
Chapter 4: Composing Infrastructure with Crossplane
Composing is a powerful construct of Crossplane that makes it unique among its peers, such as the Open Service Broker API or AWS Controllers for Kubernetes. The ability to organize infrastructure recipes in a no-code way perfectly matches the organization’s agile expectation of building a lean platform team. This chapter will take us on a journey to learn about composing from end to end. We will start with a detailed understanding of how Crossplane Composite Resources (XRs) work and then cover a hands-on journey to build an XR step by step.
The following are the topics covered in this chapter:
- Feeling like an API developer
- How do XRs work?
- Postprovisioning of an XR
- Preprovisioned resources
- Building an XR
- Troubleshooting
Feeling like an API developer
Traditionally, infrastructure engineers know the most profound infrastructure configuration options and different infrastructure setup patterns. But they may not have experience in building APIs. Building an infrastructure platform with Crossplane will be a shift from these usual ways. Modern infrastructure platform developers should have both pieces of knowledge, that is, infrastructure and API engineering. Building infrastructure APIs as a platform developer means implementing the following aspects:
- Evolving the APIs as time passes by. This involves introducing new APIs, updating an existing API version, and deprecating the old APIs.
- Applying API cross-cutting concerns for consuming product teams, such as authentication, authorization, caching, and auditing.
- Encapsulating different infrastructure policies within the APIs.
- Building reusable infrastructure recipes used across teams. For example, some product teams might develop their applications with the MEAN stack (MongoDB, Express.js, AngularJS, and Node.js). We might be interested in developing infrastructure provisioning for this stack as a template API.
- Building the required shared infrastructure used across teams. For example, we might want to provision a virtual private network shared by different infrastructure resources.
- Achieving and evolving correct API boundaries considering the different infrastructure recipes and shared infrastructure. We must perform trade-off analysis to deal with conflicting concerns between infrastructure recipes and shared infrastructure.
Infrastructure recipes and shared infrastructure are vital elements in API-bounded context trade-offs. We will examine this in detail in an upcoming chapter. The following figure represents the nuances of API infrastructure engineering:
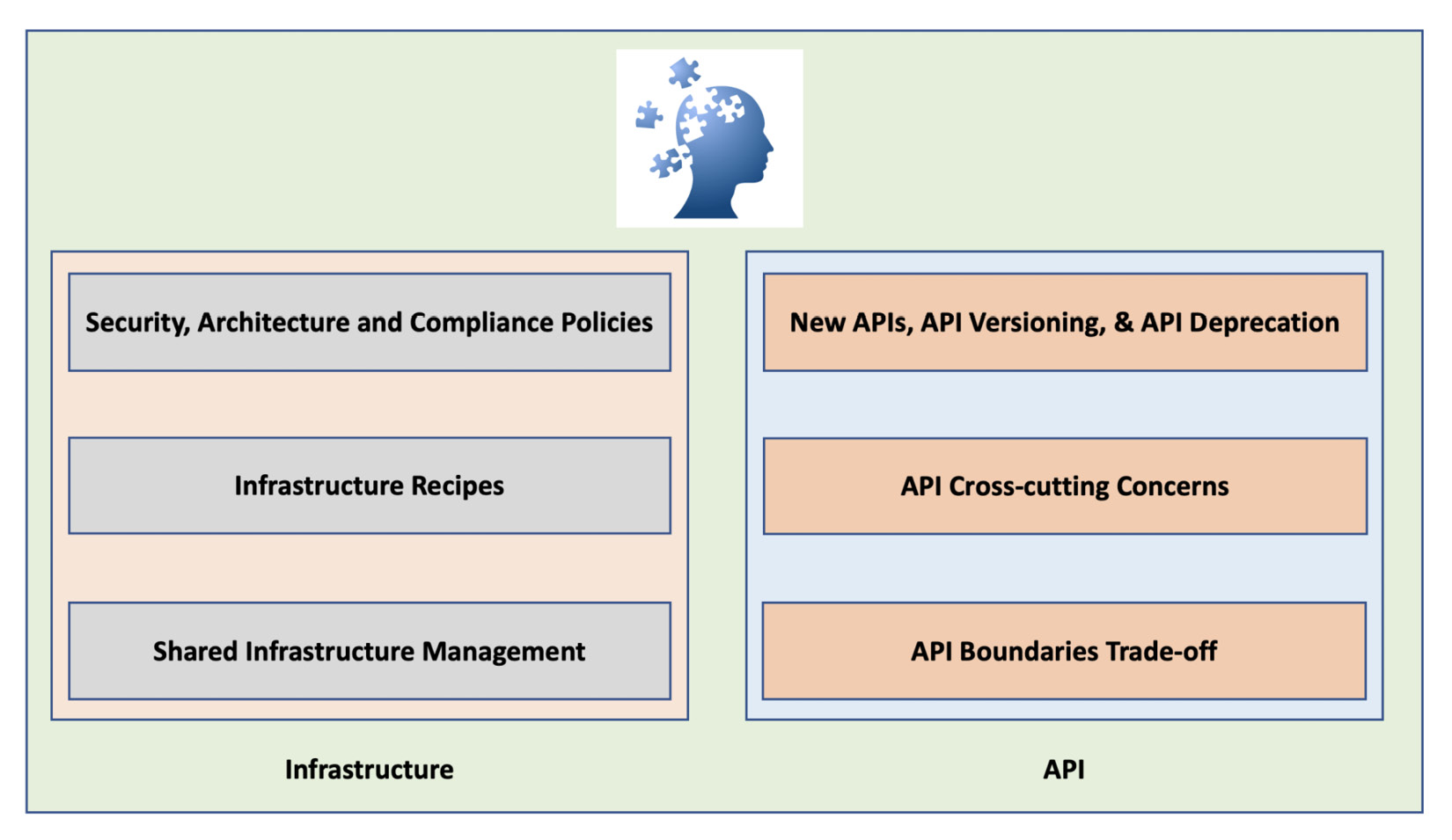
Figure 4.1 – API infrastructure engineering
We are looking at these aspects to understand XR architecture in the best possible way. Every element of the Crossplane composite is designed to cover infrastructure engineering practices from the perspective of an API.
Tip
We can use the learnings from microservices architecture pattern to define infrastructure API boundaries. There is no perfect boundary, and every design option will have advantages and disadvantages. In Chapter 6, More Crossplane Patterns, we can look for ways to adopt microservices with the Crossplane infrastructure platform.
How do XRs work?
An XR can do two things under the hood. The first purpose is to combine related Managed Resources (MRs) into a single stack and build reusable infrastructure template APIs. When we do this, we might apply different patterns, such as shared resources between applications or cached infrastructure for faster provisioning. The second one is to expose only limited attributes of the infrastructure API to the application team after abstracting all organization policies. We will get into the details of achieving these aspects as we progress in this chapter. The following are the critical components in an XR:
- Composite Resource Definition (XRD)
- Composition
- Claim
Let’s start looking at the purpose of each component and how they interact with each other.
XRD
The XRD is the schema defining the infrastructure API specification. It is best to describe an XRD first. Fixing the API specification first will force us to think about end users’ needs and the different ways they will consume the API. We will also apply all the organization policies to decide what fields are to be exposed to an application team. It will clearly set the scope and the boundary of the API. CompositeResourceDefinition is the Crossplane configuration element used to define an XRD. Creating this configuration is like writing an OpenAPI Specification or Swagger API definition. The following are the critical aspects of the CompositeResourceDefinition configuration YAML:
- The XR names: These will be the first to define, representing the infrastructure API name in singular and plural format. The singular name will eventually become the kind attribute of the new API. Note that it’s standard practice to use X as a prefix for the XR name.
- API group: This will help us to group the API logically, avoid naming conflicts, and manage authorization.
- Metadata name: Metadata is a string value constructed in a standard format. It is the concatenation of the plural name (plural name of the XR) and a dot followed by the API group (the group under which we what to classify the XR resource). In other words, the string follows this template: <resource plural name>.<API group>.
- versions: This is an XRD configuration construct that will help us to manage the API versions. The versions element is an array and can hold configuration for multiple versions of the same XR API. Typically, when we start, we will have just one version. As time progresses, we will increment the API version with changes. The old version can become a technical debt to deprecate later.
- served and referenceable: These are a couple of mandatory Boolean attributes for every defined version. The served element will indicate whether the XR API is served with the given version. The referenceable flag will determine whether we can define an implementation for the given API version. We can look at version management and these attributes in more depth in Chapter 5, Exploring Infrastructure Platform Patterns. For now, both flags will be true when we have only one version defined in the XRD.
- Schema: This is a section under each version covering the actual OpenAPI specification. It covers details such as parameter lists, data types, and required parameters.
- Connection secret keys: This will hold the list of keys that need to be created and populated in the Kubernetes Secrets after the resource provisioning.
- Composition reference: These parameters influence which resource-composing implementation is to be used on specific infrastructure API calls. In other words, we could have multiple API implementations for the given XRD, and this section of the XRD configuration will help to define the default implementation or enforced implementation. DefaultCompositionRef and EnforcedCompositionRef are a couple of attributes providing this flexibility.
- Claim names: These are optional parameters that create a proxy API for the given XR API with the specified name. Applying the claim object’s create, delete, and update action will create, delete, and update the underlying XR. Claims are a critical component in Crossplane, and we will look at that in a dedicated topic shortly in this chapter.
The XRD is nothing but an opinionated Custom Resource Definition (CRD), and many parts of the configuration look like a CRD. These are just a few possible parameters. We will look at a few more parameters as we progress through the book. The complete API documentation is available at https://doc.crds.dev/github.com/crossplane/crossplane.
Tip
We are looking at v1.5.1 of the Crossplane documentation, which is the latest at the time of writing this chapter. Refer to the latest version at the time of reading for more accurate details.
Note that some of the configurations discussed previously are not part of the following YAML, such as DefaultCompositionRef and ConnectionSecretKeys. These configurations are injected by Crossplane with default behavior if not specified. Refer to the following YAML for an example:
apiVersion: apiextensions.crossplane.io/v1
kind: CompositeResourceDefinition
metadata:
#'<plural>.<group>'
name: xclouddbs.book.imarunrk.com
spec:
# API group
group: book.imarunrk.com
# Singular name and plural name.
names:
kind: xclouddb
plural: xclouddbs
# Optional parameter to create namespace proxy claim API
claimNames:
kind: Clouddb
plural: Clouddbs
# Start from alpha to beta to production to deprecated.
versions:
- name: v1
# Is the specific version actively served
served: true
# Can the version be referenced from an API implementation
referenceable: true
# OpenAPI schema
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
parameters:
type: object
properties:
storageSize:
type: integer
required:
- storageSize
required:
- parameters
Once we are done with the API specification, the next step is to build the API implementation. Composition is the Crossplane construct used for providing API implementation.
Composition
The composition will link one or more MRs with an XR API. When we create, update, and delete an XR, the same operation will happen on all the linked MRs. We can consider XRD as the CRD and composition as the custom controller implementation. The following diagram represents how XR, XRD, composition, and MRs are related:

Figure 4.2 – XRM, composition, and XR
Tip
We have referred to XR in this book in two contexts. We can use XR to refer to a new infrastructure API that we are building. Also, the composition resources list can hold both an MR and an existing XR. We will also refer to an XR from that context. Look at Figure 4.2 where XR is referred to in both dimensions.
Let’s look at some of the crucial elements from the composition configuration:
- CompositeTypeRef: This is an attribute that will help us to map a specific XR version with the current composition. kind and apiVersion are the two configuration elements defined under CompositeTypeRef. While kind specifies the XR name, apiVersion will refer to a specific version defined in the XRD. The mapped version should be configured as referenceable in the XRD.
- WriteConnectionSecretsToNamespace: This will specify the namespace for storing the connection Secrets.
- Resources: This section is an array that holds the list of MRs to be created, updated, and deleted when someone creates, updates, and deletes the XR. We can even define another XR under this section. It is a mandatory section, and we should define at least one resource, either an MR or XR. The base is the critical object under each resource that holds the XR/MR configuration template.
- Patches: This section under a given resource will be helpful to overlay the API input attributes to the composing resource (MR/XR) attributes. This section is optional and an array where we can specify multiple patches. There are many predefined types of patches. FromCompositeFieldPath is the default type and is used most frequently. It is helpful to patch an attribute from the XR into the composition resource base template, that is, feeding the user input into the composing resources. FromFieldPath and ToFieldPath are the subattributes that perform the actual patching. There is a patch type called ToCompositeFieldPath, which does the reverse of FromCompositeFieldPath. We could copy fields from the resources back into the XR using this patch type. The CombineFromComposite patch type is the most suitable option when combining multiple attributes.
- Transforms: These are optional elements helpful in computing the patched fields. These are predefined functions, such as convert for typecasting, math for mathematical operations, and map for key-value operations. We could have a list of transform functions on a given patch, and they are executed in the order specified in the configuration. Both patches and transforms are vital patterns. We will look at different configuration examples for patches and transforms throughout the book.
- Policy: These are under each patch and will determine the patching behavior. We can mandate the patch path presence because the default behavior is to skip the patch if the field is absent. Also, we can configure the behavior of merge when the patching is performed over an object.
- ConnectionDetails: These are specified under each resource and will hold the list of secret keys we want to propagate back into the XR.
- ReadinessChecks: These will allow us to define any custom readiness logic. If this section is not provided, the default behavior is to make the XR state ready when all the composing resources are ready.
- PatchSets: This is the final attribute that we will cover. Patch sets allow us to define a set of reusable patch functions that can be used across multiple resources. It’s like a shared reusable function.
Tip
We have a few field path attributes when defining a composition. Values for these fields will follow standard JavaScript syntax to access JSON, for example, spec.parameters.storageSize or spec.versions[0].name.
We covered most of the configuration options available with the composition. Have a look at the Crossplane documentation for the complete list. The following figure represents the composition configuration options and the relationship between them:
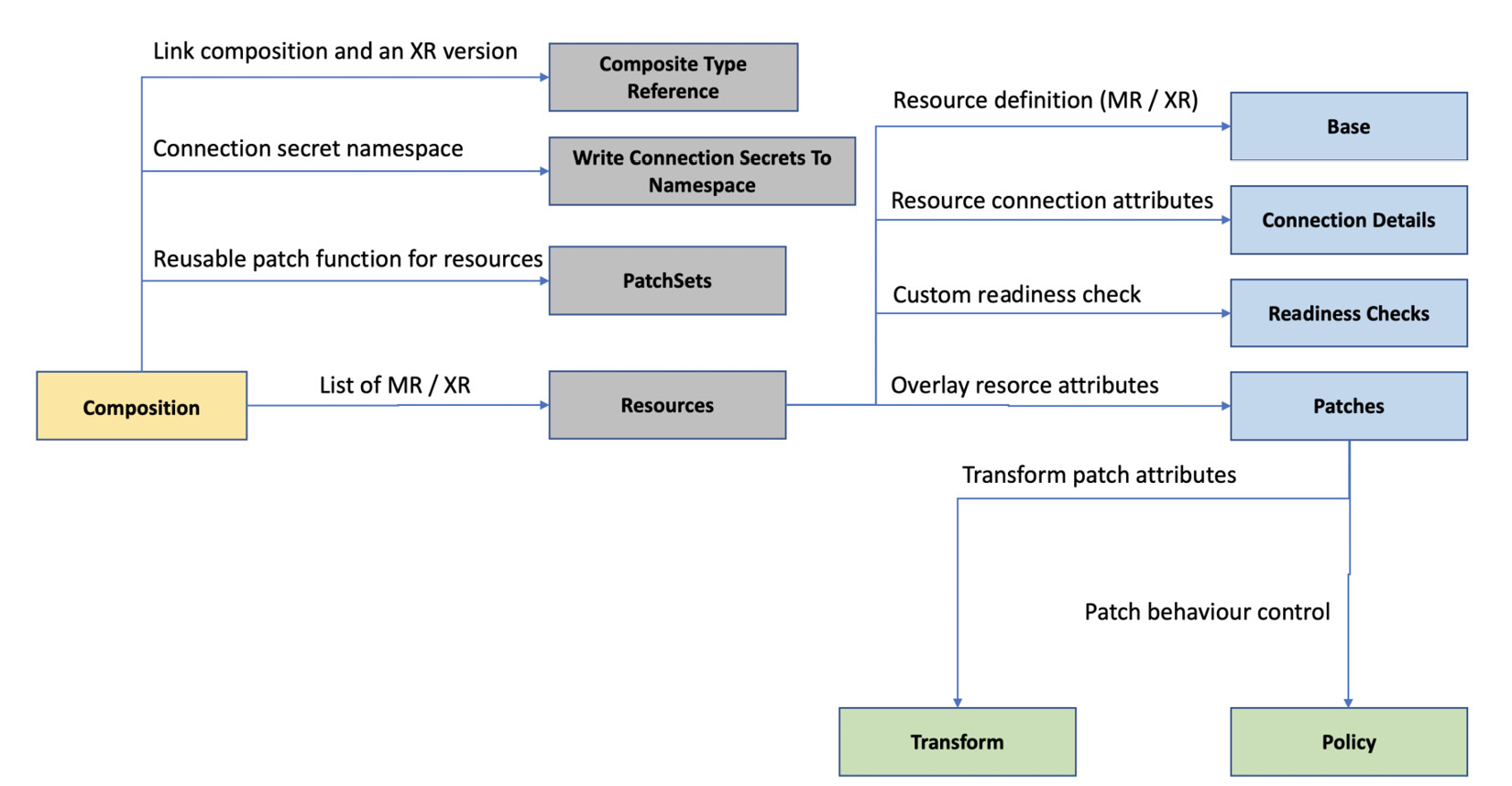
Figure 4.3 – Composition configuration
The following is a sample composition configuration YAML:
apiVersion: apiextensions.crossplane.io/v1
kind: Composition
metadata:
name: xclouddb-composition
spec:
# Link Composition to a specific XR and version
compositeTypeRef:
apiVersion: xclouddb.book.imarunrk.com/v1
kind: Xclouddb
# Connection secrets namespace
writeConnectionSecretsToNamespace: crossplane-system
# List of composed MRs or XRs.
resources:
- name: clouddbInstance
# Resource base template
base:
apiVersion: database.gcp.crossplane.io/v1beta1
kind: CloudSQLInstance
spec:
forProvider:
databaseVersion: POSTGRES_9_6
region: us-central
settings:
tier: db-g1-small
dataDiskSizeGb: 20
# Resource patches
patches:
- type: FromCompositeFieldPath
fromFieldPath: spec.parameters.storageSize
toFieldPath: spec.forProvider.settings.dataDiskSizeGb
# Resource secrets
connectionDetails:
- name: hostname
fromConnectionSecretKey: hostname
We will cover an example with more configuration elements in the Building an XR section. An XRD version can have more than one composition, that is, one-to-many relationships between the XRD version and composition. It provides polymorphic behavior for our infrastructure API to work based on the context. For example, we could have different compositions defined for production and staging. The CompositionRef attribute defined in the XR can refer to a specific composition. Instead of CompositionRef, we can also use CompositionSelector to match the compositions based on labels.
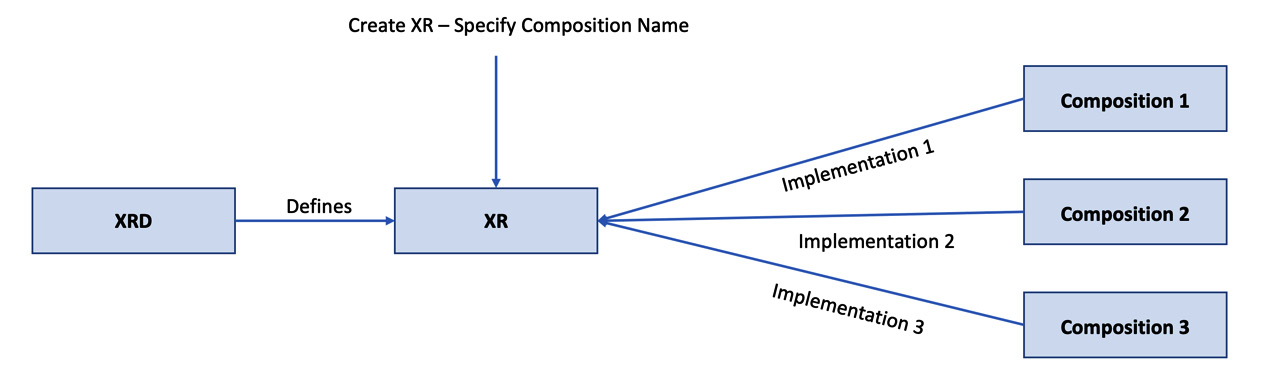
Figure 4.4 – XR and composition relation
In the next section, we will look at XR claims, also known as claims.
Claim
A claim is a proxy API to the XR, created by providing claim name attributes in XRD configurations. As a general practice, we provide the exact name of the XR after removing the initial X. In the preceding example, xclouddb is the XR name and Clouddb is the claim name but following such naming conventions is not mandatory. Claims are very similar to the XR, and it might tempt us to think that it’s an unnecessary proxy layer. Having a claim is helpful in many ways, such as the following:
- XRs are cluster-level resources, while the claims are namespace level. It enables us to create namespace-level authorization. For example, we can assign different permissions for different product teams based on their namespace ownership.
- We can keep some of the XR only as a private API at the cluster level for the platform team’s use. For example, the platform team may not be interested in exposing the XR API that creates a virtual private network.
- It’s not ideal to manage some of the resources at the namespace level as they are shared between teams and do not fit into the context.
- We can also use this pattern to support the preprovisioning of infrastructure. A claim can just reference itself with a preprovisioned XR infrastructure, keeping the provisioning time low. It is very similar to caching.
The following figure represents how claims, XR, XRD, composition, and MRs are related, giving an end-to-end view of how the whole concept works:
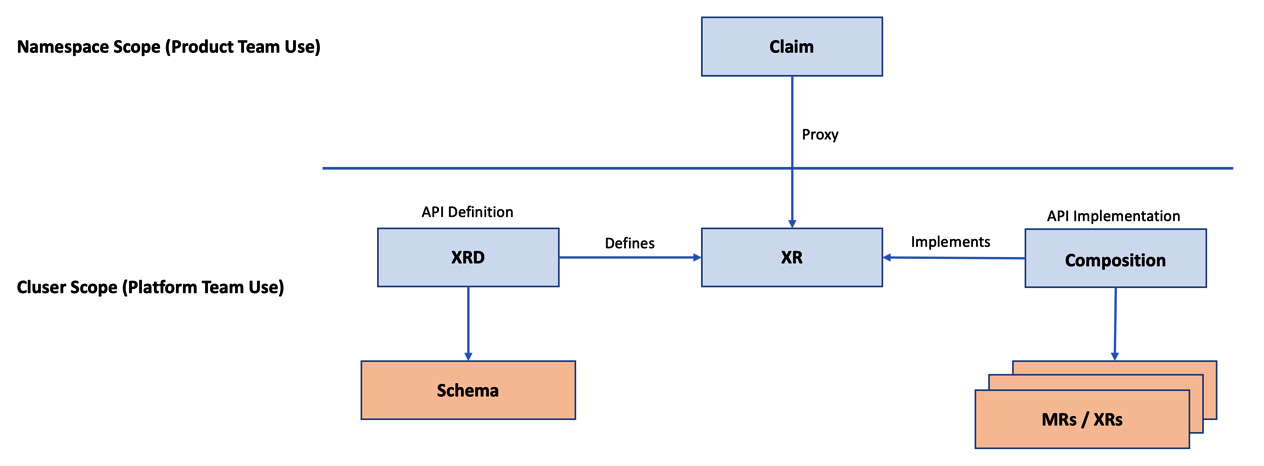
Figure 4.5 – How does composition work?
The following are the sample claim and XR YAML. The claim YAML is as follows:
apiVersion: book.imarunrk.com/v1
# Kind name matches the singular claim name in the XRD
kind: Clouddb
metadata:
name: cloud-db
spec:
# Parameters to be mapped and patched in the composition
parameters:
storageSize: 20
# Name of the composition to be used
compositionRef:
name: xclouddb-composition
writeConnectionSecretToRef:
namespace: crossplane-system
name: db-conn
A namespace is not part of the preceding claim YAML. Hence, it will create the resource in the default namespace, the Kubernetes standard. An equivalent XR YAML to the preceding claim YAML is as follows:
apiVersion: book.imarunrk.com/v1
kind: XClouddb
metadata:
name: cloud-db
spec:
parameters:
storageSize: 20
compositionRef:
name: xclouddb-composition
writeConnectionSecretToRef:
namespace: crossplane-system
name: db-conn
Note that the XR is always created at the cluster level and namespace configuration under metadata is not applicable. We can look at a more detailed claim and XR configurations in the Building an XR section. Let’s explore a few more XR, XRD, composition, and claim configurations from the perspective of postprovisioning requirements.
Postprovisioning of an XR
After performing CRUD operations over a claim or XR resource, the following are some critical aspects to bring the API request to a close:
- Readiness check
- Patch status
- Propagating the credentials back
Let’s start with learning about readiness checks.
Readiness check
The XR state will be ready by default when all the underlying resources are ready. Every resource element in the composition can define its custom readiness logic. Let’s look at a few of the custom readiness check configurations. If you want to match one of the composing resource status fields to a predefined string, use MatchString. A sample configuration for MatchString is as follows:
- type: MatchString
fieldPath: status.atProvider.state
matchString: "Online"
MatchInteger will perform a similar function when two integers are matched. The following sample configuration will check the state attribute with integer 1:
- type: MatchInteger
fieldPath: status.atProvider.state
matchInteger: 1
Use the None type to consider the readiness as soon as the resource is available:
- type: None
Use NonEmpty to make the resource ready as soon as some value exists in the field of our choice. The following example will make the readiness true as soon as some value exists under the mentioned field path:
- type: NonEmpty
fieldPath: status.atProvider.state
In the next section, we will look at an example of patching a status attribute after resource provisioning. Note that fieldPath falls under the status attribute. These are the attributes filled by MR during resource provisioning based on the values it gets back from the cloud provider.
Patch status
ToCompositeFieldPath is a patch type for copying any attribute from a specific composed resource back into the XR. Generally, we use it to copy the status fields. We can look at these as a way to define the API response. While there is a set of existing default status fields, patched fields are custom defined to enhance our debugging, monitoring, and audit activities. First, we need to define the state fields as a part of openAPIV3Schema in the XRD to make the new status fields available in the XR. The next step is to define a patch under the specific composing resource. The following patch will copy the current disk size of the CloudSQLInstance to the XR:
- type: ToCompositeFieldPath
fromFieldPath: status.atProvider.currentDiskSize
toFieldPath: status.dbDiskSize
We can also use the CombineToComposite patch type if we need to copy a combination of multiple fields.
Propagating credentials back
We can see that the connection secret-related configuration is part of the XRD, XR, claim, and composition. We must understand the relationship between these configurations to configure it correctly and get it working:
- Define the list of connection secret keys in the XRD using the ConnectionSecretKeys configuration.
- Configure the composing resources to define how to populate connection keys defined in the XRD. Connection details configuration can be of different types. The FromConnectionSecretKey type is correct when copying the secret from an existing secret key. We have the FromFieldPath type for copying the connection details from one of the composing resource fields.
- The claim or XR should save the Secrets using the WriteConnectionSecretToRef configuration.
The following diagram can help create a mind map of these configurations:
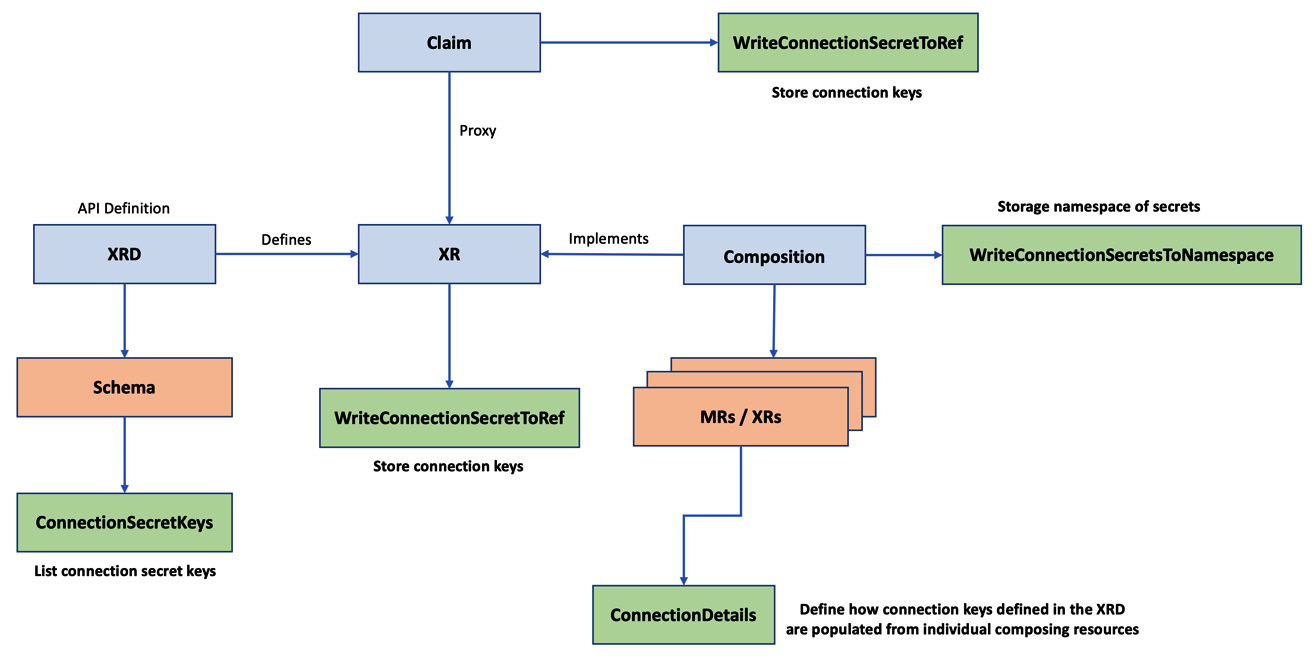
Figure 4.6 – Propagating the Secrets
The section covered different patterns that we can use with composition after the resources are provisioned. It is like customizing the API responses. Now we can look at the usefulness of reusing existing resources.
Preprovisioned resources
There are a few use cases where we may not create a new external resource and instead will reuse an existing provisioned resource. We will look at two such use cases in this section. The first use case is when we decide to cache the composed recourses because new resource provisioning may take too long to complete. The platform team can provision an XR and keep the resources in the resource pool. Then, the product team can claim these resources by adding the ResourceRef configuration under the spec of a claim YAML. With this pattern, we should ensure that the new claim attributes match the attributes in the existing pre-provisioned XR. If some of the attributes are different, Crossplane will try to update the XR specifications to match what is mentioned in the claim.
The second use case is about importing the existing resources from the external provider into the Crossplane. The crossplane.io/external-name annotation can help with this. Crossplane will look for an existing resource with the name mentioned in this configuration. The external name configuration mentioned in a claim will automatically be propagated into the XR. Still, it’s our responsibility to patch this configuration into the composing resource. The following is a sample MR YAML where we onboard an existing VPC with the name alpha-beta-vpc:
apiVersion: compute.gcp.crossplane.io/v1beta1
kind: Network
metadata:
name: alpha-beta-vpc-crossplane-ref
annotations:
# Annotation to provide existing resource named
crossplane.io/external-name: alpha-beta-vpc
spec:
providerConfigRef:
name: gcp-credentials-project-1
# Provide the required parameters same as external resource.
forProvider:
autoCreateSubnetworks: true
Once you apply the YAML, you will see that it’s ready for use in Crossplane. This can be seen in the following screenshot:

Figure 4.7 – VPC reference status
Note that the alpha-beta-vpc VPC is an existing VPC we created manually in GCP. What we achieve here is to map the manual resource to a Claim.The section covered different ways we can use preprovisioned resources with an XR/claim. The following section will be a hands-on journey to build an XR from scratch.
Building an XR
It’s time to go through a hands-on journey to build an XR from scratch. We will start with writing down the infrastructure API requirement at a high level, then provide an API specification with XRD and finally provide an implementation with a composition. We will cover the API requirement in such a way as to learn most of the configuration discussed in this chapter.
The infrastructure API requirement
We will develop an API to provision a database from Google Cloud. The following are the compliance, architecture, and product team’s requirements:
- Compliance policy: The provisioning should be done in the us-central region to comply with the data storage regulations from the government.
- Architecture policy: We should have two tiers of the database. For small, the disk size should be 20 GB, and it should be 40 GB for big.
- Architecture policy: The small tier’s virtual machine should be db-g1-small, and db-n1-standard-1 for the big tier.
- Product team: We should have the option to choose between Postgres and MySQL.
- Product team: We should specify the size in the XR with two enums (SMALL or BIG).
- Platform team: Patch the zone in which the database is created back into the XR/claim status field for monitoring requirements.
The next step is to write the XRD configuration YAML.
Creating the XRD
When defining the API specification with an XRD, the following configurations should be encoded into the YAML:
- Use alpha-beta.imarunrk.com as the API group to organize all APIs for alpha and beta teams.
- We will provide the XR name as XGCPdb and the claim name as GCPdb.
- We will start with a new API version, v1.
- Create size as an input parameter and zone as the response status attribute.
As the example XRD is oversized, we will cover only the schema definition here. Refer to the entire XRD file at https://github.com/PacktPublishing/End-to-End-Automation-with-Kubernetes-and-Crossplane/blob/main/Chapter04/Hand-on-examples/Build-an-XR/xrd.yaml. Without wasting much time, let’s look at the schema:
schema:
openAPIV3Schema:
type: object
properties:
# Spec – defines the API input
spec:
type: object
properties:
parameters:
type: object
properties:
# Size will be a user input
size:
type: string
required:
- size
required:
- parameters
# status – the additional API output parameter
status:
type: object
# Recourse zone - status patch parameter.
properties:
zone:
description: DB zone.
type: string
Save the YAML from GitHub and apply it to the cluster with kubectl apply -f xrd.yaml. Refer to the following screenshot, which shows successful XRD creation:

Figure 4.8 – XRD creation
Note that the ESTABLISHED and OFFERED flags in the screenshot are True. This means that the XRD is created correctly. If these statuses are not True, use kubectl to describe the details of the XRD and look for an error.
Providing implementation
The next step is to provide an API implementation. As a part of the implementation, we should be providing a composition configuration. We will create two compositions, one for Postgres and the other for MySQL. It will be an example of the polymorphic behavior implementation. The following are the steps to remember when we build the composition YAML:
- Refer to the v1 XRD API version with the CompositeTypeRef configuration.
- Define the CloudSQLInstance configuration under the resource base.
- Hardcode the region to us-central1 to meet the compliance requirement.
- The database tier and disk size will hold default values, but the patch configuration will overlay them using the FromCompositeFieldPath patch type.
- Use the Map transformation to convert the SMALL tier size to the db-g1-small machine tier. Use the Map and Convert transformations to map the SMALL tier size to the 20 GB disk size.
- Similar mapping will be done for the BIG configuration.
- Patch the GceZone attribute from the MR status to the XR/claim for monitoring. We can achieve this using the ToCompositeFieldPath patch type.
- Provide a mapping between the MR connection secret key to the XR/claim keys with the ConnectionDetails configuration.
We will look at the Postgres composition example in four parts. The XRD and resource definition section of the composition will look like the following configuration:
spec:
# Refer to an XRD API version
compositeTypeRef:
apiVersion: alpha-beta.imarunrk.com/v1
kind: XGCPdb
writeConnectionSecretsToNamespace: crossplane-system
resources:
# Provide configuration for Postgres resource
- name: cloudsqlinstance
base:
apiVersion: database.gcp.crossplane.io/v1beta1
kind: CloudSQLInstance
spec:
# reference to GCP credentials
providerConfigRef:
name: gcp-credentials-project-1
forProvider:
databaseVersion: POSTGRES_9_6
# Compliance Policy
region: us-central1
settings:
# These are default values
# Architecture policies will be a patch
tier: db-g1-small
dataDiskSizeGb: 20
Read through the comments between the code snippets to understand concepts in detail. The following configuration uses the map transform to patch the virtual machine tier:
- type: FromCompositeFieldPath
fromFieldPath: spec.parameters.size
toFieldPath: spec.forProvider.settings.tier
# Use map transform
# If the from-field value is BIG, then
# the mapped to-field value is db-n1-standard-1
transforms:
- type: map
map:
BIG: db-n1-standard-1
SMALL: db-g1-small
policy:
# return error if there is no field.
fromFieldPath: Required
Next, we can look at the configuration to patch the disk size. The patch will have two transform operations. The first operation is to map the disk size, and the second one is to convert the mapped string to an integer:
- type: FromCompositeFieldPath
fromFieldPath: spec.parameters.size
toFieldPath: spec.forProvider.settings.dataDiskSizeGb
# If the from-field value is BIG, then
# the mapped to-field value is '40;
# Apply the second transform to convert '40' to int
transforms:
- type: map
map:
BIG: "40"
SMALL: "20"
- type: convert
convert:
toType: int
policy:
# return error if there is no field.
fromFieldPath: Required
Finally, the following patch adds the resource zone into the API response:
# Patch zone information back to the XR status
# No transformation or policy required
- type: ToCompositeFieldPath
fromFieldPath: status.atProvider.gceZone
toFieldPath: status.zone
The composition configuration for MySQL will be the same as the preceding configuration, excluding two changes. We should be changing the name of the composition in the metadata, and in the resource definition, we should change the database version to MYSQL_5_7. We can implement this with an additional parameter in the XR as well. Building two different compositions does not make sense when the difference is so small. We can capture the difference as a parameter in the XR. We are building two compositions, as an example. All composition examples and the upcoming claim examples are available for reference at https://github.com/PacktPublishing/End-to-End-Automation-with-Kubernetes-and-Crossplane/tree/main/Chapter04/Hand-on-examples/Build-an-XR.
Refer to the following screenshot, which shows the successful creation of both compositions:

Figure 4.9 – Composition created
The final step is to use the claim API and create the database resources.
Provisioning the resources with a claim
Finally, we can start provisioning the GCP database with an XR or a claim. The CompositionRef configuration will specify which composition implementation to use. Note that the claims are namespace resources, and we provision them in the alpha namespace here. The following is a sample claim YAML for the MySQL database:
apiVersion: alpha-beta.imarunrk.com/v1
kind: GCPdb
metadata:
# Claims in alpha namespace
namespace: alpha
name: mysql-db
spec:
# Refer to the mysql composition
compositionRef:
name: mysql
# save connection details as secret - db-conn2
writeConnectionSecretToRef:
name: db-conn2
parameters:
size: SMALL
The Postgres YAML as well will look similar with minor changes. Refer to the following screenshot, which shows a successful database creation:
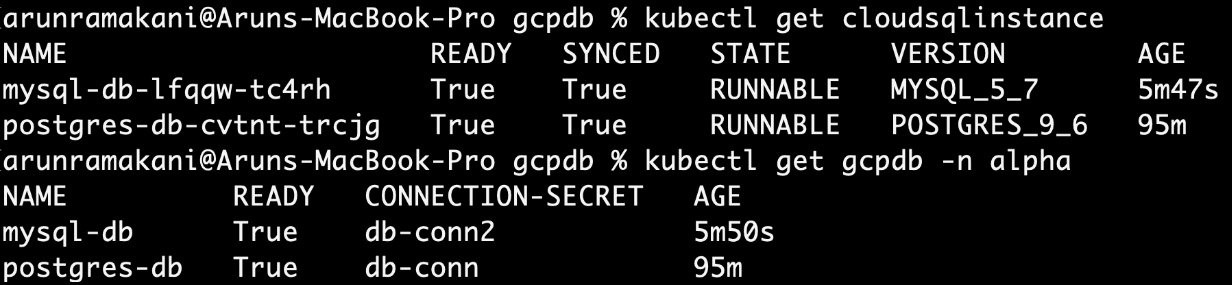
Figure 4.10 – Claim status
Note that the zone information is made available as the part of claim status:
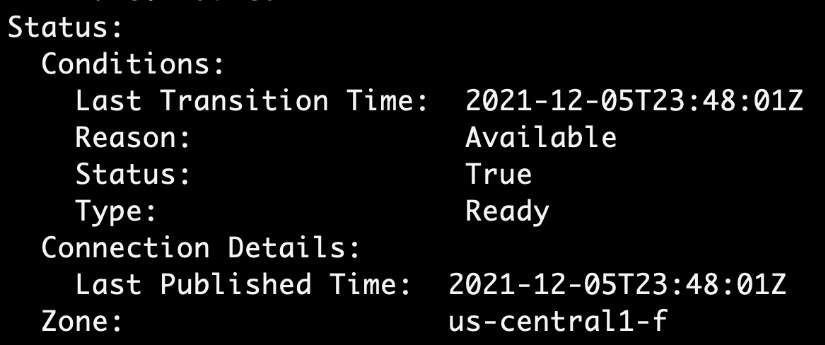
Figure 4.11 – Zone information
This concludes the journey to build an XR. We will look at a few troubleshooting tips.
Troubleshooting
If we face issues with our infrastructure API, these tips could help us debug the problem in the best possible way:
- Status attributes and events are essential elements to debug issues. These details can be viewed by running kubectl describe on the given resource.
- When we start looking for issues, we take a top-down approach. This is because Crossplane follows the same convention as Kubernetes to hold the errors close to the resource where it happens.
- The debugging order will be claim, then XR, and then each composing resource. We should start with a claimed object. If we cannot locate the issue, we go deep into the XR and then the composing resources.
- spec.resourceRef from the claim description can help us to identify the XR name. Again, the same attribute can be used to find the composing resources from the XR.
Make an intentional mistake in the resource configuration of the composition to go through the debugging experience. You learn more when you debug issues. This concludes our troubleshooting section. Next, we will look at the chapter summary before moving on to the next chapter.
Summary
With this chapter, we covered one of the critical aspects of Crossplane, the XR. We started with understanding how an XR works and configuring an XR. Above all, we went through a hands-on journey to build a fresh infrastructure API from end to end. The chapter also covered some advanced XR configuration patterns and ways to approach debugging when there is an issue. This will be the base knowledge for what we will learn in the next chapter.
The next chapter will cover different advanced infrastructure platform patterns.