
Chapter 7. Extracting text with Tika
- Understanding Tika’s logical design
- Using Tika’s built-in tool and APIs for text extraction
- Parsing XML
- Handling known Tika limitations
One of the more mundane yet vital steps when building a search application is extracting text from the documents you need to index. You might be lucky to have an application whose content is already in textual format or whose documents are always the same format, such as XML files or regular rows in a database. If you’re unlucky, you must instead accept the surprisingly wide plethora of document formats that are popular today, such as Outlook, Word, Excel, PowerPoint, Visio, Flash, PDF, Open Office, Rich Text Format (RTF), and even archive file formats like TAR, ZIP, and BZIP2. Seemingly textual formats, like XML or HTML, present challenges because you must take care not to accidentally include any tags or JavaScript sources. The plain text format might seem simplest of all, yet determining its character set may not be easy.
In the past it was necessary to “go it alone”: track down your own document filters, one by one, and interact with their unique and interesting APIs in order to extract the text you need. You’d also need to detect the document type and character encoding yourself. Fortunately, there’s now an open source framework called Tika, under the Apache Lucene top-level project, that handles most of this work for you.
Tika has a simple-to-use API for providing a document source and then retrieving the text filtered from it. In this chapter we’ll start with an overview of Tika, then delve into its logical design, API, and tools. After showing you how to install Tika, we’ll discuss useful tools that let you filter a document without writing any Java code. Next we’ll explore a class that extracts text programmatically and produces a corresponding Lucene document. After that, we’ll examine two approaches for extracting fields from XML content, and then we’ll wrap up by considering some of Tika’s limitations and visiting a few alternative document filtering options.
7.1. What is Tika?
Tika was added to the Lucene umbrella in October 2008, after graduating from the Apache incubator, which is the process newly created projects go through to become an Apache project. The most recent release as of this writing is 0.6. Development continues at a rapid pace, and it’s expected there will be non-backward-compatible changes in the march to the 1.0 release, so be sure to check Tika’s website at http://lucene.apache.org/tika for the latest documentation.
Tika is a framework that hosts plug-in parsers for each supported document type. The framework presents the same standard API to the application for extracting text and metadata from a document, and under the hood the plug-in parser interacts with the external library using the custom API exposed by that library. This lets your application use the same uniform API regardless of document type. When you need to extract text from a document, Tika finds the right parser for the document (details on this shortly).
As a framework, Tika doesn’t do any of the document filtering itself. Rather, it relies on external open source projects and libraries to do the heavy lifting. Table 7.1 lists the formats supported as of the 0.6 release, along with which project or library the document parser is based on. There’s support for many common document formats and new formats are added frequently, so check online for the latest list.
Table 7.1. Supported document formats and the library used to parse them
|
Format |
Library |
|---|---|
| Microsoft’s OLE2 Compound Document Format (Excel, Word, PowerPoint, Visio, Outlook) | Apache POI |
| Microsoft Office 2007 OOXML | Apache POI |
| Adobe Portable Document Format (PDF) | PDFBox |
| Rich Text Format (RTF)—currently body text only (no metadata) | Java Swing API (RTFEditorKit) |
| Plain text character set detection | ICU4J library |
| HTML | CyberNeko library |
| XML | Java’s javax.xml classes |
| ZIP Archives | Java’s built-in zip classes, Apache Commons Compress |
| TAR Archives | Apache Ant, Apache Commons Compress |
| AR Archives | Apache Commons Compress |
| CPIO Archives | Apache Commons Compress |
| GZIP compression | Java’s built-in support (GZIPInputStream), Apache Commons Compress |
| BZIP2 compression | Apache Ant, Apache Commons Compress |
| Image formats (metadata only) | Java’s javax.imageio classes |
| Java class files | ASM library (JCR-1522) |
| Java JAR files | Java’s built-in zip classes and ASM library, Apache Commons Compress |
| MP3 audio (ID3v1 tags) | Implemented directly |
| Other audio formats (wav, aiff, au) | Java’s built-in support (javax.sound.*) |
| OpenDocument | Parses XML directly |
| Adobe Flash | Parses metadata from FLV files directly |
| MIDI files (embedded text, eg song lyrics) | Java’s built-in support (javax.audio.midi.*) |
| WAVE Audio (sampling metadata) | Java’s built-in support (javax.audio.sampled.*) |
In addition to extracting the body text for a document, Tika extracts metadata values for most document types. Tika represents metadata as a single String <-> String map, with constants exposed for the common metadata keys, listed in table 7.2. These constants are defined in the Metadata class in the org.apache.tika.metadata package. But not all parsers can extract metadata, and when they do, they may extract to different metadata keys than you expect. In general the area of metadata extraction is still in flux in Tika, so it’s best to test parsing some samples of your documents to understand what metadata is exposed.
Table 7.2. Metadata keys that Tika extracts
|
Metadata Constant |
Description |
|---|---|
| RESOURCE_KEY_NAME | The name of the file or resource that contains the document. A client application can set this property to allow the parser to use filename heuristics to determine the format of the document. The parser implementation may set this property if the file format contains the canonical name of the file (for example, the GZIP format has a slot for the filename). |
| CONTENT_TYPE | The declared content type of the document. A client application can set this property based on an HTTP Content-Type header, for example. The declared content type may help the parser to correctly interpret the document. The parser implementation sets this property to the content type according to which document was parsed. |
| CONTENT_ENCODING | The declared content encoding of the document. A client application can set this property based on an HTTP Content-Type header, for example. The declared content type may help the parser to correctly interpret the document. The parser implementation sets this property to the content type according to which document was parsed. |
| TITLE | The title of the document. The parser implementation sets this property if the document format contains an explicit title field. |
| AUTHOR | The name of the author of the document. The parser implementation sets this property if the document format contains an explicit author field. |
| MSOffice.* | Defines additional metadata from Microsoft Office: APPLICATION_NAME, CHARACTER_COUNT, COMMENTS, KEYWORDS, LAST_AUTHOR, LAST_PRINTED, LAST_SAVED, PAGE_COUNT, REVISION_NUMBER, TEMPLATE, WORD_COUNT. |
Let’s drill down to learn how Tika models a document’s logical structure and what concrete API is used to expose this.
7.2. Tika’s logical design and API
Tika uses the Extensible Hypertext Markup Language (XHTML) standard to model all documents, regardless of their original format. XHTML is a markup language that combines the best of XML and HTML: because an XHTML document is valid XML, it can be programmatically processed using standard XML tools. Further, because XHTML is mostly compatible with HTML 4 browsers, it can typically be rendered with a modern web browser. With XHTML, a document is cast to this logical top-level structure:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>...</title>
</head>
<body>
...
</body>
</html>
Within the <body>...</body> are other tags (such as <p>, <h1>, and <div>) representing internal document structure.
This is the logical structure of an XHTML document, but how does Tika deliver that to your application? The answer is SAX (Simple API for XML), another well-established standard used by XML parsers. With SAX, as an XML document is parsed, the parser invokes methods on an instance implementing the org.xml.sax.ContentHandler. This is a scalable approach for parsing XML documents because it enables the application to choose what should be done with each element as it’s encountered. Arbitrarily large documents can be processed with minimal consumption of RAM.
The primary interface to Tika is the surprisingly simple parse method (in the org.apache.tika.parser.Parser class):
void parse(InputStream stream
ContentHandler handler,
Metadata metadata,
ParseContext context)
Tika reads the bytes for the document from the InputStream but won’t close it. We recommend you close the stream using a try/finally clause.
The document parser then decodes the bytes, translates the document into the logical XHTML structure, and invokes the SAX API via the provided ContentHandler. The third parameter, metadata, is used bidirectionally: input details, such as specified ContentType (from an HTTP server) or filename (if known), are set before invoking parse, and then any metadata encountered while Tika is processing the document will be recorded and returned. The last parameter is used to pass in arbitrary programmatic configuration for parsers that require it.
You can see that Tika is simply a conduit: it doesn’t do anything with the document text it encounters except invoke the ContentHandler. It’s then up to your application to provide a ContentHandler that does something of interest with the resulting elements and text. But Tika includes helpful utility classes that implement ContentHandler for common cases. For example, BodyContentHandler gathers all text within the <body>...</body> part of the document and forwards it to another handler, OutputStream, Writer, or an internal string buffer for later retrieval.
If you know for certain which document type you’re dealing with, you can directly create the right parser (for example, PDFParser, OfficeParser, or HtmlParser) and then invoke its parse method. If you’re unsure of the document’s type, Tika provides an AutoDetectParser, which is a Parser implementation that uses various heuristics to determine the document’s type and apply the correct parser.
Tika tries to autodetect things like document format and the encoding of the character set (for text/plain documents). Still if you have preexisting information about your documents, such as the original filename (containing a possibly helpful extension) or the character encoding, it’s best if you provide this information via the metadata input so Tika may use this. The filename should be added under Metadata. RESOURCE_NAME_KEY; content type should be added under Metadata.CONTENT_TYPE, and the content encoding should be added under Metadata.CONTENT_ENCODING.
It’s time to get our feet wet! Let’s walk through the installation process for Tika.
7.3. Installing Tika
You’ll first need a build of Tika. The source code with this book includes the 0.6 release of Tika, in the lib directory, but likely you’re staring at a newer release. The binary builds for Tika are included in the Maven 2 repository, which you may either download directly or reference in your application if you’re already using Maven 2.
Building Tika from sources is also easy, although you should check “Getting Started” on the Tika website for any changes since this was written. Download the source release (for example, apache-tika-0.6-src.tar.gz for version 0.6) and extract it. Tika uses Apache’s Maven 2 build system and requires Java 5 or higher, so you’ll need to first install those dependencies. Then run mvn install from within the Tika source directory you unpacked. That command will download a bunch of dependencies into your Maven area, compile Tika’s sources, run tests, and produce the resulting JARs. If all goes well, you’ll see BUILD SUCCESSFUL printed at the end. If you encounter OutOfMemoryError, you can increase the heap size of the JVMs that maven spawns by setting the environment variable MAVEN_OPTS (for example, type export MAVEN_OPTS="-Xmx2g" for the bash shell).
Tika has a modular design, consisting of these components:
- tika-core contains the key interfaces and core functionality.
- tika-parsers contains all the adapters to external parser libraries.
- tika-app bundles everything together in a single executable JAR.
The sources for each of these components live in subdirectories by the same name. Once your build completes, you’ll find a target subdirectory (under each of the component directories) containing the built JAR, such as tika-app-0.6.jar.
It’s most convenient to use the tika-app-0.6.jar, because it has all dependencies, including the classes for all external parsers that Tika uses, contained within it. If for some reason that’s not possible or you’d like to pick which external JARs your application requires, you can use Maven to gather all dependency JARs into the target/dependency directory under each component directory.
Note
You can gather all required dependency JARs by running mvn dependency:copy-dependencies. This command will copy the required JARs out of your Maven area and into the target/dependency directory under each component directory. This command is useful if you intend to use Tika outside of Maven 2.
Now that we’ve built Tika, it’s time to finally extract some text. We’ll start with Tika’s built-in text extraction tool.
7.4. Tika’s built-in text extraction tool
Tika comes with a simple built-in tool allowing you to extract text from documents in the local file system or via URL. This tool creates an AutoDetectParser instance to filter the document, and then provides a few options for interacting with the results. The tool can run either with a dedicated GUI or in a command line–only mode, allowing you to further process its output, using pipes, using other command-line tools. To run the tool with a GUI:
java -jar lib/tika-app-0.6.jar --gui
This command brings up a simple GUI window, in which you can drag and drop files in order to test how the filters work with them. Figure 7.1 shows the window after dragging the Microsoft Word document for chapter 2 of this book onto the window. The window has multiple tabs showing different text extracted during filtering:
- The Formatted Text tab shows the XHTML, rendered with Java’s built-in javax.swing.JEditorPane as text/html content.
- The Plain Text tab shows only the text and whitespace parts, extracted from the XHTMLdocument.
- The Structured Text tab shows the raw XHTMLsource.
- The Metadata tab contains all metadata fields extracted from the document.
- The Errors tab describes any errors encountered while parsing the document.
Figure 7.1. You can drag and drop any binary document onto Tika’s built-in text extraction tool GUI in order to see what text and metadata Tika extracts.

Although the GUI tool is a great way to quickly test Tika on a document, it’s often more useful to use the command line–only invocation:
cat Document.pdf | java -jar lib/tika-app-0.6.jar -
This command prints the full XHTML output from the parser (the extra – at the end of the command tells the tool to read the document from the standard input; you could also provide the filename directly instead of piping its contents into the command). This tool accepts various command-line options to change its behavior:
- --help or -? prints the full usage.
- --verbose or –v prints debug messages.
- --gui or –g runs the GUI.
- --encoding=X or –eX specifies the output encoding to use.
- --xml or –x outputs the XHTML content (this is the default behavior). This corresponds to the Structured Text tab from the GUI.
- --html or –h outputs the HTML content, which is a simplified version of the XHTML content. This corresponds to the Formatted text (rendered as HTML) from the GUI.
- --text or –t outputs the plain-text content. This corresponds to the Plain Text tab from the GUI.
- --metadata or –m outputs only the metadata keys and values. This corresponds to the Metadata tab from the GUI.
You could use Tika’s command-line tool as the basis of your text extraction solution. It’s simple to use and fast to deploy. But if you need more control over which parts of the text are used, or which metadata fields to keep, you’ll need to use Tika’s programmatic API, which we cover next.
7.5. Extracting text programmatically
We’ve seen the signature for Tika’s simple parse API, which is the core of any text extraction based on Tika. But what about the rest of the text extraction process? How can you build a Lucene document from a SAX ContentHandler? That’s what we’ll do now. We’ll also see a useful utility class, aptly named Tika, that provides some methods that are particularly useful for integrating with Lucene. Finally, we’ll show you how to customize which parser Tika chooses for each MIME type.
Note
Tika is advancing very quickly, so it’s likely by the time you read this there is a good out-of-the-box integration of Lucene and Tika, so be sure to check at http://lucene.apache.org/tika. Solr already has a good integration: if you POST binary documents, such as PDFs or Microsoft Word documents, Solr will use Tika under-the-hood to extract and index text with flexible field mappings.
7.5.1. Indexing a Lucene document
Recall that the Indexer tool from chapter 1 has the serious limitation that it can only index plain-text files (with the extension .txt). TikaIndexer, shown in listing 7.1, fixes that! The basic approach is straightforward. You have a source for the document, which you open as an InputStream. Then you create an appropriate ContentHandler for your application, or use one of the utility classes provided with Tika. Finally, you build the Lucene Document instance from the metadata and text encountered by the ContentHandler.
Listing 7.1. Class to extract text from arbitrary documents and index it with Lucene


In TikaIndexer, we simply subclass the original Indexer and override the static main and getDocument methods:
This example will work well, but you should fix a few things before using it in production:
- Catch and handle the exceptions that may be thrown by parser.parse. If the document is corrupted, you’ll see a TikaException. If there was a problem reading the bytes from the InputStream, you’ll encounter an IOException. You may see class loader exceptions if the required parser couldn’t be located or instantiated.
- Be more selective about which metadata fields you want in your index and how you’d like to index them. Your choices are very much application dependent.
- Be more selective about which text is indexed. Right now TikaIndexer simply appends together all text from the document into the contents field by adding more than one instance of that field name to the document. You may instead want to handle different substructures of the document differently, and perhaps use an analyzer that sets a positionIncrementGap so that phrases and span queries can’t match across two different contents fields.
- Add custom logic to filter out known “uninteresting” portions of text documents, such as standard headers and footer text that appear in all documents.
- If your document’s text could be very large in size, consider using the Tika.parse utility method (described in the next section) instead.
As you can see, it’s quite simple using Tika’s programmatic APIs to extract text and build a Lucene document. In our example, we used the parse API from AutoDetectParser, but Tika also provides utility APIs that might be a useful alternate path for your application.
7.5.2. The Tika utility class
The Tika class, in the org.apache.tika package, is a utility class that exposes a number of helpful utility methods, shown in Table 7.3.
Table 7.3. Useful methods exposed by the Tika utility class
|
Method |
Purpose |
|---|---|
| String detect(...) | Detects the media type of the provided InputStream, file, or URL, with optional metadata |
| Reader parse(...) | Parses the InputStream, file, or URL, returning a Reader from which you can read the text |
| String parseToString(...) | Parses the InputStream, file, or URL to a String |
These methods often let you create a one-liner to extract the text from your document. One particularly helpful method for integrating with Lucene is the Reader parse(...) method, which parses the document but exposes a Reader to read the text. Lucene can index text directly from a Reader, making this is a simple way to index the text extracted from a document.
The returned Reader is an instance of ParsingReader, from the org.apache.tika.parser package, and it has a clever implementation. When created, it spawns a background thread to parse the document, using the BodyContentHandler. The resulting text is written to a PipedWriter (from java.io), and a corresponding PipedReader is returned to you. Because of this streaming implementation, the full text of the document is never materialized at once. Instead, the text is created as the Reader consumes it, with a small shared buffer. This means even documents that parse to an exceptionally large amount of text will use little memory during filtering.
During creation, ParsingReader also attempts to process all metadata for the document, so after it’s created but before indexing the document you should call the getMetadata() method and add any important metadata to your document.
This class may be a great fit for your application. But because a thread is spawned for every document, and because PipedWriter and PipedReader are used, it’s likely net indexing throughput is slower than if you simply materialize the full text yourself up front (say, with StringBuilder). Still, if materializing the full text up front is out of the question, because your documents may be unbounded in size, this method is a real lifesaver.
7.5.3. Customizing parser selection
Tika’s AutoDetectParser first determines the MIME type of the document, through various heuristics, and then uses that MIME type to look up the appropriate parser. To do that lookup, Tika uses an instance of TikaConfig, which is a simple class that loads the mapping of MIME type to parser class via an XML file. The default TikaConfig class can be obtained with the static getDefaultConfig method, which in turn loads the file tika-config.xml that comes with Tika. Because this is an XML file, you can easily open it with your favorite text editor to see which MIME types Tika can presently handle. We also used TikaConfig’s getParsers method in listing 7.1 to list the MIME types.
If you’d like to change which parser is used for a given MIME type, or add your own parser to handle a certain MIME type, create your own corresponding XML file and instantiate your own TikaConfig from that file. Then, when creating AutoDetect-Parser, pass in your TikaConfig instance.
Now that we’ve seen all the nice things Tika can do, let’s briefly touch on some known limitations.
7.6. Tika’s limitations
As a new framework, Tika has a few known challenges that it’s working through. Some of these issues are a by-product of its design and won’t change with time without major changes, whereas others are solvable problems and will likely be resolved by the time you read this.
The first challenge is loss of document structure in certain situations. In general, some documents may have a far richer structure than the simple standard XHTML model used by Tika. In our example, addressbook.xml has a rich structure, containing two entries, each with rich specific fields. But Tika regularizes this down to a fixed XHTML structure, thus losing some information. Fortunately, there are other ways to create rich documents from XML, as you’ll learn in the next section.
Another limitation is the astounding number of dependencies when using Tika. If you use the standalone JAR, this results in a large number of classes in that JAR. If you’re not using the standalone JAR, you’ll need many JAR files on your classpath. In part, this is because Tika relies on numerous external packages to do the actual parsing. But it’s also because these external libraries often do far more than Tika requires. For example, PDFBox and Apache POI understand document fonts, layouts, and embedded graphics, and are able to create new documents in the binary format or modify existing documents. Tika only requires a small portion of this (the “extract text” part), yet these libraries don’t typically factor that out as a standalone component. As a result, numerous excess classes and JARs end up on the classpath, which could cause problems if they conflict with other JARs in your application. To put this in perspective, Tika’s 0.6 JAR weighs in at about 15MB, whereas Lucene’s core JAR is about 1MB!
Another challenge is certain document parsers, such as Microsoft’s OLE2 Compound Document Format, require full random access to the document’s bytes, which InputStream doesn’t expose. In such cases Tika currently copies all bytes from the stream into a temporary file, which is then opened directly for random access. A future improvement, possibly already done by the time you read this, will allow you to pass a random access stream directly to Tika (if your document is already stored and accessible via a random access file), to avoid this unnecessary copy.
Next you’ll see how to extract text from XML content while preserving its full structure.
7.7. Indexing custom XML
XML is a useful markup language for representing document structure using your own schema or DTD. Unfortunately, Tika only supports simplistic handling of such content: it strips all tags, and extracts all text between the tags. In short, it discards all of the document’s structure.
Typically this is not what you want; instead you need custom control over which tags within the XML are converted into fields of your document. To do this, you shouldn’t use Tika at all, but rather build your own logic to extract the tags. In this section we’ll describe two approaches for parsing XML content and creating Lucene documents. The first is to use an XML SAX parser. The second is to build a converter using the Apache Commons Digester project, which simplifies access to an XML document’s structure.
As our working example throughout this section, listing 7.2 shows an XML snippet holding a single entry from an imaginary address book. It has a clear structure, recording the usual details about each contact. Notice, too, that the <contact> element has an attribute type. We’ll extract this type, along with the text in all the elements, as separate fields in a Lucene document.
Listing 7.2. XML snippet representing an address book entry
<?xml version='1.0' encoding='utf-8'?>
<address-book>
<contact type="individual">
<name>Zane Pasolini</name>
<address>999 W. Prince St.</address>
<city>New York</city>
<province>NY</province>
<postalcode>10013</postalcode>
<country>USA</country>
<telephone>+1 212 345 6789</telephone>
</contact>
</address-book>
7.7.1. Parsing using SAX
SAX defines an event-driven interface in which the parser invokes one of several methods supplied by the caller when a parsing event occurs. Events include beginnings and endings of documents and their elements, parsing errors, and so on. Listing 7.3 shows our solution for parsing the XML address book and converting it to a Lucene document.
Listing 7.3. Using the SAX API to parse an address book entry


The five key methods in this listing are getDocument, startDocument, startElement, characters, and endElement. Also note the elementBuffer and the attributeMap. The former is used to store the textual representation of the CDATA enclosed by the current document element. Some elements may contain attributes, such as the <contact> element containing the attribute type, in our address book entry. The attributeMap is used for storing names and the value of the current element’s attributes.
The getDocument method ![]() doesn’t do much work: it creates a new SAX parser and passes it a reference to the InputStream of the XML document. From there, the parser implementation calls the other four key methods in this class, which together
create a Lucene document instance that’s eventually returned by the getDocument method.
doesn’t do much work: it creates a new SAX parser and passes it a reference to the InputStream of the XML document. From there, the parser implementation calls the other four key methods in this class, which together
create a Lucene document instance that’s eventually returned by the getDocument method.
In startDocument ![]() , which is called when XML document parsing starts, we only create a new instance of the Lucene Document. This is the Document that we’ll eventually populate with fields.
, which is called when XML document parsing starts, we only create a new instance of the Lucene Document. This is the Document that we’ll eventually populate with fields.
The startElement method ![]() is called whenever the beginning of a new XML element is found. We first erase the elementBuffer by setting its length to 0, and clear the attributeMap to remove data associated with the previous element. If the current element has attributes, we iterate through them and save
their names and values in the attributeMap. In the case of the XML document in listing 7.2, this happens only when startElement method is called for the <contact> element, because only that element has an attribute.
is called whenever the beginning of a new XML element is found. We first erase the elementBuffer by setting its length to 0, and clear the attributeMap to remove data associated with the previous element. If the current element has attributes, we iterate through them and save
their names and values in the attributeMap. In the case of the XML document in listing 7.2, this happens only when startElement method is called for the <contact> element, because only that element has an attribute.
The characters method ![]() may be called multiple times during the processing of a single XML element. In it we append to our elementBuffer the element contents passed into the method.
may be called multiple times during the processing of a single XML element. In it we append to our elementBuffer the element contents passed into the method.
The last method of interest is endElement ![]() , where you can finally see more of Lucene in action. This method is called when the parser processes the closing tag of the
current element. Therefore, this is the method where we have all the information about the XML element that was just processed.
We aren’t interested in indexing the top-level element, <address-book>, so we immediately return from the method in that case. Similarly, we aren’t interested in indexing the <contact> element. But we’re interested in indexing that <contact>’s attributes, so we use attributeMap to get attribute names and values, and add them to the Lucene document. All other elements of our address book entry are
treated equally, and we blindly index them as Field.Index.NOT_ANALYZED. Attribute values as well element data are indexed.
, where you can finally see more of Lucene in action. This method is called when the parser processes the closing tag of the
current element. Therefore, this is the method where we have all the information about the XML element that was just processed.
We aren’t interested in indexing the top-level element, <address-book>, so we immediately return from the method in that case. Similarly, we aren’t interested in indexing the <contact> element. But we’re interested in indexing that <contact>’s attributes, so we use attributeMap to get attribute names and values, and add them to the Lucene document. All other elements of our address book entry are
treated equally, and we blindly index them as Field.Index.NOT_ANALYZED. Attribute values as well element data are indexed.
The final document returned is a ready-to-index Lucene document populated with fields whose names are derived from XML elements’ names and whose values correspond to the textual content of those elements. You can run this tool by typing ant SAXXMLDocument at the command line in the root directory after unpacking the book’s source code. It will produce output like this, showing you the document it created:
Document<stored,indexed<name:Zane Pasolini> stored,indexed<address:999 W. Prince St.> stored,indexed<city:New York> stored,indexed<province:NY> stored,indexed<postalcode:10013> stored,indexed<country:USA> stored,indexed<telephone:+1 212 345 6789>>
Although this code alone will let you index XML documents, let’s look at another handy tool for parsing XML: Digester.
7.7.2. Parsing and indexing using Apache Commons Digester
Digester, available at http://commons.apache.org/digester/, is a subproject of the Apache Commons project. It offers a simple, high-level interface for mapping XML documents to Java objects; some developers find it easier to use than DOM or SAX XML parsers. When Digester finds developer-defined patterns in an XML document, it takes developer-specified actions.
The DigesterXMLDocument class in listing 7.4 parses XML documents, such as our address book entry (shown in listing 7.2), and returns a Lucene document with XML elements represented as fields.
Listing 7.4. Using Apache Commons Digester to parse XML
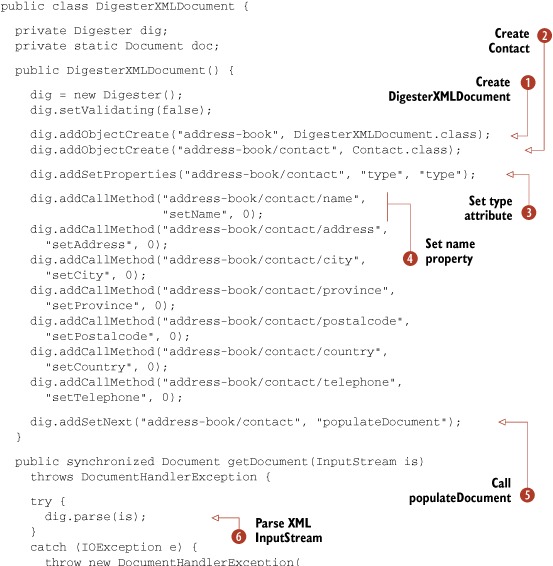

Note that the Contact class is a simple JavaBean (it has setters and getters for each element); we left it out of listing 7.4, but you can see it in the book’s source code.
This is a lengthy piece of code, and it deserves a few explanations. In the DigesterXMLDocument constructor, we create an instance of Digester and configure it by specifying several rules. Each rule specifies an action and a pattern that will trigger the action when encountered.
The first rule ![]() tells Digester to create an instance of the DigesterXMLDocument class when the pattern address-book is found. It does that by using Digester’s addObjectCreate method. Because <address-book> is the opening element in our XML document, this rule is triggered first.
tells Digester to create an instance of the DigesterXMLDocument class when the pattern address-book is found. It does that by using Digester’s addObjectCreate method. Because <address-book> is the opening element in our XML document, this rule is triggered first.
The next rule ![]() instructs Digester to create an instance of class Contact when it finds the <contact> child element under the <address-book> parent, specified with the address-book/contact pattern.
instructs Digester to create an instance of class Contact when it finds the <contact> child element under the <address-book> parent, specified with the address-book/contact pattern.
To handle the <contact> element’s attribute, we set the type property of the Contact instance when Digester finds the type attribute of the <contact> element ![]() . To accomplish that, we use Digester’s addSetProperties method. The Contact class is written as an inner class and contains only setter and getter methods.
. To accomplish that, we use Digester’s addSetProperties method. The Contact class is written as an inner class and contains only setter and getter methods.
Our DigesterXMLDocument class contains several similar-looking rules, all of which call Digester’s addCallMethod method ![]() . They’re used to set various Contact properties. For instance, a call such as dig.addCallMethod("address-book/contact/ name", "setName", 0) calls the setName method of our Contact instance. It does this when Digester starts processing the <name> element, found under the parent <address-book> and <contact> elements. The value of the setName method parameter is the value enclosed by <name> and </name> tags. If you consider our sample address book from listing 7.2, this would call setName("Zane Pasolini").
. They’re used to set various Contact properties. For instance, a call such as dig.addCallMethod("address-book/contact/ name", "setName", 0) calls the setName method of our Contact instance. It does this when Digester starts processing the <name> element, found under the parent <address-book> and <contact> elements. The value of the setName method parameter is the value enclosed by <name> and </name> tags. If you consider our sample address book from listing 7.2, this would call setName("Zane Pasolini").
We use Digester’s addSetNext method ![]() to specify that the populateDocument(Contact) method should be called when the closing </contact> element is processed. The getDocument method takes an InputStream to the XML document to parse. Then we begin parsing the XML InputStream
to specify that the populateDocument(Contact) method should be called when the closing </contact> element is processed. The getDocument method takes an InputStream to the XML document to parse. Then we begin parsing the XML InputStream ![]() . Finally, we populate a Lucene document with fields containing data collected by the Contact class during parsing
. Finally, we populate a Lucene document with fields containing data collected by the Contact class during parsing ![]() .
.
It’s important to consider the order in which the rules are passed to Digester. Although we could change the order of various addSetProperties() rules in our class and still have properly functioning code, switching the order of addObjectCreate() and addSetNext() would result in an error.
As you can see, Digester provides a high-level interface for parsing XML documents. Because we’ve specified our XML parsing rules programmatically, our DigesterXMLDocument can parse only our address book XML format. Luckily, Digester lets you specify these same rules declaratively using the XML schema described in the digester-rules DTD, which is included in the Digester distribution. By using such a declarative approach, you can design a Digester-based XML parser that can be configured at runtime, allowing for greater flexibility.
Under the covers, Digester uses Java’s reflection features to create instances of classes, so you have to pay attention to access modifiers to avoid stifling Digester. For instance, the inner Contact class (not shown in the listing) is instantiated dynamically, so it must be public. Similarly, our populateDocument(Contact) method needs to be public because it, too, will be called dynamically. Digester also required that our Document instance be declared as static; in order to make DigesterXMLDocument thread-safe, we have to synchronize access to the getDocument(InputStream) method.
In our final section we briefly consider alternatives to Tika.
7.8. Alternatives
Although Tika is our favorite way to extract text from documents, there are some interesting alternatives. The Aperture open source project, hosted by SourceForge at http://aperture.sourceforge.net, has support for a wide variety of document formats and is able to extract text content and metadata. Furthermore, whereas Tika focuses only on text extraction, Aperture also provides crawling support, meaning it can connect to file systems, web servers, IMAP mail servers, Outlook, and iCal files and crawl for all documents within these systems.
There are also commercial document filtering libraries, such as Stellent’s filters (also known as INSO filters, now part of Oracle), ISYS file readers, and KeyView filters (now part of Autonomy). These are closed solutions, and could be fairly expensive to license, so they may not be a fit for your application.
Finally, there are numerous individual open source parsers out there for handling document types. It’s entirely possible your document type already has a good open source parser that simply hasn’t yet been integrated with Tika. If you find one, you should consider building the Tika plug-in for it and donating it back, or even simply calling attention to the parser on Tika’s developers mailing list.
7.9. Summary
There are a great many popular document formats in the world. In the past, extracting text from these documents was a real sore point in building a search application. But today, we have Tika, which makes text extraction surprisingly simple. We’ve seen Tika’s command-line tool, which could be the basis of a quick integration with your application, as well as an example using Tika’s APIs that with some small modifications could easily be the core of text extraction for your search application. Using Tika to handle text extraction allows you to spend more time on the truly important parts of your search application. In some cases, such as parsing XML, Tika isn’t appropriate, and you’ve now seen how to create your own XML parser for such cases.
In the next chapter we’ll look at Lucene’s contrib modules, which provide a wide selection of interesting functionality that extends or builds on top of Lucene’s core functionality.