
As you can see there are a number of places Apex code is invoked by various platform features. Such places represent areas for valuable code to potentially hide. It is hidden because it is typically not easy or appropriate to reuse such logic as each of the areas mentioned in the previous table has its own subtle concerns with respect to security, state management, transactions, and other aspects such as error handling (for example, catching and communicating errors) as well as varying needs for bulkification.
Throughout the rest of this chapter, we will review these requirements and distill them into a Separation of Concerns that allows a demarcation of responsibilities between the Apex code used to integrate with these platform features versus the code implementing your application business logic, such that the code can be shared between platform features today and in the future more readily. Wikipedia describes the benefits of Separation of Concerns as the following:
"The value of Separation of Concerns is simplifying development and maintenance of computer programs. When concerns are well separated, individual sections can be developed and updated independently. Of especial value is the ability to later improve or modify one section of code without having to know the details of other sections, and without having to make corresponding changes to those sections."
Apex Triggers can lead to a more traditional pattern of if/then/else style coding resulting in a very procedural logic that is hard to maintain and follow. This is partly due to them not being classes and as such they don't naturally encourage breaking up the code into methods and separate classes. As we saw in the previous table, Apex Triggers are now not the only execution context for Apex; others do support Apex classes and the object-orientated programming (OOP) style, often leveraging system-defined Apex interfaces to allow the developer to integrate with the platform such as Batch Apex.
Apex has come a long way since its early introduction as a means of writing more complex Validation Rules in Apex Triggers. These days, the general consensus in the community is to write as little code as possible directly in Apex Trigger, instead of delegating the logic to separate Apex classes. For a packaged application, there is no real compelling reason to have more than one Apex Trigger per object. Indeed, the Salesforce security review has been known to flag this even if the code is conditioned to run independently.
A key motivation to move the Apex Trigger code into an Apex class is to gain access to the more powerful language semantics of the Apex language, such as OOP, allowing the developer to structure the code more closely to the functions of the application and gain better code reuse and visibility.
Each execution context has its own requirements for your code, such as implementing system interfaces, annotations, or controller bindings. Within this code are further coding requirements relating to how you engineer your application code, which lead to a set of common architecture layers of concern, such as loading records, applying validations, and executing business logic.
Understanding these layers allows us to discover a different way to write the application code than simply writing all our code in a single Apex class, which becomes tightly coupled to the execution context and thus less flexible in the future.
To manage these layers of concern in the code, create separate classes—those that are bound to the specific execution context (such as Batch Apex, Scheduler, Apex REST, and Inbound Messaging) and those that contain the application business logic that implements the actual task for the user.
The following UML diagram shows the Apex classes that implement the requirements (or concerns) of the execution context and Apex classes to execute the application business logic. The dotted line indicates a Separation of Concerns between UI controller (these could be Visualforce or Lightning Component Controllers) classes and classes implementing the application business logic.
Like Visualforce's use of the Model View Controller (MVC), Lightning Components also think in terms of SOC by splitting up the implementation of the component into several distinct files that each have their own concerns. As Lightning Components are mostly implemented on the client side these files represent a way to implement separation of concerns within the JavaScript code you write.
When creating a Lightning Component in the Salesforce Developer Console, you are presented with the following side panel which outlines the different files that make up your component:
We will go into more detail on these in Chapter 9, Lightning, for now let's consider the CONTROLLER, HELPER and RENDER files.
CONTROLLER: Code in this file is responsible for implementing bindings to the visual aspects of the component. Defined via the markup defined in theCOMPONENTfile. Unlike a Visualforce controller, it only contains logic providing bindings to the UI. The client side state of your component is accessed via the controller.HELPER: Code in this file is responsible for the logic behind your components behavior, button presses and other interactions, which lead to accessing the backend Apex controller, combining inputs and outputs to interface with the user and the backend. Methods on the helper take an instance of the controller to manipulate the state and UI.RENDER: Code in this file is only needed in more advanced scenarios where you want to override or modify the HTML DOM created by the Lightning Framework itself using markup expressed in yourCOMPONENTfile. It is focused on the presentation of your component in the browser.
Lightning Components client-side controllers can communicate with an Apex Controller class via the @AuraMethod annotation and thus access classes implementing your share application business logic as shown in the preceding diagram.
In this section, we will review the needs/concerns of the execution context and how each can lead to a common requirement of the application business logic. This helps define the guidelines around writing the application business logic, thus making it logical and more reusable throughout the platform and application:
- Error handling: When it comes to communicating errors, traditionally, a developer has two options: Let the error be caught by the execution context or catch the exception to display it in some form. In the Visualforce Apex controller context, it's typical to catch exceptions and route these through the
ApexPage.addMessagemethod to display messages to the user via theapex:pageMessagestag. In contrast to Batch Apex, letting the platform know that the job has failed involves allowing the platform to catch and handle the exception instead of your code. In this case, Apex REST classes, for example, will automatically output exceptions in the REST response.- Application business code implication: The point here is that there are different concerns with regard to error handling within each execution context. Thus, it is important for application business logic to not dictate how errors should be handled by calling the code.
- Transaction management: As we saw earlier in this chapter, the platform manages a single default transaction around the execution context. This is important to consider with the error handling concern, particularly if errors are caught, as the platform will commit any records written to the database prior to the exception occurring, which may not be desirable and may be hard to track down.
- Application business code implication: Understanding the scope of the transaction is important, especially when it comes to writing application business logic that throws exceptions. Callers, especially those catching exceptions, should not have to worry about creating
Database.Savepointto rollback the state of the database if an exception is thrown.
- Application business code implication: Understanding the scope of the transaction is important, especially when it comes to writing application business logic that throws exceptions. Callers, especially those catching exceptions, should not have to worry about creating
- Number of records: Some contexts deal with a single database record, such as a Visualforce Standard Controller, and others deal with multiple records, such as Visualforce Standard Set Controllers or Batch Apex. Regardless of the type of execution context, the platform itself imposes governors around the database operations that are linked with the number of records being processed. Every execution context expects code to be bulkified (minimal queries and DML statements).
- Application business code implication: Though some execution contexts appear to only deal with a single record at a time in reality because database-related governors apply to all execution context types, it is good practice to assume that the application code should consider bulkification regardless. This also helps make the application code more reusable in future from different contexts.
- State management: Execution contexts on Force.com are generally stateless; although as described earlier in this chapter, there are some platform facilities to store state across execution contexts.
- Application business code implications: As the state management solutions are not always available and are also implemented in different ways, the application code should not attempt to deal directly with this concern and should make itself stateless in nature. If needed, provide custom Apex types that can be used to exchange the state with the calling execution context code, for example, a controller class.
- Security: It could be said that the execution context should be the one concerned with enforcing this, as it is the closest to the end user. This is certainly the case with a controller execution context where Salesforce recommends the
with sharingkeyword is placed. However, when it comes to CRUD and FLS security, the practicality of placing enforcement at the execution context entry point will become harder from a maintenance perspective, as the code checking the users' permissions will have to be continually maintained (and potentially repeated) along with the needs of the underlying application business code.- Application business code implication: The implication here is that it is the concern of both the execution context and the application business logic to enforce the users permissions. However, in the case of sharing, it is mainly the initial Apex caller that should be respected. As we dive deeper into the engineering application business logic in later chapters, we will revisit security several times.
Tip
A traditional approach for logging errors for later review by administrators or support teams is to use a log table. While in Force.com this can be implemented to some degree, keep in mind that some execution contexts work more effectively with the platform features if you don't catch exceptions and let the platform handle it. For example, the Apex Jobs page will correctly report failed batches along with a summary of the last exception. If you implement a logging solution and catch these exceptions, visibility of failed batch jobs will be hidden from administrators. Make sure that you determine which approach suites your users best. If you decide to implement your own logging, keep in mind that this requires some special handling of Apex database transactions and the provision of application functionality to allow users to clean up old logs.
There is Separation of Concerns between code invoked directly through an execution context and the application business logic code within an application. This knowledge is important to ensure whether you can effectively reuse application logic easily, incrementally, and with minimal effort. It is the developer's responsibility to maintain this Separation of Concerns by following patterns and guidelines set out in the chapters of this book and those you devise yourself as part of your own coding guidelines.
Reuse needs may not always be initially obvious. However, by following Separation of Concerns and the design patterns in this book, when they do arise as your application evolves and/or new platform features are added, the process is more organic without refactoring, or worse, copying and pasting the code!
To illustrate a reuse scenario, imagine that in the first iteration of the FormulaForce application, awarding points to a race contestant was accomplished by the user through an Award Points button on the Contestant detail page for each contestant. Also, the newsletter functionality was accessed by manually clicking a Send News Letter button on the Season detail page each month.
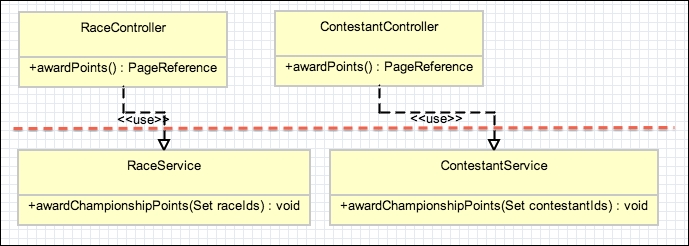
The class diagram for the first iteration is shown in the next diagram. Note that you can already see the beginning of a separation of concern between the Apex controller logic and application business logic, which is contained in the classes ending in Service. The Service layer is discussed in more detail later in this chapter.
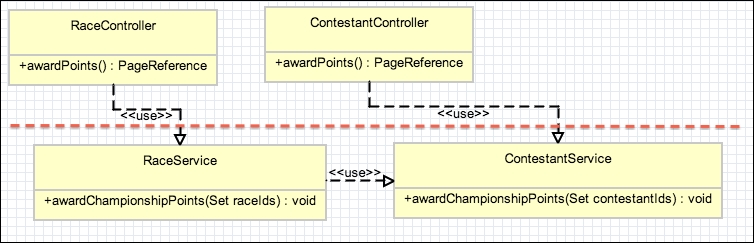
Now, imagine that in the second iteration of the application, user feedback requested that the awarding of points should also be available at the race level and applied in one operation for all contestants through a button on the Race detail page. In the following class diagram, you can see that the ContestService class is now reused by the RaceService class in order to implement the RaceController.awardPoints service method:
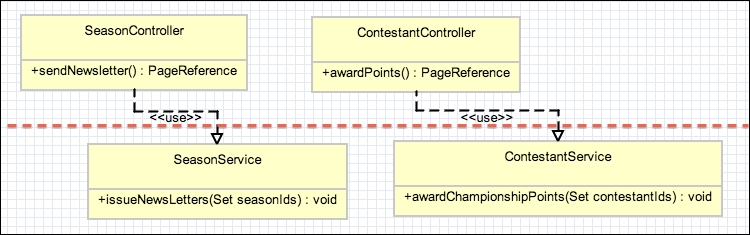
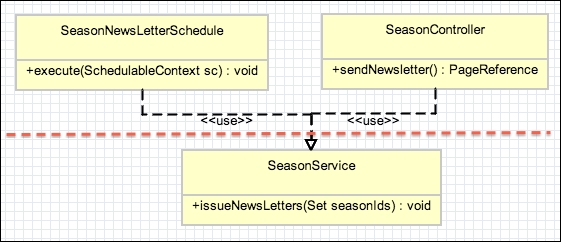
An additional enhancement was also requested to permit the newsletter functionality to use the platform scheduler to automatically issue the newsletter. The following diagram shows that the SeasonService class is now reused by both the SeasonNewsLetterSchedule class as well as the SeasonController class:
The preceding examples have shown that code from the first iteration can be reused either from the new application business logic or from a new execution context in the case of the scheduler. In the next chapter, we will take a further look at the Service layer, including its design guidelines that make this kind of reuse possible.