
15 Concluding Remarks
NOSQL data stores excel with their distribution features and the schemaless storage of data. However, given the huge variety of modern data stores and data management systems, a major question for a production environment remains: which system is the best choice for the application at hand? Moreover, several steps are necessary to transfer a legacy application to support new data models, new query languages and new access methods and hence to fully integrate the new data store with the existing application. In this chapter we provide a discussion on the consequences that might ensue from changing the data models or precautions that must be taken to smoothly integrate the novel systems. In addition, we survey approaches to enable polyglot database architectures: database and storage systems that integrate multiple data models into a common framework.
15.1 Database Reengineering
The notion of database reengineering covers all the aspects that are involved with restructuring existing data management solutions and migrating data to new data stores. It also includes the impact that a change of the data management level can have on applications or users accessing the data store. A database reengineering process can be seen as a special case of a general software engineering project. It hence requires an appropriate project lifecycle management that supports the different phases of the project; such phases can for example comprise (following the “lean and mean” strategy of [RL14]):
Migration planning: The planning phase should clarify all constraints and requirements involved in the reengineering process – including business goals, time constraints, budget, and volume of migrated data – as well as analyze potential risks.
State Analysis: This analysis phase first of all determines the state of the legacy system in terms of data model and used technology as well as all dependencies to external applications. Next the projected state of the future system should be assessed in detail.
Gap Analysis: This analysis phase should identify the differences (that is, the “gaps”) between the legacy and the future system states. It should also investigate which steps are necessary to fill these gaps.
Data Analysis: In this phase a more detailed analysis of the future data model is due. It should assess future access requirements on the data. Based on this and the previous phases, the future data model is chosen.
Data Design: This phase comprises an in-depth design of the future data model. Even for schemaless data stores, a so-called implicit schema must be derived as an interface for all external applications.
Data Model Transformation: In this phase a transformation on the model level is executed. Formal schema mapping rules can be obtained.
Data Conversion: This activity comprises the conversion of the legacy data set into the future data set. Ideally, this can be a fully automated process; yet errors can occur due to inconsistencies or invalidity of the legacy data set.
Data Validation: Before the actual migration process is executed and production systems are switched to the new data store, a validation of the converted data set is due. This step ensures correctness of the converted data and hence can avoid unwanted rollbacks.
Data Distribution: This phase includes the final migration to the new data store. For a large data set, it is useful to split the data set into several subsets and to subsequently execute a step-wise (incremental) migration on the smaller data sets.
Data migration is only one side of the coin. Another major activity is adapting the data access layer of legacy systems to the new data management layer. This in particular involves translating and rewriting queries.
15.2 Database Requirements
When choosing the appropriate data store in the Data Analysis phase of the database reengineering process, several characteristics of the target data store must be considered. Due to the diversity of modern data stores, choosing a data store requires looking carefully at the requirements the store should fulfill in order to comply with legacy applications as well as future demands. Here we survey some decisive features:
Data model: Which data model is suited best for the raw data (for example nested and hierarchical data)? Which data model requires only minimal and error-free transformation operations for converting the raw data into data records of the data model? Is referencing from one data record to another data record supported? Is a normalization of the data required to allow for non-redundancy in the data; or is some duplication of data acceptable to reduce complexity of the data model?
Data types: Does the data store support the needed basic data types (for example a date type of sufficient granularity)? Does it support container types (likes lists, sets or arrays)? Can database users extend the type system and define their own data types?
Database schema: Is schemaless of schema-based storage needed? How is schema information stored? Can schema information automatically be generated for a given set of records? Is schema validation offered – or even an advanced constraint checking mechanism with active triggers? Is referential integrity supported that checks whether referenced data records exist in the data store? How easy is it to implement schema evolution with the data store? Which kinds of schema change require a restart of the data store? Schemaless storage is not always a good option: an implicit schema must be agreed upon by accessing applications; hence, schema changes also require consolidation at the application level. Lastly, without an explicit schema, storage or query optimizations are harder to implement.
Operating System support: Which operating system does the data store run on? Does the database system integrate well with the existing infrastructure?
Tools and APIs: How well does the database integrate with existing applications or development environments? Are there extra tools for development, visualization, or maintenance? Are all necessary APIs (like REST-based access) offered?
Query languages and expressiveness: Which programming languages or query languages are supported? Can the queries of all accessing applications be expressed in the query language? Does the data store support advanced operations (for example, joins or link walking) to avoid additional data processing at the application side? With such advanced operations complexity of the accessing application can be reduced. Are transactions needed – and which is the scope of the transaction support (for example, only single record-based transactions, read-only transactions versus full-blown read-write transactions)? Are aggregation operators necessary to allow for analytical queries?
Standard support: Does the database adhere to standards in terms of persistence (like for example, JPA compliance)? Does it support standardized query languages so that portability of query code (both data manipulation and data definition operations) is possible and provides some kind of platform independence?
Search and retrieval: How does the database support search on data records? Is full-text search available? Which kinds of indexes are supported to speed up search?
Versioning: Is it necessary that multiple versions of the same data record can be maintained to allow for an analysis of how data have evolved over time? How can different versions of a data record be accessed?
Workloads and performance: What kind of workload is expected to run on the data store? Should the data store be read-optimized (and hence better support read-heavy workloads) or should it be write-optimized (with a better support for write-heavy workloads)? Are usually individual data values accessed and updated directly or is sufficient to support only aggregation-oriented writes and reads (like reading and writing an entire JSON document)?
Concurrency: How is concurrency handled? If a lock-based concurrency control is employed: how fine-grained can this locking be configured; what is the level of locking employed? If multiversion concurrency control is implemented, how are conflicts resolved? Does the concurrency control approach comply with the requirements of the accessing applications?
Distribution and scalability: Is a distributed data store required? How well does the data store support a distributed installation? How does the system handle churn (additions and removals of servers)? Does it support automatic partitioning (“auto-sharding”) of the data? Is replication supported – and if so is multi-master or master-slave replication more appropriate? Can the system support distributed counters that can be auto-incremented among the database servers? Consistency: Which consistency level is provided? Can consistency be configured on a per-query basis? How failure-tolerant is the system and what is the failure model supported by the system?
Maturity and support: Is a commercial data store or a commercial support needed? In case of open source systems, how can a lack of community support and major changes in the APIs be handled?
Security: Are security mechanisms required? Is role-based access control supported and how are users authenticated? Can access to certain records in the database be restricted by an access control policy? Is a form of encryption offered?
15.3 Polyglot Database Architectures
When designing the data management layer for an application, several of the identified database requirements may be contradictory. For example, regarding access patterns some data might be accessed by write-heavy workloads while others are accessed by read-heavy workloads. Regarding the data model, some data might be of a different structure than other data; for example, in an application processing both social network data and order or billing data, the former might usually be graph-structured while the latter might be semi-structured data. Regarding the access method, a web application might want to access data via a REST interface while another application might prefer data access with query language. It is hence worthwhile to consider a database and storage architecture that includes all these requirements.
15.3.1 Polyglot Persistence
Instead of choosing just one single database management system to store the entire data, so-called polyglot persistence could be a viable option to satisfy all requirements towards a modern data management infrastructure. Polyglot persistence (a term coined in [FS12]) denotes that one can choose as many databases as needed so that all requirements are satisfied. Polyglot persistence can in particular be an optimal solution when backward-compatibility with a legacy application must be ensured. The new database system can run alongside the legacy database system; while the legacy application still remains fully functional, novel requirements can be taken into account by using the new database system.

Polyglot persistence however comes with severe disadvantages:
–there is no unique query interface or query language, and hence access to the database systems is not unified and requires knowledge of all needed database access methods;
–cross-database consistency is a major challenge because referential integrity must be ensured across databases (for example if a record in one database references a record in another database) and in case data are duplicated (and hence occur in different representation in several databases at the same time) the duplicates have to be updated or deleted in unison.
It should obviously be avoided to push the burden of all of these query handling and database synchronization task to the application level – that is, in the end to the programmers that maintain the data processing applications. Instead it is usually better to introduce an integration layer (see Figure 15.1). The integration layer then takes care of processing the queries – decomposing queries in to several subqueries, redirecting queries to the appropriate databases and recombining the results obtained from the accessed databases; ideally, the integration layer should offer several access methods, and should be able to parse all the different query languages of the underlying database systems as well as potentially translate queries into other query languages. Moreover, the integration layer should ensure cross-database consistency: it must synchronize data in the different databases by propagating additions, modifications or deletions among them.
15.3.2 Lambda Architecture
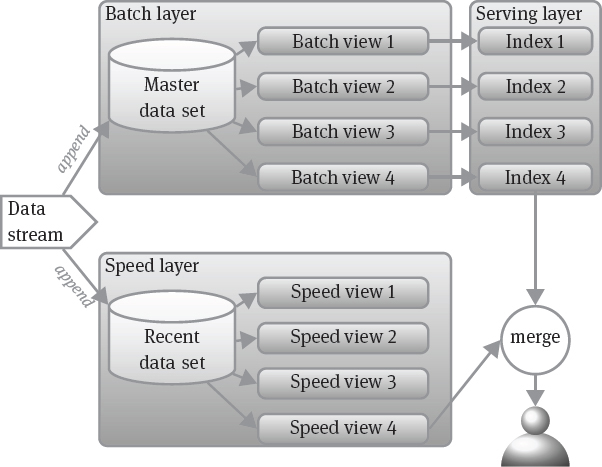
When real-time (stream) data processing is a requirement, a combination of a slower batch processing layer and a speedier stream processing layer might be appropriate. This architecture has been recently termed lambda architecture [MW15] (see Figure 15.2). The lambda architecture processes a continuous flow of data in the following three layers:
Speed Layer: The speed layer collects only the most recent data. As soon as data have been included in the other two layers (batch layer and serving layer), the data can be discarded from the speed layer dataset. The speed layer incrementally computes some results over its dataset and delivers these results in several real-time views; that is, the speed layer is able to adapt his output based on the constantly changing data set. Due to the relatively small size of the speed layer data set, the runtime penalty of incremental computations are still within acceptable limits.
Batch Layer: The batch layer stores all data in an append-only and immutable fashion in a so-called master dataset. It evaluates functions over the entire dataset; the results are delivered in so-called batch views. Computing the batch views is an inherently slow process. Hence, recent data will only be gradually reflected in the results.
Serving Layer: The serving layer makes batch views accessible to user queries. This can for example be achieved by maintaining indexes over the batch views.
User queries can be answered by merging data from both the appropriate batch views and the appropriate real-time views.
15.3.3 Multi-Model Databases
Relying on different storage backends increases the overall complexity of the system and raises concerns like inter-database consistency, inter-database transactions and interoperability as well as version compatibility and security. It might hence be advantageous to use a database system that stores data in a single store but provides access to the data with different APIs according to different data models. Databases offering this feature have been termed multi-model databases. Multi-model databases either support different data models directly inside the database engine or they offer layers for additional data models on top of a single-model engine. Figure 15.3 shows an example multi-model database with a key-value store as the main engine and a graph layer on top of it.
Several advantages come along with this single-database multi-model approach:
–Reduced database administration: maintaining a single database installation is easier than maintaining several different database installations in parallel, keeping up with their newest versions and ensure inter-database compatibility. Configuration and fine-tuning database settings can be geared towards a single database system.
–Reduced user administration: In a multi-model database only one level of user management (including authentication and authorization) is necessary.
–Integrated low-level components: Low-level database components (like memory buffer management) can be shared between the different data models in a multi-model database. In contrast, polyglot persistence with several database systems requires each database engine to have its own low-level components.
–Improved consistency: With a single database engine, consistency (including synchronization and conflict resolution in a distributed system) is a lot easier to ensure than consistency across several different database platforms.
–Reliability and fault tolerance: Backup just has to be set up for a single database and upon recovery only a single database has to be brought up to date. Intradatabase fault handling (like hinted handoff) is less complex than implementing fault handling across different databases.

–Scalability: Data partitioning (in particular “auto-sharding”) as well as profiting from data locality can best be configured in a single database system – as opposed to more complex partitioning design when data are stored in different distributed database systems.
–Easier application development: Programming efforts regarding database administration, data models and query languages can focus on a single database system. Connections (and optimizations like connection pooling) have to be managed only for a single database installation.
15.4 Implementations and Systems
The systems surveyed here are a polyglot data processing system, a real-time event processing framework as well as two multi-model database systems.
15.4.1 Apache Drill
Apache Drill is inspired by the ideas developed in Google’s Dremel system [MGL+10].
| Web resources:
–Apache Drill: http://drill.apache.org/ –documentation page: http://drill.apache.org/docs/ –GitHub repository: https://github.com/apache/drill |
Apache Drill’s aim is to support several storage sources that are connected to Drill by storage plugins. These plugins provide an interface to the data sources as well as query optimization rules for the specific query languages. The two main principles in Drill (and Dremel) to achieve a high performance are:
Move code not data: instead of transmitting large amounts of data to the servers with appropriate processing routines, the data remain on the storage servers. Each query is decomposed into a multi-level execution tree where the subqueries lower in the tree (and closer to the data) process the data on the storage servers.
Process data “in situ”: Data transformations (between different encodings or formats) are avoided by providing native query execution routines for the attached data stores.
Data sources can be database systems but also files in a distributed file system: Drill supports plain textual formats with a flat structure (comma-separated, tab-separated or pipe-separated files) as well as textual formats with more complex structures (JSON, Avro or Parquet files).
Several service processes called Drillbits accept requests from clients, process the data, and return the results. The Drillbit that handles a specific client request is called the foreman for this query. Its main task is to parse the incoming SQL query and obtain a logical execution plan for it (containing several logical operators). In a next step, this logical plan is optimized for example by swapping some operators. After the optimization a physical plan is obtained that describes how and with which data sources which part of the query should be answered. The physical plan is then converted into a multi-level execution tree where the leaf operators of the tree can be run in parallel on the appropriate data sources. The leaf operators then obtain partial results based on executing their subquery on the appropriate data sources. As the partial results move back up the tree (towards the root), the data of different sources are exchanged and combined (for example, aggregated). Data type conversions from the data types specific to the database system or file format into SQL data types have to be executed before passing the results back up the tree. Drill can process nested data in a schemaless way. An internal schema is obtained while reading in the data; this process is called schema discovery.
Apache Drill implements some extensions to SQL in order to be able to handle self-describing, nested data in different formats. Drill’s SQL dialect uses backticks to quote terms that would otherwise be interpreted as reserved keywords in SQL or to quote file paths.
As an example consider a selection query on a file in the distributed file system (DFS). The storage plugin used in the query is called dfs and a comma-separated (CSV) file is accessed by specifying the path and file name. Drill splits the comma-separated values in each line into an array of columns that can be addressed by an index (starting with 0). Assume we query a CSV file containing a pair of book identifier and book title (separated by a comma) in each line of a file called books.csv:
SELECT COLUMNS[0] as ID, COLUMNS[1] as Title FROM dfs.ʻ/books.csvʻ;
A query can also be applied to a directory: in effect, the query will be executed on all files in a directory and the output will contain the relevant values from all files. All these files however have to be compatible; for example, in CSV files the columns must be of the same type in all files and occur in all files in the same order. Drill can also work with a directory hierarchy: if a query is executed on a directory containing subdirectories (which themselves may again contain subdirectories), Drill will descend into the subdirectories, execute that query on the files located there and aggregate the results of all subdirectories. Several functions can be used in a query to exactly tell Drill which subdirectories it should descend into.
15.4.2 Apache Druid
Druid offers the functionality to merge real-time and historical data.
| Web resources:
–Apache Druid: http://druid.io/ –documentation page: http://druid.io/docs/0.8.0/ –GitHub repository: https://github.com/druid-io/druid |
Worker nodes in the Druid architecture are divided into real-time nodes and historical nodes. Real-time nodes can process streams of data while batches of data can be loaded into the historical nodes. Druid can be backed up by so-called”deep storage” to enable long-term persistence of the data. The data format processed by Druid in the real-time nodes are JSON files; the historical nodes can process JSON as well as CSV (comma-separated) or TSV (tab-separated) data. More precisely, a data item processed in Druid is a timestamped event. A segment is a group of such events for a certain period of time. Each event is represented by a data record consisting of a timestamp column, several attributes called dimension columns as well as several attributes called the metrics columns. The format of the input events have to be declared in a so-called input specification by providing schema information – in particular, the names and types of the columns. In the real-time nodes, several events can then grouped by timestamp or a subset of the dimensions; next, data in the groups can be processed further – for example, counting the size of each grouping; or aggregating (for example, summing) over the metrics columns for each group; or otherwise filtering the data (for example, with selection or pattern matching).
Real-time nodes keep data (for a certain time segment) in an index structure; these index structures are periodically transfered to the deep storage. From the deep storage the data can be loaded into the historical nodes where they are immutable (that is, read-only). Druid stores data in a column-oriented way to enable column compression and data locality. Broker nodes are the ones responsible to handle client requests; this includes relaying requests to multiple real-time or historical nodes as well as aggregating partial results before returning results to the client. Coordinator nodes manage data distribution among historical nodes.
15.4.3 OrientDB
As a multi-model database, OrientDB offers a document API, an object API, and a graph API; it implements extensions of the SQL standard to interact with all three APIs. Alternatively, Java APIs are available. The Java Graph API is compliant with TinkerPop (see Section 4.6.1).
| Web resources:
–OrientDB: http://orientdb.com/ –documentation page: http://orientdb.com/docs/last/ –GitHub repository: https://github.com/orientechnologies/ |
Classes describe the type of a record. Classes can be explicitly created as an OClass object in the database schema and inheritance is supported where the superclass must also be registered in the schema:
OClass person = db.getMetadata().getSchema().createClass("Person");
OClass employee = db.getMetadata().getSchema()
.createClass("Employee").setSuperClass(person);
Records are organized into clusters (by default one cluster per class). In OrientDB, each record (document, object, vertex or edge) is identified by a recordID of the form #<cluster-id>:<cluster-position> that represents the physical position of the record in the database. Records can be linked by storing the recordID of the target record in the source record; this avoids joins (based on IDs) as well as embedding. The APIs offered by OrientDB are the following:
Graph API: The graph API offers commands to create vertices and edges with properties as follows where V and E are the default vertex and edge classes, respectively:
CREATE VERTEX V SET name = ʾAliceʾ
Output: Created vertex with RID #13:1
CREATE VERTEX V SET name = ʾBobʾ
Output: Created vertex with RID #13:2
CREATE EDGE E FROM #13:1 TO #13:2 SET knows_since = ʾ2010ʾ
To obtain custom vertex and edge classes, V and E can be extended.
For example, a new friend class can be obtained for edges and a new friend edge created as follows:
CREATE CLASS Friend EXTENDS E
CREATE EDGE Friend FROM #13:1 TO #13:2
Traversing the edge can be done by calling the in (incoming edges), out (outgoing edges) or both (bidirectional edges) functions; for example, Alice’s friends can be obtained:
SELECT EXPAND( OUT( ʾFriendʾ ) ) FROM Person WHERE name = "Alice"
Edges without properties can be stored as lightweight edges that do not have a record identifier but are stored as a link to the target vertex in the source vertex. Document API: The document API is Java-based. A document database can be opened within a transaction ODatabaseDocumentTx by specifying a URL; the URL determines whether the database is in-memory (memory:), embedded in the Java application (plocal:) or running on a remote server (remote:). The open method accepts a username and a password as strings. When the database is closed, all resources will be released. The ODocument class represents a JSON document in the database. It can be created, its fields can be set and then it can be saved. For example, we can create a person document in an embedded database called persondb as follows:
ODatabaseDocumentTx db =
new ODatabaseDocumentTx("plocal:/persondb");
db.open("user", "password");
try {
ODocument alice = new ODocument("Person");
alice.field( "firstname", "Alice" );
alice.field( "lastname", "Smith" );
alice.field( "age", 31 );
alice.save();
} finally {
db.close();
}
Note that Person is the class name for the new document. The database offers methods to iterate over all documents for a class (browseClass) and over all documents stored in a cluster (browseCluster).
SQL queries can be passed to the database by calling the query() method and passing an OSQLSynchQuery object with a SQL string.
List<ODocument> result = db.query(
new OSQLSynchQuery<ODocument>("select * from Person
where firstname = ʾAliceʾ"));
OrientDB also supports asynchronous queries (where instead of collecting all results a result listener returns result records step by step), non-blocking queries (so that the thread does not wait for the answer) and prepared queries (that accept various parameters).
SQL commands (like updates) can be passed to the database by calling the command() method and passing an OCommandSQL object with a SQL string:
int recordsUpdated = db.command(
new OCommandSQL("update Person set lastname = ʾMillerʾ
where firstname = ʾAliceʾ")).execute();
Object API: Internally, OrientDB uses a mapping of objects into documents. When reading in objects, they are constructed from the documents by using Java Reflection. That is why each persisted class has to provide an empty constructor as well as getter and setter methods for its non-transient and non-static fields.
An object database can be opened within a transaction OObjectDatabaseTx by specifying a URL and then opened. Immediately after opening, an entity manager must be notified which objects are persistent; this registration can be done for individual classes or entire packages. A non-proxied object is one that does not have a representation in the database; a proxied object is one represented in the database. With the newInstance method, an object will be created that is immediately proxied.
OObjectDatabaseTx db = new OObjectDatabaseTx("plocal:/persondb");
db.open("user", "password");
db.getEntityManager().registerEntityClasses(Person.class);
try {
Person p = db.newInstance(Person.class);
p.setFirstname("Alice");
p.setLastname("Smith");
p.setAge(31);
db.save(p);
} finally {
db.close();
}
If instead the object is created with the usual constructor, it will only be proxied after calling the save method; then a proxied version of the object is returned that should be reassigned to the old (non-proxied) reference:
OObjectDatabaseTx db = new OObjectDatabaseTx("plocal:/persondb");
db.open("user", "password");
db.getEntityManager().registerEntityClasses(Person.class);
try {
Person p = new Person();
p.setFirstname("Alice");
p.setLastname("Smith");
p.setAge(31);
p = db.save(p);
} finally {
db.close();
}
15.4.4 ArangoDB
ArangoDB is a multi-model database with a graph API, a key-value API and a document API. Its query language AQL (ArangoDB query language) resembles SQL in parts but adds several database-specific extensions to it.
| Web resources:
–ArangoDB: https://www.arangodb.com/ –documentation page: https://www.arangodb.com/documentation/ –GitHub repository: https://github.com/arangodb |
Documents are stored in collections. Each collection has an internal ID as well as a unique name; the name can be set by the user. Whenever a document is created, a document key is assigned to it (stored in a document field _key) that is unique inside the collection; by default the key is system-generated but can also be provided by the user. In addition, a system-wide ID (denoted by _id) is maintained that allows for cross-collection accesses; it consists of the collection name and the key.
Inserting values into a database corresponds to inserting a JSON document as follows:
INSERT {firstname: "Alice", lastname: "Smith", Age:31} IN persons
A query is expressed with a for-in-return statement:
FOR person IN persons RETURN person
The output format can be modified in the return statement (for example, concatenating first and last name):
FOR person IN persons RETURN
{name: CONCAT(person.firstname," ",person.lastname)}
A selection condition is expressed with a filter statement:
FOR person IN persons FILTER person.age > 30 RETURN person
The update statement replaces individual fields of a document:
FOR person IN persons FILTER person._key == 1 UPDATE person WITH {lastname: "Miller"} IN persons
Whereas the replace statement replaces the entire document:
FOR person IN persons FILTER person._key == 1 REPLACE person WITH {firstname: "Jane", lastname: "Doe", Age:29}
In addition, AQL supports several statements to express joins between two documents as well as aggregation and sorting. It can be extended by custom JavaScript code.
In the graph API, vertices are normal documents; edges are documents that have the additional internal attributes _from and _to. To make edge handling more effcient in the graph API, dedicated edge collections can be created that are automatically indexed to allow for fast traversals. For example, all neighbors of a vertex can be obtained by using the NEIGHBORS statement based on the vertex collection persons, as well as the edge collection friendedges, and starting from the node with ID "persons/alice" along outbound edges with the label knows:
NEIGHBORS(persons, friendedges, "persons/alice", "outbound",
[ { "$label": "knows" } ] )
15.5 Bibliographic Notes
A critical discussion of NOSQL data stores in general is taking place; see for example [IS12, Lea10, Sto10].
Several attempts have been undertaken to define common interfaces for different data stores; see for example [HTV10, ABR14, GBR14]. However, the limitation of such an approach is that expressiveness is limited: a uniform interface cannot support all the special features and particularities of the individual data stores.
Other articles compare the features of several NoSQL stores [Cat11, HJ11, Pok13, GHTC13] – yet as the feature set of the databases is rapidly changing, these results are quite short-lived.
Moreover a variety of performance comparisons have been carried out [PPR+09, CST+10, PPR+11, FTD+12, LM13, AB13, KSM13a, PPV13, ABF14] – however mostly over synthetic data sets and with artificial workloads and in particular not in a production environment.
The notion of polyglot persistence – as coined in [FS12] – describes the approach that applications represent data in different data models and use a mix of database systems: the application can choose the data store and access method that is most appropriate for the current task.
Drill system internals have been described in [HN13] and Druid system internals in [YTL+14].