
Chapter 2. Enterprise integration fundamentals
- Loose coupling and event-driven architectures
- Synchronous and asynchronous interaction models
- The most important enterprise integration styles
Commercial applications are, most of the time, solutions to problems posed by the business units for which they’re developed. It makes little difference whether the problem under discussion is older, and the solution is automating an existing process, or the problem is new, and the solution is an innovation that allows the organization to do business in a way that wasn’t possible before.
In some cases, the solutions consist of newly developed components that reuse already-existing applications by delegating functionality to them. This is often the case with legacy applications that implement complex business logic and for which a complete rewrite would be an unjustifiable cost. Other applications are divided from the beginning into multiple components that run independently to get the most out of the modern hardware and its high concurrency capabilities. What both these approaches have in common is that they tie together separate components and applications, sometimes even located on different machines. Such applications are the focus of enterprise application integration.
Each of these concepts discussed in this chapter plays an important role in designing integrated applications. They make sure that the integrated components don’t impose needless restrictions on each other and that the system is responsive and can process concurrent requests efficiently. Applying these principles in practice results in several integration styles, each with its own advantages and disadvantages. This chapter shows you how to take them into account when implementing a solution. As a Spring Integration user, you’ll benefit from understanding the foundational principles of the framework.
2.1. Loose coupling and event-driven architecture
We already discussed building applications that consist of multiple parts (or that orchestrate collaboration between standalone applications). It’s important to understand the implications of integration on your design. One of the most important consequences of decomposing applications into multiple components is that these components can be expected to evolve independently. The proper design and implementation of these parts (or independent applications) can make this process easy. Failing to properly separate concerns can make evolution prohibitively hard. Our criterion to decide whether a particular design strategy fosters independent evolution or stands in the way is coupling.
In this section we argue why loose coupling is preferable over tight coupling in almost every situation. Because coupling can come in different forms, such as type-level or system-level, we explore these variants of coupling in more detail. The last part of the section discusses how to reduce coupling in your application by using dependency injection or adopting an event-driven architecture.
2.1.1. Why should you care about loose coupling?
Loose coupling within systems and between systems deserves serious consideration, because it has serious implications for design and maintenance. Achieving an appropriate degree of loose coupling allows you to spend more time adding new features and delivering business value. By contrast, tightly coupled systems are expensive to maintain and expand because small changes to the code tend to produce ripple effects, requiring modifications across a large number of interacting systems. It’s important to note that this increase in cost isn’t the product of a change in conditions but something that could have been avoided at design time.
It’s not so much that loosely coupled systems guarantee quality but that highly coupled systems nearly always guarantee complexity in the code and the paths through the code, making systems hard to maintain and hard to understand. Highly coupled systems are also generally harder to test, and often it’s nearly impossible to unit test their constituent parts, for example, because their units can’t be constructed without constructing the entire system.
Identifying Highly Coupled Systems
How can you identify a system that’s highly coupled? Measuring coupling has been the focus of various academic attempts based on various forms of code-level connections. For example, one measure could be how many user types a class references. Where a class is referencing many user types, as shown in figure 2.1, it’s considered highly coupled, which is usually a bad sign because changes in those referenced types may lead to a requirement to change the class referencing them. Take, for example, adding a parameter to a method signature: all invokers must provide a value for it.
Figure 2.1. A highly coupled system: components become entangled because of the complex relationships between them.
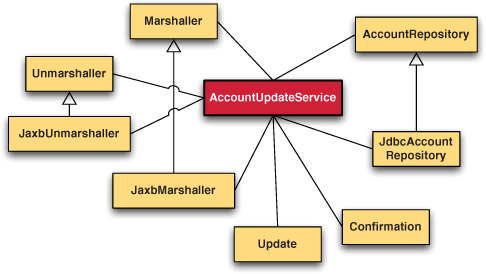
Using referenced types as a measure of how interconnected classes within a system are will give you an idea whether the system’s coupling is high or low. This method works well for individual applications, but as new application design strategies are employed, other forms of coupling have become prominent. For example, in service-oriented architectures (SOAs), the coupling between the service contract and the service implementation is also taken into account, so that a change in the implementation of the service doesn’t create a need to update all service clients. In many SOA scenarios, service consumers may not be under the control of the service implementation. In this case, loose coupling can insulate you from causing regressions that in turn cause unhappy service consumers with broken systems.
A general way of defining coupling is as a measure of how connected the parts of a system are or how many assumptions the components of the system make about each other. For example, systems that directly reference Remote Method Invocation (RMI) for communication in many places are highly coupled to RMI. Or a system that directly references a third-party system in a large number of places can be said to be highly coupled to that third-party system. The connections you create in and between your systems introduce complexity and act as conduits for change, and change generally entails cost and effort.
Coupling
Coupling is an abstract concept used to measure how tightly connected the parts of a system are and how many assumptions they make about each other.
Loose coupling, in the context of integrating systems, is therefore vital in allowing the enterprise to switch between different variants of a particular component (for example, accounting packages) without incurring prohibitive cost due to required changes to other systems. Coupling is an abstract concept, and we show over the next few sections a few concrete examples of different types of coupling, along with approaches using Spring and Spring Integration to reduce coupling and improve code quality through increased simplicity, increased testability, and reduced fragility.
2.1.2. Type-level coupling
Coupling between types is probably the best understood because it’s the form of coupling that’s most often discussed. The following listing shows a booking service that allows airline passengers to update their meal preferences. The service first looks up the booking from the database to obtain the internal reference, and then invokes a meal-preference web service.
Listing 2.1. Airline booking service
package siia.fundamentals;
import siia.fundamentals.Booking;
import siia.fundamentals.BookingDao;
import siia.fundamentals.MealPreference;
import siia.fundamentals.SimpleBookingDao;
import org.springframework.ws.client.core.WebServiceOperations;
import org.springframework.ws.client.core.WebServiceTemplate;
import org.springframework.xml.transform.StringResult;
import org.springframework.xml.transform.StringSource;
import javax.xml.transform.Source;
public class BookingService {
private final BookingDao bookingDao;
private final WebServiceOperations mealPreferenceWebServiceInvoker;
public BookingService() {
this.bookingDao = new SimpleBookingDao();
WebServiceTemplate template = new WebServiceTemplate();
template.setDefaultUri(System.getProperty(
"meal.preference.service.uri"));
this.mealPreferenceWebServiceInvoker = template;
}
public void updateMeal(MealPreference mealPreference) {
Booking booking = bookingDao.getBookingById(
mealPreference.getBookingId());
Source mealUpdateSource = buildMealPreferenceUpdateRequest(
booking, mealPreference);
StringResult result = new StringResult();
mealPreferenceWebServiceInvoker.sendSourceAndReceiveToResult(
mealUpdateSource, result);
}
public Source buildMealPreferenceUpdateRequest(
Booking booking, MealPreference mealPreference) {
return new StringSource(
"<updateMealPreference>" +
"<flightRef>" +
booking.getFlightRef() +
"</flightRef>" +
"<mealPreference>" +
mealPreference +
"</mealPreference>" +
"</updateMealPreference>");
}
}
The following example shows the BookingReportingService used to generate management reports with the business methods omitted:
package siia.fundamentals;
public class BookingReportingService {
private final BookingDao bookingDao;
public BookingReportingService(){
this.bookingDao = new SimpleBookingDao();
}
/** Actual methods omitted */
}
Because both classes directly reference the SimpleBookingDao and the constructor declared by that class, changes to that type may affect both the BookingService and the BookingReportingService. This type of coupling is known as unambiguous type coupling because it’s coupled to a concrete implementation even though it then assigns the instance to members’ fields typed as the interface. The BookingService also exhibits unambiguous type coupling to the Spring WebServiceTemplate. Generally, a system repeating this pattern of coupling to the concrete type can be considered highly coupled because changes in those concrete types will have widespread impact.
The solution to this problem is deferring the creation of concrete instances to the framework, using what we call dependency injection, which is our next topic.
2.1.3. Loosening type-level coupling with dependency injection
Standard dependency injection allows you to reduce coupling by addressing unambiguous type coupling. One way to do this is to move the instantiation concern into a single configuration file rather than code. Removing the code that instantiates the collaborators for your services both reduces coupling and simplifies the code. This makes maintenance easier, simplifies testing by allowing tests to inject test-only implementations, and increases the chances of reuse. The following example shows the new version of the BookingService, which now exposes a constructor that accepts instances of its collaborators:
package siia.fundamentals;
import org.springframework.ws.client.core.WebServiceOperations;
import org.springframework.xml.transform.StringResult;
import org.springframework.xml.transform.StringSource;
import javax.xml.transform.Source;
public class BookingService {
private final BookingDao bookingDao;
private final WebServiceOperations mealPreferenceWebServiceInvoker;
public BookingService(BookingDao bookingDao,
WebServiceOperations mealPreferenceWebServiceInvoker) {
this.bookingDao = bookingDao;
this.mealPreferenceWebServiceInvoker =
mealPreferenceWebServiceInvoker;
}
/*
updateMeal() and buildMealPreferenceUpdateRequest() remain
unchanged
*/
}
The Spring configuration to instantiate the BookingService in production looks as follows:
<beans:beans xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/integration"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd">
<beans:bean id="bookingDao"
class="siia.fundamentals.SimpleBookingDao" />
<beans:bean id="mealPreferenceWebServiceTemplate"
class="org.springframework.ws.client.core.WebServiceTemplate">
<beans:property name="defaultUri"
value="${meal.preference.service.uri}" />
</beans:bean>
<beans:bean id="bookingService"
class="siia.fundamentals.BookingService">
<beans:constructor-arg ref="bookingDao" />
<beans:constructor-arg
ref="mealPreferenceWebServiceTemplate" />
</beans:bean>
<beans:bean id="bookingReportingService"
class="siia.fundamentals.BookingReportingService" />
</beans:beans>
This example reduces coupling in the Java code but introduces a new configuration file that’s coupled to the concrete implementations. Taking a broader view of the system, you now have that coupling in one place rather than potentially many calls to the constructors, so the system as a whole is less highly coupled because changes to SimpleBookingDao will impact only one place.
With type-level coupling out of the way, it’s still possible for the different collaborators to make excessive assumptions about each other, such as about the data format being exchanged (for example, using a nonportable format such as a serialized Java class) or about whether two collaborating systems are available at the same time. We group such assumptions under the moniker of system-level coupling.
2.1.4. System-level coupling
It’s possible that collaborators might need to change to address new requirements, but it’s almost inevitable that where a large number of systems talk to each other, those systems will evolve at different rates. Limiting one system’s level of coupling to another is key in being able to cope easily with changes such as these.
Currently, the booking service is coupled to the use of a web service to contact the meal-preference service as well as the XML data format expected by the service. Things could’ve been worse: the data format could’ve been a serialized Java class instead of XML. Serialization would be the right tool to use whenever the expectation is that data will be consumed by the same application at a later time or when data is exchanged between components that are expected to be highly connected to each other (like a client/server application). Exchanging serialized data between independent applications couples them needlessly because it introduces the assumption that both of them have access to the bytecode of the serialized class. It also requires that they use the same version of the class. This in turn demands that new versions of the serialized classes be incorporated into the clients as soon as they’re deployed on the server. It obviously assumes that both applications are using the same platform (Java in our case). By using a portable data format like XML, we’ve just avoided all of this. Of course, the applications are still coupled by the XML format, but in the end, both applications must have a basic agreement on what is and what isn’t a correct message. We believe consumers should be as liberal as possible with that.
We still have another problem to deal with: the BookingService is also temporally coupled to the meal-preference web service in that we make a synchronous call and therefore the call to the BookingService will fail if the meal-preference service is unavailable at that point. Whether that’s the desired behavior will depend on the requirements, but it would be nice to make the temporal coupling optional.
One option would be to introduce a new class that encapsulates the call to the meal-preference service, removing the web service concern and the data format concern from the BookingService. This solution eliminates some coupling, but it also introduces coupling on a new meal-preference service type and on the signature of the method declared by that type.
By instead replacing the call to the meal-preference service with a new component and connecting the BookingService with the meal-preference service, you can further reduce coupling in the BookingService without introducing additional type coupling. This can be achieved by replacing direct method invocations with message passing over channels.
The following example shows the simplified booking service, which now simply enriches the meal preference passed in with the flight reference:[1]
1 The functionality of the BookingService is now spread across multiple components. You can explore this final implementation in the code example repository.
<beans:beans xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/integration"
xmlns:ws="http://www.springframework.org/schema/integration/ws"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd
http://www.springframework.org/schema/integration/ws
http://www.springframework.org/schema/integration/ws/spring-integration-ws.xsd">
<beans:bean id="bookingDao"
class="siia.fundamentals.SimpleBookingDao"/>
<channel id="mealPreferenceUpdatesChannel"/>
<beans:bean id="bookingService"
class="siia.fundamentals.BookingService">
<beans:constructor-arg ref="bookingDao"/>
</beans:bean>
<service-activator input-channel="mealPreferenceUpdatesChannel"
output-channel="bookingEnrichedMealUpdates"
ref="bookingService"
method="populatePreference"/>
<channel id="bookingEnrichedMealUpdates"/>
<beans:bean id="updateRequestTransformer"
class="siia.fundamentals.MealPreferenceRequestTransformer"/>
<service-activator input-channel="bookingEnrichedMealUpdates"
output-channel="xmlMealUpdates"
ref="updateRequestTransformer"
method="buildMealPreferenceUpdateRequest"/>
<channel id="xmlMealUpdates"/>
<ws:outbound-gateway uri="http://example.com/mealupdates"
request-channel="xmlMealUpdates" />
</beans:beans>
Focusing on message passing as the main integration mechanism leads us toward the adoption of an event-driven architecture, since each component in the message flow simply responds to messages being delivered by the framework.
2.1.5. Event-driven architecture
Event-driven architecture (EDA) is an architectural pattern in which complex applications are broken down into a set of components or services that interact via events. One of the primary advantages of this approach is that it simplifies the implementation of the component by eliminating the concern of how to communicate with other components. Where events are communicated via channels that can act as buffers in periods of high throughput, such a system can be described as having a staged event-driven architecture (SEDA). SEDA-based systems generally respond better to significant spikes in load than do standard multithreaded applications and are also easier to configure at runtime, for example, by modifying the number of consumers processing a certain event type. This allows for optimizations based on the actual requirements of the application, which in turn provides a better usage experience.
The question of whether an application built around the Spring Integration framework is inherently an EDA or SEDA application is open to debate. Certainly Spring Integration provides the building blocks to create both EDA and SEDA applications. Whether your particular application falls into one category or another in a strict interpretation depends on the messages you pass and your own working definition of what constitutes an event. In most cases, this is probably not a useful debate to enter into, so Spring Integration makes no distinction between agents as producers of events and producers of messages, nor are event sinks and consumers distinguished. The one place in which the term event is used in Spring Integration is in the implementation of the Event-Driven Consumer pattern, but here the consumer is consuming messages rather than events—it’s just that the consumption is triggered by the event of a message becoming available.
Reducing coupling is one of the main concerns when integrating applications. You’ve just finished a section that shows how this can be done by eliminating assumptions about the concrete types used in the application as well as replacing method and web service invocations with message passing. With respect to the latter, we mentioned synchronous communication as a way to increase the coupling of two systems, which we now address in more detail.
2.2. Synchronous and asynchronous communication
Another possible assumption made when integrating multiple components is that they’re available simultaneously. Depending on whether this assumption is incorporated in the system’s design, the components may interact synchronously or asynchronously, and in this section we look at the main differences between the two interaction models as well as their advantages and disadvantages.
From the Spring Integration perspective, you’ll see the options that the framework provides in each case and how simple configuration options allow you to switch between synchronous and asynchronous communication without changing the overall logical design of your application.
2.2.1. What’s the difference?
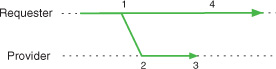
In synchronous communication (figure 2.2), one component waits until the other provides an answer to its request and proceeds only after a response is provided. The requests are delivered immediately to the service provider, and the requesting component blocks until it receives a response.
Figure 2.2. Synchronous invocation: the requester suspends execution until it receives an answer.

When communicating asynchronously (figure 2.3), the component that issues the request proceeds without waiting for an answer. The requests aren’t delivered to the service provider but stored in an intermediate buffer and from there will be delivered to their intended recipient.
Figure 2.3. Asynchronous invocation: the requester doesn’t block and executes in parallel with the provider.
Looking at how different these two alternatives are, the decision to use synchronous or asynchronous communication should be based on their strengths and weaknesses. Let’s examine the upsides and downsides of each approach a bit further.
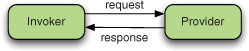
Of the two, synchronous communication is more straightforward: the recipient of the call is known in advance, and the message is received immediately (see figure 2.4). The invocation, processing, and response occur in the same thread of execution (like a Java thread if the call is local or a logical thread if it’s remote). This allows you to propagate a wealth of contextual information, the most common being the transactional and security context. Generally, the infrastructure required to set it up is simpler: a method call or a remote procedure call. Its main weaknesses are that it’s not scalable and it’s less resilient to failure.
Figure 2.4. Synchronous message exchange: the message is received immediately by the provider.
Scaling up is a problem for synchronous communication because if the number of simultaneous requests increases, the target component has few alternatives, for example:
- Trying to accommodate all requests as they arrive, which will crash the system
- Throttling some of the requests to bring the load to a bearable level[2]
2 Throttling is the process of limiting the number of requests that a system can accommodate by either postponing some of them or dropping them altogether.
When the load increases, the application will eventually fail, and you can do little about it.
The lack of resilience to failure comes from the fundamental assumption that the service provider is working properly all the time. There’s no contingency, so if the service provider is temporarily disabled, the client features that depend on it won’t work either. The most obvious situation is a remote call that fails when the service provider is stopped, but this also applies to local calls when an invoked service throws a RuntimeException.
Dealing with Exceptions
Exception-handling strategies are beyond the scope of this discussion, but it should be noted that a service can attempt to retry a synchronous call if the downtime of the service provider is very short, but it’s generally unacceptable to block for a long time while waiting for a service to come up.
Asynchronous communication offers better opportunities to organize the work on the service provider’s side. Requests aren’t processed immediately but left in an intermediate storage and from there are delivered to the service provider whenever it can handle them (see figure 2.5). This means the requests will never be lost, even if the service provider is temporarily down, and also that a pool of concurrent processes or threads can be used to handle multiple requests in parallel.
Figure 2.5. Asynchronous message exchange: the message is stored in an intermediate buffer before being received by the provider.
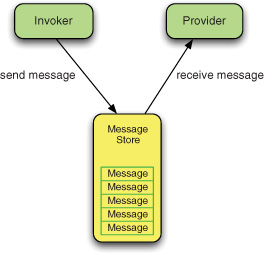
Asynchronous message exchange provides control for the behavior of the system under heavy load: a larger number of concurrent consumers means a better throughput. The caveat is that it puts the system under more stress. The point is that, unlike synchronous calls where the load of the system is controlled by the requesting side, in the asynchronous model, the load of the system is controlled by the service provider’s side. Furthermore, asynchronous communication has better opportunities for retrying a failed request, which improves the overall resilience to failure of the system.
You saw that asynchronous communication has obvious advantages in terms of scalability and robustness, but there’s a price to be paid for that: complexity. The messaging middleware that performs the message storage and forwarding function is an additional mechanism that must be integrated with the application, which means that instead of a simple method call, you must deal with supplemental APIs and protocols. Not only does the code become more complex, but also a performance overhead is introduced.
Also, in a request-reply scenario using the synchronous approach, the result of an operation can be easily retrieved: when the execution of the caller resumes, it already has the result. In the case of asynchronous communication, the retrieval of the result is a more complex matter. It can either follow the Future Object pattern (as in java.util.concurrent.Future), where after the asynchronous invocation, the invoker is provided with a handle to the asynchronous job and can poll it to find out whether a result is available, or the requester might provide a callback to be executed in case the request has been processed.
After issuing an asynchronous request, you have two components that execute independently: the requester that continues doing its work and the service provider whose work is deferred until later. Concurrency is a powerful tool for increasing the application performance, but it adds complexity to your application too. You have to consider concerns like thread--safety, proper resource management, deadlock, and starvation avoidance. Also, at runtime, it’s harder to trace or debug a concurrent application. Finally, the two concurrent operations will typically end up executing in distinct transactions. Synchronous and asynchronous communication are compared in more detail in table 2.1.
Table 2.1. Synchronous and asynchronous communication compared
|
Synchronous |
Asynchronous |
|
|---|---|---|
| Definition | Request is delivered immediately to provider, and the invoker blocks until it receives a response. | The invoker doesn’t wait to receive a response. Requests are buffered and will be processed when the provider is ready. |
| Advantages |
|
|
| Disadvantages |
|
|
The advantages and disadvantages of the two paradigms should be carefully considered when choosing one over the other. Traditionally, the integration between enterprise applications is based on message-driven, asynchronous mechanisms.
As the capabilities of hardware systems increase, especially when it comes to execution of concurrent processes and as multicore architectures become more pervasive, you’ll find opportunities to apply the patterns that are specific to integrating multiple applications to different components of an individual application. The modules of the application may interact, not through a set of interfaces that need to be kept up to date, but through messages. Various functions might be executed asynchronously, freeing up their calling threads to service other requests. Distinct message handlers, otherwise perfectly encapsulated components, may be grouped together in an atomic operation.
2.2.2. Where does Spring Integration fit in?
While synchronous communication can take place using either procedure calls or messages, by its nature, asynchronous communication is message-driven. We explored the benefits of the messaging paradigm compared to the service-interface approach, and we found the message-driven approach superior, so here’s what happens next: Spring Integration allows you to focus on the most important part of your system, the logical blueprint that describes how messages travel through the system, how they are routed, and what processing is done in the various nodes.
This is done through a structure of channels and endpoints through which the information-bearing messages travel to carry out the functionality of the application. It’s a very abstract structure. To understand the actions that’ll be taken in response to various messages, what transformations they’ll undergo, or where to send a particular message in order to get certain results, you don’t need to know whether the communication will be synchronous or asynchronous.
Let’s consider the following example:
<channel id="input"/>
<payload-type-router input-channel="input">
<mapping type="siia.fundamentals.Order" channel="orders" />
<mapping type="siia.fundamentals.Notification" channel="notifications" />
</payload-type-router>
<channel id="orders"/>
<channel id="notifications"/>
<service-activator ref="ordersProcessor"
input-channel="orders"
output-channel="results"/>
<service-activator ref="notificationsProcessor"
input-channel="notifications"
output-channel="results"/>
<channel id="results"/>
Without getting into too much detail, this configuration means the following:
All requests made to the system are sent to the input channel where, depending on their payload (either Order or Notification), they’re routed to the appropriate services. Services in this context are just POJOs, completely unaware of the existence of the messaging system. The results of processing the requests are sent to another channel where they’re picked up by another component, and so on.
Figure 2.6 provides a visual representation of the same message flow.
Figure 2.6. Wiring of the order processing system: channels and endpoints define the logical application structure.
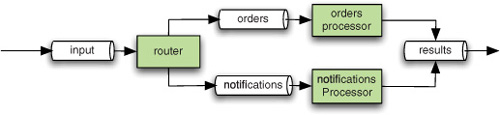
The structure doesn’t seem to tell what kind of interaction takes place (is it synchronous or asynchronous?), and from a logical standpoint, it shouldn’t. The interaction model is determined by the type of channel that’s used for transferring the messages between the endpoints. Spring Integration supports both approaches by using two different types of message channels: DirectChannel (synchronous) and QueueChannel (asynchronous).
The interaction model doesn’t affect the logical design of the system (how many channels, what endpoints, how they’re connected). But to improve the performance, you may want to free the message sending thread (which belongs to the main application) from executing the processing of orders and notifications and do that work asynchronously in the background, as seen in figure 2.8.
SEDA
The technical name for this design is staged event-driven architecture, or SEDA, and you saw it in a previous section.
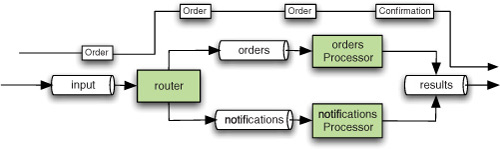
Both types of channels are configured using the same <channel/> element. By default, its behavior is synchronous, so the handling of a single message sent to the input-channel, including routing, invocation of the appropriate service, and whatever comes after that, will be done in the context of the thread that sends the message, as shown in figure 2.7. If you want to buffer the messages instead of passing them directly through a channel and to follow an asynchronous approach, you can use a queue to store them, like this:
Figure 2.7. Synchronous order processing: the continuous line indicates an uninterrupted thread of control along the entire processing path.
<channel id="input"> <queue capacity="10"/> </channel>
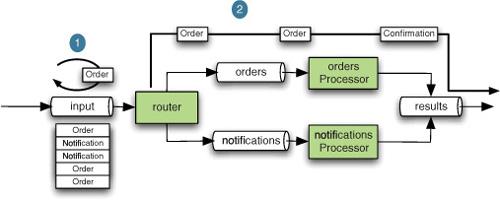
Now the router will poll to see if any messages are available on the channel and will deliver them to the POJO that does the actual processing, as shown in figure 2.8. All this is taken care of transparently by the framework, which will configure the appropriate component. You don’t need to change anything else in your configuration.
Figure 2.8. Asynchronous order processing: the introduction of a buffered channel creates two threads of control (indicated by a continuous
line)—delivery to the router takes place in  and processing takes place in
and processing takes place in  .
.
The configuration can also specify how the polling will be done or how many threads will be available to process notifications or orders, enabling the concurrent processing of those messages.
In this case, your application is implemented as a pipes-and-filters architecture. The behavior of each component encapsulates one specific operation (transformation, business operation, sending a notification, and so on), and the overall design is message-driven so that the coupling between components is kept to a low level. In some environments, it might be desirable to implement a full traversal of the messaging system as a synchronous operation (for example, if the processing is done as part of an online transaction processing system, where immediate response is a requirement, or for executing everything in a single transaction).
In this case, using synchronous DirectChannels would achieve the goal while keeping the general structure of the messaging system unchanged. As you can see, Spring Integration allows you to design applications that work both synchronously and asynchronously, doing what it does best: separating concerns. Logical structure is one concern, but the dynamic of the system is another, and they should be addressed separately.
This overview of synchronous and asynchronous communication wraps up our discussion about coupling. Over the years, the effort to reduce coupling and to take advantage of the available communication infrastructure has led to the development of four major enterprise integration styles, which are the focus of the next section.
2.3. Comparing enterprise integration styles
As the adoption of computer systems in enterprise environments grew, the need to enable interaction between applications within the enterprise soon became apparent. This interaction allowed organizations to both share data and make use of functionality provided by other systems. Though enterprise application integration can take many different forms, from extract-transform-load jobs run overnight to all-encompassing SOA strategies, all approaches leverage one of four well-known integration styles:
- File-based integration
- Shared-database integration
- Remote Procedure Calls
- Message-based integration
In this section, we provide an overview of these four integration styles and their advantages and disadvantages, noting that although Spring Integration is built on the message-based paradigm, the other three forms are supported by the framework.
2.3.1. Integrating applications by transferring files
The most basic approach is for one application to produce a file and for that file to be made available to another system. This approach is simple and generally interoperable because all that’s required is for interacting applications to be able to read and write files. Because the basic requirements for using file-based integration are simple, it’s a fairly common solution, but some of the limitations of filesystems mean that additional complexity may be created in applications having to deal with files.
One limitation is that filesystems aren’t transactional and don’t provide metadata about the current state and validity of a file. As a consequence, it’s hard to tell, for example, if another process is currently updating the file. In general, to work properly, this type of integration requires some strategies to ensure that the receiver doesn’t read inconsistent data, such as a half-written file. Also, it requires setting up a process by which corrupt files are moved out of the way to prevent repeated attempts to process them. Another significant drawback is that applications generally need to poll specific locations to discover if more files are ready to be processed, thus introducing additional application complexity and a potential for unnecessary delay.
Considering these drawbacks, before deciding to use file-based integration, it’s always good to see whether any other integration style would work better. Nevertheless, in certain situations, it may be the only integration option, and it’s not uncommon to come across applications that use it. It’s important in such cases to be diligent and to address the limitations through appropriate strategies, like the ones mentioned previously, and Spring Integration addresses some of them through its support for file-based integration, as discussed in chapter 11.
2.3.2. Interacting through a shared database
Databases are more advanced data storage mechanisms than files and alleviate some of the limitations of the filesystems. They provide atomic operations, well-defined data structures, and mechanisms that provide some guarantees on data consistency.
Shared-database integration consists of providing the different applications with access to the same database. In general, shared databases are used in two scenarios:
- As a smarter form of data transfer, by defining a set of staging tables where the different applications can write data that will be consumed by the receiver applications. Compared with the filesystem style, this approach has the advantage that metadata, validation, and support for concurrent access are available out of the box for the transferred data.
- By allowing different applications to share the same data. This has no direct correspondent to the filesystem style and has the advantage that changes made by one application are made available to everyone else in real-time (unlike the data transfer approach, which involves writing data in the file or staging tables and a certain lag until the recipient application makes use of it).
The challenges of shared-database integration are as follows:
- One-size-fits-all is hardly true in software development, and the compromises necessary to implement a domain model (and subsequent database model) based on the needs of multiple business processes may result in a model that fits no one very well.
- Sharing the same data model may create unwanted coupling between the different applications in the system. This may seriously affect their capabilities of evolving in the future because changing it will require all the other applications to change as well (at least in the parts that deal directly with the shared model).
- Concurrent systems frequently writing the same set of data might face performance problems because exclusive access will need to be granted from time to time, so they will end up locking each other out.
- Caching data in memory might be an issue because applications may not be aware when it becomes stale.
- Database sharing works well with transferring data between applications but doesn’t solve the problem of invoking functionality in the remote application.
When it comes to invoking functionality in the remote application, one possible solution is to use Remote Procedure Calls, which we discuss next.
2.3.3. Exposing a remote API through Remote Procedure Calls
Remote Procedure Calls (RPC) is an integration style that tries to hide the fact that different services are running on different systems. The method invocation is serialized over the network to the service provider, where the service is invoked. The return value is then serialized and sent back to the invoker. This involves proxies and exporters (in Spring) or stubs and skeletons (in EJB).
RPC would presumably allow architects to design scalable applications without developers having to worry about the differences between local and remote invocations. The problem with this approach is that certain details about remoting can’t safely be hidden or ignored. Assuming that RPC can hide these details will lead to simplistic solutions and leaky abstractions. Dealing with problems properly will violate the loose coupling we’ve come to enjoy.
RPC requires that parameters and return values of a service are serializable, which means they can be translated into an intermediate format that can be transmitted over the wire. From case to case, this can be achieved in different ways, such as through Java serialization or using XML marshalling through mechanisms such as Java Architecture for XML Binding (JAXB). This not only restricts the types that can be sent, it also requires that the application code deal with serialization or marshalling errors.
We’re probably not the first to tell you, but it’s worth mentioning again that the network isn’t reliable. You can assume that a local method invocation returns within a certain (reasonable) time with the return value or an exception, but with a network connection in the mix, this can take much longer, and worse, it’s much less predictable. The trickiest part is that the service that’s invoked can return successfully, but the invoker doesn’t get the response. Assuming you don’t need to account for this is usually a bad idea.
Finally, serializing arguments and return values harms interoperability. Sending a representation of some Serializable to an application written in Perl is wishful thinking at best. The need to know about the method name and argument order is questionable. Once this is understood, it’s not such a big leap to look for an interoperable representation and a way to decouple the integration concerns from the method signatures on both sides. This is one of the goals of messaging, our final integration style and the one that’s the general focus of Spring Integration.
2.3.4. Exchanging messages
Messaging is an integration style based on exchanging encapsulated data packets (messages) between components (endpoints) through connections (channels). As described at www.enterpriseintegrationpatterns.com, the packets should be small, and they should be shared frequently, reliably, immediately, and asynchronously. Potentially this resolves many of the problems of encapsulation and error handling associated with the previous three integration styles. It also provides an easy way to deal with sharing both data and functionality, and overall it’s the most recommended integration style when you have a choice.
Message exchanging is the core paradigm of Spring Integration, and we discuss in detail in chapters 3 and 4 the concepts behind the integration style and how they’re applied in the framework.
2.4. Summary
This chapter explained the fundamental concepts that stand behind enterprise application integration. We provided applicable samples from the framework, and in the rest of the book, you’ll see them at work.
First, we discussed coupling as a way to measure how many assumptions two independent systems make about each other. You saw how important it is to minimize coupling to allow the components to evolve independently. There are multiple forms of coupling, but the most important ones are type-level and temporal coupling. Dependency injection helps you deal with type-level coupling, and using a message passing approach instead of direct calls (either local or remote) helps you deal with temporal coupling.
We presented a detailed overview of the differences between synchronous and asynchronous communication and its implications in coupling, system complexity, and performance. You saw how Spring Integration helps separate the logical design of the system from the dynamic behavior at runtime (whether interaction should be synchronous or asynchronous).
Finally, you got an overview of the four application integration paradigms and their respective strengths and weaknesses. Spring Integration is generally focused on messaging, but it provides support for using the other three types as well.
We introduced Spring Integration from a high level in the first chapter. Then we zoomed in on the fundamental concepts at the root of messaging in chapter 2. In chapter 3, we look in detail at the parts of Spring Integration that enable messaging, starting with messages and channels.