
Chapter 1. Introduction to Spring Integration
We live in an event-driven world. Throughout each day, we’re continuously bombarded by phone calls, emails, and instant messages. As if we’re not distracted enough by all of this, we also subscribe to RSS feeds and sign up for Twitter accounts and other social media sites that add to the overall event noise. In fact, technological progress seems to drive a steady increase in the number and types of events we’re expected to handle. In today’s world of hyperconnectivity, it’s a wonder we can ever focus and get any real work done. What saves us from such event-driven paralysis is that we can respond to most events and messages at our convenience. Like a return address on an envelope, events usually carry enough information for us to know how and where to respond.
Now, let’s turn our attention to software. When we design and build a software application, we strive to provide a foundation that accurately models the application’s domain. The domain is like a slice of reality that has particular relevance from the perspective of a given business. Therefore, successful software projects are accurate reflections of the real world, and as such, the event-driven nature plays an increasingly important role. Whereas many software applications are based on a conversational model between a client and a server, that paradigm doesn’t always provide an adequate reflection. Sometimes the act of making a request and then waiting for a reply is not only inefficient but artificial when compared with the actual business actions being represented.
For example, consider an online travel booking application. When you plan a trip by booking a flight, hotel, and rental car, you don’t typically sit and wait at the computer for all of the trip details. You may receive a confirmation number for the trip itself and a high-level summary of the various reservations, but the full details will arrive later. You may receive an email telling you to log in and review the details. In other words, even though the application may be described as a service, it’s likely implemented as an event-driven system. Too many different services are involved to wrap the whole thing in a single synchronous action as the traditional client/server conversational model may suggest. Instead, your request is likely processed by a series of events, or messages, being passed across a range of participating systems. When designing software, it’s often useful to consider the events and messages that occur within the domain at hand. Focusing on events and messages rather than being excessively service-oriented may lead to a more natural way to think about the problem.
As a result of all this, it’s increasingly common that enterprise developers must build solutions that respond to a wide variety of events. In many cases, these solutions are replacements for outdated client/server versions, and in other cases, they’re replacements for scheduled back-office processes. Sure, those nightly batch-processing systems that grab a file and process it shortly after midnight still exist, but it’s increasingly common to encounter requirements to refactor those systems to be more timely. Perhaps a new service-level agreement (SLA) establishes that files must be processed within an hour of their arrival, or maybe the nightly batch option is now insufficient due to 24/7 availability and globalized clientele. These are, after all, the motivating factors behind such hyped phrases as “near-real-time.” That phrase usually suggests that legacy file-drop systems need to be replaced or augmented with message-driven solutions. Waiting for the result until the next day is no longer a valid option. Perhaps the entry point is now a web service invocation, or an email, or even a Twitter message. And by the way, those legacy systems won’t be completely phased out for several years, so you need to support all of the above. That means you also need to be sure that the refactoring process can be done in an incremental fashion.
Spring Integration addresses these challenges. It aims to increase productivity, simplify development, and provide a solid platform from which you can tackle the complexities. It offers a lightweight, noninvasive, and declarative model for constructing message-driven applications. On top of this, it includes a toolbox of commonly required integration components and adapters. With these tools in hand, developers can build the types of applications that literally change the way their companies do business.
Spring Integration stands on the shoulders of two giants. First is the Spring Framework, a nearly ubiquitous and highly influential foundation for enterprise Java applications that has popularized a programming model which is powerful because of its simplicity. Second is the book Enterprise Integration Patterns (Hohpe and Woolf, Addison-Wesley, 2003), which has standardized the vocabulary and catalogued the patterns of common integration challenges. The original prototype that eventually gave birth to the Spring Integration project began with the recognition that these two giants could produce ground-breaking offspring.
By the end of this chapter, you should have a good understanding of how the Spring Integration framework extends the Spring programming model into the realm of enterprise integration patterns. You’ll see that a natural synergy exists between that model and the patterns. If the patterns are what Spring Integration supports, the Spring programming model is how it supports them. Ultimately, software patterns exist to describe solutions to common problems, and frameworks are designed to support those solutions. Let’s begin by zooming out to see what solutions Spring Integration supports at a very high level.
1.1. Spring Integration’s architecture
From the 10,000-foot view, Spring Integration consists of two parts. At its core, it’s a messaging framework that supports lightweight, event-driven interactions within an application. On top of that core, it provides an adapter-based platform that supports flexible integration of applications across the enterprise. These two roles are depicted in figure 1.1.
Figure 1.1. Two areas of focus for Spring Integration: lightweight intra-application messaging and flexible interapplication integration

Everything depicted in the core messaging area of the figure would exist within the scope of a single Spring application context. Those components would exchange messages in a lightweight manner because they’re running in the same instance of a Java Virtual Machine (JVM). There’s no need to worry about serialization, and unless necessary for a particular component, the message content doesn’t need to be represented in XML. Instead, most messages will contain plain old Java object (POJO) instances as their payloads.
The application integration area is different. There, adapters are used to map the content from outbound messages into the format that some external system expects to receive and to map inbound content from those external systems into messages. The way mapping is implemented depends on the particular adapter, but Spring Integration provides a consistent model that’s easy to extend. The Spring Integration 2.0 distribution includes support for the following adapters:
- Filesystem, FTP, or Secured File Transfer Protocol (SFTP)
- User Datagram Protocol (UDP)
- Transmission Control Protocol (TCP)
- HTTP (Representational State Transfer [REST])
- Web services (SOAP)
- Mail (POP3 or IMAP for receiving, SMTP for sending)
- Java Message Service (JMS)
- Java Database Connectivity (JDBC)
- Java Management Extensions (JMX)
- Remote Method Invocation (RMI)
- Really Simple Syndication (RSS) feeds
- Extensible Messaging and Presence Protocol (XMPP)
Most of the protocols and transports listed here can act as either an inbound source or an outbound target for Spring Integration messages. In Spring Integration, the pattern name Channel Adapter applies to any unidirectional inbound or outbound adapter. In other words, an inbound channel adapter supports an in-only message exchange, and an outbound channel adapter supports an out-only exchange. Any bidirectional, or request-reply, adapter is known as a Gateway in Spring Integration. In part 2 of this book, you’ll learn about channel adapters and gateways in detail.
Figure 1.1 obviously lacks detail, but it captures the core architecture of Spring Integration surprisingly well. The figure contains several boxes, and those boxes are connected via pipes. Now substitute “filters” for boxes, and you have the classic pipes-and-filters architectural style.[1]
1 In this context, it’s probably better to think of filter as meaning processor.
Anyone familiar with a UNIX-based operating system can appreciate the pipes-and-filters style: it provides the foundation of such operating systems. Consider a basic example:
$> echo foo | sed s/foo/bar/ bar
You can see that it’s literally the pipe symbol being used to connect two commands (the filters). It’s easy to swap out different processing steps or to extend the chain to accomplish more complex tasks while still using these same building blocks (returns elided):
$> cat /usr/share/dict/words | grep ^foo | head -9 | sed s/foo/bar/ bar bard barder bardful bardless bardlessness bardstuff bardy barfaraw
To avoid digressing into a foofaraw,[2] we should turn back to the relevance of this architectural style for Spring Integration. Those of us using the UNIX pipes-and-filters model on a day-to-day basis may take it for granted, but it provides a great example of two of the most universally applicable characteristics of good software design: low coupling and high cohesion.
2 “A great fuss or disturbance about something very insignificant.” Random House via Dictionary.com.
Thanks to the pipe, the processing components aren’t connected directly to each other but may be used in various loosely coupled combinations. Likewise, to provide useful functionality in a wide variety of such combinations, each processing component should be focused on one task with clearly defined input and output requirements so that the implementation itself is as cohesive, and hence reusable, as possible.
These same characteristics also describe the foundation of a well-designed messaging architecture. Enterprise Integration Patterns introduces Pipes-and-Filters as a general style that promotes modularity and flexibility when designing messaging applications. Many of the other patterns discussed in that book can be viewed as more specialized versions of the pipes-and-filters style.
The same holds true for Spring Integration. At the lowest level, it has simple building blocks based on the pipes-and-filters style. As you move up the stack to more specialized components, they exhibit the characteristics and perform the roles of other patterns described in Enterprise Integration Patterns. In other words, if it were representing an actual Spring Integration application, the boxes in figure 1.1 could be labeled with the names of those patterns to depict the actual roles being performed. All of this makes sense when you recall our description of Spring Integration as essentially the Spring programming model applied to those patterns. Let’s take a quick tour of the main patterns now. Then we’ll see how the Spring programming model enters the picture.
1.2. Spring Integration’s support for enterprise integration patterns
Enterprise Integration Patterns describes the patterns used in the exchange of messages, as well as the patterns that provide the glue between applications. Like the diagram in figure 1.1, it’s about messaging and integration in the broadest sense, and the patterns apply to both intra-application and inter application scenarios. Spring Integration supports the patterns described in the book, so we need to establish a broad understanding of the definitions of these patterns and the relations between them.
From the most general perspective, only three base patterns make up enterprise integration patterns: Message, Message Channel, and Message Endpoint. Figure 1.2 shows how these components interact with each other in a typical integration application.
Figure 1.2. A message is passed through a channel from one endpoint to another endpoint.

There are two main ways to differentiate between these patterns. First, each pattern has more specific subtypes, and second, some patterns are composite patterns. This section focuses on the subtypes so you have a clear understanding of the building blocks. Composite patterns are introduced as needed throughout the book.
1.2.1. Messages
A message is a unit of information that can be passed between different components, called message endpoints. Messages are typically sent after one endpoint is done with a bit of work, and they trigger another endpoint to do another bit of work. Messages can contain information in any format that’s convenient for the sending and receiving endpoints. For example, the message’s payload may be XML, a simple string, or a primary key referencing a record in a database. See figure 1.3.
Figure 1.3. A message consists of a single payload and zero or more headers, represented here by the square and circle, respectively.
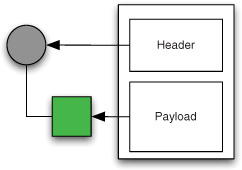
Each message consists of headers and a pay-load. The header contains data that’s relevant to the messaging system, such as the Return Address or Correlation ID. The payload contains the actual data to be accessed or processed by the receiver. Messages can have different functions. For example, a Command Message tells the receiver to do something, an Event Message notifies the receiver that something has happened, and a Document Message transfers some data from the sender to the receiver.
In all of these cases, the message is a representation of the contract between the sender and receiver. In some applications it might be fine to send a reference to an object over the channel, but in others it might be necessary to use a more interoperable representation like an identifier or a serialized version of the original data.
1.2.2. Message Channels
The message channel is the connection between multiple endpoints. The channel implementation manages the details of how and where a message is delivered but shouldn’t need to interact with the payload of a message. Whereas the most important characteristic of any channel is that it logically decouples producers from consumers, there are a number of practical implementation options. For example, a particular channel implementation might dispatch messages directly to passive consumers within the same thread of control. On the other hand, a different channel implementation might buffer messages in a queue whose reference is shared by the producer and an active consumer such that the send and receive operations each occur within different threads of control. Additionally, channels may be classified according to whether messages are delivered to a single endpoint (point-to-point) or to any endpoint that is listening to the channel (publish-subscribe). As mentioned earlier, regardless of the implementation details, the main goal of any message channel is to decouple the message endpoints on both sides from each other and from any concerns of the underlying transport.
Two endpoints can exchange messages only if they’re connected through a channel. The details of the delivery process depend on the type of channel being used. We review many characteristics of the different types of channels later when we discuss their implementations in Spring Integration. Message channels are the key enabler for loose coupling. Both the sender and receiver can be completely unaware of each other thanks to the channel between them. Additional components may be needed to connect services that are completely unaware of messaging to the channels. We discuss this facet in the next section on message endpoints.
Channels can be categorized based on two dimensions: type of handoff and type of delivery. The handoff can be either synchronous or asynchronous, and the delivery can be either point-to-point or publish-subscribe. The former distinction will be discussed in detail in the synchronous versus asynchronous section of the next chapter. The latter distinction is conceptually simpler, and central to enterprise integration patterns, so we describe it here.
In point-to-point messaging (see figure 1.4), each single message that’s sent by a producer is received by exactly one consumer. This is conceptually equivalent to a postcard or phone call. If no consumer receives the message, it should be considered an error. This is especially true for any system that must support guaranteed delivery. Robust point-to-point messaging systems should also include support for load balancing and failover. The former would be like calling each number on a list in turn as new messages are to be delivered, and the latter would be like a home phone that’s configured to fall back to a mobile when nobody is home to answer it.
Figure 1.4. A Point-to-Point Channel
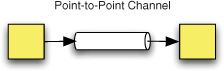
As these cases imply, which consumer receives the message isn’t necessarily fixed. For example, in the Competing Consumers (composite) pattern, multiple consumers compete for messages from a single channel. Once one of the consumers wins the race, no other consumer will receive that message from the channel. Different consumers may win each time, though, because the main characteristic of that pattern is that it offers a consumer-driven approach to load balancing. When a consumer can’t handle any more load, it stops competing for another message. Once it’s able to handle load again, it will resume.
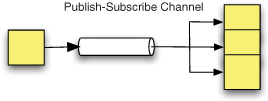
Unlike point-to-point messaging, a Publish-Subscribe Channel (figure 1.5) delivers the same message to zero or more subscribers. This is conceptually equivalent to a newspaper or the radio. It provides a gain in flexibility because consumers can tune in to the channel at runtime. The drawback of publish-subscribe messaging is that the sender isn’t informed about message delivery or failure to the same extent as in point-to-point configurations. Publish-subscribe scenarios often require failure-handling patterns such as Idempotent Receiver or Compensating Transactions.
Figure 1.5. A Publish-Subscribe Channel
1.2.3. Message endpoints
Message endpoints are the components that actually do something with the message. This can be as simple as routing to another channel or as complicated as splitting the message into multiple parts or aggregating the parts back together. Connections to the application or the outside world are also endpoints, and these connections take the form of channel adapters, messaging gateways, or service activators. We discuss each of them later in this section.
Message endpoints basically provide the connections between functional services and the messaging framework. From the point of view of the messaging framework, endpoints are at the end of channels. In other words, a message can leave the channel successfully only by being consumed by an endpoint, and a message can enter the channel only by being produced by an endpoint. There are many different types of endpoints. We discuss a few of them here to give you a general idea.
Channel Adapter
A Channel Adapter (see figure 1.6) connects an application to the messaging system. In Spring Integration we chose to constrict the definition to include only connections that are unidirectional, so a unidirectional message flow begins and ends in a channel adapter. Many different kinds of channel adapters exist, ranging from a method-invoking channel adapter to a web service channel adapter. We go into the details of these different types in the appropriate chapters on different transports. For now, it’s sufficient to remember that a channel adapter is placed at the beginning and the end of a unidirectional message flow.
Figure 1.6. Channel Adapter

Messaging Gateway
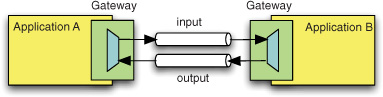
In Spring Integration, a Messaging Gateway (see figure 1.7) is a connection that’s specific to bidirectional messaging. If an incoming request needs to be serviced by multiple threads but the invoker needs to remain unaware of the messaging system, an inbound gateway provides the solution. On the outbound side, an incoming message can be used in a synchronous invocation, and the result is sent on the reply channel. For example, outbound gateways can be used for invoking web services and for synchronous request-reply interactions over JMS.
Figure 1.7. Messaging Gateway
A gateway can also be used midstream in a unidirectional message flow. As with the channel adapter, we’ve constrained the definition of messaging gateway a bit in comparison to Enterprise Integration Patterns (see figure 1.8.)
Figure 1.8. Messaging Gateway and Channel Adapters

Service Activator
A Service Activator (see figure 1.9) is a component that invokes a service based on an incoming message and sends an outbound message based on the return value of this service invocation. In Spring Integration, the definition is constrained to local method calls, so you can think of a service activator as a method-invoking outbound gateway. The method that’s being invoked is defined on an object that’s referenced within the same Spring application context.
Figure 1.9. Service Activator

Router
A Router (see figure 1.10) determines the next channel a message should be sent to based on the incoming message. This can be useful to send messages with different payloads to different, specialized consumers (Content-Based Router). The router doesn’t change anything in the message and is aware of channels. Therefore, it’s the endpoint that’s typically closest to the infrastructure and furthest removed from the business concerns.
Figure 1.10. Router
Splitter
A Splitter (see figure 1.11) receives one message and splits it into multiple messages that are sent to its output channel. This is useful whenever the act of processing message content can be split into multiple steps and executed by different consumers at the same time.
Figure 1.11. Splitter

Aggregator
An Aggregator (figure 1.12) waits for a group of correlated messages and merges them together when the group is complete. The correlation of the messages typically is based on a correlation ID, and the completion is typically related to the size of the group. A splitter and an aggregator are often used in a symmetric setup, where some work is done in parallel after a splitter, and the aggregated result is sent back to the upstream gateway.
Figure 1.12. Aggregator

You’ll see many more patterns throughout the book, but what we covered here should be sufficient for this general introduction. If you paid close attention while reading the first paragraph in section 1.2, you may have noticed that we said Spring Integration supports the enterprise integration patterns, not that it implements the patterns. That’s a subtle but important distinction. In general, software patterns describe proven solutions to common problems. They shouldn’t be treated as recipes. In reality, patterns rarely have a one-to-one mapping to a single implementation, and context-dependent factors often lead to particular implementation details.
As far as the enterprise integration patterns are concerned, some, such as the message and message channel patterns, are more or less implemented. Others are only partially implemented because they require the addition of some domain-specific logic; examples are the content-based router in which the content is dependent on the domain model and the service activator in which the service to be activated is part of a specific domain. Yet other patterns describe individual parts of a larger process; examples are the correlation ID we mentioned when describing splitter and aggregators and the return address that we discuss later. Finally, there are patterns that simply describe a general style, such as the pipes-and-filters pattern. With these various pattern categories in mind, let’s now see how the concept of inversion of control applies to Spring Integration’s support for the patterns.
1.3. Enterprise integration patterns meet Inversion of Control
Now that we’ve seen some of the main enterprise integration patterns, we’re ready to investigate the benefits that Spring’s programming model provides when applied to these patterns. The theme of inversion of control (IoC) is central to this investigation because it’s a significant part of the Spring philosophy.[3] For the purpose of this discussion, we consider IoC in broad terms.
3 We assume some level of Spring knowledge primarily because we can’t cover everything from the basics of Spring to the full spectrum of the Spring Integration framework. If you’re new to Spring, you may want to check out some other books, such as Spring in Action, Third Edition, by Craig Walls (Manning, 2011).
The main idea behind IoC and the Spring Framework itself is that code should be as simple as possible while still supporting all of the complex requirements of enterprise applications. In other words, those complexities can’t be wholly ignored but ideally shouldn’t have a negative impact on developer productivity or software quality. To accomplish that goal, the responsibility of controlling those complexities should be inverted from the application code to a framework. The bottom line is that enterprise development isn’t easy, but it can be much easier when a framework handles much of the difficult work. With that as our definition, we discuss two key techniques that invert control when using Spring: dependency injection and method invocation. We also briefly explain the role of each technique in the Spring Integration framework.
1.3.1. Dependency injection
Dependency injection is the first thing most people think of when they hear inversion of control, and that’s understandable because it’s probably the most common application of the principle and the core functionality of IoC frameworks like Spring. Entire books are written on this subject,[4] but here we provide a quick overview to highlight the benefits of this technique and to see how it applies to Spring Integration.
4Dependency Injection by Dhanji R. Prasanna (Manning, 2009).
Object-oriented software is all about modularity. When you design applications, you carefully consider the units of functionality that should be captured within a single component and the proper boundaries between collaborating components. These decisions lead to contracts in the form of well-defined interfaces that dictate the input and output for a given module. When one component depends on another, it should make assumptions only about such an interface rather than about a particular implementation. This promotes the encapsulation of implementation details so that those details can change within the bounds of the interface definition without impacting other code. What’s the big deal? you may be asking; this is common sense. But it all breaks down as soon as we do something as seemingly harmless as the following:
Service service = new MySpecificServiceImplementation();
Now the code is tightly coupled directly to an implementation type. That implementation is being assigned to an interface, and hopefully the caller is never required to downcast. But no matter how you slice it, the code is tied to an implementation because interfaces are only contracts and are separate from the implementations. An implementation type must be chosen for instantiation, and the simplest means of instantiating objects in Java is by calling a constructor.
There is another option, and it often follows as a seemingly logical conclusion to this problem. After recognizing that the implementation type leaked into the caller’s code, even though that code really only needs the interface, a factory can be added to provide a level of indirection. Rather than constructing the object, the caller can ask for it:
Service service = factory.createTheServiceForMe();
This is the first step down the road of IoC. The factory handles the responsibility that was previously handled directly in the caller’s code. The control is inverted in favor of a factory. The caller gladly relinquishes that control in return for having to make fewer assumptions about the implementation it’s using. This seems to solve the problem at first, but to some degree it’s just pushing the problem one step further away. It’s the programmatic equivalent of sweeping dirt under the rug.
A better solution would remove all custom infrastructure code, including the factory itself. That final step to full IoC is surprisingly simple: define a constructor or setter method. In effect, that declares the dependency without any assumptions about who’s responsible for instantiating or locating it:
public class Caller {
private Service service; // an interface
public void setService(Service service) {
this.service = service;
}
...
}
In a unit test that focuses on this single component, it’s trivial to provide a stub or mock implementation of the dependency directly. Then, in a fully integrated system that may have many components sharing dependencies as well as complex transitive dependency chains, a framework such as Spring can handle the responsibility. All you need to do is provide the implementation type as metadata. Rather than being hardcoded, as in our first example, there is now a clear separation of code and configuration:[5]
5 The metadata may alternatively be provided via annotations. For example, the @Autowired annotation can be placed on the setService(..) method, and the @Service annotation could be applied on the implementation class so that XML isn’t required. You’ll see examples of the annotation-based style throughout the book, but XML was chosen here because it may be easier to understand initially.
<bean id="caller" class="example.Caller"> <property name="service" ref="myService"/> </bean> <bean id="myService" class="example.MySpecificServiceImplementation"/>
The Spring Integration framework takes advantage of this same technique to manage dependencies for its components. In fact, you can use the same syntax to define the individual bean definitions, but for convenience, custom XML schemas are defined so that you can declare a namespace[6] and then use elements and attributes whose names match the domain. The domain in this case is that of the enterprise integration patterns, so the element and attribute names will match those components described in the previous section. For example, any Spring Integration message endpoint requires a reference to at least one message channel (determined by its role as producer, consumer, or both). Here’s an example of a simple message splitter:
6 Visit www.springframework.org/schema/integration to explore Spring Integration’s various XML schema namespace configurations.
<splitter input-channel="orders" output-channel="items"/>
Another common case for dependency injection is when a particular implementation of a strategy interface[7] needs to be wired into the component that delegates to that strategy. For example, here’s a message aggregator with a custom strategy for determining when the processed items received qualify as a complete order that can be released:
7 See the Strategy Method pattern in Design Patterns: Elements of Reusable Object-Oriented Software by the Gang of Four: Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides (Addison-Wesley, 1994).
<aggregator input-channel="processedItems"
release-strategy="orderCompletionChecker"
output-channel="processedOrders"/>
Don’t worry about understanding the details of the examples yet. These components are covered in more detail throughout the book. The only point we’re trying to make so far is that dependency injection plays a role in connecting the collaborating components while avoiding hardcoded references.
1.3.2. Method invocation
IoC is often described as following the Hollywood principle: Don’t call us, we’ll call you.[8] From the preceding description of dependency injection, you can see how well this applies. Rather than writing code that calls a constructor or even a factory method, you can rely on the framework to provide that dependency by calling a constructor or setter method. This same principle can also apply to method invocation at runtime.
8 In Hollywood, that probably means, “Don’t bother us with your calls. On the slim chance that you get the part, we’ll call you. But we probably won’t, so get over it.” In software, we rely on things being more definite.
Let’s first consider the Spring Framework’s support for asynchronous reception of JMS messages. Prior to Spring 2.0, the only support for receiving JMS messages within Spring was the synchronous (blocking) receive() method on its JmsTemplate. That works fine when you want to control polling of a JMS destination, but when working with JMS, the code that handles incoming messages can usually be reactive rather than proactive. In fact, the JMS API defines a simple MessageListener interface, and the Enterprise JavaBeans (EJB) 2.1 specification introduced message-driven beans as a component model for hosting such listeners within an application server.
public interface MessageListener {
void onMessage(Message message);
}
With version 2.0, Spring introduced its own MessageListener containers as a lightweight alternative. MessageListeners can be configured and deployed in a Spring application running in any environment instead of requiring an EJB container. As with message-driven beans, a listener is registered with a certain JMS destination, but with Spring, the listener’s container is a simple object that is itself managed by Spring. There’s even a dedicated XML namespace:
<jms:listener-container>
<jms:listener destination="someDestination" ref="someListener"/>
</jms:listener-container>
The container manages the subscription and the background processes that are ultimately responsible for receiving the messages. There are configuration options for controlling the number of concurrent consumers, managing transactions, and more:
It gets even more interesting and more relevant for our lead-up to Spring Integration when we look at Spring’s support for invoking methods on any Spring-managed object. Sure, the MessageListener interface seems simple enough, but it has a few limitations. First, it requires a dependency on the JMS API. This inhibits testing and also pollutes otherwise pure business logic achieved by relying on the IoC principle. Second, and more severe, it has a void return type. That means you can’t easily send a reply message from the listener method’s implementation. Both of these limitations are eliminated if you instead reference a POJO instance that doesn’t implement MessageListener and add the method attribute to the configuration. For example, let’s assume you want to invoke the following service method:
public class QuoteService {
public BigDecimal currentQuote(String tickerSymbol) {...}
}
The configuration would look like this:
<jms:listener-container>
<jms:listener destination="quoteRequests" ref="quoteService"
method="currentQuote"/>
</jms:listener-container>
<bean id="quoteService" class="example.QuoteService"/>
Whatever client is passing request messages to the quoteRequest destination could also provide a JMSReplyTo property on each request message. Spring’s listener container uses that property to send the reply message to the destination where the caller is waiting for the response to arrive. Alternatively, a default reply destination can be provided with another attribute in the XML.
This message-driven support is a good example of IoC because the listener container is handling the background processes. It’s also a good example of the Hollywood principle because the framework calls the referenced object whenever a message arrives.
Another common requirement in enterprise applications is to perform some task at a certain time or repeatedly on the basis of a configured interval. Java provides some basic support for this with java.util.Timer, and, beginning with version 5, a more powerful scheduling abstraction was added: java.util.concurrent.Scheduled-ExecutorService. For functionality beyond what the core language provides, there are projects such as Quartz[9] to support scheduling based on cron expressions, persistence of job data, and more.
Interacting with any of these schedulers normally requires code that’s responsible for defining and registering a task. For example, imagine you have a method called poll in a custom FilePoller class. You might wrap that call in a Runnable and schedule it in Java as in the following listing.
Listing 1.1. Scheduling a task programmatically
Runnable task = new Runnable() {
public void run() {
File file = filePoller.poll();
if (file != null) {
fileProcessor.process(file);
}
}
};
long initialDelay = 0;
long rate = 60;
ScheduledExecutorService scheduler =
Executors.newScheduledThreadPool(5);
scheduler.scheduleAtFixedRate(task, initialDelay,
rate, TimeUnit.SECONDS);
The Spring Framework can handle much of that for you. It provides method-invoking task adapters and support for automatic registration of the tasks. That means you don’t need to add any extra code. Instead, you can declaratively register your task. For example, in Spring 3.0, the configuration might look like this:
<task:scheduled-tasks scheduler="myScheduler">
<task:scheduled ref="filePoller" method="poll" fixed-rate="60000"/>
</task:scheduled-tasks>
<task:scheduler id="myScheduler" pool-size="5"/>
As you can see, this provides a literal example of the Hollywood principle. The framework is now calling the code. This provides a few benefits beyond the obvious simplification. First, even though the code being invoked should be thoroughly unit tested, you can rest assured that the Spring scheduling mechanism is tested already. Second, the configuration of the initial delay and fixed-rate period for the task and the thread pool size for the scheduler are all externalized. By enforcing this separation of configuration from code, you’re much less likely to end up with hardcoded values in the application. The code is not only easier to test but also more flexible for deploying into different environments.
Now let’s see how this same principle applies to Spring Integration. The configuration of scheduled tasks follows the same technique as shown previously. The configuration of a Polling Consumer’s trigger can be provided through declarative configuration. Spring Integration takes the previous example a step further by actually providing a file-polling channel adapter:
<file:inbound-channel-adapter directory="/tmp/example" channel="files">
<poller max-messages-per-poll="10" fixed-rate="60000"/>
</file:inbound-channel-adapter>
We should also mention that both the core Spring Framework scheduling support and the Spring Integration polling triggers accept cron expressions in place of the interval-based values. If you only want to poll during regular business hours, something like the following would do the trick:
<file:inbound-channel-adapter directory="/tmp/example" channel="files">
<poller max-messages-per-poll="10" cron="0 * 9-17 * * MON-FRI"/>
</file:inbound-channel-adapter>
For now, let’s move beyond these isolated examples. Thus far, you’ve seen just a few glimpses of how the IoC principle and the Spring programming model can be applied to enterprise integration patterns. The best way to reinforce that knowledge is by diving into a simple but complete hands-on example.
1.4. Say hello to Spring Integration
Now that you’ve seen the basic enterprise integration patterns and an overview of how IoC can be applied to those patterns, it’s time to jump in and meet the Spring Integration framework face to face. In the time-honored tradition of software tutorials, let’s say hello to the Spring Integration world.
Spring Integration aims to provide a clear line between code and configuration. The components provided by the framework, which often represent the enterprise integration patterns, are typically configured in a declarative way using either XML or Java annotations as metadata. But many of those components act as stereotypes or templates. They play a role that’s understood by the framework, but they require a reference to some user-defined, domain-specific behavior in order to fulfill that role.
For our Hello World example, the domain-specific behavior is the following:
package siia.helloworld.channel;
public class MyHelloService implements HelloService {
@Override
public void sayHello(String name) {
System.out.println("Hello " + name);
}
}
The interface that MyHelloService implements is HelloService, defined as follows:
package siia.helloworld.channel;
public interface HelloService {
void sayHello(String name);
}
There we have it: a classic Hello World example. This one is flexible enough to say hello to anyone. Because this book is about Spring Integration, and we’ve already established that it’s a framework for building messaging applications based on the fundamental enterprise integration patterns, you may be asking, Where are the Message, Channel, and Endpoint? The answer is that you typically don’t have to think about those components when defining the behavior. What we implemented here is a straightforward POJO with no awareness whatsoever of the Spring Integration API. This is consistent with the general Spring emphasis on noninvasiveness and separation of concerns. That said, let’s now tackle those other concerns, but separately, in the configuration:
<beans:beans
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/integration"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd">
<channel id="names"/>
<service-activator input-channel="names" ref="helloService"
method="sayHello"/>
<beans:bean id="helloService"
class="siia.helloworld.channel.MyHelloService"/>
</beans:beans>
This code should look familiar. In the previous section, we saw an example of the Spring Framework’s support for message-driven POJOs, and the configuration for that example included an element from the jms namespace that similarly included the ref and method attributes for delegating to a POJO via an internally created Message-ListenerAdapter instance. Spring Integration’s service activator plays the same role, except that this time it’s more generic. Rather than being tied to the JMS transport, the service activator is connected to a Spring Integration MessageChannel within the ApplicationContext. Any component could be sending messages to this service activator’s input-channel. The key point is that the service activator doesn’t require any awareness or make any assumptions about that sending component.
All of the configured elements contribute components to a Spring Application-Context. In this simple case, you can bootstrap that context programmatically by instantiating the Spring context directly. Then, you can retrieve the MessageChannel from that context and send it a message. We use Spring Integration’s MessageBuilder to construct the actual message, shown in the following listing. Don’t worry about the details; you’ll learn much more about message construction in chapter 3.
Listing 1.2. Hello World with Spring Integration
package siia.helloworld.channel;
import org.springframework.context.ApplicationContext;
import
org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.integration.Message;
import org.springframework.integration.MessageChannel;
import org.springframework.integration.support.MessageBuilder;
public class HelloWorldExample {
public static void main(String args[]) {
String cfg = "siia/helloworld/channel/context.xml";
ApplicationContext context = new ClassPathXmlApplicationContext(cfg);
MessageChannel channel =
context.getBean("names", MessageChannel.class);
Message<String> message =
MessageBuilder.withPayload("World").build();
channel.send(message);
}
}
Running that code produces “Hello World” in the standard output console. That’s pretty simple, but it would be even nicer if there were no direct dependencies on Spring Integration components even on the caller’s side. Let’s make a few minor changes to eradicate those dependencies.
First, to provide a more realistic example, let’s modify the HelloService interface so that it returns a value rather than simply printing out the result itself:
package siia.helloworld.gateway;
public class MyHelloService implements HelloService {
@Override
public String sayHello(String name) {
return "Hello " + name;
}
}
Spring Integration handles the return value in a way that’s similar to the Spring JMS support described earlier. You add one other component to the configuration, a gateway proxy, to simplify the caller’s interaction. Here’s the revised configuration:
<beans:beans
xmlns:beans="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.springframework.org/schema/integration"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/integration
http://www.springframework.org/schema/integration/spring-integration.xsd">
<gateway id="helloGateway"
service-interface="siia.helloworld.gateway.HelloService"
default-request-channel="names"/>
<channel id="names"/>
<service-activator input-channel="names" ref="helloService"
method="sayHello"/>
<beans:bean id="helloService"
class="siia.helloworld.gateway.MyHelloService"/>
</beans:beans>
Note that the gateway element refers to a service interface. This is similar to the way the Spring Framework handles remoting. The caller should only need to be aware of an interface, while the framework creates a proxy that implements that interface. The proxy is responsible for handling the underlying concerns such as serialization and remote invocation, or in this case, message construction and delivery. You may have noticed that the MyHelloService class does implement an interface. Here’s what the HelloService interface looks like:
package siia.helloworld.gateway;
public interface HelloService {
String sayHello(String name);
}
Now the caller only needs to know about the interface. It can do whatever it wants with the return value. In the following listing, you just move the console printing to the caller’s side. The service instance would be reusable in a number of situations. The key point is that this revised main method now has no direct dependencies on the Spring Integration API.
Listing 1.3. Hello World revised to use a Gateway proxy
package siia.helloworld.gateway;
import org.springframework.context.ApplicationContext;
import
org.springframework.context.support.ClassPathXmlApplicationContext;
public class HelloWorldExample {
public static void main(String args[]) {
String cfg = "siia/helloworld/gateway/context.xml";
ApplicationContext context = new ClassPathXmlApplicationContext(cfg);
HelloService helloService =
context.getBean("helloGateway", HelloService.class);
System.out.println(helloService.sayHello("World"));
}
}
As with any Hello World example, this one only scratches the surface. Later you’ll learn how the result value can be sent to another downstream consumer, and you’ll learn about more sophisticated request-reply interactions. The main goal for now is to provide a basic foundation for applying what you’ve learned in this chapter. Spring Integration brings the enterprise integration patterns and the Spring programming model together. Even in this simple example, you can see some of the characteristics of that programming model, such as IoC, separation of concerns, and an emphasis on noninvasiveness of the API.
1.5. Summary
We covered a lot of ground in this chapter. You learned that Spring Integration addresses both messaging within a single application and integrating across multiple applications. You learned the basic patterns that also describe those two types of interactions.
As you progress through this book, you’ll learn in much greater detail how Spring Integration supports the various enterprise integration patterns. You’ll also see the many ways in which the framework builds on the declarative Spring programming model. So far, you’ve seen only a glimpse of these features, but some of the main themes of the book should already be clearly established.
First, with Spring’s support for dependency injection, simple objects can be wired into these patterns. Second, the framework handles the responsibility of invoking those objects so that the interactions all appear to be event-driven even though some require polling (control is inverted so that the framework handles the polling for you). Third, when you need to send messages, you can rely on templates or proxies to minimize or eliminate your code’s dependency on the framework’s API.
The bottom line is that you focus on the domain of your particular application while Spring Integration handles the domain of enterprise integration patterns. From a high-level perspective, Spring Integration provides the foundation that allows your services and domain objects to participate in messaging scenarios that take advantage of all of these patterns.
In chapter 2, we dive a bit deeper into the realm of enterprise integration. We cover some of the fundamental issues such as loose coupling and asynchronous messaging. This knowledge will help establish the background necessary to take full advantage of the Spring Integration framework.