
Chapter 16. Batch applications and enterprise integration
- Quick introduction to batch applications and Spring Batch
- Using batch applications in enterprise integration
- Combining the functionality of Spring Integration and Spring Batch
An important niche in the landscape of software solutions is occupied by batch processes—applications that run independently with no user interaction. Akin to living fossils, they’re a glimpse into the history of computing. At the beginning of the computing era, collecting data and feeding it to programs that ran on mainframes was the only efficient option. Access to the actual system, let alone the idea of a user interface, was restricted to a limited number of operators.
Technology has evolved since then, and progress in user interface and communications technology has led to their gradual replacement with more interactive solutions. But, resorting again to an analogy with evolutionary biology, the secret of the survival of batch applications is the specific set of traits that ensured that they remain a superior solution in specific use cases.
By the end of this chapter, you’ll be familiar with the most significant features of batch applications, recognizing the main differences between them and other paradigms, such as online transaction processing. In the context of this book, batch applications are important for their role in enterprise integration.
Because this book focuses on Java enterprise software development, we highly recommend one of Spring Integration’s siblings, Spring Batch, as an implementation solution (and if you take a strong interest in batch job implementation, we also recommend you read Spring Batch in Action to learn about it in detail). In this chapter, you get a quick glimpse of how to use it for implementing a typical batch job example. Apart from that, you’ll find no sibling rivalry here; the two frameworks complement each other well to produce sophisticated, event-driven, and highly scalable applications, and learning about the various integration opportunities will conclude our foray into batch application development.
Let’s begin by looking at what makes batch jobs so special.
16.1. Introducing batch jobs
Before introducing you to Spring Batch, we provide some background on the typical features of batch applications. This section is a must-read if batch applications are new or unfamiliar to you, and it’s a recommended read for everyone else. It focuses on the main concepts and concerns that drive the design and implementation of batch jobs in general, laying the foundation for the next section’s insight into the specifics of Spring Batch.
A quick definition of batch processing would describe it as the execution of a set of programs (called jobs) with little to no manual intervention. Their working model is that the input data is collected in advance and provided up front in a machine-readable format, such as files or database entries, and the output is, in counterpoint, machine consumable as well. As a result, these applications aren’t user-driven, and the set of operations that can be performed manually is limited to starting a job and introducing its input parameters (such as the location of the input file or other values relevant to a particular execution of the program) as well as checking the results and perhaps restarting failed jobs if necessary. Currently, this application model faces strong competition from online transaction processing, which was made possible by advances in user interface technology and communications infrastructure.
16.1.1. Online or batch, that’s the question
To understand the differences between the two approaches, as shown in figure 16.1, consider a payment processing application. The online transaction processing approach would take the payments as soon as they’re submitted, contact the buyer’s and seller’s financial institutions, execute the debit and credit operations, and return a confirmation immediately. The batch processing approach bundles the payments and processes them later. We stress the importance of bundling as opposed to simple deferral. Batch processing isn’t the same as asynchronous processing whereby requests are buffered until the system can process them; in such cases, the input is still granular and consists of a single request at a time. What’s characteristic for batch applications is that multiple requests (potentially of an order of magnitude of millions of items) are provided as input at once.
Figure 16.1. Online versus batch processing: requests are processed individually or as a group respectively
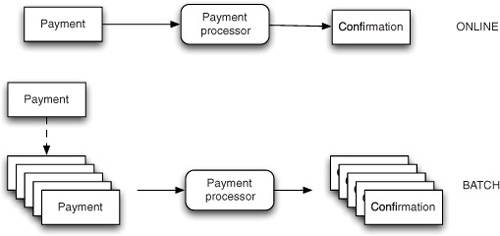
In some use cases, such as airline reservations, using a batch processing approach makes little sense. You could collect the travel information and process requests overnight, returning an answer with the available options on the next day. It’s an absurd example, but it serves to explain why highly interactive and online transaction processing systems gained so much traction. In such situations, users want to receive answers immediately and be able to act on them: what if there’s limited seating on the flight of their choice? But there are specific cases when processing items in a batch is necessary or at least preferable.
16.1.2. Batch processing: what’s it good for?
For one thing, some business processes are based on the concept of gathering data during the day and processing them overnight. For example, processing credit card transactions in batches as opposed to in real time is preferred because of the increased security (when the list of transactions is sent once a day, it’s easier to monitor and authorize than if interactions take place randomly, and this approach also simplifies logistics).
In other cases, batch processing is used for importing data outside the normal usage hours of the application. This may be necessary for avoiding data inconsistency. Consider an online store that needs to update its products catalog every month; the store might need to be offline while the catalog is updated. Likewise, processing during off-peak times may be preferred for performance reasons—for example, a large import that involves writing a massive amount of data to the database can seriously impair the performance of a running application that uses the same storage system because of the high resource consumption or frequent table locking that may need to take place during the import.
Extract, transform, and load (ETL) processes (see figure 16.2) are frequently used in enterprise integration for transferring data between applications.
Figure 16.2. A typical ETL job: data is extracted from an external source, transformed, and loaded into the target

This is a fairly generic description of a batch job, and at a first glance, it looks simple—a lot of batch jobs are implemented as scripts or as simple stored procedures that are executed periodically. A closer look reveals that they have a complex set of requirements, which in certain cases require a significantly more sophisticated approach. Let’s look at an example to guide us through the intricacies of a batch job implementation.
16.1.3. Batch by example
Consider the case of a batch payment processing system. At the end of each day, the day’s transactions are submitted in a file and, overnight, the accounts in the system must be updated. The transactions are transmitted as a text file, each line containing the payer and payee accounts and the amount that’s transferred between them, as well as the transfer date, as in the following listing. This application must record the payments and update the payer and payee accounts accordingly.
Listing 16.1. An input file for a batch job; each row represents an individual item
1,2,2.0,2011-01-03 3,4,10.0,2011-01-03 5,1,22.0,2011-01-04 1,2,21.75,2011-01-04 ... 4,2,9.55,2011-01-05
The general outline of the batch job is shown in figure 16.3.
Figure 16.3. A simple batch job definition: the transactions are loaded from the input file  , parsed
, parsed  , processed
, processed  , and written to the database
, and written to the database 

Input Data Must be Streamed
Each row of the input file represents a payment, and this application must parse this data and convert it into data structures. Because of the data volume, it’s impractical to assume that the whole file will be loaded in memory and parsed from there. The transaction log may contain millions of records, and the sheer amount of memory necessary to hold that data might exceed the physical capacity of the machine—and if it doesn’t, it’ll cripple the performance of the application nevertheless.
Instead of doing that, the application must process the input data gradually, row by row—in other words, it must be capable of streaming the data. Streaming may need to be performed for a wide variety of input sources ranging from input files, for which the application must implement its own strategy of partitioning the content into records, to database access, where the records are already well defined, but the application may still need to maintain an open cursor so it can deal with a large amount of input data (consider a SELECT statement returning millions of data records).
Working in Chunks
Reading data is only half of the problem. Gradually reading and processing input data implies gradually writing output data as well. More often than not, the goal of processing is to transform each input item into one or more output items (the alternative being a simple aggregate calculation). To ensure data consistency, operations must be transactional. The simplest approach, which isn’t necessarily the right one, would be to process each item in its own transaction. But that may be inefficient because every transaction start and subsequent commit introduces overhead. The impact of the overhead depends on how many transactions need to execute within a given time period, which is why it can be neglected in an online system, where items are processed as soon as they arrive, but the impact may be severe when a huge number of items are submitted for processing as a batch. The solution in this case is to span a transaction over a chunk of multiple items. The size of a chunk varies from case to case; large chunks will buffer the items in memory and drain resources, at the same time risking the loss of data if an error occurs, whereas extremely small chunks limit the benefit of this strategy.
Dealing with Failure
If the application fails while processing an item, it has a few options regarding what to do next: it can ignore the current item and pass to the next; it can retry processing the item; or it can abort the process altogether. A robust implementation should provide an automatic mechanism that can decide, based on the nature of the error, whether the application should retry processing the item (if the error is the result of a temporary condition), skip it (if the error is nonrecoverable but losing this piece of data is noncritical), or completely abort the execution.
When a batch process stops because of an irrecoverable error, it usually needs to be restarted after the errors are fixed. But usually this doesn’t mean that everything has to be started again from the beginning. Consider an application that’s importing data. Restarting the process after half of the data has been imported can mean, in the best case, that the items previously imported will be overwritten, and in the worst case, that they’ll be imported twice. Ideally, the state of the batch process must be persistent, and the application must provide the necessary infrastructure for recovering after a crash by resuming from where it left off.
As you can see, even if the business logic isn’t too complicated, implementing a batch application can become a complex task because of the additional requirements for streaming, chunking, and recoverable execution. As is always the case with enterprise middleware, most of the effort may be spent on the infrastructure instead of the business logic. Fortunately, as sophisticated as they are, the fact that almost all batch applications share a common set of requirements presents a good opportunity to provide a generic solution: a framework.
16.2. Introducing Spring Batch
Spring Batch is a batch application development framework built on top of Spring. As a batch-oriented framework, it provides the generic constructs and infrastructure that implement the main components of a batch job, allowing you to fill in the details with your own implementation. Being built on top of Spring, it can take advantage of the container’s features, such as dependency injection, handling of cross-cutting concerns, and the extended set of modules that simplify messaging and database access, including Object-Relational Mapping (ORM) integration.
Fundamentally, Spring Batch covers the implementation of a batch process by providing the following essential capabilities:
- A batch job skeleton and a toolkit of components for building the definition of a batch process as a collection of Spring beans
- A job execution API that allows you to launch new job instances
- A state management infrastructure
We illustrate how Spring Batch provides these facilities through a simple batch process.
16.2.1. A batch job in five minutes
To complete a reservation, our travel agency must receive the payment for it. The transactions are carried out through an external payment system. Overnight, the application must be updated with the transactions that took place during the day. The transactions are transmitted as a text file, each line containing the payer and payee accounts and the amount that’s transferred between them. The application must record the payments and update the payer and payee accounts accordingly.
The batch job definition for this example is shown in the following listing.
Listing 16.2. Batch process definition in Spring Batch
<batch:job id="importPayments">
<batch:step id="loadPayments">
<batch:tasklet>
<batch:chunk reader="itemReader" writer="itemWriter" commit-interval="5"/>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="itemReader" class="org.springframework.batch.item.file.FlatFileItemReader" scope="step">
<property name="resource" value="file:///#{jobParameters['input.file.name']}"/>
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<property name="names" value="source,destination,amount,date"/>
</bean>
</property>
<property name="fieldSetMapper">
<bean class="com.manning.siia.batch.PaymentFieldSetMapper"/>
</property>
</bean>
</property>
</bean>
<bean id="itemWriter" class="com.manning.siia.batch.PaymentWriter">
<constructor-arg ref="dataSource"/>
</bean>
The example uses the dedicated Spring Batch namespace as a domain-specific language to define batch jobs. Every batch job consists of a sequence of steps. More sophisticated applications can have multiple steps, but this example has just one: importing the batch file.
The most common way to implement a step is delegating to a tasklet, which defines the activity that must be performed, leaving the proper step implementation to deal with the boilerplate aspects of the execution (maintaining state, sending events, and so on). The work performed in a tasklet can be a simple service call or a complex operation. The most typically used tasklet implementation is the chunk-based tasklet (see figure 16.4), which processes a stream of items and writes back the results in bulk. The streaming and chunking aspects of batch processing can be easily identified: the ItemReader parses the raw input into a stream of items, releasing data as soon as a complete item is read; the ItemProcessor handles any data transformations (if necessary); and the ItemWriter aggregates output data and writes it back as soon as a chunk is assembled.
Figure 16.4. Chunk-oriented step: items are read individually by the ItemReader, optionally processed by the ItemProcessor, then written in bulk by the ItemWriter

The framework allows for constructing batch jobs that consist of multiple steps, so, for example, the job may need to execute some additional tasks after importing the data, and a multistep job is the right way to do so. Also, steps may specify various levels of fault tolerance, allowing the process to retry or skip items for certain types of exceptions rather than stop a job if an error occurs.
Your responsibility as an application developer is to provide the application-specific details of the job: the item reading, item processing, and item writing strategies. In practice, you don’t have to implement all of it. Spring Batch provides its own toolkit of predefined components, which includes support for reading a file and transforming its content into a sequence of individual items. Your responsibility in this case is to provide the strategy for transforming the individual row content into an object that can be further processed, as illustrated by the PaymentFieldSetMapper class from the following listing. The location of the file can be passed as a job property (more about it in the next section) so that you can execute this job for different physical files.
Listing 16.3. A FieldSetMapper converts raw input into a domain object
public class PaymentFieldSetMapper implements FieldSetMapper<Payment> {
@Override
public Payment mapFieldSet(FieldSet fieldSet) throws BindException {
Payment payment = new Payment();
payment.setSourceAccountNo(fieldSet.readString("source"));
payment.setDestinationAccountNo(
fieldSet.readString("destination"));
payment.setAmount(fieldSet.readBigDecimal("amount"));
payment.setDate(fieldSet.readDate("date"));
return payment;
}
}
The same goes for writing the item back. Your only responsibility is to provide a strategy for persisting the read data in the form of an ItemWriter implementation (PaymentWriter in this sample).
As you can see, the batch job definition can be created as Spring beans, using dependency injection for customizing various aspects such as the tasks that must be performed during the job or the read and write strategies. In most cases, you can use one of the out-of-the box reader implementations and customize it for your application’s needs so that you can avoid the critical yet tedious tasks of dealing with file line reading, database cursors, and so on. The only things you need to provide are what’s specific to your application: a definition of your business entities, a strategy for converting the basic records read from the file to these entities, and the functionality that needs to be performed with these entities once they’re extracted from the incoming stream.
Next you need to set up the infrastructure so that you can execute the job.
16.2.2. Getting the job done
What you’ve created so far is the definition of a batch job. To put it to work, you must start it using the job execution API. To get access to that, you must define a distinct type of bean in your context definition: a batch job launcher, shown in the following listing.
Listing 16.4. A JobLauncher bean is used for starting job executions
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository"/>
</bean>
With this definition in place, you can start a new batch job as in the following example (noting that the Job instance is the bean defined in the previous section):
JobParametersBuilder jobParametersBuilder = new JobParametersBuilder();
jobParametersBuilder.addString("input.file.name", "payment.input");
JobExecution execution =
jobLauncher.run(job, jobParametersBuilder.toJobParameters());
The role of the JobLauncher is to create a new batch job instance according to the Job definition. The JobParameters passed as arguments while launching the job fulfill a dual role: as their name indicates, you can use them to pass particular properties that are specific to this job execution instance (such as the name of the file that needs to be processed), and you can also use them as unique identifiers of the Job execution.
There can be no two JobExecutions for the same Job and JobParameters set of values. This is an important point to take into account when executing batch jobs automatically: when launching a new job instance, the list of parameters must contain at least one unique attribute; otherwise, the launcher will complain that the job has already completed.
The returned JobExecution is a handle that allows the invoker to access the state of the executing Job. Spring Batch supports synchronous and asynchronous execution of batch jobs (which can be configured through the jobLauncher bean definition), which means that the call to JobLauncher.run() may return while the job is in progress. As such, an application may track the progress of a batch job by repeatedly inquiring on the JobExecution instance about the current state.
This leads us to the third and final component of Spring Batch: the job execution state management infrastructure.
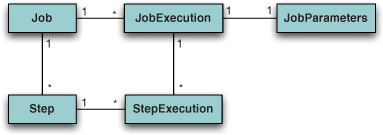
You got a hint in the previous section about what we discuss in the next section. The JobLauncher bean we configured in listing 16.4 is injected with a jobRepository. As we explained earlier, the state of the batch jobs is persistent so that jobs can be resumed after a failure or a shutdown. Resuming a job that stopped in the middle of processing a data stream requires avoiding the potential duplication of data that may occur as a result of processing items twice. The job repository records the ongoing progress of the running batch jobs, including information such as the current step and how far the application got while processing the data stream that corresponds to a particular step.
Figure 16.5. The relationship between Spring Batch entities: Job and Step define the logic of a job, JobExecution and StepExecution are used to save the state, and JobParameters customizes a specific job instance
Unless you have special needs, all you need to do to create a job repository is include a bean definition in your context. The repository uses a set of database tables, which can be created automatically when the repository is instantiated for the first time:
<batch:job-repository data-source="dataSource" id="jobRepository" transaction-manager="transactionManager" table-prefix="BATCH_"/>
This concludes our quick overview of Spring Batch and its capabilities. As you can see, it allows you to create pretty complex batch jobs, launch them, and manage and interrogate their state, all while writing only a limited amount of code. Let’s see what opportunities are available for using all these capabilities in enterprise integration scenarios and, mainly, how Spring Batch can complement Spring Integration.
16.3. Integrating Spring Batch and Spring Integration
Using Spring Batch greatly simplifies the process of implementing a batch job. Apart from the job implementation, a complete solution must be able to schedule and launch jobs automatically, monitor them, and interact with the environment and other applications. For achieving these goals, implementors must look beyond the framework.
Fortunately, this goal can be achieved with minimal effort by pairing Spring Batch with Spring Integration. The two frameworks complement each other, and together they can provide a complete solution for creating enterprise integration applications that use batch processes for handling large quantities of data.
Spring Batch Admin is an open source project that provides a web-based administration console for Spring Batch applications. It has access to a set of job definitions and a job repository, and it provides support for
- Inspecting jobs and adding new job definitions
- Launching and stopping jobs, including uploading data files that can be used as input when launching a job
- Inspecting job execution state
Of interest to our topic is that most of the interaction between the web application and the batch jobs is done via Spring Integration. Spring Batch Admin provides a set of utility classes that implement most of the collaboration patterns discussed in this section and can be used out of the box in your applications.
We examine the various ways in which Spring Integration and Spring Batch can collaborate, and we present examples that use components provided by the spring-batch-integration module of Spring Batch Admin.
16.3.1. Launching batch jobs through messages
Let’s assume that you finished implementing the batch job, as described in the previous section. The next step is to launch it, which you can do from the Spring Batch API by invoking JobLauncher.run()with the appropriate parameters. But how does this method get called in an application? You can write a web application that invokes the method from a controller, or you can invoke it from the main() method of a launcher class for command-line operation. In the latter case, you can create a shell script or schedule the batch job using a scheduler such as cron.
But you can create even more powerful scenarios, such as running batch jobs in an event-driven fashion, for example, whenever a file is dropped in a target directory. Using Spring Integration, it’s easy. A file channel adapter will monitor the directory and send out a message whenever a new file is detected, as shown in figure 16.6.
Figure 16.6. Event-driven batch job launch: the file channel adapter monitors a directory , a file message is converted to a JobLaunchRequest , which triggers the batch job launch (). Other components may trigger a launch by sending a File payload  .
.
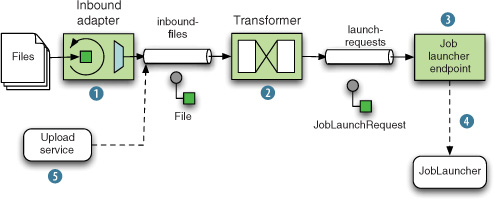
Spring Batch Admin provides a JobLaunchingMessageHandler that can be used to launch batch jobs based on information provided by an inbound message with a JobLaunchRequest payload, which is a wrapper around the Job that needs to be launched and the JobParameters for this launch. The configuration for such a message flow is displayed in the following listing, where the launching message is triggered by dropping a file in a directory monitored by a file channel adapter.
Listing 16.5. Triggering jobs with messages sent by a file channel adapter
<si:channel id="files"/>
<si:channel id="requests"/>
<si:channel id="statuses">
<si:queue capacity="10"/>
</si:channel>
<si-file:inbound-channel-adapter
directory="classpath:/${incoming.directory}"
channel="files"/>
<si:transformer input-channel="files" output-channel="requests">
<bean class="com.manning.siia.batch.FileMessageToJobRequest">
<property name="job" ref="importPayments"/>
<property name="fileParameterName" value="input.file.name"/>
</bean>
</si:transformer>
<si:service-activator method="launch" input-channel="requests"
output-channel="statuses">
<bean
class="org.springframework.batch.integration.launch.JobLaunchingMessageHandler">
<constructor-arg ref="jobLauncher"/>
</bean>
</si:service-activator>
Whereas most of the components are provided out of the box, the conversion between the file sent by the channel adapter and the JobLaunchRequest is application-specific and therefore must be implemented as part of the solution. An example is shown in the following listing.
Listing 16.6. Transforming a file into a JobLaunchRequest
public class FileMessageToJobRequest {
private Job job;
private String fileParameterName;
public void setFileParameterName(String fileParameterName) {
this.fileParameterName =fileParameterName;
}
public void setJob(Job job) {
this.job = job;
}
@Transformer
public JobLaunchRequest toRequest(Message<File> message) {
JobParametersBuilder jobParametersBuilder =
new JobParametersBuilder();
jobParametersBuilder.addString(fileParameterName,
message.getPayload().getAbsolutePath());
return new JobLaunchRequest(job,
jobParametersBuilder.toJobParameters());
}
}
The event-driven approach for launching jobs is extremely flexible, allowing for a large number of variations in implementation. For example, any kind of channel adapter output can be transformed into a JobLaunchRequest, so you can trigger the batch jobs for inbound emails, Java Message Service (JMS) messages, or File Transfer Protocol (FTP)-accessible files. As a matter of fact, the trigger doesn’t even have to be a message source; for example, a generic scheduled channel adapter, as shown in chapter 15, may be used for launching batch jobs periodically.
Besides the sheer variety of sources, another benefit of integrating the batch job launch into a pipes-and-filters architecture is the ability to take on multiple input formats simultaneously. The batch job may require a canonical format, but different sources of data may use different formats. Spring Integration transformers could be added between the source adapters and the channel expecting the canonical format.
But message-based integration can work either way: not only can batch processes be launched using messages, but they can also send notifications while they change state.
16.3.2. Providing feedback with informational messages
A batch job can run for a long time. For operators, it’s critical to get up-to-date information about its progress, and most important, whether it completed successfully or had to stop because of a nonrecoverable failure. As many similar situations, this information can be gathered through active polling or in an event-driven manner.
Spring Batch provides a JobExecution class that reflects the current status of the eponymous job execution, so the application that launched the job can use it as a handle for inquiring whether the job is complete or still running, what its current status is, if it stopped because of an error, and so on; and in the case of running processes, it can be used to stop them. But polling the JobExecution repeatedly is suboptimal. An event-driven approach is superior and preferable.
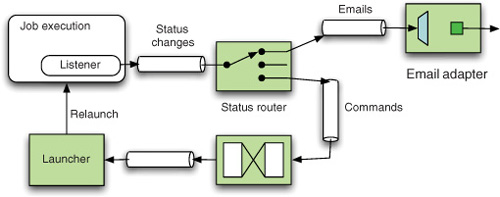
Spring Batch provides a mechanism for registering listeners such as StepListener, ChunkListener, and JobExecutionListener that get invoked during the execution of a job on events such as before and after processing an item, on read/write errors, or on the completion of a job execution. Figure 16.7 shows an example of using listeners for message-based integration. In this example, a JobExecutionListener registered with the Job sends a notification message with a JobExecution payload after a job has stopped running. A router decides, based on the execution status, whether it’s necessary to take any further steps (such as relaunching the job if it failed and the failures are recoverable, perhaps with a delay), in which case the message is sent to an appropriate endpoint to be processed, or it’s a matter of sending a notification message (completion was successful or the failures are nonrecoverable), in which case the message is sent to an outbound email channel adapter.
Figure 16.7. Handling batch events using informational messages
For this, you need to add the listener to the job definition and add the rest of the bus configuration, as shown in the following listing.
Listing 16.7. Registering a job listener and handling batch notifications
<batch:job id="importPayments">
<!-- other properties omitted -->
<batch:listeners>
<batch:listener ref="notificationExecutionsListener"/>
</batch:listeners>
</batch:job>
<si:gateway id="notificationExecutionsListener"
service-interface="org.springframework.batch.core.JobExecutionListener"
default-request-channel="jobExecutions"/>
<si:router id="executionsRouter" input-channel="jobExecutions">
<bean class="com.manning.siia.batch.JobExecutionsRouter"/>
</si:router>
<si:chain input-channel="jobRestarts">
<si:delayer default-delay="10000"/>
<si:service-activator>
<bean class="com.manning.siia.batch.JobRestart"/>
</si:service-activator>
</si:chain>
<si:transformer id="mailBodyTransformer"
input-channel="notifiableExecutions"
output-channel="mailNotifications">
<bean class="com.manning.siia.batch.ExecutionsToMailTransformer"/>
</si:transformer>
<si:channel id="mailNotifications"/>
<si-mail:outbound-channel-adapter id="notificationsSender"
channel="mailNotifications" mail-sender="mailSender"/>
Message-driven job launching and message-driven notifications are two examples of Spring Batch/Spring Integration collaboration, which expands the feature set of the application and builds upon complementary features of the two frameworks to provide a scalable execution infrastructure.
16.3.3. Externalizing batch process execution
The way we’ve described it so far, it would seem that the natural way to combine the two frameworks is by wrapping Spring Batch jobs in a Spring Integration outer shell that can take care of the interactions with the external world. But that isn’t the only way. Spring Batch can use Spring Integration internally, too, for delegating the processing of an item or even a chunk outside the process.
In a simple case, the ItemProcessor can be a messaging gateway, as shown in figure 16.8, thus deferring the processing of items to the message bus. This is useful when item processing logic is fairly complex and involves invoking multiple transformations or service invocations, either local or remote (through the use of channel adapters and gateways). When item processing on the bus takes a relatively long time, such as when the application performs a remote invocation, you can increase performance by introducing asynchronous item processing. You use two wrapper components provided by Spring Batch Integration for your item processor and item writer: AsyncItemProcessor and the corresponding AsyncItemWriter. This is essentially a fork-join scenario: by using the AsyncItemProcessor, the invocations on the gateway are performed concurrently rather than sequentially, leaving the AsyncItemWriter to gather the results and write back the chunk as soon as all the results are available.
Figure 16.8. A gateway is used as an ItemProcessor.

In a more elaborate use case, shown in figure 16.9, an application can use a writer, for example the ChunkMessageChannelItemWriter provided by Spring Batch Integration, to send an entire chunk externally to a gateway. In this case, the batch job only reads items and groups them, and once a chunk is sent out, it continues to read items and assemble chunks without waiting for a result. It’s the job of the ChunkMessageChannelItemWriter to get the results from the gateway and integrate them in the batch process. By introducing asynchronous processing (for example, by using a queue channel instead of a direct channel), you can increase the concurrency of the system. By using channel adapters, you can completely externalize the processing of a chunk, creating the premise of a distributed architecture. For example, you can use a JMS channel adapter to send chunks on a message queue, letting external components read the chunks, handle them individually, and return information about their successful completion.
Figure 16.9. Externalizing chunk processing by using a gateway

The latter part is necessary because the batch process must update the Job-Execution state continuously to acknowledge whether the step execution succeeded. Because of that, the request and response messages contain metadata that helps the batch job executor carry out this process (Did we get responses for all chunks? Were there any errors?). The chunk messages are received by another special component, the ChunkProcessorChunkHandler, which processes the chunk by delegating to an ItemProcessor and ItemWriter.
By looking at Spring Integration as underlying support for boosting the concurrency and distribution capabilities of Spring Batch, we’ve concluded our overview of the collaboration between the two frameworks. It’s time to move on to the next chapter, but first, let’s quickly review the takeaways of this chapter.
16.4. Summary
This chapter provided an overview of batch processes and their typical features, and you gained a general understanding of how they fit in the enterprise integration landscape. In a Java environment, you can create powerful batch processing applications by using Spring Batch, which, in a typical Inversion of Control fashion, provides the infrastructure for defining and executing jobs, including facilities for managing state.
The main strength of Spring Batch is in dealing with the complex details of defining and running batch jobs, such as chunking and transaction management as well as state management. Spring Batch doesn’t include facilities for scheduling batch jobs or executing them in an event-driven fashion, but it finds an ideal companion in Spring Integration, whose strength is in dealing with the challenges of interacting with external systems and creating an event-driven environment that can be used for launching and managing batch jobs.
The two components of the Spring portfolio are complementary frameworks that can and should be used together for implementing a complete batch job–based enterprise integration solution. The integration between the two goes from simple, event-driven launching of batch jobs from Spring Integration to more sophisticated notification and automated feedback mechanisms using events published by Spring Batch and, even beyond that, to creating parallel and distributed batch jobs using Spring Integration as the underlying infrastructure.