
Chapter 11. Filesystem integration
The book Enterprise Integration Patterns defines four basic integration styles: file transfer, shared database, Remote Procedure Call (RPC), and messaging. This chapter deals with file-based integration. No different from the other integration options, file-based integration is all about getting information from one system into another. In file-based integration, this is accomplished by one system writing to disk and another reading from it. The particular details of the implementation (for example, whether both systems stream to the same large file, or multiple files are being moved around) aren’t part of the definition. After reading this chapter, you’ll have a solid understanding of the details of file-based integration and how to implement it cleanly using Spring Integration’s file handling support.
In the previous two chapters, we looked at messaging through Java Message Service (JMS) and email. In many ways, messaging-based integration is desirable over file-based integration. Unfortunately, many legacy systems still offer file transfer as their only integration option, but when comparing the simplicity of sharing a file to more modern solutions like JMS or web services, file-based integration is also tempting in many new applications. Having one process write a file in a directory and another read from that directory is often the simplest thing that might possibly work. If a simple solution just works, it has earned a right to stay in business.
Enterprises have been trying hard to move away from file-based integration in favor of service-oriented architecture, or SOA (with various definitions), but most of them have ended up keeping some of the legacy file-based integration points around.
Building new applications that have to be integrated into an architecture that has grown under these circumstances necessitates interaction with the filesystem. In this chapter, you learn how to do this with Spring Integration, and we provide some generic pointers on designing interaction with the filesystem. The chapter explores reading and writing, different ways of dealing with files, how the different components work under the hood, and how to handle several advanced problems you might encounter.
Before exploring how to interact with the filesystem, let’s carefully examine why it makes sense to do so in the first place. An example is in order too.
11.1. Can you be friends with the filesystem?
Most Java developers dread dealing with the filesystem like they dread dealing with concurrency. If you consider yourself a good developer and you really like those things, you might have noticed that applying yourself to using them doesn’t make you friends in your team. In the introduction, we associated file-based integration with the simplest thing that might possibly work, but in many cases, dealing with files properly is far from simple. Simplicity is the best friend you can have in your programming career. More often than you’d expect, things like the filesystem can be safely ignored in favor of a memory solution.
A component as common as the filesystem can’t be all bad. In UNIX, for example, everything is a file, and working with intermediary files is often the simplest solution. In an object-oriented realm such as the Java Virtual Machine (JVM), dealing with the filesystem requires an extra abstraction, which adds complexity. Table 11.1 lists the advantages and disadvantages of using files.
Table 11.1. Advantages and disadvantages of interacting with the filesystem
|
Advantage |
Disadvantage |
|---|---|
| Files survive an application crash. | Extra complexity dealing with resources, open streams, locking. |
| The disk has much more room than memory, so running out of room is less likely. | Filesystem access is much slower than memory access. |
| Files are easier than more advanced data stores to integrate with other applications. | Filesystem has no atomicity, consistency, isolation, durability (ACID) or Representational State Transfer (REST) semantics, and scalability is more complicated. |
If you can get away with the simple solution of using objects on the heap, go for it. But if it just doesn’t work, look at the filesystem seriously before you jump into even more complex solutions. We look at an example that can best be implemented using file sharing. The rest of the chapter teaches you how you can implement it using Spring Integration’s file support.
11.1.1. A file-based collaborative trip diary editor
One of the best examples of filesystem integration is an editor. In this chapter, we talk about a web-based editor for trip details. It would be great fun to elaborate on a vector graphics editor or something like that, but that would be over the top. To keep things simple, let’s discuss a plain text editor.
The editor uses a plain text file as its output format, and that would be that if we didn’t have to worry about undo history and live collaboration. For this example, we make it a point to worry about those things. In the flight-booking application, users can connect with friends and keep a diary of the trip online. You expect heavy usage, you don’t want to bombard the database with updates, and you don’t want to keep everything in memory either. Put this way, the filesystem seems like a decent middle road. To keep the undo history, you create small files with changes and store them alongside the base file. Whenever a change is made in the editor, a file containing that change is created.
Now when the editor is closed, you can reload the file and the full undo history at startup, but the organization used here also allows you to do something even better. You can have multiple editors open, perhaps at different terminals, that all edit the same piece of text. If one editor writes a change to the directory, the other editors pick up the file and update their screen.
The examples discussed here can easily be extended to a rich text editor, a spreadsheet, or something else. The only restriction is that you can define a base file format and a file format for the changes. In figure 11.1 you can see the high-level design of the application.
Figure 11.1. A file is picked up by the inbound adapter; it then flows through the transformer. The UI interprets the change and sends changes made by its user back to the working directory.

Let’s explore the responsibilities of the components in figure 11.1 in more detail. First, a single client creates a new document to work on, which results in a directory for the document and an empty file as a starting point. After each change, a file with the change is created.
To ease the configuration of file-related components, Spring Integration comes with a dedicated file: namespace. To use this namespace, add the following to the root element of your configuration file:
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:i="http://www.springframework.org/schema/integration" xmlns:file= "http://www.springframework.org/schema/integration/file" xmlns:util="http://www.springframework.org/schema/util" xsi:schemaLocation= "http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/integration http://www.springframework.org/schema/integration/spring-integration.xsd http://www.springframework.org/schema/integration/file http://www.springframework.org/schema/integration/file/spring-integration-file.xsd">
Note in particular the addition of xmlns:file="http://www.springframework.org/schema/integration/file". This is where you add the file namespace.
The file: namespace allows you to use the shorthand for file-specific inbound and outbound channel adapters and various file-oriented message transformers. All the different components can also be configured using plain old <beans/>. If you need to do more advanced customizations to the configuration, it could be useful to understand the bean configuration. Look at the “Under the hood” section at the end of this chapter.
You might want more fine-grained modifications later on, perhaps to update other clients on a key-by-key basis, but for this example, the solution we outlined in the previous paragraphs will suffice.
If another client joins in now, things get interesting. If both clients watch the directory with the base file for changes, they’ll see new files appearing in the directory as the other client edits the file. Each client can then apply these changes to the in-memory model and refresh the screen so that the user is aware of the change. With an appropriate scan rate and change size, a seamless collaboration between different users can be achieved.
We chose this example because it requires the right interactions with the filesystem to be suitable as an illustration of Spring Integration’s file support. The first thing you should remember about file support in Spring Integration is the namespace. You don’t have to use the namespace to be able to configure the various elements, but typically the namespace is an excellent tool to hide unwanted complexity. Only in advanced scenarios does it become important to consider the underlying plumbing in detail.
Change
A change is a consistent set of manipulations to the document. It’s recorded between two cursor positions.
In the next section, we use the namespace to configure the file-writing leg of the application.
11.2. Writing files
Writing a file to the local filesystem is a simple job, so let’s start there. To be able to write a file, your application needs several things: write access to the directory where the file should be written, a byte array or a string to write to the file, and a filename to write this data into. If you tried to do this using the raw File API of the JDK, you’d have to write some less-than-elegant boilerplate code that you’ve probably reproduced dutifully on countless occasions:
Writer output = new BufferedWriter(new FileWriter(aFile));
try {
output.write("This is written to the file in default encoding");
}
finally {
output.close();
}
Spring Integration contains a component that does all these things (see figure 11.2), as detailed in the next few sections. The only thing left to do is wire that up in your application context.
Figure 11.2. Schematic design of the Spring Integration file outbound channel adapter. The outbound adapter is a passive component that responds to incoming messages by writing their payloads to a file.
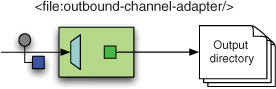
Some concerns related to the intended reader of the file must be taken into account. What do you do about encoding? If writing a file takes a long time, how do you prevent readers from picking up incomplete files? This section focuses on the standard solution to this problem, and at the end of the chapter, we go into more complex scenarios.
The easiest way out of a concurrent read/write bug is to write to a file until it’s done and only then move it to a place where the reader can pick it up. This is exactly what the outbound adapter described in the next section does by default.
11.2.1. Configuring the file-writing endpoint
To set up an outbound channel adapter, you use <file:outbound-channel-adapter/>. This element creates a file-writing component that writes the payloads of messages to a directory of your choosing. You can configure several things for this element. Table 11.2 lists the attributes you can use in this configuration.
Table 11.2. Attributes of the <file:outbound-channel-adapter/> element
|
Description |
|
|---|---|
| id | The ID of the endpoint or the implicit channel leading to it (see channel). |
| channel | The channel from which the messages that should be converted to files are received. If no channel is specified, a channel is created automatically as with any other channel adapter. |
| directory | The directory to which the files should be written. This directory is a resource, but the default loading rule is always from the filesystem, no matter in what type of ApplicationContext this bean is loaded. |
| filename-generator | Allows custom naming strategy; the default strategy is to use a header or the name of the File instance in the payload. |
| delete-source-files | If delete-source-files is set to true and the payload of the messages is a File, the original file is deleted. |
Of these attributes, only id (and/or channel) and directory are required. In keeping with good practices in Spring Integration components, reasonable defaults are included for the other properties.
What Does this Do?
When a file is received from the input channel, the file channel adapter opens it and looks at the payload. Several payloads, such as byte[], File, and String, are supported. If the payload can be written to a new file, a temporary file is opened. This file has a suffix so that readers can prevent opening files that aren’t ready yet. Then the adapter writes the contents to the file, and if all goes well, it moves the file to its final name. This name is provided by the FileNameGenerator that you can wire up as a bean and inject using the filename-generator attribute.
Alternative: <File:Outbound-Gateway/>
In many cases, you must handle an original file after its contents are written to a directory. See also section 11.4.2. You can configure a <file:outbound-gateway/> for this task. This component behaves similarly to the channel adapter, but it allows you to send the created file to another endpoint immediately. This option is an excellent choice if you must notify another service when the file is written.
What Could Go Wrong?
Several potential problems must be considered when you write files. You might encounter an IOException, for example, because you suddenly lost the ability to write to the disk. In this case, a MessageDeliveryException is thrown containing the original IOException. There is nothing special about this failure, but Spring Integration allows you to let the exception bubble up as a RuntimeException.
It’s also possible to overwrite an existing file unintentionally. Be careful to implement a custom FileNameGenerator in such a way that it doesn’t generate the same filename for files that should be named differently. The default name generator ensures that within the same application context the names are unique, but you’ll probably need more control over the filenames. It’s also important to avoid overwrites between multiple runs of the application, whether in parallel or in sequence.
Now that we have the tools, let’s try them. With the outbound adapter, you can implement the save feature of the collaborative editor.
11.2.2. Writing increments from the collaborative editor
In the sample application introduced earlier, we defined the requirement to track changes incrementally. The files should be easily identifiable and orderable. To make this work, the files are named after the running application key (which is unique for each time the application context is loaded) and a timestamp. Later in this chapter, you learn how to use this information to make sure changes are applied to the other applications in the right order.
Each file will contain a change in a format which allows an endpoint that’s processing it to apply it to a string. The details of applying the changes are tricky, but lucky for us they’re not relevant to this book. It’s not the responsibility of the channel adapter to ensure that the content of the files is in an appropriate format for the reader. This responsibility lies with the application itself. See figure 11.3 for a graphical representation of the writing leg of the application.
Figure 11.3. The writing leg of the collaborative editor: a String is passed to the <file:outbound-channel-adapter/> as a message. The String payload is then converted to a file in the work directory.

At this point it’s good to inspect the configuration related to file writing:
<file:outbound-channel-adapter
channel="outgoingChanges" directory="#{config.diary.store}"
auto-create-directory="true"
filename-generator="nameGenerator"/>
<bean id="nameGenerator"
class="com.manning.siia.trip.diary.ChangeFileNameGenerator">
<constructor-arg value="#{config.processId}"/>
</bean>
Now you can write files to the work directory, but you must also learn to read files.
11.3. Reading files
Reading files is more complex than writing them, but once it’s clear which file should be read, it’s as trivial as writing to a file:
BufferedReader input = new BufferedReader(new FileReader(aFile));
StringBuilder contents = new StringBuilder();
try {
String line = null;
while (( line = input.readLine()) != null){
contents.append(line);
contents.append(System.getProperty("line.separator"));
}
} finally {
input.close();
}
This snippet contains some boilerplate, and judging from countless examples of where people have messed this up, it’s quite error prone.
Automatic Resource Management in Java 7
Closing resources properly has become easier in Java 7 with Automatic Resource Management.
Although it’s interesting to discuss the low-level correctness of filesystem access, the primary goal of this chapter is to address the functional complexities of dealing with files. Back to the example.
The Trip Diary module must read files from a directory to update the displayed diary with changes from other editors.
The complexity lies in determining which file to open and when. When a reading process is watching a directory, it has to periodically list all the files in a directory and decide which ones are new. This task may seem simple, but it’s tricky. Imagine you’re looking at a directory that someone else is dropping files in. How can you know which files to pick up and which files you’ve already processed? How do you ensure that no one is still writing to that file?
By default, Spring Integration’s file inbound channel adapter (depicted in figure 11.4) reads all files in a certain directory, but once it’s read, a file isn’t picked up again. As a user, you can customize the behavior by specifying which files should be read using FileListFilters. More on this later. First let’s make sure you understand Java’s file API a little better.
Figure 11.4. Design of the Spring Integration inbound channel adapter

11.3.1. A File in Java isn’t a file on your disk
Central to the filesystem interaction in Java is the File class, which is immutable. This means that once created, it can’t be changed. This is a good thing, because as mentioned earlier, immutable payloads make your life much easier once you start processing messages concurrently. Having a File object as a message payload is perfectly safe from a concurrency point of view. But don’t be lulled into complacency too soon. We all know that files change all the time, so there must be something more to it.
What’s in a File?
Looking at the File source code reveals where the problem is hidden. The File’s path is effectively immutable, but most operations on the File don’t access immutable fields; instead, they access the filesystem. You can understand that getting the last modification date requires accessing the filesystem to check whether the file was changed lately. This means you have to be careful to distinguish between operations that access the filesystem and operations that don’t. If you need to look at the modification date or the file size to determine if a file should be read, you assume the responsibility to account for concurrent filesystem access. Good, lazy programmers shun responsibility.
Keeping it Simple
A common tactic in dealing with this problem is to make sure that while files are being written, reading processes don’t see them yet—for example, by writing in a directory that isn’t visible to the reading process, or, as we do automatically in Spring Integration, writing to files with an agreed suffix. Then, when you’ve finished writing, move the file to where the reading process can see it. By holding the writing process partly responsible, the readers can be much simpler. Exclude in-progress files using a File-ListFilter and let Spring Integration deal with the visible files with the default behavior.
But how can you make Spring Integration do all that? The next section shows you the details of the configuration.
11.3.2. Configuring the file-reading endpoint
The <file:inbound-channel-adapter/> element creates a file-reading adapter. The attributes for this element are listed in table 11.3.
Table 11.3. Attributes of the <file:inbound-channel-adapter/> element
Of these attributes, only id (and/or channel) and directory are required. In addition, the <file:inbound-channel-adapter/> uses a poller, which can be configured as a subelement, as with a <service-activator/>.
What Does this Do?
You have quite a few options here, but because only a couple of attributes are required, an inbound channel adapter configuration can be as simple as this:
<file:inbound-channel-adapter id="fileGuzzler" directory="work"/>
This configuration would pick up files written to the work directory and send them to a channel called fileGuzzler wrapped in a message. It would also make sure they’re picked up only once during the lifetime of the application.
When neither filter nor filename-pattern is specified, the FileReadingMessageSource that’s created will use an AcceptOnceFileListFilter by default. This filter remembers all files it has seen before and doesn’t let them pass again. The default filter works well in combination with, for example, a SimplePatternFileListFilter that excludes unfinished files in agreement with the writing process. If the writing isn’t under your control, though, you might have no choice but to write a more elaborate (and more stateful) FileListFilter by either extending Abstract-FileListFilter or implementing FileListFilter directly.
When the poller invokes receive() on the internal FileReadingMessageSource, it lists the files in the directory, adds them to an internal queue, and lets the poller iterate over the files until it satisfies its maxMessagesPerPoll. The internal queue is prioritized according to the Comparator, if provided. Otherwise, the files come out in natural order.
In the next section, we again apply the tools to the example application. The tricks you just learned will help you implement the reading leg of the application.
11.3.3. From the example: picking up incremental updates
Now that you know how to read files, let’s look at reading the incremental updates from the directory. First, a quick outline of the algorithm.
Given two running editors on the same document, editor A and editor B, files will be written into the directory by both A and B. Editor A wants to read the files from B, or more precisely, the files not written by A itself. See figure 11.5.
Figure 11.5. Inbound components of the collaborative editor: a file is picked up from the working directory and sent on the incomingFiles channel wrapped in a message. It’s then transformed into a String and passed along to the editor.

If you distinguish each editor uniquely by a key generated on startup, restarting A will result in a running editor C, where C != A. This is convenient because a newly started editor can read all the changes to the file, and even a restarted editor can read all the files written by the previous editor run by the same user. As mentioned before, you could use a combination of a timestamp and process ID to prevent file duplication:
<file:inbound-channel-adapter
channel="incomingChanges" directory="#{config.diary.store}"
filter="onlyNewChangesFilter"/>
<bean id="onlyNewChangesFilter"
class="org.springframework.integration.file.filters.CompositeFileListFilter">
<constructor-arg>
<list>
<bean class="org.springframework.integration.file.filters.AcceptOnceFileListFilter"/>
<bean class="com.manning.trip.diary.RefuseWrittenByThisProcess">
<constructor-arg value="#{config.processId}"/>
</bean>
</list>
</constructor-arg>
</bean>
You learned in this section how to configure a file-reading component, and we discussed the more elaborate details of the possible configuration options. In the examples, you can see that the typical boilerplate code is replaced by somewhat more readable declarative XML. The collaborative editor now has both legs to stand on.
Great. Now you can read and write files. But what are you going to do with them inside the application?
11.4. Handling file-based messages
When a file is read and wrapped into a message, you need to do something with it that makes sense within the context of your application. Rarely is a File meaningful within the application domain. If it isn’t, it must be converted into something that makes sense, typically an object from the domain. The process consists of two parts: first, the contents of the file are read into memory, and second, the raw data is converted into domain objects. The conversion process is called unmarshalling, and plenty of frameworks, such as Spring OXM (discussed in chapter 8), can do it. Spring Integration file support doesn’t care how you do your unmarshalling, so even though it’s an important concern, it’s not discussed in detail in this chapter. The first part of the process, reading the files into memory, is an important responsibility of the file support. We discuss it from several angles in this section.
11.4.1. Transforming files into objects
Many different types of content can reside in a file, but from a high-level view, it’s all just bytes. The built-in transformers of Spring Integration can transform a File object into either a byte[] or a String. You can use a FileToByteArrayTransformer or a FileToStringTransformer respectively for transformations. Transforming a file means your system is now going to deal with it. At this point, you might choose to delete the file, but if the system fails to deal with the file’s content successfully and you’ve already deleted the file, you may lose the data.
Imagine you’re writing new products in a directory for your online shop. These products will be dropped in a directory as XML messages and picked up by a process that inserts them into the database backing your web application. First, the XML must be transformed into a String, and then an unmarshalling step will prepare the objects destined for persistence through a repository. If the transformer deletes the file, it does so after it finishes the transformation, but it’s not unthinkable that subsequent requests are separated by asynchronous handoff. In this case, obviously, the file will be deleted before the objects are persisted, but even if there is no asynchronous handoff, problems can occur because the transaction boundaries are broken. If the process crashes before the file is deleted, but after the inserts are committed, restarting the process might cause duplication.
The next section outlines some common file-handling scenarios and discusses the pros and cons of each approach.
11.4.2. Common scenarios when dealing with files
Managing files on disk from several applications can be done many different ways. A lot of passionate discussion takes place on how this file management should work. In the end, it depends on individual circumstances. Let’s a look at a few different strategies: (1) letting the file sit in the input directory, (2) deleting the file as soon as it’s consumed by a transformer, and (3) simulating a transaction that attempts to make delivering the message and deleting the file an atomic operation.
Just Leave It
If no harm is caused by picking up the file again when the application is restarted, or if you have a clear way to filter out old messages, it’s often best to leave the files in the input directory. If dealing with a file is a nondestructive operation, it’s much easier to recover from a bug or failure that causes the file to be dealt with improperly. The downside of this approach is that from the outside it’s impossible to determine, on the basis of its name or location, whether a file was processed. If a new file is created that can be correlated to the input, or if the application can be queried to determine whether a file was processed, this problem can be worked around.
If the files are left on the filesystem, it’s usually easy to devise a cleanup strategy after the application is operating for a while and you start running out of space. For example, a script that deletes all files older than a week is not hard to write. It’s important, though, to think of how much space you need for the files in advance and also to think about purging strategies. If these strategies are complicated, you shouldn’t postpone implementing them.
Delete on Consumption
Sometimes incoming files aren’t valuable, and dropping a file or two is no big deal. For example, if a weather service gets forecast updates every minute, dropping one when it crashes won’t be noticed when the service restarts, so deleting the file from the transformer makes perfect sense. But of the three options listed, this one is the most likely to delete a file prematurely and never deliver the contents to a downstream component. Avoid this solution if you can’t afford to lose some data.
Simulate Transaction
Some files are too big to just leave them, but you can’t afford to lose a single one. In this case, you can’t delete the file from the transformer because you could lose the data if the JVM is killed, but you have to delete the file in process. A file-reading endpoint will set the original file on the message as a header. This header can be used to delete a file after it’s fully processed. Usually, the process should write a file to a processed directory when processing is complete. You can do this with a <file:outbound-channel-adapter ... delete-source-files="true" />, but it’s not a real transaction. If the filesystem is full or the process crashes midstream, input files could sit in the input directory even though they’re already processed. To mitigate this risk, you can implement an idempotent receiver in the endpoint that processes the file. Then again, it might be easier to just leave the file and write a separate cleanup routine.
11.4.3. Configuring file transformers
The file: namespace contains a couple more elements: the <file:file-to-bytes-transformer/> and the <file:file-to-string-transformer/>. Each supports the same attributes (other than a charset attribute that’s only present on the string transformer), so the primary difference is the type of the payload of the outgoing message. Table 11.4 shows a short description of the allowed attributes.
Table 11.4. Attributes of the <file:file-to-bytes-transformer/> and <file:file-to-string-transformer/> elements
|
Description |
|
|---|---|
| id | The identifier of the endpoint. |
| input-channel | The channel from which the file messages that should be transformed are received. Can be omitted only if the transformer is part of a chain. |
| output-channel | The channel to which output of the transformation is sent. When omitted, the result is sent to the reply channel set as a message header. |
| delete-files | Boolean flag that determines whether the file payloads of incoming messages will be deleted by this component. Defaults to false. |
The configuration of this element is almost trivial. Only the input-channel is required; in a chain, the element can even be used without any attributes. Setting the delete-files attribute to true is equivalent to deleting on consumption. This attribute defaults to false for a good reason: you wouldn’t be happy if your application deleted a file even though its content wasn’t processed correctly. In some use cases, it’s reasonable to have no strict guarantees about picking up files; then the overhead of having a separate cleanup strategy might not be worth the extra security.
By now you’re probably ready to see the application work, so we put the ends together in the next section.
11.4.4. Applying incoming changes to the collaborative editor
In the example collaborative editor, the incoming changes contain snippets of text and a position at which they should be inserted in the overall text. We don’t dive deeply into the tricky domain at this point, but if you’re interested in the details, check out the sources and play around with them for a while. As far as Spring Integration support is concerned, applying changes is only about reading the files and passing the resulting strings along to the editor. The transformer is blissfully unaware of whatever tricks the editor needs to do with the supplied strings.
You can refer back to figure 11.5 to see how the transformer fits in the overall flow of the application.
There is little else to the API for reading files. On the surface, it looks simple, and if the file interaction you’re planning for your application is as simple as this, there’s no more to it than configuring inbound and outbound adapters and transformers, as necessary. As mentioned in the introduction of this chapter, though, the devil is in the details. If the details become important, the next section will help you find your footing when dealing with issues such as locking or files being picked up multiple times or before they’re ready.
11.5. Under the hood
This section deals with the nitty-gritty details of filesystem integration. It’s interesting for people who need to understand the source code of the spring-integration-file project, but it can safely be ignored without missing out on the power of filesystem integration support. If you need to implement more elaborate file-related use cases, you can avoid painful debugging by understanding the underlying concepts and rules. Reading this section in advance is highly recommended in such cases. Here we discuss the details of ordering and locking when reading files. These concerns are caused by writing files but surface on the reading end in particular. This section therefore focuses on the FileReadingMessageSource.
11.5.1. FileReadingMessageSource
The FileReadingMessageSource is the core of the <file:inbound-channel-adapter>. It’s a completely passive component that should be polled on its receive() method. The endpoint that the component is wrapped in by Spring Integration takes care of the polling transparently.
When a poll occurs for the first time, it follows the steps depicted in figure 11.6.
Figure 11.6. Internal behavior of the FileReadingMessageSource when polled: (1) get a listing of the input directory, (2) filter the resulting list, (3) add the listed files to the internal queue, and (4) return the head of the queue wrapped in a message.

On subsequent receive() invocations, the internal queue is synchronized with the filesystem only if it’s empty or if the scanEachPoll flag is set to true. This can have implications on the internal ordering, as discussed next.
Ordering Files
In some cases, the order in which files are read is important. The collaborative editor, for example, is highly dependent on the order in which files are processed. The internal workings of the FileReadingMessageSource should be understood before assumptions are made about ordering. Before we dive into the code, first we need to understand the problem better.
The file listing returned by the File’s listFiles() method is a File[], so it’s ordered, but the order isn’t well defined on different operating systems and under different configurations. To keep a long story short: it isn’t a good idea to rely on the ordering of this array. The FileReadingMessageSource doesn’t. Because ordering is required in some cases, as mentioned, it keeps the files in a PriorityBlockingQueue internally to ensure that files in the queue are returned in order. As usual, a Comparator can be used to control the ordering.
The problem now arises that when files aren’t written in order, the queue might have to be reordered after a file was wrapped in a message and sent to a channel by a poller. If the file sent should’ve come after the file added to the queue just after the ordering was broken, the FileReadingMessageSource can do nothing to fix it, because the incorrectly reordered subset has already been sent downstream. We wouldn’t be telling you this if you couldn’t fix it, though.
If you write the files into the directory in the order in which you want them to be received and you provide a comparator that puts the files in the desired order, the files will be received in that order. If you do something else, like writing the files in the right order without a comparator, the files might be received in the right order if you’re lucky. If you tweak the concurrency settings, this might change. It’s never a good idea to depend on message order implicitly. If you can’t avoid depending on order, you should use a resequencer (see chapter 7). This makes the system more robust and easier to maintain. Another problem that we already touched on in the introduction of this chapter is the risk of reading unfinished files. Let’s consider it in some more detail.
Reading Unfinished Files
As mentioned in section 11.3, it’s usually important to pick up files only after the writing process is done writing to them. For example, the built-in transformers assume that a file is finished and return a String or byte[] containing whatever was in the file at the moment they reached the end of it. As long as the file isn’t opened, there’s no problem passing around a reference while other processes are writing to it, but once a transformer (or another endpoint) opens the file for reading, all bets are off.
The best way to avoid premature reading of a file is to have the writing process decide when the file can be picked up. This can be done through a move at the moment the writing is finished or through a barrier that holds file messages until the writer says they’re done. The move-when-ready process has a few caveats. One is that the move operation isn’t always transactional. For example, an application using this strategy might start failing unpredictably when a system administrator configures a different device for the input directory than the directory where the file is moved. This is typically configured from the outside in a properties file, so the type of directories that should be used now must be part of the documentation of the application.
If the writing process is out of the control of the reader, it might still be possible to determine whether a file is ready. For example, if an XML file is being written linearly, the only thing the reader has to do is postpone files that don’t have the last end tag. Many formats have similar terminator sequences that can help prevent reading unfinished files.
The problem with reading terminator sequences is that they’re located at the end of the file, so you must open the file and read the last part of it. This approach obviously performs a lot worse than the move-when-ready strategy.
Another tricky problem arises when the writing process is writing in multiple parts of the file concurrently. The last part could be done while the middle part is still under construction. BitTorrent uses this strategy, as do other fields, such as image processing. In cases where a file isn’t moved when it’s done, and looking for terminators is either too inefficient or not possible, you have yet another option: file locking.
File locking works differently on different operating systems, but Java has an abstraction over file locking in the java.nio libraries. Spring Integration’s file support was expanded to include support for filtering based on java.nio in version 2.0. You inject a NioFileLocker and make sure the writing process respects locks too. You can also work with lock files that are created, moved, and deleted according to a protocol agreed upon by both writer and reader.
A word of warning is in order here. Locking might seem like a great idea at first, but it’s more complex than you might think. If you can find a way to solve your problem without locking, you’re doing yourself a huge favor. And with that, we’ve told you enough about dealing with files. It’s time to round up and move on to the next challenge.
11.6. Summary
In this chapter you learned how to work with files using Spring Integration. We discussed the basics of writing files first with the <file:outbound-channel-adapter/>. This adapter provides the most common options needed to create output files in a configurable directory. Using the file-writing components of Spring Integration frees you from the responsibility of opening FileOutputStreams or FileWriters and closing them again. We also discussed the outbound gateway, which is useful if you need to postprocess the written file.
You saw how to read files from the filesystem, prevent duplication, and deal with pattern-matching filters. We discussed the FileListFilter extension point that allows you to filter incoming files on any criterion of your choosing. You can go even further than that and implement your own scanner.
When files are read from the system, there are several things you might need to do with them; the most common tasks are implemented in the Spring Integration file transformers. You can easily apply what you learned to implement a file transformer that better suits the needs of your business case.
Finally, we looked under the hood of the components we discussed. We examined ordering and locking in the FileReadingMessageSource and urged you to avoid as much as possible relying on these complex options. In the final section, we explored reading unfinished files in more detail, so you have a better idea of the advanced problems you may encounter when implementing file-based integration with or without Spring Integration.
After reading this chapter, you should have a good understanding of how Spring Integration helps you tie your messaging infrastructure into the filesystem. With the adapters described here, it’s simple to convert between messages and files. As a final note, remember that the file support in Spring Integration, though convenient, doesn’t compete with frameworks that focus on the interpretation and processing of files, such as Spring Batch and other extract, transform, and load tools. It’s a healthy idea to use Spring Integration to create the events that drive the specialized process that deals with the files.
In chapter 12, we discuss integration through web services, which in many cases is a more robust alternative to file-based integration.