
In this section, we will review when system and custom indexes maintained by the Force.com platform are used to make queries more performant and, once larger query results are returned, the ways in which they can be most effectively consumed by your Apex logic.
As with other databases, Force.com maintains database indexes as record data is manipulated to ensure that, when data is queried, such indexes can be used to improve query performance. Due to the design of the Force.com multitenant platform, it has its own database index implementation (instead of using the underlying Oracle database indexes) that considers the needs of each tenant. By default, it maintains standard indexes for the following fields:
- ID
- Name
- OwnerId
- CreateDate
- CreatedById
- LastModifiedDate
- LastModifiedById
- SystemModStamp
- RecordType
- Any Master Detail fields
- Any Lookup fields
- Any fields marked as Unique
- Any fields marked as External Id
Once your application is deployed into a subscriber org, you can also request that Salesforce to consider creating additional custom indexes on fields not covered by the preceding list, such as fields used by your application logic to filter records, including custom formula fields and custom fields added to your objects by the subscriber as well.
As creating indexes and maintaining them consumes platform resources, custom indexes cannot be packaged, as the decision to enable them is determined by conditions only found in the subscriber org.
Note
Though objects can contain millions of records, standard indexes will only index up to 1 million records and custom indexes up to 333,333 records. These limits have a bearing on whether an index is used or not, depending on the query and filter criteria being used. This is discussed in more detail further in this chapter.
With respect to the Race Data object, the following fields will be indexed by default by the platform. Only through contacting Salesforce support and enabling in the subscriber org can additional custom indexes be created, for example, on the Type__c field.
|
Field |
Standard Index |
|---|---|
|
|
Yes (Lookup Field) |
|
|
Yes (Lookup Field) |
|
|
Yes |
|
|
Yes |
|
|
Yes (Lookup Field) |
|
|
Yes (Lookup Field) |
|
|
No |
|
|
No |
|
|
No |
|
|
No |
|
|
No |
|
|
No |
|
|
No |
Under Setup, navigate to Objects and locate the Race Data object. When viewing fields listed in the Standard Fields or Custom Fields & Relationships related lists, observe the Index column. This is the easiest way to determine whether a field has a standard or custom index applied to it.
Thus, if a query filters by fields covered by a system or custom index, the index will be considered by the Force.com query optimizer. This means that just because an index exists does not mean it will be used. The final decision is determined by how selective the query is.
Note
By default, Salesforce does not include rows (that contain null values) within its indexes for the respective field. In this case, although the Contestant field is indexed by default, it initially contains a null value and thus initially the index will be ineffective (this fact relates to why the use of nulls in filter criteria will deter the Force.com query optimizer from using an index, as discussed in the next section). You can, however, get Salesforce Support to discuss enablement of the inclusion of nulls in indexes.
The process of selecting an appropriate index applies to queries made via SOQL through APIs and Apex, but also via Reporting and List Views. The use of an index is determined by the SOQL statement being selective or not. The following provides definitions of being selective and being non selective:
- Salesforce uses the term selective to describe queries filtering record data that are able to leverage indexes maintained behind the scenes by Salesforce, making such queries more efficient and thus returning results more quickly.
- Conversely, the term non selective implies a given query is not leveraging an index; thus, it will, in most cases, not perform as well. It will either time-out or, for objects with records greater than 100,000, result in a runtime exception.
In a nonselective query situation, the platform will scan all the records in the object, applying the filtering to each; this is known as a full table scan. However, this is not necessarily the slowest option, depending on the number of records and the filter criteria.
The main goal of this part of the chapter is to explain what it takes for Salesforce to select an index for a given query. This depends on a number of factors, both when you build your application queries and the number of records in your objects within the subscriber org.
There are two things that determine whether an index is used. Firstly, the filter criteria (or the WHERE clause in SOQL terms) of the query must comply with certain rules in terms of operators and conditions used. Secondly, the total number of records in the object versus the estimated number of records that will be returned by applying the filter criteria.
The filter criteria must, of course, reference a field that has either a standard or custom index defined for it. After this, unary, AND, OR, and LIKE operators can be used to filter records. However, other operators, such as negative operators, wild cards, and text comparison operators, as well as the use of null in the filter criteria, can easily disqualify the query from using an index. For example, a filter criteria that is more explicit in the rows it wants, Type__c = 'Sector Time', is more likely to leverage an index (assuming that this field has a custom index enabled), than say, for example, Type__c != 'Pit Stop Time', which will cause the platform to perform a full table scan, as the platform cannot leverage the internal statistics it maintains on the spread of data throughout the rows across this column.
The filtered record count must be below a certain percentage of the overall records in the object for an index to be used. You might well ask how Salesforce knows this information without actually performing the query in the first place? Though they do not give full details, they do describe what is known as a pre-query, using statistical data that the platform captures as the standard or custom indexes are maintained. This statistical data helps to understand the spread of data based on the field values. For example, the percentage of rows loaded by the execution of the scripts to load sample data where the Type__c field contains the PitStop Time value is 0.16 percent, and thus, if a custom index was in place and the queries filter criteria was selective enough (for example, Type__c = 'PitStop Time'), an index would be used.
A query for Sector Time, such as Type__c = 'Sector Time', will result in 1664 records, which is 16.64 percent of the total rows being selected. So, while the filter criteria are selective, the filtered record count is above the threshold for custom index: 10 percent or 333,333 records max. Thus, in this case, an index is not used. This might result in a timeout or runtime exception. So, in order to avoid this, the query must be made more selective, for example, by enabling a custom index and adding either Lap__c or Sector__c into the filter criteria.
Salesforce provides more detailed information on how to handle large data volumes, such as fully documenting the filter record count tolerances used to select indexes (note that they differ based on standard or custom indexes) and some insights as to how they store data within the Oracle database that help make more sense of things. These are a must-read in my view and can be found in various white papers and Wiki pages. Some of them are as follows:
- Query & Search Optimization Cheat Sheet: http://resources.docs.salesforce.com/rel1/doc/en-us/static/pdf/salesforce_query_search_optimization_developer_cheatsheet.pdf
- Best Practices for Deployments with Large Data Volumes: http://www.salesforce.com/docs/en/cce/ldv_deployments/salesforce_large_data_volumes_bp.pdf
- Force.com SOQL Best Practices: Nulls and Formula Fields: https://developer.salesforce.com/blogs/engineering/2013/02/force-com-soql-best-practices-nulls-and-formula-fields.html
- Developing Selective Force.com Queries through the Query Resource Feedback Parameter Pilot: https://developer.salesforce.com/blogs/engineering/2014/04/developing-selective-force-com-queries-query-resource-feedback-parameter-pilot.html
As you can see, consideration for which indexes are needed and when they are used are very much determined by the rate of data growth in the subscriber org and also the spread of distinct groups of data values in that data. So, profiling is typically something that is only done in conjunction with your customers and Salesforce, within the subscriber org.
In some cases, disclosing the queries your application makes from Apex and Visualforce pages might help you and your subscribers plan ahead as to which indexes are going to be needed. You can also capture the SOQL queries made from your code through the debug logs, once you're logged in through the Subscriber Support feature.
Once you have a SOQL query you suspect is causing problems, you will profile it to determine which indexes are being used in order to determine what to do to resolve the issue, create a new index, and/or make the filter criteria select less records by adding more constraints. To do this, you can use a feature of the platform to ask it to explain its choices when considering which index (if any) to use for a given query. Again, it is important to use this in the subscriber org or sandbox itself.
For the purposes of this chapter, the following example utilizes the explain parameter on the Salesforce REST API to execute a query within the packaging org we ran the preceding script in, to populate the Race Data object with 10,000 records.
Note
Developer Console includes Query Planner Tool, which can be enabled under the Preferences tab. When you run queries via Query Editor, a popup will appear with an explanation of the indexes considered. The information shown is basically the same as that described in this chapter via the explain parameter.
This section utilizes the explain parameter when running SOQL via the Developer Workbench tool. Here, you can run the various queries in the explain mode and review the results. The results show a list of query plans that would have been used, had the query been actually executed. They are shown in order of preference by the platform. The following steps show how to login to the Developer Workbench to obtain a query plan for a given query:
- Log in to Developer Workbench.
- From the Utilities menu, select REST Explorer.
- Enter
/services/data/v30.0/query?explain=and then paste your SOQL. You may also use the latest Salesforce API version in the URL. - Click on Execute.
First, let's try the following example without a custom index on the Type__c field. Note that the fforce prefix is used; as the SOQL query is being executed in the namespace-enabled packaging org, you should replace this with your own chosen namespace.
select id from fforce__RaceData__c where fforce__Type__c = 'PitStop Time'
The following screenshot shows the Developer Workbench showing the query plan result for this query:
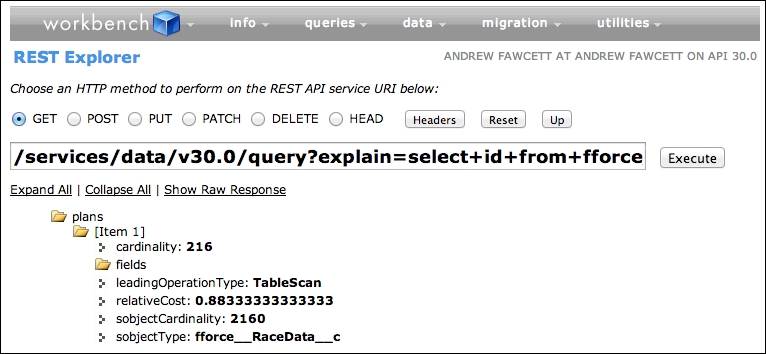
You can see, as expected, the result is TableScan, compared to the following query:
select id from fforce__RaceData__c where CreatedDate = TODAY
The following screenshot shows the query plan for this query:
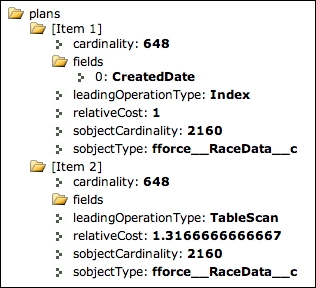
This results in two plans; however, the standard Index was selected over TableScan.
Note
The cardinality and sobjectCardinality fields are both estimates based on the aforementioned statistical information that Salesforce maintains internally relating to the spread of records (in this case, distinct records by Type__c). Thus, it gives the rows it thinks will be selected by the filter versus the total number of also estimated rows in the SObject.
In this case, we can see that these are just estimates, as we know we have 10,000 records in the RaceData__c object; actually, 1,664 of those are Sector Time records. In general though, as long as these are broadly relative to the actual physical records, what the platform is doing is looking for the percentage of one from the other in order to decide whether an index will be worth using. It is actually the relativeCost field that is most important; basically a value greater than 1 means that the query will not be executed using the associated plan.
Now that you have a general idea of how to obtain this information, let's review a few more samples, but this time with 100,000 RaceData__c records (10 races worth of data using the same distribution of records). In my org, I have also asked Salesforce Support to enable a custom index over the Type__c, Lap__c and Sector__c custom fields. The namespace fforce prefix has been removed for clarity.