
5.4 Native XML Storage
Storing XML documents in a format that makes processing it (querying and updating it) effcient is often called native XML storage; database systems that use such an efficient storage format (instead of relational tables) are called native XML databases. Such native XML databases should provide all the features of a general DBMS (see Section 1.1). An additional requirement for native XML storage is round-tripping: when an XML document is stored and later on retrieved, its original structure must be preserved including the document order of all its elements and attributes. Moreover, regarding database access from external programs, some standards have been defined to facilitate access and interoperation with native XML databases: for example, XQJ is the standard XQuery API for Java which allows establishing a connection to an XML database from a Java program. Native XML storage heavily relies on additional data structures that provide extra information about the XML document (like for example different kinds of indexes). Moreover, an advanced management of the memory pages is necessary to split large XML document to multiple pages while still allowing for effcient navigation without wasting too much memory space. Both, memory management and additional data structures, are the main reason for the effciency gain of native XML databases in comparison to other (non-native) storage approaches. We survey index variants and native storage mechanisms in the following subsections.
5.4.1 XML Indexes
Indexes are crucial for an accelerated evaluation of XML queries. Some queries can even be answered by only consulting an index; that is, the stored XML document itself need not be loaded and accessed. Indexes that are particularly useful for XML processing can roughly be categorized into the following types:
Value indexes: A value index maps each content value of attributes and text nodes to a list of node IDs of matching nodes; that is, node IDs of those attribute and text nodes that contain the value. In particular, evaluation of predicates is much faster with a value index. For the example XPath query in Section 5.2.1, the predicate [./location=“Newtown”] can be evaluated by a lookup in the value index resulting in the set of matching node IDs. To answer the example query //hotel[./location=“Newtown”]/@hotelID, starting form the resulting node IDs, the XML document must only be traversed upwards to get the matching location and hotel elements and lastly the corresponding hotelID attribute. Without a value index the whole XML document would have to be traversed in order to check all text nodes of location elements for a match.
Name indexes: A name index maps all element and attribute names to the corresponding node IDs. For example, finding all hotel element nodes anywhere in the document (written as //hotel) can quickly be answered by a lookup of the element name “hotel” in the name index.
Path indexes: A path index maps all unique paths in the XML document to node IDs that match the given path. For example, a mapping to all location element node IDs would be maintained for /reservationsystem/hotel/location. Several extensions of path indexes have been considered: For one, a path index is sometimes called summary index, because some of the paths might coincide and can be summarized into a common representation. Instead of mapping paths to node IDs, the path index might also introduce a dedicated path ID for each indexed path; this path ID can then be used in combination with other indexes. For a more effcient evaluation of some queries, an index can be built for reversed paths. A reversed path does not contain the description of the path from the root down to a node but instead in reversed order: starting from the node and then concatenating all element names on the upward path up to the root node. For example, queries containing a descendant-or-self axis (like //hotel/location) can be answered quickly by looking up in the reversed path index all entries for the reversed path starting with location/hotel/. More generally, a path index may contain additional information for each path that helps answer queries solely with the index – that is, without consulting the XML document. For example, for a small range of short values, the index could directly store the content value of each indexed path ending with an element or attribute node. Storing frequencies of those values allows for answering count queries. If the range of values is too large to store all of them, the index could just store the minimum and maximum values in order to quickly determine that queries asking for values outside the minimum-maximum range have no match.
Join indexes: In an XPath expression, several subexpressions might have to be evaluated independently. In particular, a structural join is the evaluation of a descendant-or-self axis (abbreviated as //) where an arbitrary amount of levels can lie between the ancestor and the descendant. For example, the XPath expression //hotel//location searches for any location elements under any hotel elements in the XML tree: the hotel element might be arbitrarily far away from the root element and the location element might be arbitrarily far away from a hotel element (but inside the subtree starting from a hotel element). A simple structural join algorithm would then have to find all the hotel elements and all the location elements (maybe by using a name index), and then try to find pairs of hotel and location elements for which there is an ancestor-descendant path between them. Several other types of joins might be computed during query evaluation; some index structures (for example, tree-based or stack-based) help evaluate those joins more effciently.
Type indexes: With an XML Schema definition, user-defined types can be speci-fied; indexes may be built for each such type to be able to compare and find element nodes of this type more effciently.
Word-break indexes: A word-break index splits the whole XML document into separate words according to whitespace boundaries (and other special characters like <). This allows for substring (“contains”) queries of whole words.</).
Full-text indexes: A full-text index is an advanced value index that can handle imprecise queries (like for example known from information retrieval). It also indexes content values of attribute or text nodes. Each string value is split into separate tokens (for example, words or n-grams). In addition, the full-text index could provide other options like stemming and language-specific capabilities together with scoring of tokens and other advanced features. Full-text indexes are extremely helpful to quickly evaluate XQuery Full Text (XQFT) queries.
Each such index type provides a sorted maintenance of the indexed values and are usually implemented with specialized data structures (like variants of a so-called B-tree) that allow for a fast search in the index. Whenever the XML document is modified, the indexes have to be updated. Both sorting and updating of indexes are costly procedures that must be implemented with care. For example, upon deletion of an element node, the element’s node ID must be deleted from a name index and any text node of this element must be deleted from a value index; in a path index, the element node must be removed from each corresponding path entry and any additional information (like frequencies of values) have to be modified accordingly.
While indexes greatly improve query processing, they come at the cost of additional management and storage requirements. That is, important points to consider are, for instance, update cost and index size. Which type of index is useful for a certain XML document highly depends on the typical query pattern used – for example, if it is mostly navigational access or full text search.
5.4.2 Storage Management
Similar to relational databases, XML databases have to manage secondary disk space for persistent storage of XML documents. XML documents have to be stored in memory pages (see Section 1.2), because memory pages are the storage unit of secondary disk storage. Hence, as soon as an XML document is larger than a single memory page, the parts of the document have to be distributed among different pages. Loading (parts of) the XML document into main memory and storing pages back to disk is done pagewise and must be effciently handled. Some techniques for an improved page handling are the following:
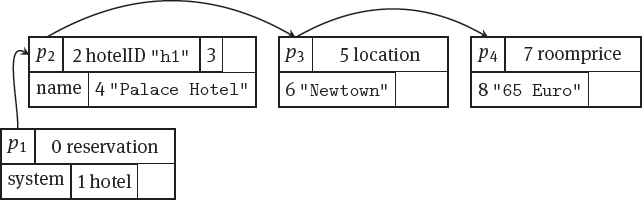
Ordered storage: The XML document is stored into a page where the nodes follow each other in document order; that is, starting from the root node, the document is consecutively stored in memory up until the last leaf node while adding to each node a node ID according to some numbering scheme. An example can be seen in Figure 5.6: The XML tree from Figure 5.3 is stored in document order. That is, each node ID is stored followed by a description of the node (the element or attribute name and/or its value); all node IDs occur in increasing order. When one page is full, a new page is allocated and a link is added from the full page to the new page. In other words, the pages for one document form a linked list; they are called chained pages. By following these links, a forward traversal of the entire document can be done. In the example, page p1 has a link to the next page p2 and so on until the last page p4 is reached. When pages are chained in both directions (one link to the following and one link to the preceding page), both backward and forward traversal are possible.
Clustered storage: The clustered storage groups (that is, “clusters”) elements according to their position in the XML document; each cluster is then stored in a page. This is advantageous when the elements inside a cluster are often processed together. The exact document order can then be reconstructed by the stored node IDs. For example, a cluster can be built for those elements that are 1) in the same level of the XML tree and 2) have the same element name – this approach was implemented in the Sedna XML DBMS [TSK+10]. Queries that have to retrieve nodes of the same name can then be processed quickly because only the page with the appropriate cluster has to be loaded. Chained pages can be used for clusters larger than one memory page.
Subtree extraction: An alternative storage organization is to clip out subtrees of the XML tree and store each such subtree in a separate page. The root node and the remainder of the XML document (the elements that are not part of an extracted subtree) are stored together in one page; links to the appropriate subtree pages are stored there, too. The advantage is that the entire subtree can be processed without loading any other pages, because all subelements are already loaded together with root of the subtree.

Text extraction: Variable-length text values can appear in XML documents, in particular, in text nodes and attribute values. To achieve an effcient parsing of the XML document, it makes sense to store the structural information for an XML document (tree structure of elements and attributes) separate from the content (text node values and attribute values). In particular, large text values can be extracted into a new memory page and only a link to this value is stored in the corresponding position (attribute node or text node) of the document. In the example in Figure 5.7, the value of the text node with node ID 4 is extracted into page p5; only a pointer to this page (depicted by the @-sign) is stored together with node ID 4 in the referencing page p2. The extracted text might itself span multiple pages that can be chained together.
Dictionary: Due to self-descriptiveness, XML documents have often-repeated text parts – like element names that occur multiple times in the same document. A dictionary can be used to store XML documents in a more compact format: each repetitive text part is replaced by a short unique internal placeholder; the dictionary maps each placeholder to the replaced text part and must be stored together with the document. When processing the document, one level of indirection (one look-up in the dictionary) is necessary for re-inserting the replaced text parts in place of the placeholder.
B-tree: An XML document that is stored in ordered storage (with elements sorted according to the document) can be accessed more effciently by using a form of a B-tree. A B-tree is a balanced tree – which is also widely used as an effcient index structure; in general, a B-tree effciently locates a single element in a sorted set of elements. Hence, a B-tree can sort the node IDs of the first node in each page; for a given node ID the page in which the node is stored can be located quickly by following the correct path in the B-tree. Coming back to the example, we see in Figure 5.6 that the first node ID in page p1 is node ID 0, in page p2 the first node ID is 2, in page p3 the first node ID is 5, and in page p4 the first node ID is 7. The corresponding B-tree that sorts these IDs is shown in Figure 5.8. The root node contains the median ID 5. By going to its left child, we find the pages for node IDs between 0 and 4 (that is, less than 5); by going to its right child, we find the pages for node IDs between 5 and 7 (that is, greater than or equal to 5). In the next level of the B-tree we can quickly determine that nodes with IDs 0 and 1 are stored in page p1, nodes with IDs 2 to 4 are stored in page p2, nodes with IDs 5 and 6 are stored in page p3, and lastly nodes with IDs greater or equal to 7 are stored in page p4.

Indirection table vs direct referencing: Usually, references to nodes are done by their node ID. For example, determining a parent, a child or a sibling of a node requires calculation of their node IDs based on the chosen numbering scheme and then determining their memory address (for example by using an indirection table mapping node IDs to memory addresses); this is called indirect ID-based referencing. A quicker traversal which requires no lookup in an indirection table can be achieved by storing inside a node description not only the element name or value of this node but also a set of memory addresses (that is, direct pointers) to parent, child nodes and sibling, respectively. Although direct pointers allow for a much quicker traversal of the XML document, this comes at the cost of more intricate maintenance of these direct pointers: in case the memory address changes, all pointers have to be adjusted in all referencing nodes. In particular, this is critical when links to parent nodes are stored as direct pointers: when the memory address of the parent nodes changes, the pointers inside all children nodes have to be modified accordingly.
When it comes to modifying an XML document, the storage organization in the memory pages is affected. When a new node is inserted, it may often happen that the new node does not fit into the page where it belongs into. In this case, a page split has to be carried out as depicted in Figure 5.9: while some part of the old data remains in the original page pi, a new page pj is allocated to store the remainder of the old data; the new data can then be inserted at the correct position. When pages are chained, a link from the original page pi to the new page pj has to be added, and the link to the page succeeding the original page (say, pi+1) has to be moved to the new page pj.
Replacing a text node value by a longer value may also cause a page split: because the new text is longer, the following page content has to be moved and possibly does not fit on the page any longer. In contrast, a deletion of a node causes a fragmentation of a block: free space remains where the description of the deleted node is removed. A reorganization of pages might be advantageous from time to time to defragment the memory pages. Ideally, memory pages should be filled to nearly 100% even under frequent modifications.

Renumbering of nodes (due to insertion or deletion of nodes) affects usually all other referencing nodes when node referencing is implemented by an indirection table – as well any metadata that use node IDs like the B-tree for effcient page localization. That is why usually native storage relies on another level of indirection: nodes have an internal identifier which is different from the node ID assigned by some numbering schema, because the node ID might change due to renumbering after inserting or deleting nodes from the document tree. The node IDs (assigned by some numbering scheme) are thus used only externally for a higher-level view of the XML document; for referencing a node on the memory-page-level, however, an internal ID is used for each node. The internal ID is assigned to a node uniquely; it is immutable and hence will never change during the existence of the node (even though the external node ID may change due to renumbering) and it will not be reused by any other node. This concept is called identifier stability. Page management, node referencing as well as all indexes can use the internal IDs and are not affected by renumbering issues. To link the external node ID and the internal ID, a mapping between external and internal ID must be maintained in a second indirection table; that is, all accesses on the document which use an external node ID must be accompanied by looking up the internal ID in the indirection table before further processing the access. On average it might be better to accept this additional table lookup for the sake of a more effcient handling of renumbering.
Another issue is storage effciency of node IDs: care must be taken that node IDs do not get too long, because this would increase storage requirements and would complicate node ID management. In general, it easier to handle fixed-length node IDs than node IDs with varying length; when encoding variably-sized node IDs, the length of each node ID has to be stored in each memory page, too. The problem that a node ID requires more storage space than actually planned is termed identifier overflow. An ID overflow is in particular a problem of prefix-based numbering schemes like DeweyIDs because node IDs encode level information and hence longer for nodes at deeper levels. This problem is exacerbated in OrdPath (see Section 5.1.6): OrdPath uses even numbers as markers for an insertion of a node in between two odd numbers which accounts for why OrdPath IDs become exceedingly lengthy after a sequence of node insertions.
5.4.3 XML Concurrency Control
Concurrency of transactions on an XML document is decisive for an effcient and responsive management of large XML documents. Isolation is a crucial property that has to be ensured when an XML document is accessed by concurrent transactions: the different transactions should not interfere with each other. Concurrent accesses by different users (or transactions) on a single XML document should be supported by XML databases in a way similar to how concurrent accesses on relational tables are supported by RDBMSs (see Section 2.5). Concurrency is no problem when the XML document is never modified, that is, when there are only read accesses (that is, queries) to the document. As soon as modifying accesses (that is, updates) are allowed, concurrency control is needed. Updates can consist of editing, inserting, moving or deleting nodes in the XML tree. Editing a node means changing the name of an element or an attribute node or changing the content value of a text or attribute node. This kind of editing affects other users working concurrently on the same node: when one user edits a node which another user is reading, the edited node might not match the second user’s query anymore; when two users edit at basically the same time, it is not obvious which of the two modifications should be persisted. Inserting a node can happen anywhere in the tree. The easiest case is adding a leaf node: adding a node in between two nodes as a new sibling; but even in this simple case, the insertion might be in conflict with a read access. See Figure 5.10 for an example: when a read access iterates over all child nodes of node x while concurrently a new child node y is inserted, the inserted child y is not covered by the iteration.
More generally, insertions of internal nodes (that is, non-leaf nodes) can be done along any path in the tree; this case is more complicated as it would require renumbering of several affected nodes. Even a new root node can be added which would require a renumbering of the whole XML tree; from a concurrency control point of view, all other users working concurrently on the XML document would be affected by such an insertion. Moving nodes happens when a subtree is moved to a new position in the XML tree, the subtree itself is however not modified. Deleting nodes is also an intricate problem: when one user deletes a node, another user might currently be reading the deleted node; see Figure 5.10 for an illustration where a query reads the child nodes of x while concurrently this node is deleted. Similar to node insertions, node deletions can also lead to renumbering of parts of the tree and hence affect other users working concurrently on the tree. Particularly important for XML concurrency control is support for multi-lingual accesses on the same XML document. That is, if an XML databases supports different access methods, concurrent execution should be possible independent of the access method used – for example, one XQuery execution in parallel with a DOM-based access.

As can be seen from these examples, concurrency control is more intricate for tree-shaped XML documents than for the flat relational data model. Concurrency control on XML documents can be optimistic or pessimistic as for relational database systems (see Section 2.5). One form of pessimistic concurrency control is lock-based concurrency control. As XML documents correspond to a tree-like structure, XML locks are substantially different from the read-only locks and read-write locks on data items known from relational concurrency control (as for example the 2PL protocol). Different locking protocols for XML have been proposed; these can further be divided into node-locking and path-index-locking protocols.
Node-locking protocols put locks on single nodes or subsets of nodes in the XML tree.
Path-index-locking protocols put locks on path indexes that are maintained to speed up query evaluation.
Let us have a closer look at node-locking protocols; they might implement some of the following kinds of locks.
Node locks: Node locks are locks on individual nodes in the tree. Node locks can have different subtypes depending on whether the content of the node is accessed (read, modified, inserted, deleted) or whether merely a node test for existence (for example existence of an element with a certain name) is executed. It enhances concurrency to distinguish such access modes, that is, have different locks depending on whether the node content is accessed, or whether merely its existence is checked with a node test. A node lock is a lock of finest granularity; that is, there is no smaller unit on which a lock can be put.

Subtree locks: To lock all descendants of a node, subtree locks can be used. That is, entire subtrees can be locked by putting a lock on the root of the subtree. This avoids the need to put a lock on every single node in the subtree. Hence, a subtree lock provides coarser granularity than a node lock.
Child locks: A child lock locks a node together with all its direct child nodes. This is helpful when a node is accessed followed by an iteration over all direct children of the node.
Edge locks: Edge locks are locks for navigation in the tree along the axis like ancestor, descendant, following, or preceding.
These locks can be shared (to allow for concurrent reads) or exclusive (to allow for modifications without interfering with other accesses). When using a locking-based protocol, a compatibility matrix then shows which locks are compatible with other locks – and the other way round: which lock combinations are prohibited and hence which accesses have to be postponed until conflicting locks are released. Intention locks are a further special kind of locks: when an exclusive lock is put on a node, all ancestor nodes of this node receive an intention exclusive lock to denote the fact that a modification will take place in a subtree; this is necessary to avoid conflicting locks with coarser granularity than the one used for the exclusive lock. In a similar way, intention shared locks can be defined.
Moreover, it is important to handle locks at a low granularity: The less nodes are in the scope of a lock, the more concurrent transactions are possible. The process of lock escalation allows for a flexible adaptation of the granularity: for example, if many single nodes inside a subtree are already locked by one transaction, it is usually more effcient to obtain a single lock for the whole subtree (instead of managing all the individual node locks). And similarly it might be better to lock the whole document when several subtrees inside the document are already locked by the same transaction.
5.5 Implementations and Systems
Several tools for editing and processing XML data are available. From the database perspective two main open source systems are eXistDB and BaseX.
5.5.1 eXistDB
The eXist database is a Java-based open source XML database.
| Web resources: –eXistDB: http://exist-db.org/ –documentation page: http://exist-db.org/exist/apps/doc/ –GitHub repository: https://github.com/eXist-db/exist |
Internally it uses a tree representation of the XML document with a numbering scheme that virtually expands the tree into a complete tree such that not all node IDs correspond to existing nodes; in this way, there is room for additions in the tree using the virtual node IDs. A system lookup table maps nodeIDs to physical addresses. eXistDB backs up its search functionality by several index structures, the following indexes are supported:
–structural index: it maps element and attribute names (more precisely their internal qualified names) inside a collection to document IDs and node IDs. This index is used whenever an element name or attribute name is looked up in an XPath query.
–full-text index: the full-text index uses Apache Lucene that by default splits text around whitespaces as well as tags; it can be defined on an individual element or attribute name or on an entire path.
–n-gram index: it indexes ngrams of text data: data strings are split into overlapping sequences of n (by default three) characters. This index enables effcient substring searches.
–spatial index: an experimental spatial index enables searches in geometries described in the Geography Markup Language (GML).
–range index: it indexes text nodes and attributes based on the data type of the stored value; this makes comparison operations more effcient. The range index is also based on Apache Lucene.
Settings for indexing are maintained in configuration files. Recently, eXistDB has added support for arrays (and in particular nested arrays) in response to the XQuery 3.1 Candidate Recommendation. In particular, JSON documents can be represented as a mixture of maps (containing key-value pairs) and nested arrays; for example:
let $persons := [
map {
“firstName”: “Alice”,
“lastName” : “Smith”,
“age”: 31,
“address”: [
map {
“street”: “Main Street”,
“number”: 12,
“city”: “Newtown”,
“zip”: 31141
}
]
}
]
eXistDB offers several user APIs:
–RESTful API: XQuery and XPath queries are specified using a GET statement with optional parameters; for example for finding the lastnames of all persons with firstname Alice:
http://localhost:8080/exist/db/personcollection?_query=//lastname[firstname=%22Alice%22]
Stored XQueries can be called in a GET or PUT request; the queries will then be executed on server-side.
–XML:DB API: Java applications can use the XML:DB API to interact with eXist. First of all, a database driver has to be used to instantiate a new database object. This database object has to be registered with the database manager class, which in turn can be used to open a collection. Afterwards, XML documents can be retrieved as resources from the database:
try{
Class driver = Class.forName(“org.exist.xmldb.DatabaseImpl”);
Database existdb = (Database) driver.newInstance();
DatabaseManager.registerDatabase(existdb);
Collection collection=DatabaseManager.getCollection(“xmldb:” +”exist://localhost:8080/exist/db/personcollection”); XMLResource resource =
(XMLResource)collection.getResource(“persons”); System.out.println(resource.getContent());
}
catch (Exception e){}
finally {
if(resource != null) {
try {
((EXistResource)res).freeResources();
}
catch(XMLDBException xe) {}
}
if(col != null) {
try { col.close(); } catch(XMLDBException xe) {}
}
–XML-RPC API: The XML Remote Procedural Call API can be used with an object of type XmlRpcClient that can execute methods on the database server.
–SOAP API: eXistDB uses the Apache Axis SOAP toolkit in a servlet to offer the SOAP interface.
5.5.2 BaseX
BaseX is a native Java-based XML database that stores XML documents in a tabular representation. BaseX supports full-text search with additional scoring functions and thesauri as well as fuzzy text search based on the Levenshtein distance between words.
| Web resources:
–BaseX: http://basex.org/ –documentation page: http://docs.basex.org/ –GitHub repository: https://github.com/BaseXdb |
BaseX implements the Pre/Dist/Size encoding of each node [KGGS15] to facilitate navigation in the XML tree: The Pre value is the preorder number of the node, the Dist value is the difference between the Pre value of the node to its parent node, the Size value is the amount of descendants nodes plus the node itself. This means that the preorder number of the parent node can be derived from the preorder number of the context node and its Dist value:
pre(parent) = pre(self ) − dist(self )
The preorder number of all descendants of the self node lie in between pre(self ) + 1 and pre(self ) + size(self ) − 1.
Several serialization methods are offered including methods to serialize XML documents into CSV or JSON format as well as to import these formats. Regarding the handling of JSON documents, BaseX offers several transformation options:
–direct conversion: The direct conversion results in a lossless transformation of JSON documents into XML and back. It creates a <json> element as the root. For each key part (of a JSON object) a new element is created. Attributes called type are added to specify that an element corresponds to a certain JSON type (string, number, boolean, null, object or array). Arrays have an empty key that is represented by an element with the name _ (underscore).
–attributes conversion: The attributes conversion is another lossless transformation. It creates a <json> element as the root. Objects (key-value pairs) are converted into a <pair> element in which the key part is stored as an attribute called name. Array entries are represented as several <item> elements. The value parts are all stored as separate text nodes again with an attribute type specifying the JSON type.
–other conversion types are map conversion (transforms a JSON document into an XQuery map), basic and JsonML.
Several language bindings as well as a REST API, an XQJ API and a XML:DB API (only in standalone mode) are offered. For example, the BaseXClient class is offered in the Java API with which a session can be created and queries can be sent to the database. The Geo Module can handle data according to the Open Geospatial Consortium (OGC) Simple Feature (SF) data model.
Indexes available in BaseX are:
–name index: containing all the names of elements and attributes. – path index: containing all distinct paths in the XML documents which is useful when optimizing queries.
–resource/document index: referencing the Pre values of all document nodes hence facilitating access to certain document.
–text index: containing all text nodes and hence used in evaluating equality tests or range queries on text values.
–attribute index: containing all attribute texts and hence speeding up equality tests or range queries on attribute values.
–full-text index: containing all text values and used during the evaluation of contains text queries.
5.6 Bibliographic Notes
XML is an established standard of the World Wide Web Consortium [Gro08]. Due to its long-standing nature, most relational database systems offer the XML data type and support at least one XML query language. Mappings of XML data to relational tables (or from XML schemas to relational schemas) have been proposed and analyzed in several approaches; some of them can be found in [STZ+99, LC01, TVB+02, ACL+07].
Several native XML databases are available; yet they differ in the offered features like support for XML query languages, support for XML updates, or indexing techniques.
Numbering schemes and the renumbering effects of updates have been formalized in a variety of prior work for example in [FM12] or using the pre/post numbering in [Gru02]. The Ordpath numbering was introduced in [OOP+04]. A recent overview and an order-centric comparison is given in [XLW12]. Notably, there are only few numbering schemes that avoid renumbering of nodes in case of updates: the work of Li, Ling and Hu [LLH08] proposes a certain binary encoding for node IDs together with lexicographic ordering; whereas O’Connor and Roantree [OR13] introduce a numbering scheme based on the Fibonacci numbers.
Different XML concurrency control approaches including locking have been studied and surveyed for example in [JC06, PK07, BHH09, SLJ12]. Query optimization for XML queries is another well-studied topic. In particular, different indexing mechanisms can be used to speed up XML processing; see for example [WH10].