
Chapter 9. Transaction management
- Managing transactions in batch jobs
- Overriding transaction management defaults
- Using global transaction patterns
Chapter 8 introduced techniques like skip and restart to make batch jobs robust and reliable. This chapter complements the last one by covering another topic critical to batch jobs: transaction management. As batch jobs interact with transactional resources like databases, proper transaction management is crucial to make batch applications robust and reliable. Because an error can occur at any time during batch processing, a job needs to know if it should roll back the current transaction to avoid leaving data in an inconsistent state or if it can commit the transaction to persist changes.
This chapter starts with a quick transaction primer. Section 9.2 explains how Spring Batch handles transactions. How does Spring Batch manage transactions in a tasklet and in a chunk-oriented step? When and why does Spring Batch trigger a rollback? Section 9.2 answers these questions. Once we show the transaction management defaults in Spring Batch, section 9.3 explains why and how to override them. It also shows you how to avoid common pitfalls related to using declarative transactions and transactional readers.
Section 9.4 covers patterns that help you tackle tricky transaction scenarios in batch applications. You use these patterns to deal with global transactions—transactions spanning multiple resources—and batch jobs that interact with JMS queues.
Why should you read this chapter? Spring Batch has reasonable defaults for simple jobs. To implement complex jobs, you need to know more about transaction management. That’s what this chapter is about: explaining how Spring Batch handles transactions and providing you with guidelines and ready-to-use solutions to deal with challenging jobs.
9.1. A transaction primer
Transactions make the interactions between an application and a data store reliable. When writing batch applications, you need to know exactly what you’re doing with transactions, because they affect the robustness of your batch jobs and even their performance. With a transaction, you can safely interact with a data store. An interaction consists of one or more operations—SQL statements if the data store is a database. “Safely” means that the transaction is atomic, consistent, isolated, and durable. We commonly refer to these kinds of transactions as having ACID properties. Here is what an ACID transaction requires:
- Atomicity —All the operations in the transaction are successful, or none is.
- Consistency —A transaction always leaves the data store in a consistent state.
- Isolation —An ongoing transaction can’t see partial data of other ongoing transactions.
- Durability —A committed transaction survives any system failure.
A transaction often scopes to a business use case, and its ACID properties apply to the affected data. For example, for the use case of a money transfer between two bank accounts, we have the following operations: select both accounts, debit one account, and credit the other. The debit and credit should both happen; otherwise, money disappears (or appears, depending on the order of the operations); this illustrates the atomicity property. The balance between the two accounts should be the same before and at the end of the transfer (again, no money appears or disappears); this is the consistency property. Isolation is about how other transactions can see or even update the same data at the same time. Isolation deals with concurrent access and can affect performance; a high isolation level translates to poor performance. As soon as a data store tells you it committed a transaction, it should never lose the transacted data, even in case of a severe failure; this is the durability property.
In most applications, you choose how to drive transactions by using programmatic transaction demarcations or declarative transaction management (as the Spring Framework provides). It’s not the same in a Spring Batch job: Spring Batch drives the flow and the transactions. Batch applications don’t follow the request-response flow of typical web applications; this makes transaction management in batch jobs more complicated. The next section explains the default Spring Batch behavior that drives transactions.
9.2. Transaction management in Spring Batch components
Spring Batch handles transactions at the step level. This means that Spring Batch will never use only one transaction for a whole job (unless the job has a single step). Remember that you’re likely to implement a Spring Batch job in one of two ways: using a tasklet or using a chunk-oriented step. Let’s see how Spring Batch handles transactions in both cases.
9.2.1. Transaction management in tasklets
You use a tasklet whenever you need custom processing. This differs from the usual read-process-write behavior that Spring Batch’s chunk-oriented step handles well. Here are cases where you can use a tasklet: launching a system command, compressing files in a ZIP archive, decompressing a ZIP archive, digitally signing a file, uploading a file to a remote FTP server, and so on. The Tasklet interface is
public interface Tasklet {
RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception;
}
By default, the execute method of a tasklet is transactional. Each invocation of execute takes place in its own transaction. Here’s a simple example implementation:

A tasklet is repeatable: Spring Batch calls the execute method of a tasklet as long as the method returns RepeatStatus.CONTINUABLE. As we mentioned, each execute invocation takes place in its own transaction. When the execute method returns RepeatStatus.FINISHED or null, Spring Batch stops calling it and moves on to the next step.
Note
Be careful when implementing repeatable tasklets, because Spring Batch creates a new transaction for each invocation to the execute method. If a tasklet doesn’t use a transactional resource—like when decompressing a ZIP archive—you can set the propagation level to PROPAGATION_NEVER. Section 9.3.1 covers modifying transaction attributes.
To summarize, a tasklet is a potentially repeatable transactional operation. Let’s now see how Spring Batch handles transactions in a chunk-oriented step.
9.2.2. Transaction management in chunk-oriented steps
A chunk-oriented step follows the common read-process-write behavior for a large number of items. You know by now that you can set the chunk size. Transaction management depends on the chunk size: Spring Batch uses a transaction for each chunk. Such transaction management is
- Efficient —Spring Batch uses a single transaction for all items. One transaction per item isn’t an appropriate solution because it doesn’t perform well for a large number of items.
- Robust —An error affects only the current chunk, not all items.
When does Spring Batch roll back a transaction in a chunk? Any exception thrown from the item processor or the item writer triggers a rollback. This isn’t the case for an exception thrown from the item reader. This behavior applies regardless of the retry and skip configuration.
You can have transaction management in a step; you can also have transaction management around a step. Remember that you can plug in listeners to jobs and step executions, to log skipped items, for example. If logging to a database, for example, logging needs proper transaction management to avoid losing data or logging the wrong information.
9.2.3. Transaction management in listeners
Spring Batch provides many types of listeners to respond to events in a batch job. When Spring Batch skips items from an input file, you may want to log them. You can plug in an ItemSkipListener to the step. How does Spring Batch handle transactions in these listeners? Well, it depends (the worst answer a software developer can get). There’s no strict rule on whether or not a listener method is transactional; you always need to consider each specific case. Here’s one piece of advice: always check the Javadoc (you’re in luck; the Spring Batch developers documented their source code well).
If we take the ChunkListener as an example, its Javadoc states that Spring Batch executes its beforeChunk method in the chunk transaction but its afterChunk method out of the chunk transaction. Therefore, if you use a transaction resource such as a database in a ChunkListener’s afterChunk method, you should handle the transaction yourself, using the Spring Framework’s transaction support.
Spring Batch also includes listeners to listen to phases for item reading, processing, and writing. Spring Batch calls these listeners before and after each phase and when an error occurs. The error callback is transactional, but it happens in a transaction that Spring Batch is about to roll back. Therefore, if you want to log the error to a database, you should handle the transaction yourself and use the REQUIRES_NEW propagation level. This allows the logging transaction to be independent from the chunk and the transaction to be rolled back.
Now that we’ve completed this overview of transaction management in Spring Batch jobs, let’s study how to tune transactions during job executions. Setting transaction attributes like the isolation level is common in batch applications because it can provide better performance.
9.3. Transaction configuration
Spring Batch uses reasonable defaults for transaction management, but you can’t use these defaults for all batch jobs. This section explains why and how to override these defaults and how to avoid common pitfalls.
9.3.1. Transaction attributes
You learned in chapter 3 that you can use the transaction-attributes element in a tasklet element to set a transaction’s attributes, such as the propagation level, isolation level, and timeout. This allows you to have transaction attributes for a specific chunk different from the default attributes provided by a data source (which are commonly REQUIRED for the propagation level and READ_COMMITED for the isolation level).
Note
We don’t provide an in-depth explanation of transaction attributes. If you want to learn more about this topic, please see Spring in Action by Craig Walls (Manning Publications, 2011).
Most of the time, default transaction attributes are fine, so when would you need to override these defaults? It depends on the use case. Some batch jobs can work concurrently with online applications, for example. The isolation level dictates the visibility rules between ongoing, concurrent transactions. Table 9.1 lists isolation levels, from the least isolated—READ_UNCOMMITTED—to the most isolated—SERIALIZABLE.
Table 9.1. Isolation levels for transactions
|
Isolation level |
Description |
|---|---|
| READ_UNCOMMITTED | A transaction sees uncommitted changes from other transactions. Dirty reads, nonrepeatable reads, and phantom reads may occur. |
| READ_COMMITTED | A transaction sees only committed changes from other transactions. No dirty reads are possible. Nonrepeatable reads and phantom reads may occur. |
| REPEATABLE_READ | A transaction can read identical values from a field multiple times. Dirty reads and nonrepeatable reads don’t occur. Phantom reads may occur. |
| SERIALIZABLE | Dirty reads, nonrepeatable reads, and phantom reads don’t occur. Performance can be poor. |
When a batch job works concurrently with an online application, increasing the isolation level can ensure that the batch job and the online application properly read and update data, but at the cost of lower performance.
Alternatively, a batch job can be the only process working on the data, so decreasing the isolation level can result in faster processing than with the default isolation level. The following snippet shows how to set the isolation level to the lowest level, READ_UNCOMMITED:
<job id="importProductsJob">
<step id="importProductsStep">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="100" />
<transaction-attributes
isolation="READ_UNCOMMITTED" />
</tasklet>
</step>
</job>
In this snippet, you ask the database to provide the lowest isolation guarantee, but because the batch job is the only one working on the data, you don’t care about concurrent access.
That’s it for transaction attributes: override them only when you must. Let’s now see how a powerful Spring feature—declarative transaction management—can have catastrophic consequence when used in Spring Batch.
9.3.2. Common pitfalls with declarative transactions
Spring provides declarative transaction management: you say what you want to be transactional and Spring demarcates transactions for you. You can configure transactions using the @Transactional annotation or XML. This is convenient for online applications, like web applications: application code doesn’t depend on transaction management because Spring adds it transparently at runtime. Transactions become a crosscutting concern.
In a Spring Batch application, Spring Batch is in charge of transactions. If at any time Spring Batch calls application code annotated with @Transactional, the transaction for this code uses the transaction managed by Spring Batch. Because it’s using the default propagation level—REQUIRED—the transaction that @Transactional uses is the same as the Spring Batch transaction. Figure 9.1 illustrates how application code annotated with @Transactional can interfere with the chunk transaction in a Spring Batch job.
Figure 9.1. Be careful when using Spring’s declarative transaction in a Spring Batch job. Depending on the transaction attributes, the Spring-managed transaction can participate (or not) with the Spring Batch–managed transaction.

The following are guidelines to avoid conflict between Spring Batch–managed and Spring-managed transactions:
- Disable Spring’s declarative transactions for your batch application —Don’t use the tx:annotation-driven element or any XML configuration related to declarative transaction management.
- Be careful using propagation levels if declarative transactions are on —If you call transactional classes from a Spring Batch job, Spring’s transaction propagation can interfere with the Spring Batch transaction because of the propagation level. The REQUIRES_NEW propagation level could typically cause problems because the application code runs in its own transaction, independent of the Spring Batch transaction.
In short, be careful with declarative transactions. One of your best friends in online applications can become your worst enemy in offline applications! Let’s now meet another friend, the transactional reader.
9.3.3. Transactional reader and processor
Spring Batch can perform optimizations at any time. For example, Spring Batch buffers read items for a chunk so that, in case of a retryable error during writing, it can roll back the transaction and get the read items from its cache to submit to the writer instead of reading them again from the item reader. This behavior works perfectly if you read items from a data source like a database: Spring Batch reads a record, that’s it. The transaction rollback has no effect on the record read by Spring Batch: the database doesn’t care.
The story isn’t the same with a Java Message Service (JMS) queue. You not only read a message from a queue, you dequeue it: you read a message and remove it from the queue at the same time. Reading and removing a message must be atomic. In message-oriented middleware (MOM) and JMS terms, you also say that you consume a message. When there’s a transaction rollback, JMS returns the read messages to the queue. If the processing of the messages failed, the messages must stay on the queue. In the case of a JMS reader, buffering the read items is a bad idea: if a rollback occurs, the messages go back to the queue, Spring Batch then resubmits the items to the writer using its cache, and the writing succeeds. This is a bad combination: the processing succeeded but the messages are still on the queue, ready for Spring Batch to read and to trigger the processing...again!
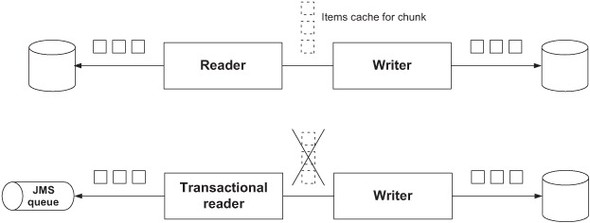
Figure 9.2 illustrates the difference between a nontransactional and a transactional reader. The nontransactional reader can read from a database (the database doesn’t care about clients reading it). The transactional reader gets items from the data source and puts them back in case of an error. The cache Spring Batch maintains for read items prevents the transactional reader from getting items again after a failure, so you should disable it when the reader is transactional.
Figure 9.2. The difference between nontransactional and transactional readers. By default, Spring Batch maintains a cache of read items for retries. You must disable this cache when the reader is transactional, so Spring Batch can read the items again in case of a rollback. A JMS item reader is an example of a transactional reader because reading a message from a JMS queue removes it from the queue. A database reader is a nontransactional reader, because reading rows from a database doesn’t modify the database.
To avoid processing messages several times because of Spring Batch’s cache, set the reader-transactional-queue attribute of the chunk element to true (the default is false), as the following snippet demonstrates:

Setting the reader-transactional-queue attribute to true disables Spring Batch’s chunk cache. Spring Batch sends messages back to the queue on a rollback and reads them again if it attempts to process the chunk again.
Note
The processor-transactional attribute allows for the same settings as reader-transactional-queue, but for the processor. The default value is true, which implies always re-executing the processor before sending items to the writer.
The only known use case of a transactional reader is JMS, but if you come up with a new one, don’t forget to set the reader-transactional-queue flag attribute to true! Let’s now see how to avoid transaction rollbacks.
9.3.4. To roll back or not to roll back
In a chunk-oriented step, Spring Batch rolls back a chunk transaction if an error occurs in the item processor or in the item writer. This seems safe because an error could have corrupted the state of the transaction, so a rollback ensures data isn’t in an inconsistent state. Sometimes you’re sure that a specific error didn’t corrupt the transaction, so Spring Batch can retry the operation or skip the item. This saves a rollback and therefore a new transaction. Having fewer transactions is better because transactions are costly.
Use the no-rollback-exception-classes element in the tasklet element to cause Spring Batch to avoid triggering a rollback on specific exceptions, as shown in the following listing.
Listing 9.1. Avoiding a rollback for an exception

Use the no-rollback-exception-classes feature only when you’re sure that an exception can’t corrupt a transaction; consider yourself warned!
You now know a lot about transaction management in Spring Batch and related configuration options. Robust batch applications sometimes need more than tuning. The next section explores transaction management patterns for real-world batch scenarios.
9.4. Transaction management patterns
This section covers commons challenges related to transaction management in batch applications. We look at guidelines and patterns using the Spring Framework and Spring Batch to overcome these challenges. By the end of this section, you’ll have a clear understanding of global transactions (transactions spanning multiple resources). We also see how to deal with global transactions when a database and a JMS queue are involved.
9.4.1. Transactions spanning multiple resources: global transactions
Applications sometimes need to perform transactional operations spanning multiple resources. We call these types of transactions global or distributed transactions. For example, such resources can be two databases, or a database and a JMS queue. Such transactional operations must meet the ACID properties we previously listed.
In the case of two databases and the classic money transfer example, imagine that the credited account is in a first database and the debited account in a second database. The consistent state—C in ACID—spans both databases.
For a database and a JMS queue, the reception of the message and its processing must be atomic. We don’t want to lose the message if the processing fails. Figure 9.3 shows an application that uses transactions over multiples resources.
Figure 9.3. A global transaction spanning multiple resources. The system must enforce ACID properties on all participating resources.

Local Transactions
Global transactions are different from local transactions, where only one resource is involved and the application directly communicates with the resource to demarcate transactions, as shown in figure 9.4.
Figure 9.4. Local transactions between an application and a resource. The application directly communicates with the resource to demarcate transactions. Try to use local transactions as much as possible: they’re fast, simple, and reliable.

Local transactions are the most common case. You should strive to use local transactions as much as possible because they’re simple to set up, reliable, and fast. Always consider if you need a JMS queue or a second database in your application. The Spring Framework provides support for local transactions for various data access technologies such as JDBC, Hibernate, Java Persistence API (JPA), and JMS. Spring Batch benefits directly from this support.
Transaction Managers and Global Transactions
Support for global transactions is a different beast. Global transactions are too difficult for an application to deal with, so an application relies on a dedicated component called a transaction manager. This transaction manager component implements a special protocol called XA. In this case, a third-party component handles the transactions, so we call such transactions managed transactions. In Java, to perform global transactions using the XA protocol, we need the following:
- A JTA transaction manager —It implements the Java Transaction API (JTA) specification, which requires the implementation of the XA protocol. Such a transaction manager is included in a Java EE application server or is available as a standalone component.
- XA-aware drivers —The resources must provide XA-compliant drivers so the transaction manager can communicate with the resources using the XA
protocol. Practically speaking, this implies the drivers provide implementations of interfaces like javax.sql.XAConnection. Thanks to these interfaces, the JTA transaction manager can enlist the resources in distributed transactions, as shown in
figure 9.5.
Figure 9.5. An application can use a JTA transaction manager to handle global transactions. The resources must provide XA drivers to communicate with the transaction manager using the XA protocol.

All Java EE application servers include a JTA transaction manager (Glassfish, JBoss, WebSphere, and so on; forgive us if we don’t list the others). Standalone JTA transaction managers also exist: Atomikos, Java Open Transaction Manager (JOTM), and the Bitronix Transaction Manager are some examples. You can plug in a standalone transaction manager in a web container like Tomcat and Jetty to provide JTA transactions. You can also use a standalone JTA transaction manager in a standalone process, like a batch application. Figure 9.5 shows an application using a JTA transaction manager to demarcate transactions spanning multiple resources.
If you want to use global transactions, the database or the JMS provider you’re using must have an XA-compliant driver available. Most of the popular databases and JMS providers have XA drivers.
If an application wants to use global transactions, it doesn’t need to write any global transaction–specific code: the transaction manager and the resources handle all the heavy lifting. The application only needs to use the JTA, or it can use an abstraction, like the one provided by Spring with the PlatformTransactionManager interface and the JtaTransactionManager implementation.
Warning
Spring doesn’t provide a JTA transaction manager. The Spring JtaTransactionManager class is only a bridge between Spring’s transaction management support and a full-blown JTA transaction manager.
Make no mistake: global transactions are tricky. First, the configuration can be difficult. Second, some implementations (transaction managers and XA drivers) remain buggy. Third, XA is inherently slower than local transactions because the strong transactional guarantees it provides imply some overhead (the transaction manager and the resources need to maintain precise logs of what they’re doing, for instance).
Note
The source code for this chapter contains an example of using Spring Batch with a standalone JTA transaction manager (the Bitronix Transaction Manager). This is appropriate for integration tests. If your jobs are running inside a Java EE application server, consider using that server’s transaction manager.
We’re not saying that using JTA for global transactions is a bad solution. It provides strong guarantees, but they come at a price. JTA has the advantage of working in all cases, as long you meet its requirements: a transaction manager and XA drivers. XA isn’t the only solution for global transactions. Depending on the context and resources involved, other techniques are viable alternatives to XA; they involve coding and usually perform better than XA.
We examine the following two patterns: the shared resource transaction pattern when two databases are involved, and the best effort pattern when a database and a JMS queue are involved. You can use both in batch applications by leveraging the Spring Framework and Spring Batch.
9.4.2. The shared resource transaction pattern
Sometimes, the same physical resource backs multiple logical resources. For example, two JDBC DataSources can point to the same database instance. Using Oracle terminology, we say that you refer to schema B from schema A by using the same connection. You also need to define synonyms in schema A for schema B’s tables. This enables real global transactions using the same mechanism as for local transactions. The overhead is a little more than for true local transactions but less than with XA.
Figure 9.6 shows a use case of the shared resource pattern, where a database schema contains tables for a first application and Spring Batch’s tables. Another database schema contains tables for a second application. A Spring Batch job executes against both applications’ tables, but using only one connection, with the use of synonyms.
Figure 9.6. Use the shared resource transaction pattern when a common resource hosts the transactional resources. In this example, two Oracle database schemas exist in the same database instance. The first schema refers to the second schema’s tables using synonyms. This allows the application to use local transactions.

Applying the shared resource transaction pattern can have some limitations, depending on the database engine. For example, you may need to change some application or configuration code to add a schema prefix to refer explicitly to the correct schema.
Here’s an example of the shared resource transaction pattern applied to Spring Batch. People are sometimes reluctant to host the batch execution metadata in the same database as the business data (they don’t want to mix infrastructure and business concerns, which makes sense). Therefore, Spring Batch must span transactions over two databases for the execution metadata and the business data to ensure proper counts of skipped items, retries, and so on. You can use the shared resource transaction pattern to host batch execution metadata and business data in different databases. The pattern keeps your batch metadata and business data separate and properly synchronized, and you can stick to local transactions.
Even when this pattern applies in a specific context, it generally provides better throughput and needs less configuration than an XA solution. Let’s now see the best effort pattern, which applies to a database and a JMS queue.
9.4.3. The best effort pattern with JMS
Reading messages from a JMS queue and processing them in a database is a common scenario for a batch application. For example, our online store could accumulate orders in a JMS queue and read them periodically to update its inventory. This solution allows for full control over the processing of messages, including postponing processing to periods when the system isn’t under heavy load. Note that this example solution doesn’t exclude processing the messages as they’re arriving by plugging in a queue listener. Figure 9.7 illustrates a chunk-oriented step that reads from a queue and updates a database during the writing phase.
Figure 9.7. The best effort pattern can apply when reading from a JMS queue and writing to a database.

What Can Go Wrong on Message Delivery
This pattern requires two resources—a JMS queue and a database—and must be transactional. What can go wrong? Let’s look at the two cases:
- Losing the message —The application receives a message, acknowledges it, but fails to process it. The message is no longer on the queue, and there’s been no processing in the database: the message is lost.
- Receiving and processing the same message twice —The application receives a message and processes it, but the acknowledgment fails. The JMS broker delivers the message again, and the application processes it again. We call this a duplicate message.
Back to the inventory update example: losing messages means that orders arrive but the application doesn’t update the inventory. The inventory ends up with more products than it should. Perhaps the company won’t be able to provide customers with their ordered items. Processing orders multiple times means that the inventory runs out of products faster. Perhaps you’ll lose orders because customers won’t buy items that aren’t virtually in stock. Perhaps the company will ask to resupply its stock when it doesn’t need to. All these scenarios could put the company in a world of hurt. You want to avoid that.
Acknowledging a message means that you tell the JMS provider that you processed the message you received. Once you acknowledge a message, the JMS provider removes it from the queue. JMS has two techniques to acknowledge messages: one is using JMS in acknowledgment mode, and the other is using a local JMS transaction. The two techniques are exclusive. JMS has three acknowledgment modes: acknowledge messages as soon as they’re received (AUTO_ACKNOWLEDGE), let the application acknowledge messages explicitly (CLIENT_ACKNOWLEDGE), and lazily acknowledge the delivery of messages (DUPS_OK_ACKNOWLEDGE). This last acknowledgment mode is faster than the auto acknowledgment mode but can lead to duplicate messages. When using a local JMS transaction for acknowledgment, you start a transaction in a JMS session, receive one or more messages, process the messages, and commit the transaction. The commit tells the JMS broker to remove the messages from the queue.
We could use XA to avoid both problems, but remember that we can do without XA sometimes. Let’s see how Spring helps us avoid losing messages.
Avoiding Losing Messages with Transaction Synchronization
To avoid losing messages, Spring synchronizes the local JMS transaction with the database transaction. Spring commits the JMS transaction immediately after the commit of the database transaction. We call this the best effort pattern. Spring does the synchronization transparently as long as you use the correct settings. This synchronization is a Spring feature; you can use it in any kind of application, and Spring Batch jobs are no exception. Figure 9.8 shows how Spring synchronizes a local JMS transaction with a chunk transaction.
Figure 9.8. The best effort pattern. Spring automatically synchronizes the local JMS transaction commit with the commit of an ongoing transaction (the chunk transaction in the context of a Spring Batch job).

To benefit from transaction synchronization, you need to tell Spring to use a local JMS transaction with a JmsTemplate to receive messages. Listing 9.2 sets up a JmsTemplate and a JMS item reader to use a local JMS transaction and so benefits from the automatic transaction synchronization feature. Note that the sessionTransacted flag is set to true in the JmsTemplate, which instructs Spring to use a local JMS transaction.
Listing 9.2. Using transaction synchronization to avoid losing messages
<bean id="jmsTemplate" class="org.springframework.jms.core.JmsTemplate"> <property name="connectionFactory" ref="connectionFactory" /> <property name="defaultDestination" ref="orderQueue" /> <property name="receiveTimeout" value="100" /> <property name="sessionTransacted" value="true" /> </bean> <bean id="jmsReader" class="org.springframework.batch.item.jms.JmsItemReader"> <property name="jmsTemplate" ref="jmsTemplate" /> </bean>
Remember that it’s not only thanks to local JMS transactions that you avoid losing messages; it’s also due to the transaction synchronization that Spring performs transparently.
The JmsTemplate uses the AUTO_ACKNOWLEDGE mode by default, but don’t use this default; set the sessionTransacted flag to true to use local JMS transactions. Remember that the acknowledgment mode and the use of a JMS transaction are exclusive: you choose one or the other (JMS brokers usually ignore the acknowledgment mode when you ask for a transacted JMS session).
Note
When using a JMS item reader, remember to set the reader-transactional-queue flag to true in the chunk XML element.
Synchronizing the commit of the local JMS transaction with the database transaction commit ensures that the application acknowledges the message only if processing is successful. No more lost messages, no more lost inventory updates!
You can apply the best effort pattern to any resources that have transaction-like behavior. Spring Batch uses the best effort pattern when writing files. Do you remember the transactional flag in the FlatFileItemWriter? It applies to the buffer Spring Batch maintains for the output file.
If this flag is set to true (the default), Spring Batch flushes the buffer only after the transaction commit (once it’s sure the chunk completed successfully). It does this by synchronizing the flush with the database commit (it’s the same when synchronizing a JMS commit with a database commit). The flush is the file equivalent of the transaction commit in a database. We resort to the best effort pattern for file writing because there’s no support—like JTA—for true distributed transactions over a database and a file system.
But the best effort pattern isn’t perfect, and the next subsection covers its shortcomings. Don’t worry: we’ll see techniques to address these shortcomings.
Avoiding Duplicate Messages
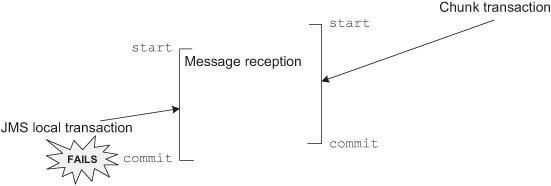
Let’s consider the following vicious failure scenario. The JMS item reader reads messages, the item writer processes the chunk, and Spring Batch commits the chunk transaction. The JMS transaction is then committed because it’s synchronized with the chunk transaction commit. What happens if the JMS transaction commit fails because of a network failure? Remember what a JMS transaction rollback means for the JMS broker: the application says the processing of the messages failed. The JMS broker then puts back the messages read during the transaction on the queue. The messages are then ready to be read and processed again. Figure 9.9 illustrates this failure scenario, where the best effort pattern shows its limitation.
Figure 9.9. When the best effort pattern fails. The database commit works, but the JMS commit fails. JMS puts the message back on the queue, and the batch job processes it again. Even if such duplicate messages are rare, they can corrupt data because of repeated processing.
The best effort pattern isn’t bulletproof because of the small window it leaves open between the commit of the two transactions. You won’t lose messages, thanks to the best effort pattern, but you still need to deal with duplicate messages. Let’s now see two solutions to deal with duplicate messages.
9.4.4. Handling duplicate messages with manual detection
When you use the best effort pattern, you need to avoid processing duplicate messages. This is easily doable, but you need some extra code in your application. This extra code has two parts:
- Tracking messages during processing —The tracking mechanism can be a dedicated database table that flags messages as processed. Tracking must be part of the database transaction.
- Detecting previously processed messages and filtering them out —The application must perform this check before processing by using a tracking system.
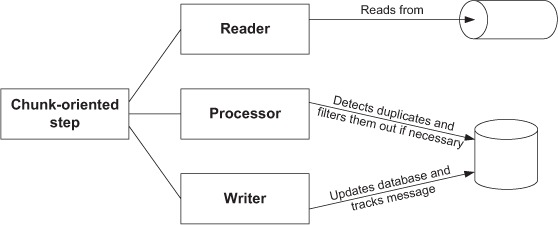
You have everything you need to build such a tracking system in Spring Batch. In a chunk-oriented step, the item writer processes messages by updating the database and takes care of tracking by adding a row in the tracking table. An item processor is in charge of filtering out duplicate, already-processed messages by checking the tracking table. Remember that an item processor can transform read items before Spring Batch passes them to an item writer, but it can also filter out items by returning null. Figure 9.10 shows a chunk-oriented step that reads JMS messages, filters out duplicate messages, and implements processing in the writing phase.
Figure 9.10. Detecting duplicate messages and filtering them out with an item processor in a chunk-oriented job. The item writer must track whether a processor processed each message. The best effort pattern combined with this filtering technique prevents a processor from processing duplicate messages.
Let’s get back to the inventory example to see how to implement the detection of duplicate messages.
JMS Messages and Domain Objects
The online store accumulates orders in a JMS queue, and a batch job reads the messages to update the inventory table. A JMS message contains an Order, which itself contains a list of OrderItems. The following listing shows the definition of the Order and OrderItem classes.
Listing 9.3. A JMS message containing an Order object


You now know what kind of objects you’re dealing with. Let’s look at the processing by implementing the corresponding item writer.
Writing and Tracking Items in an Item Writer
The following listing shows how the InventoryOrderWriter processes and then tracks orders.
Listing 9.4. Processing and tracking orders in an item writer


For each order, the InventoryOrderWriter first handles the processing ![]() , which consists of removing the items from the inventory. Then, the writer tracks that the order has been processed
, which consists of removing the items from the inventory. Then, the writer tracks that the order has been processed ![]() . To track the processing, the system uses a dedicated database table to store the order ID
. To track the processing, the system uses a dedicated database table to store the order ID ![]() .
.
Note
You’re lucky in this case to have a unique business ID. If you don’t have access to a unique ID for your custom processing, use the JMS message ID.
You also store the timestamp of the processing. This can be useful to purge the table from time to time.
You now have the first part of your mechanism to detect duplicate messages. The second part detects redelivered messages and checks to see if the job has already processed a redelivered message.
Detecting and Filtering Out Duplicate Messages with an Item Processor
The following listing shows the item processor code that detects and filters out duplicate messages.
Listing 9.5. Detecting and filtering out duplicate messages with an item processor

When a JMS broker redelivers a message, it sets the message object’s redelivered flag to true. You use this flag ![]() to avoid querying the database, an optimization. If the message isn’t a redelivery, you let it go to the writer. In the case
of a redelivered message, you check
to avoid querying the database, an optimization. If the message isn’t a redelivery, you let it go to the writer. In the case
of a redelivered message, you check ![]() whether you’ve already processed the message. The check consists of querying the tracking table to see if it contains the order ID
whether you’ve already processed the message. The check consists of querying the tracking table to see if it contains the order ID ![]() . The detection of a duplicate is simple and cheap, and duplicate messages are rare. This solution also performs better than
the equivalent using XA.
. The detection of a duplicate is simple and cheap, and duplicate messages are rare. This solution also performs better than
the equivalent using XA.
Configuring a Job to Detect Duplicate Messages
The following listing shows the relevant portion of the job configuration (we skipped the infrastructure configuration for brevity).
Listing 9.6. Configuring the duplicates detection job

This configuration is typical for a chunk-oriented step, but it contains a couple of subtleties. Note the use of the reader-transactional-queue attribute ![]() . This flag should always be set to true for a JMS item reader. At
. This flag should always be set to true for a JMS item reader. At ![]() , you ask the JMS item reader to pass the plain JMS message—no extraction of the body—to the item processor. Remember that
you need the JMS message in the item processor to check the redelivered flag. Because you want to use the best effort pattern,
you use local JMS transactions with the JMS template for message acknowledgment
, you ask the JMS item reader to pass the plain JMS message—no extraction of the body—to the item processor. Remember that
you need the JMS message in the item processor to check the redelivered flag. Because you want to use the best effort pattern,
you use local JMS transactions with the JMS template for message acknowledgment ![]() .
.
That’s it; you detect duplicate messages with your filtering item processor. By also using the best effort pattern, you enforce atomicity in your global transaction without using XA. This solution is straightforward to implement thanks to Spring Batch and the Spring Framework, and it avoids the overhead of an XA solution. Your inventory is now safe!
Next, we see how to deal with duplicate messages without any extra code.
9.4.5. Handling duplicate messages with idempotency
In the inventory update example, you want to avoid duplicate messages because you can’t afford to process messages multiple times. You need this functionality because processing removes ordered items from the inventory. What if processing a message multiple times is harmless? When an application can apply an operation multiple times without changing the result, we say it’s idempotent.
What is Idempotency?
Idempotency is an interesting property for message processing. It means that we don’t care about duplicate messages! Always think about idempotency when designing a system: idempotent operations can make a system much simpler and more robust.
Idempotent Operations in a Batch Job
Let’s see an example of an idempotent operation in the online store application. The shipping application—a separate application—sends a message on a JMS queue for each shipped order. The online store keeps track of the state of orders to inform customers of their orders. A batch job reads messages from the shipped order queue and updates the online store database accordingly. Figure 9.11 illustrates this batch job.
Figure 9.11. When performing an idempotent operation on the reception of a message, there’s no need to detect duplicate messages. The best effort pattern combined with an idempotent operation is an acceptable solution.

The processing is simple: it consists only of setting the shipped flag to true. The following listing shows the item writer in charge of updating shipped orders.
Listing 9.7. Updating the shipped order (idempotent processing)


Because the message processing is idempotent—setting the shipped flag to true in the database—you don’t need to handle duplicate messages. You can kiss goodbye any tracking system and filtering item processors. This only works for idempotent operations!
This completes our coverage of transaction management patterns. You now know how to implement global transactions in Spring Batch. A use case must meet specific conditions to apply these patterns successfully, and it’s up to you to design your system in a manner suitable to apply these patterns. We saw how the shared transaction resource pattern applies when a transaction spans two schemas that belong to the same database instance. Spring implements the best effort pattern—synchronizing the local JMS transaction with the database transaction commit—but you need to be careful using it. You must detect duplicate messages by using a tracking system if the message processing isn’t idempotent. You don’t have to worry if the processing is idempotent.
Transaction management in batch application holds no secrets for you anymore!
9.5. Summary
Transaction management is a key part of job robustness and reliability. Because errors happen, you need to know how Spring Batch handles transactions, figure out when a failure can corrupt data, and learn to use appropriate settings. Remember the following about transaction management in batch applications, and don’t hesitate to go back to the corresponding sections for more details:
- Spring Batch handles transactions at the step level. A tasklet is transactional; Spring Batch creates and commits a transaction for each chunk in a chunk-oriented step.
- Be careful with declarative transaction management (with XML or the Transactional annotation); it can interfere with Spring Batch and produce unexpected results.
- When a batch application interacts with more than one transactional resource and these interactions must be globally coordinated, use JTA or one of the patterns we’ve discussed.
- JTA is a bulletproof solution for global transactions, but it can be complex to set up and adds overhead.
- The alternative techniques for handling global transactions without JTA work only in specific contexts and can add extra logic to the application.
With the previous chapter on bulletproofing jobs and this chapter on transaction management, you now know the techniques to write truly bulletproof jobs.
Remember an interesting feature Spring Batch provides: skipping. In a chunk-oriented step, Spring Batch can skip exceptions to avoid failing a whole step. When the step reaches the skip limit, Spring Batch fails the step. Does Spring Batch cause the failure of the whole job? By default, yes, but you can override this behavior. Instead of failing the whole job immediately, for example, you can execute a tasklet to create and email a report on the execution of the job to an operator. If you’re interested in discovering how you can choose between different paths for steps in a Spring Batch job, please continue on to the next chapter, which covers how Spring Batch handles the execution of steps inside a job.