
Chapter 7. Splitting and aggregating messages
Previous chapters explained how a single message is processed as a unit. You saw channels, endpoints such as service activators and transformers, and routing. All these components have one thing in common: they don’t break the unit of the message. If one message goes in, either one message comes out the other end or it is gone forever. This chapter looks at situations in which this rule no longer holds. In some situations, one message goes in and several messages come out (splitter), and in others, several messages go in before messages start coming out (aggregator, resequencer). Examples of endpoints illustrating the various possible scenarios are shown in figure 7.1.
Figure 7.1. Examples of endpoints processing a message in one-to-one, one-to-many, and many-to-one scenarios
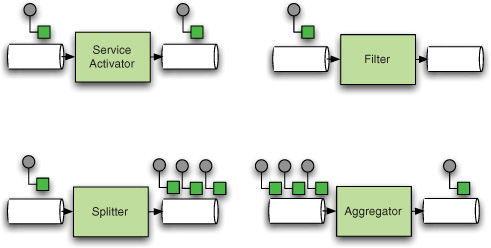
This chapter is the first to introduce stateful endpoints. The resequencer and the aggregator must maintain state because the outcome of handling a given message depends on the previous messages, which isn’t the case for the endpoints described in earlier chapters. The fact that these endpoints maintain state for functional reasons differentiates them also from other stateful endpoints that maintain state for improving performance, such as file adapters, which hold a queue of files in memory to prevent costly file listings (see chapter 11). Not all the endpoints in this chapter are stateful: for example, the splitter, which we introduce for symmetry with the aggregator, is a stateless component. Generally, the fact that components are stateful or stateless plays an important role in the concurrent and transactional behavior of your application, so it’s important to pay close attention to this aspect.
As we discussed in chapter 1, correlating messages is sometimes essential to implementing a certain business requirement. This chapter explains the different options for message correlation, whether your goal is to reassemble a previously split-up array of related data (splitter-aggregator), make sure ordering constraints are enforced on messages (resequencer), or split up work between specialized services (Scatter-Gather pattern). In all these cases, the correlation of the messages is key, so it makes sense to discuss how Spring Integration stores and identifies the correlation of messages and how you can extend this functionality. It’s explained in detail in the “Under the hood” section later in the chapter; for now, it’s enough to understand the functional concept of correlating messages in a group.
7.1. Introducing correlation
The functionality of the components discussed in this chapter—aggregators, splitters, and resequencers—is based on the idea that certain messages are related in a particular way. This section focuses on correlation from a functional perspective, introducing the main concepts behind it.
An aggregator, such as the one in figure 7.2, waits for messages in a certain group to arrive and then sends out the aggregate. In this particular case, the aggregator waits for all the items of an order to come in, and after they are received, it sends an order to its output channel.
Figure 7.2. An aggregator is an endpoint that combines several related messages into one message.

The part we’re interested in first is how it determines what messages belong together. Details follow in later sections. Spring Integration uses the concept of a message group which holds all the messages that belong together in the context of an aggregator. These groups are stored with their correlation key in a message store. The correlation key is determined by looking at the message, and it may differ between endpoints.
Now is a good time to look at an analogy to help anchor the important terms used in this chapter.
7.1.1. A real-life example
Let’s say you’re having guests for dinner. Maybe you’re not the cooking kind, but you’re probably familiar with the concept of home cooking, and that’s more than enough. We’ll look at the whole process of preparing and serving a meal to see what’s involved in automating this process and how it applies in terms of messaging. For the sake of argument, we’ll ignore the possibility of ordering take-out (which would greatly decrease the complexity of the setup but would ruin the analogy). Figure 7.3 illustrates the scenario described in the rest of this section.
Figure 7.3. The flow of messages in the home cooking example

A recipe is split into ingredients that are aggregated to a shopping list. This shopping list is converted into bags filled with products from the supermarket. The bags are then split into products, which are aggregated to a mise en place, which is finally transformed into a meal. The channel configurations are considered trivial and are omitted from the diagram.
Involved in the dinner are the host (that’s you), the kitchen, the guests, and the shops. You orchestrate the whole event; the guests consume the end product and turn it into entertaining small talk and other things irrelevant to our story. The kitchen is the framework you use to transform the ingredients you get from the shop into the dinner.
We’re interested in the sequence of events that take place after a date is set.
It starts with your selecting a menu and gathering the relevant recipes from your cookbook or the internet. The ingredients for the recipes must be bought at various shops, but to buy them one at a time, making a round trip to the shop for each product, is unreasonably inefficient, so you must find a smarter way to handle this process. The trick is to create a shopping list for each shop you must visit. You pick the ingredients from each recipe, one by one, and put them on the appropriate shopping list. You then make a trip to each shop, select the ingredients, and deliver the ingredients back to your kitchen.
With the ingredients now in a central location, each shopping bag must be unpacked and the ingredients sorted according to recipe. Having all the right ingredients (and implements) gathered together is what professional chefs call the mise en place. With all the necessary elements at hand, each dish can be prepared, which usually involves putting the ingredients together in some way in a large container. When the dish is done, it’s divided among plates to be served.
But what does this have to do with messaging? Perhaps more than you think.
7.1.2. Correlating messages
Let’s say the recipe is a message. This message is split into ingredients, which can be sent by themselves as messages. The ingredients (messages) reach an aggregator that aggregates them to the appropriate shopping lists. The shopping lists (messages) then travel to the supermarket where the shopper turns them into bags filled with groceries (messages), which travel back to the kitchen (endpoint).
The shopping bags are unpacked (split) into products that are put together in different configurations on the counter during the mise en place. These groups of ingredients are then transformed into a course in a pan. The dish in the pan is split onto different plates (messages), which then travel to the endpoints that consume them at the table. What we see here is a lot of breaking apart and putting together of payloads. The recipes are split and the ingredients aggregated to grocery lists. The bags are unpacked and the products regrouped for the different courses. The dishes are split and assembled on plates.
Some observations can be made from this analogy that will be helpful to think back on later in the chapter. Splitting is a relatively easy job, but it’s important to keep track of which ingredients belong to which recipe. Messages (ingredients in this example) are given a Correlation ID to help track them. Most easy examples of splitting and aggregating use a splitter that takes a thing apart and an aggregator that turns all the split parts into a thing again. This is a simplistic example, so it’s good to keep a simple analogy in mind that does things differently. In a real enterprise, an aggregator often has no symmetric splitter.
It now becomes important to think about how we’ll know when the aggregate is done. Or to stay with the example, when is the shopping list done? The answer is that it’s only done when all the recipes have been split and all ingredients are on their appropriate list. This is still relatively simple but more interesting than to say that a list is done when all ingredients of one particular recipe are on it.
When aggregating is done without a previous symmetric splitting, it becomes harder to figure out which messages belong together, or in this example, which ingredients go on which list. Usually aggregation relies not on a message’s native key but on a key generated by a business rule. For example, it could be that all vegetable ingredients go on the greenery list and all meat ingredients go on the butcher list. This assumes that you’re not just buying everything from the supermarket, but even if you do, it makes sense to organize your shopping list by type to avoid having to backtrack through the supermarket.
The next sections explain how the components introduced here are used. For those interested in the home cooking example, some code is available on the Spring Integration in Action repository (https://github.com/SpringSource/Spring-Integration-in-Action).
7.2. Splitting, aggregating, and resequencing
It’s common for domain models to contain high-level aggregates that consist of many smaller parts. An order, for example, consists of different order items; an itinerary consists of multiple legs. When in a messaging solution one service deals with the smaller parts and another deals with the larger parts, it’s common to tie these services together with endpoints that can pull the parts out of a whole (splitter) and endpoints that can (re)assemble the aggregate root from its parts (aggregator). The next few sections show typical examples and the related configuration of splitters, aggregators, and resequencers.
7.2.1. The art of dividing: the splitter
The basic functionality of a splitter is to send multiple messages as a response to receiving a single message. Usually these messages are similar and are based on a collection that was in the original payload, but this model isn’t required in order to use the splitter.
Let’s look at an example of splitting in our sample application. Look at flight-notifications.xml to see the starting point of the relevant code. When flight notifications come in, you want to turn them into notifications about trips and send them to impacted users. To do so, you enrich the header of a flight notification with a list of impacted trips. At the end of the chain, you can then use a splitter that creates a TripNotification for each trip related to the flight:
<chain input-channel="flightNotifications"
output-channel="tripNotifications">
<header-enricher>
<header name="affectedTrips"
ref="relatedTripsHeaderEnricher"
method="relatedTripsForFlight"/>
</header-enricher>
<splitter>
<beans:bean
class="siia.booking.integration.notifications.FlightToTripNotificationsSplitter"/>
</splitter>
</chain>
Interesting to note here is that the payload isn’t chopped up; the splitting is based instead on a list in a header. Spring Integration is indifferent to the splitting strategy as long as it gets a collection of things to send on as separate messages. It’s entirely up to you what those things are.
The home cooking example also contains a splitter, which chops up a recipe into its ingredients:
<chain id="splitRecipesIntoIngredients"
input-channel="recipes"
output-channel="ingredients">
<header-enricher>
<header name="recipe" expression="payload"/>
</header-enricher>
<splitter expression="payload.ingredients"/>
</chain>
As you can see, a chain is used around the splitter to pop references to the original recipe on a header, so you can use it as a correlation key later when you aggregate the products. The splitter is a simple expression that gets the ingredients (a list) from the recipe payload.
Splitters are relatively simple to configure. You can use a plain old Java object (POJO) or a simple Spring Expression Language (SpEL) expression to retrieve the desired information from the message in the form of a List.
7.2.2. How to get the big picture: the aggregator
We looked at splitting messages using a splitter. Before we think about doing the reverse, we need to think backwards through the splitting process. The splitter outputs sets of messages, each generated by a single message received by the splitter. It’s the original message that correlates them (see section 7.2).
In Spring Integration, messages that are correlated through a correlation key can be grouped in certain types of endpoints. These endpoints keep the notion of a MessageGroup, discussed in the section “Under the hood” later in this chapter.
Messages can belong to the same group for many reasons. They may have originated from the same splitter or publish-subscribe channel, or they may have common business concerns that correlate them. For example, the flight notification application could have a feature that allows users to have the system batch the notifications they receive per email on the basis of certain timing constraints. In this case, there’s no concept of an original message; you’ll often see examples where aggregating isn’t used in relation with any splitting logic.
Back in the kitchen, aggregation is also going on. Remember popping the recipe on a header? Now when you aggregate the products from the stores back together, you can use this recipe as a correlation key:
<aggregator
id="kitchen"
input-channel="products"
output-channel="meals"
ref="cook"
method="prepareMeal"
correlation-strategy="cook"
correlation-strategy-method="correlatingRecipeFor"
release-strategy="cook"
release-strategy-method="canCookMeal"/>
The aggregator called kitchen refers to a cook for the assembly of the meal. The cook has a method to aggregate the products:
@Aggregator
public Meal prepareMeal(List<Message<Product>> products) {
Recipe recipe = (Recipe) products.get(0).getHeaders().get("recipe");
Meal meal = new Meal(recipe);
for (Message<Product> message : products) {
meal.cook(message.getPayload());
}
return meal;
}
This snippet shows how a group of related products are assembled into a meal, but it doesn’t show how these messages are related and when they’re released. More details on this are found in the “Under the hood” section. For now, we just show the implementations of correlation strategy (to determine which message belongs to which group) and release strategy (to determine when a group is offered to the cook).
The correlation strategy relates products according to their recipe:
@CorrelationStrategy
public Object correlatingRecipeFor(Message<Product> message) {
return message.getHeaders().get("recipe");
}
The release strategy delegates to the recipe to determine if all the ingredient requirements are met by products:
public boolean canCookMeal(List<Message<?>> products) {
Recipe recipe = (Recipe) products.get(0).getHeaders().get("recipe");
return recipe.isSatisfiedBy(productsFromMessages(products));
}
But gathering related messages and processing them as a group isn’t the only use case for correlation. Another component works similarly to the aggregator and can be used to make sure messages from the same group flow in the correct order: the resequencer.
7.2.3. Doing things in the right order: the resequencer
When different messages belonging to the same group are processed by different workers, they may arrive at the end of a message flow in the wrong order. As we saw in chapter 3, there is a priority channel that can order messages internally, but this channel doesn’t consider the whole group. Instead, it passes along the message first in line, not caring about gaps in the sequence caused by messages that haven’t yet arrived at the channel.
The solution for this problem is a resequencer. It can guarantee that all messages in the group arrive in exactly the right order on the resequencer’s output channel. This pattern is more like an aggregator than you might realize at first glance. Like the aggregator, the resequencer has to wait for several members of a group of correlated messages to arrive before it can make a decision to send a message to its output channel.
Before looking at examples of where a resequencer might be useful, we offer a word of warning. From an architectural perspective, depending on the ordering of messages is almost without exception a problem when scaling and performance are at stake. The problem arises because the resequencer is a stateful component, and to guarantee that all messages of the sequence arrive in the right order, the only way to clean up the state from a resequencer is to ensure that all messages of the sequence have been sent to it.
As a rule, you should only depend on resequencing within a single node and only if the whole sequence can reasonably be expected within a short time. What is reasonable and short wholly depends on the characteristics of your application and target environment.
Recovering from message loss or timeouts is far from trivial when you have sequence dependencies. If you can design the system in such a way that messages which are older than the last message processed are simply dropped, this is a fundamentally more robust solution. That said, in some cases resequencing is convenient, so you should understand the concept.
Good recipes give the ingredients in an order that makes sense for the preparation. But as you split the ingredients lists and spread the items out over multiple shopping lists, you end up with the ingredients in a different order than they should be.
When groups of messages are processed concurrently, say, when you start splitting recipes with multiple people or when you let multiple people shop at the same time, it’s obvious that you introduce race conditions. As long as no checking is done later and no ordering requirements are presented, you won’t see any negative side effects. Remember this rule of thumb: adding concurrency increases the random reordering of messages.
On the shopping list, the ingredients are in semi-random order determined by the order in which the recipes are split. Because stores generally arrange their products by type, it’s most efficient for you to organize your list in the same way. This is a traveling salesman problem[1] that can be simplified by assuming the shop has only one possible walking route and you only have to avoid backtracking.
1 A traveling salesman problem is the problem of finding the shortest route that visits all destinations from a given set exactly once.
It’s important to make sure the shopping list is reordered when it’s completed (not before). This is done by the resequencer, which is much like the aggregator, but instead of releasing a single message, it releases all messages ordered according to their sequence number or a custom comparator. In the shopping example, the sequence number isn’t used, but instead, the ingredients are compared in shopping-list order.
Using a custom comparator, it’s not possible to release partial sequences because you can’t know in advance whether another ingredient might need to be inserted in the middle of the list.
When doing the mise en place, it’s a good practice to arrange the ingredients in the order they appear in the ingredient list. The mise en place is essentially the resequencing of the correlated ingredients according to the order in which they appear in the recipe. This happens just before they’re aggregated into the pan (or bowl or what have you).
For this example of resequencing, you can depend on the sequence number and size set by the recipe splitter. Therefore, you can release partial sequences. If your ingredients list starts with onions and lists garlic as a second item, you can be sure that if you pull the onions and the garlic out of the shopping bag first, you can prepare them before pulling the next items out.
This should give you some idea of how to think about resequencing in an everyday life scenario. In most complex enterprise applications, it’s possible to find an analogy, using your favorite subject, that fits well with what should happen. Car and kitchen metaphors will carry you a long way as an architect.
After reading this section, you should have a good general idea of what splitting, aggregating, and resequencing are and how you can use them in an architecture. The next section elaborates a bit more on some common but nonstandard configurations.
7.3. Useful patterns
Our example cases so far have shown the most obvious correlations between messages: a well-defined group of payloads that are released as a group. This isn’t the only possible use for correlation, though, and this section elaborates on two other use cases: timing-based aggregation and the scatter-gather pattern. Both demonstrate that aggregation involves much more diverse scenarios than you might first think. The way the different payloads and headers are aggregated is important, and so are the ways of determining what messages belong together and how strong this correlation is from a business point of view.
Many scenarios don’t operate with groups of individual messages that can be aggregated together like the order items that belong to a specific order. They operate in a looser fashion: the groups have certain requirements concerning the numbers or kinds of payloads that must be present in the group before release, but, for example, payload instances of the same kind may be interchangeable. Consider an order trading system: the condition for making a trade and releasing a group of messages is to find a match between the buy (long) and sell (short) orders. For example, broker A places a long order for 1000 shares for Glorp Corporation, and then customer B places a short order for 600 Glorp shares, and customer C places a short order for 400 Glorp shares. These three orders can be fulfilled against each other, but if a customer D then placed a long order of 500 Glorp shares, its order could also be fulfilled against customer B’s short order. The outcome depends greatly on the sequence in which the orders arrive, including timing.
Race conditions like this one are often inevitable because being completely fair is impractical, if not impossible, given the performance requirements. A heuristic approach is a better fit, and various patterns have emerged in an attempt to offer a satisfactory, albeit not ideal, solution. The next two sections focus on two common patterns in aggregation that don’t immediately fall under the straightforward example of taking something apart and putting it back together. The first section explores aggregation based on nothing but timing, and the second section deals with scatter-gather.
7.3.1. Grouping messages based on timing
In many aggregator use cases, completion is based not only on the group of messages but also on external factors such as time. Let’s look into such a scenario and see how it’s supported by Spring Integration.
Refining the Shopping List Aggregation
Let’s think back on the dinner example. When, as the host, you’re aggregating ingredients on the shopping lists, you can of course wait until all recipes have been split before going to the store, but that might make for a very long list. It might also take a lot of time; say, for example, 10 minutes longer than if you were to give your spouse a partial list so they could leave for a particular shop while you wait for the splitting to finish. Then you can give the next part of your unfinished but long list to a friend, who can also start shopping before the splitting is complete. When the splitting is done, you have three separate lists, two of which are already being worked on. This early completion strategy is useful to ensure all workers are busy in a complex system. Big lists are good for optimization, but making a list infinitely big doesn’t help effectiveness.
In terms of Spring Integration’s aggregator support, what should be happening here? First of all, this scenario has a time-based constraint. At a particular time, the aggregated list is sent regardless of whether or not it’s complete. Then, of course, the newly arriving messages must still be aggregated, so multiple aggregates, not just one, are sent. In figure 7.4, you can see how this might work in practice.
Figure 7.4. Before the timeout, just two out of three messages have arrived. On the timeout, the aggregator sums 1 and 3 and sends the aggregate (4). A bit later, it receives the missing 2, which it must send out without the rest of the aggregate.
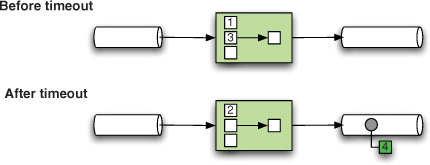
Timing out means a separate trigger is fired when the timeout point is reached. This is fundamentally different from normal release because the timeout event is not based on reception of a message. In Spring Integration 2.0 this functionality has been pushed down from the aggregating message handler into the message store itself. Because timeout is important to the end user, it’s still exposed as a flag on the <aggregator/> element. The message store will give the aggregator a callback when it’s time to timeout, and when you set the send-partial-result-on-expiry flag, the incomplete group will be sent.
The release strategy in a timeout can be unchanged. This means you need to do something else to ensure a partial timeout at some point. It’s sometimes possible to modify the release strategy to always release the group when it finds a certain time has elapsed, but the problem with this approach is that the release strategy is only interrogated when a new message arrives. If it takes a while for messages to arrive, the timeout might pass without a release happening.
When an incomplete group is sent on expiry, the remaining group is usually also incomplete. For example, the default strategy of counting the messages and comparing their number with the sequence size will no longer work. Usually in this case, there’s a business rule that can tell you whether you received all the messages. In the shopping list example, you can check whether all recipes are split already, and because a direct channel is used for sending ingredients, the last group can be completed without checking the size.
As you can see, aggregation can be based on more than just business keys and even on the same key repeatedly. Next we look at a situation in which the different messages are the result of work done on a different collaborating node: scatter-gather.
7.3.2. Scatter-gather
In the most typical cases, aggregating is based on a list of similar messages and splitting is about cutting up the payload of a message. This isn’t always the case, though. In this section, we look at a common use case that doesn’t follow this pattern.
Isn’t Scatter-Gather the Same as Mapreduce?
The next few paragraphs are about the definition of scatter-gather and how it’s different from MapReduce. (Even if you don’t know what MapReduce is, you should be fine with the rest of the chapter.)
Scatter-gather is a name commonly used to refer to a system that scatters a piece of information over nodes that all perform a certain operation on it; then another node gathers the results and aggregates them into the end result. The major difference between it and MapReduce is that, in scatter-gather, the different nodes might have different functions. You can learn about MapReduce from many other resources, and because Spring Integration isn’t a MapReduce framework, we don’t cover it here. It’s important to note that scatter-gather and MapReduce are by no means mutually exclusive; they are complementary, and a good architect should be able to weigh the applicability of both or either of them against the complexity they inevitably add to the system.
Enterprise Integration Patterns (http://www.enterpriseintegrationpatterns.com/) defines scatter-gather as follows: “Scatter-Gather routes a request message to a number of recipients. It then uses an Aggregator to collect the responses and distill them into a single response message.”
This is a broad definition, and it could even be said that MapReduce is a subtype of scatter-gather. We look at an example where the different nodes have different functions so that we’re forced to stay clear of MapReduce concerns.
The home cooking example contains a good candidate for scatter-gather. When you split the ingredients over multiple shopping lists, you might find that certain shops offer the same products. You can implement several behaviors that take this into account.
For example, a certain product might often be out of stock in shops. If so, then it’s no problem to stock more than you need (it’s conservable), so you can try to buy it at all the shops. If you serialize the shopping or allow communication between the shoppers, you could decrease the risk of overbuying.
If you’re looking at an expensive product, you can allow shoppers to compare prices with each other when they’re shopping in parallel. This happens at the cost of synchronization overhead. The amount of synchronization needed here depends on how bad it would be if you bought too much or if you bought it at a higher price.
Our example assumes that no synchronization is done and you’ll try to buy the ingredient at all shops. The one that ends up on the mise en place is closest to the best-before date. Figure 7.5 presents a schematic overview of a this scatter-gather scenario.
Figure 7.5. The needed ingredient is scattered over all shopping lists and sent to each shop (A and B). The gatherer decides, on the basis of the best-before date (or some other criterion), what is the best product to use and sends that to the mise en place (not in this picture).

To scatter an ingredient after splitting, you need to route it to multiple nodes. You can do this by configuring a router that does its best to route to a single shopping list, but if that fails, it routes to a publish-subscribe channel that all the shopping lists are connected to (so it ends up on all lists instead of one).
Another option is to get rid of the router altogether and use a filter in front of each shop that drops all ingredients which can’t be found at the shop. Yet another option is to let the filtering occur naturally by asking each shop for each product and taking all that are available. It depends on the situation which option is more efficient, and we won’t spend time tuning it further here.
Gathering happens when the products come back from the shops. The easiest way is to use whatever comes first out of the shopping bags and to not use unneeded items. The other option is to compare the duplicate products’ best-before date when all products for a mise en place are complete and store the one that can be conserved longest.
In this section, you saw two examples of aggregator that differ from the standard usage of reassembling some collection. There’s only one thing left to do, and that’s to open the black box and look at the machinery of Spring Integration that makes all this tick.
7.4. Under the hood
The best class to start looking at when you want to figure out what Spring Integration does under the hood in terms of correlating messages is the CorrelatingMessageHandler. This class is wired by the AggregatorParser with collaborators that make it into an aggregator, as well as wired by the ResequencerParser with collaborators that make it into a resequencer.[2] In this section, we look at the steps the CorrelatingMessageHandler performs to group, store, and process messages, and then we look at two examples of wiring a CorrelatingMessageHandler as an aggregator and as a resequencer.
2 In Spring Integration 2.1, this has been refactored so that AbstractCorrelatingMessageHandler is a common base class of the Aggregator and Resequencer handler classes. Many of the details discussed here changed as well, but the default strategies are the same. See the latest reference manual for details.
7.4.1. Extension points of the CorrelatingMessageHandler
The CorrelatingMessageHandler can process a group of messages in two ways: message in and message out. When the message comes in, it’s correlated and stored. When a message group might go out, it’s released, processed, and finally marked as completed. Let’s look into the details of each of those steps—correlate, store, release, process, complete—as shown in figure 7.6, and introduce collaborators as we go along.
Figure 7.6. The CorrelatingMessageHandler and its collaborators

When a message hits the CorrelatingMessageHandler, the first thing it needs to do is figure out what MessageGroup this message belongs to. The message group is defined by its correlation key (not to be confused with correlation ID). The correlation key is retrieved from the CorrelationStrategy, which defaults to a HeaderAttributeCorrelationStrategy. The default strategy picks the correlation ID from the message headers, but this doesn’t have to be your strategy.
After the correlation key is found, the message can be stored with its group. For this it uses a MessageGroupStore, which defaults to an in-memory implementation. Storage used by the CorrelatingMessageHandler can be entirely customized. A JdbcMessageStore is available in the framework, but it stands to reason that a NoSQL store is more fitting in many cases.[3] The storage will hold all incomplete message groups, so it’s important to consider memory consumption and performance in case of large groups or large numbers of incomplete aggregates.
3 A few NoSQL implementations are available in Spring Integration version 2.1.
After the message is stored, that message’s group is considered for release. For example, a completed aggregation will be released, or a partially completed group that may contain the first few elements of a sequence may be released. The release strategy says nothing about the completeness of the group. Its only responsibility is to decide whether the message processor may process this particular group.
Once a group is released, it’s handed to the MessageGroupProcessor of the CorrelatingMessageHandler. This is where the actual operations on the messages are performed. The processor is handed a template to send messages with and is expected to make all decisions relevant to sending output messages. It’s also responsible for marking the messages it has processed in the message group.
The marked messages are then recognizable as processed if the same group hits the processor later. There is no restriction on the contract that the processor has to fulfill that disallows it from reprocessing marked messages.
In the next few paragraphs, you’ll see the implementation of aggregator and resequencer as examples of the mentioned strategies. In both aggregator and resequencer, correlation and storage are the same (and trivial), so we go into the details of release and processing only.
7.4.2. How do Resequencer and Aggregator do it?
The aggregator, as discussed earlier, takes a group as a whole and forges a new message out of it. We look at the release and processor strategies in detail in the next few paragraphs.
The release strategy of an aggregator should be to release the group only when the processing is complete (or if it times out). The SequenceSizeReleaseStrategy implementation handles this behavior. For this common case, the MessageGroup has an isComplete() method, the default implementation of which compares the sequence size header to the size of the group. This is convenient if you’re implementing a custom release strategy but still are interested in the default completeness of the group.
The message group processor of an aggregator should turn all the messages of a group into a single aggregated message and send it off to the output channel. The most common implementation used is the MethodInvokingMessageGroupProcessor, which wraps around a method. The method should have the following signature (pointcut expression language):
* *(List)
Similar to other implicit conversions to and from messages in the framework, Spring Integration automatically unwraps the elements in the list if they’re not messages. The return value is wrapped in a message if needed and sent to the output channel of the aggregator.
The resequencer example follows the same lines as the aggregator with two main differences. First, the messages from an incomplete group may already be released. Second, the processor is expected to return the same messages that came in.
By default, the release strategy used by the resequencer is also the SequenceSizeReleaseStrategy. In the case of a resequencer, the releasePartialSequences flag can be set. This flag allows the release strategy to release parts of an incomplete sequence that are in the right order to allow for a smoother message flow.
The message group processor of a resequencer takes all the messages in the group, orders them, and then sends all the messages that form a sequence to the output channel. The main customization is to supply a different comparator for the ordering so sequence numbers can be avoided.
In summary, one central component, CorrelatingMessageHandler, uses several strategies to delegate its work. CorrelationStrategy is used to find the correlation key of the message group, and MessageGroupStore is used to store the message group. To decide when to release the group for processing, a ReleaseStrategy is used. A MessageGroupProcessor finally deals with the messages. Implementations of these strategies together form the different correlating endpoints.
7.5. Summary
In this chapter you learned to deal with splitters, aggregators, and resequencers. You also saw examples of some nontrivial aggregator use cases and finally looked at the design that’s at the core of Spring Integration. Let’s review what you learned about splitters first.
- One message goes in; many messages come out.
- The output can be based on the payload but also other criteria, such as headers.
- The splitter sets a correlation ID, sequence size, and sequence number for each message.
The chapter also discussed endpoints that group messages together before sending reply messages. Correlation, the basis for both aggregating and resequencing, was examined in detail. The following points are relevant to remember:
- CorrelationStrategy finds the correlation key, which is based on a message and doesn’t have to be the correlation ID (for example, as set by a splitter).
- MessageGroupProcessor determines what happens in reaction to the release of a group.
- ReleaseStrategy determines when a group is released. A group can be released multiple times.
- MessageGroupStore stores the messages until they are processed.
The aggregator uses a processor that aggregates the messages. By default, its correlation and release strategies are complementary to the splitter.
The resequencer processes messages by reordering them. Its correlation and release strategies are similar to those of the aggregator with the exception of releasing partial sequences. When partial sequences are released, multiple releases for the same group may happen.
Now that you’ve read this chapter, you should have a clear idea how Spring Integration can help you when you need to split up some work or aggregate the results of some operations back together. Aggregation is a particularly complex use case that often differs subtly from the examples found in this book or online. In some cases it pays to write a custom solution. It’s particularly important here to consider carefully the pros and cons of extending the framework versus inventing your own.
This concludes part 2 of the book. You now know how the core of Spring Integration works. We reviewed all the main components in the core and showed you several examples of messaging applications using the components. But this is only the foundation. The interesting part comes when you start integrating with remote systems and look beyond the walls of the JVM. In the next chapter, you’ll work with XML, because it’s the ubiquitous language of system integration. Chapter 8 shows you concepts from this and previous chapters reused in the context of XML payloads, such as the XPath splitter and the XPath router. From there, we’ll look at many different integration possibilities. Read on!