
5 XML Databases
The Extensible Markup Language (XML) was defined by the WWW Consortium (W3C) as a document markup language. Related standards (in particular, XML Schema, XQuery and XSLT) are maintained by the W3C, too.
| Web resources: –XML Technology: http://www.w3.org/standards/xml/ |
In recent years, XML has become a major format for data exchange, flexibly structured documents, or configuration files. This fact demanded that XML documents could be persistently stored in database systems that respect the special structure of XML documents and support effcient data retrieval on them. Although the Java Script Object Notation (JSON) manifested itself as the more readable successor of XML, several legacy systems still rely on data in XML format. Due to its mature and standardized format, management of XML data is still a current topic. In this chapter we introduce the basics of XML and discuss several options for storing XML documents in a database.
5.1 XML Background
An XML document consists of tags that structure the document. As this structure can be less rigid than the conventional relational table model, XML documents can be used to store data in a so-called semi-structured format. In general, due to well-formedness conditions for XML documents each XML document can be represented in a tree shape. In addition, validity can be checked based on some schema definitions: their use is an optional feature of XML that facilitates document exchange and processing. There are two forms of schema definitions for XML widely used today which we will briefly survey in the following subsections: Document Type Definitions and XML Schema. Several query or transformation languages can be used to process XML documents. We focus here on the most relevant background on XML technology; other introductory as well as advanced literature on XML is widely available.
5.1.1 XML Documents
As already mentioned, XML documents are structured by tags; a tag is basically a label which spans a section of the document. More precisely, such a section of the document is called an XML element, and it begins with a start tag and ends with an end tag. The start tag contains the name of the element (surrounded by “<“ and “>“); the end tag additionally contains a slash sign “/”. For example, let us store all data of a hotel reservation system in an XML document. For each hotel, we would need an element that stores the location of a hotel; hence, the name of this element would be “location”. With the corresponding start and end tags, the element for a hotel located in Newtown would look like this:
<location> Newtown </location>
In this example, the location element contains the text “Newtown”. Apart from text, an element can also contain other elements, which are then called subelements of this element; in other words, elements can be nested. For example, to model a hotel we can have a hotel element with contains as subelements a name element, a location element and a room price element:
<hotel>
<name> Palace Hotel</name>
<location> Newtown </location>
<roomprice> 65 Euro </roomprice>
</hotel>
An element may contain several subelements with the same name; for example, we might have an element with the name reservationsystem as the top-level element (the so-called root element) and it might have several hotel elements as subelements:
<reservationsystem>
<hotel>
<name> Palace Hotel </name>
<location> Newtown </location>
<roomprice> 65 Euro </roomprice>
</hotel>
<hotel>
<name> Eden Hotel </name>
<location> Newtown </location>
<roomprice> 75 Euro </roomprice>
</hotel>
</reservationsystem>
Elements may also be empty (they neither contain text nor subelements). Moreover, an XML element can have XML attributes. An attribute is alternative for subelements: they are another way of assigning information to an element. Attribute names and their values are written inside the start tag of the element: the attribute name is followed by an equality sign (=) and the attribute value inside quotation marks (“). An attribute name can only occur once inside an element; this is in contrast to subelements which can occur multiple times inside the same element. In our example, we add an ID attribute to the hotel element:
<reservationsystem>
<hotel hotelID=“h1”>
<name> Palace Hotel </name>
<location> Newtown </location>
<roomprice> 65 Euro </roomprice>
</hotel>
<hotel hotelID=“h2”>
<name> Eden Hotel </name>
<location> Newtown </location>
<roomprice> 75 Euro </roomprice>
</hotel>
</reservationsystem>
An XML document might contain additional information that facilitates handling of the document; version declarations, entity declarations (which are shortcuts for often repeated texts), as well as comments or processing instruction are possible. For example, an XML version declaration can be optionally included at start of XML document as follows: <?xml version “1.0”>. Moreover, XML namespaces (XMLNS) are useful to have a unique naming of elements: Because tag names can be used with a different meaning in two different XML documents, exchanging these documents or processing these documents together may cause a confusion. This confusion can be avoided when each element name is prefixed by a unique namespace identifier; the names-pace itself is usually a Uniform Resource Identifier (URI) which denotes the scope and origin of the document.
5.1.2 Document Type Definition (DTD)
Document Type Definitions (DTDs) are the simplest way to specify a schema for XML documents. DTDs have their own syntax (that is, they are not written in XML). The two basic components of a DTD are element definitions and attribute definitions; their syntax is as follows:
<!ELEMENT element (subelements-specification)>
<!ATTLIST element (attributes-specification)>
An element definition defines which element names can occur in an XML document, how elements can be combined with other ones, and how elements can be nested. Subelements can be specified as
–names of elements,
–#PCDATA (“parsed character data”; which mostly means arbitrary text – but parsed character data may also contain markup elements),
–EMPTY (no subelements), or
–ANY (any element defined in the DTD can be a subelement).
Note that DTDs do not offer different data types for the content of an element: every text value inside an element is simply a string (#PCDATA). A subelement specification may contain regular expressions to further specify occurrences or combinations of elements. Commas between element names indicate they must occur in the specified order, whereas without commas elements can occur in any order. Moreover, the following notation can be used to quantify the occurrences of elements: | denotes alternatives, + denotes 1 or more occurrences, * denotes 0 or more occurrences, and ? denotes 0 or 1 occurrences; if no such quantifying notation is given for an element name, the element must occur exactly once. In our example reservation system we can specify in a DTD that an arbitrary amount of hotel elements can be contained in the document, but hotel name, location and room price should be specified in a fixed order; the room price is optional. Example:
<!ELEMENT reservationsystem (hotel*)>
<!ELEMENT hotel (name, location, roomprice?)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT location (#PCDATA)>
<!ELEMENT roomprice (#PCDATA)>
An attribute specification determines, which attributes are available for the specified element. It can also specify what values the attribute may have. The attribute specifi-cation contains the name of the attribute and it defines its content type. The content type may be “character data” #CDATA for arbitrary text, or a fixed enumeration of values that the attribute may hold, or IDs or IDREFs. IDs are identifier for elements: an ID associates a unique value with the individual element; and IDREF is an ID reference (or IDREFS for multiple references): the value of a reference must correspond to the value of the ID attribute for some element in the same document. Note that each element can have at most one attribute of type ID and the ID attribute value of each individual element in an XML document must be distinct to act as a unique identifier. Optional specifications for attributes are whether the attribute is mandatory (#REQUIRED) or optional (#IMPLIED); or whether it has a default value. Hence, to extend our example, we can specify the hotel ID to be a mandatory ID attribute of the hotel element:
<!ATTLIST hotel hotelID ID #REQUIRED>
In order to illustrate ID references, assume that we have another element called booking which stores the booking of a particular hotel for a client.
<!ELEMENT reservationsystem (hotel* booking*)>
…
<!ELEMENT booking (client)>
<!ELEMENT client (#PCDATA)>
<!ATTLIST booking
bookingID ID #REQUIRED
hotelbooked IDREF #REQUIRED>
Each booking should have its own ID as an attribute, but we can specify the booked hotel by an ID reference as an attribute in the booking element.
Finally, the element and attribute definitions should be surrounded by a DOCTYPE top-level declaration which states the name of the root element. For example, for our root element reservationsystem:
<!DOCTYPE reservationsystem[
<!ELEMENT reservationsystem (hotel* booking*)>
…
]>
While DTDs are quite easily readable, they have some limitations. In particular, they only offer limited data typing: All values are strings, and one cannot differentiate strings from other basic types like integers, reals, etc. Moreover note that IDs and IDREFs are untyped: in our example, the ID reference hotelbooked can refer to another booking ID instead of referring to a hotel ID which would be nonsensical.
5.1.3 XML Schema Definition (XSD)
An XML Schema definition is an XML document; it can hence directly be processed by the applications that process the other (non-schema) XML documents. XML Schema is a much more sophisticated schema language than DTD. It allows for data typing with basic system-defined types (we can define elements to contain integers, decimals, dates, strings, or list types) and even user-defined types including inheritance. XML Schema also supports constraints on the number of occurrences of subelements, on minimum or maximum values and an advanced ID referencing. But this increased expressiveness comes at the cost of less readability: XML Schema definitions are significantly more complicated than DTDs. To start with, there is a standard URI that defines all the necessary components (like elements and attributes); this URI can be used in a namespace throughout an XML Schema definition. In our examples, we call this namespace xsd:
<xsd:schema xmlns:xsd=http://www.w3.org/2001/XMLSchema>
Elements that do not contain other elements or attributes are of type simpleType and can be defined as having a basic type like string or decimal.
<xsd:element name=“name” type=“xsd:string”/>
<xsd:element name=“location” type=“xsd:string”/>
<xsd:element name=“roomprice” type=“xsd:decimal”/>
Elements that contain subelements are of type complexType. The list of subelements of a complex type element is defined inside a sequence element.
<xsd:element name=“hotel”>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=“name” />
<xsd:element name=“location” />
<xsd:element name=“roomprice” />
…
</xsd:sequence>
</xsd:complexType>
</xsd:element>
With XML Schema definitions, the number of occurrences (the cardinality) of subelements can be defined. The cardinality of an element is represented by minOccurs and maxOccurs in the element definition. When the element is optional, its minOccurs property should be set to 0. When there is no restriction on the maximum number of occurrences, maxOccurs should be set to “unbounded”. In our case, there should be exactly one hotel name and location but the room price is optional:
<xsd:element name = “hotel”>
<xsd:complexType> <xsd:sequence>
<xsd:element name=“name” minOccurs=“1” maxOccurs=“1”/>
<xsd:element name=“location” minOccurs=“1” maxOccurs=“1”/>
<xsd:element name=“pricesgl” minOccurs=“0” maxOccurs=“1”/>
…
</xsd:sequence>
</xsd:complexType>
</xsd:element>
Attributes must be defined after the corresponding element definitions; for example:
<xsd:element name = “hotel”>
<xsd:complexType>
<xsd:sequence>
<xsd:element name=“name” minOccurs=“1” maxOccurs=“1”/>
<xsd:element name=“location” minOccurs=“1” maxOccurs=“1”/>
<xsd:element name=“pricesgl” minOccurs=“0” maxOccurs=“1”/>
…
</xsd:sequence>
<xsd:attribute name=“hotelID” type=“xsd:string”/>
</xsd:complexType>
</xsd:element>
XML Schema offers user-defined types which can be reused throughout the XML Schema definition. For example, we can define a new HotelType by giving the complex type definition the appropriate name:
<xsd:complexType name=“HotelType”>
<xsd:sequence>
<xsd:element ref=“name” minOccurs=“1” maxOccurs=“1”/>
…
</xsd:sequence>
</xsd:complexType>
User-defined types can then be used as types for elements:
<xsd:element name=“hotel” type=“HotelType”>
5.1.4 XML Parsers
Programs that process inputs in XML format are usually called XML parsers. An indispensable syntactic requirement for an XML document is the well-formedness of the document: an XML document must have a certain structure because otherwise a parser will fail to process it. The main aspect of well-formedness is proper nesting of elements: every start tag must have a unique matching end tag, inside the scope of the same parent element. An example for proper nesting is when the start and end tag for element name are both inside the element hotel: <hotel> <name> </name> </hotel>. An example for an improper nesting is when the end tag of element name is outside of the element hotel: <hotel> <name> </hotel> </name>; this improper nesting would cause an error when processing the document. Moreover, a well-formed XML document should always have a unique top-most element (which surrounds all other elements of the document; this top-most element is called the root element of the XML document. Other conditions for well-formedness include for example the correct syntax of attributes or comments.
A validating XML parser not only check if an XML document is well-formed but it also checks its validity: that is, that it conforms to a Document Type Definition (DTD) or XML Schema definition.
There are two basic application programming interfaces (APIs) an XML parser can offer:
Simple API for XML (SAX): A SAX parser reads in an XML document as a stream of data. When reading a part of the document (for example, a start tag), the SAX parser creates an event (for example, a start-element event). An application using the SAX API can then provide event handlers for these parsing events. A SAX parser processes an XML document in a read-once fashion which makes it fast. On the downside, however, one cannot navigate in the document or modify it.
Document Object Model (DOM): A DOM parser transforms the XML document into a tree representation. The DOM API provides several functions for traversing or updating the DOM tree. The Java DOM API provides a Node class with methods for navigating in the tree (for example, getParentNode(), getFirstChild(), get-NextSibling(), getAttribute()), reading text from a text node (getData()), or searching in the tree (for example, getElementsByTagName()).
5.1.5 Tree Model of XML Documents
XML documents have a structure that resembles a tree. The root element is the root node of the tree; the subelements of the root element are the child nodes of the root node; and so on. Subelements nested inside the same element are child nodes of the same parent node; they are on the same level in the tree and are called siblings. All nodes on the path from a node to the root node are called ancestors of this node; whereas all nodes in the subtree starting from a node are called descendants of this node. The nodes for the elements are usually constructed in the order in which they appear in the XML document (the document order). For each node in the tree one can hence also differentiate between the preceding nodes and the following nodes (in the document order). Note that preceding nodes are disjoint from ancestors and following nodes are disjoint from descendants: only those nodes that occur before a node in the document but that are not ancestors of the node are preceding nodes for the node; only those nodes that occur after a node in the document but that are not descendants of the node are following nodes for the node. When moving along from node to node inside the tree (“navigating” the tree), the node where one is currently located is called the context node or self node. Figure 5.1 shows the different classes of nodes from the perspective of the context node self.
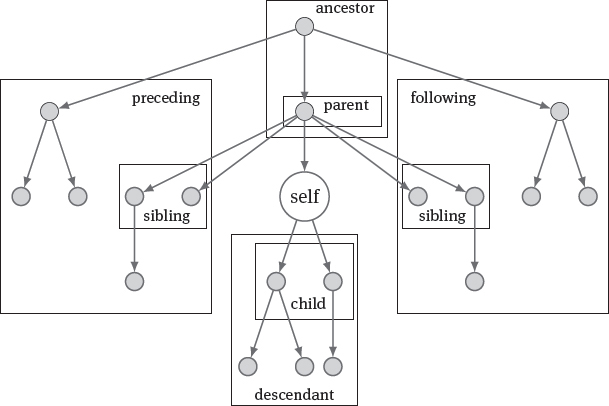
There are two more kinds of nodes: text nodes and attribute nodes. When an element contains text, this text is positioned as a child node of the element node in a special text node. When an element contains an attribute, an attribute node is created for it as a child node of the element; in contrast to text nodes of an element, the text value of an attribute is stored (together with the attribute name) in the attribute node – there is no separate text node for attributes. Figure 5.2 shows the representation of the following example XML document; element and text nodes are drawn as rectangles whereas attributes nodes are drawn as dashed ellipses:
<reservationsystem>
<hotel hotelID=“h1”>
<name> Palace Hotel </name>
<location> Newtown </location>
<roomprice> 65 Euro </roomprice>
</hotel>
</reservationsystem>
Note that this tree-model view of XML documents does not take ID references into account: as an ID reference attribute basically forms a link to a different subtree identified by the matching ID attribute, the data model is no longer a tree. Hence, more generally an XML document can be seen as a directed graph; this graph may even contain cycles – for example, in case we have a bidirectional ID-based reference between two elements with appropriate ID attributes.

5.1.6 Numbering Schemes
Numbering schemes (also called labeling schemes) are important when working with XML documents. A numbering scheme assigns each node of an XML tree a unique identifier (a label or node ID which is usually a number). The simplest way of numbering an XML tree is doing a preorder traversal of the tree and simply increasing a counter for each node. Preorder traversal means that the root node is numbered as the first node before numbering any other node; and this is done recursively for all child nodes. The preorder numbering for our example is shown in Figure 5.3
Another way of traversing a tree is the postorder traversal. The root node is numbered last after all child nodes have been numbered; this way, the postorder numbering starts with the left-most leaf node as the first node with the lowest number while the root node receives the highest number.
Both preorder and postorder traversal can be combined in the so-called pre/post numbering. This combination of the preorder and postorder numbering has some advantages for navigating in the tree: by comparing the preorder and postorder numbering of the context node self with the preorder and postorder numbering of another node w, we can easily determine whether the node w is an ancestor, a descendant, a preceding or a following node of self.
| Navigation rules with pre/post numbering: 1.w ancestor if pre(w) < pre(self ) and post(w) > post(self ) 2.w descendant if pre(w) > pre(self ) and post(w) < post(self ) 3.w preceding if pre(w) < pre(self ) and post(w) < post(self ) 4.w following if pre(w) > pre(self ) and post(w) > post(self ) |


Fig. 5.4. Pre/post numbering and pre/post plane
These rules can conveniently be visualized by drawing a diagram where the x-axis is the preorder numbering and the y-axis is the postorder numbering; this diagram is called the pre/post diagram. Nodes are positioned in the plane according to their pre/post numbering. In Figure 5.4 an example tree is numbered in preorder as well as postorder (here the numbering starts with 1). The pre/post plane of the tree contains all nodes of the tree. Assuming that node d is the context node, all ancestors of d are located in the upper left corner (in this case, node a); all descendants are located in the lower right corner (in this case, node e); all preceding nodes are located in the lower left corner (in this case, nodes b and c); all following nodes are located in the upper right corner (in this case, nodes f and g).
The pre/post numbering has some advantages regarding fast query processing and compact storage. But it also has a major disadvantage: Modifications in the tree (inserting or deleting nodes) are costly because the numbering of several nodes must be altered; this is known as renumbering (or relabeling). One extension of the basic pre/post numbering scheme adds containment information: one can decide more easily whether a node is a descendant of another node. The preorder numbering is stored for each node plus the information of the range of the node; that is, the node ID of the last descendant (the one with the highest node ID) incremented by 1. This encoding clearly makes it easier to determine whether a node is a descendant of some other node because its ID is contained in the range of each of its ancestor nodes. Hence, these extensions run under the name of range-based or interval-based numbering schemes. Another extension adds level information: for each node its level in the tree is stored (where the root node is at level 0, its children at level 1 and so on). This way, siblings can be easily determined because they are on the same level. However both approaches suffer from the renumbering problem, too.

Ultimately, what we need for an effcient storage and management of XML documents is a modification-friendly numbering scheme. More precisely, a numbering scheme should only renumber a minimal number of nodes in the existing tree when a new node is inserted in the tree or an existing node is deleted. Prefix numbering schemes are one step towards modification friendliness: numbering occurs level-wise, and when inserting a node, only siblings of the new node and their subtrees have to be renumbered. The simplest prefix numbering scheme is called DeweyID. Each level of the tree has its own counter (starting from 1); to a level counter, the counters of all ancestors on the path to the root node are prepended (where the dot ‘.’ is used as a separator). This way it is easy to see on which level the node is located and which node is the parent node of the tree. That is, the root node always has node ID 1; the root’s first child has node ID 1.1; the root’s second child has node ID 1.2; and so on. Figure 5.5 shows an example tree with DeweyID numbering.
OrdPath [OOP+04] is an extension of DeweyID where the intial numbering only consists of positive odd integers. Even numbers and negative numbers serve for later insertions into an existing tree. For example, let the initial encoding contain two siblings numbered 1.3 and 1.5; inserting a new sibling in between the two would result in a node ID 1.4.1 for this new sibling. Hence, numbering in OrdPath is a bit ambiguous because although 1.3 and 1.4.1 are on the same level, their numbering depth is different; this makes comparison of node IDs more diffcult.
A further step to avoid renumbering is to use binary strings (instead of numbers) for node IDs as in [LLH08]. These binary strings are then compared lexicographically (instead of numerically). The following property makes binary strings beneficial for numbering schemes: between any two binary strings ending in ‘1’ there is another binary string which is lexicographically between those two; in particular, there is there one such binary string that also ends in in ‘1’. Hence, with binary strings to encode node IDs modifications in the tree can be easily handled because renumbering is reduced. For example, assume a modification wants to insert a new node between a node with ID 4 and a node with ID 5. With integer representation of 4 and 5, it is impossible to find an integer between 4 and 5; hence renumbering would be necessary to do the insertion. However, when representing node labels as binary strings, we can find a binary string in between the two: for example for a node ID 0011 and a node ID 01, a binary string which is lexicographically in between the two would be 01001. As the new number again ends with ‘1’, further insertion would be possible without renumbering. More formally, lexicographical order of binary strings is defined by comparing the two strings from left to right: If one string is a prefix of the other, the prefix is the smaller one (for example, 01 is smaller than 011); if (after a common prefix) one string has a 0 where the other has a 1, the one with the zero is smaller (for example, 0011 is smaller than 01).
5.2 XML Query Languages
Due to the tree-like nature of XML documents, query languages for XML need to offer functionalities to navigate the tree. We briefly survey XPath, XQuery and XSLT which are all mature and established XML query and processing languages.
5.2.1 XPath
XPath is a language for navigating an XML document; modifications of the document are not possible. An XPath query consists of a location path, that is, a concatenation of navigation steps in the tree. A single step has three components – axis, node test and predicate – written in the following notation: axis::nodetest[predicate]. The axis specifies the direction of the step (for example, going from the current context node to a child node); the node test defines the node type or name that the accessed node should have; and the (optional) predicate can be evaluated to true or false and acts as filter for the resulting set of nodes by only considering those nodes in the final result set for which the predicate is true. For example, we could ask for the ID attributes of all those hotels that have the text “Newtown” in their location element.
/descendant-or-self::hotel[self::node()/child::location/ child::text()=“Newtown”]/attribute::hotelID
As XPath queries in full notation are hard to read, several ways to shorten the expressions have been defined. The following query is equivalent to the previous one but uses the shorter notation.
//hotel[./location=“Newtown”]/@hotelID
Note that ‘//’ stands for the descendant-or-self axis, ‘.’ stands for the self axis, ‘@’ stands for the attribute axis, and the child axis as well as the node test node() and text() can simply be dropped.
5.2.2 XQuery
XQuery as a query language has some declarative language features: the for, let, order, where and return clauses; an XQuery query is hence also called a FLOWR expression. With a for clause, we can iterate with a variable over a set of values; with a let clause, we can assign a value to a variable; with a where clause we can specify a selection condition to filter out some parts of the document; with the order clause we can sort the result; and with the return clause we define the structure of the query result. XQuery uses XPath expressions to specify navigational paths in the XML document. In contrast to XPath, XQuery can modify the structure of an XML document. For example, an XQuery expression can add elements or attributes to the query result (which were not present in the input XML document). This is achieved by using these elements or attributes in the XQuery expression. For example, for our reservation system example, we could load the XML document from a file, assign the document to a variable, iterate over the hotel names with a for loop and then output only the hotel names in an XML document with the new elements hotels and hotelname.
<Hotels> {
let $b := doc(“reservationsystem.xml”)
for $a in $b//hotel/name
return
<Hotelname> { $a } </Hotelname>
}
</Hotels>
From a database point of view, the XQuery Update Facility (XQUF) is an important feature that allows for effcient modifications (in particular, insertions and deletions of elements) inside an XML document without the need to load the whole document into main memory and then storing it back to disk after modifications; most interestingly, existing elements can be updated without changing their node IDs. As a simple example, let us change the value of the name element of the hotel node with hotelID set to h1:
let $c := doc(“reservationsystem.xml”)//hotel[@hotelID = ‘h1’]/name return replace value of node $c with (‘City Residence’)
XQuery offers lots of other useful features like user-defined function. In addition, XQuery Full Text (XQFT) offers the capability of full-text search: for example, XQFT queries can ask for substrings, or use language-specific features and stemming of words.
5.2.3 XSLT
XSLT stands for XSL transformation; the eXtensible Stylesheet Language (XSL) is commonly used to define how the content of an XML documents should be formatted and displayed. XSLT as a subset of XSL is used to define how the structure of the input XML document can be transformed into a differently structured XML document or even other data formats like HTML or other textual formats. XSLT supports features like recursion or sorting and hence qualifies itself as a general-purpose transformation tool for different output formats.
XSLT expressions consist of transformation rules that are called templates; inside a template, XPath expressions can be used to navigate to the matching elements. These matching elements in the XML document are processed according to the actions specified inside the XSL template element. For example, an XSL value-of element selects (and outputs) the value of the specified element. In contrast to XQuery, elements that do not match any template are also processed; that is, their attributes and text element contents are part of the output document. To avoid this, by using the asterisk * as the match path in the XSL template, a default behavior can be specified. In other words, this default XSL template is used to match all the remaining elements that do not match any other template; by leaving this template empty, the remaining elements will be ignored and do not show up in the output. Any text or tag in the XSL stylesheet that is not in the xsl namespace will be output as is; this way we can easily introduce new elements in the output document. As a simple example of an XSLT template with match and select part, let us just output the names of all hotels of our reservationsystem XML document under a new root element Hotels: we put each hotel name inside a new Hotelname element and ignore all other elements. We define the string xsl as the namespace for the XSL definitions:
<xsl:stylesheet version=“2.0”
xmlns:xsl=“http://www.w3.org/1999/XSL/Transform”>
<xsl:template match=“/reservationsystem/hotel”>
<Hotelname>
<xsl:value-of select=“name”/>
</Hotelname>
</xsl:template>
<xsl:template match=“*”/>
</xsl:stylesheet>
</Hotels>
5.3 Storing XML in Relational Databases
A relational database system might be used to store XML documents due to several reasons (for example, maturity and well-documented behavior of RDBMSs, licensing issues or supporting legacy applications). In this section, we survey three options for storing XML in a SQL database: (i) the SQL/XML data type for XML data, (ii) schema-based mappings, or (iii) schemaless (also called schema-oblivious or schema-independent) mapping. What we will see in this section is that it is possible to map an XML document to a set of relational tables – as long as the XML document is simply-structured (not too many levels in the tree, not too many optional subelements). However in the general case – for complex hierarchical, sparse and maybe recursive XML documents – this mapping procedure will in general be a tedious process. What is more, joining several tables (using foreign keys) to recompose the original XML document results in performance penalties during query processing. And lastly, document order is important for XML documents (it may be defined in the XML schema defi-nition) and must be preserved in query results. The relational data model however sees data as an unordered set of tuples and hence document order of XML documents mapped to a relational table can only be preserved by storing additional ordering information in the table.
5.3.1 SQL/XML
Several relational database management systems support the XML-related standard of SQL, SQL/XML for short. The main feature is that a data type called XML can now be used to store an entire XML document (or parts of an XML document) as an attribute of a relational table. However, the internal storage structure, the extent to which SQL/XML is supported, and the types of XML query languages supported (in particular, effcient updates with XQUF; see Section 5.2.2) all depend on the RDBMS provider. Internally, an RDBMS can store XML data in a binary format containing the entire document, or in decomposed format distributing the XML content to various tables.
As an example for XML as the data type of a column, consider the case that we store hotel information in a table with a single XML column; each hotel is stored as a separate row in the table:
CREATE TABLE HotelInfos (
hotelData XML
);
INSERT INTO HotelInfos VALUES (
XML( <HOTEL HotelID=“h1”>
<NAME>Palace Hotel</NAME>
<LOCATION>Newtown</LOCATION>
<ROOMPRICE>69</ROOMPRICE>
</HOTEL>
)
);
With the XMLTABLE function a stored XML document can be transformed into relational table format; column names can be specified in the function call to map XML elements (or attributes) to the relational output format. In our example the following statement reads the XML document in the column hotelData from the HotelInfos table and maps the subelements (as well as the ID attribute) of each hotel element to a row and then returns all these values as a new table called Xtable with four columns.
SELECT Xtable.* FROM HotelInfos,
XMLTABLE(‘/hotel’ PASSING HotelInfos.hotelData
COLUMNS
“hotelid” VARCHAR(100) PATH ‘@HotelID’,
“hotelname” VARCHAR(100) PATH ‘NAME’,
“hotellocation” VARCHAR(100) PATH ‘LOCATION’,
“hotelprice” INTEGER PATH ‘ROOMPRICE’,
)AS Xtable
In the opposite direction, the SQL/XML standard also defines some functions that can be used to generate an XML document from data stored in relational tables. Constructors for elements and attributes can be used to obtain an XML fragment with a correct syntax. As an example, assume that we have a table that stores data on persons; the Person table has as columns PersonID, LastName and FirstName. We can access the values in this columns and create an XML element named Personname that contains a concatenation of first and last name (separated by a blank space ‘ ‘); the PersonID is added as an attribute of that element.
SELECT XMLELEMENT ( “Personname”,
XMLATTRIBUTES (p.PersonID AS “pid”),
p.FirstName ||’ ‘ || p.LastName
)
FROM Person p
Assume that a person named Alice Smith it stored in the table with PersonID 1; the output would then contain the XML element for this person:
<Personname pid=‘1’>Alice Smith</Personname>
Several such function calls can be nested to obtain a nested XML document.
5.3.2 Schema-Based Mapping
The schema-based mapping of an XML document to relational database tables first of all processes the XML schema definition: from the given DTD or XML Schema defi-nitions, a database schema is derived that contains the definition of database tables holding the necessary elements and attributes; this is called the schema mapping step. The different tables are linked by foreign key constraints. For example, the table for the XML root element is the base table that contains a primary key – the primary key can later on be used as a foreign key in other tables. Next, subelements must be accounted for in the relational schema. First of all, subelements that can be repeated multiple times inside the same parent element (that is, their number of occurrences is greater than 1) should be mapped to their own tables; here we indeed need a foreign key column to map the subelement to the matching parent element (based on the primary key of the parent table). Moreover, in case the subelements contain subelements on their own, again as primary key the node ID of each element should be stored in a separate column. In contrast, subelements that can occur at most once can be stored as a column in the same table as their parent; this process is called inlining. If this subelement is optional, the content of the column will be null for every parent element which does not contain the subelement. Hence in the relational schema definition, these columns should be nullable to explicitly allow the use of null values, where as – the other way round – required elements and attributes should be not null. Note that in general also the data type has to be mapped: If the XML schema definition contains information on data types, then the data type of the corresponding column must be set to a matching type; if no data type information is given, a default data type for the column must be chosen (for example, a variable-length character string like VARCHAR(255)). Moreover, default values for XML attributes must be mapped into default values for the corresponding columns. So far, with this kind of schema-based mapping, still some information of the original XML document is lost. First and foremost, the XML document order is not fully mapped. While the child-parent relationship is generally maintained because of the foreign key constraints, the sibling order is disregarded. This is why it is not clear for two subelements that belong to the same parent, which of them comes first and which last. If sibling order is important, it can be encoded by additionally storing the node IDs of subelements themselves in a separate column instead of just storing the parent ID as a foreign key. Similarly, XML ID reference attributes must be mapped to foreign key constraints to match the correct XML ID attribute.
We will now look at our example DTD and map it to the corresponding SQL CREATE TABLE statements; while we do consider an ID reference attribute, we refrain from encoding the sibling order (and hence leave out the additional ID attributes).
<!ELEMENT reservationsystem (hotel* booking*)>
<!ELEMENT hotel (name, location, roomprice?)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT location (#PCDATA)>
<!ELEMENT roomprice (#PCDATA)>
<!ATTLIST hotel
hotelID ID #REQUIRED>
<!ELEMENT booking (client)>
<!ELEMENT client (#PCDATA)>
<!ATTLIST booking
bookingID ID #REQUIRED
hotelbooked IDREF #REQUIRED>
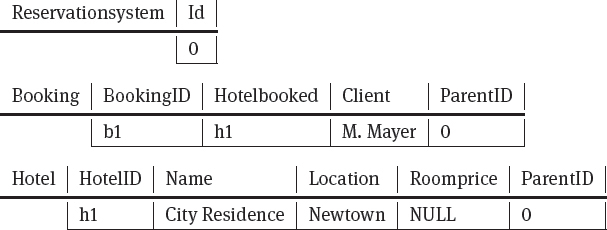
First of all we see that the root element has two subelements (hotel and booking) with multiple occurrences; this is why the subelements will each be stored in their own table with a foreign key to the root element table. Next, we decide how to store subelements of the hotel element. Inside the hotel element, all elements only occur at most once; hence the subelements of hotel are all inlined elements in the same table. The hotelID attribute is defined with a unique not null constraint. Lastly, we decide how to store subelements of the booking element. Inside the booking element the ID reference to the hotel must be modeled by a foreign key to the hotelID. The resulting SQL statements are:
CREATE TABLE Reservationsystem (Id INTEGER PRIMARY KEY);
CREATE TABLE Hotel (HotelID VARCHAR(10) UNIQUE NOT NULL,
Name VARCHAR(20) NOT NULL,
Location VARCHAR(20) NOT NULL,
ParentID INTEGER REFERENCES
Reservationsystem (Id));
CREATE TABLE Booking (BookingID VARCHAR(10) UNIQUE NOT NULL,
Hotelbooked VARCHAR(10) REFERENCES
Hotel (HotelID),
Client VARCHAR(20) NOT NULL, ParentID INTEGER REFERENCES
Reservationsystem (Id));
We reinforce the point that we do not consider sibling order in this example as otherwise node ID columns would have to be added for all elements.
After the definition of the relational schema, the content of the XML document is parsed, tuples are constructed out of it and these tuples are stored in the corresponding tables; this step is called data mapping. As primary keys for the mapped data, a node ID based on a numbering scheme (see Section 5.1.5) can be used. When looking at the following example XML document
<reservationsystem>
<hotel hotelID=‘h1’>
<name> City Residence </name>
<location> Newtown </location>
</hotel>
<booking bookingID=‘b1’ hotelbooked=‘h1’>
<client> M. Mayer </client>
</booking>
</reservationsystem>
the data mapping results in the three tables shown in Table 5.1.
Table 5.1. Schema-based mapping
When evaluating an XML query, the XPath or XQuery expressions have to be translated into SQL statements in a so-called query mapping step. The SQL query has to contain joins based on the foreign keys established in the relational schema to recombine the values from the relational tuples into an XML (sub-)tree. As the tables contain only the data content of the XML document, the XML structure information for the query result (element and attribute names, tree-like structure) must be obtained from the external XML schema definition. As already mentioned, the three mapping steps (schema mapping, data mapping, and query mapping) may turn out to be prohibitively expensive for large, possibly sparse XML documents with a complex hierarchical structure.
5.3.3 Schemaless Mapping
The schemaless mapping of an XML document to relational database tables does not look at an XML schema definition; instead, it used a fixed generic database schema. Basically, the schemaless mapping creates a tuple out of each XML node (element or attribute). More precisely for each node the node type (root node, element node, text node or attribute node), the node name (element name or attribute name), and the node data (for attribute nodes or text nodes) are stored in separate columns. Not all nodes have values for all columns: an element node has no data, and a text node has no name. Hence, the resulting table contains several empty fields (that is, null values). The tree-like structure of the XML document is maintained by storing node IDs (based on a numbering scheme as discussed in Section 5.1.5): The database schema contains a column for the node ID of the component itself and a column for the node ID of the parent node (the parent ID). As an example consider the XML tree with preorder numbering in Figure 5.3. It will be mapped to the table shown in Table 5.2.
XML queries (in particular, the XPath components) have to be translated into SQL queries including self-joins on the generic table. For example, to evaluate a child axis, the node ID of the context node must be matched with the parent ID of the child node. Several other information may be added to the generic schema to speed up query processing; for example, the full path (from the XML root) of each element may be stored to make XPath evaluation more effcient. An obvious disadvantage of the schemaless mapping is that for a large XML document the mapping results in one large relational table containing many null values and requiring costly self-joins for query processing.
Table 5.2. Schemaless mapping
