
5
Syntax-directed Translation
What you will learn in this chapter
- What do we mean by “meaning” of a program?
- Semantics of a program
- Interplay of Syntax and Semantics
- What is “Syntax-directed Translation”?
- Static and Dynamic semantic analysis
- Methods of semantic specifications
- What is a Semantic stack and how it is used?
- Semantic stacks in yacc
- Actions in yacc
- What are Attribute grammars?
- What is a dependency graph?
- What are Inherited and Synthesized Attributes?
- What are S-type Definitions and L-type Definitions?
- Synthesized and Inherited Attributes in yacc
- Symbol Table handling and semantic analysis
- Symbol Table in miniC
- Intermediate Representation output for miniC
Key Words
semantic analysis, syntax-directed translation, semantic specifications, Semantic stack, actions, attribute grammars, inherited and synthesized attributes, Intermediate representation
Until now we have discussed how a program in a High Level language is analyzed, by Scanner and Parser, to find its grammatical structure and validate it as a grammatically correct program. However, this is not sufficient from the viewpoint of both achieving the desired translation to the target code and validating the semantic correctness of the program. Even in day-to-day English, both the sentences “cow eats grass” and “grass eats cow” are grammatically correct, but one of them is semantically, i.e. by its meaning, not correct.
Moreover, in the case of programming languages, a particular statement can have different shades of meaning depending upon how such a statement was meant to be interpreted in a language. For example, consider a statement c = a + 5.

The declarative interpretation simply specifies a relationship between ‘c’ and ‘a’; in fact it can be used to find value of ‘a’ given the value of ‘c’ and vice versa. The algorithmic interpretation announces the method of finding the value of ‘c’, if the value of ‘a’ is known, but it does not specify who (which agent) will do that work and how will it be done. Of course, it is more specific that the value of ‘c’ is to be obtained from the value of ‘a’. The imperative interpretation commands some agent (may be a CPU) to add number 5 to the value of ‘a’ and assign the result to ‘c’.
This example shows that the same sequence of symbols may represent different meaning depending upon in which type of language it is written. This is the reason why it is necessary to specify, for each syntactic construct, what exact action the target machine is required to take. As the target machine will be controlled by the target language program, the process of finding out the meaning or semantics of the program should be completed before the target code can be generated. Thus apart from the grammar to specify the syntax, we need to have specification of the semantics of the language.
Consider an arithmetic expression 2+3. If we give this expression as an input to an expression calculator, a type checker and an infix-to-prefix parser, respectively, we get;
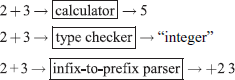
This example shows that different phases of a compiler may interpret a program segment in different ways, depending upon the analyses or synthesis they are doing.
Going back to the two English sentences “cow eats grass” and “grass eats cow”, note that we are able to say that the second sentence is wrong in English language because we have unconsciously analyzed both the sentences syntactically as “SUBJECT VERB OBJECT” and after that syntax analysis, realized that “grass”, being an inanimate thing, cannot be a SUBJECT for the VERB “eats”. The operation we do is semantic checking. Thus, we note that in order to completely analyze a sentence, we had to do first syntax analysis and then semantic checking (and analysis) controlled by or based on that syntax analysis. This is what is meant by syntax-driven semantics. As semantic analysis is a step in the language translation, we do syntax-driven translation.
Further note that “grass” would be an allowed SUBJECT in sentence like “grass is green”, i.e. whether “grass” is allowed as a SUBJECT in a sentence depends upon which VERB we have in that sentence. Thus, we have to consider relationships between the types of syntactical elements to do the semantic analysis.
Thus, we realize that
- Lexically and syntactically correct programs may still contain other types of errors.
- Lexical and syntax analyses are not powerful enough to ensure correct usage of variables, functions, statement constructs, etc. For example,
int a; a = 1.345;
This error cannot be caught by the Scanner or the Parser.
The goal of semantic analysis is to ensure that the program satisfies a set of rules regarding the usage of various programming elements like variables, constants, functions and control constructs, etc. A typical partial set of such rules is given below:
- Variables must be defined before being used.
- A variable should not be defined multiple times.
- The same identifier cannot be used to denote different types of syntactic objects.
- In an IF statement, the condition expression must have Boolean type.
- In an assignment statement, the LHS must be a variable and the RHS expression must have the same type as LHS (or, in some languages like C, the RHS can be coerced into the type of LHS).
The semantic analysis is of two types – static (i.e. when the program is being compiled) and dynamic (i.e. when the program is running). The static semantic analysis is most useful for usual languages. It can be used to the following ways:
- Ensure validity of input programs. If we do not make these tests at compile time, the program may not work correctly.
- Check that all variables and functions that are used in a program have been defined.
- Check that the correct number and type of arguments are passed to functions and procedures.
- Check that all variables are initialized before they are used.
- Clarify potential back-end ambiguities. If we do not do such an analysis, then it might be difficult or impossible to compile the programs.
- Distinguish between different uses of the same variable name, for example, global and local.
- Distinguish between different uses of the same symbols, for example, arithmetic operations on integers, floats, doubles, etc.
- Detect possibility for back-end optimizations. If we do not do this type of analysis, then we might not get the expected performance for the programs.
- Identify redundant computations.
- Identify repeated computations.
- Allow run-time type checks to be omitted.
- Efficiently use the CPU's registers and other computational resources.
Under the umbrella of semantic analysis, we have semantic rules regarding types, scope (i.e. regions of validity) and other semantic rules. We shall discuss the type checking in Chapter 6.
Most modern High Level languages contain considerable context-sensitive constructs. One way to handle this checking is to use a context-sensitive grammar to define our language and build a context-sensitive parser, but this is difficult and inefficient as of present-day state-of-art. That is why we use a separate semantic analysis phase to do the job. This phase gets activated generally after each statement is parsed, but it can be interspersed within partial statement also, for example, during an expression parsing.
Another matter to be remembered is that the Symbol Table entries, which get initiated by the Scanner, get updated with new and additional information as the parsing and semantic analysis progress. The Symbol Table also gets referred to during these phases.
Semantics are of two types:
- Static semantics: The semantics of each program element (variable, function, label, etc.) remains fixed during the program execution.
- Dynamic semantics: The semantics of some of the program elements may change during the program execution.
Languages with static semantics allow considerable checking and error detection during compilation and are generally preferred. Java is a good example of such languages. Languages which are specified using dynamic semantics are more flexible to use, but require more careful programming, as their compilers would not have chance to catch many semantic errors.
There are several ways in which the semantics can be specified. Let us consider as example a “Let-expression” in some language. Its syntax is
E ::= let x = E1 in E2
The following are various methods of specifying the semantics of such a statement:
Informal semantics: The occurrence of x in the expression E2 denotes the value E1. The whole expression E takes the value of E2. This method is useful for human understanding and human checking of the implemented semantics.
Attribute grammar: Attribute val of E denotes a value. Attribute env binds variables to values. Thus, operation bind(x,v,env) creates a new environment with x in it bounds to v, and the bindings of the remaining variables are as in env. The specification for the “Let” is
E.val ⇐ E2. val
E1. env ⇐E.env
E2. env ⇐ bind(x, E1.val, E1.env)
Operational semantics: An interpreter eval takes two parameters – an expression and an environment. “Let” is specified as
eval(E, env) ⇐(E2, bind(x, eval(E1, env), env))
This method is used for dynamic semantics.
Denotational semantics: The meaning of E, written as [[E]], is a function from environments to values. Thus, [[E]] env is application of [[E]] to environment env, is a value. For our example “Let”,
[[let x = E1 in E2]] env = [[E2 ]]bind(x, [[E1]] env, env)
Each of the above methods has corresponding implementations. We shall consider only one of them – the attribute grammar method – in Section 5.4.
We shall first see how the semantics, represented by the generated code, is implemented within the Parser as it goes through the parsing steps. The purpose of discussing implementation before theory of attribute grammars is to provide a background in which the theory can be understood better. We shall discuss Implicit Stacking in an RDP, Synchronized Semantic Stacks and Action Symbols.