
Chapter 3. Batch configuration
- Configuring batch processes using Spring Batch XML
- Configuring batch jobs and related entities
- Using advanced techniques to improve configuration
In chapter 2, we explored Spring Batch foundations, described all Spring Batch concepts and entities, and looked at their interactions. The chapter introduced configuring and implementing the structure of batch jobs and related entities with Spring Batch XML.
In this chapter, we continue the online store case study: reading products from files, processing products, and integrating products in the database. Configuring this process serves as the backdrop for describing all of Spring Batch’s configuration capabilities.
After describing Spring Batch XML capabilities, we show how to configure batch jobs and related entities with this dedicated XML vocabulary. We also look at configuring a repository for batch execution metadata. In the last part of this chapter, we focus on advanced configuration topics and describe how to make configuration easier.
How should you read this chapter? You can use it as a reference for configuring Spring Batch jobs and either skip it or come back to it for a specific configuration need. Or, you can read it in its entirety to get an overview of nearly all the features available in Spring Batch. We say an “overview” because when you learn about configuring a skipping policy, for example, you won’t learn all the subtleties of this topic. That’s why you’ll find information in dedicated sections in other chapters to drill down into difficult topics.
3.1. The Spring Batch XML vocabulary
Like all projects in the Spring portfolio and the Spring framework itself, Spring Batch provides a dedicated XML vocabulary and namespace to configure its entities. This feature leverages the Spring XML schema–based configuration introduced in Spring 2 and simplifies bean configuration, enabling configurations to operate at a high level by hiding complexity when configuring entities and related Spring-based mechanisms.
In this section, we describe how to use Spring Batch XML and the facilities it offers for batch configuration. Without this vocabulary, we’d need intimate knowledge of Spring Batch internals and entities that make up the batch infrastructure, which can be tedious and complex to configure.
3.1.1. Using the Spring Batch XML namespace
Like most components in the Spring portfolio, Spring Batch configuration is based on a dedicated Spring XML vocabulary and namespace. By hiding internal Spring Batch implementation details, this vocabulary provides a simple way to configure core components like jobs and steps as well as the job repository used for job metadata (all described in chapter 2). The vocabulary also provides simple ways to define and customize batch behaviors.
Before we get into the XML vocabulary and component capabilities, you need to know how use Spring Batch XML in Spring configuration files. In the following listing, the batch namespace prefix is declared and used in child XML elements mixed with other namespace prefixes, such as the Spring namespace mapped to the default XML namespace.
Listing 3.1. Spring Batch XML namespace and prefix
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch.xsd">
<batch:job id="importProductsJob">
(...)
</batch:job>
</beans>
Spring Batch uses the Spring standard mechanism to configure a custom XML namespace: the Spring Batch XML vocabulary is implemented in Spring Batch jars, automatically discovered, and handled by Spring. In listing 3.1, because Spring XML Beans uses the default namespace, each Spring Batch XML element is qualified with the batch namespace prefix.
Note that a namespace prefix can be whatever you want; in our examples, we use the batch and beans prefixes by convention.
As of version 2.0, Spring uses an XML schema–based configuration system. XML schemas replace the previous Document Type Definition (DTD)-driven configuration system that mainly used two tags: bean for declaring a bean and property for injecting dependencies (with our apologies to Spring for this quick-and-dirty summary). While this approach works for creating beans and injecting dependencies, it’s insufficient to define complex tasks. The DTD bean and property mechanism can’t hide complex bean creation, which is a shortcoming in configuring advanced features like aspectoriented programming (AOP) and security. Before version 2.0, XML configuration was non-intuitive and verbose.
Spring 2.0 introduced a new, extensible, schema-based XML configuration system. On the XML side, XML schemas describe the syntax, and on the Java side, corresponding namespace handlers encapsulate the bean creation logic. The Spring framework provides namespaces for its modules (AOP, transaction, Java Message Service [JMS], and so on), and other Spring-based projects can benefit from the namespace extension mechanism to provide their own namespaces. Each Spring portfolio project comes with one or more dedicated vocabularies and namespaces to provide the most natural and appropriate way to configure objects using module-specific tags.
Listing 3.2 declares the Spring Batch namespace as the default namespace in the root XML element. In this case, the elements without a prefix correspond to Spring Batch elements. Using this configuration style, you don’t need to repeat using the Spring Batch namespace prefix for each Spring Batch XML element.
Listing 3.2. Using the Spring Batch namespace as the default namespace
<?xml version="1.0" encoding="UTF-8"?>
<beans:beans
xmlns="http://www.springframework.org/schema/batch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:beans="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<job id="importProductsJob">
(...)
</job>
</beans:beans>
With a configuration defined using Spring Batch XML, you can now leverage all the facilities it provides. In the next section, we focus on Spring Batch XML features and describe how to configure and use those capabilities.
3.1.2. Spring Batch XML features
Spring Batch XML is the central feature in Spring Batch configurations. You use this XML vocabulary to configure all batch entities described in chapter 2. table 3.1 lists and describes the main tags in Spring Batch XML.
Table 3.1. Main tags in Spring Batch XML
|
Tag name |
Description |
|---|---|
| job | Configures a batch job |
| step | Configures a batch step |
| tasklet | Configures a tasklet in a step |
| chunk | Configures a chunk in a step |
| job-repository | Configures a job repository for metadata |
Spring Batch XML configures the structure of batches, but specific entities need to be configured using Spring features. Spring Batch XML provides the ability to interact easily with standard Spring XML. You can configure other entities like item readers and writers as simple beans and then reference them from entities configured with Spring Batch XML. Figure 3.1 describes the possible interactions between the Spring Batch namespace and the Spring default namespace.
Figure 3.1. Interactions between Spring Batch and Spring XML vocabularies. The batch vocabulary defines the structure of batches. Some batch entities, such as a job, can refer to Spring beans defined with the beans vocabulary, such as item readers and writers.

Now that you’ve seen the capabilities provided for Spring Batch configuration, it’s time to dive into details. In our case study, these capabilities let you configure a batch job and its steps.
3.2. Configuring jobs and steps
As described in chapter 2, the central entities in Spring Batch are jobs and steps, which describe the details of batch processing. The use case entails defining what the batch must do and how to organize its processing. For our examples, we use the online store case study. After defining the job, we progressively extend it by adding internal processing.
We focus here on how to configure the core entities of batch processes; we also examine their relationships at the configuration level. Let’s first look at the big picture.
3.2.1. Job entities hierarchy
Spring Batch XML makes the configuration of jobs and related entities easier. You don’t need to configure Spring beans corresponding to internal Spring Batch objects; instead you can work at a higher level of abstraction, specific to Spring Batch. Spring Batch XML configures batch components such as job, step, tasklet, and chunk, as well as their relationships. Together, all these elements make up batch processes. Figure 3.2 depicts this hierarchy.
Figure 3.2. The entity configuration hierarchy for batch processing. The Spring configuration contains the job configuration, which contains the step configuration, which contains the tasklet configuration, which contains the chunk configuration.
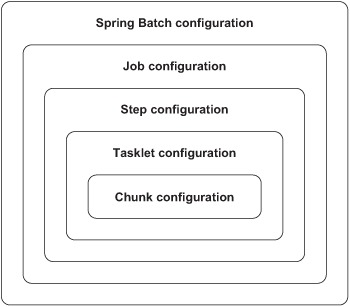
Within Spring Batch XML, this hierarchy corresponds to nested XML elements with the ability to specify parameters at each level, as shown in the following listing. For example, a job defined with the job element can contain one or more steps, which you define with step elements within the job element. Similar types of configurations can be used for steps, tasklets, and chunks.
Listing 3.3. Nested configuration of a job
<batch:job id="importProductsJob">
(...)
<batch:step id="readWriteStep">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk
reader="productItemReader"
processor="productItemProcessor"
writer="productItemWriter"
commit-interval="100"/>
</batch:tasklet>
</batch:step>
</batch:job>
For our case study, these nested elements are used to define each job, particularly the reading, processing, and writing logic.
Now that we’ve described high-level configuration concepts for Spring Batch entities, let’s examine configuration details using Spring Batch XML.
3.2.2. Configuring jobs
When implementing a batch application with Spring Batch, the top-level entity is the job, and it’s the first entity you configure when defining a batch process. In the context of our case study, the job is a processing flow that imports and handles products for the web store. (The job concept is described in chapter 2, section 2.3.)
To configure a job, you use the Spring Batch XML job element and the attributes listed in table 3.2.
Table 3.2. Job attributes
|
Job attribute name |
Description |
|---|---|
| id | Identifies the job. |
| restartable | Specifies whether Spring Batch can restart the job. The default is true. |
| incrementer | Refers to an entity used to set job parameter values. This entity is required when trying to launch a batch job through the startNextInstance method of the JobOperator interface. |
| abstract | Specifies whether the job definition is abstract. If true, this job is a parent job configuration for other jobs. It doesn’t correspond to a concrete job configuration. |
| parent | Defines the parent of this job. |
| job-repository | Specifies the job repository bean used for the job. Defaults to a jobRepository bean if none specified. |
The attributes parent and abstract deal with configuration inheritance in Spring Batch; for details, see section 3.4.4. Let’s focus here on the restartable, incrementer, and job-repository attributes.
The restartable attribute specifies whether Spring Batch can restart a job. If false, Spring Batch can’t start the job more than once; if you try, Spring Batch throws the exception JobRestartException. The following snippet describes how to configure this behavior for a job:
<batch:job id="importProductsJob" restartable="false">
(...)
</batch:job>
The job-repository attribute is a bean identifier that specifies which job repository to use for the job. Section 3.3 describes this task.
The incrementer attribute provides a convenient way to create new job parameter values. Note that the JobLauncher doesn’t need this feature because you must provide all parameter values explicitly. When the startNextInstance method of the JobOperator class launches a job, though, the method needs to determine new parameter values and use an instance of the JobParametersIncrementer interface:
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}
The getNext method can use the parameters from the previous job instance to create new values.
You specify an incrementer object in the job configuration using the incrementer attribute of the job element, for example:
<batch:job id="importProductsJob" incrementer="customIncrementer">
(...)
</batch:job>
<bean id="customIncrementer" class="com.manning.sbia
 .configuration.job.CustomIncrementer"/>
.configuration.job.CustomIncrementer"/>
Chapter 4, section 4.5.1, describes the use of the JobOperator class in more detail.
Besides these attributes, the job element supports nested elements to configure listeners and validators. We describe listeners in section 3.4.3.
You can configure Spring Batch to validate job parameters and check that all required parameters are present before starting a job. To validate job parameters, you implement the JobParametersValidator interface:
public interface JobParametersValidator {
void validate(JobParameters parameters)
throws JobParametersInvalidException;
}
The validate method throws a JobParametersInvalidException if a parameter is invalid. Spring Batch provides a default implementation of this interface with the DefaultJobParametersValidator class that suits most use cases. This class allows you to specify which parameters are required and which are optional. The following listing describes how to configure and use this class in a job.
Listing 3.4. Configuring a job parameter validator
<batch:job id="importProductsJob">
(...)
<batch:validator ref="validator"/>
</batch:job>
<bean id="validator" class="org.springframework.batch
.core.job.DefaultJobParametersValidator">
<property name="requiredKeys">
<set>
<value>date</value>
</set>
</property>
<property name="optionalKeys">
<set>
<value>productId</value>
</set>
</property>
</bean>
The validator element’s ref attribute references the validator bean. This configuration uses a bean of type DefaultJobParametersValidator to specify the required and optional parameter keys. The requiredKeys and optionalKeys properties of the validator class are used to set these values.
Now let’s look at configuring job steps to define exactly what processing takes place in that job.
3.2.3. Configuring steps
Here, we go down a level in the job configuration and describe what makes up a job: steps. Don’t hesitate to refer back to figure 3.2 to view the relationships between all the batch entities. A step is a phase in a job; chapter 2, section 2.3.1, describes these concepts. Steps define the sequence of actions a job will take, one at a time. In the online store use case, you receive products in a compressed file; the job decompresses the file before importing and saving the products in the database, as illustrated in figure 3.3.
Figure 3.3. The steps of the import products job: decompress and readWrite. The decompress step first reads a zip file and decompresses it to another file. The readWrite step reads the decompressed file.
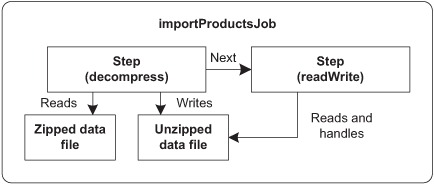
You configure a job step using the step element and the attributes listed in table 3.3.
Table 3.3. Step attributes
|
Description |
|
|---|---|
| next | The next step to execute in a sequence of steps. |
| parent | The parent of the step configuration. |
| abstract | Specifies whether the step definition is abstract. If true, this step is a parent step configuration for other steps. It doesn’t correspond to a concrete step configuration. |
The attributes parent and abstract deal with configuration inheritance in Spring Batch; for details, see section 3.4.4.
Configuring a step is simple because a step is a container for a tasklet, executed at a specific point in the flow of a batch process. For our use case, you define what steps take place and in what order. Product files come in as compressed data files to optimize file uploads. A first step decompresses the data file, and a second step processes the data. The following fragment describes how to configure this flow:
<job id="importProductsJob">
<step id="decompress" next="readWrite">
(...)
</step>
<step id="readWrite">
(...)
</step>
</job>
You always define the step element as a child element of the job element. Spring Batch uses the id attribute to identify objects in a configuration. This aspect is particularly important to use steps in a flow. The next attribute of the step element is set to define which step to execute next. In the preceding fragment, the step identified as decompress is executed before the step identified as readWrite.
Now that we’ve described the job and step elements, let’s continue our tour of Spring Batch core objects with tasklets and chunks, which define what happens in a step.
3.2.4. Configuring tasklets and chunks
The tasklet and chunk are step elements used to specify processing. Chapter 2, section 2.3.1, describes these concepts. To import products, you successively configure how to import product data, how to process products, and where to put products in the database, as illustrated in figure 3.4.
Figure 3.4. The import product tasklet configuration and chunk configuration define three steps: import, process, and store products.

Tasklet
A tasklet corresponds to a transactional, potentially repeatable process occurring in a step. You can write your own tasklet class by implementing the Tasklet interface or use the tasklet implementations provided by Spring Batch. Implementing your own tasklets is useful for specific tasks, such as decompressing an archive or cleaning a directory. Spring Batch provides more generic tasklet implementations, such as to call system commands or to do chunk-oriented processing.
To configure a tasklet, you define a tasklet element within a step element. table 3.4 lists the attributes of the tasklet element.
Table 3.4. Tasklet attributes
|
Tasklet attribute name |
Description |
|---|---|
| ref | A Spring bean identifier whose class implements the Tasklet interface. You must use this attribute when implementing a custom tasklet. |
| transaction-manager | The Spring transaction manager to use for tasklet transactions. By default, a tasklet is transactional, and the default value of the attribute is transactionManager. |
| start-limit | The number of times Spring Batch can restart a tasklet for a retry. |
| allow-start-if-complete | Specifies whether Spring Batch can restart a tasklet even if it completed for a retry. |
Listing 3.5 shows how to use the last three attributes of the tasklet element, whatever the tasklet type. Because you want to write the products from the compressed import file to a database, you must specify a transaction manager to handle transactions associated with inserting products in the database. This listing also specifies additional parameters to define restart behavior.
Listing 3.5. Configuring tasklet attributes
<batch:job id="importProductsJob">
(...)
<batch:step id="readWriteStep">
<batch:tasklet
transaction-manager="transactionManager"
start-limit="3"
allow-start-if-complete="true">
(...)
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="transactionManager" class="(...)">
(...)
</bean>
The transaction-manager attribute contains the bean identifier corresponding to the Spring transaction manager to use during the tasklet’s processing. The bean must implement the Spring PlatformTransactionManager interface. The attributes start-limit and allow-start-if-complete specify that Spring Batch can restart the tasklet three times in the context of a retry even if the tasklet has completed. We describe in section 3.2.5 how to control rollback for a step.
In the case of a custom tasklet, you can reference the Spring bean implementing the Tasklet interface with the ref attribute. Spring Batch delegates processing to this class when executing the step. In our use case, decompressing import files doesn’t correspond to processing that Spring Batch natively supports, so you need a custom tasklet to implement decompression. The following snippet describes how to configure this tasklet:
<job id="importProductsJob">
<step id="decompress" next="readWrite">
<tasklet ref="decompressTasklet" />
</step>
</job>
Listing 1.5 in chapter 1 shows the code for the DecompressTasklet tasklet and listing 1.6 shows its configuration.
Spring Batch also supports using chunks in tasklets. The chunk child element of the tasklet element configures chunk processing. Note that you don’t need to use the ref attribute of the tasklet element. On the Java side, the ChunkOrientedTasklet class implements chunk processing.
Configuring a tasklet can be simple, but to implement chunk processing, the configuration gets more complex because more objects are involved.
Chunk-Oriented Tasklet
Spring Batch provides a tasklet class to process data in chunks: the ChunkOrientedTasklet. You typically use chunk-oriented tasklets for read-write processing. In chunk processing, Spring Batch reads data chunks from a source and transforms, validates, and then writes data chunks to a destination. In the online store case study, this corresponds to importing products into the database.
To configure chunk objects, you use an additional level of configuration using the chunk element with the attributes listed in table 3.5.
Table 3.5. Chunk attributes
|
Chunk attribute name |
Description |
|---|---|
| reader | Bean identifier used to read data from a chunk. The bean must implement the Spring Batch ItemReader interface. |
| processor | Bean identifier used to process data from a chunk. The bean must implement the Spring Batch ItemProcessor interface. |
| writer | Bean identifier used to write data from a chunk. The bean must implement the Spring Batch ItemWriter interface. |
| commit-interval | Number of items to process before issuing a commit. When the number of items read reaches the commit interval number, the entire corresponding chunk is written out through the item writer and the transaction is committed. |
| skip-limit | Maximum number of skips during processing of the step. If processing reaches the skip limit, the next exception thrown on item processing (read, process, or write) causes the step to fail. |
| skip-policy | Skip policy bean that implements the SkipPolicy interface. |
| retry-policy | Retry policy bean that implements the RetryPolicy interface. |
| retry-limit | Maximum number of retries. |
| cache-capacity | Cache capacity of the retry policy. |
| reader-transactional-queue | When reading an item from a JMS queue, whether reading is transactional. |
| processor-transactional | Whether the processor used includes transactional processing. |
| chunk-completion-policy | Completion policy bean for the chunk that implements the CompletionPolicy interface. |
The first four attributes (reader, processor, writer, commit-interval) in table 3.5 are the most commonly used in chunk configuration. These attributes define which entities are involved in processing chunks and the number of items to process before committing.
Listing 3.6. Using tasklet configuration attributes

The attributes reader, processor, and writer ![]() correspond to Spring bean identifiers defined in the configuration. For more information on these topics, see chapter 5 for configuring item readers; chapter 6 for configuring item writers; and chapter 7 for configuring item processors. The commit-interval attribute
correspond to Spring bean identifiers defined in the configuration. For more information on these topics, see chapter 5 for configuring item readers; chapter 6 for configuring item writers; and chapter 7 for configuring item processors. The commit-interval attribute ![]() defines that Spring Batch will execute a database commit after processing each 100 elements.
defines that Spring Batch will execute a database commit after processing each 100 elements.
Other attributes deal with configuring the skip limit, retry limit, and completion policy aspects of a chunk. The following listing shows how to use these attributes.
Listing 3.7. Configuring chunk retry, skip, and completion
<batch:job id="importProductsJob">
(...)
<batch:step id="readWrite">
<batch:tasklet>
<batch:chunk
(...)
skip-limit="20"
retry-limit="3"
cache-capacity="100"
chunk-completion-policy="timeoutCompletionPolicy"/>
</batch:tasklet>
</batch:step>
</batch:job>
<bean id="timeoutCompletionPolicy"
class="org.springframework.batch.repeat
.policy.TimeoutTerminationPolicy">
<constructor-arg value="60"/>
</bean>
In listing 3.7, the skip-limit attribute configures the maximum number of items that Spring Batch can skip. The retry-limit attribute sets the maximum number of retries. The cache-capacity attribute sets the cache capacity for retries, meaning the maximum number of items that can fail without being skipped or recovered. If the number is exceeded, an exception is thrown. The chunk-completion-policy attribute configures the completion policy to define a chunk-processing timeout.
We’ve described rather briefly how to configure skip, retry, and completion in steps. We look at this topic in more detail in chapter 8, where we aim for batch robustness and define error handlers.
The last attributes correspond to more advanced configurations regarding transactions. We describe these in section 3.2.5.
Most of the attributes described in table 3.5 have equivalent child elements to allow embedding beans in the chunk configuration. These beans are anonymous and specially defined for the chunk. Table 3.6 describes chunk children elements usable in this context.
Table 3.6. Chunk child elements
|
Description |
|
|---|---|
| reader | Corresponds to the reader attribute |
| processor | Corresponds to the processor attribute |
| writer | Corresponds to the writer attribute |
| skip-policy | Corresponds to the skip-policy attribute |
| retry-policy | Corresponds to the retry-policy attribute |
The following listing describes how to rewrite listing 3.6 using child elements instead of attributes for the reader, processor, and writer.
Listing 3.8. Using child elements in the tasklet configuration

You can configure other objects with child elements in chunks. Table 3.7 lists these additional elements.
Table 3.7. Additional chunk child elements
|
Chunk child element name |
Description |
|---|---|
| retry-listeners | See section 3.4.3. |
| skippable-exception-classes | A list of exceptions triggering skips. |
| retryable-exception-classes | A list of exceptions triggering retries. |
| streams | Each stream element involved in the step. By default, objects referenced using a reader, processor, and writer are automatically registered. You don’t need to specify them again here. |
The chunk element can configure which exceptions trigger skips and retries using, respectively, the elements skippable-exception-classes and retryable-exception-classes. The following listing shows these elements specifying which exceptions will trigger an event (include child element) and which ones won’t (exclude child element).
Listing 3.9. Configuring skippable exceptions
<batch:job id="importProductsJob">
(...)
<batch:step id="readWrite">
<batch:tasklet>
<batch:chunk commit-interval="100"
skip-limit="10">
<skippable-exception-classes>
<include class="org.springframework.batch
.item.file.FlatFileParseException"/>
<exclude class="java.io.FileNotFoundException"/>
</skippable-exception-classes>
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>
You can use the same mechanism for the retryable-exception-classes element as used for the skippable-exception-classes element to configure retries. The following fragment configures retries when DeadlockLoserDataAccessExceptions are caught:
<batch:chunk commit-interval="100" retry-limit="3">
<retryable-exception-classes>
<include
class="org.springframework.dao.DeadlockLoserDataAccessException"/>
</retryable-exception-classes>
</batch:chunk>
The last item in table 3.7 deals with streams. We provide a short description of the feature and show how to configure it. Chapter 8 provides more details on this topic. Streams provide the ability to save state between executions for step restarts. The step needs to know which instance is a stream (by implementing the ItemStream interface). Spring Batch automatically registers as streams everything specified in the reader, processor, and writer attributes. Note that it’s not the case when the step doesn’t directly reference entities. That’s why these entities must be explicitly registered as streams, as illustrated in figure 3.5.
Figure 3.5. Registration of entities as streams. Spring Batch automatically registers readers, processors, and writers if they implement the ItemStream interface. Explicit registration is necessary if Spring Batch doesn’t know about the streams to register, such as the writers in the figure used through a composite writer.

Let’s look at an example. If you use a composite item writer that isn’t a stream and that internally uses stream writers, the step doesn’t have references to those writers. In this case, you must define explicitly the writers as streams for the step in order to avoid problems on restarts when errors occur. The following listing describes how to configure this aspect using the streams child element of the chunk element.
Listing 3.10. Configuring streams in a chunk

In listing 3.10, you must register as streams ![]() the item writers
the item writers ![]() involved in the composite item writer for the step using the streams element as a child of the chunk element. The streams element then defines one or more stream elements—in this example, two stream elements
involved in the composite item writer for the step using the streams element as a child of the chunk element. The streams element then defines one or more stream elements—in this example, two stream elements ![]() .
.
In this section, we described how to configure a batch job with Spring Batch. We detailed the configuration of each related core object. We saw that transactions guarantee batch robustness and are involved at several levels in the configuration. Because this is an important issue, we gather all configuration aspects related to transactions in the next section.
3.2.5. Configuring transactions
Transactions in Spring Batch are an important topic: transactions contribute to the robustness of batch processes and work in combination with chunk processing. You configure transactions at different levels because transactions involve several types of objects. In the online store use case, you validate a set of products during processing.
The first thing to configure is the Spring transaction manager because Spring Batch is based on the Spring framework and uses Spring’s transaction support. Spring provides built-in transaction managers for common persistent technologies and frameworks. For JDBC, you use the DataSourceTransactionManager class as configured in the following snippet:
<bean id="transactionManager"> class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="batchDataSource"/> </bean>
Every Spring transaction manager must be configured using the factory provided by the framework to create connections and sessions. In the case of JDBC, the factory is an instance of the DataSource interface.
Once you configure the transaction manager, other configuration elements can refer to it from different levels in the batch configuration, such as from the tasklet level. The next snippet configures the transaction manager using the transaction-manager attribute:
<batch:job id="importProductsJob">
(...)
<batch:step id="readWrite">
<batch:tasklet transaction-manager="transactionManager" (...)>
(...)
</batch:tasklet>
</batch:step>
</batch:job>
Section 3.3 explains that you must also use a transaction manager to configure entities to interact with a persistent job repository.
Now that you know which Spring transaction manager to use, you can define how transactions are handled during processing. As described in chapter 1, section 1.4.1, Spring Batch uses chunk processing to handle items. That’s why Spring Batch provides a commit interval tied to the chunk size. The commit-interval attribute configures this setting at the chunk level and ensures that Spring Batch executes a commit after processing a given number of items. The following example sets the commit interval to 100 items:
The Spring framework provides generic transactional support. Spring bases this support on the PlatformTransactionManager interface that provides a contract to handle transaction demarcations: beginning and ending transactions with a commit or rollback. Spring provides implementations for a large range of persistent technologies and frameworks like JDBC, Java Persistence API (JPA), and so on. For JDBC, the implementing class is DataSourceTransactionManager, and for JPA it’s JpaTransactionManager.
Spring builds on this interface to implement standard transactional behavior and allows configuring transactions with Spring beans using AOP or annotations. This generic support doesn’t need to know which persistence technology is used and is completely independent of it.
![]()
Transactions have several attributes defining transactional behaviour, isolation, and timeout. These attributes specify how transactions behave and can affect performance. Because Spring Batch is based on Spring transactional support, configuring these attributes is generic and applies to all persistent technologies supported by the Spring framework. Spring Batch provides the transaction-attributes element in the tasklet element for this purpose, as described in following snippet:

Transactional attributes are configured using the transaction-attributes element ![]() and its attributes. The isolation attribute specifies the isolation level used for the database and what is visible from outside transactions. The READ_COMMITTED level prevents dirty reads (reading data written by a noncommitted transaction); READ_UNCOMMITTED specifies that dirty reads, nonrepeatable reads, and phantom reads can occur, meaning that all intermediate states of transactions
are visible for other transactions; REPEATABLE_READ prevents dirty reads and nonrepeatable reads, but phantom reads can still occur because intermediate data can disappear between
two reads; and SERIALIZABLE prevents dirty reads, nonrepeatable reads, and phantom reads, meaning that a transaction is completely isolated and no intermediate
states can be seen. Choosing the DEFAULT value leaves the choice of the isolation level to the database, which is a good choice in almost all cases.
and its attributes. The isolation attribute specifies the isolation level used for the database and what is visible from outside transactions. The READ_COMMITTED level prevents dirty reads (reading data written by a noncommitted transaction); READ_UNCOMMITTED specifies that dirty reads, nonrepeatable reads, and phantom reads can occur, meaning that all intermediate states of transactions
are visible for other transactions; REPEATABLE_READ prevents dirty reads and nonrepeatable reads, but phantom reads can still occur because intermediate data can disappear between
two reads; and SERIALIZABLE prevents dirty reads, nonrepeatable reads, and phantom reads, meaning that a transaction is completely isolated and no intermediate
states can be seen. Choosing the DEFAULT value leaves the choice of the isolation level to the database, which is a good choice in almost all cases.
The propagation attribute specifies the transactional behavior to use. Choosing REQUIRED implies that processing will use the current transaction if it exists and create a new one if it doesn’t. The Spring class TransactionDefinition declares all valid values for these two attributes. Finally, the timeout attribute defines the timeout in seconds for the transaction. If the timeout attribute is absent, the default timeout of the underlying system is used.
Java defines two types of exceptions: checked and unchecked. A checked exception extends the Exception class, and a method must explicitly handle it in a try-catch block or declare it in its signature’s throws clause. An unchecked exception extends the RuntimeException class, and a method doesn’t need to catch or declare it. You commonly see checked exceptions used as business exceptions (recoverable) and unchecked exceptions as lower-level exceptions (unrecoverable by the business logic).
By default, in Java EE and Spring, commit and rollback are automatically triggered by exceptions. If Spring catches a checked exception, a commit is executed. If Spring catches an unchecked exception, a rollback is executed. You can configure Spring’s transactional support to customize this behavior by setting which exceptions trigger commits and rollbacks.
The Spring framework follows the conventions outlined in the sidebar “Rollback and commit conventions in Spring and Java Enterprise Edition.” In addition, Spring Batch lets you configure specific exception classes that don’t trigger rollbacks when thrown. You configure this feature in a tasklet using the no-rollback-exception-classes element, as described in the following snippet:
<batch:tasklet>
(...)
<batch:no-rollback-exception-classes>
<batch:include
class="org.springframework.batch.item.validator.ValidationException"/>
</batch:no-rollback-exception-classes>
</batch:tasklet>
In this snippet, Spring issues a commit even if the unchecked Spring Batch exception ValidationException is thrown during batch processing.
Spring Batch also provides parameters for special cases. The first case is readers built on a transactional resource like a JMS queue. For JMS, a step doesn’t need to buffer data because JMS already provides this feature. For this type of resource, you need to specify the reader-transactional-queue attribute on the corresponding chunk, as shown in the following listing.
Listing 3.11. Configuring a transactional JMS item reader
<batch:tasklet>
<batch:chunk reader="productItemReader"
reader-transactional-queue="true" (...)/>
</batch:tasklet>
<bean id="productItemReader"
class="org.springframework.batch.item.jms.JmsItemReader">
<property name="itemType"
value="com.manning.sbia.reader.jms.ProductBean"/>
<property name="jmsTemplate" ref="jmsTemplate"/>
<property name="receiveTimeout" value="350"/>
</bean>
As described throughout this section, configuring batch processes can involve many concepts and objects. Spring Batch eases the configuration of core entities like job, step, tasklet, and chunk. Spring Batch also lets you configure transaction behavior and define your own error handling. The next section covers configuring the Spring Batch job repository to store batch execution data.
3.3. Configuring the job repository
Along with the batch feature, the job repository is a key feature of the Spring Batch infrastructure because it provides information about batch processing. Chapter 2, section 2.2, describes the job repository: it saves information about the details of job executions. In this section, we focus on configuring the job repository in Spring Batch XML. The job repository is part of the more general topic concerning batch process monitoring. Chapter 12 is dedicated to this topic.
3.3.1. Choosing a job repository
Spring Batch provides the JobRepository interface for the batch infrastructure and job repository to interact with each other. Chapter 2, section 2.2.1, shows this interface. The interface provides all the methods required to interact with the repository. We describe the job repository in detail in chapter 12.
For the JobRepository interface, Spring Batch provides only one implementation: the SimpleJobRepository class. Spring Batch bases this class on a set of Data Access Objects (DAOs) used for dedicated interactions and data management. Spring Batch provides two kinds of DAOs at this level:
- In-memory with no persistence
- Persistent with metadata using JDBC
You can use the in-memory DAO for tests, but you shouldn’t use it in production environments. In fact, batch data is lost between job executions. You should prefer the persistent DAO when you want to have robust batch processing with checks on startup. Because the persistent DAO uses a database, you need additional information in the job configuration. Database access configuration includes data source and transactional behavior.
3.3.2. Specifying job repository parameters
In this section, we configure the in-memory and persistent job repositories.
Configuring an In-Memory Job Repository
The first kind of job repository is the in-memory repository. Spring Batch provides the MapJobRepositoryFactoryBean class to make its configuration easier. The persistent repository uses a Spring bean for configuration and requires a transaction manager. Spring Batch provides the ResourcelessTransactionManager class as a NOOP (NO OPeration) implementation of the PlatformTransactionManager interface.
The following listing describes how to use the Spring Batch MapJobRepositoryFactoryBean and ResourcelessTransactionManager classes to configure an in-memory job repository.
Listing 3.12. Configuring an in-memory job repository
<bean id="jobRepository"
class="org.springframework.batch.core.repository
.support.MapJobRepositoryFactoryBean"
<property name="transactionManager-ref" ref="transactionManager"/>
</bean>
<bean id="transactionManager"
class="org.springframework.batch.support
.transaction.ResourcelessTransactionManager"/>
<batch:job id="importInvoicesJob"
job-repository="jobRepository">
(...)
</batch:job>
The in-memory job repository is first defined using the MapJobRepositoryFactory class provided by Spring Batch. The transactionManager-ref attribute is specified to reference a configured transaction manager. This particular transaction manager is a ResourcelessTransactionManager because the job repository is in-memory. Finally, the job repository is referenced from the job using the job-repository attribute of the job element. The value of this attribute is the identifier of the job repository bean.
Configuring a Persistent Job Repository
Configuring a persistent job repository isn’t too complicated, thanks to Spring Batch XML, which hides all the bean configuration details that would otherwise be required with Spring XML. Our configuration uses the job-repository element and specifies the attributes listed in table 3.8.
Table 3.8. job-repository attributes
|
Repository attribute name |
Description |
|---|---|
| data-source | Bean identifier for the repository data source used to access the database. This attribute is mandatory, and its default value is dataSource. |
| transaction-manager | Bean identifier for the Spring transaction manager used to handle transactions for the job repository. This attribute is mandatory, and its default value is transactionManager. |
| isolation-level-for-create | Isolation level used to create job executions. This attribute is mandatory, and its default value is SERIALIZABLE, which prevents accidental concurrent creation of the same job instance multiple times (REPEATABLE_READ would work as well). |
| max-varchar-length | Maximum length for VARCHAR columns in the database. |
| table-prefix | Table prefix used by the job repository in the database. This prefix allows identifying the tables used by the job repository from the tables used by the batch. The default value is BATCH_. |
| lob-handler | Handler for large object (LOB)-type columns. Use this attribute only with Oracle or if Spring Batch doesn’t detect the database type. This attribute is optional. |
The following listing shows how to use the job-repository element and its attributes to configure a persistent job repository for a relational database.
Listing 3.13. Configuring a persistent job repository

The configuration in listing 3.13 uses a data source named dataSource and the Apache DBCP library for connection pooling ![]() . The listing also configures a transaction manager named transactionManager as a Spring DataSourceTransactionManager
. The listing also configures a transaction manager named transactionManager as a Spring DataSourceTransactionManager ![]() , which uses JDBC for database access.
, which uses JDBC for database access.
The job-repository element can then configure the persistent job repository ![]() . This element references the data source and transaction manager previously configured. It also uses additional parameters
to force the use of the SERIALIZABLE isolation level when creating new job executions and to identify Spring Batch tables with the BATCH_ prefix. This job repository is then referenced from the job configuration
. This element references the data source and transaction manager previously configured. It also uses additional parameters
to force the use of the SERIALIZABLE isolation level when creating new job executions and to identify Spring Batch tables with the BATCH_ prefix. This job repository is then referenced from the job configuration ![]() .
.
What happens if you launch the same Spring Batch job from different physical nodes? There’s a small risk that you create the same job instance twice. This is bad for the batch metadata: Spring Batch would have a hard time restarting a failed execution of the instance—which instance should it choose? That’s where the job repository and the isolation-level-for-create attribute of the job-repository element come in. The job repository maintains batch metadata such as job instances and executions. When creating these entities, the job repository also acts as a centralized safeguard: it prevents the creation of identical job instances when jobs launch concurrently. The job repository relies on the transactional capabilities of the underlying database to achieve this synchronization. With an aggressive value for the isolation-level-for-create attribute—SERIALIZABLE is the default—you can avoid concurrency issues when creating entities like job instances. Thanks to this safeguard, you can distribute Spring Batch on multiple nodes and be sure not to start the same instance twice due to a race condition.
3.4. Advanced configuration topics
The job repository is an important part of the Spring Batch infrastructure because it records batch-processing information to track which jobs succeed and fail. Although Spring Batch provides an in-memory job repository, you should use it only for tests. Use the persistent job repository in production. In chapter 12, we monitor batch applications using the job repository. This section focuses on advanced Spring Batch configurations that leverage the Spring Expression Language (SpEL), modularize configurations with inheritance, and use listeners. Our goal is to simplify batch-processing configuration. Let’s begin with the Spring Batch step scope feature.
3.4.1. Using step scope
Spring Batch provides a special bean scope class—StepScope—implemented as a custom Spring bean scope. The goal of the step scope is to link beans with steps within batches. This mechanism allows instantiation of beans configured in Spring only when steps begin and allows you to specify configuration and parameters for a step.
If you use Spring Batch XML, the step scope is automatically registered for the current Spring container and is usable without additional configuration. If you don’t use Spring Batch XML, you must define the step scope with its StepScope class, as described in the following snippet:
Starting in version 2, Spring supports custom bean scopes. A bean scope specifies how to create instances of the class for a given bean definition. Spring provides scopes like singleton, prototype, request, and session but also allows custom scopes to be plugged in. You must register a custom scope in the container using the CustomScopeConfigurer Spring class.
A custom scope implementation handles how an instance is served in a given Spring container. For example, with the singleton scope, the same instance is always provided by Spring. With the prototype scope, Spring always creates a new instance.
The scope attribute of the bean element defines the bean scope; for example:
<bean id="myBean" class="(...)" scope="prototype">
<bean class="org.springframework.batch.core.scope.StepScope"/>
Developers using custom Spring scopes may be surprised by this configuration. In fact, the StepScope class implements the Spring BeanFactoryPostProcessor interface, which automatically applies the step scope to beans.
The step scope is particularly useful and convenient when combined with SpEL to implement late binding of properties. Let’s describe this feature next.
3.4.2. Leveraging SpEL
To configure Spring Batch entities, SpEL offers interesting possibilities. It handles cases when values can’t be known during development and configuration because they depend on the runtime execution context.
Spring version 3 introduced the Spring Expression Language to facilitate configuration. SpEL was created to provide a single language for use across the whole Spring portfolio, but it’s not directly tied to Spring and can be used independently. SpEL supports a large set of expression types, such as literal, class, property access, collection, assignment, and method invocation.
The power of this language is in its ability to use expressions to reference bean properties present in a particular context. You can view this feature as a more advanced and generic Spring PropertyPlaceholderConfigurer. SpEL can resolve expressions not only in a properties file but also in beans managed in Spring application contexts.
Spring Batch leverages SpEL to access entities associated with jobs and steps and to provide late binding in configurations. The typical use case of late binding is to use batch parameters specified at launch time in the batch configuration. The values are unknown at development time when configuring batch processes. Spring evaluates these values at runtime during the batch process execution.
Table 3.9 describes all entities available from the step scope.
Table 3.9. Entities available from the step scope
|
Entity name |
Description |
|---|---|
| jobParameters | Parameters specified for the job |
| jobExecutionContext | Execution context of the current job |
| stepExecutionContext | Execution context of the current step |
With this approach, it’s now possible to specify property values filled in at launch time, as shown in the following listing.
Listing 3.14. Configuring batch parameters with SpEL
<bean id="decompressTasklet"
class="com.manning.sbia.ch01.batch.DecompressTasklet"
scope="step">
<property name="inputResource"
value="#{jobParameters['inputResource']}" />
<property name="targetDirectory"
value="#{jobParameters['targetDirectory']}" />
<property name="targetFile"
value="#{jobParameters['targetFile']}" />
</bean>
You configure the decompressTasklet bean using the Spring Batch step scope. Specifying this scope allows you to use SpEL’s late binding feature for job parameters within values of bean properties. The jobParameters object acts as a map for a set of parameters and elements and is accessed using notation delimited by #{ and }. You also use this format in the example with the objects jobExecutionContext and stepExecutionContext.
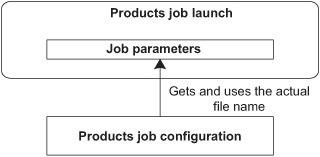
In the context of the case study, this mechanism makes it possible to specify at batch startup the file to use to import product data. You don’t need to hardcode the filename in the batch configuration, as illustrated in figure 3.6.
Figure 3.6. Using the filename to import from the job configuration
3.4.3. Using listeners to provide additional processing
Spring Batch provides the ability to specify and use listeners at the job and step levels within batches. This feature is particularly useful and powerful because Spring Batch can notify each level of batch processing, where you can plug in additional processing. For example, in the online store case study, you can add a listener that Spring Batch calls when a batch fails, or you can use a listener to record which products Spring Batch skips because of errors, as shown in figure 3.7.
Figure 3.7. Notifications of lifecycle events and errors during job execution

We provide concrete examples of this feature in chapter 8. Table 3.10 describes the listener types provided by Spring Batch.
Table 3.10. Listener types
|
Listener type |
Description |
|---|---|
| Job listener | Listens to processing at the job level |
| Step listeners | Listens to processing at the step level |
| Item listeners | Listens to item repeat or retry |
Job Listeners
The job listener intercepts job execution and supports the before and after job execution events. These events add processing before a job and after a job according to the completion type of a batch process. They’re particularly useful to notify external systems of batch failures. Such listeners are implementations of the JobExecutionListener interface:
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}
You configure a listener in a job configuration with the listeners element as a child of the job element. The listeners element can configure several listeners by referencing Spring beans. The following snippet describes how to register the ImportProductsJobListener class as a listener for the importProductsJob job:
<batch:job id="importProductsJob">
<batch:listeners>
<batch:listener ref="importProductsJobListener"/>
</batch:listeners>
</batch:job>
<bean id="importProductsJobListener" class="ImportProductsJobListener"/>
The ImportProductsJobListener class receives notifications when Spring Batch starts and stops a job regardless of whether the job succeeds or fails. A JobExecution instance provides information regarding job execution status with BatchStatus constants. The following listing shows the ImportProductsJobListener class.
Listing 3.15. Listening to job execution with a listener
public class ImportProductsJobListener
implements JobExecutionListener {
public void beforeJob(JobExecution jobExecution) {
// Called when job starts
}
public void afterJob(JobExecution jobExecution) {
if (jobExecution.getStatus()==BatchStatus.COMPLETED) {
// Called when job ends successfully
} else if (jobExecution.getStatus()==BatchStatus.FAILED) {
// Called when job ends in failure
}
}
}
The listener class must implement the JobExecutionListener interface and define the beforeJob method that Spring Batch calls before the job starts and the afterJob method called after the job ends.
Spring Batch can also use annotated classes as listeners. In this case, you don’t implement the JobExecutionListener interface. To specify which methods do the listening, you use the BeforeJob and AfterJob annotations. The following listing shows the annotated class (AnnotatedImportProductsJobListener) corresponding to the standard listener class (ImportProductsJobListener).
Listing 3.16. Listening to job execution with annotations
public class AnnotatedImportProductsJobListener {
@BeforeJob
public void executeBeforeJob(JobExecution jobExecution) {
//Notifying when job starts
}
@AfterJob
public void executeAfterJob(JobExecution jobExecution) {
if (jobExecution.getStatus()==BatchStatus.COMPLETED) {
//Notifying when job successfully ends
} else if (jobExecution.getStatus()==BatchStatus.FAILED) {
//Notifying when job ends with failure
}
}
}
This listener class is a plain old Java object (POJO) and defines which methods to execute before the job starts with the BeforeJob annotation and after the job ends with the AfterJob annotation.
Step Listeners
Steps also have a matching set of listeners to track processing during step execution. You use step listeners to track item processing and to define error-handling logic. All step listeners extend the StepListener marker interface. StepListener acts as a parent to all step domain listeners. Table 3.11 describes the step listeners provided by Spring Batch.
Table 3.11. Step listeners provided by Spring Batch
|
Listener interface |
Description |
|---|---|
| ChunkListener | Called before and after chunk execution |
| ItemProcessListener | Called before and after an ItemProcessor gets an item and when that processor throws an exception |
| ItemReadListener | Called before and after an item is read and when an exception occurs reading an item |
| ItemWriteListener | Called before and after an item is written and when an exception occurs writing an item |
| SkipListener | Called when a skip occurs while reading, processing, or writing an item |
| StepExecutionListener | Called before and after a step |
The StepExecutionListener and ChunkListener interfaces relate to lifecycle. They’re respectively associated to the step and chunk and provide methods for before and after events. The StepExecutionListener interface uses a StepExecution parameter for each listener method to access current step execution data. The afterStep method triggered after step completion must return the status of the current step with an ExistStatus instance. The following snippet describes the StepExecutionListener interface:
public interface StepExecutionListener extends StepListener {
void beforeStep(StepExecution stepExecution);
ExitStatus afterStep(StepExecution stepExecution);
}
The ChunkListener interface provides methods called before and after the current chunk. These methods have no parameter and return void, as described in the following snippet:
public interface ChunkListener extends StepListener {
void beforeChunk();
void afterChunk();
}
The item listener interfaces (read, process, and write) listed in table 3.11 each deal with a single item and support Java 5 generics to specify item types. Each interface provides three methods triggered before, after, and on error. Each interface accepts as a parameter a single item from a list of handled entities for before and after methods. For error-handling methods, Spring Batch passes the thrown exception as a parameter.
For item processing, these methods are beforeProcess, afterProcess, and onProcessError. The following snippet lists the ItemProcessListener interface:
public interface ItemProcessListener<T, S> extends StepListener {
void beforeProcess(T item);
void afterProcess(T item, S result);
void onProcessError(T item, Exception e);
}
For the ItemReadListener interface, these methods are beforeRead, afterRead, and onReadError, as shown in the following snippet:
public interface ItemReadListener<T> extends StepListener {
void beforeRead();
void afterRead(T item);
void onReadError(Exception ex);
}
For the ItemWriteListener interface, these methods are beforeWrite, afterWrite, and onWriteError, as shown in the following snippet:
public interface ItemWriteListener<S> extends StepListener {
void beforeWrite(List<? extends S> items);
void afterWrite(List<? extends S> items);
void onWriteError(Exception exception, List<? extends S> items);
}
The last kind of interface in table 3.11 listens for skip events. Spring Batch calls the SkipListener interface when processing skips an item. The interface provides three methods corresponding to when the skip occurs: onSkipInRead during reading, onSkipInProcess during processing, and onSkipInWrite during writing. The following snippet lists the SkipListener interface:
public interface SkipListener<T,S> extends StepListener {
void onSkipInRead(Throwable t);
void onSkipInProcess(T item, Throwable t);
void onSkipInWrite(S item, Throwable t);
}
You can also define listeners for all these events as annotated POJOs. Spring Batch leaves the choice up to you. Spring Batch provides annotations corresponding to each method defined by the interfaces in table 3.11. For example, for the ExecutionListener interface, the BeforeStep annotation corresponds to the beforeStep method and the AfterStep annotation to the afterStep method. Configuring listeners using annotations follows the same rules as the interfacebased configurations described in the next section. The following listing shows how to implement an annotation-based listener for step execution.
Listing 3.17. Implementing an annotation-based step listener
public class ImportProductsExecutionListener {
@BeforeStep
public void handlingBeforeStep(StepExecution stepExecution) {
(...)
}
@AfterStep
public ExitStatus afterStep(StepExecution stepExecution) {
(...)
return ExitStatus.FINISHED;
}
}
As is done for a job, configuring a step listener is done using a listeners element as a child of the tasklet element. You can configure all kinds of step listeners at this level in the same manner. For example:
<batch:job id="importProductsJob">
<batch:step id="decompress" next="readWrite">
<batch:tasklet ref="decompressTasklet">
<batch:listeners>
<batch:listener ref="stepListener"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
</ batch:job>
Note that you can also specify several listeners at the same time.
Repeat and Retry Listeners
Another type of listener provided by Spring Batch deals with robustness and provides notification when repeats and retries occur. These listeners support the methods listed in table 3.12 and allow processing during repeat or retry.
Table 3.12. Methods for retry and repeat listeners
|
Method |
Description |
|---|---|
| after (repeat listener only) | Called after each try or repeat |
| before (repeat listener only) | Called before each try or repeat |
| close | Called after the last try or repeat on an item, whether successful or not in the case of a retry |
| onError | Called after every unsuccessful attempt at a retry or every repeat failure with a thrown exception |
| open | Called before the first try or repeat on an item |
The following snippet lists the RepeatListener interface called when repeating an item:
public interface RepeatListener {
void before(RepeatContext context);
void after(RepeatContext context, RepeatStatus result);
void open(RepeatContext context);
void onError(RepeatContext context, Throwable e);
void close(RepeatContext context);
}
The following snippet lists the content of the RetryListener interface called when retrying an item:
public interface RetryListener {
<T> void open(RetryContext context, RetryCallback<T> callback);
<T> void onError(RetryContext context,
RetryCallback<T> callback, Throwable e);
<T> void close(RetryContext context,
RetryCallback<T> callback, Throwable e);
}
Such listeners must be configured like step listeners using the listeners child element of the tasklet element, as described at the end of the previous section.
The next and last feature in our advanced configuration discussion is the Spring Batch inheritance feature used to modularize entity configurations.
3.4.4. Configuration inheritance
As emphasized in section 3.2.2, Spring Batch XML provides facilities to ease configuration of batch jobs. While this XML vocabulary improves Spring Batch configuration, duplication can remain, and that’s why the vocabulary supports configuration inheritance like Spring XML.
This feature is particularly useful when configuring similar jobs and steps. Rather than duplicating XML fragments, Spring Batch allows you to define abstract entities to modularize configuration data. In the online store case study, you define several jobs with their own steps. As a best practice, you want to apply default values of the batch processes. To implement this, you define abstract jobs and steps. The default configuration parameters then apply to all child jobs and steps. Modifying one parameter affects all children automatically, as shown in figure 3.8.
Figure 3.8. Using configuration inheritance lets jobs inherit from an abstract job and steps inherit from an abstract step.

Configuration inheritance is a built-in feature of the default Spring XML vocabulary since version 2.0. Its aim is to allow modularizing configuration and to prevent configuration duplication. It targets the same issue that Spring XML addresses: making configuration less complex.
Spring allows defining abstract bean definitions that don’t correspond to instances. Such bean definitions are useful to modularize common bean properties and avoid duplication in Spring configurations. Spring provides the abstract and parent attributes on the bean element. A bean with the attribute abstract set to true defines a virtual bean, and using the parent attribute allows linking two beans in a parent-child relationship.
Inheriting from a parent bean means the child bean can use all attributes and properties from the parent bean. You can also use overriding from a child bean.
The following fragment describes how to use the abstract and parent attributes:
<bean id="parentBean" abstract="true"> <property name="propertyOne" value="(...)"/> </bean> <bean id="childBean" parent="parentBean"> <property name="propertyOne" value="(...)"/> <property name="propertyTwo" value="(...)"/> </bean>
You can use Spring Batch configuration inheritance at both the job and step levels. Spring Batch also supports configuration merging. Table 3.13 describes the abstract and parent configuration inheritance attributes.
Table 3.13. Configuration inheritance attributes
|
Attribute |
Description |
|---|---|
| abstract | When true, specifies that the job or step element isn’t a concrete element but an abstract one used only for configuration. Abstract configuration entities aren’t instantiated. |
| parent | The parent element used to configure a given element. The child element has all properties of its parent and can override them. |
As we’ve seen, configuration inheritance in Spring Batch is inspired by Spring and is based on the abstract and parent attributes. Configuration inheritance allows you to define abstract batch entities that aren’t instantiated but are present in the configuration only to modularize other configuration elements.
Let’s look at an example that uses steps. A common use case is to define a parent step that modularizes common and default step parameters. The following listing shows how to use configuration inheritance to configure step elements.
Listing 3.18. Using configuration inheritance for steps
<step id="parentStep">
<tasklet allow-start-if-complete="true">
<chunk commit-interval="100"/>
</tasklet>
</step>
<step id="productStep" parent="parentStep">
<tasklet start-limit="5">
<chunk reader="productItemReader"
writer="productItemWriter"
processor="productItemProcessor"
commit-interval="15"/>
</tasklet>
</step>
The parent step named parentStep includes a tasklet element, which also includes a chunk element. Each element includes several attributes for its configuration, allow-start-if-complete for tasklet and commit-interval for chunk. You name the second step productStep and reference the previous step as its parent. The productStep step has the same element hierarchy as its parent, which includes all elements and attributes. In some cases, a parent defines attributes but children don’t, so Spring Batch adds the attributes to the child configurations. In other cases, attributes are present in both parent and child steps, and the values of child elements override the values of parent elements.
An interesting feature of Spring Batch related to configuration inheritance is the ability to merge lists. By default, Spring Batch doesn’t enable this feature; lists in the child element override lists in the parent element. You can change this behavior by setting the merge attribute to true. The following listing combines the list of listeners present in a parent job with the list in the child job.
Listing 3.19. Merging two lists with configuration inheritance

We specify the merge attribute ![]() for the listeners element in the configuration of the child job. In this case, Spring Batch merges the listeners of the parent and child jobs,
and the resulting list contains listeners named globalListener and specificListener.
for the listeners element in the configuration of the child job. In this case, Spring Batch merges the listeners of the parent and child jobs,
and the resulting list contains listeners named globalListener and specificListener.
With configuration inheritance in Spring Batch, we close our advanced configuration section. These features allow easier and more concise configurations of Spring Batch jobs.
3.5. Summary
Spring Batch provides facilities to ease configuration of batch processes. These facilities are based on Spring Batch XML—an XML vocabulary dedicated to the batch domain—which leverages Spring XML. This vocabulary can configure all batch entities described in chapter 2, such as jobs, tasklets, and chunks. Spring Batch supports entity hierarchies in its XML configuration and closely interacts with Spring XML to use Spring beans.
XML configuration of batch processes is built in and allows plug-in strategies to handle errors and transactions. All these features contribute to making batches more robust by providing support for commit intervals, skip handling, and retry, among other tasks. We focus on batch robustness in chapter 8.
Spring Batch provides support to configure access to the job repository used to store job execution data. This feature relates to the more general topic of batch monitoring, and chapter 12 addresses it in detail.
Spring Batch XML also includes advanced features that make configuration flexible and convenient. Features include the step scope and the ability to interact with the batch execution context using SpEL late binding of parameter values at runtime. You can implement job, step, and chunk listeners with interfaces or by using annotations on POJOs. Finally, we saw that Spring Batch provides modularization at the configuration level with the ability to use inheritance to eliminate configuration duplication.
Chapter 4 focuses on execution and describes the different ways to launch batch processes in real systems.