
Chapter 2. Spring Batch concepts
This chapter covers
- Defining the domain language
- Surveying infrastructure components
- Modeling jobs
- Understanding job execution
Chapter 1 introduced Spring Batch with some hands-on examples. You saw how to implement a batch process from soup to nuts: from business requirements to the batch implementation and finally to running the process. This introduction got you started with Spring Batch and gave you a good overview of the framework’s features. It’s time to strengthen this newly acquired knowledge by diving into batch applications concepts and their associated vocabulary, or domain language.
Batch applications are complex entities that refer to many components, so in this chapter we use the Spring Batch domain language to analyze, model, and define the components of batch applications. This vocabulary is a great communication tool for us in this book but also for you, your team, and your own batch applications. We first explore Spring Batch’s services and built-in infrastructure components for batch applications: the job launcher and job repository. Then, we dive into the heart of the batch process: the job. Finally, we study how to model a Spring Batch job and how the framework handles job execution.
By the end of this chapter, you’ll know how Spring Batch models batch applications and what services the framework provides to implement and execute jobs. All these concepts lay the foundation for efficient configuration and runtime behavior as well as for features like job restart. These concepts form the starting point for you to unleash the power of Spring Batch.
2.1. The batch domain language
In chapter 1, we used many technical terms without proper definitions. We wrote this book with a gentle introduction and without overwhelming you with a large first helping of concepts and definitions. We introduced Spring Batch from a practical point of view. Now it’s time to step back and take a more formal approach. Don’t worry: we’ll make this short and sweet.
In this section, we define the batch domain language: we pick apart the batch application ecosystem and define each of its elements. Naming can be hard, but we use some analysis already provided by the Spring Batch project itself. Let’s start by looking at the benefits of using a domain language for our batch applications.
2.1.1. Why use a domain language?
Using well-defined terminology in your batch applications helps you model, enforce best practices, and communicate with others. If there’s a word for something, it means the corresponding concept matters and is part of the world of batch applications. By analyzing your business requirements and all the elements of the batch ecosystem, you find matches, which help you design your batch applications.
In our introduction to chunk processing in chapter 1, we identified the main components of a typical batch process: the reader, the processor, and the writer. By using the chunk-processing pattern in your applications, you also structure your code with readers, processors, and writers. The good news about chunk processing is that it’s a pattern well suited for batch applications, and it’s a best practice in terms of memory consumption and performance.
Another benefit of using the domain language is that by following the model it promotes, you’re more likely to enforce best practices. That doesn’t mean you’ll end up with perfect batch applications, but at least you should avoid the most common pitfalls and benefit from years of experience in batch processing.
At the very least, you’ll have a common vocabulary to use with other people working on batch applications. This greatly improves communication and avoids confusion. You’ll be able to switch projects or companies without having to learn a brand new vocabulary for the same concepts.
Now that you’re aware of the benefits of using a domain language to work with batch applications, let’s define some Spring Batch concepts.
2.1.2. Main components of the domain language
In this subsection, we focus on the core components of Spring Batch applications, and the next subsection covers external components that communicate with Spring Batch applications. Figure 2.1 shows the main Spring Batch components. The figure shows two kinds of Spring Batch components: infrastructure components and application components. The infrastructure components are the job repository and the job launcher. Spring Batch provides implementations for both—and you do need to configure these components—but there’s little chance you’ll have to create your own implementations.
Figure 2.1. The main Spring Batch components. The framework provides a job repository to store job metadata and a job launcher to launch jobs, and the application developer configures and implements jobs. The infrastructure components—provided by Spring Batch—are in gray, and application components—implemented by the developer—are in white.
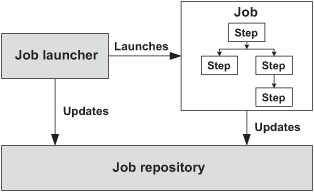
The application components in Spring Batch are the job and its constituent parts. From the previous chapter you know that Spring Batch provides components like item readers and item writers you only need to configure and that it’s common to implement your own logic. Writing batch jobs with Spring Batch is a combination of Spring configuration and Java programming.
Figure 2.1 painted the big picture; table 2.1 gives a more comprehensive list of the components of a Spring Batch application and their interactions.
Table 2.1. The main components of a Spring Batch application
|
Component |
Description |
|---|---|
| Job repository | An infrastructure component that persists job execution metadata |
| Job launcher | An infrastructure component that starts job executions |
| Job | An application component that represents a batch process |
| Step | A phase in a job; a job is a sequence of steps |
| Tasklet | A transactional, potentially repeatable process occurring in a step |
| Item | A record read from or written to a data source |
| Chunk | A list of items of a given size |
| Item reader | A component responsible for reading items from a data source |
| Item processor | A component responsible for processing (transforming, validating, or filtering) a read item before it’s written |
| Item writer | A component responsible for writing a chunk to a data source |
Going forward from this point, we use the terms listed in table 2.1. The remainder of this chapter describes the concepts behind these terms, but first we see how the components of a Spring Batch application interact with the outside world.
2.1.3. How Spring Batch interacts with the outside world
A batch application isn’t an island: it needs to interact with the outside world just like any enterprise application. Figure 2.2 shows how a Spring Batch application interacts with the outside world.
Figure 2.2. A Spring Batch application interacts with systems like schedulers and data sources (databases, files, or JMS queues).

A job starts in response to an event. You’ll always use the JobLauncher interface and JobParameters class, but the event can come from anywhere: a system scheduler like cron that runs periodically, a script that launches a Spring Batch process, an HTTP request to a web controller that launches the job, and so on. Chapter 4 covers different scenarios to trigger the launch of your Spring Batch jobs.
Batch jobs are about processing data, and that’s why figure 2.2 shows Spring Batch communicating with data sources. These data sources can be of any kind, the file system and a database being the most common, but a job can read and write messages to Java Message Service (JMS) queues as well.
Note
Jobs can communicate with data sources, but so does the job repository. In fact, the job repository stores job execution metadata in a database to provide Spring Batch reliable monitoring and restart features.
Note that figure 2.2 doesn’t show whether Spring Batch needs to run in a specific container. Chapter 4 says more about this topic, but for now, you just need to know that Spring Batch can run anywhere the Spring Framework can run: in its own Java process, in a web container, in an application, or even in an Open Services Gateway initiative (OSGi) container. The container depends on your requirements, and Spring Batch is flexible in this regard.
Now that you know more about Spring Batch’s core components and how they interact with each other and the outside world, let’s focus on the framework’s infrastructure components: the job launcher and the job repository.
2.2. The Spring Batch infrastructure
The Spring Batch infrastructure includes components that launch your batch jobs and store job execution metadata. As a batch application developer, you don’t have to deal directly with these components, as they provide supporting roles to your applications, but you need to configure this infrastructure at least once in your Spring Batch application.
This section gives an overview of the job launcher, job repository, and their interactions, and then shows how to configure persistence of the job repository.
2.2.1. Launching jobs and storing job metadata
The Spring Batch infrastructure is complex, but you need to deal mainly with two components: the job launcher and the job repository. These concepts match two straightforward Java interfaces: JobLauncher and JobRepository.
The Job Launcher
As figure 2.2 shows, the job launcher is the entry point to launch Spring Batch jobs: this is where the external world meets Spring Batch. The JobLauncher interface is simple:
package org.springframework.batch.core.launch;
(...)
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException,
JobRestartException, JobInstanceAlreadyCompleteException,
JobParametersInvalidException;
}
The run method accepts two parameters: Job, which is typically a Spring bean configured in Spring Batch XML, and JobParameters, which is usually created on the fly by the launching mechanism.
Who calls the job launcher? Your own Java program can use the job launcher to launch a job, but so can command-line programs or schedulers (like cron or the Java-based Quartz scheduler).
The job launcher encapsulates launching strategies such as executing a job synchronously or asynchronously. Spring Batch provides one implementation of the JobLauncher interface: SimpleJobLauncher. We look at configuring SimpleJobLauncher in chapter 3 and at fine-tuning in chapter 4. For now, it’s sufficient to know that the SimpleJobLauncher class only launches a job—it doesn’t create it but delegates this work to the job repository.
The Job Repository
The job repository maintains all metadata related to job executions. Here’s the definition of the JobRepository interface:
package org.springframework.batch.core.repository;
(...)
public interface JobRepository {
boolean isJobInstanceExists(String jobName, JobParameters jobParameters);
JobExecution createJobExecution(
String jobName, JobParameters jobParameters)
throws JobExecutionAlreadyRunningException, JobRestartException,
JobInstanceAlreadyCompleteException;
void update(JobExecution jobExecution);
void add(StepExecution stepExecution);
void update(StepExecution stepExecution);
void updateExecutionContext(StepExecution stepExecution);
void updateExecutionContext(JobExecution jobExecution);
StepExecution getLastStepExecution(JobInstance jobInstance,
String stepName);
int getStepExecutionCount(JobInstance jobInstance, String stepName);
JobExecution getLastJobExecution(String jobName,
JobParameters jobParameters);
}
The JobRepository interface provides all the services to manage the batch job lifecycle: creation, update, and so on. This explains the interactions in figure 2.2: the job launcher delegates job creation to the job repository, and a job calls the job repository during execution to store its current state. This is useful to monitor how your job executions proceed and to restart a job exactly where it failed. Note that the Spring Batch runtime handles all calls to the job repository, meaning that persistence of the job execution metadata is transparent to the application code.
What constitutes runtime metadata? It includes the list of executed steps; how many items Spring Batch read, wrote, or skipped; the duration of each step; and so forth. We won’t list all metadata here; you’ll learn more when we study the anatomy of a job in section 2.3.
Spring Batch provides two implementations of the JobRepository interface: one stores metadata in memory, which is useful for testing or when you don’t want monitoring or restart capabilities; the other stores metadata in a relational database. Next, we see how to configure the Spring Batch infrastructure in a database.
2.2.2. Configuring the Spring Batch infrastructure in a database
Spring Batch provides a job repository implementation to store your job metadata in a database. This allows you to monitor the execution of your batch processes and their results (success or failure). Persistent metadata also makes it possible to restart a job exactly where it failed.
Configuring this persistent job repository helps illustrate the other concepts in this chapter, which are detailed in chapter 3.
Spring Batch delivers the following to support persistent job repositories:
- SQL scripts to create the necessary database tables for the most popular database engines
- A database implementation of JobRepository (SimpleJobRepository) that executes all necessary SQL statements to insert, update, and query the job repository tables
Let’s now see how to configure the database job repository.
Creating the Database Tables for a Job Repository
The SQL scripts to create the database tables are located in the core Spring Batch JAR file (for example, spring-batch-core-2.1.x.jar, depending on the minor version of the framework you’re using) in the org.springframework.batch.core package. The SQL scripts use the following naming convention: schema-[database].sql for creating tables and schema-drop-[database].sql for dropping tables, where [database] is the name of a database engine. To initialize H2 for Spring Batch, we use the file schema-h2.sql.
Spring Batch supports the following database engines: DB2, Derby, H2, HSQLDB, MySQL, Oracle, PostgreSQL, SQLServer, and Sybase.
All you have to do is create a database for Spring Batch and then execute the corresponding SQL script for your database engine.
Configuring the Job Repository with Spring
We already configured a job repository bean in chapter 1, but it was in an in-memory implementation (H2). The following listing shows how to configure a job repository in a database.
Listing 2.1. Configuration of a persistent job repository

The job-repository XML element in the batch namespace creates a persistent job repository ![]() . To work properly, the persistent job repository needs a data source and a transaction manager. A data source implementation
. To work properly, the persistent job repository needs a data source and a transaction manager. A data source implementation
![]() that holds a single JDBC connection and reuses it for each query is used because it’s convenient and good enough for a single-threaded
application (like a batch process). If you plan to use the data source in a concurrent application, then use a connection
pool, like Apache Commons DBCP or c3p0. Using a persistent job repository doesn’t change much in the Spring Batch infrastructure
configuration: you use the same job launcher implementation as in the in-memory configuration.
that holds a single JDBC connection and reuses it for each query is used because it’s convenient and good enough for a single-threaded
application (like a batch process). If you plan to use the data source in a concurrent application, then use a connection
pool, like Apache Commons DBCP or c3p0. Using a persistent job repository doesn’t change much in the Spring Batch infrastructure
configuration: you use the same job launcher implementation as in the in-memory configuration.
Now that the persistent job repository is ready, let’s take a closer look at it.
Accessing Job Metadata
If you look at the job repository database, you see that the SQL script created six tables. If you want to see how Spring Batch populates these tables, launch the LaunchDatabaseAndConsole class and then the GeneratesJobMetaData class (in the source code from this book). The latter class launches a job several times to populate the batch metadata tables. (Don’t worry if you see an exception in the console: we purposely fail one job execution.) We analyze the content of the job repository later in this chapter because it helps to explain how Spring Batch manages job execution, but if you’re impatient to see the content of the batch tables, read the next note.
Note
The LaunchDatabaseAndConsole class provided with the source code of this book starts an in-memory H2 database and the HTTP-based H2 Console Server. You can access the Console Server at http://127.0.1.1:8082/ and provide the URL of the database: jdbc:h2:tcp://localhost/mem:sbia_ch02. The Console Server then provides the default username and password to log in. You can see that Spring Batch created all the necessary tables in the database (take a look at the root-database-context.xml file to discover how). Keep in mind that this is an in-memory database, so stopping the program will cause all data to be lost!
Figure 2.3 shows how you can use the Spring Batch Admin web application to view job executions. Spring Batch Admin accesses the job repository tables to provide this functionality.
Figure 2.3. The Spring Batch Admin web application lists all job instances for a given job, in this case, import products. Spring Batch Admin uses job metadata stored in a database to monitor job executions.
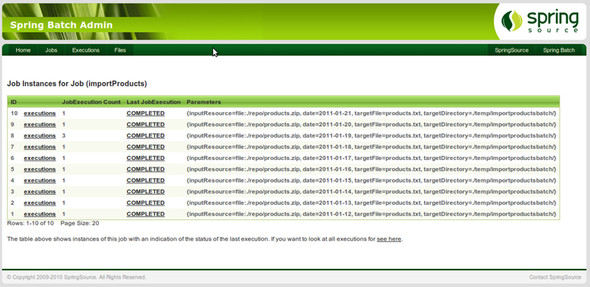
Spring Batch Admin is an open source project from SpringSource that provides a web-based UI for Spring Batch applications. We cover Spring Batch Admin in chapter 12, where we discuss Spring Batch application monitoring. Appendix B covers the installation of Spring Batch Admin. You’ll also see more of Spring Batch Admin in this chapter when you use it to browse batch execution metadata.
We now have a persistent job repository, which we use to illustrate forthcoming runtime concepts. You have enough knowledge of the in-memory and persistent implementations of the job repository to compare them and see which best suits your needs.
Considerations on Job Repository Implementations
Spring Batch users sometimes see the persistent job repository as a constraint because it means creating dedicated Spring Batch tables in a database. They prefer to fall back on the in-memory job repository implementation, which is more flexible. These users don’t always realize the consequences of using the in-memory implementation. Let’s answer some frequently asked questions about the various job repository implementations.
- Can I use the in-memory job repository in production? You should avoid doing that; the in-memory job repository is meant for development and testing. Some people run the in-memory job repository successfully in production because it works correctly under specific conditions (it isn’t designed for concurrent access, when multiple jobs can run at the same time). If you get errors with the in-memory job repository and if you really don’t want to create batch tables in your database, use the persistent job repository with an in-memory database (like H2 or Derby).
- What are the benefits of the persistent job repository? The benefits are monitoring, restart, and clustering. You can browse the batch execution metadata to monitor your batch executions. When a job fails, the execution metadata is still available, and you can use it to restart the job where it left off. The persistent job repository, thanks to the isolation the database provides, prevents launching the exact same job from multiple nodes at the same time. Consider the persistent job repository as a safeguard against concurrency issues when creating batch entities in the database.
- Does the persistent job repository add overhead? Compared to the in-memory job repository, yes. Communicating with a potentially remote database is always more costly than speaking to local in-memory objects. But the overhead is usually small compared to the actual business processing. The benefits the persistent job repository brings to batch applications are worth the limited overhead!
- Can I use a different database for the persistent job repository and my business data? Yes, but be careful with transaction management. You can use the Java Transaction API (JTA) to make transactions span both databases: the batch tables and the business tables will always be synchronized, but you’ll add overhead because managing multiple transactional resources is more expensive than managing just one. If transactions don’t span the two databases, batch execution metadata and business data can get unsynchronized on failure. Data such as skipped items could then become inaccurate, or you could see problems on restart. To make your life easier (and your jobs faster and reliable), store the batch metadata in the same database as the business data.
This completes our coverage of the job repository. Let’s dive into the structural and runtime aspects of the core Spring Batch concept: the job.
2.3. Anatomy of a job
The job is the central concept in a batch application: it’s the batch process itself. A job has two aspects that we examine in this section: a static aspect used for job modeling and a dynamic aspect used for runtime job management. Spring Batch provides a well-defined model for jobs and includes tools—such as Spring Batch XML—to configure this model. Spring Batch also provides a strong runtime foundation to execute and dynamically manage jobs. This foundation provides a reliable way to control which instance of a job Spring Batch executes and the ability to restart a job where it failed. This section explains these two job aspects: static modeling and dynamic runtime.
2.3.1. Modeling jobs with steps
A Spring Batch job is a sequence of steps configured in Spring Batch XML. Let’s delve into these concepts and see what they bring to your batch applications.
Modeling a Job
Recall from chapter 1 that the import products job consists of two steps: decompress the incoming archive and import the records from the expanded file into the database. We could also add a cleanup step to delete the expanded file. Figure 2.4 depicts this job and its three successive steps.
Figure 2.4. A Spring Batch job is a sequence of steps, such as this import products job, which includes three steps: decompress, read-write, and cleanup.

Decomposing a job into steps is cleaner from both a modeling and a pragmatic perspective because steps are easier to test and maintain than is one monolithic job. Jobs can also reuse steps; for example, you can reuse the decompress step from the import products job in any job that needs to decompress an archive—you only need to change the configuration.
Figure 2.4 shows a job built of three successive linear steps, but the sequence of steps doesn’t have to be linear, as in figure 2.5, which shows a more advanced version of the import products job. This version generates and sends a report to an administrator if the read-write step skipped records.
Figure 2.5. A Spring Batch job can be a nonlinear sequence of steps, like this version of the import products job, which sends a report if some records were skipped.

To decide which path a job takes, Spring Batch allows for control flow decisions based on the status of the previous step (completed, failed) or based on custom logic (by checking the content of a database table, for example). You can then create jobs with complex control flows that react appropriately to any kind of condition (missing files, skipped records, and so on). Control flow brings flexibility and robustness to your jobs because you can choose the level of control complexity that best suits any given job.
The unpleasant alternative would be to split a big, monolithic job into a set of smaller jobs and try to orchestrate them with a scheduler using exit codes, files, or some other means.
You also benefit from a clear separation of concerns between processing (implemented in steps) and execution flow, configured declaratively or implemented in dedicated decision components. You have less temptation to implement transition logic in steps and thus tightly couple steps with each other.
Let’s see some job configuration examples.
Configuring a Job
Spring Batch provides an XML vocabulary to configure steps within a job. The following listing shows the code for the linear version of the import products job.
Listing 2.2. Configuring a job with linear flow
<job id="importProductsJob">
<step id="decompress" next="readWrite">
<tasklet ref="decompressTasklet" />
</step>
<step id="readWrite" next="clean">
<tasklet>
<chunk reader="reader" writer="writer"
commit-interval="100" />
</tasklet>
</step>
<step id="clean">
<tasklet ref="cleanTasklet" />
</step>
</job>
The next attribute of the step tag sets the execution flow, by pointing to the next step to execute. Tags like tasklet or chunk can refer to Spring beans with appropriate attributes.
When a job is made of a linear sequence of steps, using the next attribute of the step elements is enough to connect the job steps. The next listing shows the configuration for the nonlinear version of the import products job from figure 2.5.
Listing 2.3. Configuring a job with nonlinear flow

Note
Chapter 10 covers the decider XML element, the corresponding JobExecutionDecider interface, and the job execution flow. We introduce these concepts here only to illustrate the structure of a Spring Batch job.
Notice from the previous XML fragment that Spring Batch XML is expressive enough to allow job configuration to be human readable. If your editor supports XML, you also benefit from code completion and code validation when editing your XML job configuration. An integrated development environment like the Eclipse-based SpringSource Tool Suite also provides a graphical view of a job configuration, as shown in figure 2.6. To get this graph, open the corresponding XML file and select the Batch-Graph tab at the bottom of the editor.
Figure 2.6. A job flow in the SpringSource Tool Suite. The tool displays a graph based on the job model defined in Spring Batch XML.
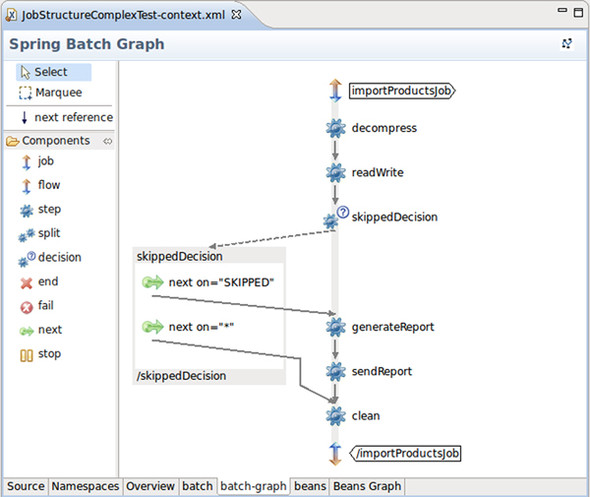
Note
The SpringSource Tool Suite is a free Eclipse-based product that provides tooling for Spring applications (code completion for Spring XML files, bean graphs, and much more). It also provides support for projects in the Spring portfolio like Spring Batch. Appendix A covers how to install and use the SpringSource Tool Suite for Spring Batch applications.
We won’t go into further details here of configuration and execution flow, as chapters 3 and 10 respectively cover these topics thoroughly. Now that you know that a Spring Batch job is a sequence of steps and that you can control job flow, let’s see what makes up a step.
Processing with Taskletstep
Spring Batch defines the Step interface to embody the concept of a step and provides implementations like FlowStep, JobStep, PartitionStep, and TaskletStep. The only implementation you care about as an application developer is TaskletStep, which delegates processing to a Tasklet object. As you discovered in chapter 1, the Tasklet Java interface contains only one method, execute, to process some unit of work. Creating a step consists of either writing a Tasklet implementation or using one provided by Spring Batch.
You implement your own Tasklet when you need to perform processing, such as decompressing files, calling a stored procedure, or deleting temporary files at the end of a job.
If your step follows the classic read-process-write batch pattern, use the Spring Batch XML chunk element to configure it as a chunk-processing step. The chunk element allows your step to use chunks to efficiently read, process, and write data.
Note
The Spring Batch chunk element is mapped to a Tasklet implemented by the ChunkOrientedTasklet class.
You now know that a job is a sequence of steps and that you can easily define this sequence in Spring Batch XML. You implement steps with Tasklets, which are either chunk oriented or completely customized. Let’s move on to the runtime.
2.3.2. Running job instances and job executions
Because batch processes handle data automatically, being able to monitor what they’re doing or what they’ve done is a must. When something goes wrong, you need to decide whether to restart a job from the beginning or from where it failed. To do this, you need to strictly define the identity of a job run and reliably store everything the job does during its run. This is a difficult task, but Spring Batch handles it all for you.
The Job, Job Instance, and Job Execution
We defined a job as a batch process composed of a sequence of steps. Spring Batch also includes the concepts of job instance and job execution, both related to the way the framework handles jobs at runtime. Table 2.2 defines these concepts and provides examples.
Table 2.2. Definitions for job, job instance, and job execution
|
Term |
Description |
Example |
|---|---|---|
| Job | A batch process, or sequence of steps | The import products job |
| Job instance | A specific run of a job | The import products job run on June 27, 2010 |
| Job execution | The execution of a job instance (with success or failure) | The first run of the import products job on June 27, 2010 |
Figure 2.7 illustrates the correspondence between a job, its instances, and their executions for two days of executions of the import products job.
Figure 2.7. A job can have several job instances, which can have several job executions. The import products job executes daily, so it should have one instance per day and one or more corresponding executions, depending on success or failure.

Now that we’ve defined the relationship between job, job instance, and job execution, let’s see how to define a job instance in Spring Batch.
Defining a Job Instance
In Spring Batch, a job instance consists of a job and job parameters. When we speak about the June 27, 2010, instance of our import products job, the date is the parameter that defines the job instance (along with the job itself). This is a simple yet powerful way to define a job instance, because you have full control over the job parameters, as shown in the following snippet:
jobLauncher.run(job, new JobParametersBuilder()
.addString("date", "2010-06-27")
.toJobParameters()
);
As a Spring Batch developer, you must keep in mind how to uniquely define a job instance.
Job Instance
A job instance consists of a job and job parameters. We define this contract with the following equation: JobInstance = Job + JobParameters.
The previous equation is important to remember. In our example, a job instance is temporal, as it refers to the day it was launched. But you’re free to choose what parameters constitute your job instances thanks to job parameters: date, time, input files, or simple sequence counter.
What happens if you try to run the same job several times with the same parameters? It depends on the lifecycle of job instances and job executions.
The Lifecycle of a Job Instance and Job Execution
Several rules apply to the lifecycle of a job instance and job execution:
- When you launch a job for the first time, Spring Batch creates the corresponding job instance and a first job execution.
- You can’t launch the execution of a job instance if a previous execution of the same instance has already completed successfully.
- You can’t launch multiple executions of the same instance at the same time.
We hope that by now all these concepts are clear. As an illustration, let’s perform runs of the import products job and analyze the job metadata that Spring Batch stores in the database.
Multiple Runs of the Import Products Job
The import products job introduced in chapter 1 is supposed to run once a day to import all the new and updated products from the catalog system. To see how Spring Batch updates the job metadata in the persistent job repository previously configured, make the following sequence of runs:
- Run the job for June 27, 2010. The run will succeed.
- Run the job a second time for June 27, 2010. Spring Batch shouldn’t launch the job again because it’s already completed for this date.
- Run the job for June 28, 2010, with a corrupted archive. The run will fail.
- Run the job for June 28, 2010, with a valid archive. The run will succeed.
Starting the database:
1. Launch the LaunchDatabaseAndConsole program.
Running the job for June 27, 2010:
1. Copy the products.zip file from the input directory into the root directory of the ch02 project.
2. Run the LaunchImportProductsJob class: this launches the job for June 27, 2010.
3. Run the LaunchSpringBatchAdmin program from the code samples to start an embedded web container with the Spring Batch Admin application running.
4. View instances of the import products job at the following URL: http://localhost:8080/springbatchadmin/jobs/importProducts. Figure 2.8 shows the graphical interface with the job instances and the job repository created for this run.
Figure 2.8. After the run for June 27, 2010, Spring Batch created a job instance in the job repository. The instance is marked as COMPLETED and is the first and only execution to complete successfully.

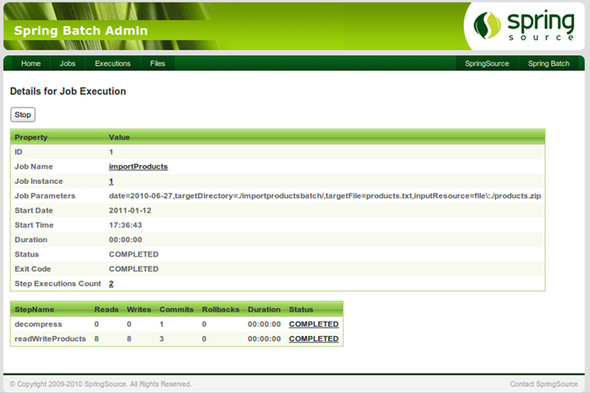
3. Follow the links from the Job Instances view to get to the details of the corresponding execution, as shown in figure 2.9.
Figure 2.9. Details (duration, number of steps executed, and so on) of the first and only job execution for June 27, 2010. You can also learn about the job instance because the job parameters appear in the table.
Note
You must check the job parameters to be sure of the execution identity. For example, the date job parameter tells you that this is an execution of the June 27, 2010, instance. The Start Date attribute indicates exactly when the job ran.
Running the job a second time for June 27, 2010:
1. Run the LaunchImportProductsJob class. You get an exception because an execution already completed successfully, so you can’t launch another execution of the same instance.
Running the job for June 28, 2010, with a corrupted archive:
1. Delete the products.zip file and the importproductsbatch directory created to decompress the archive.
2. Copy the products_corrupted.zip from the input directory into the root of the project and rename it products.zip.
3. Simulate launching the job for June 28, 2010, by changing the job parameters in LaunchImportProductsJob; for example:
jobLauncher.run(job, new JobParametersBuilder()
.addString("inputResource", "file:./products.zip")
.addString("targetDirectory", "./importproductsbatch/")
.addString("targetFile","products.txt")
.addString("date", "2010-06-28")
.toJobParameters()
);
4. Run the LaunchImportProductsJob class. You get an exception saying that nothing can be extracted from the archive (the archive is corrupted).
5. Go to http://localhost:8080/springbatchadmin/jobs/importProducts, and you’ll see that the import products job has another instance, but this time the execution failed.
Running the job for June 28, 2010 with a valid archive:
1. Replace the corrupted archive with the correct file (the same as for the first run).
2. Launch the job again.
3. Check in Spring Batch Admin that the instance for June 28, 2010, has completed. Figure 2.10 shows the two executions of the June 28, 2010, instance.
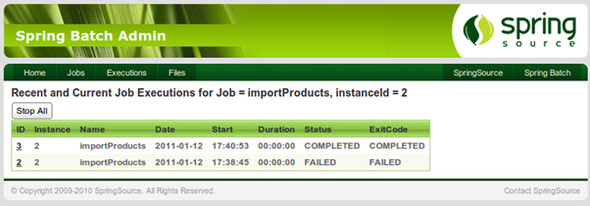
Figure 2.10. The two June 28, 2010, executions. The first failed because of a corrupted archive, but the second completed successfully, thereby completing the job instance.
Note
To run the tests from scratch after you run the job several times, stop and restart the LaunchDatabaseAndConsole class.
You just put into practice the concepts of job instance and job execution. To do so, you used a persistent job repository, which allowed you to visualize job instances and executions. In this example, job metadata illustrated the concepts, but you can also use this metadata for monitoring a production system. The metadata is also essential to restart a failed job—a topic covered in depth in chapter 8.
2.4. Summary
This chapter is rich in Spring Batch concepts and terminology! Using a now well-defined vocabulary, you can paint a clear picture of your batch applications. You learned how the Spring Batch framework models these concepts, an important requirement to understanding how to implement batch solutions. You saw the static and dynamic aspects of jobs: static by modeling and configuring jobs with steps, dynamic through the job runtime handling of job instances and executions. Restarting failed jobs is an important requirement for some batch applications, and you saw how Spring Batch implements this feature by storing job execution metadata; you also saw the possibilities and limitations of this mechanism.
With this picture of the Spring Batch model in mind, let’s move on to the next chapter and see how to configure our batch applications with the Spring lightweight container and Spring Batch XML.