
7
Message Authentication and Hash Functions
1. What do you mean by message authentication?
Ans.: Message authentication refers to the mechanism used to ensure that the integrity of the received message has been preserved - that the message has not been altered during transmission. It also assures the receiver that the message has originated from the intended sender and not from any intruder. Thus, a message is said to be authentic if the message has not been altered and has come from the actual sender.
2. What types of attacks are addressed by message authentication?
Ans.: The messages transmitted across a network are subject to various attacks. The types of attacks that are addressed by message authentication are as follows:
![]() Masquerade: This attack happens when the messages from a fraud source are put into the network; an intruder impersonates an authorized entity and creates fake messages, which are sent to the recipient. This attack also includes the fake acknowledgements corresponding to the received or failed messages by some other entity except the intended recipient.
Masquerade: This attack happens when the messages from a fraud source are put into the network; an intruder impersonates an authorized entity and creates fake messages, which are sent to the recipient. This attack also includes the fake acknowledgements corresponding to the received or failed messages by some other entity except the intended recipient.
![]() Modification of the message: This attack involves making certain modifications in the contents of the captured message or changing the sequence of messages being transmitted between the communicating parties. An intruder may insert, delete or transpose the contents of the message, or he or she may reorder the messages being sent in order to cause an unauthorized effect.
Modification of the message: This attack involves making certain modifications in the contents of the captured message or changing the sequence of messages being transmitted between the communicating parties. An intruder may insert, delete or transpose the contents of the message, or he or she may reorder the messages being sent in order to cause an unauthorized effect.
![]() Timing modification: This attack involves delaying or replaying the messages being transmitted. The term ‘replay’ means capturing a copy of the message sent by the original sender and retransmitting it later to bring about an unauthorized result. In a connection-oriented application, the entire session can be delayed or replayed, whereas in a connection-less application, the individual messages can be delayed or replayed.
Timing modification: This attack involves delaying or replaying the messages being transmitted. The term ‘replay’ means capturing a copy of the message sent by the original sender and retransmitting it later to bring about an unauthorized result. In a connection-oriented application, the entire session can be delayed or replayed, whereas in a connection-less application, the individual messages can be delayed or replayed.
3. Discuss various types of authentication functions?
Ans.: Each authentication mechanism involves the use of a function to produce a value to be used for authenticating a message. This value is known as the authenticator. The authenticator enables the recipient of the message to verify the authenticity of the message.
The authentication functions that are used to produce an authenticator fall under three classes, which are as follows:
![]() Message encryption: In this class, the authenticator of the message is the ciphertext that is produced after encrypting the entire plaintext.
Message encryption: In this class, the authenticator of the message is the ciphertext that is produced after encrypting the entire plaintext.
![]() Message authentication code (MAC): In this class, the authenticator of the message is a fixed-length value that is generated by applying a function on the message and the secret key.
Message authentication code (MAC): In this class, the authenticator of the message is a fixed-length value that is generated by applying a function on the message and the secret key.
![]() Hash function: In this class, a hash function (also called message digest algorithm ) is applied on a variable-length message to produce a fixed-length output that acts as the authenticator of the message.
Hash function: In this class, a hash function (also called message digest algorithm ) is applied on a variable-length message to produce a fixed-length output that acts as the authenticator of the message.
4. Write a short note on message authentication code?
Ans.: Message authentication code (MAC) is a piece of information used to authenticate a message being transmitted between two communicating parties. A MAC algorithm is applied on an arbitrary-length message to be authenticated and the common secret key shared between the parties to generate a small fixed-size block of data called cryptographic checksum (or MAC). The calculated MAC is concatenated with the original message, and the message plus MAC are then sent to the receiver.
Let A and B be two parties that share a common secret key K. When A wants to send a message (say, M) to B, it computes MAC by applying the MAC algorithm (say, C) on message M and secret key K, as shown here:
MAC = C(K, M)
After MAC has been computed, A sends the message M and MAC to B through the network. On receiving, B distinguishes the message M from MAC and applies the same MAC algorithm C on the message M and the secret key K to generate MAC'. Then, MAC' and MAC are compared to determine whether they are the same. If so, B is assured that the message M has not been altered, because if it was changed by an attacker, then MAC' would not match with MAC; the attacker cannot change MAC to correspond to the changed message, as he or she is not aware of the secret key K. In addition, B is also assured that the message M has actually come from A, since nobody else could have created a message with the proper MAC without having knowledge of the secret key K. Notice that in case the messages being transmitted between A and B also comprise sequence numbers, then B can also be assured about the proper sequence, as the attacker cannot change the sequence number successfully.
Figure 7.1 depicts the use of MAC to authenticate a message at the sender's end and to verify the authenticity of the message at the receiver's end.

Figure 7.1 Message Authentication using MAC
MAC is different from message encryption in the sense that the MAC algorithm is not required to be reversible as it should be for decryption at the receiver's end. Generally, the MAC function is a many-to-one function whose domain comprises messages of any length, while the range comprises all possible MACs and keys. For an n-bit MAC, there are 2n possible MACs and m possible messages, where m>>2n. For a k-bit key, there are 2k possible keys. For example, if the messages being transmitted are of 100 bits and the MAC is of 10 bits, then there are 2100 different messages and 210 different MACs. Thus, it can be said that, on average, each MAC is generated by 2100/210 = 290 different messages. Furthermore, if the key used is of 10 bits, then there are 210 different mappings between all the messages and the MACs.
MAC is widely helpful in some situations, which are as follows:
![]() When the same message has to be broadcasted to several destinations, it would be desirable to assign to one destination the responsibility of checking the authenticity of the message. Thus, the plaintext message and the message authentication code must be sent to all the destinations. Since the responsible destination is aware of the secret key, it verifies whether the message is authentic. In case some violation occurs, it alerts other destinations.
When the same message has to be broadcasted to several destinations, it would be desirable to assign to one destination the responsibility of checking the authenticity of the message. Thus, the plaintext message and the message authentication code must be sent to all the destinations. Since the responsible destination is aware of the secret key, it verifies whether the message is authentic. In case some violation occurs, it alerts other destinations.
![]() When the receiving side is heavily loaded and cannot decrypt all the messages, then messages can be authenticated on a selective basis. That is, the messages are chosen randomly for verification.
When the receiving side is heavily loaded and cannot decrypt all the messages, then messages can be authenticated on a selective basis. That is, the messages are chosen randomly for verification.
![]() When it is more important to authenticate messages rather than keeping them secret.
When it is more important to authenticate messages rather than keeping them secret.
5. Write down the purpose of hash function along with a simple hash function.
Ans.: A hash function (or one-way hash function) is a variation of MAC used for message authentication. Like MAC, it takes a variable-length message as input and produces a fixed-length output referred to as the hash code or hash value or a message digest. However, unlike MAC, a hash function does not require a secret key and, thus, is also called a non-key message digest. Formally, the hash code (h) can be expressed as:
h = H(M)
Where,
M = message (string) of any length
H = hash function
H(M) = a fixed-length string (hash code).
At the sender's end, the hash code is computed and concatenated with the message. The message plus hash code are then sent to the receiver through the network. At the receiving end, the receiver separates the message from the hash code and again applies the hash function on it to produce a new hash code. If the recomputed hash code is the same as the received hash code, the message is authenticated.
A secret key is not given as an input to hash function. Thus, hash code plays the role of a ‘signature’ for the data being sent from the sender to the receiver through the network. In addition, the hash function takes into account all bits of the message; therefore, a change to any bit of the message results in a change to the hash code.
Simple Hash Function
All the hash functions consider the input message as a sequence of blocks where each block is of m bits. They process the input message one block at a time iteratively and produce an m-bit hash code.
One of the simple hash functions takes the bitwise XOR of every block of the input message to produce the hash code. This can be expressed as follows:
![]()
Where,
hi = ith bit of the hash code with 1 ≤ i ≤ m
n = number of m-bit blocks in the input message
bik = ith bit of the kth block with 1 ≤ k ≤ n.
The preceding operation is known as longitudinal redundancy check (LRC), and it generates a simple parity corresponding to each bit position. It effectively ensures data integrity for randomly selected input; however, it proves less effective in case of predictable formatted data. To improve the effectiveness, an alternate simple hash function is used that circular-shifts (or rotates) the hash value by one bit after processing each block. This hash function uses the following steps to produce an m-bit hash code from an input message consisting of m-bit blocks.
1. Set all the m bits of hash code to zeros.
2. For each successive m-bit block, perform the following:
i. Shift left the current value of hash code by one bit.
ii. Take the XOR of new hash code and the block.
6. What characteristics (requirements) are needed in secure hash function.
Ans.: A hash function takes as input a variable-length message, a file or any block of data and produces a hash code, referred to as the fingerprint of the message, file or block of data. If M is a variable-length message and H is the hash function, then the hash code (h) can be expressed as:
h = H(M)
The hash function must possess the following properties in order to be used for message authentication.
1. The hash function should be applicable on a block of data of any size.
2. The output produced by the hash function should always be of fixed length.
3. For any given message or block of data, it should be easier to generate the hash code. That is, given a message M, H(M) should be easily computable. This property is important to make the hardware and software implementation feasible.
4. Given a hash code, it should be nearly impossible to determine the corresponding message or block of data. That is, if h is given, one should not be able to determine M such that H(M)= h. This is referred to as one-way property. This property is of prime importance when a secret value is being used in the authentication technique. Though the secret value is not sent through the network, the attacker can still easily find out the secret value if the used hash function does not show the one-way property.
5. Given a message or block of data, it should not be computationally feasible to determine another message or block of data generating the same hash code as that of the given message or block of data. That is, if M1 is given, there is no other M2 (where M1 ≠ M2) such that H(M1)= H(M2). This property is referred to as weak collision resistance.
6. No two messages or blocks of data, even being almost similar, should be likely to have the same hash code. That is, it is virtually impossible to determine a pair (M1,M2) such that H(M1)= H(M2). This property is referred to as strong collision resistance.
From these six properties, if the first five properties are satisfied, then the hash function is called a weak hash function, and if all the six properties are satisfied, then it is called a strong hash function. This is because the sixth property protects the hash function from the birthday attack.
7. Describe the birthday attack against any hash function.
Ans.: When two different messages on applying the same hash function yield the same hash code, it is known as collision. A specific type of cryptographic attack that is performed against hash functions in order to discover collisions in them is referred to as birthday attack. This attack is based on the principle of Birthday Paradox, according to which, in a group of 23 randomly chosen people, the probability of finding two people sharing the same birthday is more than 50%. In case the number of people increases to 57, this probability becomes more than 99%. Thus, it can be concluded that the probability of finding a pair with same birthday in a group increases with increase in number of people in the group and, at a certain point, it may reach 100%.
In a birthday attack against a given hash function H, the goal of the attacker is to find two input messages, say M1 and M2, such that H(M1)= H(M2); this is what is referred to as collision. To detect the collision, the attacker may continue to evaluate the hash function H for different randomly selected inputs until he or she gets the same output more than once. In case a hash function H produces N different outputs with same probability and N is quite large, then it can be expected to get a pair of different inputs M1 and M2 such that H(M1) = H(M2) after we evaluate the function for approximately 1.25![]() different inputs on average.
different inputs on average.
To estimate the expected number of values that we must choose before detecting the first collision, let us take q values at random from the set of N values, with repetitions allowed. Further, assume that p(q; N) denotes the probability that at least one value is chosen more than once. The approximate value of this probability can be given as shown here:
![]()
If n(p; N) denotes the least number of values that must be chosen such that the probability for detecting a collision is at least p, then we can find the approximate value of n(p; N) by inverting the preceding expression as shown here:
![]()
For 50% probability of detecting collision (that is, p = 0.5), we get
![]()
Now, the expected number of values that must be selected before detecting the first collision, denoted as Q(N), can be approximated as shown here:
![]()
For example, if we use a 64-bit hash code, then there will be approximately 1.8 × 1019 different outputs. If all of these are equally probable (the best case), then an attacker would require approximately 5.1 × 109 attempts to generate a collision using brute force. This value is called birthday bound. In general, for an m-bit hash code, the birthday bound can be approximated as 2m/2.
8. Write a short note on iterated hash functions?
Ans.: To ensure message integrity, the hash functions are used that produce a fixed-length message digest from a variable-length message. To accomplish this efficiently, iterations are used in the hash function. In place of using hash functions with variable-length input, the hash functions with fixed-length input can also be created and used the required number of times. Such a fixed-size input hash function is termed as a compression function. This function takes as input an m-bit string and produces an n-bit string as output such that n < m. This scheme is known as iterated cryptographic hash function.
There are two different approaches that can be used in designing iterated hash functions. In the first approach, the cryptographic hash functions employ a compression function that is made from the scratch and has been designed for that specific purpose. Examples of such cryptographic hash functions include all versions of message digest (MD) algorithm such as MD2, MD4 and MD5 as well as all versions of secure hash algorithm (SHA) such as SHA-1, SHA-224, SHA-256, SHA-384 and SHA-512. On the other hand, in the second approach, the cryptographic hash functions use a symmetric-key block cipher such as triple-DES or AES as the compression function. Notice that the role of block ciphers here is to perform only encryption and not decryption. An example of a cryptographic hash function based on this approach is Whirlpool.
9. Explain MD5 algorithm with the help of a block diagram.
Ans.: MD5 (message digest, version 5) is a cryptographic hash algorithm developed by Ron Rivest in 1991. It came into existence after its four predecessors, all of which were developed by Rivest. The original hash algorithm was named MD. Then came MD2, which was quite weak. Therefore, Rivest started working on MD3. However, due to some technical deficiency, MD3 was never released. This led Rivest to the release of MD4, which too worked for a short period of time and ultimately, it was replaced by MD5. MD5 is quite fast and has been resistant to collision till now.
Figure 7.2 shows the block diagram for generating message digest using MD5. The algorithm takes a variable-length message as input and produces a fixed-length message digest. It processes the given input in blocks of 512 bits, which are again divided into 16 blocks of 32 bits each. The output obtained is a set of four blocks of 32 bits each, that is, total 128 bits.
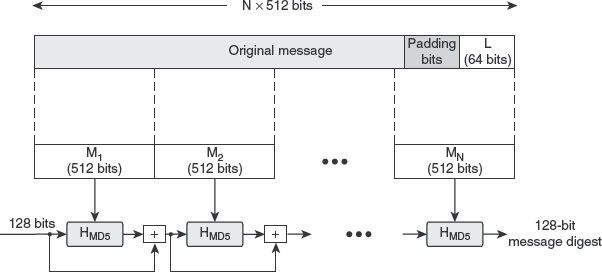
Figure 7.2 Generation of Message Digest using MD5
The following steps are involved in the working of MD5.
Step 1: Append Padding Bits
In the initial step, the padding bits are added to the end of the original message. This is done as to make the number of bits in the message equal to 64 bits less than an integral multiple of 512. For example, if the original message is of 1900 bits, then 84 bits are padded to make the length of the message 1984 bits. The reason behind adding 84 bits is that when we add 64 to 1984, we get 2048, which is an exact multiple of 512 (512*4 = 2048). Padding bits comprise a single one bit followed by the required number of zero bits. It is mandatory to add padding bits even if the length of the original message plus 64 is already an exact multiple of 512. For example, if the original message is of 448 bits (448 + 64 = 512), even then 512 padding bits need to be added. Thus, the number of padding bits may vary from 1 to 512 bits, and the length of the message after adding padding bits can be 448 bits, 960 bits, 1472 bits, and so on.
Step 2: Append Length
The next step is to calculate the length of the message excluding the padding bits. For example, if the original message is 1900 bits long, and the length of message after adding padding bits is 1984 bits, then here the length is considered as 1900 and not 1984. The length (say, L) is expressed as a 64-bit value, and these 64 bits are added at the end of the message, plus the padding bits. In case the message is too long to be expressed as a 64-bit value, then we need to take the length modulo 264. After appending the length, we get a message whose length is an exact multiple of 512. Now, the digest of this message is to be found.
Step 3: Divide the Input Message into 512-bit Blocks
In this step, the input message is divided into N 512-bit blocks, denoted as M1, M2, …, MN. For example, in our case, the 2048-bit message will be divided into four blocks of 512 bits each.
Step 4: Initialize MD Buffer
A 128-bit buffer is used to hold the intermediate and final results of the hash function while computing the message digest. This buffer is represented as four 32-bit registers (A, B, C, D). Each of these registers is initialized with a 32-bit integer in hexadecimal (initial hash values), as shown here:

The MD5 algorithm treats the registers A, B, C and D as a single 128-bit register ABCD.
Step 5: Process Blocks
Each 512-bit block of the message is now processed as follows:
a. Copy the contents of A, B, C and D into four corresponding 32-bit variables H0, H1, H2 and H3 as shown here:
![]()
b. The 512-bit block is divided into 16 sub-blocks of 32 bits each, denoted as, S1, S2, …, S16 or in general as Si where 1 ≤ i ≤ 16.
c. Now, the compression function, labelled as HMD5 in Figure 7.2, is applied on the 512-bit block. The compression function comprises four rounds where each round takes three inputs: all the 16 32-bit sub-blocks of the current 512-bit block, the register ABCD and an array of constants T (see Figure 7.3). The array T consists of 64 elements of 32 bits each, represented as T1, T2, …, T64 or in general as Tj where 1 ≤ j ≤ 64. As there are total four rounds, 16 values of array T are used in each round. Each round updates the contents of the register ABCD by performing the MD5 algorithm steps.
d. Each round contains 16 iterations, one per each sub-block, that is, there are total 64 iterations in MD5 for one 512-bit block. Each iteration involves certain operations to update the contents of the register ABCD.
After performing all the 64 iterations for one 512-bit block, each of the four registers (A, B, C and D) is incremented by the value it had before the processing of that block, as shown here:

This incremented value of A, B, C and D (128 bits together) becomes one of the inputs to the first round of the next 512-bit block. Notice that addition is performed using modulo 232.

Figure 7.3 MD5 Processing of a Single 512-Block
Single MD5 Iteration: Each iteration in MD5 goes through the following steps (see Figure 7.4).
i. Apply a function F on registers B, C and D. The function F differs for each round.
ii. Add the contents of register A to the output of the previous step.
iii. Add the message sub-block Si to the output of the previous step.
iv. Add the constant Tj to the output of the previous step.
v. Perform circular left shift operation by m bits on the output of the previous step. Notice that the value of m and Tj differ for each iteration, as defined by MD5.
vi. Add the contents of register B to the output of the previous step.
vii. Store the contents of register D into a 32-bit temporary variable (say, Temp).
viii. Copy the contents of register C to register D.
ix. Copy the contents of register B to register C.
x. Copy the output of step (vi) to register B.
xi. Copy the value of variable Temp to register A.
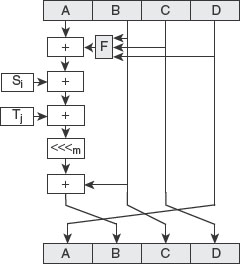
Figure 7.4 Single MD5 Iteration
After performing these steps, we get new ABCD for the next iteration.
Mathematical representation of a single MD5 iteration can be given as:
![]()
Where,
F = a non-linear function different for each round
Si = Sq x 16 + i, the ith 32-bit sub-block in the qth 512-bit block of the message
Tj = a 32-bit constant
<<<m = circular left shift by m bits
+ = addition modulo 232.
Function F: The function F is different in each of the four rounds, while the rest of the steps are the same. The function F involves some Boolean operations on the variables B, C and D in the four rounds, as shown here:

Step 6: Output
After all the 512-bit blocks of the message have been processed, the contents of the register ABCD form the 128-bit message digest.
10. Explain the working of SHA-1.
Ans.: Secure Hash Algorithm (SHA), also referred to as Secure Hash Standard (SHS), was developed by the National Security Agency (NSA). In 1993, it was published by the National Institute of Standards and Technology (NIST) as a Federal Information Processing Standard (FIPS PUB 180). In 1995, a revised version of SHA was issued as FIPS PUB 180-1, which was given the name SHA-1. SHA-1 has been designed such that it is computationally infeasible to determine the original message from a given message digest, as well as to determine two messages generating the same message digest.
Figure 7.5 shows the block diagram for generating a message digest using SHA-1. Like MD5, the SHA-1 algorithm takes an input message with a maximum length of 264 bits and processes the input in 512-bit blocks. However, it produces a message digest of 160 bits, unlike MD5.

Figure 7.5 Generation of Message Digest using SHA-1
The working of SHA-1 involves the following steps:
Step 1: Append Padding Bits
In the initial step, the padding bits are added to the end of the original message. This is done as to make the number of bits in the message equal to 64 bits less than an integral multiple of 512. For example, if the original message is of 1900 bits, then 84 bits are padded to make the length of the message 1984 bits. The reason behind adding 84 bits is that when we add 64 to 1984, we get 2048, which is an exact multiple of 512 (512*4 = 2048). Padding bits comprise a single one bit followed by the required number of zero bits. It is mandatory to add padding bits even if the length of the original message plus 64 is already an exact multiple of 512. For example, if the original message is of 448 bits (448 + 64 = 512), even then 512 padding bits need to be added. Thus, the number of padding bits may vary from 1 to 512 bits, and the length of the message after adding padding bits can be 448 bits, 960 bits, 1472 bits and so on.
Step 2: Append Length
The next step is to calculate the length of message excluding the padding bits. For example, if the original message is 1900 bits long, and the length of message after adding the padding bits is 1984 bits, then here the length is considered as 1900 and not 1984. The length (say, L) is expressed as a 64-bit value, and these 64 bits are added at the end of the message plus padding bits. In case the message is too long to be expressed as a 64-bit value, then we need to take the length modulo 264. After appending the length, we get a message whose length is an exact multiple of 512. Now, the digest of this message is to be found.
Step 3: Divide the Input Message into 512-bit Blocks
In this step, the input message is divided into N 512-bit blocks, denoted as M1, M2, …, MN. For example, in our case, the 2048-bit message will be divided into four blocks of 512 bits each.
Step 4: Initialize Hash Buffer
A 160-bit buffer is used to hold the intermediate and final results of the hash function while computing the message digest. This buffer is represented as five 32-bit registers (A, B, C, D, E). Each of these registers is initialized with a 32-bit integer in hexadecimal (initial hash values), as shown here:

The SHA-1 algorithm treats the registers A, B, C, D and E as a single 160-bit register ABCDE.
Step 5: Process Blocks
Each 512-bit block of message is now processed. Initially, the contents of the five registers A, B, C, D and E are copied to five 32-bit variables H0, H1, H2, H3 and H4, respectively. Then, the 512-bit block is divided into 16 sub-blocks of 32 bits each. Now, the compression function, labelled as HSHA-1 in Figure 7.5 , is applied on the 512-bit block. The compression function consists of four rounds, with each round consisting of 20 iterations. That is, a total of 80 iterations are performed to process one 512-block. As shown in Figure 7.6 , each of the four rounds takes three inputs: all the 16 32-bit
sub-blocks of the current 512-bit block, the register ABCDE and an additive constant Ti where 1 ≤ i ≤ 80. Unlike MD5, in SHA-1, we have only four values defined for Ti, one value per round, as shown in Table 7.1.
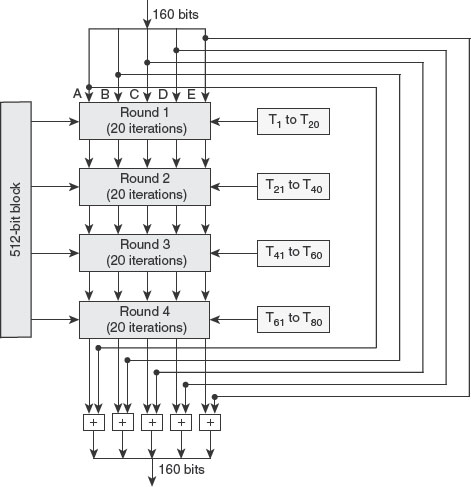
Figure 7.6 SHA-1 Processing of a Single 512-bit Block
| Round | Value of i | Value of Ti (in hexadecimal) |
|---|---|---|
1 |
1 ≤ i ≤ 20 |
5A 92 79 99 |
2 |
21 ≤ i ≤ 40 |
6E D9 EB A1 |
3 |
41 ≤ i ≤ 60 |
F8 1B BC DC |
4 |
61 ≤ i ≤ 80 |
CA 62 C1 D6 |
Each iteration of SHA-1 involves certain operations to update the contents of the register ABCDE. After performing all the 80 iterations for one 512-bit block, each of the five registers (A, B, C, D and E) is incremented by the value it had before the processing of that block, as shown here:
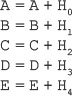
This incremented value of A, B, C, D and E (160 bits together) becomes one of the inputs to the first round of next 512-bit block. Notice that addition is performed using modulo 232.
Single SHA-1 Iteration: Each iteration in SHA-1 goes through the following steps (see Figure 7.7).
i. Apply a function F on registers B, C and D. The function F differs for each round.
ii. Add the contents of register E to the output of the previous step.
iii. Store the contents of register A into a 32-bit temporary variable (say, Temp).
iv. Perform circular left shift operation by five bits on the contents of register A.
v. Add the output of step (ii) and step (iv).
vi. Derive Wi from the current sub-block and add it to the output of the previous step.
vii. Add the constant Ti to the output of the previous step.
viii. Copy the contents of register D to register E.
ix. Copy the contents of register C to register D.
x. Perform circular left shift operation by 30 bits on the contents of register B and store the result in register C.
xi. Copy the value of variable Temp to register B.
xii. Copy the output of step (vii) to register A.

Figure 7.7 Single SHA-1 Iteration
After performing the preceding steps, we get new ABCDE for the next iteration.
Mathematical representation of a single SHA-1 operation can be given as:
![]()
Where,
F = a non-linear function different for each round
Wi = a 32-bit block derived from current 32-bit sub-block Si based on rules (see Table 7.2)
Ti = one of the five 32-bit additive constants
<<<m = circular left shift by m positions
+ = addition modulo 232.
| Value of i | Value of Wi |
|---|---|
1 ≤ i ≤ 16 |
Same as Mi |
17 ≤ i ≤ 80 |
|
Function F: The function F is different in each of the four rounds, while the rest of the steps are the same. The function F involves some Boolean operations on the variables B, C and D in the four rounds, as shown here:
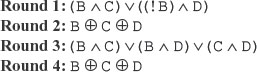
Step 6: Output
After all the 512-bit blocks of the message have been processed, the contents of the register ABCDE form the 160-bit message digest.
11. Differentiate between SHA-1 and MD5.
Ans.: Both SHA-1 and MD5 are message digest algorithms. The design and functionality of SHA-1 and MD5 are almost similar. However, there are certain key differences between them. Some of these differences are listed in the Table 7.3.
| SHA-1 Algorithm | MD5 Algorithm |
|---|---|
| It generates a message digest of 160 bits. | It generates a message digest of 128 bits. |
| It uses little-endian scheme to interpret the message as a sequence of 32-bit words. In this scheme, the most significant byte of a 32-bit word is stored in the low-address byte position. | It uses big-endian scheme, where the least significant byte of a 32-bit word is stored in the low-address byte position. |
| It undergoes four rounds, each having 20 iterations, that is, a total of 80 iterations are used. Moreover, it requires a 160-bit buffer and, thus, is slower in operation than MD5. | It undergoes four rounds, each having 16 iterations, that is, a total of 64 iterations are used. Moreover, it requires a 128-bit buffer and, thus, is faster in operation than SHA-1. |
| It requires 2160 operations for finding the original message from the given message digest and 280 operations to find two messages generating the same message digest. | It requires 2128 operations for finding the original message from the given message digest and 264 operations to find two messages generating the same message digest. |
| It is not vulnerable to cryptanalytic attack. | It is vulnerable to cryptanalytic attack. |
| It is more secure than MD5. | It is less secure as compared to SHA-1. |
12. Explain Whirlpool cryptographic hash function.
Ans.: Whirlpool is a cryptographic hash function designed by Vincent Rijmen and Paulo S.L.M. Barreto. It is one of the hash functions that have been supported by New European Schemes for Signatures, Integrity, and Encryption (NESSIE). It is based on the use of a symmetric-key block cipher instead of a compression function as used in MD5 and SHA. The Whirlpool cipher is a modified version of the Advanced Encryption Standard (AES) cipher.
Whirlpool Hash Function
Figure 7.8 shows the block diagram for generating a message digest using Whirlpool (the triangular hatch in the figure indicates key input). The algorithm takes as input a message with a maximum length of up to 2256 bits, processes the input in 512-bit blocks and returns a 512-bit hash code as output. The steps involved in the working of the Whirlpool hash function are as follows:
1. Append padding bits: In the initial step, the padding bits are added to the end of the original message. This is done so as to make the length of the message an odd multiple of 256. For example, if the original message is of 600 bits, then 168 bits are padded to make the length of the message 768 bits (768 = 256*3). Padding bits comprise a single one bit followed by the required number of zero bits. It is mandatory to add padding bits even if the length of the original message is already of the desired length. For example, if the original message is of 256 bits, even then 512 padding bits need to be added to make the length equal to 768 bits. Thus, the number of padding bits may vary from 1 to 512 bits.

Figure 7.8 Message Digest Generation using Whirlpool
2. Append length: The next step is to calculate the length of the message excluding the padding bits. The length (say, L) is expressed as a 256-bit value, and these 256 bits are added at the end of the message plus padding bits. After appending the length, we get a message whose length is an even multiple of 256 or an integral multiple of 512.
3. Divide the message into 512-bit blocks: The message is divided into N 512-bit blocks, M1, M2, …, MN. Each of these blocks is treated as an array of 8-bit bytes (that is, total 64 bytes). A byte matrix of size 8 × 8 is used to hold the intermediate and final hash values. The matrix is initialized with zero bits.
4. Process message blocks: Each message block of 512 bits is processed through the Whirlpool cipher (W) and, finally, a 512-bit message digest (h) is generated. To process the first message block, the 512-bit message digest (h0) is initialized with all zeros and is used as the cipher key for encrypting the first message block. The ciphertext produced after encrypting each block is XORed with the previous cipher key and previous plaintext block. The result obtained is used as the cipher key for encrypting the next 512-bit block. This process continues, and the final ciphertext block after the last XOR operation becomes the final 512-bit message digest h.
Whirlpool Cipher
The Whirlpool cipher (W) is a non-Feistel cipher that operates on 512-bit blocks (64 bytes). It consists of 10 rounds and uses a key size of 512 bits. The cipher uses a total of 11 round keys (K0, K1, …, K10), with each key of 512 bits. The round keys are generated using the key expansion algorithm. The general design of the Whirlpool cipher is shown in Figure 7.9.
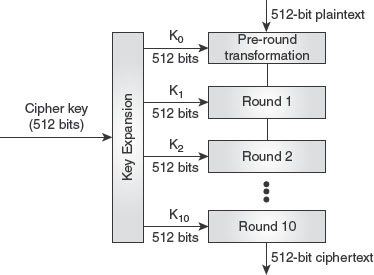
Figure 7.9 General Design of Whirlpool Cipher
State and blocks: Each round in the Whirlpool cipher consists of many stages, where each stage transforms the 512-bit (64-byte) data block. As with AES, the Whirlpool cipher also uses the term ‘block’ at the beginning and end of the cipher and the term ‘state’ before and after each stage. The only difference is that here the size of state and block is 512 bits. Each 512-bit block is treated as a row matrix of 64 bytes, and a state is treated as a square matrix of 8 × 8 bytes. The transformation from block to state and vice versa is performed row wise, unlike in AES cipher.
Structure of each round: Each round involves four transformations; namely, Substitute Bytes, Shift Columns, Mix Rows and Add Round Key (see Figure 7.10). Moreover, one Add Round Key transformation is applied before the first round (mentioned as pre-round transformation in Figure 7.9). Each transformation accepts a state, changes it and creates a new state, which is given as input to the next transformation or the next round.
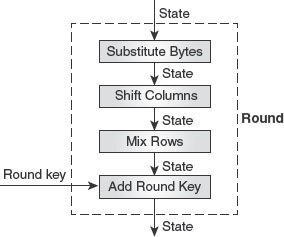
Figure 7.10 Structure of each Round in Whirlpool Cipher
The transformations involved in each round are described as follows:
![]() Substitute Bytes: This is the first transformation of a round that performs substitution of bytes. The input to this transformation is an 8 × 8 byte state matrix. The bytes in the matrix are substituted one at a time; thus, there are 64 distinct byte-to-byte transformations. The bytes are substituted either with the help of a substitution table or by performing the mathematical calculations in
Substitute Bytes: This is the first transformation of a round that performs substitution of bytes. The input to this transformation is an 8 × 8 byte state matrix. The bytes in the matrix are substituted one at a time; thus, there are 64 distinct byte-to-byte transformations. The bytes are substituted either with the help of a substitution table or by performing the mathematical calculations in GF(24) field. To substitute the bytes using a substitution table, each byte is treated as two hexadecimal digits, where the first digit (left one) specifies the row and the second digit (right one) specifies the column of the substitution table. The value (two hexadecimal digits) at the intersection of the row and the column in the substitution table is the new byte with which the given byte is to be replaced. Notice that, in this transformation, the contents of each byte is changed; however, the order of bytes in the matrix does not change.
![]() Shift Columns: This transformation performs the byte-level permutation. It is similar to Shift Rows transformation of AES with the only difference that, here, the columns of the matrix are shifted, and not the rows. The bytes in the columns of the input state matrix are shifted to the left and the number of the bytes to be shifted depends on the column number. For example, the column 0 is not shifted at all, the column 1 is shifted one byte, column 2 is shifted two bytes, and so on.
Shift Columns: This transformation performs the byte-level permutation. It is similar to Shift Rows transformation of AES with the only difference that, here, the columns of the matrix are shifted, and not the rows. The bytes in the columns of the input state matrix are shifted to the left and the number of the bytes to be shifted depends on the column number. For example, the column 0 is not shifted at all, the column 1 is shifted one byte, column 2 is shifted two bytes, and so on.
![]() Mix Rows: This is a matrix transformation that diffuses the bits inside the bytes of the state matrix. It takes one row of input state matrix at a time and transforms it to a new row. For transforming the rows, a constant square matrix is used whose each row is the circular right shift of its previous row. The square matrix is multiplied by each row of the state matrix, resulting in another row. Notice that the bytes multiplication operation is performed in the
Mix Rows: This is a matrix transformation that diffuses the bits inside the bytes of the state matrix. It takes one row of input state matrix at a time and transforms it to a new row. For transforming the rows, a constant square matrix is used whose each row is the circular right shift of its previous row. The square matrix is multiplied by each row of the state matrix, resulting in another row. Notice that the bytes multiplication operation is performed in the GF(28) field, and the bytes addition operation is performed by simply XORing the bits within bytes.
![]() Add Round Key: This is the only transformation that makes use of the round key. To perform this transformation, the 512-bit round key is considered as an 8 × 8 state matrix. Each byte of the input state matrix is added with the corresponding byte of round key state matrix in the GF(28 ) field, resulting in a new byte.
Add Round Key: This is the only transformation that makes use of the round key. To perform this transformation, the 512-bit round key is considered as an 8 × 8 state matrix. Each byte of the input state matrix is added with the corresponding byte of round key state matrix in the GF(28 ) field, resulting in a new byte.
13. What is HMAC? What are its design objectives? Explain its working.
Ans.: Hash-based MAC (HMAC) is a message authentication code derived from a cryptographic hash function such as MD5 and SHA-1. The basic idea behind HMAC is to use a secret key in the existing message digest algorithms (hash functions). It has been issued as a standard (FIPS 198) by NIST. As algorithms such as MD5 and SHA-1 do not rely on the secret key, HMAC has been selected as mandatory-to-implement MAC for IP security. It is also used in other Internet protocols, such as Secure Socket Layer (SSL).
HMAC can work with any existing message digest algorithms (hash functions). It considers the message digest produced by the embedded hash function as a black box. It then uses the shared symmetric key to encrypt the message digest, thus, producing the final output, that is, MAC.
Design Objectives of HMAC
HMAC was issued as RFC 2104, which defines the following objectives for HMAC.
![]() To use the existing hash functions such as MD5 and SHA-1 without modification.
To use the existing hash functions such as MD5 and SHA-1 without modification.
![]() To be able to easily replace an existing hash function in case a fast hash function is available or needed.
To be able to easily replace an existing hash function in case a fast hash function is available or needed.
![]() To maintain the original performance of the function till the time it is possible.
To maintain the original performance of the function till the time it is possible.
![]() To use the keys and to handle them in a simple and efficient manner.
To use the keys and to handle them in a simple and efficient manner.
![]() To better understand the cryptographic analysis of the strength of the authentication mechanism used in embedded hash function.
To better understand the cryptographic analysis of the strength of the authentication mechanism used in embedded hash function.
HMAC Implementation
The implementation of HMAC is very complex. Before discussing the algorithm, let us define the variables used in the algorithm.
H = embedded cryptographic hash function such as MD5 or SHA
IV = initial value to the hash function
M = input message
q = number of input blocks in M
n = length of the message digest (or hash value)
b = number of bits in a block
Mi = ith block of input message with 1 ≤ i ≤ q
K = shared symmetric key (secret key)
Kpad = secret key K padded with 0s on the left to make the length b bits
Ipad = input pad, a constant having value 00110110 (36 in hex) repeated b/8 times
Opad = output pad, a constant having value 01011100 (5C in hex) repeated b/8 times
Mathematically, the HMAC operation can be expressed as:
![]()
Figure 7.11 depicts the HMAC operation. Initially, the given input message M is divided into q blocks, M1, M2, …, Mq, with each block having b bits. Then, the following steps are performed to produce the n-bit message digest.
1. Add padding bits to secret key K: Add the required number of zeros to the left of secret key K to make it a b-bit string, Kpad. It is recommended that the original size of secret key K should not be greater than n, the length of the message digest.
2. XOR Kpad with Ipad : Apply XOR operation on b-bit Kpad obtained from the previous step and the constant Ipad to create a b-bit block, say S1.
3. Append M to S1 : Append the input message M (equivalent to q b-bit blocks) to the output of the previous step, that is, S1. The result is q+1 blocks of b bits each.
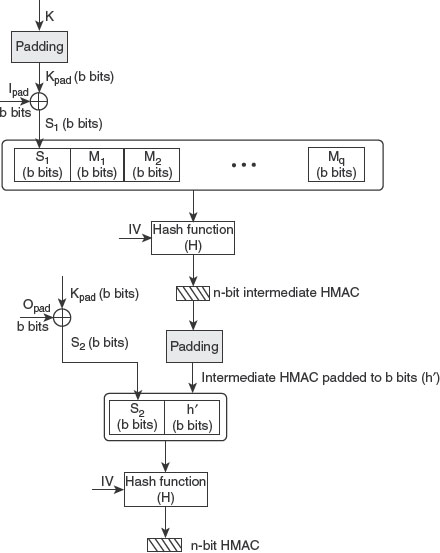
Figure 7.11 HMAC Structure
4. Apply hash function: Apply the selected hash function H on the stream containing q+1 blocks, generated in the previous step, to produce n-bit digest, referred to as the intermediate HMAC. The n-bit IV is also given as input to the hash function.
5. Add padding bits to intermediate HMAC: Add the required number of zeros to the left of n-bit intermediate HMAC to produce h′ with length equal to b bits.
6. XOR Kpad with Opad: Apply XOR operation on b-bit Kpad and the constant Opad to create a b-bit block, say S2.
7. Append h′ to S2: Append the b-bit intermediate HMAC (h′) obtained from step 5 to the output of the previous step, that is, S2.
8. Apply hash function: Apply the same hash function H with an n-bit IV as input on the output of the previous step to produce a final n-bit message digest.
14. Discuss the security of HMAC.
Ans.: The security of HMAC depends on the cryptographic strength of the embedded hash function, the size of secret key used and the length of the message digest produced. In essence, the probability of attacking HMAC successfully is equal to either of the following attacks on the embedded hash function.
![]() The intruder can calculate the output of compression function without having the knowledge of
The intruder can calculate the output of compression function without having the knowledge of IV, which is selected at random and kept secret.
![]() The intruder determines the collisions in the hash function even if the I V is secret and random.
The intruder determines the collisions in the hash function even if the I V is secret and random.
To attempt the first attack, the compression function can be viewed as a hash function that is applied on a message containing only one b-bit block. The intruder selects a random value of n bits (i.e. the length of the message digest produced) and uses it in place of IV. However, to perform this attack on the hash function, either a brute-force attack on the secret key or a birthday attack is to be attempted, because HMAC involves the secret key also while computing the hash value. Attempting a brute-force attack on the secret key requires the intruder to perform 2n operations.
On the other hand, to attempt the second attack, the intruder needs to determine two messages, M1 and M2, such that when the hash function H is applied on them, they yield the same output, that is, H(M1)=H(M2). This is the birthday attack, and it requires the intruder to perform 2n/2 operations in case the hash code is of n bits. For example, if the MD5 algorithm, which produces 128-bit hash code, is used as the embedded hash function, the intruder has to perform 264 operations in order to attempt birthday attack on the hash function. Performing so many operations does not seem infeasible with today's technology. However, it does not necessarily mean that MD5 is unsuitable to HMAC. The reason behind this is explained in the following text.
The intruder can attack MD5 by selecting some set of messages and generating the corresponding hash codes to determine the collisions. As the intruder knows the hash function as well as the default IV to MD5, he or she is able to work offline on some dedicated computing facility. However, when MD5 is used in HMAC, the intruder cannot determine the messages and their corresponding hash codes offline. This is because HMAC also involves the use of a secret key that is not known to the intruder. Therefore, the intruder needs to observe a series of messages being generated by HMAC using the same key and then attempt to attack these known messages. For a 128-bit hash code in MD5, this requires observing 264 blocks generated using the same key. To observe so many blocks on a 1-Gbps link, one would need approx 1,50,000 years to succeed. Thus, the use of MD5 is acceptable to HMAC as far as speed is concerned.
Multiple-choice Questions
1. A _________ is used to verify the integrity and authenticity of a message.
(a) Decryption algorithm
(b) Message digest
(c) MAC
(d) Both (b) and (c)
2. Which of the following is the latest version of the SHA algorithm?
(a) SHA-512
(b) SHA-256
(c) SHA-128
(d) SHA-1
3. The purpose of hash function is to ensure _________.
(a) Message integrity
(b) Message authentication
(c) Both (a) and (b)
(d) None of these
4. Choose the odd one out.
(a) RC5
(b) Blowfish
(c) ECC
(d) MAC
5. When two different messages yield the same message digest, it is called _________.
(a) Attack
(b) Collision
(c) Hash
(d) None of these
6. Which of the following is based on the use of asymmetric-key block cipher?
(a) SHA-1
(b) MD5
(c) RIPEMD
(d) Whirlpool
7. An attacker needs to perform _________ operations in order to determine collision in SHA-1.
(a) 264
(b) 280
(c) 2256
(d) 272
Answers
1. (c)
2. (a)
3. (a)
4. (d)
5. (b)
6. (d)
7. (b)