
Chapter 2: Examining the State of Infrastructure Automation
This chapter will look at the history of infrastructure automation, its evolution, and its current state. We will explore how the evolving situation in the cloud-native ecosystem and agile engineering practices exposes the limitations of Infrastructure as Code (IaC). We will also examine how control plane-based infrastructure automation is a cutting-edge technique that solves the limitations of IaC and can change the DevOps operating model to move software engineering further in a positive direction.
The chapter will dive deep into the following topics:
- The history of infrastructure automation
- The limitations of IaC
- The need for end-to-end automation
- Multi-cloud automation requirements
- Crossplane as a cloud control plane
- Other similar projects
The history of infrastructure automation
The hardware purchase cycle was the critical factor influencing an organization’s infrastructure landscape changes during the 1990s. Back then, there was not much emphasis on infrastructure automation. The time spent from receiving an order to a physical infrastructure becoming available was much more than the effort spent in infrastructure setup. Individual infrastructure engineers and small teams automated repetitive scripting tasks without much industry-wide adaptation. Tools such as CFEngine, launched in 1993 for automating infrastructure configuration, did not have enough adoption during that decade. There was no industry-wide trend to invest in automation because of its minimal benefits and return on investment. In the 2000s, the idea of infrastructure automation slowly got traction because of the following:
- Virtualization techniques
- The cloud
Virtualization brought in the ability to have software representation of resources such as memory, CPU, storage, and network using a hypervisor installed over physical hardware. It brought us into the era of virtual machines, where machines are abstracted away from the underlying physical hardware. We could have multiple virtual machines over single hardware. It gave us many advantages, such as lower costs, minimal downtime, and effective utilization of resources. But the critical advantage was agility in infrastructure engineering, breaking the traditional hardware purchasing cycles. While virtualization was there before the 2000s for a long time, it saw wide adoption much later because of cloud computing.
Different cloud platforms were launched during the late 2000s, adding more agility. We got into the Infrastructure as a Service (IaaS) era. As we increased our velocity of spinning new virtual machines, new problems evolved. The number of servers to manage was rapidly growing. Also, virtual machines are transient, and we needed to move, modify, and rebuild them quickly. Keeping configurations up to date with the preceding scenarios is challenging. We ended up with snowflake servers because of an error-prone, intensive human effort to manage the virtual machines manually. These limitations made us move toward the widespread adoption of infrastructure automation. New tools such as Puppet, Ansible, Chef, and Terraform quickly evolved, introducing IaC to manage configuration and provisioning of infrastructure the same way as code. Our ability to be agile in infrastructure life cycle management and store the relevant code in Git is the foundation for modern infrastructure engineering. IaC and IaaS is a deadly combination that provides unique characteristics for infrastructure engineering. We made consistent, repeatable, interchangeable, and elastic infrastructure provisioning and configuration management.
The following diagram summarizes the evolution from scripting to IaC:

Figure 2.1 – Infrastructure automation evolution
The need for the next evolution
The cloud became the holy grail of infrastructure as we progressed further. Tools such as Terraform, Pulumi, AWS CloudFormation, Google Cloud Deployment Manager, and Azure Resource Manager became the center of IaC. While these tools did well to fulfill their promises, we can see that the next evolution of infrastructure automation is beginning to show up already. Before looking at the next phase of infrastructure automation, it’s essential to understand why we need to evolve our tools and practices around infrastructure automation. A few recent trends in the software industry are triggering the next phase of evolution. These trends are the following:
- The limitations of IaC
- The Kubernetes operating model for automation
- Multi-cloud automation requirements
Let’s look at each of these trends to justify the need for progression toward the next phase of infrastructure automation.
The limitations of IaC
Most of the widely used infrastructure automation tools are template-based, such as Terraform, Ansible, and Azure Resource Manager. They do not scale well from multiple points of view. It does not mean that IaC tools are not best for automation with all due respect. IaC tools have transformed software engineering positively for more than a decade. We will attempt to explain how evolving situations expose the weakness of template-based IaC tools and how control plane-based tools can be an alternative and the next evolutionary step. Let’s pick up Terraform, one of the most popular template-based tools, and look at the limitations. The following are the different limitation issues with Terraform:
- Missing self-service
- A lack of access control
- Parametrization pitfalls
Terminology
The amount of knowledge to be possessed and processed to perform a task is called cognitive load. You will come across the term high team cognitive load in the upcoming sections, which means that a team must stretch its capacity to hold more knowledge than it usually does to perform day-to-day functions.
Missing self-service
With Terraform, we have too many templates abstracting thousands of cloud APIs. Remembering the usage of each parameter in thousands of templates is not an easy job. Also, infrastructure usage policies come from different teams in an organization, such as security, compliance, product, and architecture. Implementing Terraform automation involves a significant team cognitive load and centralized policy requirements. Hence, many organizations prefer to implement infrastructure automation with centralized platform teams to avoid increased cognitive load on the product team and enable centralized policy management. But template-based automation tools do not support APIs, the best way to provide platform self-service. So, we must build Terraform modules/libraries to create artificial team boundaries and achieve self-service. Modules/libraries are a weak alternative to APIs. They have a couple of problems in enabling platform self-service:
- There is a leak in cognitive load abstraction by the platform team, as using Terraform modules/libraries by the product team means learning Terraform fundamentals at least.
- The team dependencies as modules and libraries require a collaborative model of interaction between the product and platform teams rather than a self-service model. It is against the modern platform topologies, hindering the agility of both platform and product teams.
Alternatively, some organizations outsource the infrastructure provisioning completely to the platform team. The complete centralization hinders the product team’s agility, with external coupling for infrastructure provisioning. Few organizations even attempt to decentralize the infrastructure management into the product teams. A complete decentralization will increase team cognitive load and the difficulty of aligning centralized policies across teams. The new evolution needs to find the middle ground with correctly abstracted self-service APIs.
Lack of access control
As we saw in the previous section, building and using Terraform modules requires collaboration between multiple teams. We have access control issues by sharing Terraform modules with product teams for infrastructure provisioning and management. We cannot have precise Role Based Access Control (RBAC) on individual resources required by the product team, and we will leak the underlying cloud credentials with all the necessary permissions required by the modules. For example, a Terraform module to provision Cosmos DB requires Azure credentials for database and Virtual Private Cloud (VPC) provisioning. But the access needed for the product team is only to create the database, and they don’t need to modify the VPC directly. In addition to this, we also have version management issues with modules/libraries. It requires a coordinated effort between all product teams, creating friction on a module/library’s version upgrade. A highly interoperable API-based infrastructure automation abstraction can solve collaboration and access control issues.
Parameterization pitfalls
Parameterization pitfalls are one of the general issues with any template-based solution, be it an infrastructure automation tool or otherwise. We create parameter placeholders for variables with changing values in any template-based solution. These solutions are easy to implement, understand, and maintain. They work well if we are operating at a small scale. When we try to scale template-based solutions, we end up with either one of the following issues:
- As time passes, we will have requirements to parameterize new variables, and slowly, we will expose all the variables at some point in time. It will erode the abstraction we created using templates. Looking at any Helm chart will show this clearly, where almost everything is a parameter.
- We may decide to fork the main template to implement customization for a specific use case. Forks are challenging to keep up to date, and as the number of forks increases, it will be challenging to maintain the policies across the templates.
Parameterization is generally not a perfect abstraction when we operate at scale.
Important Note
Parameterization pitfalls is a critical topic to understand in detail for DevOps engineers. In a later chapter, we will look at the configuration clock, a concept of eroding template abstractions as time passes.
A Kubernetes operating model for automation
As we saw in the previous chapter, the control theory implementation of Kubernetes entirely changed the IT operations around application automation. Infrastructure automation as well deserves the same benefits. But traditional infrastructure automation tools lack these attributes, as they don’t have an intact control theory implementation. Some of the missing features are the following:
- Synchronous provisioning is a crucial scalability issue with Terraform or similar automation tools. The resources are provisioned in a sequence, as described in the dependencies with conventional automation tools. If infrastructure A depends on infrastructure B, we must respect it while defining the order of execution, and if one of the executions fails, the whole automation fails. The monolithic representation of infrastructure is the key concern here. With Terraform, the monolithic state file is the model representing infrastructure resources. Kubernetes-based automation can change this equation. There will be a continuous reconciliation to move the current state toward the expected state. Hence, we can efficiently manage the dependencies with no order of execution. Infrastructure A provisioning may fail initially, but continuous reconciliation will eventually fix the state once infrastructure B is available.
- Modeling team boundaries is another missing piece with traditional tools. The monolithic Terraform state file is not flexible to model different team boundaries. In the Kubernetes-based automation model, we have resources represented as individual APIs that can be grouped and composed as required by any team structure. We don’t need to collect all pieces of automation into a single monolithic model.
- Drift management is the process of maintaining the infrastructure in the intended state by protecting it against any unintended or unauthorized changes. Changing the Identity and Access Management (IAM) policy directly in the cloud console without changing the relevant automation code is an example of drift. Drift management is all about bringing it back to the authorized state. Drift management is impossible with no control plane continuously monitoring the infrastructure’s condition and performing reconciliation against the last-executed code. Achieving drift management with an additional external tool will add complexity and not solve all the issues.
- Automating day 2 concerns in a standard way is another missing piece with conventional tools. A Kubernetes-based automation model can provide configuration models to support day 2 concerns such as scaling, monitoring, and logging. Also, we can use standard extension points (operators) to automate any custom day 2 problems.
These are a few essential perspectives on what Kubernetes-based infrastructure automation can bring to the table.
Multi-cloud automation requirements
Almost all organizations of a significant size run their workloads in more than one cloud provider. There can be many reasons why an organization is determined to build its infrastructure supported by multiple cloud providers. We will not get into details of these factors, but we must understand the impact of multi-cloud on infrastructure management. Typically, a cloud provider offers managed services, be it basic IaaS such as Amazon EC2 or more abstracted platforms such as AWS Lambda. From the perspective of cloud infrastructure consumers, infrastructure automation is all about the provisioning and life cycle management of these managed services in an automated fashion after applying all the in-house policies. Organizations use infrastructure automation tools to build an abstraction over the cloud infrastructure APIs to encode all the in-house policies.
To support multi-cloud capability requires a lot of work, as it brings in new requirements. Think about the multi-cloud environment. Embedding policies into the automation scripts of every cloud provider is a hell of a lot of work. Even if we do that after making a significant effort, keeping these policies in sync across the automation scripts involves friction and is error-prone. A centralized experience in authentication, authorization, billing, monitoring, and logging across cloud providers will be an added advantage for an organization to provide a unified experience. Achieving these cross-cutting concerns with traditional automation tools requires a lot of custom engineering, making our platform team big. What we need is a centralized control plane, abstracting cross-cutting concerns and policies.
The following figure represents how an API-driven centralized control plane can provide a unified experience for product teams:
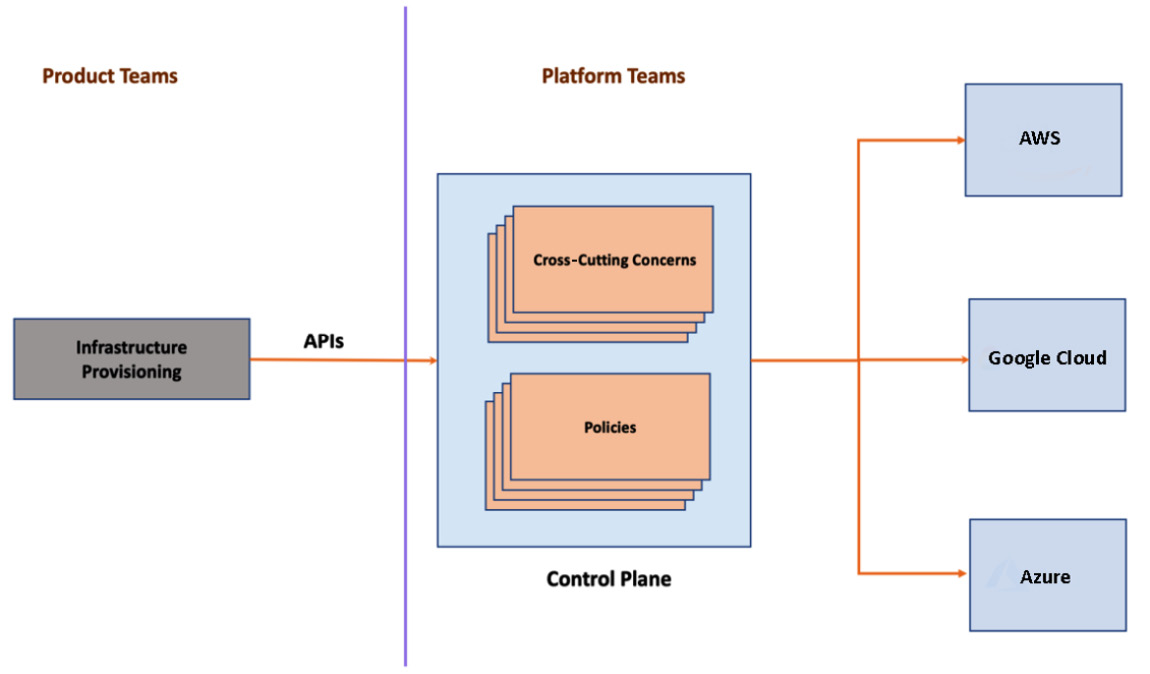
Figure 2.2 – A multi-cloud control plane
Tools such as Terraform or Pulumi help with these problems to some extent, but they are not end-to-end automation, have scalability issues, and require custom engineering to build on. Also, these tools are not unbiased open source projects. The companies who initially created these open source projects and provided enterprise offerings dominate the control of the former. Now that we are all convinced that the next evolution of infrastructure automation is required, it’s time to define the attributes needed by such tools. The subsequent development of infrastructure automation should be a control plane-based, fully community-driven solution, powered by APIs. The following diagram summarizes the evolution from Infrastructure as Code- to Central Control Plane-based automation:

Figure 2.3 – The next evolution
Crossplane as a cloud control plane
Crossplane, a modern control plane-based infrastructure automation platform built on Kubernetes, matches all the attributes required for the next evolution of infrastructure engineering. With Crossplane, we can assemble infrastructure from multiple cloud providers to expose them as a high-level API. These APIs can provide a universal experience across teams, irrespective of the underlying cloud vendor. While composing the APIs for the product team, the platform team can use different resource granularity to suit the organization’s structure. Such carefully crafted APIs for infrastructure automation will facilitate self-service, multi-persona collaboration with precise RBAC, less cognitive load, continuous drift management, and dependency management with asynchronous reconciliation. Above all, the platform team can compose these APIs in a no-code way with configurations. Finally, we can have a lean platform team, as highly recommended by modern team topologies.
Crossplane is nothing but a set of custom controllers that extends Kubernetes for managing infrastructure from different vendors. Being built on Kubernetes as a new API extension, Crossplane inherits all the goodness of the Kubernetes operating model and can leverage the rich ecosystem of cloud-native tools. Additionally, this can unify the way we automate applications and infrastructure. Crossplane can cover end-to-end automation of both day 1 and day 2 concerns. Infrastructure provisioning, encoding policies, governance, and security constraints are the day 1 concern we can automate. We can cover drift management, upgrades, monitoring, and scaling on day 2. Above all, it follows the Kubernetes model of open source governance through the Cloud Native Computing Foundation (CNCF). The following figure represents how Crossplane works with Kubernetes:

Figure 2.4 – The Crossplane control plane
To adopt platforms as a universal control plane requires a much closer look at open source governance and ecosystem acceptance. The following sections will look deep into these aspects.
A universal control plane
Launched in 2018 as an open source project, Crossplane took steps to become a universally accepted control plane. The project’s donation to CNCF in 2020 was the next significant step. It helped Crossplane become a foundation-driven, open source initiative with broader participation rather than just becoming another open source project. Initially, it was a sandbox project but did not stop there. In 2021, it was accepted as an incubating project. Above all, Crossplane is simply another extension to Kubernetes, already an accepted platform for application DevOps. It also means that the entire ecosystem of tools available for Kubernetes is also compatible with Crossplane. Teams can work with the existing set of tools without much cognitive load:

Figure 2.5 – The journey
Crossplane has a few more unique attributes compelling it to be accepted as a universal control plane. The attributes are the following:
- Open standards for infrastructure vendors
- Wider participation
- Cloud provider partnerships
Open standards for infrastructure vendors
Crossplane uses the Crossplane Resource Model (XRM), an extension of the Kubernetes Resource Model (KRM), as the open standard for infrastructure providers. It solves issues such as naming identity, package management, and inter-resource references when infrastructure offerings from different vendors are consolidated into a single control plane. The Crossplane community has developed these standards to enforce how infrastructure providers can integrate into the centralized Crossplane control plane. The ability to compose different infrastructures in a uniform and no-code way has its foundation on this standardization.
Wider participation
Upbound was the company that initially created Crossplane. They provide enterprise offerings for organizations that require support and additional services. But to become a universal control plane, Upbound cannot be the only enterprise Crossplane provider. Any vendor should be able to make an enterprise offering. With Crossplane gaining CNCF incubation status, a lot of work is happening in this area. CNCF and the Crossplane community have introduced something called the Crossplane Conformance Program. It’s an initiative run by CNCF (https://github.com/cncf/crossplane-conformance). The idea is to create foundation governance for any vendors to pick up Crossplane open source, build additional features, and offer a CNCF-certified version. It is very similar to Kubernetes-certified distribution, a program run by CNCF where all vendors pick up the base Kubernetes version and offer it as a certified version. The Crossplane Conformance Program works on two levels:
- Providers: On one level, infrastructure providers will be interested in building respective Crossplane controllers to enable customers to use their offerings through Crossplane. It requires following the standards set by XRM. CNCF will ensure this happens by certifying the providers built by infrastructure vendors.
- Distribution: On another level, many vendors will be interested in providing the Crossplane enterprise offering. The Crossplane Conformance Program enables this support.
Read more about the Crossplane Conformance Program at https://github.com/cncf/crossplane-conformance/blob/main/instructions.md.
The cloud provider partnerships
Crossplane has an excellent partnership ecosystem with all major cloud providers. There have been production-ready Crossplane providers for all the major cloud providers for quite some time now. Initially, IBM joined the Crossplane community and released its first version of the provider in 2020. Similarly, AWS and Azure made Crossplane providers part of their code generation pipeline to ensure that the newest provider is available up front for all their cloud resources. Alibaba is experimenting with Crossplane on many of its internal initiatives and also has a production-ready provider. Similarly, there has been a Google Cloud Platform (GCP) provider managed by the community. These partnerships and community efforts make Crossplane a compelling, widely accepted universal control plane offering.
Other similar projects
A few other Kubernetes-based infrastructure automation projects share common interests and support similar use cases such as Crossplane. These projects extend Kubernetes with APIs and custom controllers identical to Crossplane architecture. This section will look at those tools to have a comprehensive comparison with Crossplane. The following is a list of a few such projects:
- Kubernetes’ Service Catalog by the open service broker enables life cycle management of cloud resources from Kubernetes. Like Crossplane, it works as a Kubernetes controller extension. But it does not have a solid framework to compose infrastructure recipes with policy guardrails. Also, we can’t model the API for different team boundaries. The open service broker Kubernetes Service Catalog is not designed for platform teams to build reusable recipes with encoded policies. Typically, this means that we have to struggle with policy enforcement and a high cognitive load on the teams to understand cloud offerings in detail.
- AWS Controllers for Kubernetes (ACK) is a Kubernetes-based extension developed by AWS to manage its resources from the Kubernetes cluster using controllers. Again, it does not have a framework to compose infrastructure recipes and model APIs. Also, this does not work cross-cloud and is meant to be used only with AWS.
- The GCP Config Connector is a replacement developed by Google for the GCP service catalog. It works like ACK and inherits identical limitations. An additional point to note is that the GCP Config Connector is not an open source initiative.
None of these tools cover an end-to-end automation use case or provide an ability to compose resources as recipes. We have already seen the limitations of Terraform, AWS CloudFormation, Azure Resource Manager, and similar IaC tools in detail. These were the motivations that the Crossplane creators had when developing such universal abstraction.
Summary
This chapter discussed the details of limitations with IaC. We also looked at why it is inevitable to move toward a control plane automation in the evolving world of software engineering. It brings us to the end of the first part of this book. In summary, part one covered how Kubernetes won the war on application deployment automation and how the same pattern is evolving a new trend in infrastructure automation. The upcoming sections of the book will take us on a hands-on journey to learn Crossplane, Kubernetes configuration management, and ecosystem tools. We also will cover the different nuances and building blocks of developing state-of-the-art cloud infrastructure automation platforms with Crossplane.
In the next chapter, we will learn about automating infrastructure with Crossplane.