
Chapter 7. Processing data
- Writing business logic in a chunk-oriented step
- Processing items in a chunk-oriented step
- Transforming items
- Filtering items
- Validating items
Chapters 5 and 6 focused heavily on Spring Batch input and output: how to read and write data from various types of data stores. You learned that Spring Batch enforces best practices to optimize I/O and provides many ready-to-use components. This is important for batch applications because exchanging data between systems is common. Batch applications aren’t limited to I/O; they also have business logic to carry on: enforcing business rules before sending items to a database, transforming data from a source representation to one expected by a target data store, and so on.
In Spring Batch applications, you embed this business logic in the processing phase: after you read an item but before you write it. Thanks to its chunk-oriented architecture, Spring Batch provides first-class support for this type of processing in a dedicated component—the item processor—that you insert between the item reader and the item writer. After explaining item processing and its configuration in Spring Batch, we show you how to use item processors to modify, filter, and validate items. For validation, we examine two techniques: programmatic validation in Java and validation through configuration files using a validation language and validation annotations. Finally, we cover how to chain item processors following the composite design pattern. By the end of this chapter, you’ll know exactly where and how to write the business logic for your batch application. You’ll also learn about advanced topics, such as the distinction between filtering and skipping items. Let’s start with processing items in Spring Batch.
7.1. Processing items
Spring Batch provides a convenient way to handle a large number of records: the chunk-oriented step. So far, we’ve covered the read and write phases of the chunk-oriented step; this section explains how to add a processing phase. This processing phase is the perfect place to embed your application-specific business logic. It also avoids tangling your business code in the reading and writing phases (input and output). We’ll see what kind of business logic the processing phase can handle, how to configure an item processor in a chunk-oriented step, and the item processor implementations delivered with Spring Batch.
7.1.1. Processing items in a chunk-oriented step
Recall that a chunk-oriented step includes a reading component (to read items one by one) and a writing component (to handle writing several items in one chunk). The two previous chapters covered how to read and write items from different kinds of data stores and in various formats. Spring Batch can insert an optional processing component between the reading and writing phases. This component—the item processor—embeds some business logic, such as transforming or filtering items, between reading and writing. Figure 7.1 illustrates where item processing takes place in a chunk-oriented step.
Figure 7.1. Spring Batch allows insertion of an optional processing phase between the reading and writing phases of a chunk-oriented step. The processing phase usually contains some business logic implemented as an item processor.

When a chunk-oriented step contains no processing phase, items read are sent asis to the writer, and Spring Batch takes care of aggregating items in chunks. Now, imagine that an application can’t allow writing items as-is because some kind of processing must be applied to the items first. Let’s add a new business requirement to the online store example: you want to apply discounts to products before the job imports them in the online store database. To do so, you must modify the products imported from the flat file in the item-processing phase.
7.1.2. Use cases for item processing
The processing phase is a good place for business logic. A common use case in Spring Batch is to use built-in readers and writers to deal with data stores—like flat files and databases—and to add an item processor to hold any custom business logic. Table 7.1 lists the categories of business logic that can take place in the item-processing phase.
Table 7.1. Categories of business logic in the item-processing phase
|
Category |
Description |
|---|---|
| Transformation | The item processor transforms read items before sending them to the writer. The item processor can change the state of the read item or create a new object. In the latter case, written items may not be of the same type as read items. |
| Filtering | The item processor decides whether to send each read item to the writer. |
The processing phase is an interesting link between the reading and writing phase. It allows you to go beyond the simple “read an item–write that item” pattern. The rest of this chapter examines the subtleties of item processing—with realistic use cases—to illustrate the many possibilities of this pattern. Let’s start with the basic configuration of an item processor in Spring Batch.
7.1.3. Configuring an item processor
Spring Batch defines the item-processing contract with the ItemProcessor interface as follows:
package org.springframework.batch.item;
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}
The ItemProcessor interface uses two type arguments, I and O:
- Spring Batch passes a read item of type I to the process method. The type I must be compatible with the item reader type.
- The process method returns an item of type O, which Spring Batch in turn sends to the item writer, also of a type compatible with O.
You define the concrete types I and O in your ItemProcessor implementation. If the process method returns null, Spring Batch won’t send the item to the writer, as defined by the filtering contract (filtering is different from skipping; more on this later). The following listing shows how to implement a filtering ItemProcessor.
Listing 7.1. Implementation of a filtering item processor

This ItemProcessor implementation has the following characteristics:
- No transformation— The processor receives a Product object and returns a Product object. Therefore, the I and O type arguments of the FilteringProductItemProcessor class both use the Product class.
- Filtering— Depending on the result of the needsToBeFiltered method, Spring Batch sends the item to the writer or discards it. The filtering logic is simple: if an item ID’s last character is an even digit, the filter accepts the item.
Our ItemProcessor example isn’t useful beyond showing you how to configure item processing in a chunk-oriented step. The following listing shows how to configure this item processor.
Listing 7.2. Configuring an item processor in a chunk-oriented step

Adding an item processor is straightforward with the Spring Framework and Spring Batch XML: you write a Spring bean that implements the ItemProcessor interface and then refer to it in your chunk-oriented step configuration with the processor attribute of a chunk element.
Now that you know the basics of item processing in Spring Batch, let’s see what the framework offers in terms of ready-to-use ItemProcessor implementations.
7.1.4. Item processor implementations
As you saw in the previous section, implementing an ItemProcessor is simple, and it’s usually what you end up doing to implement business logic. Nevertheless, Spring Batch provides implementations of ItemProcessors that can come in handy; table 7.2 lists these implementations.
Table 7.2. Spring Batch implementations of ItemProcessor
|
Implementation class |
Description |
|---|---|
| ItemProcessorAdapter | Invokes a custom method on a delegate POJO, which isn’t required to implement ItemProcessor |
| ValidatingItemProcessor | Delegates filtering logic to a Validator object |
| CompositeItemProcessor | Delegates processing to a chain of ItemProcessors |
You’ll have opportunities to use these ItemProcessor implementations later in the chapter. For now, let’s dive into the details of transforming items.
7.2. Transforming items
Transforming read items and then writing them out is the typical use case for an item processor. In Spring Batch, we distinguish two kinds of transformation: changing the state of the read item, and producing a new object based on the read item. In the latter case, the object the processor returns can be of a different type than the incoming item.
We illustrate both kinds of transformation with our online store application. Imagine that the application is successful and that other companies ask ACME to add their products to the online catalog; for this service, ACME takes a percentage of each partner’s product sold. For the application, this means importing products from different files: a file for its own catalog and a file for each partner catalog. With this use case in mind, let’s first explore transforming the state of read items.
7.2.1. Changing the state of read items
ACME needs to import a flat file for each partner’s product catalog. In our scenario, the model of the ACME product and of each partner product is similar, but some modifications must be made to all partners’ imported products before they’re written to the database. These modifications require some custom business logic, so you embed this logic in a dedicated application component. You then use this component from an item processor.
Introducing the Use Case
The model of the ACME product and of each partner product is similar, but each partner maintains its own product IDs. ACME needs to map partner product IDs to its own IDs to avoid collisions. Figure 7.2 shows that the item reader, processor, and writer of the chunk-oriented step all use the same type of object.
Figure 7.2. In the processing phase of a chunk-oriented step, you can choose to only change the state of read items. In this case, the item reader, processor, and writer all use the same type of object (illustrated by the small squares).

The custom mapping between partner IDs and online store IDs takes place in the PartnerIdMapper class, as shown in the following listing.
Listing 7.3. Mapping partner IDs with store IDs in a business component

To perform the product ID mapping, you search the product ID for the online store in a mapping database table, using the partner ID and product ID in the partner namespace as the criteria. In an alternative implementation, the PartnerIdMapper class could generate the ID on the fly and store it if it didn’t find it in the mapping table.
Note
The PartnerIdMapper class is a POJO (plain old Java object): it doesn’t depend on the Spring Batch API, but it does use the JdbcTemplate class from the Spring JDBC Core package. This is important because this class implements the business logic, and you don’t want to couple it tightly to the Spring Batch infrastructure.
Let’s now plug the business component into Spring Batch.
Implementing a Custom Item Processor
You implement a dedicated ItemProcessor with a plug-in slot for a PartnerIdMapper, as shown in the following snippet:

Now you need to wire these components together in the configuration of a chunk-oriented step, as shown in the following listing.
Listing 7.4. Configuring the dedicated item processor to map product IDs

That’s it! You configured processing that converts the IDs of the incoming products into the IDs that the online store uses. You isolated the business logic from Spring Batch—separation of concerns—but you had to implement a custom ItemProcessor to call your business logic. You can achieve the same goal without this extra custom class.
Plugging in an Existing Component with the ItemProcessorAdapter
Sometimes an existing business component is similar to a Spring Batch interface like ItemProcessor, but because it doesn’t implement the interface, the framework can’t call it directly. That’s why the PartnerIdItemProcessor class was implemented in the previous section: to be able to call business code from Spring Batch. It worked nicely, but isn’t it a shame to implement a dedicated class to delegate a call? Fortunately, Spring Batch provides the ItemProcessorAdapter class that you can configure to call any method on a POJO. Using the ItemProcessorAdapter class eliminates the need to implement a class like PartnerIdItemProcessor. All you end up doing is a bit of Spring configuration. The following listing shows how to use the ItemProcessorAdapter to call the PartnerIdMapper without a custom ItemProcessor.
Listing 7.5. Using the ItemProcessorAdapter to plug in an existing Spring bean

Using an ItemProcessorAdapter should eliminate the need to implement a dedicated ItemProcessor. This reminds us that it’s a best practice to have your business logic implemented in POJOs. The ItemProcessorAdapter class helps in reducing the proliferation of classes if you often need to use a processing phase.
The ItemProcessorAdapter class has a couple of drawbacks, though: it’s not as type-safe as a dedicated ItemProcessor class, and you can make typos on the target method name when configuring it in XML. The good news is that the ItemProcessorAdapter checks its configuration when it’s created; you get an exception when the Spring application context starts and also at runtime.
We’re done looking at a processing phase that changes the state of read items. We use such processing when read items are of the same type as written items but need some sort modification, such as the ID conversion for imported products. The next section covers a processing phase that produces a different type of object from the read item.
7.2.2. Producing new objects from read items
As ACME finds more partners, it must deal with different product lines as well as with mismatches between the partners’ product models and its own product model. These model differences make the importing job more complex. You still base the import on an input flat file, but ACME needs a processing phase to transform the partners’ products into products that fit in the online store database.
Introducing the Use Case
The processing phase of your chunk-oriented step transforms PartnerProduct objects read by the ItemReader into Product objects that the ItemWriter writes into the online store database. This is a case where the reader, the processor, and the writer don’t manipulate the same kind of objects at every step, as shown in figure 7.3.
Figure 7.3. The item processor of a chunk-oriented step can produce objects of a different type (represented by circles) than the read items (squares). The item writer then receives and handles these new objects.

The logic to transform a PartnerProduct object into an ACME Product object takes place in a dedicated business component—the PartnerProductMapper class—that implements the PartnerProductMapper interface:
package com.manning.sbia.ch07;
import com.manning.sbia.ch01.domain.Product;
public interface PartnerProductMapper {
Product map(PartnerProduct partnerProduct);
}
We don’t show an implementation of the PartnerProductMapper interface because it’s all business logic not directly related to Spring Batch and therefore not relevant to our presentation of Spring Batch. You can find a simple implementation in the source code for this book. What we need to do now is to plug this business logic into a Spring Batch job.
Here’s an example of what a PartnerProductMapper implementation could do in a real-world online store application. Up to now—for simplicity’s sake—we’ve used a static structure for the products of our online store application. Most of the time, online store applications don’t have a static structure for the products in their catalog: they use a metamodel configured with the structure of the products and a generic engine that uses this metamodel to display products dynamically. For example, a metamodel for products in a book category could have fields for author, title, publication date, and so on. We could imagine that the ACME online application uses such a metamodel but that the partners don’t. The goal of the PartnerProductMapper would be to map statically structured partner products (from input flat files) to the online store’s products model. Such a mapper would rely heavily on the metamodel to do its job.
Let’s plug our PartnerProductMapper into an item processor.
Implementing a Custom Item Processor
Listing 7.6 shows a custom ItemProcessor called PartnerProductItemProcessor that calls the PartnerProductMapper class. This item processor is Spring Batch–specific because it implements ItemProcessor and delegates processing to its PartnerProductMapper, itself a business POJO.
Listing 7.6. A dedicated item processor to call the partner product mapper

Note that the actual argument types of the generic ItemProcessor interface now take two different types: PartnerProduct (for the input type) and Product (for the output type). Now that we have our ItemProcessor, let’s see its configuration in the following listing.
Listing 7.7. Configuring an item processor to map partner products to store products

Thanks to the product mapping that takes place during the processing phase of this step, you can transform the partner product representation to the product representation expected by the online store application. If you need to perform a different conversion for another partner, you only need to implement another item processor and reuse the item reader and writer.
Note
As you did in the previous section, you can use the ItemProcessorAdapter class to plug in the business component (PartnerProductMapper) in the processing phase, eliminating the need for the PartnerProductItemProcessor class.
Before ending this section on using the item-processing phase to modify or transform read items, let’s see how to use an ItemProcessor to implement a common pattern in batch applications: the driving query pattern.
7.2.3. Implementing the driving query pattern with an item processor
The driving query pattern is an optimization pattern used with databases. The pattern consists of two parts:
- Execute one query to load the IDs of the items you want to work with. This first query—the driving query—returns N IDs.
- Execute queries to retrieve a database row for each item. In total, N additional queries load the corresponding objects.
This seems counterintuitive, but using this pattern can end up being faster than loading the whole content of each object in one single query. How is that possible?
Some database engines tend to use pessimistic locking strategies on large, cursor-based result sets. This can lead to poor performance or even deadlocks if applications other than the batch application access the same tables. The trick is to use a driving query to select the IDs and then load complete objects one by one. A single query can prevent the database from handling large datasets.
The driving query pattern works nicely with object-relational mapping (ORM) tools. A simple JDBC item reader reads IDs, and a custom item processor uses an ORM tool to load the objects. ORM tools like Hibernate use a built-in second-level cache to improve performance.
Spring Batch can easily match and implement the driving query pattern in a chunk-oriented step:
- An ItemReader executes the driving query.
- An ItemProcessor receives the IDs and loads the objects.
- The loaded objects go to the ItemWriter.
Figure 7.4 illustrates the driving query pattern in Spring Batch.
Figure 7.4. The driving query pattern implemented in Spring Batch. The item reader executes the driving query. The item processor receives the IDs and loads the objects. The item writer then receives these objects to, for example, write a file or update the database or an index.
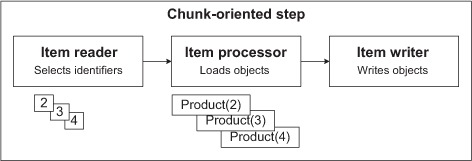
Let’s use the driving query pattern in our online application. Imagine the application features a search engine whose index needs to be updated from time to time (a complete re-indexing is rare because it takes too long). The indexing batch job consists of selecting recently updated products and updating the index accordingly. Because the online store is running during the indexing, you want to avoid locking overhead, so you shouldn’t load large datasets; therefore, the driving query pattern is a good match. Let’s see how to implement this with Spring Batch!
Executing the Driving Query with a JDBC Item Reader
You use a Spring Batch cursor-based JDBC item reader to retrieve the product IDs. The product table contains an update_timestamp column updated each time a product row changes. Who performs the update? The application, a database trigger, or a persistence layer like Hibernate can perform the update. We use the update_timestamp column to select the products that the database must index. Listing 7.8 shows how to configure a JdbcCursorItemReader to execute the driving query for our use case.
Listing 7.8. Configuring an item reader to execute the driving query

If you’re unfamiliar with the JdbcCursorItemReader class, please see chapter 5. You use the JdbcCursorItemReader sql property to set the SQL query to execute. This query selects the IDs of the products that were updated after a given date
(by using the where > ? clause). To pass a parameter to the query, you set the preparedStatementSetter property ![]() with an ArgPreparedStatementSetter (this is a class from the Spring Framework). You use the Spring Expression Language to get the date query parameter from
the job parameters. To retrieve the IDs from the JDBC result set, you use the Spring class SingleColumnRowMapper
with an ArgPreparedStatementSetter (this is a class from the Spring Framework). You use the Spring Expression Language to get the date query parameter from
the job parameters. To retrieve the IDs from the JDBC result set, you use the Spring class SingleColumnRowMapper ![]() .
.
That’s it! You configured your item reader to execute the driving query. Note that you didn’t write any Java code: you configured only existing components provided by Spring Batch and the Spring Framework. Next, let’s see how to load the products from their IDs within an item processor.
Loading Items in an Item Processor
You need to load a product based on its ID. This is a simple operation, and a data access object (DAO) used in the online store application already implements this feature. The following listing shows the implementation of this DAO.
Listing 7.9. Implementing a DAO to load a product from its ID
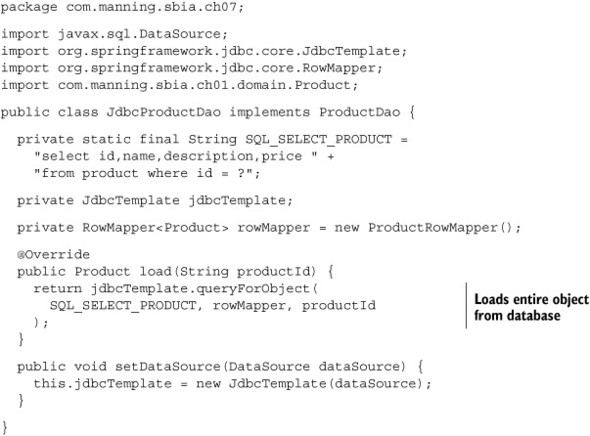
You use a ProductRowMapper to map a JDBC result set to Product objects. Remember that the RowMapper is a Spring interface. You can use RowMapper implementations in a JDBC-based data access layer for your online applications. You can also use a RowMapper with a Spring Batch JDBC-based item reader.
What you need to do now is connect your data access logic with Spring Batch. This is what the item processor in the following listing does.
Listing 7.10. Implementing an item processor to call the DAO
package com.manning.sbia.ch07;
import org.springframework.batch.item.ItemProcessor;
import com.manning.sbia.ch01.domain.Product;
public class IdToProductItemProcessor implements
ItemProcessor<String, Product> {
private ProductDao productDao;
@Override
public Product process(String productId) throws Exception {
return productDao.load(productId);
}
public void setProductDao(ProductDao productDao) {
this.productDao = productDao;
}
}
The class IdToProductItemProcessor delegates product loading to the product DAO. To avoid writing a dedicated class, you could have used an ItemProcessorAdapter, but with the IdToProductItemProcessor class, the input and output types are easier to picture: String for the IDs returned by the driving query (input), and Product instances loaded by the item processor (output).
Configuring a Chunk-Oriented Step for the Driving Query Pattern
The configuration of a chunk-oriented step using the driving query pattern is like any other chunk-oriented step, except that it needs to have an item processor set. The following listing shows this configuration (we elided the reader and writer details).
Listing 7.11. Configuring a driving query

The implementation of the driving query pattern with Spring Batch ends this section. We covered how to use the processing phase of a chunk-oriented step as a way to modify read items and create new items. The next section covers how to use the processing phase as a way to filter read items before sending them to an item writer.
7.3. Filtering and validating items
The processing phase of a chunk-oriented step not only can modify read items but also can filter them. Imagine reading a flat file containing some products that belong in the database and some that don’t. For example, some products don’t belong to any of the categories of items sold in the store, some products are already in the database, and so on. You can use an item processor to decide whether to send a read item to the item writer, as shown in figure 7.5.
Figure 7.5. An item processor filters read items. It implements logic to decide whether to send a read item to the item writer.
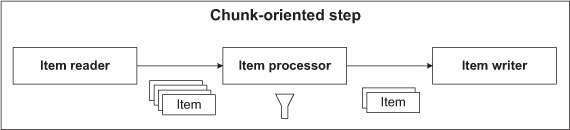
We cover how to implement a typical filtering item processor and how to filter using validation. We implement programmatic validation, but we also use declarative validation using integration between Spring Batch and the Spring Modules project. First, let’s learn more about the filtering contract in the item-processing phase.
7.3.1. Filtering in the item-processing phase
The basic contract for filtering in an item processor is simple: if the item processor’s process method returns null, the read item won’t go to the item writer. This defines the main contract, but there are subtleties; let’s look at the filtering rules for item processors:
- If the process method returns null, Spring Batch filters out the item and it won’t go to the item writer.
- Filtering is different from skipping.
- An exception thrown by an item processor results in a skip (if you configured the skip strategy accordingly).
The basic contract for filtering is clear, but we must point out the distinction between filtering and skipping:
- Filtering means that Spring Batch shouldn’t write a given record. For example, the item writer can’t handle a record.
- Skipping means that a given record is invalid. For example, the format of a phone number is invalid.
Note
The job repository stores the number of filtered items for each chunk-oriented step execution. You can easily look up this information using a tool like Spring Batch Admin or by consulting the corresponding database table.
The last detail of the filtering contract we need to examine is that an item processor can filter items by returning null for some items, but it can also modify read items, like any other item processor. You shouldn’t mix filtering and transformation in a same-item processor (separation of concerns), but it’s your right to do so!
If your application needs to both filter items and transform items, then follow the separation of concerns pattern by using two item processors: one to filter and one to transform.
Now that you know all about the filtering contract, let’s see how to implement a filtering item processor.
7.3.2. Implementing a filtering item processor
Let’s look back at the import products job from chapter 1 and see in which circumstances it could use filtering. Remember that this job consists of reading a flat file containing product records and creating or updating the database accordingly. You get into trouble if you execute the import job while the online store application hits the database: updating products from the job locks database rows and makes the online store less responsive. Nevertheless, you want the database to be as up to date as possible. A good compromise is to read the flat file and create new product records, but discard updating existing products. You can update existing products later, in a separate job, when there’s less traffic in the online store.
You meet this requirement by inserting a filtering item processor between the reading of the flat file and the writing to the database. This item processor checks the existence of the record in the database and discards it if it already exists. Figure 7.6 illustrates how the import products job works with a filtering phase.
Figure 7.6. The filtering item processor discards products that are already in the database. This item writer only inserts new records and doesn’t interfere with the online application. A different job updates existing records when there’s less traffic in the online store.

The following listing shows the implementation of the filtering item processor.
Listing 7.12. Filtering existing products with an item processor

Note
A more advanced version of the filtering item processor could let record updates pass through in a given time window, such as between 2 a.m. and 4 a.m. when there isn’t much activity in the online store. This would make the filtering more dynamic and could eliminate the need to have two distinct jobs (one for inserts only and one for inserts and updates).
The following listing shows the configuration of the import products job with the filtering item processor.
Listing 7.13. Configuring the filtering item processor

The item processor implemented here is a typical case of using the item processor phase as a filter. The item processor receives valid items from the item reader and decides which items to pass to the item writer. The item processor effectively filters out the other items.
Let’s now see another case where you can use item processing to prevent read items from reaching the item writer: validation.
7.3.3. Validating items
Because validation is business logic, the standard location to enforce validation rules is in the item-processing phase of a chunk-oriented step. A common practice in Spring Batch is for an item processor to perform validation checks on read items and decide whether to send the items to the item writer. As an example, let’s see how to validate the price of imported products and check that prices aren’t negative numbers (products with a negative price shouldn’t reach the database—you don’t want to credit your customers!). Should you consider an item that fails the validation check filtered or skipped? Skipping is semantically closer to a validation failure, but this remains questionable, and the business requirements usually lead to the correct answer.
A validation failure should lead to a skipped or filtered item, but what you care about is that the item writer doesn’t receive the item in question. Remember that the corresponding stepexecution metadata stored in the job repository is distinct (skip and filter count), and this distinction can be relevant for some use cases. If you want to enforce validation rules in your item processor, use the following semantics for validation failure in the item processor’s process method:
- If validation means skip, throw a runtime exception
- If validation means filter, return null
What kind of validation can an item processor perform? You can do almost anything: state validation of the read object, consistency check with other data, and so forth. In the import products job, for example, you can check that the price of products from the flat file is positive. A well-formatted negative price would pass the reading phase (no parsing exception), but you shouldn’t write the product to the database. The job of the item processor is to enforce this check and discard invalid products.
You can implement an item processor corresponding to this example and follow the semantics outlined here, but Spring Batch already provides a class called ValidatingItemProcessor to handle this task.
Validation with a ValidatingItemProcessor
The Spring Batch class ValidatingItemProcessor has two interesting characteristics:
- It delegates validation to an implementation of the Spring Batch Validator interface.
- It has a filter flag that can be set to false to throw an exception (skip) or true to return null (filter) if the validation fails. The default value is false (skip).
By using the ValidatingItemProcessor class, you can embed your validation rules in dedicated Validator implementations (which you can reuse) and choose your validation semantics by setting the filter property.
The Spring Batch Validator interface is
package org.springframework.batch.item.validator;
public interface Validator<T> {
void validate(T value) throws ValidationException;
}
When you decide to use the ValidatingItemProcessor class, you can either code your validation logic in Validator implementations or create a Validator bridge to a full-blown validation framework. We illustrate both next.
Validation with a Custom Validator
Let’s say you want to check that a product doesn’t have a negative price. The following snippet shows how to implement this feature as a Validator:
package com.manning.sbia.ch07.validation;
import java.math.BigDecimal;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.batch.item.validator.Validator;
import com.manning.sbia.ch01.domain.Product;
public class ProductValidator implements Validator<Product> {
@Override
public void validate(Product product) throws ValidationException {
if(BigDecimal.ZERO.compareTo(product.getPrice()) >= 0) {
throw new ValidationException("Product price cannot be negative!");
}
}
}
This validator isn’t rocket science, but as you configure it with Spring, it benefits from the ability to use dependency injection to, for example, access the database through a Spring JDBC template. The configuration for this validating item processor example has some interesting aspects, so let’s examine the following listing.
Listing 7.14. Configuring a validating item processor

Most of this configuration isn’t elaborate: an XML chunk element for a chunk-oriented step, positioning of the item processor between the reader and the writer, and injection of the product validator in the ValidatingItemProcessor.
Because you set the filter property of the validating item processor to false—this is the default value, but we wanted to make this example explicit—the item processor rethrows any ValidationException thrown by its validator.
This implies the configuration of a skip strategy if you don’t want to fail the whole job execution in case of a validation failure. The skip configuration consists of setting a skip limit and skipping ValidationExceptions.
If you were only to filter products that have a negative price, you would set the filter property of the ValidatingItemProcessor to true and wouldn’t need any skip configuration.
Writing dedicated validator classes can be overkill and result in overall code bloat. An alternative is to make the validation declarative: instead of coding the validation in Java, you implement it with a dedicated validation language in the configuration file.
Validation with the Valang Validator from Spring Modules
The Spring Modules project provides a simple yet powerful validation language: Valang (for va-lidation lang-uage). You can easily integrate Valang with Spring Batch to write your validation rules without Java code. For example, to verify that the product price isn’t negative, you write the following rule in Valang (assuming the evaluation context is a Product object):
{ price : ? >= 0 : 'Product price cannot be negative!' }
Valang has a rich syntax to create validation expressions. We don’t cover this syntax here; our point is to show how to integrate Valang rules within a validating item processor.[1]
1 You can learn more about the Valang syntax at https://springmodules.dev.java.net/docs/reference/0.9/html/validation.html.
Because Valang isn’t Java code, we use the Spring configuration to implement validating the product price, as shown in the following listing.
Listing 7.15. Embedding validation logic in the configuration with Valang


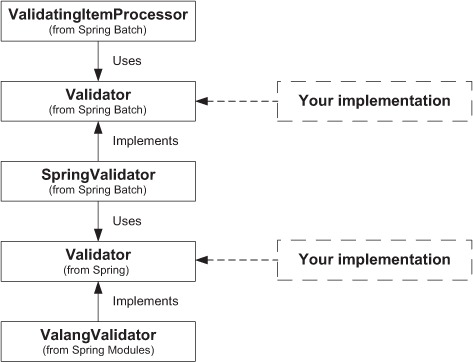
The key to this configuration is the link between the Spring Batch ValidatingItemProcessor class and the Spring Modules ValangValidator class. The Spring Batch ValidatingItemProcessor class needs a Spring Batch Validator, so you provide it a Spring Batch SpringValidator class, which itself needs a Spring Validator—the interface the ValangValidator class implements! In short, the Spring Batch SpringValidator class is the bridge between the Spring Batch and Spring validation systems, and the ValangValidator builds on the Spring system (figure 7.7 illustrates the relationships between these interfaces and classes, and you can also read the note about validator interfaces if you want the whole story). The valang property of ValangValidator accepts one or more validation rules (we used only one in the example). We explicitly set the validating item processor to skip mode (the filter property is false), so we need to set up a skip strategy to avoid failing the job if the validation fails.
Figure 7.7. The relationships between Spring Batch, Spring, and your validation logic. Spring Batch provides a level of abstraction with its Validator interface and an implementation (SpringValidator) that uses the Spring Validator interface. The ValangValidator implementation, from Spring Modules, depends on the Spring Validator interface. Both Validator interfaces are potential extension points for your own implementations.
Valang works great and allows you to embed validation rules directly in your Spring configuration files. But what if you want to reuse your validation rules in different contexts, such as in your batch jobs and in a web application? You can do this with Valang, but the Bean Validation standard also offers a widespread and effective solution.
Spring Batch doesn’t intend for application-specific validators to be the only implementers of the Spring Batch Validator interface. It can also provide a level of indirection between Spring Batch and your favorite validation framework. Spring Batch provides one implementation of Validator: SpringValidator, which plugs in the Spring Framework’s validation mechanism. Spring bases its validation mechanism on a Validator interface, but this one lies in the org.springframework.validation package and is part of the Spring Framework. This can look confusing, but the Spring Batch team didn’t want to directly tie Spring Batch’s validation system to Spring’s. By using the Spring Batch SpringValidator class, you can use any Spring Validator implementation, like the one from Spring Modules for Valang.
Validation with the Bean Validation Standard
It’s common to use the same validation constraints in multiple places: when an administrator updates the product catalog manually, they shouldn’t be able to enter a negative price. In this case, the web framework enforces this constraint. Web frameworks like Spring MVC (Model-View-Controller) or JavaServer Faces (JSF) have dedicated support for validation. If you really want to avoid products with a negative price, you can also validate the objects when they’re about to be persisted in the database. JPA—Java Persistence API, the Java standard for object-relational mapping—has some support to execute code before storing an object in the database. Finally, you also want to avoid negative prices when you import products with a Spring Batch job.
What you want is multiple processes—web, batch—with the same validation constraints. Is it possible to define constraints in one place and enforce them with an API from such different processes? Yes, thanks to the Bean Validation (JSR 303) standard!
The idea behind Bean Validation is simple but powerful: embed validation constraints with annotations on the classes you want to validate and enforce them anywhere you need to. The good news is that many frameworks support Bean Validation out of the box: they validate incoming objects transparently for you. That’s the case with all the frameworks we just mentioned (Spring MVC, JSF, and JPA). Wouldn’t it be nice to reuse all your Bean Validation constraints in your Spring Batch jobs? Let’s see how to do this.
Bean Validation promotes a declarative and reusable way to validate Java objects. The idea is to use Java classes as the definitive repository for validation constraints. As soon as you have access to a Java object, you can validate it, because it contains its own validation rules. You express Bean Validation constraints with Java annotations, but you can also do so in XML. Bean Validation is becoming increasingly popular, and many frameworks integrate support for it. The reference implementation for Bean Validation is the Hibernate Validator project, which is at the origin of the standard.
Let’s start with the Product class, which now contains the constraint for negative prices. The following listing shows the Product class with the Bean Validation annotations on the getter method for price.
Listing 7.16. Embedding validation constraint in the Product class

The validation constraints specify that the price can’t be null or negative. These constraints are simple, but Bean Validation includes constraints that are more advanced and lets you also define your own.
To use Bean Validation in your Spring Batch jobs, you only have to define a custom Validator that enforces the validation constraints on incoming items, as shown in the following listing.
Listing 7.17. A Spring Batch validator for Bean Validation

The validator is straightforward to implement thanks to the Bean Validation API. You can inject an instance of the validator in the validator item processor that Spring Batch provides, as shown in the following snippet:
<bean id="validator" class="com.manning.sbia.ch07.validation.BeanValidationValidator" /> <bean id="processor" class="org.springframework.batch.item.validator.ValidatingItemProcessor"> <property name="validator" ref="validator" /> </bean>
Using Bean Validation is particularly relevant if you use exactly the same classes in your batch jobs and in other applications. Many frameworks support Bean Validation, from the web layer to the persistence layer, and using it offers the best opportunity to reuse your validation constraints.
The integration between Spring Batch and the Bean Validation standard ends our coverage of the use of the item-processing phase for validation. Remember that you must follow strict rules if you don’t want to confuse skip with filter when validating items. Spring Batch includes the ValidatingItemProcessor class that you can configure to skip or filter when validation fails. Finally, you can implement your validation rules programmatically—in Java—or choose a declarative approach with a validation language like Valang or with Bean Validation. Let’s see now how to apply the composite pattern to chain item processors.
7.4. Chaining item processors
As we stated at the beginning of this chapter, the item-processing phase of a chunk-oriented step is a good place to embed business logic. Assuming that each item processor in your application implements one single business rule (this is simplistic but enough to illustrate our point), how could you enforce several business rules in the item-processing phase of a single step? Moreover, recall that you can insert only a single item processor between an item reader and an item writer. The solution is to apply the composite pattern by using a composite item processor that maintains a list of item processors (the delegates). The composite item processor delegates the calls to all the members in its list, one after the next. Figure 7.8 illustrates the model of a composite item processor.
Figure 7.8. Using a composite item processor allows item processors to be chained in order to apply a succession of business rules, transformations, or validations.
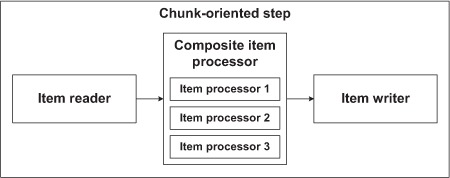
When using a composite item processor, the delegates should form a type-compatible chain: the type of object an item processor returns must be compatible with the type of object the next item processor expects.
Spring Batch provides the CompositeItemProcessor class, and we illustrate its use with the import of partner products into the online store. In section 7.2, we covered the transformation of read items, where we distinguished two types of transformations:
- Changing the state of the read item— We mapped the product ID in the partner’s namespace to the product ID in the ACME system.
- Producing another object from the read item— We produced instances of the Product class from PartnerProduct objects (created by the item reader).
What do you do if your import job needs to do both? You use two item processors: the first item processor reads raw PartnerProduct objects from the flat file and transforms them into Product objects, and then the second item processor maps partner product IDs to ACME IDs. Figure 7.9 illustrates the sequence of the import step.
Figure 7.9. Applying the composite item processor pattern to the import products job. The first delegate item processor converts partner product objects into online store product objects. The second delegate item processor maps partner IDs with ACME IDs. You reuse and combine item processors without any modification.

You already implemented all the Java code in section 7.2, so you only need to configure a Spring Batch CompositeItemProcessor with your two delegate item processors, as shown in the following listing.
Listing 7.18. Chaining item processors with the composite item processor


This example shows the power of the composite pattern applied to building a processing chain: you didn’t modify your two existing item processors, you reused them as is. Spring Batch encourages separation of concerns by isolating business logic in reusable item processors.
7.5. Summary
Spring Batch isn’t only about reading and writing data: in a chunk-oriented step, you can insert an item processor between the item reader and the item writer to perform any kind of operation. The typical job of an item processor is to implement business logic. For example, an item processor can convert read items into other kinds of objects Spring Batch sends to the item writer. Because batch applications often exchange data between two systems, going from one representation to another falls into the domain of item processors.
Spring Batch defines another contract in the processing phase: filtering. For example, if items already exist in the target data store, the application shouldn’t insert them again. You can filter items such that they’ll never get to the writing phase. We made a clear distinction between filtering items and skipping items. Skipping denotes that an item is invalid. This distinction became even more relevant when we covered validation. Thanks to the Spring Batch ValidatingItemProcessor class, you can easily switch from skipping to filtering semantics. We used the ValidatingItemProcessor class to validate that the price of imported products isn’t negative before the job writes the products to the database. We saw that we can isolate validation rules in dedicated validator components, and we used this feature to plug in two declarative validation frameworks, Valang and Bean Validation.
This chapter about data processing ends our coverage of the three phases of a chunk-oriented step: reading, processing, and writing. You now have all the information necessary to write efficient batch applications with Spring Batch. Chapter 8 introduces you to techniques used to make batch applications more robust, and you’ll see that chunk-oriented processing plays an important role.