
Chapter 8. Implementing bulletproof jobs
- Handling errors with retry and skip
- Logging errors with listeners
- Restarting an execution after a failure
Batch jobs manipulate large amounts of data automatically. Previous chapters showed how Spring Batch helps to read, process, and write data efficiently and without much Java code, thanks to ready-to-use I/O components. It’s time to deal with the automatic aspect of batch jobs. Batch jobs operate over long periods, at night, for example, and without human intervention. Even if a batch job can send an email to an operator when something’s wrong, it’s on its own most of the time. A batch job isn’t automatic if it fails each time something goes wrong; it needs to be able to handle errors correctly and not crash abruptly. Perhaps you know how frustrating it is to sit at your desk in the morning and see that some nightly jobs have crashed because of a missing comma in an input file.
This chapter explains techniques to make your batch jobs more robust and reliable when errors occur during processing. By the end of this chapter, you’ll know how to build bulletproof batch jobs and be confident that your batch jobs will succeed.
The first section of this chapter explains how a batch job should behave when errors or edge cases emerge during processing. Spring Batch has built-in support, its skip and retry features, to handle errors when a job is executing. Skip and retry are about avoiding crashes, but crashes are inevitable, so Spring Batch also supports restarting a job after a failed execution. Sections 8.2, 8.3, and 8.4 cover skip, retry, and restart, respectively.
By following the guidelines and the techniques in this chapter, you’ll go from “my job failed miserably because of a missing comma” to “bring in your fancy-formatted input file—nothing scares my job anymore.” Let’s get bulletproof!
8.1. What is a bulletproof job?
A bulletproof job is able to handle errors gracefully; it won’t fail miserably because of a minor error like a missing comma. It won’t fail abruptly, either, for a major problem like a constraint violation in the database. Before reviewing some guidelines on the design of a robust job, let’s consider some requirements that a job must meet.
8.1.1. What makes a job bulletproof?
A bulletproof batch job should meet the following general requirements:
- Robust —The job should fail only for fatal exceptions and should recover gracefully from any nonfatal exception. As software developers, we can’t do anything about a power cut, but we can properly handle incorrectly formatted lines or a missing input file.
- Traceable —The job should record any abnormal behavior. A job can skip as many incorrectly formatted lines as it wants, but it should log to record what didn’t make it in the database and allow someone to do something about it.
- Restartable —In case of an abrupt failure, the job should be able to restart properly. Depending on the use case, the job could restart exactly where it left off or even forbid a restart because it would process the same data again.
Good news: Spring Batch provides all the features to meet these requirements! You can activate these features through configuration or by plugging in your own code through extension points (to log errors, for example). A tool like Spring Batch isn’t enough to write a bulletproof job: you also need to design the job properly before leveraging the tool.
8.1.2. Designing a bulletproof job
To make your batch jobs bulletproof, you first need to think about failure scenarios. What can go wrong in this batch job? Anything can happen, but the nature of the operations in a job helps to narrow the failure scenarios. The batch job we introduced in chapter 1 starts by decompressing a ZIP archive to a working directory before reading the lines of the extracted file and inserting them in the database. Many things can go wrong: the archive can be corrupt (if it’s there!), the OS might not allow the process to write in the working directory, some lines in the files may be incorrectly formatted, and the list goes on.
Remember that Spring Batch is a lightweight framework. It means you can easily test failure scenarios in integration tests. You can simulate many failure scenarios thanks to testing techniques like mock objects, for example. Chapter 14 covers how to test batch applications. For JUnit testing techniques in general, you can also refer to JUnit in Action by Peter Tahchiev, Filipe Leme, Vincent Massol, and Gary Gregory (Manning Publications, 2011).
Once you’ve identified failure scenarios, you must think about how to deal with them. If there’s no ZIP archive at the beginning of the execution, there’s not much the job can do, but that’s no reason to fail abruptly. How should the job handle incorrectly formatted lines? Should it skip them or fail the whole execution as soon as it finds a bad line? In our case, we could skip incorrect lines and ensure that we log them somewhere.
Spring Batch has built-in support for error handling, but that doesn’t mean you can make batch jobs bulletproof by setting some magical attribute in an XML configuration file (even if sometimes that’s the case). Rather, it means that Spring Batch provides infrastructure and deals with tedious plumbing, but you must always know what you’re doing: when and why to use Spring Batch error handling. That’s what makes batch programming interesting! Let’s now see how to deal with errors in Spring Batch.
8.1.3. Techniques for bulletproofing jobs
Unless you control your batch jobs as Neo controls the Matrix, you’ll always end up getting errors in your batch applications. Spring Batch includes three features to deal with errors: skip, retry, and restart. Table 8.1 describes these features.
Table 8.1. Error-handling support in Spring Batch
|
Feature |
When? |
What? |
Where? |
|---|---|---|---|
| Skip | For nonfatal exceptions | Keeps processing for an incorrect item | Chunk-oriented step |
| Retry | For transient exceptions | Makes new attempts on an operation for a transient failure | Chunk-oriented step, application code |
| Restart | After an execution failure | Restarts a job instance where the last execution failed | On job launch |
The features listed in table 8.1 are independent from each other: you can use one without the others, or you can combine them. Remember that skip and retry are about avoiding a crash on an error, whereas restart is useful, when a job has crashed, to restart it where it left off.
Skipping allows for moving processing along to the next line in an input file if the current line is in an incorrect format. If the job doesn’t process a line, perhaps you can live without it and the job can process the remaining lines in the file.
Retry attempts an operation several times: the operation can fail at first, but another attempt can succeed. Retry isn’t useful for errors like badly formatted input lines; it’s useful for transient errors, such as concurrency errors. Skip and retry contribute to making job executions more robust because they deal with error handling during processing.
Restart is useful after a failure, when the execution of a job crashes. Instead of starting the job from scratch, Spring Batch allows for restarting it exactly where the failed execution left off. Restarting can avoid potential corruption of the data in case of reprocessing. Restarting can also save a lot of time if the failed execution was close to the end.
Before covering each feature, let’s see how skip, retry, and restart can apply to our import products job.
8.1.4. Skip, retry, and restart in action
Recall our import products job: the core of the job reads a flat file containing one product description per line and updates the online store database accordingly. Here is how skip, retry, and restart could apply to this job.
- Skip —A line in the flat file is incorrectly formatted. You don’t want to stop the job execution because of a couple of bad lines: this could mean losing an unknown amount of updates and inserts. You can tell Spring Batch to skip the line that caused the item reader to throw an exception on a formatting error.
- Retry —Because some products are already in the database, the flat file data is used to update the products (description, price, and so on). Even if the job runs during periods of low activity in the online store, users sometimes access the updated products, causing the database to lock the corresponding rows. The database throws a concurrency exception when the job tries to update a product in a locked row, but retrying the update again a few milliseconds later works. You can configure Spring Batch to retry automatically.
- Restart —If Spring Batch has to skip more than 10 products because of badly formatted lines, the input file is considered invalid and should go through a validation phase. The job fails as soon as you reach 10 skipped products, as defined in the configuration. An operator will analyze the input file and correct it before restarting the import. Spring Batch can restart the job on the line that caused the failed execution. The work performed by the previous execution isn’t lost.
The import products job is robust and reliable thanks to Spring Batch. Let’s study the roles of skip, retry, and restart individually.
8.2. Skipping instead of failing
Sometimes errors aren’t fatal: a job execution shouldn’t stop when something goes wrong. In the online store application, when importing products from a flat file, should you stop the job execution because one line is in an incorrect format? You could stop the whole execution, but the job wouldn’t insert the subsequent lines from the file, which means fewer products in the catalog and less money coming in! A better solution is to skip the incorrectly formatted line and move on to the next line.
Whether or not to skip items in a chunk-oriented step is a business decision. The good news is that Spring Batch makes the decision of skipping a matter of configuration; it has no impact on the application code. Let’s see how to tell Spring Batch to skip items and then how to tune the skip policy.
8.2.1. Configuring exceptions to be skipped
Recall that the import products job reads products from a flat file and then inserts them into the database. It would be a shame to stop the whole execution for a couple of incorrect lines in a file containing thousands or even tens of thousands of lines. You can tell Spring Batch to skip incorrect lines by specifying which exceptions it should ignore. To do this, you use the skippable-exception-classes element, as shown in the following listing.
Listing 8.1. Configuring exceptions to skip in a chunk-oriented step

In the skippable-exception-classes element, you specify the exceptions to skip with the include element. You can specify several exception classes (with several include elements). When using the include element, you specify not only one class of exception to skip but also all the subclasses of the exception. Listing 8.1 configures Spring Batch to skip a FlatFileParseException and all its subclasses.
Note also in listing 8.1 the use of the skip-limit attribute, which sets the maximum number of items to skip in the step before failing the execution. Skipping is useful, but skipping too many items can signify that the input file is corrupt. As soon as Spring Batch exceeds the skip limit, it stops processing and fails the execution. When you declare an exception to skip, you must specify a skip limit.
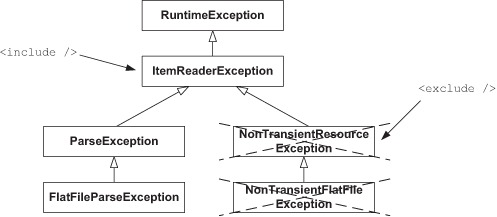
The include element skips a whole exception hierarchy, but what if you don’t want to skip all the subclasses of the specified exception? In this case, you use the exclude element. The following snippet shows how to skip ItemReaderExceptions but excludes NonTransientResourceException:
<skippable-exception-classes>
<include
class="org.springframework.batch.item.ItemReaderException"/>
<exclude
class="org.springframework.batch.item.NonTransientResourceException"/>
</skippable-exception-classes>
Figure 8.1 shows the relationship between ItemReaderException and NonTransientResourceException. With the settings from the previous snippet, a FlatFileParseException triggers a skip, whereas a NonTransientFlatFileException doesn’t. Expressing this requirement in English, we would say that we want to skip any error due to bad formatting in the input file (ParseException) and that we don’t want to skip errors due to I/O problems (NonTransientResourceException).
Figure 8.1. The include element specifies an exception class and all its subclasses. If you want to exclude part of the hierarchy, use the exclude element. The exclude element also works transitively, as it excludes a class and its subclasses.
Specifying exceptions to skip and a skip limit is straightforward and fits most cases. Can you avoid using a skip limit and import as many items as possible? Yes. When importing products in the online store, you could process the entire input file, no matter how many lines are incorrect and skipped. As you log these skipped lines, you can correct them and import them the next day. Spring Batch gives you full control over the skip behavior by specifying a skip policy.
8.2.2. Configuring a SkipPolicy for complete control
Who decides if an item should be skipped or not in a chunk-oriented step? Spring Batch calls the skip policy when an item reader, processor, or writer throws an exception, as figure 8.2 shows. When using the skippable-exception-classes element, Spring Batch uses a default skip policy implementation (LimitCheckingItemSkipPolicy), but you can declare your own skip policy as a Spring bean and plug it into your step. This gives you more control if the skippable-exception-classes and skip-limit pair isn’t enough.
Figure 8.2. When skip is on, Spring Batch asks a skip policy whether it should skip an exception thrown by an item reader, processor, or writer. The skip policy’s decision can depend on the type of the exception and on the number of skipped items so far in the step.

Note
The skip-limit attribute and the skippable-exception-classes tag have no effect as soon as you plug your own skip policy into a step.
Let’s say you know exactly on which exceptions you want to skip items, but you don’t care about the number of skipped items. You can implement your own skip policy, as shown in the following listing.
Listing 8.2. Implementing a skip policy with no skip limit

Once you implement your own skip policy and you declare it as a Spring bean, you can plug it into a step by using the skip-policy attribute, as shown in the following listing.
Listing 8.3. Plugging in a skip policy in a chunk-oriented step

Table 8.2 lists the skip policy implementations Spring Batch provides. Don’t hesitate to look them up before implementing your own.
Table 8.2. Skip policy implementations provided by Spring Batch
|
Skip policy class[*] |
Description |
|---|---|
| LimitCheckingItemSkipPolicy | Skips items depending on the exception thrown and the total number of skipped items; this is the default implementation |
| ExceptionClassifierSkipPolicy | Delegates skip decision to other skip policies depending on the exception thrown |
| AlwaysSkipItemSkipPolicy | Always skips, no matter the exception or the total number of skipped items |
| NeverSkipItemSkipPolicy | Never skips |
* From the org.springframework.batch.core.step.skip package.
When it comes to skipping, you can stick to the skippable-exception-classes and skip-limit pair, which have convenient behavior and are easy to configure, with dedicated XML elements. You typically use the default skip policy if you care about the total number of skipped items and you don’t want to exceed a given limit. If you don’t care about the number of skipped items, you can implement your own skip policy and easily plug it into a chunk-oriented step.
We focused on skipping items during the reading phase, but the skip configuration also applies to the processing and writing phases of a chunk-oriented step. Spring Batch doesn’t drive a chunk-oriented step the same way when a skippable exception is thrown in the reading, processing, or writing phase.
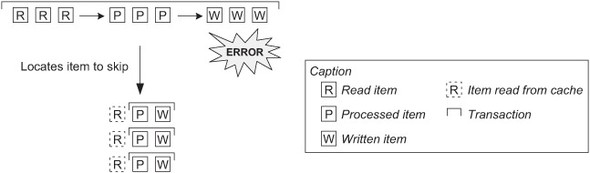
When an item reader throws a skippable exception, Spring Batch just calls the read method again on the item reader to get the next item. There’s no rollback on the transaction. When an item processor throws a skippable exception, Spring Batch rolls back the transaction of the current chunk and resubmits the read items to the item processor, except for the one that triggered the skippable exception in the previous run. Figure 8.3 shows what Spring Batch does when the item writer throws a skippable exception. Because the framework doesn’t know which item threw the exception, it reprocesses each item in the chunk one by one, in its own transaction.
Figure 8.3. When a writer throws a skippable exception, Spring Batch can’t know which item triggered the exception. Spring Batch then rolls back the transaction and processes the chunk item by item. Note that Spring Batch doesn’t read the items again, by default, because it maintains a chunk-scoped cache.
Skipping incorrect items makes a job more robust, but you might want to keep track of these items. Let’s see how Spring Batch lets you do that with a skip listener.
8.2.3. Listening and logging skipped items
Okay, your job doesn’t fail miserably anymore because of a single incorrect line in your 500-megabyte input file, fine—but how do you easily spot these incorrect lines? One solution is to log each skipped item with the skip callbacks provided by Spring Batch. Once you have the skipped items in a file or in a database, you can deal with them: correct the input file, do some manual processing to deal with the error, and so on. The point is to have a record of what went wrong!
Spring Batch provides the SkipListener interface to listen to skipped items:
public interface SkipListener<T,S> extends StepListener {
void onSkipInRead(Throwable t);
void onSkipInProcess(T item, Throwable t);
void onSkipInWrite(S item, Throwable t);
}
You can implement a skip listener and plug it into a step, as figure 8.4 shows. Spring Batch calls the appropriate method on the listener when it skips an item. To implement a skip listener, you can directly implement the SkipListener interface, but this implies implementing three methods, even if you expect skipped items only during the reading phase. To avoid implementing empty methods, you can inherit from the SkipListenerSupport adapter class, which provides no-op implementations: you override only the method you need.
Figure 8.4. Spring Batch lets you register skip listeners. Whenever a chunk-oriented step throws a skippable exception, Spring Batch calls the listener accordingly. A listener can then log the skipped item for later processing.

There’s one more solution: using annotations on a simple class (no interface, no abstract class). Spring Batch provides one annotation for each method of the SkipListener interface: @OnSkipInRead, @OnSkipInProcess, and @OnSkipInWrite.
Next, you use the annotation solution with @OnSkipInRead to skip items during the reading phase. The following listing shows the skip listener, which logs the incorrect line to a database.
Listing 8.4. Logging skipped items with a skip listener

The skip listener logs the incorrect line in the database, but it could use any other logging system, a logging framework like Java’s own java.util.logging, Apache Log4J, or SLF4J, for example.
Once you implement the skip listener, you need to register it. The following listing shows how to register the skip listener on a step, using the listeners element in the tasklet element.
Listing 8.5. Registering a skip listener

A couple of details are worth mentioning in the skip listener configuration:
- You can have several skip listeners. Only one skip listener was registered in the example, but you can have as many as you want.
- Spring Batch is smart enough to figure out the listener type. The example used the generic listener element to register the skip listener. Spring Batch detects that it is a skip listener (Spring Batch provides many different kinds of listeners).
When does Spring Batch call a skip listener method? Just after the item reader, processor, or writer throws the to-be-skipped exception, you may think. But no, not just after. Spring Batch postpones the call to skip listeners until right before committing the transaction for the chunk. Why is that? Because something wrong can happen after Spring Batch skips an item, and Spring Batch could then roll back the transaction. Imagine that the item reader throws a to-be-skipped exception. Later on, something goes wrong during the writing phase of the same chunk, and Spring Batch rolls back the transaction and could even fail the job execution. You wouldn’t want to log the skipped item during the reading phase, because Spring Batch rolled back the whole chunk! That’s why Spring Batch calls skip listeners just before the commit of the chunk, when it’s almost certain nothing unexpected could happen.
We’re done with skipping, a feature Spring Batch provides to make jobs more robust when errors aren’t fatal. Do you want your jobs to be even more robust? Perhaps skipping an item immediately is too pessimistic—what about making additional attempts before skipping? This is what we call retry, and Spring Batch offers first-class support for this feature.
8.3. Retrying on error
By default, an exception in a chunk-oriented step causes the step to fail. You can skip the exception if you don’t want to fail the whole step. Skipping works well for deterministic exceptions, such as an incorrect line in a flat file. Exceptions aren’t always deterministic; sometimes they can be transient. An exception is transient when an operation fails at first, but a new attempt—even immediately after the failure—is successful.
Have you ever used your cell phone in a place where the connection would arguably be bad? In a tunnel, for example, or on a ferry, sailing on the Baltic Sea on a Friday night while watching a Finnish clown show?[1] You start speaking on the cell phone, but the line drops out. Do you give up and start watching the clown show, or do you try to dial the number again? Maybe the connection will be better on the second attempt or in a couple of minutes. Transient errors happen all the time in the real world when using the phone or online conference tools like Skype. You usually retry several times after a failure before giving up and trying later if the call doesn’t go through.
1 It happened while one of the authors was working on this book!
What are transient exceptions in batch applications? Concurrency exceptions are a typical example. If a batch job tries to update a row that another process holds a lock on, the database can cause an error. Retrying the operation immediately can be successful, because the other process may have released the lock in the meantime. Any operation involving an unreliable network—like a web service call—can also throw transient exceptions, so a new attempt, with a new request (or connection), may succeed.
You can configure Spring Batch to retry operations transparently when they throw exceptions, without any impact on the application code. Because transient failures cause these exceptions, we call them retryable exceptions.
8.3.1. Configuring retryable exceptions
You configure retryable exceptions inside the chunk element, using the retryable-exception-classes element, as shown in the following listing.
Listing 8.6. Configuring retryable exceptions

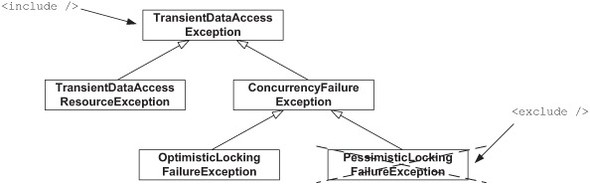
Notice the retry-limit attribute, used to specify how many times Spring Batch should retry an operation. Just as for skipping, you can include a complete exception hierarchy with the include element and exclude some specific exceptions with the exclude element. You can use both XML elements several times. The following snippet illustrates the use of the exclude element for retry:
<retryable-exception-classes>
<include
class="org.springframework.dao.TransientDataAccessException"/>
<exclude
class="org.springframework.dao.PessimisticLockingFailureException"/>
</retryable-exception-classes>
Figure 8.5 shows the relationship between the exceptions TransientDataAccessException and PessimisticLockingFailureException. In the preceding snippet, you tell Spring Batch to retry when Spring throws transient exceptions unless the exceptions are related to pessimistic locking.
Figure 8.5. Spring Batch configured to retry exceptions: the include tag includes an exception class and all its subclasses. By using the exclude tag, you specify a part of the hierarchy that Spring Batch shouldn’t retry. Here, Spring Batch retries any transient exception except pessimistic locking exceptions.
Spring Batch only retries the item processing and item writing phases. By default, a retryable exception triggers a rollback, so you should be careful because retrying too many times for too many items can degrade performance. You should use retryable exception only for exceptions that are nondeterministic, not for exceptions related to format or constraint violations, which are typically deterministic. Figure 8.6 summarizes the retry behavior in Spring Batch.
Figure 8.6. Spring Batch retries only for exceptions thrown during item processing or item writing. Retry triggers a rollback, so retrying is costly: don’t abuse it! Note that Spring Batch doesn’t read the items again, by default, because it maintains a chunk-scoped cache.

In a chunk-oriented step, Spring Batch handles retry on the item processing and writing phases. By default, a retry implies a rollback, so Spring Batch must restore the context of retried operations across transactions. It needs to track items closely to know which item could have triggered the retry. Remember that Spring Batch can’t always know which item triggers an exception during the writing phase, because an item writer handles a list of items. Spring Batch relies on the identity of items to track them, so for Spring Batch retry to work correctly, you should override the equals and hashCode methods of your items’ classes—by using a database identifier, for example.
Combining Retry and Skip
You can combine retry with skip: a job retries an unsuccessful operation several times and then skips it. Remember that once Spring Batch reaches the retry limit, the exception causes the step to exit and, by default, fail. Use combined retry and skip when you don’t want a persisting transient error to fail a step. The following listing shows how to combine retry and skip.
Listing 8.7. Combining retry and skip

Automatic retry in a chunk-oriented step can make jobs more robust. It’s a shame to fail a step because of an unstable network, when retrying a few milliseconds later could have worked. You now know about the default retry configuration in Spring Batch, and this should be enough for most cases. The next section explores how to control retry by setting a retry policy.
8.3.2. Controlling retry with a retry policy
By default, Spring Batch lets you configure retryable exceptions and the retry count. Sometimes, retry is more complex: some exceptions deserve more attempts than others do, or you may want to keep retrying as long as the operation doesn’t exceed a given timeout. Spring Batch delegates the decision to retry or not to a retry policy. When configuring retry in Spring Batch, you can use the retryable-exception-classes element and retry-limit pair or provide a RetryPolicy bean instead.
Table 8.3 lists the RetryPolicy implementations included in Spring Batch. You can use these implementations or implement your own retry policy for specific needs.
Table 8.3. RetryPolicy implementations provided by Spring Batch
|
Class |
Description |
|---|---|
| SimpleRetryPolicy | Retries on given exception hierarchies, a given number of times; this is the default implementation configured with retryable-exception-classes/retry-limit |
| TimeoutRetryPolicy | Stops retrying when an operation takes too long |
| ExceptionClassifierRetryPolicy | Combines multiple retry policies depending on the exception thrown |
Let’s see how to set a retry policy with an example. Imagine you want to use retry on concurrent exceptions, but you have several kinds of concurrent exceptions to deal with and you don’t want the same retry behavior for all of them. Spring Batch should retry all generic concurrent exceptions three times, whereas it should retry the deadlock concurrent exceptions five times, which is more aggressive.
The ExceptionClassifierRetryPolicy implementation is a perfect match: it delegates the retry decision to different policies depending on the class of the thrown exception. The trick is to encapsulate two SimpleRetryPolicy beans in the ExceptionClassifierRetryPolicy, one for each kind of exception, as shown in the following listing.
Listing 8.8. Using a retry policy for different behavior with concurrent exceptions

Listing 8.8 shows that setting a retry policy allows for flexible retry behavior: the number of retries can be different, depending on the kind of exceptions thrown during processing.
Transparent retries make jobs more robust. Listening to retries also helps you learn about the causes of retries.
8.3.3. Listening to retries
Spring Batch provides the RetryListener interface to react to any retried operation. A retry listener can be useful to log retried operations and to gather information. Once you know more about transient failures, you’re more likely to change the system to avoid them in subsequent executions (remember, retried operations always degrade performance).
You can directly implement the RetryListener interface; it defines two lifecycle methods—open and close—that often remain empty, because you usually care only about the error thrown in the operation. A better way is to extend the RetryListenerSupport adapter class and override the onError method, as shown in the following listing.
Listing 8.9. Implementing a retry listener to log retried operations
package com.manning.sbia.ch08.retry;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.retry.RetryCallback;
import org.springframework.batch.retry.RetryContext;
import org.springframework.batch.retry.listener.RetryListenerSupport;
public class Slf4jRetryListener extends RetryListenerSupport {
private static final Logger LOG =
LoggerFactory.getLogger(Slf4jRetryListener.class);
@Override
public <T> void onError(RetryContext context, RetryCallback<T> callback,
Throwable throwable) {
LOG.error("retried operation",throwable);
}
}
The retry listener uses the SLF4J logging framework to log the exception the operation throws. It could also use JDBC to log the error to a database. The following listing registers the listener in the step, using the retry-listeners XML element.
Listing 8.10. Registering a retry listener

Any time you need to know about retried operations—for example, to get rid of them!—Spring Batch lets you register retry listeners to log errors.
Retry is a built-in feature of chunk-oriented steps. What can you do if you need to retry in your own code, for example, in a tasklet?
8.3.4. Retrying in application code with the RetryTemplate
Imagine you use a web service in a custom tasklet to retrieve data that a subsequent step will then use. A call to a web service can cause transient failures, so being able to retry this call would make the tasklet more robust. You can benefit from Spring Batch’s retry feature in a tasklet, with the RetryOperations interface and its RetryTemplate implementation. The RetryTemplate allows for programmatic retry in application code.
The online store uses a tasklet to retrieve the latest discounts from a web service. The discount data is small enough to keep in memory for later use in the next step. The DiscountService interface hides the call to the web service. The following listing shows the tasklet that retrieves the discounts (the setter methods are omitted for brevity). The tasklet uses a RetryTemplate to retry in case of failure.
Listing 8.11. Programmatic retry in a tasklet

The use of the RetryTemplate is straightforward. Note how the RetryTemplate is configured with a RetryPolicy directly in the tasklet. You could have also defined a RetryOperations property in the tasklet and used Spring to inject a RetryTemplate bean as a dependency. Thanks to the RetryTemplate, you shouldn’t fear transient failures on the web service call anymore.
Use of the RetryTemplate is simple, but the retry logic is hardcoded in the tasklet. Let’s go further to see how to remove the retry logic from the application code.
8.3.5. Retrying transparently with the RetryTemplate and AOP
Can you remove all the retry logic from the tasklet? It would make it easier to test, because the tasklet would be free of any retry code and the tasklet could focus on its core logic. Furthermore, a unit test wouldn’t necessarily deal with all retry cases.
Spring Batch provides an AOP interceptor for retry called RetryOperationsInterceptor. By using this interceptor, the tasklet can use a DiscountService object directly. The interceptor delegates calls to the real DiscountService and handles the retry logic. No more dependency on the RetryTemplate in the tasklet—the code becomes simpler! The following listing shows the new version of the tasklet, which doesn’t handle retries anymore.
Aspect-oriented programming is a programming paradigm that allows modularizing crosscutting concerns. The idea of AOP is to remove crosscutting concerns from an application’s main logic and implement them in dedicated units called aspects. Typical crosscutting concerns are transaction management, logging, security, and retry. The Spring Framework provides first-class support for AOP with its interceptor-based approach: Spring intercepts application code and calls aspect code to address crosscutting concerns. Thanks to AOP, boilerplate code doesn’t clutter the application code, and code aspects address crosscutting concerns in their own units, which also prevents code scattering.
Listing 8.12. Calling the web service without retry logic
package com.manning.sbia.ch08.retry;
import java.util.List;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
public class DiscountsTasklet implements Tasklet {
private DiscountService discountService;
private DiscountsHolder discountsHolder;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
List<Discount> discounts = discountService.getDiscounts();
discountsHolder.setDiscounts(discounts);
return RepeatStatus.FINISHED;
}
(...)
}
If you want to keep the tasklet this simple, you need the magic of AOP to handle the retry transparently. Spring AOP wraps the target DiscountService—the one that makes the web service call—in a proxy. This proxy handles the retry logic thanks to the retry interceptor. The tasklet ends up using this proxy. The following listing shows the Spring configuration for transparent, AOP-based retry.
Listing 8.13. Configuring transparent retry with Spring AOP

That’s it! Not only should you no longer fear transient failures when calling the web service, but the calling tasklet doesn’t even know that there’s some retry logic on the DiscountService. In addition, retry support isn’t limited to batch applications: you can use it in a web application whenever a call is subject to transient failures.
This ends our coverage of retry. Spring Batch allows for transparent, configurable retry, which lets you decouple the application code from any retry logic. Retry is useful for transient, nondeterministic errors, like concurrency errors. The default behavior is to retry on given exception classes until Spring Batch reaches the retry limit. Note that you can also control the retry behavior by plugging in a retry policy.
Skip and retry help prevent job failures; they make jobs more robust. Thanks to skip and retry, you’ll have fewer red-light screens in the morning. But crashes are inevitable. What do you do when a job runs all night and crashes two minutes before reaching the end? If you answer, “I restart it and wait another day,” keep on reading; the next section teaches you that you can answer, “I restart it and it’s going to take two minutes.”
8.4. Restart on error
Okay, your job is running, there are some transient errors, retry comes to the rescue, but these errors aren’t that transient after all. The job ends up skipping the errors. Is the job finished? Not yet. More errors come up, and the job finally reaches the skip limit. Spring Batch must fail the job! Despite all of your bulletproofing techniques, jobs can’t dodge bullets forever—they can fail. Can’t developers honor the exchange format you spent weeks to establish?
There’s still hope, because Spring Batch lets you restart a job exactly where it left off. This is useful if the job was running for hours and was getting close to the end when it failed. Figure 8.7 illustrates a new execution of the import products job that continues processing where the previous execution failed.
Figure 8.7. If a job fails in the middle of processing, Spring Batch can restart it exactly where it left off.

8.4.1. How to enable restart between job executions
How does Spring Batch know where to restart a job execution? It maintains metadata for each job execution. If you want to benefit from restart with Spring Batch, you need a persistent implementation for the job repository. This enables restart across job executions, even if these executions aren’t part of the same Java process. Chapter 2 shows how to configure a persistent job repository and illustrates a simple restart scenario. It also discusses Spring Batch metadata and job executions, as figure 8.8 shows.
Figure 8.8. Restart is possible thanks to batch metadata that Spring Batch maintains during job executions.

Spring Batch has a default behavior for restart, but because there’s no one-size-fits-all solution for batch jobs, it provides hooks to control exactly how a restarted job execution should behave. Let’s focus first on the default restart behavior.
Default Restart Behavior
Spring Batch uses the following defaults to restart jobs:
- You can only restart a failed job execution. This seems obvious but has the following implications: you must provide the job launcher with the job and the exact same job parameters as the failed execution you want to restart. Using Spring Batch terminology: when using restart, you start a new job execution of an existing, uncompleted job instance.
- You can restart any job. You can start a new execution for any failed job instance. You can disable restart for a specific job, but you need to disable it explicitly.
- A job restarts exactly where the last execution left off. This implies that the job skips already completed steps.
- You can restart a job as many times as you want. Well, almost—the limit is a couple of billion restarts.
You can override the defaults, and Spring Batch lets you change the restart behavior. Table 8.4 summarizes the restart settings available in the configuration of a job. The defaults for these settings match the default behavior we described.
Table 8.4. Configuration of the restart behavior
|
Attribute |
XML element |
Possible values |
Description |
|---|---|---|---|
| restartable | job | true / false | Whether the job can be restarted; default is true |
| allow-start-if-complete | tasklet | true / false | Whether a step should be started even if it’s already completed; default is false |
| start-limit | tasklet | Integer value | Number of times a step can be started; default is Integer.MAX_VALUE |
Let’s learn more about restart options in Spring Batch by covering some typical scenarios.
8.4.2. No restart please!
The simplest restart option is no restart. When a job is sensitive and you want to examine each failed execution closely, preventing restarts is useful. After all, a command-line mistake or an improperly configured scheduler can easily restart a job execution. Forbid restart on jobs that are unable to restart with correct semantics. Forbidding an accidental restart can prevent a job from processing data again, potentially corrupting a database.
To disable restart, set the attribute restartable to false on the job element:
<job id="importProductsJob"
restartable="false">
(...)
</job>
Remember that jobs are restartable by default. If you’re worried that you’ll forget that, set the restartable flag explicitly on all your jobs.
Restart is a nice feature, so let’s assume now that our jobs are restartable and explore more scenarios.
8.4.3. Whether or not to restart already completed steps
Remember that the import products job consists of two steps: the first decompresses a ZIP archive, and the second reads products from the decompressed file and writes into the database. Imagine the first step succeeds and the second step fails after several chunks. When restarting the job instance, should you re-execute the first step or not? Figure 8.9 illustrates both alternatives. There’s no definitive answer to such questions; this is a business decision, which determines how to handle failed executions.
Figure 8.9. Spring Batch lets you choose if it should re-execute already completed steps on restart. Spring Batch doesn’t re-execute already completed steps by default.

When is skipping the first, already completed step a good choice? If you check the Spring Batch logs and fix the decompressed input file after the failure, restarting directly on the second step is the way to go. The chunk-oriented step should complete correctly, or at least not fail for the same reason. If you stick to this scenario, you have nothing to do: skipping already completed steps is the default restart behavior.
Let’s consider now re-executing the first, already completed step on restart. When the batch operator sees that the execution failed during the second step, their reaction may be to send the log to the creator of the archive and tell them to provide a correct one. In this case, you should restart the import for this specific job instance with a new archive, so re-executing the first step to decompress the new archive makes sense. The second step would then execute and restart exactly on the line where it left off (as long as its item reader can do so and assuming the input has no lines removed, moved, or added).
To re-execute a completed step on a restart, set the allow-start-if-complete flag to true on the tasklet element:

Restarting a job is like many things: don’t do it too often. Let’s see how to avoid restarting a job indefinitely.
8.4.4. Limiting the number of restarts
Repeatedly restarting the same job instance can mean there’s something wrong and you should simply give up with this job instance. That’s where the restart limit comes in: you can set the number of times a step can be started for the same job instance. If you reach this limit, Spring Batch forbids any new execution of the step for the same job instance.
You set the start limit at the step level, using the start-limit attribute on the tasklet element. The following snippet shows how to set a start limit on the second step of the import products job:
<job id="importProductsJob">
<step id="decompressStep" next="readWriteProductsStep">
<tasklet>
(...)
</tasklet>
</step>
<step id="readWriteProductsStep">
<tasklet start-limit="3">
(...)
</tasklet>
</step>
</job>
Let’s see a scenario where the start limit is useful. You launch a first execution of the import products job. The first decompression step succeeds, but the second step fails after a while. You start the job again. This second execution starts directly where the second step left off. (The first step completed, and you didn’t ask to execute it again on restart.) The second execution also fails, and a third execution fails as well. On the fourth execution—you’re stubborn—Spring Batch sees that you’ve reached the start limit (3) for the step and doesn’t even try to execute the second step again. The whole job execution fails and the job instance never completes. You need to move on and create a new job instance.
Spring Batch can restart a job exactly at the step where it left off. Can you push restart further and restart a chunk-oriented step exactly on the item where it failed?
8.4.5. Restarting in the middle of a chunk-oriented step
When a job execution fails in the middle of a chunk-oriented step and has already processed a large amount of items, you probably don’t want to reprocess these items again on restart. Reprocessing wastes time and can duplicate data or transactions, which could have dramatic side effects. Spring Batch can restart a chunk-oriented step exactly on the chunk where the step failed, as shown in figure 8.10, where the item reader restarts on the same input line where the previous execution failed.
Figure 8.10. A chunk-oriented step can restart exactly where it left off. The figure shows an item reader that restarts on the line where the previous execution failed (it assumes the line has been corrected). To do so, the item reader uses batch metadata to store its state.

The item reader drives a chunk-oriented step and provides the items to process and write. The item reader is in charge when it comes to restarting a chunk-oriented step. Again, the item reader knows where it failed in the previous execution thanks to metadata stored in the step execution context. There’s no magic here: the item reader must track what it’s doing and use this information in case of failure.
Note
Item writers can also be restartable. Imagine a file item writer that directly moves to the end of the written file on a restart.
A restartable item reader can increment a counter for each item it reads and store the value of the counter each time a chunk is committed. In case of failure and on restart, the item reader queries the step execution context for the value of the counter. Spring Batch helps by storing the step execution context between executions, but the item reader must implement the restart logic. After all, Spring Batch has no idea what the item reader is doing: reading lines from a flat file, reading rows from a database, and so on.
Warning
When using a counter-based approach for restart, you assume that the list of items doesn’t change between executions (no new or deleted items, and the order stays the same).
Most of the item readers that Spring Batch provides are restartable. You should always carefully read the Javadoc of the item reader you’re using to know how it behaves on restart. How the item reader implements its restart behavior can also have important consequences. For example, an item reader may not be thread-safe because of its restart behavior, which prevents multithreading in the reading phase. Chapter 13 covers how to scale Spring Batch jobs and the impacts of multithreading on a chunk-oriented step.
What if you write your own item reader and you want it to be restartable? You must not only read the items but also access the step execution context to store the counter and query it in case of failure. Spring Batch provides a convenient interface—ItemStream—that defines a contract to interact with the execution context in key points of the step lifecycle.
Let’s take an example where an item reader returns the files in a directory. The following listing shows the code of the FilesInDirectoryItemReader class. This item reader implements the ItemStream interface to store its state periodically in the step execution context.
Listing 8.14. Implementing ItemStream to make an item reader restartable


The reader implements both the ItemReader (read method) and ItemStream (open, update, and close methods) interfaces. The code at ![]() initializes the file array to read files, where you would typically set it from a Spring configuration file. You sort the
file array because the order matters on a restart and the File.listFiles method doesn’t guarantee any specific order in the resulting array. When the step begins, Spring Batch calls the open method first, in which you initialize the counter
initializes the file array to read files, where you would typically set it from a Spring configuration file. You sort the
file array because the order matters on a restart and the File.listFiles method doesn’t guarantee any specific order in the resulting array. When the step begins, Spring Batch calls the open method first, in which you initialize the counter ![]() . You retrieve the counter value from the execution context, with a defined key. On the first execution, there’s no value
for this key, so the counter value is zero. On a restart, you get the last value stored in the previous execution. This allows
you to start exactly where you left off. In the read method, you increment the counter
. You retrieve the counter value from the execution context, with a defined key. On the first execution, there’s no value
for this key, so the counter value is zero. On a restart, you get the last value stored in the previous execution. This allows
you to start exactly where you left off. In the read method, you increment the counter ![]() and return the corresponding file from the file array. Spring Batch calls the update method just before saving the execution context. This typically happens before a chunk is committed. In update, you have a chance to store the state of the reader, the value of the counter
and return the corresponding file from the file array. Spring Batch calls the update method just before saving the execution context. This typically happens before a chunk is committed. In update, you have a chance to store the state of the reader, the value of the counter ![]() . ItemStream provides the close method to clean up any resources the reader has opened (like a file stream if the reader reads from a file). You leave the
method empty, as you have nothing to close.
. ItemStream provides the close method to clean up any resources the reader has opened (like a file stream if the reader reads from a file). You leave the
method empty, as you have nothing to close.
Listing 8.14 shows you the secret to restarting in a chunk-oriented step. You can achieve this thanks to the ItemStream interface. ItemStream is one kind of listener that Spring Batch provides: you can use the interface for item processors, writers, and on plain steps, not only chunk-oriented steps. To enable restart, ItemStream defines a convenient contract to store the state of a reader at key points in a chunk-oriented step. Note that Spring Batch automatically registers an item reader that implements ItemStream.
Note
You implement the FilesInDirectoryItemReader class mainly to illustrate creating a custom, restartable item reader. If you want an item reader to read files, look at the more powerful MultiResourceItemReader provided by Spring Batch.
This ends our tour of restart in Spring Batch. Remember that Spring Batch can restart a job instance where the last execution left off thanks to the metadata it stores in the job repository. Spring Batch has reasonable defaults for restart, but you can override them to re-execute an already completed step or limit the number of executions of a step. Restarting in the middle of a chunk-oriented step is also possible if the item reader stores its state periodically in the execution context. To use this feature, it’s best to implement the ItemStream interface.
Remember that restart makes sense only when a job execution fails. You can configure restart to prevent reprocessing, potentially avoiding data corruption issues. Restart also avoids wasting time and processes the remaining steps of a failed job execution. Skip and retry are techniques to use before relying on restart. Skip and retry allow jobs to handle errors safely and prevent abrupt failures.
Congratulations for getting through this chapter! You’re now ready to make your Spring Batch jobs bulletproof.
8.5. Summary
Spring Batch has built-in support to make jobs more robust and reliable. Spring Batch jobs can meet the requirements of reliability, robustness, and traceability, which are essential for automatic processing of large amounts of data. This chapter covered a lot of material, but we can summarize this material as follows:
- Always think about failure scenarios. Don’t hesitate to write tests to simulate these scenarios and check that your jobs behave correctly.
- Use skip for deterministic, nonfatal exceptions.
- Use retry for transient, nondeterministic errors, such as concurrency exceptions.
- Use listeners to log errors.
- Make a job restartable in case of failure if you’re sure it won’t corrupt data on restart. Many Spring Batch components are already restartable, and you can implement restartability by using the execution context.
- Disable restart on a job that could corrupt data on a restart.
Another key point to consider when you want to implement bulletproof jobs is transaction management. Proper transaction management is essential to a batch application because an error during processing can corrupt a database. In such cases, the application can trigger a rollback to put the database back in a consistent state. The next chapter covers transactions in Spring Batch applications and is the natural transition after the coverage of the bulletproofing techniques in this chapter. So keep on reading for extra-bulletproof jobs!