
When starting to write Apex, it is tempting to start with an Apex Trigger or Apex Controller class and start placing the required logic in these classes to implement the desired functionality. This chapter will explore a different starting point, one that gives the developer focus on writing application business logic (the core logic of your application) in a way that is independent of the calling context. It will also explain the benefits that it brings in terms of reuse, code maintainability, and flexibility, especially when applying code to different areas of the platform.
We will explore the ways in which Apex code can be invoked, the requirements and benefits of these contexts, their commonalities, their differences, and the best practices that are shared. We will distill these into a layered way of writing code that teaches and embeds Separation of Concerns (SOC) in the code base from the very beginning. We will also introduce a naming convention to help with code navigation and enforce SOC further.
At the end of the chapter, we will have written some initial code, setting out the framework to support SOC and the foundation for the next three chapters to explore some well-known Enterprise Application Architecture patterns in more detail. Finally, we will package this code and install it in the test org.
This chapter will cover the following topics:
- Apex execution contexts
- Apex governors and namespaces
- Where is Apex used?
- Separation of Concerns
- Patterns of Enterprise Application Architecture
- Unit testing versus system testing
- Packaging the code
An execution context on the platform has a beginning and an end; it starts with a user or system action or event, such as a button click or part of a scheduled background job, and is typically short lived; with seconds or minutes instead of hours before it ends. It is especially important in multitenant architecture because each context receives its own set of limits around queries, database operations, logs, and duration of the execution.
In the case of background jobs (Batch Apex), instead of having one execution context for the whole job, the platform splits the information being processed and hands it back through several execution contexts in a serial fashion. For example, if a job was asked by the user to process 1000 records and the batch size (or scope size in Batch Apex terms) was 200 (which is the default), this would result in five distinct execution contexts, one after another. This is done so that the platform can throttle the execution of jobs up or down or if needed pause them between scopes based on the load on the service at the time.
You might think that an execution context starts and ends with your Apex code, but you would be wrong. Using some Apex code is introduced later in this chapter; we will use the debug logs to learn how the platform invokes the Apex code.
For the next two examples, imagine that an Apex Trigger has been created for the Contestant object and an Apex class has been written to implement some logic to update the contestants' championship points dependent on their position when the race ends.
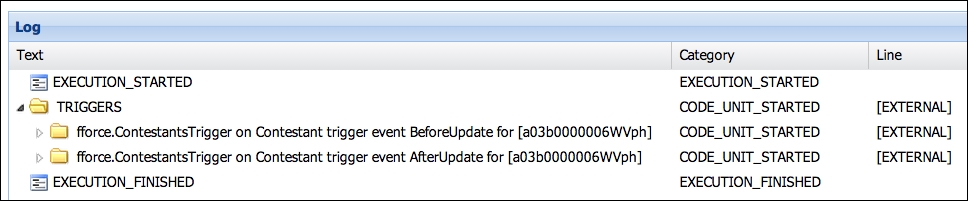
In the first example, the Contestant record is updated directly from the UI and the Apex Debug log shown in the next screenshot is captured.
Notice the EXECUTION_STARTED and EXECUTION_FINISHED lines; these show the actual start and end of the request on the Salesforce server. The CODE_UNIT_STARTED lines show where the platform invokes Apex code. Also, note that the line number shows EXTERNAL, indicating the platform's internal code called the Apex code. For the sake of brevity, the rest of the execution of the code is collapsed in the screenshot.
In this second example, imagine that some Apex code was executed to calculate the contestants' championship points once the race ends. In this case, the code was executed from an Execute Anonymous prompt (though in the application, this would be a button); again, the Apex Debug log was captured and is shown in the next screenshot.
Again, you can see the EXECUTION_STARTED and EXECUTION_FINISHED entries, along with the three CODE_UNIT_STARTED entries: one for the RaceService.awardChampionshipPoints Apex method called from the Execute Anonymous prompt and two others for the Apex Trigger code.
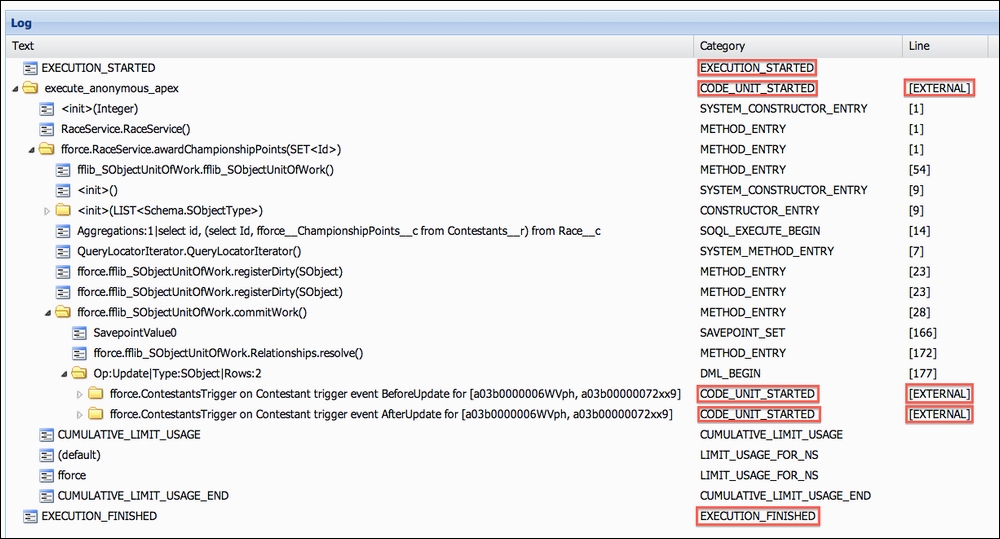
What is different from the first example is, as you can see by looking at the Line column, that the execution transitions show lines of the Apex code being executed and EXTERNAL. When DML statements are executed in Apex to update the Contestants records, the Apex code execution pauses while the platform code takes over to update the records. During this process, the platform eventually then invokes Apex Triggers and once again, the execution flows back into Apex code.
Essentially, the execution context is used to wrap a request to the Salesforce server; it can be a mix of execution of the Apex code, Validation Rules, workflow rules, trigger code, and other logic executions. The platform handles the overall orchestration of this for you. The Salesforce Developer Console tool offers some excellent additional insight into the time spent in each of these areas.
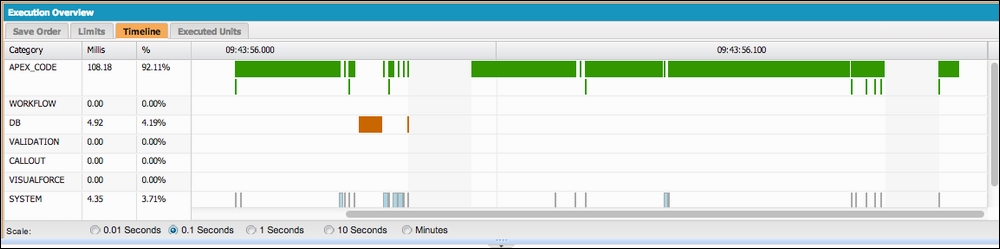
If the subscriber org has added Apex Triggers to your objects, these are executed in the same execution context. If any of these Apex code units throw unhandled exceptions, the entire execution context is stopped and all database updates performed are rolled back, which is discussed in more detail later in this chapter.
The server memory storage used by the Apex variables created in an execution context can be considered the state of the execution context; in Apex, this is known as the heap. On the whole, the server memory resources used to maintain an execution context's state are returned at the end; thus, in a system with short lived execution contexts, resources can be better managed. By using the CPU and heap governors, the platform enforces the maximum duration of an execution context and Apex heap size to ensure the smooth running of the service; these are described in more detail later in this chapter.
State management is the programming practice of managing the information that the user or job needs between separate execution contexts (requests to the server) invoked as the user or job goes about performing the work, such as a wizard-based UI or job aggregating information. Users, of course, do not really understand execution contexts and state; they see tasks via the user interface or jobs they start based on field inputs and criteria they provide. It is not always necessary to consider state management, as some user tasks can be completed in one execution context; this is often preferable from an architecture perspective as there are overheads in the managing state. Although the platform provides some features to help with state management, using them requires careful consideration and planning, especially from a data volumes perspective.
In other programming platforms such as Java or Microsoft .NET, static variables are used to maintain the state across execution contexts, often caching information to reduce the processing of subsequent execution contexts or to store common application configurations. The implementation of the static keyword in Apex is different; its scope applies only to the current execution context and no further. Thus, an Apex static variable value will not be retained between execution contexts, though they are preserved between multiple Apex code units (as illustrated in the previous section). Thus, in recursive Apex Trigger scenarios, allow the sharing of the static variable to control recursion.
Tip
Custom Settings may offer a potential parallel in Apex where other programming languages use static variables to store or cache certain application information. Such information can be configured to be org, user, or profile scope and are low cost to read from Apex. However, if you need to cache information that may have a certain life span or expiry, such as the user session or across a number of users, you might want to consider Platform Cache. Platform Cache also provides greater flexibility for your customers in terms of purchasing additional storage (Custom Settings are limited to 10 MB per package).
Caching information is not a new concept and is available on many other platforms, for example MemCache is a popular open source framework for providing a cache facility. The main motivation for considering caching is performance.
As stated earlier, state is not retained between requests. You may find that common information needs to be constantly queried or calculated. If the chances of such information changing is low, caches can be considered to gain a performance benefit. The cost, in terms of Apex execution (CPU Governor) and/or database queries (SOQL and Row Governors) has to be less than retrieving it from the cache.
Platform Cache allows you to retain state beyond the scope of the request, up to 48 hours for the org level cache and 8 hours for the session level cache. Session level cache only applies to the interactive context, it is not available in async Apex. Your code can clear cached information ahead of these expiry times if users change information that the cached information is dependent on. Apex provides APIs under the Cache namespace for storing (putting), retrieving (getting), and clearing information from either of these caches. There is also a $Cache variable to retrieve information from the Session cache within a Visualforce page. Unfortunately, there is currently no $Cache access for Lightning Component markup at time of writing, as such Apex Controllers must be used.
Tip
You can enable Cache Diagnostics on the User Detail page. Once enabled you can click the Diagnostics link next to a cache partition (more on this later in this section). This provides useful information on the size of entries in the cache and how often they are being used. This can be useful during testing. Salesforce advises to use this page sparingly, as generating the information is expensive.
Think carefully about the lifespan of what you put in the cache, once it goes in, the whole point is that it stays in the cache as long as possible and thus the performance benefit is obtained more often than not. If you are constantly changing it or clearing the cache out, the benefit will be reduced. Equally information can become stale and out of date if you do not correctly consider places in your application where you need to invalidate (clear) the cache. This consideration can become quite complex depending on what you are storing in the cache, for example if the information is a result of a calculation involving a number of records and objects.
Note
Stale cached information can impact on your validations and user experience and thus potentially cause data integrity issues if not considered carefully. If you are storing information in the org level cache for multiple users, ensure that you are not indirectly exposing information other users would not have access to via their Sharing Rules, Object, or Field Level security.
The amount of cache available depends on the customer's org type, Enterprise Edition orgs currently get 10 MB by default, whereas Unlimited and Performance Edition orgs get 30 MB. You cannot package storage, though more can be purchased by customers. To test the benefits of Platform Cache in a Developer Edition org, you can request a trail allocation from Salesforce from the Platform Cache page under Setup. Salesforce uses a Least Recently Used (LRU) algorithm to manage cache items.
The amount of cache available can be partitioned (split), much like storage partitions on a hard disk. This allows the administrator to guarantee a portion of the allocation is used for a specific application only, and if needed, adjust it depending on performance needs. As the package developer, you can reference local partitions (created by the administrator) by name dynamically. You can also package a partition name for use exclusively by your application and reference it in your code. This ensures any allocation assigned after the installation of your package by the administrator to your partition is guaranteed to be used by our application. If your code was to share a partition you may not want other applications constantly pushing out your cached entries for example.
Tip
Packaged partitions cannot be accessed by other code in the customer's org or other packages, only by code in that corresponding package namespace. You may want to provide the option (via Custom Settings) for administrators to configure your application to reference local partitions, perhaps allowing administrators to pool usage between applications. Consider using the Cache.Visibility.NAMESPACE enumeration when adding entries to the cache to avoid code outside your package accessing entries. This could be an important security consideration depending on what your caching.
Note
Salesforce themselves use MemCache internally to manage the platform. Platform Cache is likely a wrapper exposing part of these internals to Apex Developers. Refer to the blogpost "Salesforce Architecture - How They Handle 1.3 Billion Transactions A Day" at http://highscalability.com/blog/2013/9/23/salesforce-architecture-how-they-handle-13-billion-transacti.html
The Salesforce Apex Developers Guide contains a Platform Cache sub-section which goes in to further detail on the topics I have covered in this section, including further best practices and usage guidelines. You can refer to this guide at https://developer.salesforce.com/docs/atlas.en-us.apexcode.meta/apexcode/apex_cache_namespace_overview.htm.
As discussed in the last chapter, the platform provides security features to allow subscribers or administrators to manage CRUD operations on your objects as well as individual Field-Level security (FLS) ideally through the assignment of some carefully considered permission sets that you have included in your package, in addition to providing the ability to define sharing rules to control record visibility and editing.
Within an Apex execution context, it is important to understand whose responsibility it is (the platform's or developer's) to provide enforcement of these security features. With respect to sharing rules, there is a default security context, which is either set by the platform or can be specified using specific keywords used within Apex code. These two types of security are described in further detail in the following bullets:
- Sharing security: Through the use of the
with sharingkeyword when applied to an Apex class declaration, the Apex runtime provides support to filter out records returned by SOQL queries automatically that do not meet the sharing rules for the current user context. If it is not specified, then this is inherited from the outermost Apex class that controls the execution. Conversely, thewithout sharingkeyword can be used to explicitly enable the return of all records meeting the query regardless of sharing rules. This is useful when implementing referential integrity, for example, where the code needs to see all the available records regardless of the current users sharing rules. - CRUD and FLS security: As discussed in the previous chapter, it is the Apex developers' responsibility to use appropriate programming approaches to enforce this type of security. On a Visualforce page, CRUD and FLS are only enforced through the use of the appropriate Visualforce components such as
apex:inputFieldandapex:outputField. The Apex code within an execution context runs within the system mode with respect to CRUD and FLS accessibility, which means that, unless your code checks for permitted access, the platform will always permit access. Note that this is regardless of the use of thewith sharingkeyword, which only affects the records that are visible to your code.
In summary, both are controlled and implemented separately as follows:
- Row-level security applies only to the
with sharingusage - CRUD security and FLS needs separate coding considerations
In the later chapters of this book, we will see some places to position this logic to make it easier to manage and less intrusive for the rest of the code.
Handling database transactions in Apex is simpler than other platforms. By default, the scope of the transaction wraps the entire execution context. This means that if the execution context completes successfully, any record data is committed. If an unhandled exception or error occurs, the execution context is aborted and all record data is rolled back.
Unhandled Apex exceptions, governor exceptions, or Validation Rules can cause an execution context to abort. In some cases, however, it can be desirable to perform only a partial rollback. For these cases, the platform provides Savepoints that can be used to place markers in the execution context to record what data is written at the point the Savepoint was created. Later, a Savepoint can be used in the execution as the rollback position to resume further processing in response to error handling or a condition that causes the alternative code path resulting in different updates to the database.
Note
It is important to realize that catching exceptions using the Apex try and catch keywords, for example, in Visualforce controller methods, results in the platform committing any data written up until the exception occurs. This can lead to partially updated data across the objects being updated in the execution context giving rise to data integrity issues in your application. Savepoints can be used to avoid this by using a rollback in the catch code block. This does, however, present quite a boilerplate overhead for the developer each time. Later in this book, we will review this practice in more detail and introduce a pattern known as Unit Of Work to help automate this.