
CHAPTER 7
Making Sense of Chaos in Real Time: Part 1
This chapter discusses making sense of a large variety of types of events, as well as lots of events; reducing the numbers of events and concentrating the information; gross filters, filtering, prioritization, categorization and selective streaming, including:
- Organizing event flows and event processing strategies
- Categories of event processing strategies
- Gross filtering and prioritization
Most organizations have to deal with events from many different sources. This can become a major issue when, for example, a company tries to expand its business into new markets or is faced with marketing new products. And of course commercial entities and governments are already overrun with the expanding space of types of events that are “out there.”
One of the first problems is how to deal with large numbers of different types of events. This requires different kinds of strategies from those used to dealing with large numbers of events of the same type or maybe just a few different types (as is usually the case in, e.g., stock trading).
Typically, events are flowing into a large enterprise on a worldwide basis from a myriad of sources and at greatly different event rates varying from thousands of events per minute to just a few events per month. Additionally, the quality of information contained in the events can vary greatly depending upon the sources. In some cases, much irrelevant stuff is mixed in with highly relevant data. CEP principles and techniques must be applied in right now time to deal with both ends of the spectrum of event input rates.
Obviously, there will be a mix of different kinds of strategies at work. What will be needed is a way to organize those strategies for maximal effectiveness, that is, a process architecture for event processing strategies.
Event processing strategy: A goal-oriented algorithm or heuristic program that takes events as input and produces events as output to achieve a specified goal.
An event processing strategy is designed to achieve a goal. For example, a filtering strategy is used to remove input events that are unrelated to a specific goal by applying very simple tests. It must be computationally fast, so the tests will be simple. But usually it will only remove some of the unrelated events. For example, in choosing a filtering strategy for algorithmic trading in technology stocks, any stock trade report whose subject is not on the technology stocks list will be removed. And to detect short-term upswings, only reports of price changes would be allowed through the filter. Other strategies would be used after the filter to determine whether the price changes indicate an upswing.
An event processing system can be viewed as an event flow through a tree of event processing strategies. The system may have several goals or purposes—typically to supply different levels of real-time information to different people or indeed to different programs.
Today’s event processing systems are set up with a bunch of strategies, but little has been written about how to organize the order in which events flow through the strategies; we will address that in this chapter.
We start in Figure 7.1 with a very naïve view of an event processing system. Figure 7.1, in fact, shows only part of the event processing. Often a system will take a variety of output actions, such as sending alerts or triggering a business process, in addition to sending the output events to end users.
FIGURE 7.1 A Naive View of an Event Processing System
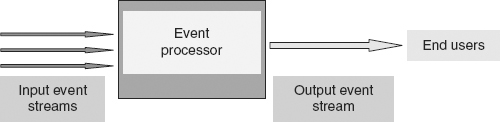
But in fact, strategies are seldom completely independent of one another, and the order in which strategies are applied can sometimes make a difference, both in terms of the quality of the information gathered and in terms of the computational efficiency of the system. Sometimes, when a number of strategies are put together, there can be surprising results (e.g., less important events get processed ahead of important ones, or some important events get omitted from further processing altogether).
Best practices for composing event processing strategies need to be defined. Events flow through processing steps: each step consists of applying a strategy to the event flow, and the resulting events flow to the next step. The flow is not necessarily linear, as we shall see. The system should be architected with a view to how various strategies interact, the complexity of the strategies, and the computational effects of the order in which strategies are applied. One needs an event-flow architecture that has the flexibility to evolve as the set of strategies change and new ones are introduced over time.
The next two chapters discuss categories of event processing strategies and event flow architectures to deal with large numbers of events and with large event type spaces at the same time. This is the typical situation facing an information-driven enterprise that provides many different kinds of services, such as a government department, a communications organization, or a large international airline. But in some cases, it can apply to small businesses as well.
Most event processing systems today are limited to processing small event type spaces.
What is an event type space? It is just a set of types of events. An event type space is usually associated with a specific application area, such as consumer relations or asset tracking. The number of events being input or output is one measure of the complexity of an event processing problem. But another measure is the number of different types of events being dealt with (i.e., a measure of the variety of events entering the system).
A large event type space system is one in which a large number of different types of events are being input to the system or output from the system, or both. The event inputs will be coming from lots of different sources. And the system has to satisfy many different demands. So one expects to see event processing operations like filtering and prioritization being applied early in the processing of incoming events, before the more precise goal-oriented strategies. Their objective is to channel the relevant types of events to specialized processing algorithms.
The first objective of event processing has two parts:
1. To extract information relevant to the goals of the enterprise from all types of event inputs
2. To make that information available to the various role players (i.e., people, applications, or devices) within the enterprise immediately
In large event type space problems, it often happens that both the spaces of input event types and output event types are large, and they can be very different. Also, there is usually another degree of complexity to the problem. Not only are the two event type spaces large and different, but they are fluid, changing all the time. New types of inputs are arising and new services are always being demanded. An event processing system must be easily reconfigured to deal with new types of inputs and outputs.
Restricting the Types of Event Inputs May Not Be an Option
Many types of events may seem irrelevant to the goals of the enterprise. They can be put on the back burner, so to speak. But should they be eliminated altogether from consideration? Experience shows that doing that can be dangerous. Obviously, some event sources can be ignored, but such choices must be careful and always subject to review. While some input events will be irrelevant to the goals of the processing, some will contain both useful and useless information all jumbled together.
Consequently, the enterprise is continuously faced with a choice between ignoring event sources or throwing more processing power at an ever-increasing filtering problem. Rather than ignore event sources, incoming events should be subjected to different kinds of operations varying in complexity from very simple and gross filtering operations at the beginning to sophisticated problem-specific strategies at the end. An array of different techniques is needed to process event inputs to concentrate relevant information.
Examples 7.1 and 7.2 are some well-known examples of the dilemma involved in choosing to restrict the types of input events.
Example 7.1: Trying to Restrict Event Inputs in Stock Trading
A stock trading operation might decide to take only stock market feeds as inputs. But as we all know, stock markets are influenced by many different kinds of information, not just the current prices of stocks.
For example,
- Industry production statistics
- Raw materials prices
- Labor union negotiations
- Weather reports
- Shipping news
and many other sources of events all have an influence on stock prices. In fact, nobody knows exactly what the total set of influences is; we only know that that set of influences is not constant; it varies from day to day.
Interestingly, recent discussion on this topic can be found in articles on stock-trading data feeds:
Algorithms going forward will have to take into account news feeds and any data source that can affect the trading decision. Trading applications will have to be more adaptable and ready to absorb new and different information types.1
The lesson from this is that one cannot plan to restrict event input; instead, one must plan for exactly the opposite! A forward-thinking stock trader will factor the feeds from news aggregators and many other sources into the algorithms used in trading strategies. But doing this requires subjecting the input events to a variety of preprocessing strategies such as adapting to standard formats and putting a lot of effort into designing event filtering strategies. Indeed, how does one input news items to a trading algorithm? This has been a subject of secret, behind-the-scenes IT development on Wall Street for twenty years.
Example 7.2: Restricting Event Inputs in Airline Passenger Scheduling Operations
An airline might be tempted to restrict the event inputs used in processing passenger schedule changes. For example, initially it might consider:
- Flight schedules
- FAA air traffic event feeds
- Current passenger schedules
- Flight connections and flight schedule delays of all connecting airlines
- Up-to-the-minute weather feeds from all operations areas
to be a sufficient list of real time event input feeds to a system that reschedules passengers making connecting flights at a large airport hub.
But not for long!
The airline will soon find that
- Aircraft maintenance tracking
- Aircraft availability
- Flight crew availability
- Maintenance schedules and tracking
- Security line and other airport operations
- Homeland security and immigration advisories
and a host of other event sources and event types need to be added to the input to improve the results of its event processing systems.
Recent experience with CEP applications to airline management systems has shown the need to use types of event inputs that had not been in the original system planning. When the input event type space was expanded beyond original plans, the CEP application was found to be useful in other airline management and planning problems in several different areas of operations. This led to other demands on the system and to its further development to produce more types of output events.
As CEP is integrated into airline operations management, it turns out that the airlines find their operations management systems can be federated into cooperating systems across the various airlines to mutual benefit.
The Expanding Input Principle: Always Plan for New Types of Event Inputs and Event Outputs
Any strategy to simplify event processing by restricting the space of event inputs or outputs will eventually be defeated by the demand for more accurate and comprehensive information.
In essence, the stock traders have been stating this principle!
The reason for this principle is very simple. There is always an implicit feedback loop from the event inputs, the event processing, and the output information to the resulting performance of the enterprise and back again. Demand for better performance implicitly requires better information and improved processing algorithms. This loop will eventually lead to an expansion of the type spaces of event inputs and outputs. Consequently, simply trying to restrict the space of input event types will not work.
Event processing systems must be designed from the beginning to be evolutionary. They must be rapidly reconfigurable to accept more types of event inputs and produce more types of outputs. As we all know, businesses are always being challenged to respond to a changing environment, and to produce new alerts and execute new processes in response to new inputs. More about reconfigurability later!
Architecting Event Processing Strategies
An important consideration in setting up an event processing system is how to flow the events through a set of processing strategies. Some categories of strategies should be applied before others. This strategy architecture should be a primary design consideration in planning the system.
When a system is first set up, a choice of event input streams is made. The inputs are limited to those that are deemed most relevant or useful to the enterprise. Usually, this is done as the application is installed and is generally a decision involving consultants and business analysts. However, according to our expanding input principle, the initial set of inputs should always be adjustable to allow for adding different types of inputs later.
Figure 7.2 shows a paradigm for event flow architecture. The first-stage processing strategies are best described as filters. If we allow a large variety of inputs, we must first filter out the relevant from the irrelevant.
FIGURE 7.2 Event Flows through a Tree of Strategies
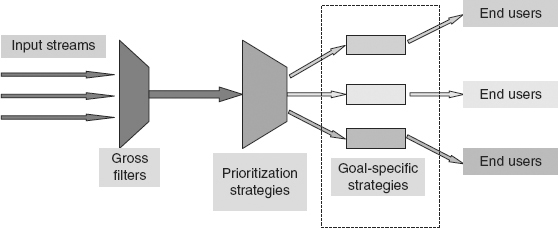
There are two families of event filters:
1. Gross filters: These are operations that eliminate events from further processing.
2. Categorization and prioritization filters: Operations that place events into various categories and determine the processing order of the various categories of events. The results of filtering are fed to the next level of event processors.
In the typical business system, these strategies are all executed on the same event-processing engine. But some systems will use several different event processors for the different strategies; usually those will be systems that deal with high volumes of event inputs.
Notice that although Figure 7.2 shows acyclic event flows, in practice it may well be that event flows through the various strategies do have cycles. Cycles are most likely to occur within the set of goal-specific strategies (i.e., in the box around the set of goal-specific strategies).
A third category, called goal-specific strategies, consists of strategies that are specialized to achieve the goals of the enterprise. They will be specific to the enterprise in question. Typically, they process the flow of events using various numerical algorithms, statistical measures, and strategies proprietary to the company to focus information in the events for different end users. They are placed last in the event flow processors, after filtering and prioritization, because they may be complex and take considerable compute power and time—so one doesn’t want to apply them to events that are going to be filtered out.
In fact, the various processing paths through the event flow tree (Figure 7.2) will take different amounts of time to deliver their results. There will be fast-flow paths that deliver events after they have been through the filters and prioritization—that is, without applying any goal-specific strategies. Other paths will be slower, because they use heavyweight goal-specific strategies that take a lot of computation time.
There is a new principle of event processing embedded in Figure 7.2: that different people within the enterprise will want to see different views of the same event input. They have different uses and goals for the information they receive, so they need to see different types of events. A network manager, for example, will be interested in everything, but specifically in network activity, server loads, event throughput, network sources, and output loads from various event generators within his network. A business planner, on the other hand, couldn’t care less about network statistics. He will be interested in new sales reports, supply chain events, perhaps sales reports of competitors, and so on—totally different types of events from the network manager. Event processing must get the right information to the right people; in fact, the event processing system might look to some end users as though they have their own separate dedicated system!
Gross filters are strategies that simply exclude events in the input feeds according to criteria that are very simple and use little processing power. Usually events are eliminated based upon their attributes or data contents.
Examples of common attributes used in gross filters:
- Event type (e.g., delete all events of type T)
- Origin (e.g., delete all events generated by sensor S)
- Topic (e.g., delete all events on yesterday’s weather)
- Creation time (e.g., delete all events created before time T–1 hour)
- Data content (e.g., delete any trade of a non-Fortune 500 company)
Gross filters must be fast so that there is little degradation in the speed of the input streams. These kinds of filters depend only upon attributes of the events and the data in them and do not refer to context, history, and state. In some systems, the input events may be flowed through several layers of gross filters.
Patterns of events can be used as filters to eliminate events that do not match the pattern. Usually, these are very simple patterns that err on the side of allowing an event if there is any doubt about whether it might be useful.
Examples: deletion of events from input stream using event patterns:
- Delete all “truck stop” and “truck start” events.
- Delete all “customer is idle” events.
- Delete all “Bought A” events dated earlier than yesterday if there have been no “Sold A” events since then.
- Delete the activities of customer C unless customer D is online at the same time.
Prioritization: Split Streaming, Topics, Sentiments, and Other Attributes
Strategies for separating events are then applied to input streams that have gone through the gross filters, as shown in Figure 7.2. They are various forms of prioritization and categorization. It is assumed that all remaining events might have some relevancy to the processing goals. So rather than being eliminated from consideration, event inputs are run through a set of ordering and categorization strategies before they are subjected to the next layer of goal-specific strategies. The essential idea is that the “more relevant” inputs should be processed before the “less relevant” inputs.
But relevancy is difficult to determine. Prioritization and categorization strategies are usually very problem specific. There are no general guidelines. In this area of processing, techniques are specialized to a given application area and in some cases depend upon categorizations and ontologies that have taken years of work and trial-and-error feedback experiments to develop.
Again, these strategies are required to be fast. But they are more complicated than the gross filters. For example, in automated stock trading, some systems split the stream of input events into many streams based upon predetermined relevancy criteria using keywords contained in the events. The streams are then prioritized.
A typical example of prioritization can be found in the use of news reports in automated stock trading. News feeds are available nowadays in which the reports are in an XML format with keywords called tags added to describe the content of each report (see Examples 7.3 and 7.4). The XML tags indicate not only the usual key economic indicators, but also trading attributes, such as sentiment and surprise values. Adding tags to news items is based upon sophisticated natural language processing of news articles.2
Example 7.3: Elementized News Feeds
Elementized news feeds deliver news items in a specified format that includes an added set of data tags. Examples include economic and corporate news items with added XML-tagged “topic” fields.
Elementizing news items involves automated language analysis to determine the presence of news on topic categories such as (an incomplete list):
- Earnings & Earnings Guidance
- Merger Announcements
- Analyst Upgrades & Downgrades
- Executive Changes
- Bankruptcy
- Stock Splits
- Significance & Unexpectedness
The topic categories on significance and unexpectedness are examples of “sentiment tags” added to all corporate news for analysis of potential impact of that news item.
These feeds are advertised in the Finextra.com article cited above as “an ultra-low-latency service delivering economic and corporate news.” Their purpose is to eliminate the need to parse unstructured text. The elementized news feeds are input directly to quantitative-analysis models and automated trading programs used in financial services operations, such as algorithmic trading, quantitative analysis, and order execution management. According the article, this approach enables “trading models to process, interpret and take action on breaking news in milliseconds.”
Example 7.4: Market Commentary on the Introduction of Elementized News Feeds in 20073
Assuming that the information is reliably encoded, these feeds should enable the creation of additional sophisticated trading and risk management algorithms.
Consider for a moment what currently occurs with the monthly release of U.S. employment data. The financial markets pause that first Friday morning of each month to digest the various statistics that are released at 8:30 ~AM ET and then trading activity often picks up a frantic pace based upon whether the economy is perceived to be stronger or weaker than expected.
By having such employment data fed directly into a quantitative algorithm, the computers can more rapidly than humans make decisions about what, if anything, should be bought or sold at which trading venue. Alternatively, the quantitative algorithms might raise a flag (or technically ‘create an alert event’) indicating that the employment data is out of some pre-determined norm and all electronic trading instructions should be stopped until there is human intervention.
Complex Filtering and Prioritization Using Event Patterns
There are cases in which it makes computational sense to run the input events through filters that are more sophisticated than gross filters. The prioritization schemes may also use complex event patterns. The complexity in the initial processing step results in fewer and more relevant events being passed on for further processing, thereby saving time downstream. Usually, in these cases much of the event processing, including filtering and prioritization, is goal-specific from the beginning.
A second approach to prioritization is to prioritize not only single events based upon their data tags, but also sets of events that match one or more event patterns on a specified list. Events that are given priority are treated as most important and passed first through the processor. Consider Example 7.5.
Example 7.5: Monitoring and Controlling a Fleet of Delivery Trucks
Let us return to the example given in the “Transportation” section in Chapter 5, in which a single human fleet supervisor is monitoring the progress of a company’s fleet of 400 delivery vans in a large metropolitan area.
The event processing system that supports the supervisor is receiving input events from each van’s radio and GPS system, and additional input events from customers, suppliers, traffic reports, weather, and other sources.
The event processing system displays output events resulting from its processing on the supervisor’s graphical screen. As Figure 7.3 shows, the input events are put through an initial complex filter that checks the event flow for each van against the van’s work order schedule. This is not a gross filter, in contrast to the processing scheme shown in Figure 7.2. It is a complex test involving matching the incoming events with event patterns that represents the van’s schedule, timing constraints, and expected progress. If the van is on schedule, no further action is taken—the van is simply displayed on the operator console as green.
FIGURE 7.3 Delivery Van Fleet’s Event Processing and Control System Showing Complex Filtering of Incoming Events
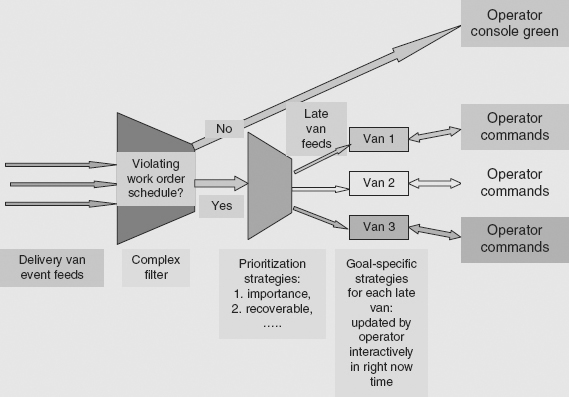
Event feeds from vans that are violating their work order schedules are then passed through the filter for further processing. At the next step the event flows are prioritized according to the importance of a van’s cargo, whether the van can recover from its lateness (which may involve many factors, including traffic reports), and other criteria. The prioritized late-van event feeds are then passed on to a goal-oriented processing stage where the goal-strategies are directly under the control of the operator. The operator interacts in right now time with these late van feeds to try to get them back on schedule. For example, the operator may elect to alter a van’s work schedule because some of its delivery or pickup orders are highly important.
This is an example of management by exception. Normal situations are simply ignored. No action is taken unless a truck gets into an exceptional situation. This is an approach to dealing with today’s information glut. CEP gives us a way to implement management by exception. There is a growing number of demanding business scenarios where the volume, latency, and complexity of the event data are exploding.
Event processing systems apply strategies to flows of incoming events. Strategies can be classified into three main categories, which are applied in the following order:
1. Filtering strategies are applied first to reduce the numbers of events that must be further processed.
2. Ordering and prioritization strategies are applied after filtering.
3. Goal-specific strategies are applied last, after filtering and ordering.
In many systems, the strategies can be altered in right now time as the event flows are being processed.
The overall objective of applying the categories of strategies in this order is to improve efficiency and speed by reducing the number of events that must be processed at each stage without eliminating events that contain information important to the goals of the enterprise.
As we discussed in the beginning of this chapter, the goal of reducing the numbers of events being processed tends to be defeated by increasing pressures for more accurate information for wider numbers of users. Event-processing systems are being required to deal with ever-wider varieties of event inputs. We take up this topic in Chapter 9.
Typically, events are processed in these systems by flowing through a tree of strategies whose paths branch toward delivering events of interest to its various users, as illustrated in Figures 7.2 and 7.3. Different users want different kinds of information. So each path through the tree gets more and more specialized toward delivering a particular kind of information.
This chapter has described strategies that tend to be applied early in the processing tree. Chapter 8 describes some of the strategies that can be used later in the event flow to abstract information in events for different users in the enterprise.
Notes
1 Dow Jones Solutions for Algorithmic and Quantitative Trading, 2008.
2 “Dow Jones Launches XML Data Feed for Algorithmic Trading,” Finextra, March 6, 2007. www.finextra.com/fullstory.asp?id=16606
3 “Dow Jones Elementized News Feed was named ‘Best Data Solution’ in the 2008 Financial News Awards for Excellence in IT.” www.stevieawards.com/pubs/awards/403_2591_19349.cfm