Information and Communication Technology for EPN
Abstract
Information and Communication Technologies (ICT) are pervasive in our urban neighborhoods, not just in terms of traditional computing devices but also in terms of embedded monitoring and control systems that manage our environment, in particular the energy consumption of our buildings, homes, outdoor lighting systems, traffic, and safety systems. Huge opportunity exists in leveraging these systems into neighborhood management platforms that can provide innovative energy services to the neighborhood and the wider energy grid.
This chapter outlines the challenges and opportunities associated with the provision of ICT based energy positive neigbborhoods. The chapter begins with an overview of the technical challenges, changing ICT landscape and the emergence of the Internet of Things (IoT). This is followed by an identification of the requirements for heterogeneous data acquisition, technologies for coping with increasingly voluminous and varied data at differing velocities and in attesting to the veracity of such data. End-to-end approaches to services at a neighborhood scale are presented followed by a discussion of a system-of-systems (SoS) approach to service provision at the district level.
This system-of-systems approach, was proposed within the European Commission part funded FP7 project—COOPERaTE. In particular the concept of a Neighborhood Information Model (NIM), a metamodel approach to a common data model and an web-based service implementation is introduced as a means of integrating heterogeneous management platforms. An example of how the NIM was used within the COOPERaTE project to integrate multiple systems into an EPN platform is presented as are exemplar service. Conclusion draw the chapter to a close.
Keywords
1. Introduction

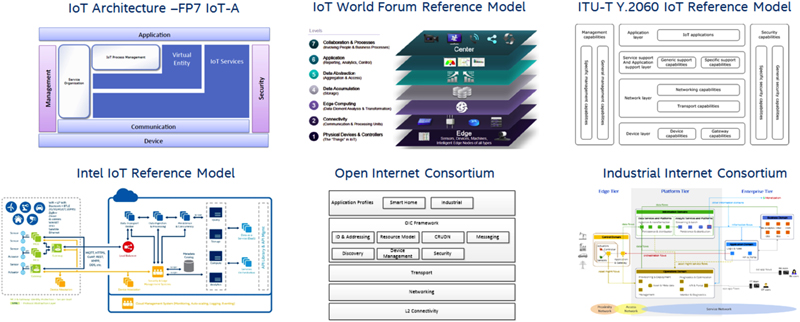
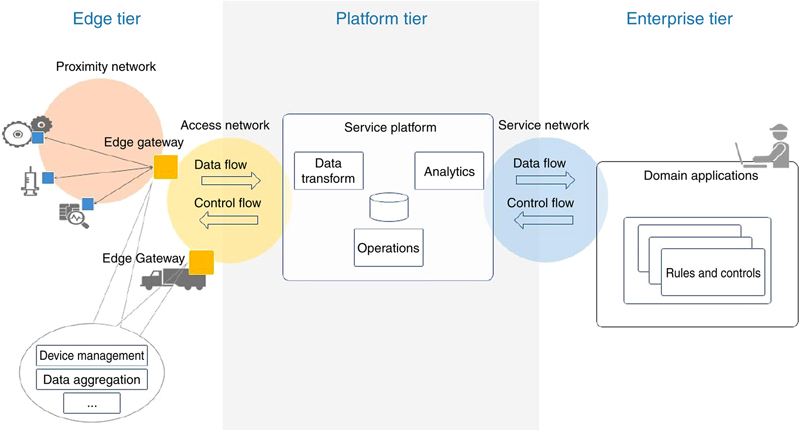
2. Standards and Technologies of Interest
2.1. Edge Compute and Communication Technologies
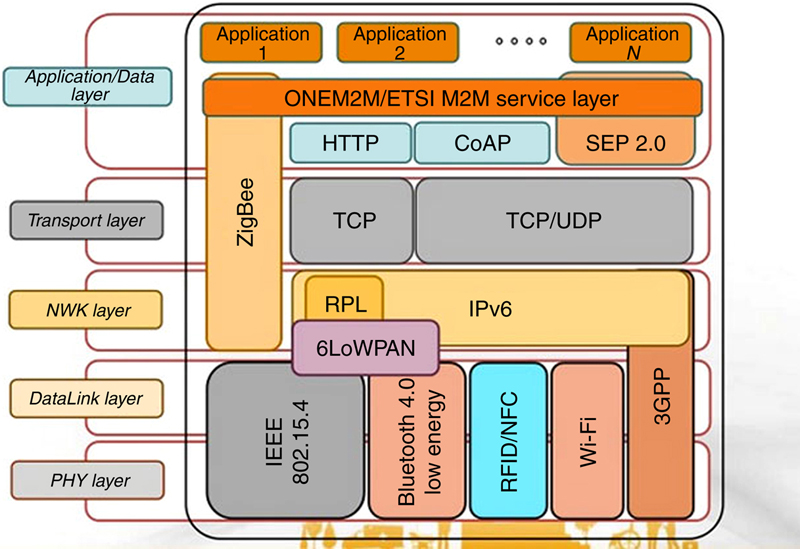
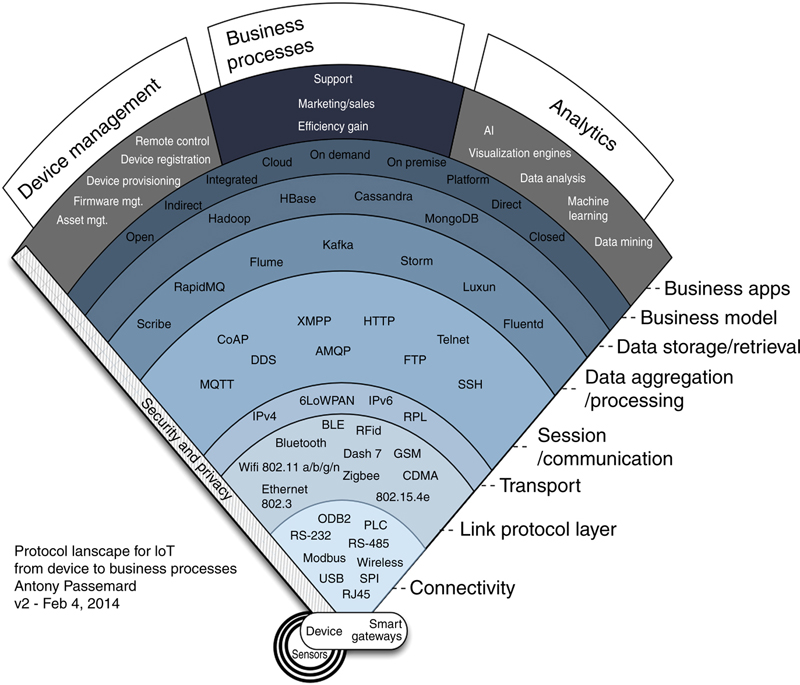
Table 5.1
Edge hardware exemplars
| x86 micro-PC | Raspberry Pi |
| Intel Galileo, Edison, | Building Automation Gateways |
| Intel DK series | Alcatel–Lucent HSG(Home Sensor Gateway) |
| Honeywell XYR300G | Lantiq GRX family |
Table 5.2
Examples of device abstraction layer software frameworks
| OIC—IoTivity | https://www.iotivity.org/ |
| OpenHab Eclipse SmartHome | |
| Thread | http://threadgroup.org/ |
| ProSyst | http://www.prosyst.com/what-we-do/ |
| Kura gateway | http://www.eclipse.org/kura/ |
| HGI | http://www.homegatewayinitiative.org/ |
| OPC-UA | https://opcfoundation.org/about/opc-technologies/opc-ua/ |
| oBIX | http://www.obix.org/ |
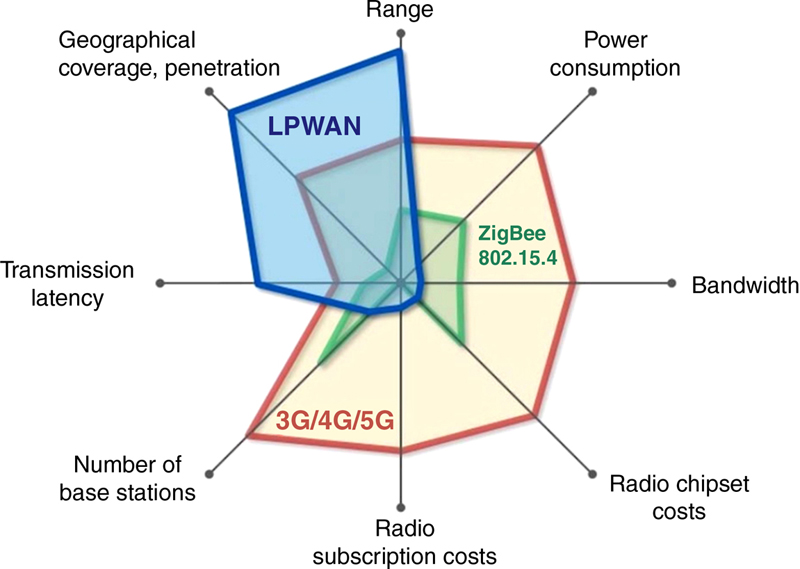
2.2. Data Analytics Technologies, Frameworks, and Applications
Table 5.3
Big data analytical infrastructure and frameworks
|
Hadoop |
|
| HDFS | For storing large datasets. Hadoop utilizes inexpensive hard drives in a very large cluster of servers. While one can expect failure on these drives, the Mean time to Failure (MTTF) is well understood. HDFS divides data into blocks and copies these blocks of data across nodes in the cluster, thus embedding built-in fault-tolerance and fault compensation within Hadoop |
| MapReduce | For processing large data sets. MapReduce is a model of programming for processing and generating large data sets utilizing a parallel, distributed algorithm on a cluster. The MapReduce framework marshals the distributed servers, running the various tasks in parallel, manages all communications and data transfers between the various parts of the system, and provides for redundancy and fault tolerance. |
| Pig | For analyzing large data sets. Is a platform for analyzing large data sets. It consists of a high-level language for expressing data analysis programs, coupled with infrastructure for evaluating these programs. The salient property of Pig programs is that their structure is amenable to substantial parallelization, which in turns enables them to handle very large data sets. Pig also allows the user to define their own user defined functions (UDFs). |
| Yet Another Resource Negotiator (YARN) | Supporting multiple processing models in addition to Map Reduce. Designed to address the tendency of MapReduce to be I/O intensive, with high latency not suitable for interactive analysis. Additionally, MapReduce was constrained in support for graph, machine learning (ML) and other memory intensive algorithms. |
| Zookeeper | Is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services. Distributed applications utilize these kinds of services and they are typically difficult to implement. Zookeeper combines these services into a interface to a centralized coordination service. The coordinated service itself is distributed and highly reliable. |
| Apache Mesos | Is a cluster manager that abstracts CPU, memory, storage, and compute resources away from machines this enables fault-tolerant and elastic distributed systems to be managed. It is built similarly to the Linux kernel, but at a different level of abstraction. The Mesos kernel runs on every machine and provides applications with APIs for resource management and scheduling across cloud environments. It can be used by Hadoop, Spark, Kafka, and Elastic Search. |
| Cloudera Enterprise, IBM big Insights, EMS/Pivotal HD, Hotonworks | Enterprise distributions of Hadoop. |
|
Big data storage |
|
| HBase, Cassandra | NOSQL Big table stores |
| CouchDB, MongoDB | NOSQL Document Based |
| Riak, Redis, HANA RDBMS, VoltDB RDBMS, OpenTSDB, KairosDB | Key Value and In-Memory Databases (both RDMS & NOSQL) |
| Neo4j | Graph Databases |
|
Big Data Processing & Querying |
|
| Hive | Is a data warehouse software which supports querying and management of large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL (HQL). |
| Apache Shark | Is a port of Apache Hive designed to run on Spark. It is still compatible with existing Hive data, megastores, and queries like HiveQL. The reason for the port is that MapReduce has simplified big data analysis but users want more complex analysis capabilities and multistage applications. |
| Apache Tajo | Data warehousing system on top of HDFS. Designed for low-latency and scalable ad-hoc queries, online aggregation, and ETL (extract-transform-load process) on large-data sets stored on HDFS and other data sources. |
| Apache Drill | Is a low latency SQL query engine for Hadoop and NoSQL. Drill provides direct queries on self-describing and semistructured data in files (such as JSON, Parquet) and HBase tables without needing to define and maintain schemas in a centralized store, such as Hive metastore. |
| Cloudera Impala | Is an open-source interactive SQL query engine for Hadoop. Built by Cloudera, it provides a way to write SQL queries against your existing Hadoop data. It does not use Map-Reduce to execute the queries, but instead uses its own set of execution daemons which need to be installed alongside your data nodes. |
| Apache Phoenix (for HBase) | Provides a relational database layer over HBase for low latency applications via an embeddable JDBC driver. It offers both read and write operations on HBase data. |
| Presto by Facebook | Is a distributed SQL query engine optimized for ad-hoc analysis. It supports standard ANSI SQL, including complex queries, aggregations, joins, and window functions. |
|
Big Data Acquisition and Distributed Stream Processing |
|
| Apache Samza | Is a distributed stream processing framework. It uses Apache Kafka for messaging, and apache Hadoop Yarn which provides fault tolerance, processor isolation, security, and resource management. |
| Apache Storm | Is a distributed real-time computation system for processing large volumes of high-velocity data. Storm on YARN provides real-time analytics, machine learning, and continuous monitoring of operations. |
| Apache Spark Streaming | Uses the core Apache Spark API which provides data consistency, a programming API, and fault tolerance. Spark treats streaming as a series of deterministic batch operations. It groups the stream into batches of a fixed duration called a Resilient Distributed Dataset (RDD). This continuous stream of RDDs is referred to as Discretized Stream (DStream). |
| Apache Spark Bagel | Is a Spark implementation of Google’s Prgel A System for Large-Scale Graph Processing. Bagel currently supports basic graph computation, combiners, and aggregators. |
| Typesafe ConductR and Akka Stream processing | ConductR is a Reactive Application Manager that lets Operations conveniently deploy and manage distributed systems. It utilizes Reactive Akka stream processing which is an open source implementation of the reactive streams draft specification. Reactive Streams provides a standard for asynchronous stream processing with nonblocking back pressure on the Java Virtual Machine (JVM). |
|
Big Data Analytics Frameworks and Tools |
|
| Apache Spark | Is a fast and general engine for large-scale processing. It provides in-memory processing for efficient data streaming applications while retaining the Hadoop’s MapReduce capabilities. It has built-in modules for machine learning, graph processing, streaming, and SQL. Spark needs a distributed storage system and a cluster manager. Spark is quick and runs programs up to 100× faster than Hadoop MapReduce in memory, or 10× faster on disk |
| Apache Flink | Is an open source system for data analytics in clusters. It supports batch and streaming analytics, in one system. Analytical programs can be written in APIs in Java and Scala. It has native support for iterations, incremental iterations, and programs consisting of large Directed acyclic graphs (DAG) operations. |
| H2O | Is an open source big data analysis offering. Using the increased power of large data sets, analytical algorithms like the generalized linear model (GLM), or K-means clustering, are available and utilize parallel computing power, rather than by truncating data. Efficiency is achieved by dividing data into subsets and then analyzing each subset simultaneously using the same algorithm. Iteratively results from these independent analysis are compared, eventually convergence produces the estimated statistical parameters of interest. |
| Weka | This is a collection of data mining tasks algorithms that provide machine learning. It has tools for visualization, for data preprocessing, for classification, for regression, for clustering and for association rules. It facilitates the development of new machine learning schemes. |
| Massive Online Analysis (MOA) | Branched from Weka, designed for data streams and concept drift. It has APIs to interact with Scala and R. |
| RapidMiner and RapidMiner Radoop | The Rapidminer platform provides an integrated environment for machine learning, data mining, text mining, predictive analytics and business analytics. Rapidminer Radoop is a big data analytics system it provides visualization, analysis, scripting, and advanced predictive analytics of big data. It is integrated into RapidMiner on top of apache Hadoop. |
| Apache SAMOA | Enables development of new machine learning (ML) by abstracting from the complexity of underlying distributed stream processing engines (DSPE). Development of distributed streaming ML algorithms can be done once and then can be executed on DSPEs. Such as Apache Storm, Apache S4, and Apache Samza. |
| Apache Spark Mlib | Is a scalable machine learning library. It consists of common learning algorithms and utilities, such as classification, dimensionality reduction, regression, clustering, collaborative filtering, and optimization primitives. |
| Apache Spark SparkR | SparkR is an R package that provides a light-weight frontend to use Apache Spark from R. Through the RDD class SparkR exposes the Spark API. Users can interactively run jobs from the R shell on a cluster. |
| Amazon, AWS ML, Microsoft Azure ML, Google prediction ML | Commercial machine Learning (ML) solutions. |



2.3. Enterprise Technologies
| D3.js | http://d3js.org/ |
| Processing.js | http://processingjs.org/ |
| AM charts | https://www.amcharts.com/ |
| Freeboard.io | https://freeboard.io/ |
| Dashing.io | http://dashing.io/ |
| Finalboard.io | http://finalboard.com/ |
| Tableau | http://www.tableau.com/ |
| Birst | https://www.birst.com/ |
| Finalboard.io | http://finalboard.com/ |
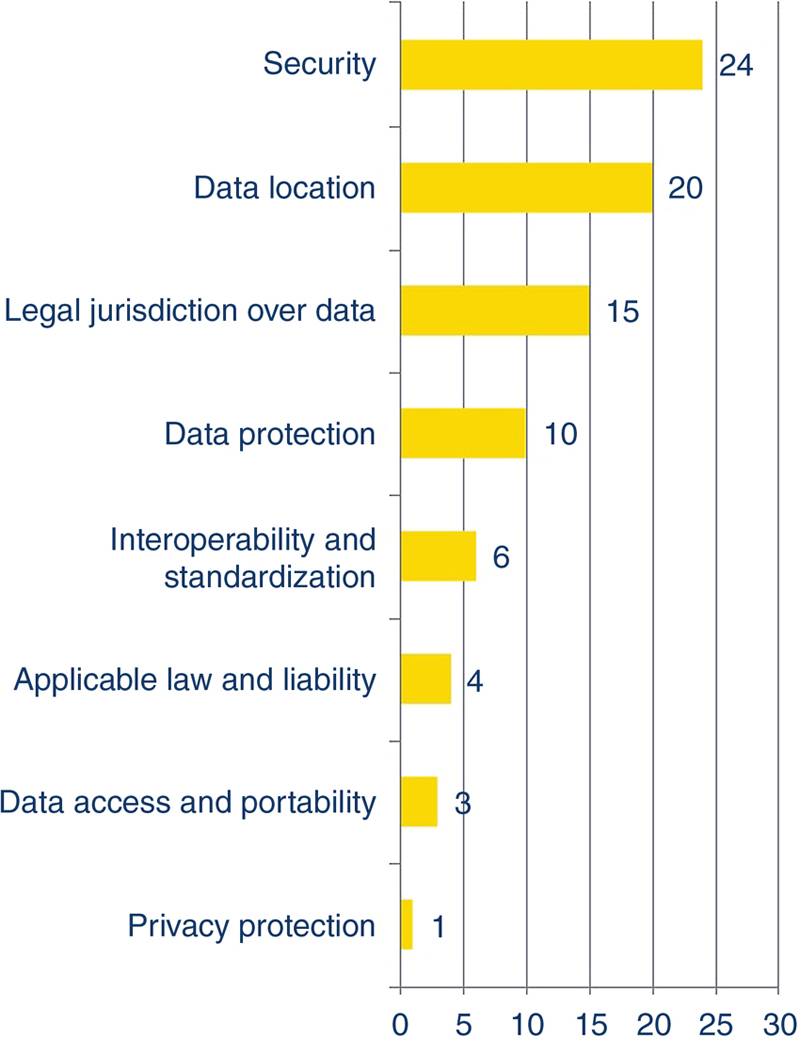
2.4. Security and Privacy Considerations
Table 5.4
EPN security considerations
| Network aspects | Other aspects |
|
• Firewall
• Virtual private networks
• Authentication
|
• Key management
• Device attestation
• Runtime controls
• Stack simplification
• Integrity measurement
• Data encryption
• Data authentication
|
| Physical aspects | |
|
• Device-specific cert
• Trusted Platform Module Platform Configuration Registers
• Secure boot
• Physical access
|

Table 5.5
Communication/Data Security standards
|
Encryption standards |
|
| Triple-DES data encryption standard | Symmetric-key block cipher, which applies the original Data Encryption Standard (DES), which is now obsolete, cipher algorithm three times to each data block. |
| Advanced Encryption Standard (AES) | AES also known as Rijndael, is a specification for the encryption of electronic data established by the US National Institute of Standards and Technology (NIST) in 2001. AES is based on the Rijndael cipher developed by two Belgian cryptographers, Joan Daemen and Vincent Rijmen, who proposed it to NIST. Rijndael is a family of ciphers with different key and block sizes. |
| RSA | Named after Ron Rivest, Adi Shamir, & Leonard Adleman at MIT, RSA s one of the first practical public-key cryptosystems and is widely used for secure data transmission. In such a cryptosystem, the encryption key is public and differs from the decryption key which is kept secret. |
| OpenPGP | Pretty Good Privacy (PGP) is a data encryption and decryption computer program that provides cryptographic privacy and authentication for data communication. PGP is often used for signing, encrypting, and decrypting texts, e-mails, files, directories, and whole disk partitions and to increase the security of e-mail communications. It was created by Phil Zimmermann in 1991. PGP and similar software follow the OpenPGP standard (RFC 4880) for encrypting and decrypting data. |
|
Wireless standards |
|
| Wi-Fi Protected Access (WPA) | Wi-Fi Protected Access (WPA) and Wi-Fi Protected Access II (WPA2) are two security protocols & security certification programs developed by the Wi-Fi Alliance to secure wireless computer networks. The Alliance defined these in response to serious weaknesses researchers had found in the previous system, Wired Equivalent Privacy (WEP). WPA2 became available in 2004 & is a common shorthand for the full IEEE 802.11i-2004 standard. |
| WPA2/802.11i uses AES | |
| A5/1 cell phone encryption for GSM | A5/1 is a stream cipher used to provide over-the-air communication privacy in the GSM cellular telephone standard. It is one of seven algorithms which were specified for GSM use. It was initially kept secret, but became public knowledge through leaks and reverse engineering. A number of serious weaknesses in the cipher have been identified. |
|
Transport Security |
|
| Secure Socket layer | Cryptographic protocol designed to provide communications security over a computer. |
| Transport Layer Security | Evolved from SSL cryptographic protocol used to provide privacy and data integrity between two communicating computer applications. Symmetric cryptography is used to encrypt the data transmitted |

2.5. Semantics, Data Models, and Ontologies of interest
3. The COOPERaTE Approach
3.1. An End-to-End Reference Model
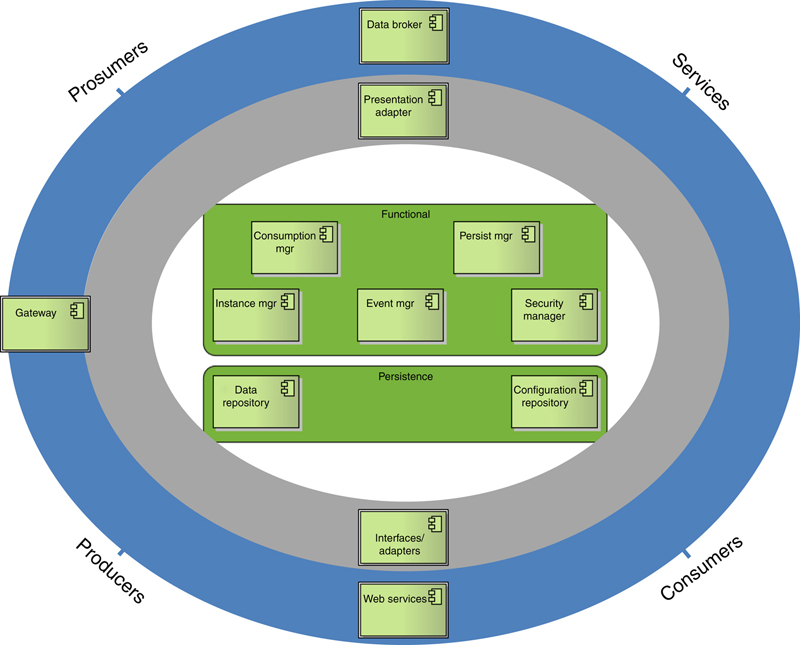
Table 5.6
COOPERaTE architecture components
| Component | Presentation Adapter PADT |
| Functionality | The presentation Adapter allows targeted adapters for specific consumption clients. There may be several types of PADT and each PADT may have several Instances configured differently. |
| Component | Consumption Mgr CMgr |
| Functionality | The CMgr provides the initial default access point to the system for Actors/consumers. The consumption Mgr will manage and ensure best fit for consumers and presentation adapters. |
| Component | Event Mgr EMgr |
| Functionality | The EMgr facilitates the communication between components via messaging mechanisms negotiating service contracts. In essence it is responsible for event propagation, initial message route configuration and queuing. The EMgr is not involved in the actual communication between components but rather routing. |
| Component | Security Mgr SMgr |
| Functionality | The SMgr is responsible for ensuring authentication and authorization and integrating security provided by individual components within each layer. |
| Component | Instance Mgr IMgr |
| Functionality | The Instance Mgr is a component to manage the life-cycle of logic/adapters / interfaces instances and their configuration. It handles the initialization of adapters and logic components and the component instances with their corresponding configurations. |
| Component | Persistence Mgr PMgr |
| Functionality | The PMgr is responsible for storage, long-time archiving, retrieving and deleting of any kind of data. Accordingly, it allows access to all persisted configuration and historical data, which are stored respectively in the configuration and data repositories. |
| Component | Data Repository DR |
| Functionality | The database component provides historical data. Historical data is collected data in the past. This data could be results from the event processing or raw data (but not limited to these). Basically, the DR is used for pattern mining and other analysis |
| Component | Configuration Repository CR |
| Functionality | This component maintains Configuration data, which includes all data necessary to configure the internal components of the COOPERaTE system including COOPERaTE consumer profile information. |
| Component | Interfaces/Adapters IA |
| Functionality | Adapters support receiving notifications, events or data from external systems devices as well as querying of same. It is possible to forward data and trigger actions to external systems. Each adapter provides an interface that allows another Layer to query for data from external systems. Several types of adapter and several instance of each adapter type may exist. |
| Component | Data Broker Br |
| Functionality | The purpose of the Br is to deliver content/messages to the consumers that is actors or systems components. |
| Component | Gateway G |
| Functionality | The G component is responsible for providing a subset of the COOPERaTE system functionality but on a compute constrained device. The G will be utilized with respect to edge v cloud processing or rather a compute-centric approach whereby compute processing occurs where most appropriate. |
3.2. A System-of-Systems Approach
“allowing for interoperability at the data level and by leveraging existing solutions via common communication interfaces, one can produce a loosely coupled integrated solution that goes beyond the current state of the art and which is likely to be adopted given an existing brownfield reality”.
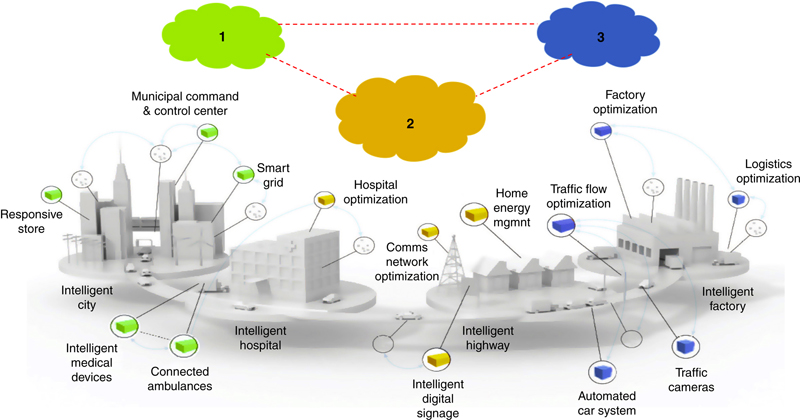
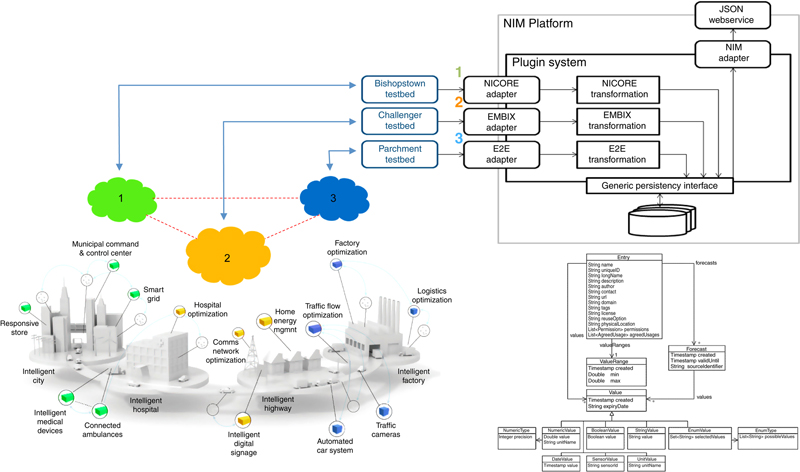
4. A NIM Enabled System-of-Systems
4.1. Overview
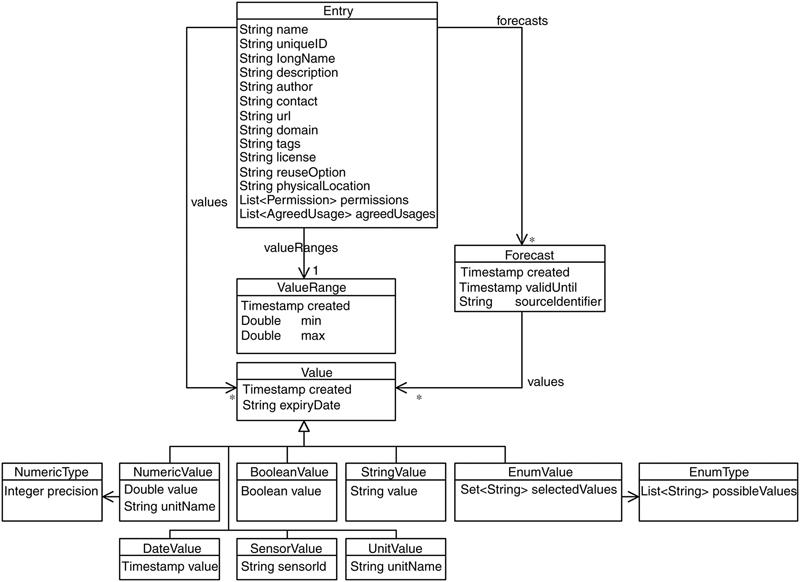
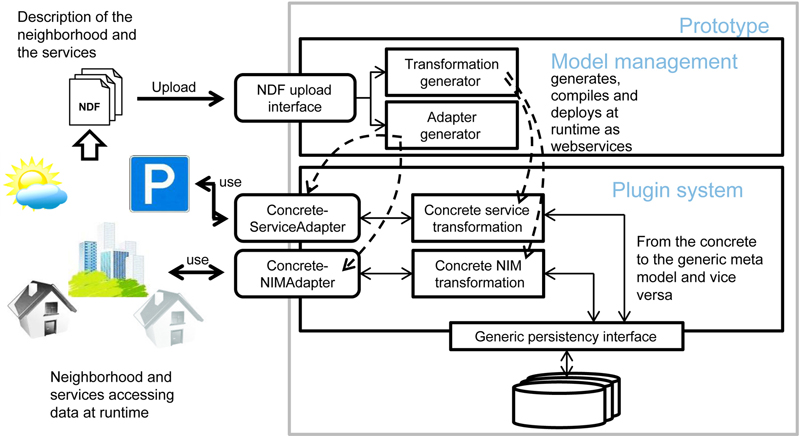
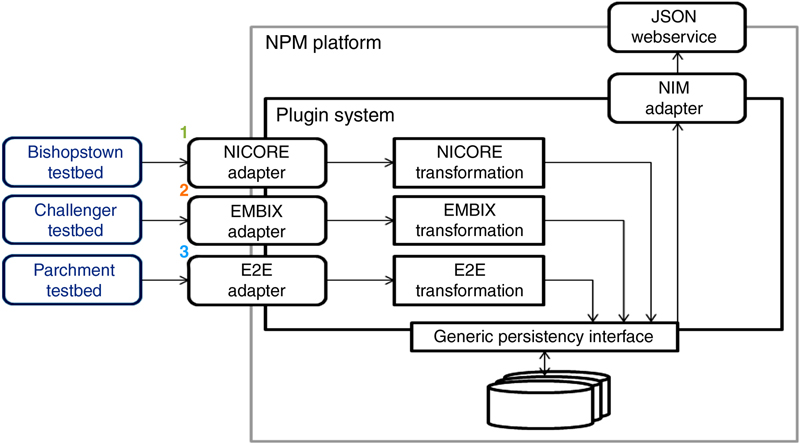
4.2. Technical NIM Description
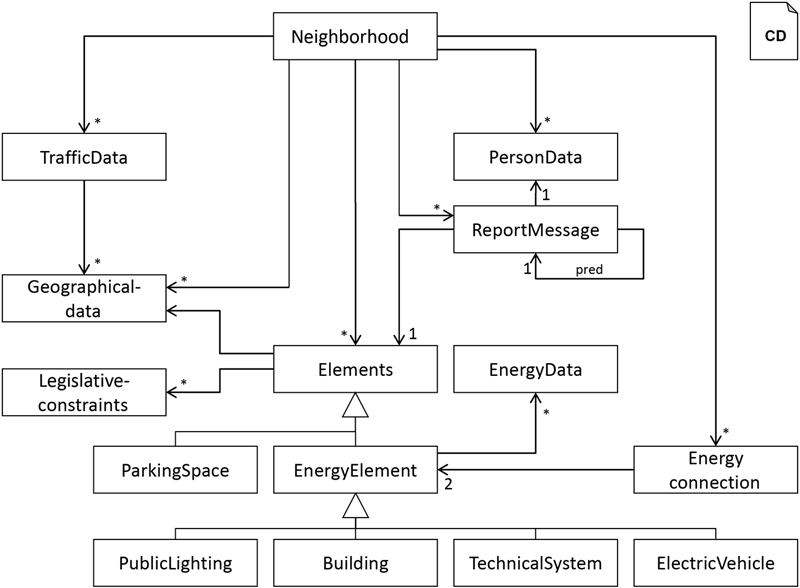
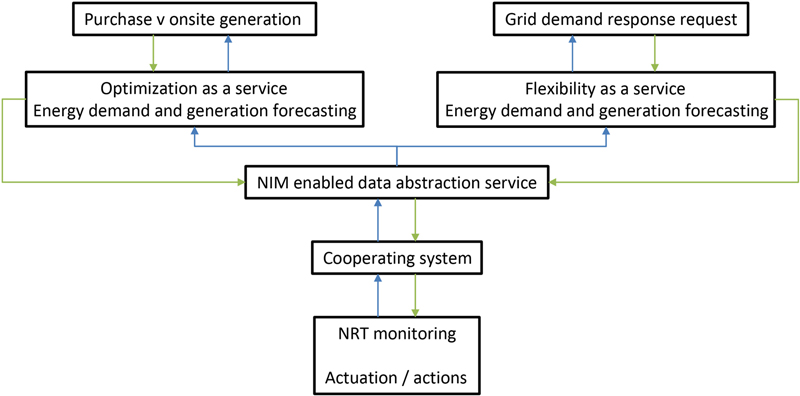
5. Example Neighborhood Services
5.1. Energy Services—Commercial
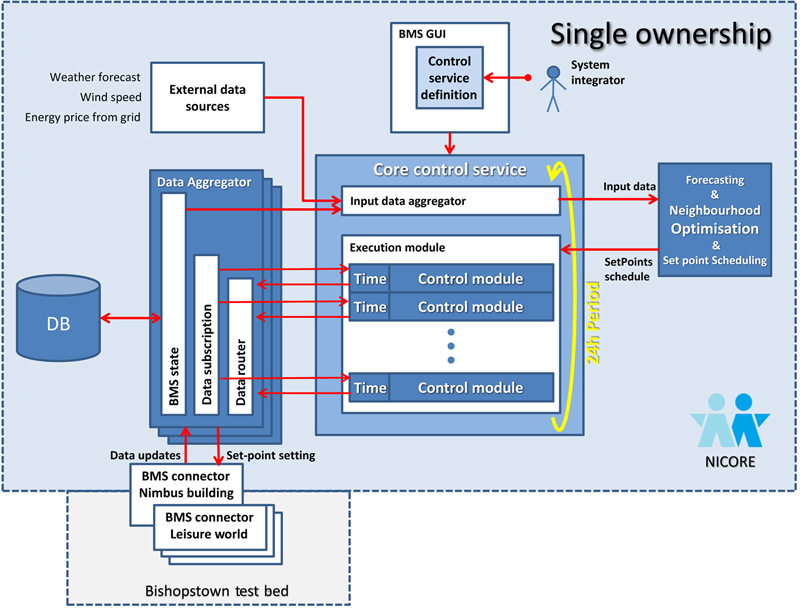
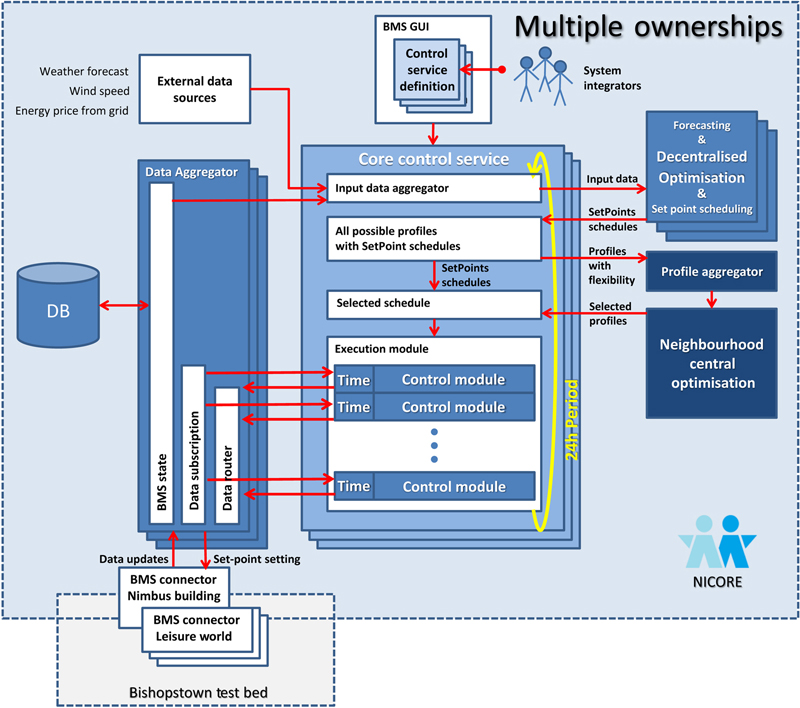
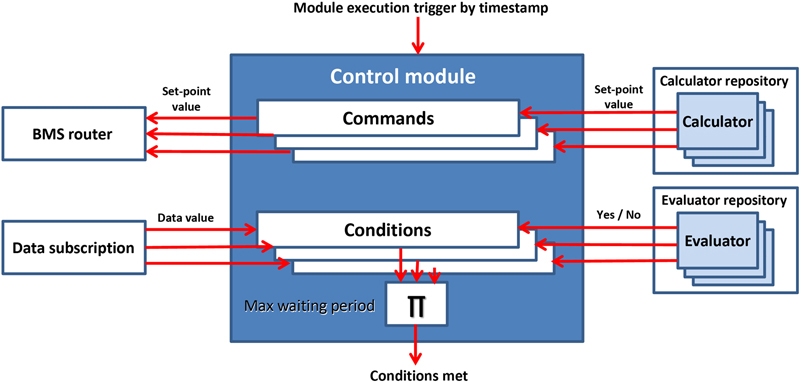
5.1.1. Forecasting Services
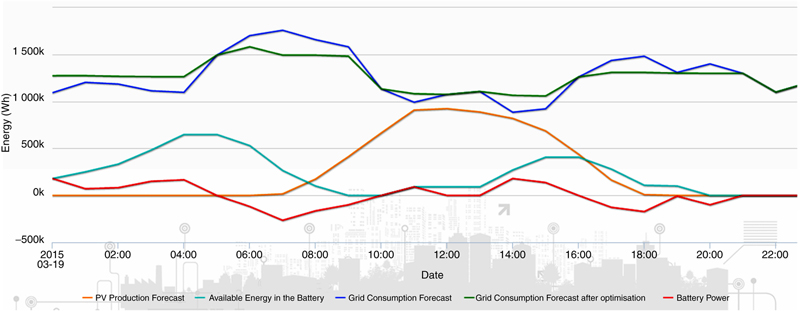
5.1.2. Optimization Service
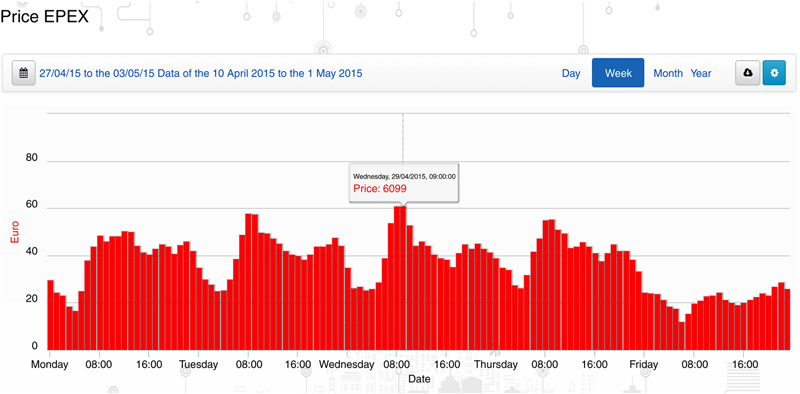
5.1.3. Demand Response Service
5.1.4. Visualization Service
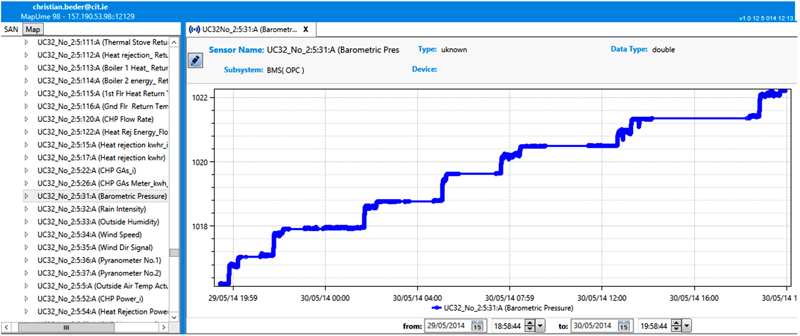
5.2. Energy Services—Residential
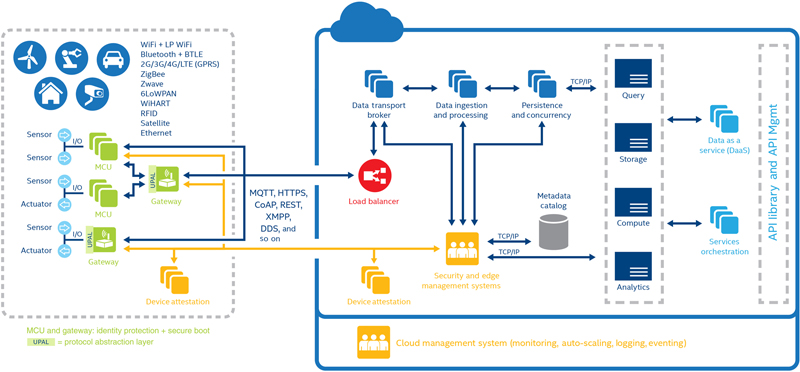
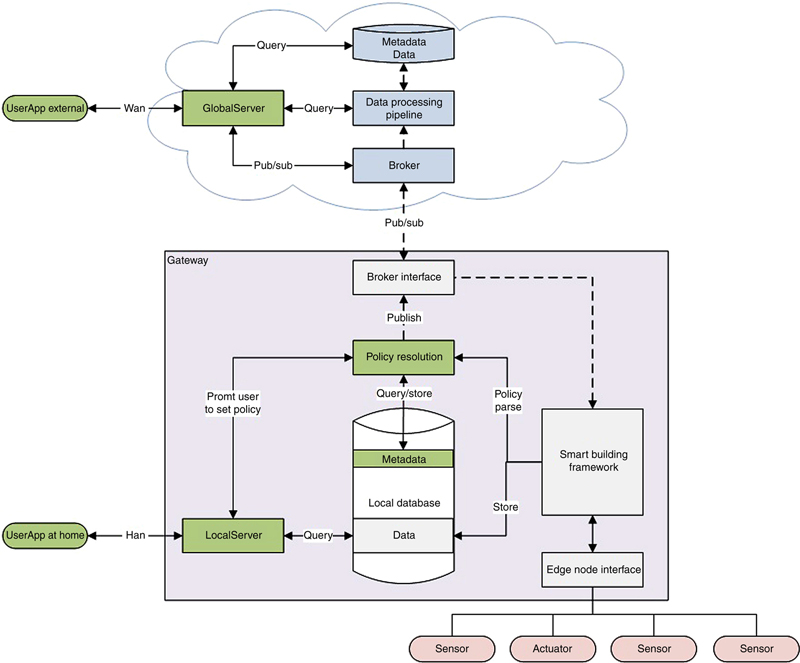
5.2.1. User Defined Data Access
5.2.2. Demand Side Management Services
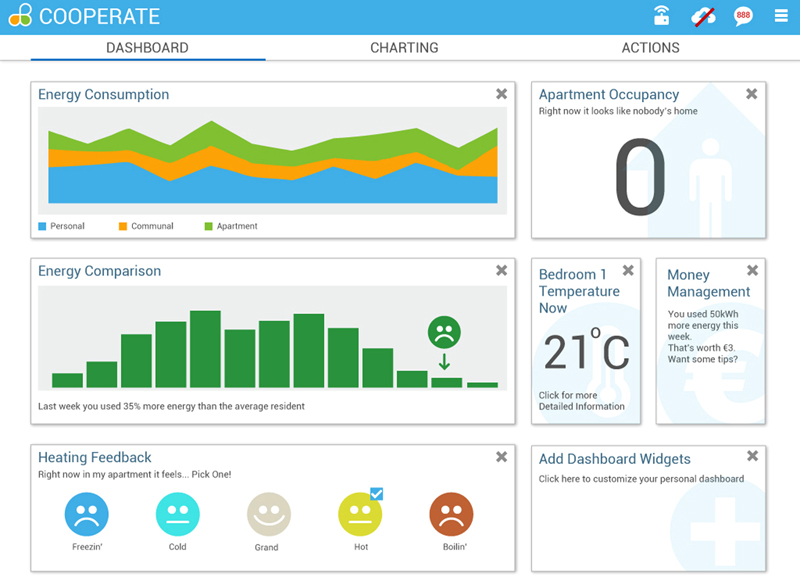
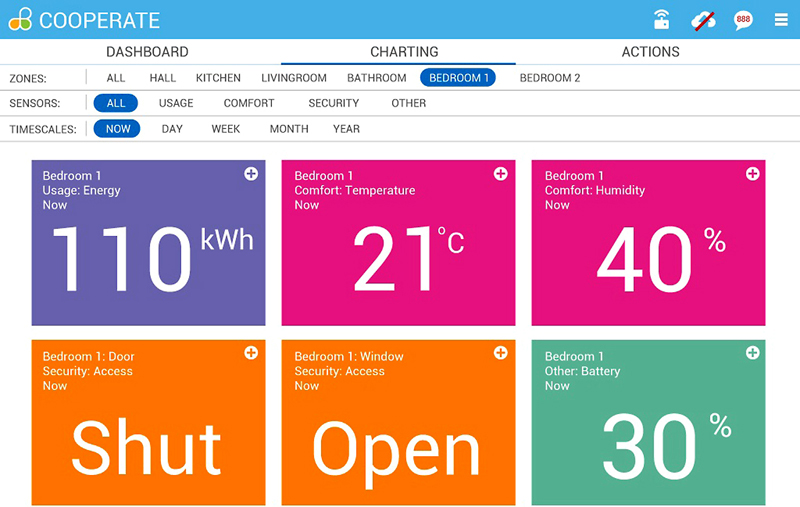
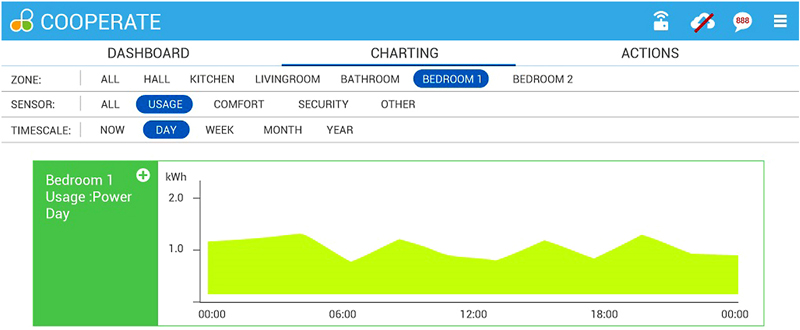
5.2.3. Optimization/Flexibility Service
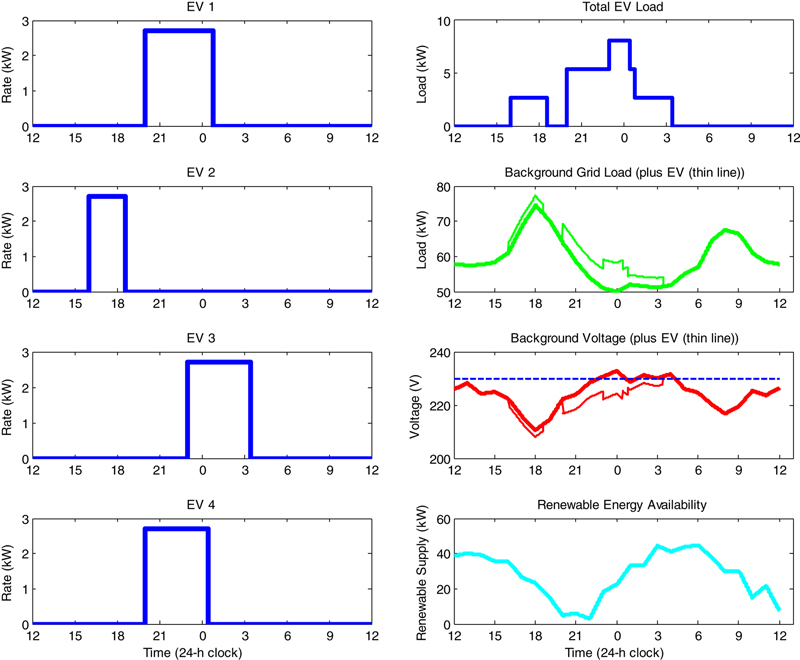
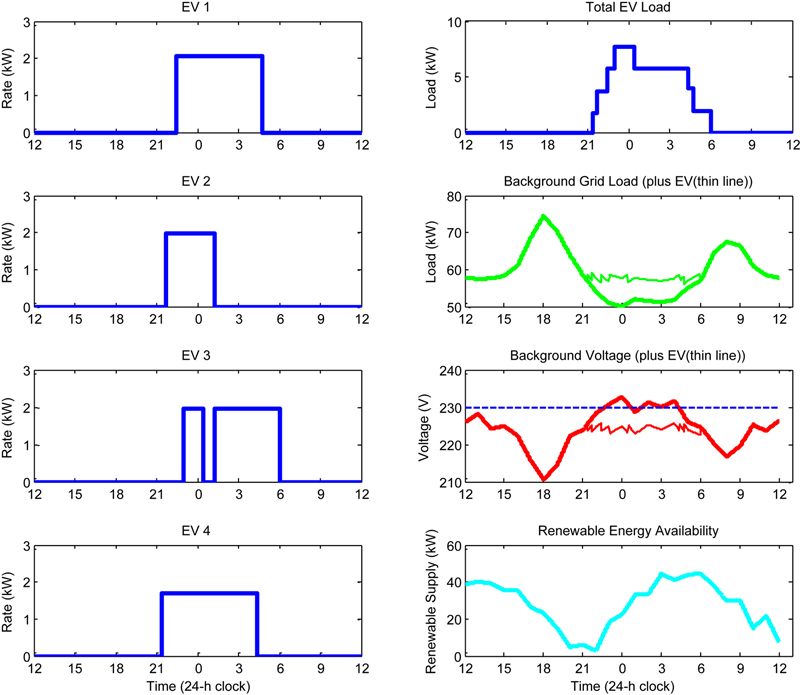
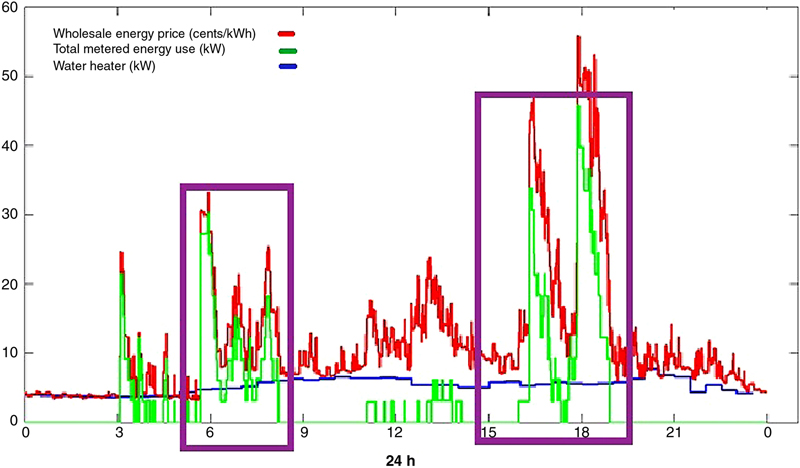
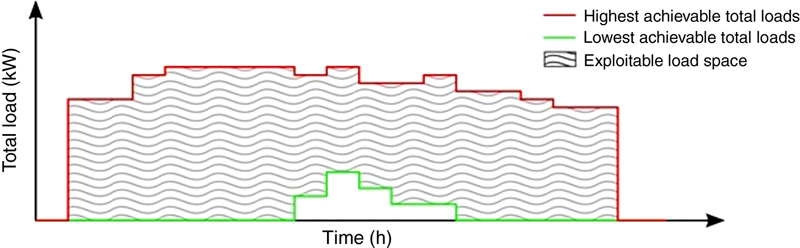
5.3. Energy Services—Industrial
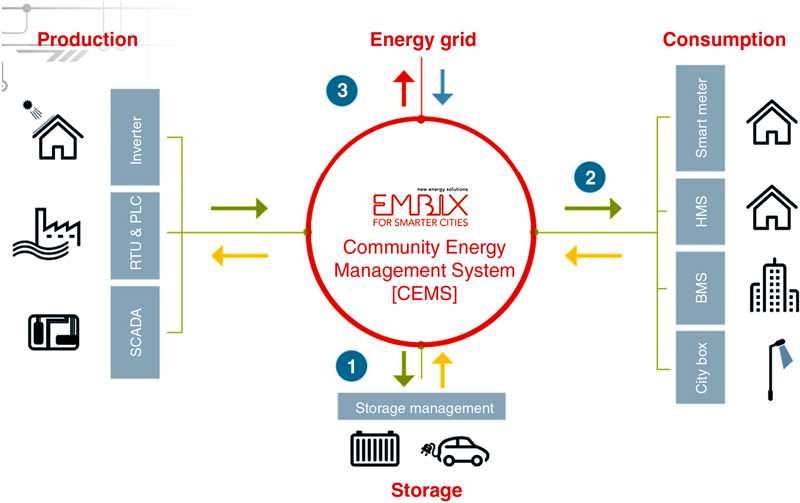
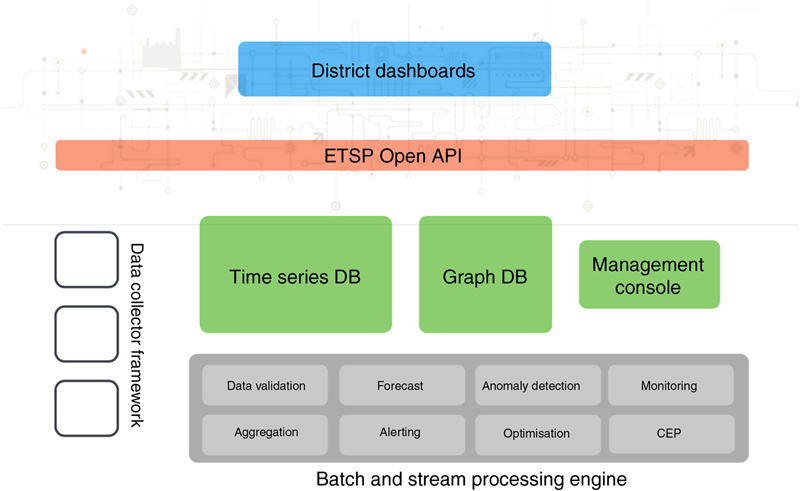
5.3.1. Visualization Service
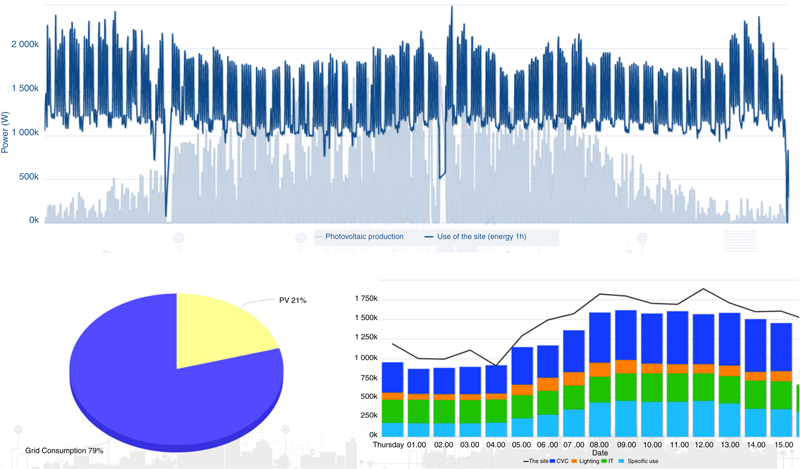
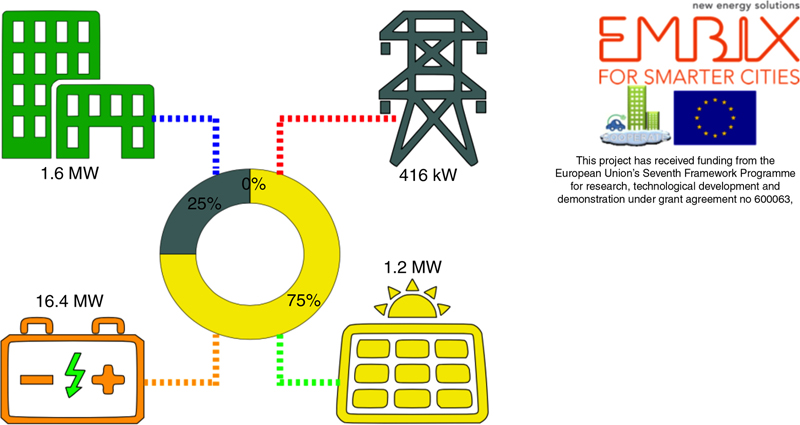
5.3.2. Load and Production Forecast
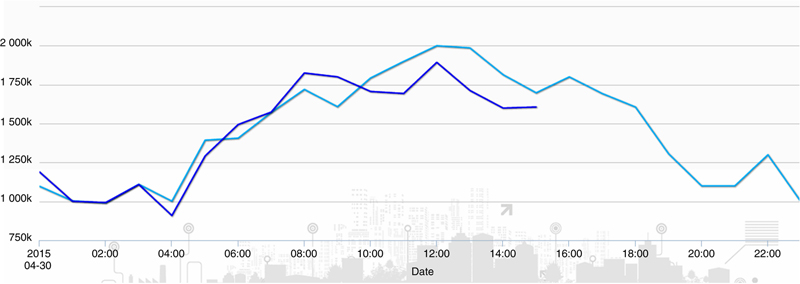
5.3.3. Flexibility Management Service