.standard.StandardAnalyzer");
$writer = new java("org.apache.lucene.index.IndexWriter",
$tmp, $analyzer, true);
Because this is just a client-server wrapper around Lucene, you can tap directly into the latest release of Lucene. Performance should be close to Lucene’s performance, except for the overhead of invoking methods over the bridge. Likely this affects indexing performance more so than searching performance.
10.7. PyLucene (Python)
Contributed by ANDI VAJDA, creator of PyLucene
In contrast to Perl, Guido van Rossum, the creator of Python, prefers to have one obvious way to do something, and in fact, there’s one obvious choice for accessing Lucene from Python: PyLucene. Table 10.8 shows PyLucene’s current status.
Table 10.8. PyLucene summary
|
Port feature |
Port status |
|---|---|
| Port type | Local wrapper |
| Programming languages | Python, C++, Java |
| Website | http://lucene.apache.org/pylucene/ |
| Development status | Stable |
| Activity | Active development, active users |
| Last stable release | 3.0 |
| Matching Lucene release | 3.0 |
| Compatible index format | Yes |
| Compatible APIs | Yes |
| License | Apache Version 2.0 |
PyLucene is a “local wrapper” port, by adding Python bindings to the actual Lucene source code. PyLucene embeds a Java VM, that in turn executes the normal Lucene code, into a Python process. The PyLucene Python extension, a Python module called lucene, is machine-generated by a package called JCC, also included with the PyLucene sources. JCC is fascinating in its own right: it’s written in Python and C++, and uses Java’s reflection API, accessed via an embedded JVM, to peek at the public API for all classes in a JAR. Once it knows that API, it generates the appropriate C++ code that enables access to that API from Python through the Java Native Interface (JNI), using C++ as the common “bridge” language. Because JCC autogenerates all wrappers by inspecting Lucene’s JAR file, the release latency is near zero.
Both PyLucene and JCC are released under the Apache 2.0 license and led by Andi Vajda, who also contributed Berkeley DbDirectory (see section 9.2) to the Lucene contrib codebase. PyLucene began as an indexing and searching component of Chandler (see section 9.2), an extensible open source PIM, but it was split into a separate project in June 2004. In January 2009, it was folded into Apache as a subproject of Lucene.
The performance of PyLucene should be similar to that of Lucene because the actual Lucene code is running in an embedded JVM in-process. The Python/Java barrier is crossed via the JNI and is reasonably fast. Virtually all the source code generated by JCC for PyLucene is C++. That code uses the Python VM for exposing Lucene objects to the Python interpreter, but none of the PyLucene code itself is interpreted Python.
PyLucene was first released in 2004. It has had a number of users over the years. Some Linux distributions, such as Debian, are now beginning to distribute PyLucene and JCC. Currently, the PyLucene developer mailing list has about 160 members. Traffic is moderate and usually involves build issues. Lucene issues while using PyLucene are usually handled on the Lucene user mailing list.
10.7.1. API compatibility
The source code for PyLucene is machine-generated by JCC. Therefore, all public APIs in all public classes available from Lucene are available from PyLucene. JCC exposes iterator and mapping access in Pythonic ways, making for a true Python experience while using Lucene. But here’s a warning: once you’ve used Lucene from Python, it can be hard to go back to using Java!
As far as its structure is concerned, the API is virtually the same, which makes it easy for users of Lucene to learn how to use PyLucene. Another convenient side effect is that all existing Lucene documentation can be used for programming with PyLucene.
PyLucene closely tracks the Lucene releases. The latest and greatest from Lucene is usually available via PyLucene a few days after a release.
10.7.2. Other Python options
PyLucene is our favorite option for using Lucene from Python, but there are other choices with different trade-offs:
- Solr, a client-server port, includes the SolPython client.
- If you prefer a native port, CLucene offers Python bindings.
- Beagle, described in section 10.3, also includes Python bindings. Like Solr, Beagle is a client-server solution, but the server runs in a .NET environment instead of a JVM.
- If you prefer a reverse port, you could simply use Jython, a port of the Python language to run on a JVM, which has full access to any Java APIs, including all releases of Lucene.
As you’ve seen, there are a number of ways to access Lucene from Python, the most popular being PyLucene.
10.8. Solr (many programming languages)
Solr, a sister project to Lucene and developed closely along with Lucene, is clientserver architecture exposing access from many programming languages. Solr has comprehensive client-side support for many programming languages. Table 10.9 summarizes Solr’s current status. In a nutshell, Solr is a server wrapper around Lucene. It provides a standard XML over HTTP interface for interacting with Lucene’s APIs, and layers on further functionality not normally available in Lucene, such as distributed search, faceted navigation, and a field schema. Because Solr “translates” Lucene’s Java-only API into a friendly network protocol, it’s easy to create clients in different programming languages that speak this network protocol. For this reason, of all ways to access Lucene from other programming languages, Solr offers the least porting effort.
Table 10.9. Solr summary
|
Port feature |
Port status |
|---|---|
| Port type | Client-server |
| Programming languages | Java and many client wrappers |
| Website | http://lucene.apache.org/solr/ |
| Development status | Stable |
| Activity | Active development, active users |
| Last stable release | 1.3 |
| Matching Lucene release | 3.0 |
| Compatible index format | Yes, 3.0 |
| Compatible APIs | No |
| License | Apache License 2.0 |
Solr has a delightful diversity of clients, shown in table 10.10. Be sure to check http://wiki.apache.org/solr/IntegratingSolr for the latest complete list. If you need to access Lucene from an exotic language, chances are there’s already at least one Solr client. And if there isn’t, it’s easy to create one! Solr is actively developed and has excellent compatibility with Lucene because it uses Lucene under the hood. If your application can accept, or prefers, the addition of a standalone server, Solr is likely a good fit.
Table 10.10. The many Solr clients currently available
|
Name |
Language/environment |
|---|---|
| SolRuby, acts_as_solr | Ruby/Rails |
| SolPHP | PHP |
| SolJava | Java |
| SolPython | Python |
| SolPerl, Solr.pm | Perl (http://search.cpan.org/perldoc?Solr) |
| SolJSON | JavaScript |
| SolrJS | JavaScript (http://solrjs.solrstuff.org/) |
| SolForrest | Apache Forrest/Cocoon |
| SolrSharp | C# |
| Solrnet | http://code.google.com/p/solrnet/ |
| SolColdFusion | ColdFusion plug-in |
10.9. Summary
In this chapter, we discussed four types of ports, and we visited the popular existing Lucene ports known to us: CLucene, Lucene.Net, Pylucene, Solr and its many clients, KinoSearch, Ferret, the upcoming Lucy, and numerous PHP options. We looked at their APIs, supported features, Lucene compatibility, development and user activity, and performance as compared to Lucene, as well as some of the users of each port. The future may bring additional Lucene ports; the Lucene developers keep a list on the Lucene Wiki at http://wiki.apache.org/lucene-java/LuceneImplementations. As you can see, there are a great many ways to access Lucene from environments other than Java, each with its own trade-offs. Although this task may seem daunting, if you’re trying to decide which of them to use, it’s a great sign of Lucene’s popularity and maturity that so many people have created all these options.
In the next chapter we’ll visit administrative aspects of Lucene, including options for tuning Lucene for better performance.