
Chapter 3. Modicum of style—coding conventions
- The dangers of dragging old coding conventions into Scala
- Working with end-of-line inference
- Avoiding dangerous names for variables
- Ensuring correct behavior with annotations
This chapter presents style suggestions that will help you avoid compiler or runtime errors. Style issues are usually a “holy war” among developers, who each has her own opinions. But there are certain things that Scala allows from a style perspective that can cause logic or runtime issues in your programs. This chapter doesn’t try to proselytize you into whether you should place spaces between parenthesis or what the best number of spaces for indentation is. This chapter merely presents a few styles that will cause real issues in Scala, and why you should modify your preferred style accordingly, if needed.
We discuss why placing opening braces for block expressions can convey different meanings to the compiler. Operator notation can cause issues if the compiler can’t tell where a line ends. Also, when naming variables in Scala, there are some names that are syntactically valid but will cause compiler or runtime errors. Finally, we discuss the benefits of compile-time warnings and how you can use annotations to increase the helpfulness of the Scala compiler. Let’s start by looking at some common coding conventions.
3.1. Avoid coding conventions from other languages
I’ve found that my style when writing in a new language tends to borrow heavily from styles I use in other languages until I’ve learned the language well. Scala is no exception. A lot of users come from Java or Ruby languages and you can see this influence in the syntax. Over time, this style will change and adjust to accommodate the new language as certain guidelines are found to cause issues in the new language. As such, it’s important to understand exactly where your style is coming from and whether that style makes sense in the new language. In fact, it’s not just the language itself that dictates style. You must consider many human social interactions, especially if you work in a company with a large developer base.
One thing that always frustrated me when using C++ was coding conventions that were developed before the ready availability of cheap mature C++ IDEs. An IDE can negate the need for a lot of coding conventions by visually altering code based on a good semantic parse. IDEs can also allow developers to click-through method calls into method definitions or declarations to quickly get a feel for what’s going on in code. A good modern IDE makes a lot of “standard practice” coding conventions unnecessary. But this doesn’t erase the need for any coding conventions. Coding conventions do serve a few purposes, which can be boiled down into three categories: code discovery, uniformity, and error prevention.
Error prevention conventions are style rules that help avoid bugs in production code. This could be anything from marking method arguments as final in Java to marking all single argument constructors as explicit in C++. The goal of these style rules will be obvious to any experienced developer of that language.
Uniformity rules are about keeping the look of code the same across a project. These are a necessary evil in development workshops and the cause of style wars. Without them, version control history can become misaligned as developers fight to push their own personal style, or lack thereof. With them, moving between source files requires little “readability” mental adjustments. These rules are things like how many spaces to put between parentheses.
Code discovery rules are about enabling engineers to easily reason through code and figure out what another developer intended. These rules usually take the form of variable naming rules, such as placing m_ in front of member variables or prefixing interfaces with a capital I. See table 3.1
Code discovery should align with the development environments that are expected in a team. If a team is using vanilla VI for editing, it will be more useful to add more code discovery guidelines than another project. If the team has a set of IDE power users, it would need less code discovery rules, as the IDE will provide many alternative means of improving discovery.
Table 3.1. Coding style examples
|
Error prevention rules |
Uniformity rules |
Code discovery rules |
|---|---|---|
|
|
|
|
|
|
The way you should develop coding conventions for a team is to:
- Start with error prevention rules. These will usually be copied from other projects in the same language, but you may need to create new rules.
- Develop discovery related rules, such as how to name packages and where to place source files. These should match the development environments used by team members.
- Follow up the rules defined above with any uniformity related rules required for the team. These rules vary from team to team and can be fun to agree upon. When creating uniformity guidelines, you should keep in mind automated tool support.
Automated Style Tooling
Many tools can automatically check style rules or refactor existing code into a given style. This can help new engineers on the project save time until they become accustomed to the style. For Scala, you should check out the Scalariform project http://mng.bz/78G9, which is a tool to automatically refactor Scala code given a set of style rules.
The issue nowadays is that most developers have a set of coding guidelines they prefer and pull them from project to project regardless of the language or the team. When starting a new project and developing new coding standards, make sure you don’t just pull conventions from previous languages. Scala syntax isn’t a direct C-clone; there are some pitfalls that certain coding styles will create in the language. We show an example with defining code blocks in Scala.
3.1.1. The block debacle
A common theme to C-style languages is code blocks, typically denoted with {}. Code blocks are sections of code that execute within loops, if statements, closures, or new variable namespaces. Coding standards tend to take two approaches with blocks: same line opening brace or next line opening brace.
if(test) {
...
}
This code shows a same line opening brace, which I prefer (go SLOBs!). In many languages, the choice between same line and next line opening brace doesn’t matter. This is not the case in Scala, where semicolon inference can cause issues in a few key places. This makes the next line opening brace style error-prone. The easiest way to show the issue is with the definition of methods. Let’s look at a common Scala method:
def triple(x: Int) =
{
x * 3
}
The more idiomatic Scala convention for a function as simple as triple is to define it on one line with no code block. This is a toy example though, so we’ll assume you have a good enough reason to use a code block, or your coding convention specifies you always having code blocks. In any case, the above function works perfectly fine. Now let’s try to make a function that returns Unit using the convenience syntax:
def foo()
{
println("foo was called")
}
This method will compile fine when used from the interpretive session, however it fails utterly when used inside a class, object, or trait definition in Scala 2.7.x and below. To reproduce the behavior in Scala 2.8, we add another line between the method name and the opening brace. In many C-style languages, including Java, this change is acceptable. In Scala, we see the issue, as shown in the following listing:
Listing 3.1. Next line opening brackets causing issues

Inside of the FooHolder class definition block, Scala sees the def foo() line of code as an abstract method. This is because it doesn’t catch the opening brace on the next line, so it assumes def foo() is a complete line. When it encounters the block expression, it assumes it found a new anonymous code block that should be executed in the construction of the class.
A simple solution to this problem exists: Add a new style guideline that requires the = syntax for all method definitions. This should solve any issues you might experience with opening brackets on the next line. Let’s try it out in the following listing:
Listing 3.2. Next line opening brackets compiling correctly

The = added after the def foo(): Unit tells the compiler that you’re expecting an expression that contains the body of the foo function. The compile will then continue looking in the file for the code block. This solves the issue for method definitions. Other types of block expressions can still cause issues. In Scala, if statements don’t require code blocks at all. This means the same kind of behavior could occur on an if statement if not properly structured. Luckily in that case, the compiler will catch and flag an error. The issue comes with else statements. Let’s try the following:
if(true)
{
println("true!")
}
else
{
println("false!")
}
In an interpretive session, you can’t enter this code because it will compile at the end of the first code block (the if statement) because it assumes the statement is complete. In a class, this should function as desired.
Should My Coding Style Allow Me to Paste Code into an Interpretive Session to Test It?
The choice depends on your development environment. Most good tools allow you to automatically start an interpretive session against a compiled instance of your project. This means you wouldn’t have to cut and paste code from your project into the session; however, in practice I find that sometimes my project isn’t compiling and I want to test out a feature. In this case, I have to edit the files before pasting into the interpretive session.
Make sure when you’re setting up a project, especially in a language you haven’t used extensively before, that you rethink your style guidelines and choose ones that fit the new language and the environment you will be developing in. Don’t merely pull what worked before in Language Foo and assume it will work well in Scala. Challenge your decisions!
A collaborative effort is in place to create a “good enough” style guide for Scala. This style guide should act as a good starting point and is currently located at http://mng.bz/48C2.
3.2. Dangling operators and parenthetical expressions
One style adjustment that can drastically help in Scala is to dangle operators at the end of lines. A dangling operator is an operator, such as + or - that’s the last nonwhitespace character in a line of code. Dangling operators will help the compiler determine the true end of a statement. Earlier, we described how this is important for block expressions. The concept works just as well with other types of expressions in Scala.
“Large string aggregation” is a great instance when dangling operators can help out the compiler or when you’re trying to create a large string such that the whole definition doesn’t fit on one line. Let’s look at an example in Java:
class Test {
private int x = 5;
public String foo() {
return "HAI"
+ x
+ "ZOMG"
+ "
";
}
}
The Test class has a foo method that’s attempting to create a large string. Rather than having dangling aggregation operators, the + operator is found on the next line. A simple translation of this to Scala will fail to compile. Let’s take a look:
object Test {
val x = 5
def foo = "HAI"
+ x
+ "ZOMG"
+ "
"
}
This will fail to compile with the error message “error: value unary_+ is not a member of java.lang.String”. Again, this is because the compiler is inferring the end of line before it should. To solve this issue, we have two options: dangling operators or parentheses. A dangling operator is an operator that ends a line, letting the compiler know there’s more to come, as shown in the following listing:
Listing 3.3. Using dangling operators
object Test {
val x = 5
def foo = "HAI" +
x +
"ZOMG" +
"
"
}
Dangling operators have the advantage of maintaining a minimal amount of syntax. This is the preferred style for the compiler itself.
An alternative to dangling operators is wrapping expressions in parentheses. You wrap any expression that spans multiple lines in parentheses. This has the advantage of allowing potentially arbitrary amount of whitespace between members of the expression. Let’s take a look at the following listing:
Listing 3.4. Using parentheses
object Test {
val x = 5
def foo = ("HAI"
+ x
+ "ZOMG"
+ "
")
}
Whichever one of these style guidelines you choose is up to you and your development shop. I prefer dangling operators, but both options are valid Scala syntax and will help you avoid parsing issues.
Now that we’ve discussed working around inference in the compiler, let’s discuss another way to avoid issues in the compiler: the naming of variables.
3.3. Use meaningful variable names
One of the most common adages in any programming language is to use meaningful argument or variable names. Code clarity is a commonly ascribed benefit of meaningful argument names. Meaningful names can help take an arcane piece of code and turn it into something a new developer can learn in moments.
Some variables exist for which it is hard to determine appropriate names. In my experience this usually comes when implementing some kind of mathematical algorithm, like fast Fourier transforms, where the domain has well-known variable names. In this case, it’s far better to use the standard symbols rather than invent your own names. In the case of Fourier transforms, the equation is shown in figure 3.1.
Figure 3.1. Fourier transform equation
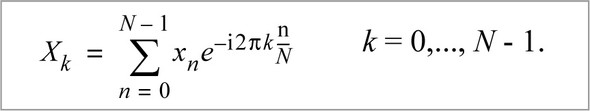
When implementing a Fourier transform, using a variable named N to represent the size of the input data, n to represent the index of a summing operation and k to represent the index to an output array is acceptable, as it’s the notation used in the function. In many of languages, you end up “spelling” symbols because the language doesn’t support mathematical symbols directly. In Scala, we can directly write ? rather than PI if we desire.
In this section well look at “reserved” characters that you shouldn’t use for variable names, as well as using named and default parameters effectively. Reserved characters are characters the compiler reserves for internal use, but it doesn’t warn you if you use them. This can cause issues at compile time or, even worse, runtime. These issues could be anything from a warning message on code that’s perfectly valid, or exceptions thrown at runtime.
Scala provides a flexible naming scheme for variables and methods. You use extended characters, if you desire to code mathematical equations directly. This allows you to write functions that look like mathematical symbols if you’re writing some form of advanced mathematics library. My recommendation here is to ensure that whatever characters you use in your variable and method names, make sure that most developers in your shop know how to input them on their keyboards or ensure there’s a direct key for it. Nothing is worse than having to copy and paste special characters into a program because you desire to use them.
An example of Scala’s flexible naming is the duality of => and ? for defining closures and pattern matching. To even use the ? character in this book, I had to look it up and paste it into my editor. The best example of unicode and non-unicode operators comes from the Scalaz library. Let’s look at one of the examples from the Scalaz source code:
val a, b, c, d = List(1)
...
a ? b ? c ? d apply {_ + _ + _ + _}
a |@| b |@| c |@| d apply {_ + _ + _ + _}
As you can see, Scalaz has provided both the |@| and the ? methods on its “Applicative Builder.” We discuss applicative style application in detail in section 11.3. For now let’s focus on the method names.
One name used for the applicative builder is a funny-looking unicode character (⊛), and the other is something someone could type without copy-paste or knowing what the correct keycode is ahead of time (|@|). By providing both, Scalaz has appealed to average developers and to those situations when using unicode characters proves you’re the better nerd at the office. I would recommend following in Scalaz’s footsteps if you wish to provide unicode operator support.
Although random unicode characters can be frustrating for developers, there’s one character that’s easy to type that can cause real issues in code: the dollar sign ($).
3.3.1. Avoid $ in names
Scala allows naming to be so flexible, you can even interfere with its own name mangling scheme for higher level concepts on the JVM. Name mangling refers to the compiler altering, or mangling, the name of a class or method to translate it onto the underlying platform. This means that if I looked at the classfile binaries Scala generates, I may not find a class with the same name as what I use in my code. This was a common technique in C++ so that it could share a similar binary interface with C but allow for method overloading. For Scala, name mangling is used for nested classes and helper methods.
As an example, let’s create a simple trait and object pairing and look at how Scala names the underlying JVM classes and interfaces. When Scala has to generate anonymous function or classes, it uses a name containing the class it was defined in—the string anonfun and a number. These strings are all joined using the $ character to create an entity. Let’s compile a sample and see what the directory looks like afterwards. This sample will be a simple main method that computes the average of a list of numbers, as shown in the following listing:
Listing 3.5. Simple method to calculate an average
object Average {
def avg(values: List[Double]) = {
val sum = values.foldLeft(0.0) { _ + _ }
sum / values.size.toDouble
}
}
The class is rather simple. We define an Average object that contains a method: avg. In the avg method, we define a closure { _ + _ } that will compile to an anonymous function class. Let’s see the compiled files for this class:
$ ls *.class Average$$anonfun$1.class Average.class Average$.class
Some interesting JVM classes are compiled here. The Average object gets compiled into the Average$ class with the Average class having the static method forwarded to the Average$ object. This is the mechanism Scala uses for “singleton objects” to ensure that they’re true objects but look similar to static method invocations to Java. The anonymous closure we sent to foldLeft ({ _ + _ }) got compiled into the Average$$anonfun$1 class. This is because it happens to be the first anonymous function defined in the Average$ class As you can see, the $ character is used heavily when creating real JVM classes for advanced Scala features.
Let’s play a game called “break Scala’s closures.” This game will help outline the issues with using $ in parameter names, something useful for those who are interested in adding plugin functionality to Scala, but not for general developers. Feel free to skip to section 3.3.2 if you’re not interested in this.
What happens if we define our own class that has the same mangled name as the anonymous function? Either our class or the anonymous function class will be used at runtime. Let’s create a new Average.scala file in the following listing and use the ` syntax to create a new mischievous class and see what happens:
Listing 3.6. Average.scala file with mischievous class

The Average object is the same as defined in listing 3.6, but we’ve created our mischievous class called Average$$anonfun$1. This compiles fine, so we know the compiler won’t catch our mischievousness. Let’s see what happens when we try to use it in an interactive interpreted session:
scala> Average.avg(List(0.0,1.0,0.5)) O MY! java.lang.IncompatibleClassChangeError: vtable stub at ...LinearSeqLike$class.foldLeft(LinearSeqLike.scala:159) at scala.collection.immutable.List.foldLeft(List.scala:46) at Average$.avg(Average.scala:3)
The mischievous class is instantiated, as seen by the “O MY!” output. The mischievous class is even passed into the foldLeft method as seen in the stack trace. It isn’t until the foldLeft function attempts to use the class instance that it realizes that this class isn’t a closure. Well, what are the odds that someone would name a class the same kind of arcane string that occurs from name mangling? Probably low, but the $ character still gives Scala some issues. When defining nested classes, Scala also uses the $ character to mangle names, similar to Java inner classes. We can cause similar errors by defining mischievous inner classes, as shown in the following listing:
Listing 3.7. Average.scala with mischievous inner classes

In general then, it’s best to avoid the $ character altogether in your naming schemes. It’s also best to avoid making an inner class with the name anonfun or $anonfun that has its own numbered inner classes, although I have no idea why you would desire to do so. For completeness, it’s best to totally avoid the mangling schemes of the compiler.
The compiler also uses name mangling for default parameters. In Scala default parameters are also encoded as a method with the name default and an ordinal representing the order the argument appears in the function. This is in the method namespace, not the classname namespace. To cause problems, we need to name a method something simple like avg$default$1.
object Average {
def avg(values: List[Double] = List(0.0,1.0,0.5)) = {
val sum = values.foldLeft(0.0) { _ + _ }
sum / values.size.toDouble
}
def 'avg$default$1' = List(0.0,0.0,0.0)
}
Luckily in this case the compiler will warn that the method avg$default$1 is a duplicate. This isn’t the most obvious error message, but then again, the method name isn’t exactly common. So, although it’s possible to use $ in method names and class names, it can get you into trouble. The examples I’ve posted are somewhat extreme, but illustrate that name mangling issues can be rather tricky to track down. Therefore you should avoid the $ character entirely.
3.3.2. Working with named and default parameters
Scala 2.8.x brings with it the ability to use named parameters. This means that the names you give parameters of methods become part of the public API. Your parameter names become part of the API, and changing them can and will break clients. Also, Scala allows users to define different parameter names in subclasses. Let’s look at the named and default parameter feature.
In Scala, parameter names are part of the API and should follow all the coding conventions used for method and variable names.
Defining named parameters in Scala is easy, it’s required syntax. Whatever name you declare for a parameter is the name you can use when calling it. Let’s define a simple Foo class with a single method foo, but with several parameters. These parameters will be set with default values. The following listing shows the various types of usage:
Listing 3.8. Simple named parameter usage


First, notice that the foo method declares defaults for all of its parameters. This allows us to call the method without passing any arguments. Things are more interesting when we pass arguments using their names, like when we write x.foo(two = "not two").
Scala still allows argument placement syntax, where the order of the parameters is the same in the definition site and the call site. This can be seen in the line x.foo(0, "zero", 0.1). On this call, 0 is the first parameter and is referred to in the function as the argument one. This is a mixed mode usage.
Mixed mode is where you can use argument placement syntax for some arguments, and named parameters for the rest. This mode is obviously limited in that you can only use placement syntax for beginning arguments but is shown in the last line: x.foo(4, three = 0.4). In this line, the first parameter, 4, is passed as argument one and the argument three is passed as 0.4.
So, why all the fuss over argument naming? Argument names become confusing with inheritance in the mix.
Scala uses the static type of a variable to bind parameter names, however the defaults are determined by the runtime type. Say it to yourself: Names are static; values are runtime. Let’s look at a “simple” example of chaos ... er ... inheritance in the following listing:
Listing 3.9. Named parameters and inheritance


Parent is a parent class that defined method foo. Child extends the foo method, but notice the naming difference. We’ve purposely reused the same names in differing orders to be confusing, but we’ve left the implementation of the method the same. If we instantiate a Parent class and execute foo, we see the value 3. When we instantiate a Child class, and execute foo we see 7 (default values are runtime!). The interesting part comes when we instantiate the Child class with the static type of Parent. When we call foo(bar = 1) on a Child instance with a static type of Child, we see the value 4. If we call foo(bar=1) on a Child instance with static type of Parent we see the value of 5.
What happened? In the Child class, we defined the argument names in the reverse order of the Parent class. The unfortunate circumstance of named parameters in Scala is that they use the static type to determine ordering. Remember our earlier mantra: values are runtime; names are static.
Renaming arguments in a child class isn’t a warning in the compiler. As of Scala 2.8.0, there’s no way to make this warning without writing your own compiler plugin. This naming issue may not be a huge deal when you’re the author of an entire type hierarchy, but it might be when working on a larger team where others are consuming classes from others and are unhappy with parameter naming schemes from other developers.
Deprecating Parameter Names
In Scala 2.8.1, there will most likely be a mechanism for deprecating parameter names. This is to be done with an annotation on the parameter itself, declaring the old name. Clients of your library can then use both names, albeit the one will issue a warning. As the specifics may change, please follow the Scala mailing list and check the release notes of 2.8.1 for the mechanics of this.
For some shops, particularly ones I’ve worked in, developers were allowed to disagree on method naming conventions because they never mattered before. As of Scala 2.8.0, they do. Ensure that your developers are aware of naming in general, and of this particular surprising change (at least surprising when coming from a language without named parameters).
Remember that naming variables, classes, and parameters are all important in Scala. Misnaming can wind up in anything from a compile-time error to a subtle and hard-to-fix bug. This is one area where the compiler can’t offer much assistance besides helpful error messages.
3.4. Always mark overridden methods
Scala did the world a great service when it introduced the override keyword. This keyword is used to demarcate when a method is intended to override vs. overload a method. If you neglect the keyword and the compiler finds you’re overriding a superclass method, it will emit an error. If you add the override keyword and no superclass has the defined method, the compiler will warn you. Thankfully, this is mostly enforced by the compiler. One scenario remains where override isn’t required but can cause issues: purely abstract methods. Scala has no abstract modifier: A purely abstract method is one that has no implementation.
In Scala, while the override keyword is optional in some situations, it’s safe to always mark methods with override.
Let’s take a look at example override usage. We want to define a business service for an application. This service will be for users. We’ll allow them to log in, change their password and log out as well as validate that someone is still logged in. We’re going to make an abstract interface for users of our service. It should look like the following:
trait UserService {
def login(credentials: Credentials): UserSession
def logout(session: UserSession): Unit
def isLoggedIn(session: UserSession): Boolean
def changePassword(session: UserSession,
credentials: Credentials): Boolean
}
The service is rather simple. We define a login method that takes the user’s credentials and returns a new session for that user. We also define a logout method that takes a UserSession object and invalidates it and performs any cleanup that may be needed. Finally, we define two methods against the session. The isLoggedIn method will check to see if a UserSession is valid, meaning the user is logged in. The changePassword method will change the user’s password but only if the new password is legal and the UserSession is valid. Now let’s make a simple implementation that assumes any credentials are okay for any user and that all users are valid.
class UserServiceImpl extends UserService {
def login(credentials: Credentials): UserSession =
new UserSession {}
def logout(session: UserSession): Unit
def isLoggedIn(session: UserSession): Boolean = true
def changePassword(session: UserSession,
credentials: Credentials): Boolean = true
}
But wait, we forgot to add the override keyword. The method still compiles, so that means the override keyword wasn’t needed. Why? Scala doesn’t require the override keyword if your class is the first to define an abstract method. It also comes into play when using multiple inheritances, but we’ll look into this in a moment. For now, let’s see what happens in the following listing if we change the method signature in the parent class:
Listing 3.10. Changing the underlying method


Notice we’ve changed the changePassword method in the UserService trait. The new method compiles fine, but the UserServiceImpl class won’t compile. Because it’s concrete, the compiler will catch the fact that changePassword defined in the User-Service isn’t implemented. What happens if instead of an implementation, we’re providing a library with partial functionality? Let’s change UserServiceImpl to a trait, as shown in the following listing:
Listing 3.11. Traits won’t cause compile errors


When we migrate UserServiceImpl to a trait, compilation now succeeds. This is an issue primarily when providing a library with no concrete implementations, or some form of DSL that’s expected to be extended. Therefore, only users of the library will notice this easy-to-prevent issue. All that’s required is to use the override modifier before any overridden method, as shown in the following listing:
Listing 3.12. Traits will cause compile errors

Because this is such an easy error for the compiler to catch, there’s no reason to run into the issue. What about the multiple inheritance we mentioned earlier? It’s time to look into how override interacts with multiple inheritance.
Scala doesn’t require the override keyword when implementing abstract methods. This was done to help multiple inheritance. Let’s look at the classic “deadly diamond” inheritance problem. A deadly diamond occurs by creating a class that has two parent classes. Both of the parent classes must also be subclasses of the same parent-parent class. If you were to draw a picture of the inheritance relationship, you would see a diamond.
Let’s start our own diamond by creating two traits, Cat and Dog, that extend a common base trait Animal. The Animal trait defines a method talk that’s also defined in Cat and Dog. Now imagine some mad scientist is attempting to combine cats and dogs to create some new species, the KittyDoggy. How well could they do this using the override keyword? Let’s define our three classes in the following listing and find out:
Listing 3.13. Animal hierarchy with override
trait Animal {
def talk: String
}
trait Cat extends Animal {
override def talk: String = "Meow"
}
trait Dog extends Animal {
override def talk: String = "Woof"
}
We define the talk method on the Animal trait to return a String. We then create the Cat and Dog traits with their own implementation of the talk method. Let’s pop open the REPL and try to construct our KittyDoggy experiment. Remember to cackle when typing, as shown in the following listing:
Listing 3.14. Multiple inheritance and override
scala> val kittydoggy = new Cat with Dog kittydoggy: java.lang.Object with Cat with Dog = $anon$1@631d75b9 scala> kittydoggy.talk res1: String = Woof scala> val kittydoggy2 = new Dog with Cat kittydoggy2: java.lang.Object with Dog with Cat = $anon$1@18e3f02a scala> kittydoggy2.talk res2: String = Meow
First we attempt to combine Cat with Dog. This results in the talk operation picking up the Dog behavior and ignoring the Cat behavior. That’s not quite what our mad-scientist experiment wants to accomplish, so instead we try to combine a Dog with a Cat.
This ends up pulling in the Cat behavior and ignoring the Dog behavior! In Scala, the last trait “wins” when it comes to class linearization and method delegation, so this isn’t unexpected.
Class linearization refers to the order in which parent calls occur for a particular class. In the preceding example, for the type Cat with Dog, the parent calls would first try the Dog trait, then Cat and then Animal. Class linearization will be covered in more detail in the section 4.2.
What happens now if we remove the override keyword from the Cat and Dog traits? Let’s find out in the following listing:
Listing 3.15. Animal hierarchy without override
trait Animal {
def talk: String
}
trait Cat extends Animal {
def talk: String = "Meow"
}
trait Dog extends Animal {
def talk: String = "Woof"
}
The definitions of Animal, Cat, and Dog are the same as before except that no override keyword is used. Let’s put on our evil lab coat again and see if we can combine our cats and dogs in the following listing:
Listing 3.16. Multiple inheritance without override
scala> val kittydoggy = new Cat with Dog
<console>:8: error: overriding method talk in
trait Cat of type => String;
method talk in trait Dog of type => String
needs `override' modifier
val kittydoggy = new Cat with Dog
^
scala> val kittydoggy2 = new Dog with Cat
<console>:8: error: overriding method talk in
trait Dog of type => String;
method talk in trait Cat of type => String
needs `override' modifier
val kittydoggy2 = new Dog with Cat
When we attempt to construct our Cat with Dog, the compiler issues an error that we’re trying to override a method without the override keyword. The compiler is preventing us from combining two different concrete methods that aren’t explicitly annotated with override. This means if I want to prevent mixing overrides of behavior, from mad scientist programmers, then I must not use the override modifier. This feature makes more sense when the traits don’t share a common ancestor, as it requires the mad scientist to manually override the conflicting behaviors of two classes and unify them. But in the presence of the base class, things can get strange. Let’s see what happens in the following listing if Cat defines its talk method with override, but Dog does not.
Listing 3.17. Multiple inheritance with mixed override
scala> val kittydoggy = new Cat with Dog
<console>:8: error: overriding method talk in
trait Cat of type =>
java.lang.String;
method talk in trait Dog of type => String needs `override' modifier
val kittydoggy = new Cat with Dog
^
scala> val kittydoggy2 = new Dog with Cat
kittydoggy2: java.lang.Object with Dog with Cat = $anon$1@5a347448
Mixing a Cat with a Dog is still bad, because Dog doesn’t mark talk method as being able to override. But extending a Dog with a Cat is acceptable because the Cat’s talk can override. We can’t use the compiler to force users to pick a talk implementation every time they inherit from Dog and another Animal. In the case where any of the Animals defines a talk method with an override, we lose our error message. This reduces the utility of the feature, specifically for the inheritance case.
Scala traits are linearized. For the purposes of overriding methods, a parent can be mixed in where we instantiate an object, rather than requiring the definition of a new class.
trait Animal { def talk: String }
trait Mammal extends Animal
trait Cat { def talk = "Meow" }
scala> val x = new Mammal with Cat
x: java.lang.Object with Mammal with Cat = $anon$1@488d12e4
scala> x.talk
res3: java.lang.String = Meow
In practice, the utility of not using the override keyword for subclass method overrides is far outweighed by the benefits of doing so. As such, you should annotate your objects with the override keyword. When it comes to multiple inheritance and overridden methods, you must understand the inheritance linearization and it consequences. We discuss traits and linearization in detail in section 4.2.
Another area where the compiler can drastically help us out is with error messages for missed optimizations.
3.5. Annotate for expected optimizations
The Scala compiler provides several optimizations of functional style code into performant runtime bytecodes. The compiler will optimize tail recursion to execute as a looping construct at runtime, rather than a recursive function call. Tail recursion is when a method calls itself as the last statement, or its tail. Tail recursion can cause the stack to grow substantially if not optimized. Tail call optimization isn’t as much about improving speed as preventing stack overflow errors.
The compiler can also optimize a pattern match that looks like a Java switch statement to act like a switch statement at runtime. The compiler can figure out if it’s more efficient and still correct to use a branch lookup table. The compiler will then emit a tableswitch bytecode for this pattern match. The tableswitch bytecode is a branching statement that can be more efficient than multiple comparison branch statements.
The switch and tail recursion optimizations come with optional annotations. The annotations will ensure the optimization is applied where expected or an error is issued.
3.5.1. Using the tableswitch optimization
The first optimization we’ll look at is treating pattern matching as a switch statement. What this optimization does is try to compile a pattern match into a branch table rather than a decision tree. This means that instead of performing many different comparisons against the value in the pattern match, the value is used to look up a label in the branch table. The JVM can then jump directly to the appropriate code. This whole process is done in a single bytecode, the tableswitch operation. In Java, the switch statement can be compiled into a tableswitch operation. In Scala, the compiler can optimize a pattern match into a single tableswitch operation if all the stars align, or at least the right conditions apply.
For Scala to apply the tableswitch optimization, the following has to hold true:
- The matched value must be a known integer.
- Every match expression must be “simple.” It can’t contain any type checks, if statements or extractors. The expression must also have its value available at compile time: The value of the expression must not be computed at runtime but instead always be the same value.
- There should be more than two case statements, otherwise the optimization is unneeded.
Let’s take a quick look at some successfully optimized code and what operations will break it. First let’s start off with a simple switch on an integer. We’re going to switch on an integer to handle three cases: the integer is one, the integer is two, and all other possible integer values.
def unannotated(x: Int) = x match {
case 1 => "One"
case 2 => "Two!"
case z => z + "?"
}
This is a match statement with three cases. As previously stated, we’re explicitly looking at the case when an integer is either one or two. The compiler is able to optimize this to a tableswitch, as you can see in the bytecode. Here’s the Java output:
public java.lang.String unannotated(int);
Code:
0: iload_1
1: tableswitch{ //1 to 2
1: 51;
2: 46;
default: 24 }
...
What you’re seeing here are the bytecode instructions for the unannotated method. The first instruction at label 0: shows us loading the first argument as an integer (iload_1). The next instruction is our tableswitch. The tableswitch instruction is made up of mappings of integer values to bytecode instruction labels (or line numbers). Now the rules for the optimization become more apparent. If the compiler is going to create this tableswitch instruction, it needs to know the values of each case statement expression in order to do the right thing. It’s fairly easy to mess this up. Let’s look at a few ways to do this.
First, we can include a type check in the pattern match. This can be surprising, as you might expect the type check would be superfluous, and not change the compiled code. Let’s take our original function and add a type check for Int on one of the case statements.
def notOptimised(x: Int) = x match {
case 1 => "One"
case 2 => "Two!"
case i: Int => "Other"
}
The difference between this example and the previous one is the type check on the third case statement: i : Int. Although the type of the variable is already known to be an Int, the compiler will still create a type check in the pattern match and this will prevent it from using a tableswitch bytecode. Let’s look at the bytecode (shortened to fit here):
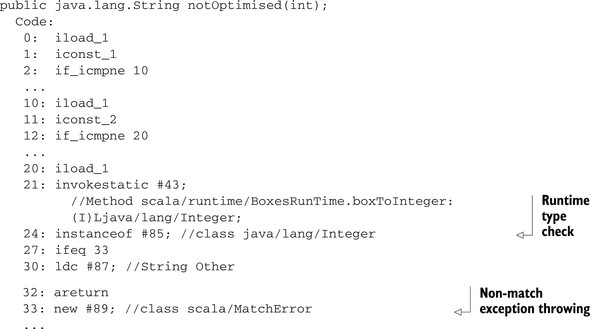
The first thing you’ll notice is that there’s an if_icmpne comparison bytecode instead of the tableswitch. Truncating the output, you’ll see that the method is compiled as a sequence of such comparison bytecodes. We also find that there’s a MatchError constructed on line 33. The truncated section is the remaining bytecode to throw the error. The compiler has inferred that our match was not complete, so it created a default case that will result in a runtime error.
On Primitives and Type Checking
In the preceding example on lines 21 and 24, you may have noticed that our argument, an Int, is boxed to perform an instanceof bytecode. The instanceof bytecode is how the JVM performs typechecks for classes, traits, and objects. But an integer is a primitive on the JVM, so to perform a type check, Scala must “box” the integer primitive into an object form of that integer. This is Scala’s standard mechanism for checking the type of any primitive on the JVM; therefore, try not to let any extraneous type checks in your code.
As you can see, it was fairly easy to construct a case where we thought the compiler would optimize our code, and yet it could not. A simple solution to this problem is to annotate your expressions so the compiler will warn you if it can’t make an optimization.
As of Scala 2.8.0, the compiler currently provides two annotations that can be used to prevent compilation if an optimization isn’t applied. These are the @tailrec and @switch annotations, which you can apply to the expression you want optimized. Let’s look at the following listing to see how the switch annotation could have helped us earlier:
Listing 3.18. Using the @switch annotation

The first thing you’ll notice is the funny (x : @switch) syntax. Scala allows annotations to be ascribed to type expressions. This tells the compiler to know that we expect the switch optimization to be performed, among other things. You could also fully ascribe the type by writing (x: Int @switch); however, adding the annotation is fine.
The compiler has given us the warning statement we desired. We’re unable to compile because our pattern match can’t be optimized. The merits of using a tableswitch are debatable, and not nearly as universal as the next annotation.
3.5.2. Using the tail recursion optimization
The @tailrec annotation is used to ensure that tail call optimization (usually abbreviated TCO) can be applied to a method. Tail call optimization is the conversion of a recursive function that calls itself as the last statement into something that won’t absorb stack space but rather execute similarly to a traditional while or for loop. The JVM doesn’t support TCO natively, so tail recursive methods will need to rely on the Scala compiler performing the optimization.
Tail recursion is easy to mix up in Scala. By annotating tail recursive methods, we can guarantee expected runtime performance.
To optimize tail calls, the Scala compiler requires the following:
- The method must be final or private: It can’t be polymorphic.
- The method must have its return type annotated.
- The method must call itself as the “end” of one of its branches.
Let’s see if we can create a good tail recursive method. My first tail recursive function was working with a tree structure, so let’s do the same: Implementing a breadth first search algorithm using tail recursion.
The breadth first search algorithm is a way to inspect a graph or tree such that you inspect the top-level elements, then the nearest neighbors of those elements, and then the nearest neighbors of the nearest neighbors, and so on, until you find the node you’re looking for. Let’s first decide what the function should look like:
case class Node(name: String, edges: List[Node] = Nil)
def search(start: Node, predicate: Node => Boolean): Option[Node] = {
error("write me")
}
The first thing we do is define a Node class that allows us to construct a graph or tree. This class is pretty simple and doesn’t allow the creation cycles, but it’s a good starting point for defining the algorithm. Next is the definition of the search method. It takes in a starting point, a Node, and a predicate that will return true when the correct node is found. The algorithm itself is fairly simple and involves maintaining a queue of nodes to inspect a mechanism to determine if a node has already been seen.
Let’s create a helper function that will use tail recursion and search for the node. This function should take the queue of nodes to inspect and a set of nodes that have already been visited. The search method can then call this helper function, passing in List(start) for the initial queue of nodes and an empty set for the list of visited nodes.
def search(start: Node, p: Node => Boolean) = {
def loop(nodeQueue: List[Node], visited: Set[Node]): Option[Node] =
nodeQueue match {
case head :: tail if p(head) =>
Some(head)
case head :: tail if !visited.contains(head) =>
loop(tail ++ head.edges, visited + head)
case head :: tail =>
loop(tail, visited)
case Nil =>
None
}
loop(List(start), Set())
}
The help method, called loop, is implemented with a pattern match. The first case pops the first element from the queue of nodes to inspect. It then checks to see if this is the node we are looking for and returns it. The next case statement also pops the first element from the work queue and checks to see if it hasn’t already been visited. If it hasn’t, the node is added to the list of visited nodes and its edges are added to the end of the work queue of nodes. The next case statement is hit when a node has already been visited. This case will continue the algorithm with the rest of the nodes in the queue. The last case statement is hit if the queue is empty. In that case, None is returned indicating no Node was found.
The interesting part of this algorithm is what the compiler does to it. Let’s look at the bytecode for the loop helper method for any sort of function call. We find none, so the tail call optimization must have kicked in for this method. Let’s check for any kind of branching in the method to see what happened. Three goto bytecodes and one return bytecode exist:
private final scala.Option loop$1(scala.collection.immutable.List,
scala.collection.immutable.Set, scala.Function1);
Code:
0: aload_1
...
61: invokespecial #97;
//Method scala/Some."<init>":(Ljava/lang/Object;)V
64: goto 221
...
150: astore_2
151: astore_1
152: goto 0
...
186: astore_1
187: goto 0
...
218: getstatic #158; //Field scala/None$.MODULE$:Lscala/None$;
221: areturn
...
Line 61 shows the byte code constructing a new Some object and then jumping to line 221. Line 221 is our return bytecode for the method. Immediately before line 221 is a getstatic operation that retrieves a reference to the None object. Finally, lines 152 and 187 both have goto instructions that return to line 0. These lines are the final bytecodes in each of our case statements. Lines 61, 64, and 221 correspond to the Some(head) call in our first case statement. Lines 218 and 221 correspond to returning None in which case our work queue is empty. Lines 150, 151, and 152 correspond to updating the current work queue and visited lists, using the astore bytecodes, and then jumping back into the algorithm. Finally, lines 186 and 187 correspond to updating the workQueue and jumping back to the start of the algorithm. The compiler has converted the tail recursion into a while loop.
This technique of converting a tail recursive function into a while loop can help prevent stack overflow issues at runtime for many recursive algorithms. It’s perhaps the most important optimization to require of the compiler when writing code. No one wants an unexpected stack overflow in production code! So, once again requiring the optimization is as simple as annotating the tail recursive method with @tailrec. Let’s take a look:
def search(start: Node, p: Node => Boolean) = {
@tailrec
def loop(nodeQueue: List[Node], visited: Set[Node]): Option[Node] =
nodeQueue match {
case head :: tail if p(head) =>
Some(head)
case head :: tail if !visited.contains(head) =>
loop(tail ++ head.edges, visited + head)
case head :: tail =>
loop(tail, visited)
case Nil =>
None
}
loop(List(start), Set())
}
Great! Now you can ensure that expected optimizations appear in programs when needed. Remember that these annotations aren’t asking the compiler to provide an optimization, but rather requiring that the compile do so or issue a warning.
In the switch example, if the compiler had been unable to provide a tableswitch instruction, the code would still have failed to compile. This doesn’t indicate that the code would have performed slowly. In fact, with only two case statements, it would possibly be slower to use a tableswitch bytecode. Therefore, make sure you use these annotations only when you require an optimization.
Unlike the switch optimization, it’s always a good idea to annotate tail recursion.
3.6. Summary
In this chapter, you’ve learned or refreshed your memory on coding conventions, their utility, and why you should look at them with fresh eyes when coming to Scala. This is a modern programming language, with an interesting twist to C style languages. As such, Scala requires adjustments to syntax and coding styles. Users of Scala should make sure to:
- Keep opening braces on the same line
- Dangle operators or use parentheses
- Use meaningful names
- Consistently name parameters
- Always mark methods with override
These rules should help you avoid simple syntax-related programming errors and be productive in your efforts.
With Scala, the syntax was designed in a “scalable” way. This means that if you attempt to write concise code and run into issues, try to use the less concise, more formal syntax until you resolve the issue. This graceful degradation is helpful in practice as it lets users “grow” into their understanding of the syntax rules. Syntax is something that shouldn’t get in the way of development but instead become a vehicle for programmers to encode their thoughts into programs. Therefore, know the syntax and how to avoid compilation or runtime problems from poor use of the language.
Now that we’ve looked at how to use Scala syntax, it’s time to dig into some of its more advanced features, starting with its object orientation.