
4 Information extraction
- Extracting information from raw text
- Exploring useful NLP techniques, such as part-of-speech tagging, lemmatization, and parsing
- Building a language-processing pipeline with spaCy
In the previous chapter, you looked into ways of finding texts that talk about particular concepts or facts. You’ve built an information-retrieval system that can search for texts answering particular questions. For example, if you were wondering what information science is or what methods information-retrieval systems use, you needed to provide your information-retrieval system with the queries like “What is information science?” or “What methods do information-retrieval systems use?” and the system found for you relevant texts that talk about these things.
This system saves you a lot of time: you don’t need to manually search for texts that contain any relevant information about your question. Moreover, you don’t need to assess how relevant these texts are as the system can also rank them by relevance. However, this information-retrieval system still has some limitations: if you had a particular question in mind like “What is information science?” and just wanted to know the answer (e.g., “It is an academic field that is primarily concerned with analysis, collection, classification, manipulation, storage, retrieval, movement, dissemination, and protection of information,” according to Wikipedia: https://en.wikipedia.org/wiki/Information_science), you probably would not be interested in reading through the whole list of documents in order to find this answer, even if all of them were relevant. In some cases, looking for the exact answer in a collection of documents would be highly impractical. For example, imagine you have access to the whole web, but all you want to know is the definition for information science. If you search for the answer on Google, you would get over 4 * 109 relevant pages for this question. Obviously, looking through even a small portion of those in search for the exact answer would be time-consuming, given that this answer can be summarized in just one sentence. Luckily, Google also provides you with a snapshot of the relevant bit of the web page or even the definition when possible (figure 4.1).
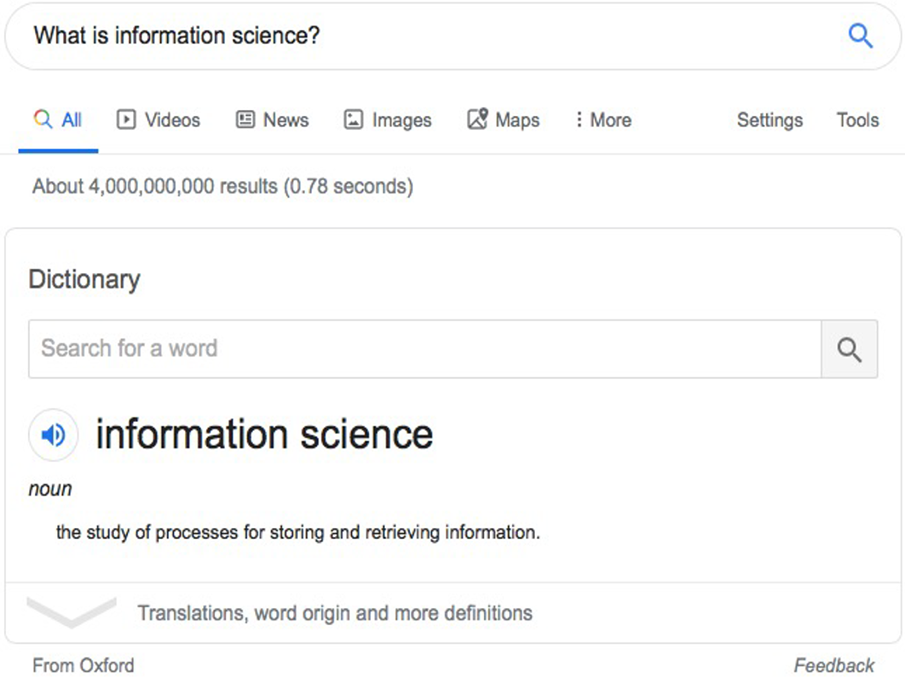
Figure 4.1 In addition to finding the relevant pages, Google returns the exact answer to the question.
The application that is used here is called information extraction (or text analytics or text mining) because it allows you to extract only particular facts or only the relevant information from an otherwise unstructured free-formatted text.
In this chapter, you will build your own system that can extract particular facts of interest from raw text. But first, let’s look into some examples of when this is useful.
4.1 Use cases
Here are some real-life applications that can benefit from information extraction.
4.1.1 Case 1
You have a collection of generally relevant documents, but all you need is a precise answer to a particular question. There are many situations where this might occur; for instance, you may be searching for an answer out of curiosity (e.g., “What is the meaning of life?”) or for educational purposes (“What temperature does water boil at?”). Perhaps you are collecting some specific information like a list of people present at the last meetings and want to automatically extract the names of all participants from the past meetings minutes. In the general case, your NLP engine might need to first find all relevant documents that talk about the subject of interest, just like you did in chapter 3, and then analyze those texts to identify the relation between the two concepts. Figure 4.2 reminds you of this process, discussed in chapter 1.

Figure 4.2 To get the answer to the question, you might need to first retrieve all relevant documents and then analyze them.
You are already familiar with the retrieval step, and this chapter will show you how to run the analysis of texts to extract the relevant facts. This case is an example of a popular NLP application—question answering. Question answering deals with a range of queries that might be formulated in a straightforward way, as in the example from figure 4.2, as well as in more convoluted ways. Just to give you a flavor of the task, the exact answer might not always be readily available in text. The question might be formulated as “Where was Albert Einstein born?” while the answer might use wording like “Albert Einstein’s birthplace is Ulm, Germany.” Despite the words born and birthplace being related to each other, the exact word matching won’t help you find the relevant answer here, and you will need to use further NLP techniques. There are many more examples where finding the correct answer is not trivial (see the examples from the SQuAD, a question-answering dataset and real-time competition, at http://mng.bz/1o5V). In this book, we will look into the extraction of relevant information from explicitly formulated answers, but the overall scope of the task is much wider.
4.1.2 Case 2
You have a collection of relevant documents, and you need to extract particular types of information to fill in a database. For instance, imagine you work in an insurance company, and you have a collection of various companies’ profiles. These profiles contain all the essential information about each company (e.g., the size of the company, the type of business it is involved in, its revenue). Many of these factors are critical for determining a suitable insurance policy, so rather than considering the companies one by one, you might want to extract these facts from the profiles and put them in a single database. Alternatively, imagine you work in a human resources division of a company that receives dozens of applications from potential candidates on a daily basis. Again, the types of information that your company would be interested in are easy to define in advance. You need to know about each candidate’s education, previous work experience, and core skills. Wouldn’t it be helpful if you could extract these bits of information automatically and put them in a single database? Information extraction in this case would help you save time on manually looking through various candidates’ CVs.
Databases are one way to structure information. In the candidates’ CVs case, you need to fill in specific information fields like Education, Work Experience, or Skills with the details extracted from CVs. One aspect of such documents as CVs and companies’ portfolios that may help you in this task is that they typically follow a particular format. A typical CV would contain a section explicitly called Education. In the simplest case, it should be possible to automatically identify relevant sections like Education and extract the information from such sections in a CV; for instance, everything related to one’s studies. Figure 4.3 visualizes this idea.
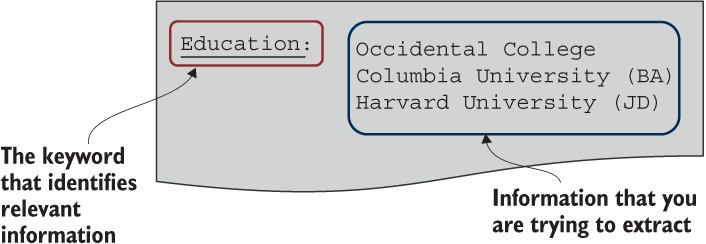
Figure 4.3 CVs are an example of semistructured documents. You may be able to identify where relevant information is located using keywords.
The problem is, not all documents of the same type will be structured in exactly the same way or even contain the same amount of information. To give you one example, imagine you undertook a project dealing with extraction of information about all famous personalities who have a Wikipedia page. A nice fact about Wikipedia is that it contains “infoboxes.” An infobox is a fixed-format table that you can see in the upper right corner of a Wikipedia page that summarizes main facts about the subject of that page. This is a good start for your project—infoboxes for people typically contain their name, birthplace, date of birth, reasons they are famous, and so on. This is an example of semistructured information: infoboxes specify the names of the information fields (e.g., Born or Citizenship). However, here is the tricky bit: even though the information is structured, it is not always structured in the same way. Moreover, even the field with the same name might provide you with a different range of information. Figure 4.4 shows an example comparing bits of just two infoboxes, one for Albert Einstein (https://en.wikipedia.org/wiki/Albert_Einstein) and one for Barack Obama (https://en.wikipedia.org/wiki/Barack_Obama).

Figure 4.4 Information extraction from Wikipedia infoboxes on two personalities
For space reasons, these are not complete infoboxes. Albert Einstein’s infobox contains additional information about his academic work, and Barack Obama’s provides more details about his political career. We may expect to see such differences. After all, Albert Einstein was not involved in politics, while Barack Obama is not an academic. However, comparing even the basic information fields, we can see that the format used for the two personalities differs: the Born field contains the name given at birth to Barack Obama, but for Albert Einstein this information is missing. Albert Einstein’s entry lists the details of his citizenship, but Barack Obama’s doesn’t, and so on. This shows that if you were to extract this information automatically, some fields in your database would end up being empty. In addition, even the fields that provide the same type of information sometimes use different formats for the same thing. Note the different date format used in Date of birth and the differences in Residence format—Albert Einstein has a list of countries where he resided, whereas Barack Obama shows only town and state. All these differences are hard to resolve without applying further NLP techniques and allowing more flexibility in the extraction process.
4.1.3 Case 3
You are working on a task not related to information extraction itself, but you expect that adding relevant information or insights would be crucial for the success of this task. Let’s take the example with the human resources task of analyzing lots of CVs one step further. Imagine this is an HR department in a large company with multiple open positions. Each position has a job specification: it lists the requirements, job responsibilities, salary level, and so on. In effect, such job specs are themselves examples of semistructured information, so using a very similar approach, one can fill in another database, this time for open job positions. Now, rather than trying to manually match job specifications to the candidates’ applications, why not automate this process and try to match relevant information fields between the two databases?
Here is another example: imagine you are a financial analyst in an investment company. It has been shown that certain types of political, financial, or business-related events reported on the news influence trends on stock markets. For instance, a report on a company CEO’s death or patent disputes might negatively affect the company’s stock prices, while news about a major acquisition or merger might result in a positive trend on the market. As an analyst, you might have to spend your time looking for such signals in the news and trying to connect them with the stock market movements, or you might use the power of data analysis and machine learning. In recent years, there has been a lot of research on the intersection of NLP and financial domains aimed at automatically predicting future stock market movements based on reported news (e.g., check http://mng.bz/N6QE). The key task here is to be able to extract the structured information (i.e., specific facts of interest) from free-formatted text (such as news articles). Apart from these examples, you might use information extraction to
-
Learn which types of businesses are riskier and require higher insurance rates by extracting relevant facts from companies’ portfolios. For example, there is a higher fire risk in a restaurant than in a convenience store, but a convenience store located in an unsafe neighborhood might have a higher risk for burglary.
-
Learn which aspects of your product or service your customers are most happy and most unhappy about by extracting their opinions from customer feedback forms and discussion forums (e.g., customers might find the location of a hotel very pleasant while being unhappy about the cleaning services. See http://mng.bz/DgBy).
-
Learn which factors contribute to higher sales of a particular product by extracting features from the product descriptions. For instance, detached houses with gardens might sell better than semidetached ones, while red cars might be more popular than yellow ones, and so on.
These three cases cover diverse areas and scenarios, and in particular examples described under case 3 require you to connect multiple pieces of information across domains, such as from text-based descriptions to financial data. In addition, in many of these cases, the power of NLP techniques combined with machine learning may help you discover new facts about your data and your task. For instance, you don’t need to know in advance which aspects of your product or service may be successful or unsuccessful, as this is what NLP techniques help you find in the raw text data. What brings all these case studies together is the need to extract relevant bits of information from fully unstructured (e.g., free-formatted text) or partially structured (e.g., Wikipedia infoboxes) information. NLP techniques that will help you in this task are the subject of this chapter.
4.2 Understanding the task
Now that you’ve looked into some real-life applications of information extraction, it’s time to start working on your own information extractor. Let’s start with a scenario inspired by one of the use cases we just covered. Imagine that you work as a data analyst. You are planning to investigate how different types of events affect stock market movements. For instance, you have a hunch that the meetings between politicians and other personalities might be important signals for the market. You have a collection of recent news articles. Using information-extraction techniques, extract the facts about all the meetings between politicians and other personalities from this data.
How should you approach this task? Let’s first define what represents the core information about the event here. In the meeting events, there are three indispensable bits of information: the action of meeting itself and two participants, each of whom can be a single person or a group of people. For example, a meeting might take place between two companies, or a president and their administration, and so on. We say that these bits are the core information because one cannot eliminate any of the three: if “X meets Y,” saying “X meets,” “X Y,” or “meets Y” will be nonsensical, as it will raise questions like “Whom X meets?”, “What do X and Y do?” and “Who meets Y?” In other words, only the phrase like “X meets Y” contains all the necessary information about who does what and who else is involved. Therefore, at the very least, you’d want to extract these three bits. Once this is done, you may explore the available information further and, if the text mentions it, find out about the time of the meeting (“X meets Y at noon” or “X meets Y on Friday”), the purpose (“X meets Y for coffee”), and so on. Now let’s see how you can use Python to do this.
Suppose all the relevant phrases in text were of the form “X meets Y” or “X met Y” (let’s ignore the difference between the two different forms of the verb here, meets and met), as in the title of the movie When Harry Met Sally . . . . In these cases, it is very clear who the two participants are and what happened (figure 4.5): the participants can be identified by the questions “Who met Sally?” and “Whom Harry met?” and the action can be identified by the questions like “What did Harry do?” or more generally “What happened with Harry and Sally?”

Figure 4.5 Analysis of the phrase When Harry met Sally . . .
Such cases are relatively easy to deal with. For instance, you can read the text word by word, and once you see a word, such as met, that is of interest to you in this application, you extract the previous word as participant1 and the next word as participant2. Listing 4.1 shows how to implement this in Python. In this code, you first provide the string information that contains met surrounded by the two participants. To extract the names of the participants from it, you split this string by whitespaces and store the result in a list words. Participant1 can be identified by its position immediately before the word met and participant2 by its position immediately after it. Printing the result should return Participant1 = Harry, Action = met, and Participant2 = Sally.
Listing 4.1 Code to extract names of the participants of a meeting
information = "When Harry met Sally" ❶ words = information.split() ❷ print (f"Participant1 = {words[words.index('met')-1]}") print (f"Action = met") print (f"Participant2 = {words[words.index('met')+1]}") ❸
❶ Provide the string information that contains “met” surrounded by the two participants.
❷ Split this text by whitespaces and store the result in the list words.
❸ Participant1 is the word preceding “met,” and participant2 is the one following it.
This approach works well in this particular case; however, you’re not done with the whole task yet, as the examples that you see in actual data will rarely be as straightforward as that. To begin with, the expressions for participants may span more than one word. For instance, the algorithm from listing 4.1 will fail on Harry Jones met Sally and on Harry met Sally Smith and Harry Jones met Sally Smith, as it will only return partial names for the participants. In addition, there are variations in the wording of the action itself. For official meetings between politicians or personalities, it is more common to say “X met with Y,” so once again the algorithm from listing 4.1 is not flexible enough to return the correct names for the participants. Finally, the particular way in which the participants are mentioned in text may differ from the “X met Y” version. The order may be different and the distance between the participants in terms of intervening words may be larger. For instance, in Sally, with whom Harry met on Friday, the participants’ names are still the same, but the order in which they are mentioned as well as the distance separating them are different. Figure 4.6 shows this idea.

Figure 4.6 A different word order expressing the same idea as in figure 4.5.
Once again, the algorithm from listing 4.1 will not be able to deal with such cases. The problem with this simple code is that it relies too much on the particular template—order and format—which would work in some cases only. After all, we said that sometimes information comes in a semistructured format, so templates are useful in such cases. But in the general case, because language is very creative, there will be multiple ways to express the same idea using different formats, word order, and distance between the meaningful words, so what you actually need is an algorithm that can capture
Figure 4.7 illustrates the requirements for such an algorithm.

Figure 4.7 An information extraction algorithm in a nutshell
Ideally, your algorithm will take raw text as input and will return tuples consisting of two participants and the action of meeting as a representation of the core information. In the preceding example, (Harry, met, Sally) will be such a tuple. For example, suppose your algorithm can extract the essential information from sentences like “Donald Trump meets with the Queen at D-Day event,” “The Queen meets with the Prime Minister every week,” and so on, and convert it into a list of tuples of the form (participant1, action, participant2)—that is, [('Donald Trump', 'meets with', 'the Queen'), ('the Queen', 'meets with', 'the Prime Minister')]. Now you can use these tuples in all sorts of applications; for example, you can find answers to questions like “Whom does Donald Trump meet with?” Just consider that you can always convert this question to the same tuple representation ('Donald Trump', 'meets with', ?). Then this question becomes identical to asking, “What are participant2 entries in tuples where action='meet with' and participant1='Donald Trump'?” Figure 4.8 shows this process.

Figure 4.8 Both the input text and the question can be represented as tuples where each bit has a specific role.
The following listing shows how the search for the exact answer, when both questions and potential answers are represented as lists of tuples, becomes just a search on Python lists.
Listing 4.2 Code to search for the exact answer in Python list of tuples
meetings = [('Boris Johnson', 'meets with', 'the Queen'),
('Donald Trump', 'meets with', 'his cabinet'),
('administration', 'meets with', 'tech giants'),
('the Queen', 'meets with', 'the Prime Minister'),
('Donald Trump', 'meets with', 'Finnish President')
] ❶
query = [p2 for (p1, act, p2) in meetings
if p1=='Donald Trump'] ❷
print(query) ❸❶ Shows a list of tuples (p1, act, p2) for participant1, action, and participant2 extracted from raw text
❷ Query looks for all p2 in tuples (p1, act, p2) where p1='Donald Trump'.
❸ The resulting list should contain two entries: ['his cabinet', 'Finnish President']
Obviously, meetings are mutual actions, so if participant1 meets with participant2, then participant2 also meets with participant1. On the news, the order will not always be exactly the same, so in listing 4.3, let’s make a minor modification to the preceding code and extract the relevant other participant whenever either participant1 or participant2 is the personality of interest. As with code in listing 4.2, first a list of tuples (p1, act, p2) for participant1, action, and participant2 is extracted from raw text. However, this time the query looks for all p2 in tuples (p1, act, p2) where p1='the Queen' as well as for all p1 in tuples (p1, act, p2) where p2='the Queen'. As a result, you should get a list with two entries: ['the Prime Minister', 'Boris Johnson'].
Listing 4.3 Code to extract information about the other participant of a meeting
meetings = [('Boris Johnson', 'meets with', 'the Queen'),
('Donald Trump', 'meets with', 'his cabinet'),
('administration', 'meets with', 'tech giants'),
('the Queen', 'meets with', 'the Prime Minister'),
('Donald Trump', 'meets with', 'Finnish President')
] ❶
query = [p2 for (p1, act, p2) in meetings if p1=='the Queen']
query += [p1 for (p1, act, p2) in meetings
if p2=='the Queen'] ❷
print(query) ❸❶ Shows a list of tuples (p1, act, p2) for participant1, action, and participant2 extracted from raw text
❷ Expand the query on tuples (p1, act, p2) so that one of the participants is 'the Queen'.
❸ The resulting list should contain two entries: ['the Prime Minister', 'Boris Johnson'].
Now let’s see how you can extract such tuple representations from raw text.
4.3 Detecting word types with part-of-speech tagging
This section will show you how to extract the meaningful bits of information from raw text and how to identify their roles. Let’s first look into why identifying roles is important.
4.3.1 Understanding word types
The first fact to notice about the preceding cases is that there is a conceptual difference between the bits of the expression like [Harry] [met] [Sally]: Harry and Sally both refer to people participating in the event, while met represents an action. When we read a text like this, we subconsciously determine the roles each word or expression plays along those lines. To us, words like Harry and Sally can only represent participants of an action but cannot denote an action itself, while words like met can only denote an action. This helps us get at the essence of the message quickly. We read Harry met Sally and we understand [HarryWHO] [metDID_WHAT] [SallyWHOM].
This recognition of word types has two major effects: the first is that the straightforward, unambiguous use of words in their traditional functions helps us interpret the message. Funnily enough, this applies even when we don’t really know the meaning of the words. Our expectations about how words are usually combined in sentences and what roles they usually play are so strong that when we don’t know what a word means, such expectations readily suggest what it might mean—for example, we might not be able to exactly pin it down, but we still would be able to say if an unknown word means some sort of an object or some sort of an action. This “guessing game” would be familiar to anyone who has ever tried learning a foreign language and had to interpret a few unknown words based on other, familiar words in the context. Even if you are a native speaker of English and never tried learning a different language, you can still try playing a guessing game, such as with nonsensical poetry. Figure 4.9 shows an excerpt from “Jabberwocky,” a famous nonsensical poem by Lewis Carroll (https://www.poetryfoundation.org/poems/42916/jabberwocky).

Figure 4.9 An example of text where the meaning of some words can only be guessed
Some of the words here would be familiar to anyone, but what do “Jabberwock”, “Bandersnatch”, and “frumious” mean? It would be impossible to give a precise definition for any of them simply because these words don’t exist in English or any other language, so their meaning is anybody’s guess. However, one can say with high certainty that “Jabberwock” and “Bandersnatch” are some sort of creatures, while “frumious” is some sort of quality (a blend of fuming and furious, according to Lewis Carroll). How do we make such guesses? You might notice that the context for these words gives us some clues: we know what “beware” means. It’s an action, and as an action it requires some participants. One doesn’t normally just “beware”; one needs to beware of someone or something. Therefore, we expect to see this someone or something, and here comes “Jabberwock”. Another clue is given away by the word the, which normally attaches itself to objects (e.g., “the car”) or creatures (e.g., “the dog”), so we arrive at an interpretation of “Jabberwock” and “Bandersnatch” being creatures. Finally, in “the frumious Bandersnatch” the only possible role for “frumious” is some quality because this is how it typically works in language (e.g., “the red car” or “the big dog”).
The second effect that the expectations about the roles that words play have on our interpretation is that we tend to notice when these roles are ambiguous or somehow violated, because such violations create a discordance. That’s why ambiguity in language is a rich source of jokes and puns, intentional or not. Here is one expressed in a news headline (figure 4.10).

Figure 4.10 An example of ambiguity in action
What is the first reading that you get? You wouldn’t be the only one if you read this as “Police help a dog to bite a victim”; however, common sense suggests that the intended meaning is probably “Police help a victim with a dog bite” (i.e., someone who was bitten by a dog). News headlines are rich in ambiguities like this because they use a specific format aimed at packing the maximum amount of information in the shortest possible expression. This sometimes comes at a price, as both “Police help a dog to bite a victim” and “Police help a victim with a dog bite (that was bitten by a dog)” are clearer but longer than “Police help dog bite victim” that a newspaper might prefer to use. This ambiguity is not necessarily intentional, but it’s easy to see how this can be used to make endless jokes.
What exactly causes confusion here? It is clear that “police” denotes a participant in an event, and “help” denotes the action. “Dog” and “victim” also seem to unambiguously be participants of an action, but things are less clear with “bite.” Bite can denote an action, as in “Dog bites a victim” or the result of an action, as in “He has mosquito bites.” In both cases, what we read is the word “bites,” and it doesn’t give away any further clues as to what it means. However, in “Dog bites a victim,” it answers the question “What does the dog do?” and in “He has mosquito bites,” it answers the question “What does he have?” Now, when you see a headline like “Police help dog bite victim,” your brain doesn’t know straightaway which path to follow:
-
Path 1—“bite” is an action answering the question “What does one do?” ® “Police help dog [biteDO_WHAT] victim”
-
Path 2—“bite” is the result of an action answering the question “What happened?” ® “Police help dog [biteWHAT] victim.”
Apart from the humorous effect of such confusions, ambiguity may also slow the information processing and lead to misinterpretations. Try solving exercise 4.1 to see how the same expression may lead to completely different readings. You can then check the answers at the end of the chapter.
So far, we’ve been using the terminology quite frivolously. We’ve been defining words as denoting actions or people or qualities, but in fact there are more standard terms for that. The types of words defined by the different functions the words might fulfill are called parts of speech, and we distinguish between a number of such types:
-
Nouns—Words that denote objects, animals, people, places, and concepts
-
Adjectives—Words that denote qualities of objects, animals, people, places, and concepts
-
Adverbs—Those for qualities of actions, states, and occurrences
Table 4.1 provides some examples and descriptions of different parts of speech.
Table 4.1 Examples of words of different parts of speech
This is not a comprehensive account of all parts of speech in English, but with this brief guide, you should be able to recognize the roles of the most frequent words in text, and this suite of word types should provide you with the necessary basis for the implementation of your own information extractor.
Why do we care about the identification of word types in the context of information extraction and other tasks? You’ve seen that correct and straightforward identification of types helps information processing, while ambiguities lead to misunderstandings. This is precisely what happens with the automated language processing: machines, like humans, can extract information from text better and more efficiently if they can recognize the roles played by different words, while misidentification of these roles may lead to mistakes of various kinds. For instance, having identified that “Jabberwock” is a noun and some sort of a creature, a machine might be able to answer a question like “Who is Jabberwock?” (e.g., “Someone/something with jaws that bite and claws that catch”), while if a machine processed “I can fish” as “I know how to fish,” it would not be able to answer the question “What did you put in cans?”
Luckily, there are NLP algorithms that can detect word types in text, and such algorithms are called part-of-speech taggers (or POS taggers). Figure 4.11 presents a mental model to help you put POS taggers into the context of other NLP techniques.

Figure 4.11 Mental model that visualizes the flow of information between different NLP components
As POS tagging is an essential part of many tasks in language processing, all NLP toolkits contain a tagger. You will often need to include it in your processing pipeline to get at the essence of the message. Let’s now look into how this works in practice.
4.3.2 Part-of-speech tagging with spaCy
In the previous chapters, you used NLTK to process text data. This chapter will introduce spaCy, another very useful NLP library that you can put under your belt. There are several reasons to look into spaCy in this book:
-
By the end of this book, you will have worked with many useful toolkits and libraries, including NLTK and spaCy. The two have their complementary strengths, so it’s good to know how to use both.
-
spaCy is an actively supported and fast-developing library that keeps up-to-date with the advances in NLP algorithms and models.
-
There is a large community of people working with this library, so you can find code examples for various applications implemented with or for spaCy on their web page, as well as find answers to your questions on their GitHub page (see various projects using spaCy or developed for spaCy at https://spacy.io/universe).
-
It includes a powerful set of tools particularly applicable to large-scale information extraction.
Note To get more information on the spaCy library, check https://spacy.io. Installation instructions walk you through the installation process, depending on your operating system: https://spacy.io/usage#quickstart. Note that for this toolkit to work properly, you will also need to install models (e.g., en_core_ web_sm, en_core_web_md, and en_core_web_lg) as explained on the web page.
Unlike NLTK, which treats different components of language analysis as separate steps, spaCy builds an analysis pipeline from the very beginning and applies this pipeline to text. Under the hood, the pipeline already includes a number of useful NLP tools that are run on input text without you needing to call on them separately. These tools include, among others, a tokenizer and a POS tagger. You simply apply the whole lot of tools with a single line of code calling on the spaCy processing pipeline, and then your program stores the result in a convenient format until you need it. This also ensures that the information is passed between the tools without you taking care of the input-output formats. Figure 4.12 shows spaCy’s NLP pipeline, which we will discuss in more detail next.

Figure 4.12 spaCy’s processing pipeline with some intermediate results. The diagram follows closely the one in the spaCy’s documentation (https://spacy.io/usage/processing-pipelines).
In the previous chapters, we’ve discussed that machines, unlike humans, do not treat input text as a sequence of sentences or words. For machines, text is simply a sequence of symbols. Therefore, the first step that we applied was splitting text into words. This step is performed by a tool called tokenizer. Tokenizer uses raw text as an input and returns a list of words as an output. For example, if you passed it a sequence of symbols like "Harry, who Sally met", it would return a list of tokens ["Harry", ",", "who", ...]. Next, we applied a stemmer that converted each word to some general form. This tool takes a word as an input and returns its stem as an output. For instance, a stemmer would return a generic, base form meet for both meeting and meets. A stemmer can be run on a list of words, where it would treat each word separately and return a list of correspondent stems. Other tools, however, will require an ordered sequence of words from the original text. We’ve seen that it’s easier to figure out that Jabberwock is a noun if we know that it follows a word like the, so order matters for POS tagging. That means that each of the three tools—tokenizer, stemmer, POS tagger—requires a different type of input and produces a different type of output, so in order to apply them in sequence, we need to know how to represent information for each of them. That is what spaCy’s processing pipeline does for you: it runs a sequence of tools and connects their outputs together.
In chapter 3, we mentioned two approaches to getting at the base form of a word. For information retrieval, we opted for stemming that converts different forms of a word to a common core. We said that it is useful because it helps connect words together on a larger scale, but it also produces nonwords: you won’t always be able to find stems of the words (e.g., something like retriev) in a dictionary. An alternative to this tool is lemmatizer, which aims at converting different forms of a word to its base form that can actually be found in a dictionary; for instance, it will return a lemma retrieval that can indeed be found in a dictionary. Such base form is called lemma. In its processing pipeline, spaCy uses a lemmatizer (more information about spaCy’s lemmatizer can be found on the API page: https://spacy.io/api/lemmatizer). Lemmatizers can be implemented in various ways, from lookup approaches, when the algorithm tries to match the word forms to the base dictionary forms; to rule-based approaches, when the algorithm applies a series of rules to process word forms; to machine learning, when the algorithm learns the correspondences from the language data; to a combination of all of the above. Although you can build your own lemmatizer, the benefit of relying on an out-of-the-box lemmatizer (e.g., from spaCy) is that such preprocessing tools are normally highly optimized in terms of speed and performance.
The starting point for spaCy’s processing pipeline is, as before, raw text. For example, “On Friday board members meet with senior managers to discuss future development of the company.” The processing pipeline applies tokenization to this text to extract individual words: ["On", "Friday", "board", ...]. The words are then passed to a POS tagger that assigns POS tags like ["ADP", "PROPN", "NOUN", ...], to a lemmatizer that produces output like ["On", "Friday", ..., "member", ..., "manager", ...], and to a bunch of other tools, many of which we will discuss in this book.
Note In the scheme used by spaCy, prepositions are referred to as “adposition” and use a tag ADP. Words like Friday or Obama are tagged with PROPN, which stands for “proper noun” and is reserved for names of known individuals, places, time references, organizations, events, and such. For more information on the tags, see documentation at https://spacy.io/api/annotation and https://universaldependencies.org/u/pos/.
You may notice that the processing tools in figure 4.12 are comprised within a pipeline called nlp. As you will shortly see in the code, calling on nlp pipeline makes the program first invoke all the pretrained tools and then applies them to the input text in relevant order. The output of all the steps gets stored in a “container” called Doc. This contains a sequence of tokens extracted from input text and processed with the tools. Here is where spaCy implementation comes close to object-oriented programming: the tokens are represented as Token objects with a specific set of attributes. If you have done object-oriented programming before, you will hopefully see the connection soon. If not, here is a brief explanation. Imagine you want to describe a set of cars. All cars share the list of attributes they have: the car model, size, color, year of production, body style (e.g., sedan, convertible), type of engine, and so on. At the same time, such attributes as wingspan or wing area won’t be applicable to cars—they relate to planes. So you can define a class of objects called Car and require that each object car of this class should have the same information fields; for instance, car.model should return the name of the model of the car, for example car.model="Volkswagen Beetle", and car.production_year should return the year the car was made, such as car.production_year="2003", and so on.
This is the approach taken by spaCy to represent tokens in text. After tokenization, each token (word) is packed up in an object token that has several attributes. For instance:
Note You may notice that some attributes are called on using an underscore, like token.lemma_. This is applicable when spaCy has two versions for the same attribute; for example, token.lemma returns an integer version of the lemma, which represents a unique identifier of the lemma in the vocabulary of all lemmas existing in English, while token.lemma_ returns a Unicode (plain text) version of the same thing. See the description of the attributes on https://spacy.io/api/token.
The nlp pipeline aims to fill in the information fields like lemma, pos, and others with the values specific for each particular token. Since different tools within the pipeline provide different bits of information, the values for the attributes are added on the go. Figure 4.13 shows this process for the words “on” and “members” in the text “On Friday board members meet with senior managers to discuss future development of the company.”

Figure 4.13 Processing of words “On” and “members” within the nlp pipeline
Now let’s see how this is implemented in Python code. Listing 4.4 provides you with an example. In this code, you rely on spaCy’s functionality. The spacy.load command initializes the nlp pipeline. The input to the command is a particular type of data (model) that the language tools were trained on. All models use the same naming conventions (en_core_web_), which means that it is a set of tools trained on English web data; the last bit denotes the size of data the model was trained on, where sm stands for “small.”
Note Check out the different language models available for use with spaCy at https://spacy.io/models/en. Small model (en_core_web_sm) is suitable for most purposes and is more efficient to upload and use. However, larger models like en_core_web_md (medium) and en_core_web_lg (large) are more powerful and some NLP tasks will require the use of such larger models. The models should be installed prior to running the code examples with spaCy. You can also install the models from within the Jupyter Notebook using the command !python -m spacy download en_core_web_sm.
Listing 4.4 Code exemplifying how to run spaCy’s processing pipeline
import spacy ❶ nlp = spacy.load("en_core_web_sm") ❷ doc = nlp("On Friday board members meet with senior managers " + "to discuss future development of the company.") ❸ rows = [] rows.append(["Word", "Position", "Lowercase", "Lemma", "POS", "Alphanumeric", "Stopword"]) ❹ for token in doc: rows.append([token.text, str(token.i), token.lower_, token.lemma_, token.pos_, str(token.is_alpha), str(token.is_stop)]) ❺ columns = zip(*rows) ❻ column_widths = [max(len(item) for item in col) for col in columns] ❼ for row in rows: print(''.join(' {:{width}} '.format( row[i], width=column_widths[i]) for i in range(0, len(row)))) ❽
❶ Start by importing the spaCy library.
❷ The spacy.load command initializes the nlp pipeline.
❸ Provide the nlp pipeline with input text.
❹ Print the output in a tabular format and add a header to the printout for clarity.
❺ Add the attributes of each token in the processed text to the output for printing.
❻ Python’s zip function allows you to reformat input from row-wise representation to column-wise.
❼ Calculate the maximum length of strings in each column to allow enough space in the printout.
❽ Use the format functionality to adjust the width of each column in each row while printing out the results.
Once the nlp pipeline is initialized, you provide it with input text. The goal of this code is to print out individual words from the input together with all their linguistic attributes assigned by the nlp pipeline, so the code shows how you can print the output in a tabular format, add a header to the printout, add the attributes of each token in the processed text to the output, and reformat row-wise representation to column-wise representation using Python’s zip function (check out documentation on Python’s functions at https://docs.python.org/3/library/functions.html). As each column may contain strings of variable lengths, the code shows how you can calculate the maximum length of strings in each column to allow enough space in the printout. Finally, it shows how to print out the results using the format functionality to adjust the width of each column in each row (check out string formatting techniques in Python 3 at https://docs.python.org/3/library/string.html).
Table 4.2 shows the output that this code will return for some selected words from the input text. Please note that “...” is used to show that there is more output omitted for space reasons.
Table 4.2 Output from listing 4.4 presented in a table format.
-
The first item in each line is the original word from text. It is returned by token.text.
-
The second is the position in text, which starts as all other indexing in Python from 0. This is identified by token.i.
-
The third item is the lowercase version of the original word. You may notice that it changes the forms of On and Friday. This is returned by token.lower_.
-
The fourth item is the lemma of the word, which returns member for members and manager for managers. Lemma is identified by token.lemma_.
-
The fifth item is the part-of-speech tag. Most of the tags should be familiar to you by now. The new tags in this piece of text are PART, which stands for particle and is assigned to particle to in to discuss, and PUNCT for punctuation marks. POS tags are returned by token.pos_.
-
The sixth item is a True/False value returned by token.is_alpha, which checks whether a word contains alphabetic characters only. This attribute is False for punctuation marks and some other sequences that don’t consist of letters only, so it is useful for identifying and filtering out punctuation marks and other nonwords.
-
Finally, the last, seventh item in the output is a True/False value returned by token.is_stop, which checks whether a word is in a stopwords list. This is a list of highly frequent words in language that you might want to filter out in many NLP applications, as they are likely to not be very informative. For example, articles, prepositions (e.g., on), and particles (e.g., to) will have their is_stop values set to True as you can see in the preceding output.
If you run the code from listing 4.4 on a text like “Jabberwocky,” you will see that even though it contains non-English words, or possibly nonwords at all, this code can tell that “Jabberwock” and “Bandersnatch” are some creatures that have specific names (it assigns a tag PROPN, proper noun, to both of them), and that “frumious” is an adjective. How does it do that? Here is a glimpse under the hood of a typical POS tagging algorithm (figure 4.14).

Figure 4.14 A glimpse under the hood of a typical POS tagging algorithm
We’ve said earlier that when we try to figure out what type of a word something like “Jabberwock” is, we rely on the context. In particular, the previous words are important to take into account. If we see the, chances that the next word is a noun or an adjective are very high, but a chance that we see a verb next is minimal—verbs shouldn’t follow articles in grammatically correct English. Technically, we rely on two types of intuition: we use our expectations about what types of words typically follow other types of words, and we also rely on our knowledge that words like fish can be nouns or verbs but hardly anything else. We perform the task of word type identification in sequence. For instance, in the example from figure 4.14, when the sentence begins, we already have certain expectations about what type of word we may see first—quite often, it will be a noun or a pronoun (like I ). Once we’ve established that it is very likely for a pronoun to start a sentence, we also rely on our intuition about how likely it is that such a pronoun will be exactly I. Then we move on and expect to see a particular range of word types after a pronoun. Almost certainly it should be a normal verb or a modal verb (as verbs denoting obligations like “should” and “must” or abilities like “can” and “may” are technically called). More rarely, it may be a noun (like “I, Jabberwock”), an adjective (“I, frumious Bandersnatch”), or some other part of speech. Once we’ve decided that it is a verb, we assess how likely it is that this verb is can; if we’ve decided that it is a modal verb, we assess how likely it is that this modal verb is can, and so on. We proceed like that until we reach the end of the sentence, and this is where we assess which interpretation we find overall more likely. This is one possible stepwise explanation of how our brain processes information, on which POS tagging is based.
The POS tagging algorithm, similarly, takes into account two types of expectations: (1) that a certain type of a word (like modal verb) may follow a certain other type of a word (like pronoun), and (2) that if it is a modal verb, such a verb may be can. These “expectations” are calculated using the data; for example, to find out how likely it is that a modal verb follows a pronoun, we calculate the proportion of times we see a modal verb following a pronoun in data among all the cases where we saw a pronoun. For instance, if we saw 10 pronouns like I and we in data before, and 5 times out of those 10 these pronouns were followed by a modal verb like can or may (as in “I can” and “we may”), what would the likelihood, or probability, of seeing a modal verb following a pronoun be? Figure 4.15 gives a hint on how probability can be estimated.

Figure 4.15 If modal verb follows pronoun 5 out of 10 times, the probability is 5/10.
Probability(modal verb follows pronoun) = 5 / 10

Note Recall, P is the notation for probability.
Similarly, to estimate how likely (or how probable) it is that the pronoun is I, we need to take the number of times we’ve seen the pronoun I and divide it by the number of times we’ve seen any pronouns in the data. So, if among those 10 pronouns that we’ve seen in the data before 7 were I and 3 were we, the probability of seeing a pronoun I would be estimated as shown in figure 4.16.
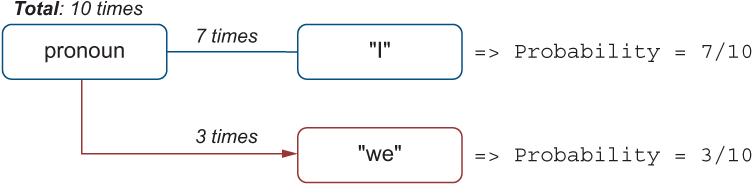
Figure 4.16 If 7 times out of 10 the pronoun is I, the probability of a word being I given that we know the POS of such a word is pronoun is 7/10.
Probability(pronoun being "I") = 7 / 10

This description of probability estimation may remind you of the discussion from chapter 2. There, we used a similar approach to estimate probabilities.
In the end, the algorithm goes through the sequence of tags and words one by one and takes all the probabilities into account. Since the probability of each decision (i.e., of each tag and each word) is a separate component in the process, these individual probabilities are multiplied. So, to find out how probable it is that “I can fish” means “I am able / know how to fish,” the algorithm calculates

This probability gets compared with the probabilities of all the alternative interpretations, like “I can fish” = “I put fish in cans”:

In the end, the algorithm compares the calculated probabilities for the possible interpretations and chooses the one that is more likely (i.e., has higher probability).
4.4 Understanding sentence structure with syntactic parsing
In this section, you will learn how to automatically establish the types of relations that link meaningful words together.
4.4.1 Why sentence structure is important
Now you know how to detect which types the words belong to. Your algorithm from listing 4.4 is able to tell that in the sentence “On Friday, board members meet with senior managers to discuss future development of the company,” words like Friday, board, members, and managers are more likely to be participants of some actions as they are nouns, while words like meet and discuss denote actions themselves as they are verbs. This brings you one step closer to solving the task; however, one bit is still missing: How are these words related to each other, and which of the potential participants are the actual participants of the action in question? That is, who met with whom?
We said before that in the simplest case, returning the words immediately before and immediately after the word that denotes the action works in some cases. However, in the sentence at hand, this doesn’t work. POS tagging helps you identify that “meet (with)” is an action, but you would need to return “board members” and “senior managers” as the two participants. So far, the algorithm is only able to detect that board, members, and managers are nouns, while senior is an adjective, but it hasn’t linked the words together yet. The next step is to identify that board and members together form one group of words and senior and managers another group, and these two groups represent the participants in the action as they are both directly related to the verb meet (with). These are not the only words that are related to the action of meeting. In fact, the group of words “On Friday” tells us about the time of the meeting, and “to discuss future development of the company” tells us about the purpose. Ideally, we would like to be able to get all these bits of information. Figure 4.17 demonstrates this idea.
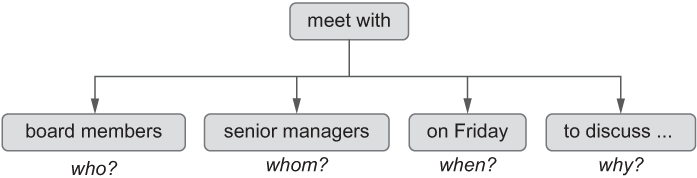
Figure 4.17 All bits of information related to the action of meeting as we expect them to be identified by a parser
In this representation, we put the action “meet (with)” at the center or root of the whole account of events because it makes it easier to detect other participants that are involved in this action and other bits of information related to it starting from the verb itself.
Word types that we’ve defined in the previous step help us identify the groups of words and their relations to the main action here. Normally, participants of an action are expressed with groups of words involving nouns, while locations and time references are usually attached to the verb with a preposition (like “on Friday” or “at the office”), and the purpose of the meeting would often be introduced using “to” and a further expression involving a verb (like “discuss”). We rely on such intuitions when we detect which words are related to each other, and machines use a similar approach as well.
Before we move on to using this tool in practice, here is an example illustrating why parsing and identification of relations between words is not a trivial task and may lead to misunderstandings, just like POS tagging before. This example comes from the joke by Groucho Marx, which went like this: “One morning I shot an elephant in my pajamas. How he got into my pajamas I’ll never know.” What exactly produces the humorous effect here? It is precisely the identification of relation links between the groups of words! Under one interpretation, “in my pajamas” is attached to “an elephant”, and, in fact, because the two groups of words are next to each other in the sentence, this is a much easier interpretation to process, so our brain readily suggests it. However, common sense tells us that “in my pajamas” should be attached to “shot” and that it was “I” who was wearing the pajamas, not an elephant. The problem is that these components are separated from each other by other words, so based on the structure of the sentence, this is not the first interpretation that comes to mind. What adds to ambiguity here is the fact that prepositional phrases (the ones that start with prepositions like in or with) are frequently attached to nouns (“to a manNOUN with a hammer, everything looks like a nail”) and to verbs (“driveVERB nails with a hammer”). Parsers, like humans, rely on the patterns of use in language and use the information about the types of words to identify how words are related to each other; however, it is by no means a straightforward task.
4.4.2 Dependency parsing with spaCy
We said before that as we are interested in the action expressed by a verb, like “meet (with),” and its participants, it is the action that we put at the center or at the root of the whole expression. Having done that, we start working from the verb at the root trying to identify which words or groups of words are related to this action verb. We also say that when the words are related to this verb, they depend on it. In other words, if the action is denoted by the verb meet, starting from this verb we try to find words that answer relevant questions: “who meet(s)?” ® “board members,” “meet with whom?” ® “senior managers,” “meet when?” ® “on Friday,” and so on. It’s as if we are saying that “meet” is the most important, most indispensable, core bit of information here, and the other bits are dependent on it. After all, if it wasn’t for the verb meet, the meeting wouldn’t have taken place and there would be no need in extracting any further information! Similarly, in the expression “board members,” the core bit is “members” as “board” only provides further clarifications (“what type of members?” ® “board”) but without “members” there would be no need in providing this clarifying information. Figure 4.18 visualizes dependencies between words in this sentence, where the arrows explicitly show the direction of relation—they go from the head to the dependent in each pair.

Figure 4.18 Flow of dependencies in “On Friday board members meet with senior managers.” Arrows show the direction of the dependency, from the head to the dependent.
Putting verbs at the root of the whole expression as well as dividing words into groups of more important ones (such words are technically called heads) and the ones that provide additional information depending on the heads (such words are called dependents) is a convention adopted in NLP. The approach to parsing that relies on this idea is therefore called dependency parsing.
Figure 4.12 shows the language-processing pipeline with a number of tools spaCy packs under the hood of nlp. Now it’s time to add one more tool, parser, to the suite (figure 4.19).
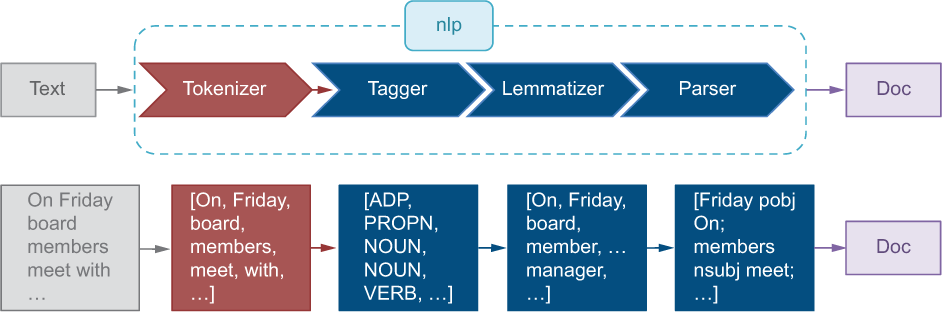
Figure 4.19 A larger suite of spaCy tools
Let’s see how spaCy performs parsing on the sentence “On Friday, board members meet with senior managers to discuss future development of the company.” First, let’s identify all groups of words that may be participants in the meeting event; that is, let’s identify all nouns and words attached to these nouns in this sentence. Such groups of words are called noun phrases because they have nouns as their heads. As before, you start by importing spaCy library and initializing the pipeline. Note, however, that if you are working in the same notebook, you don’t need to do that more than once. Next, you provide the nlp pipeline with input text. You can access groups of words involving nouns with all related words (aka noun phrases) by doc.noun_chunks. Finally, the code shows how to print out the noun phrase itself (e.g., senior managers), followed by the head of the noun phrase (i.e., the head noun, which in this case is managers), the type of relation that links the head noun to the next most important word in the sentence (e.g., pobj relation links managers to meet with), and the next most important word itself (e.g., with). The code in listing 4.5 uses tabulation in this output.
Listing 4.5 Code to identify all groups of nouns and the way they are related to each other
import spacy
nlp = spacy.load("en_core_web_sm") ❶
doc = nlp("On Friday, board members meet with senior managers " +
"to discuss future development of the company.") ❷
for chunk in doc.noun_chunks: ❸
print(' '.join([chunk.text, chunk.root.text, chunk.root.dep_,
chunk.root.head.text])) ❹❶ Start by importing spaCy library and initializing the pipeline.
❷ Provide the nlp pipeline with input text.
❸ You can access noun phrases by doc.noun_chunks.
❹ Print out the phrase, its head, the type of relation to the next most important word, and the word itself.
Let’s discuss these functions one by one:
-
doc.noun_chunks—Returns the noun phrases, the groups of words that have a noun at their core and all the related words. For instance, “senior managers” is one such group here.
-
chunk.text—Prints the original text representation of the noun phrase; for instance “senior managers”.
-
chunk.root.text—Identifies the head noun and prints it out. In “senior managers,” it’s “managers” that is the main word; it’s the root of the whole expression.
-
chunk.root.dep_—Shows what relates the head noun to the rest of the sentence. Which word is “managers” from “senior managers” directly related to? It is the preposition “with” (in “with senior managers”). Within this longer expression, “senior managers” is the object of the preposition, or prepositional object: pobj.
-
chunk.root.head.text—Prints out the word the head noun is attached to. In this case, it is “with” itself.
To test your understanding, try to predict what this code will produce before running it or looking at the following output. The preceding code will identify the following noun phrases in this sentence:
Friday Friday pobj On board members members nsubj meet senior managers managers pobj with future development development dobj discuss the company company pobj of
There are exactly five noun phrases in this sentence: Friday, board members, senior managers, future development, and the company. Figure 4.20 shows the chain of dependencies in this sentence, this time with the relation types assigned to the connecting arrows (see the description of different relation types at https://spacy.io/api/annotation#dependency-parsing and http://mng.bz/1oeV).

Figure 4.20 Chain of dependencies in “board members meet with senior managers to discuss future development of the company.”
In this sentence, “Friday” directly relates to “on”—it’s the prepositional object (pobj) of on. “Board members” has “members” as its head and is directly attached to “meet”—it’s the subject, or the main participant of the action (denoted nsubj). “Senior members” has “members” as its head, and it’s attached to “with” as pobj. “Future development” is a direct object (dobj) of the verb discuss because it answers the question “discuss what?” The head of this noun phrase is “development.” Finally, “the company” has “company” as its head, and it depends on preposition of, thus the relation that links it to of is pobj.
spaCy allows you to visualize the dependency information and actually print the graphs like the ones in figure 4.20. The code from listing 4.6 will allow you to print out the visualization of the dependencies in input text and store it to a file. If you run it on the sentence “Board members meet with senior managers to discuss future development of the company,” this file will contain exactly the graph from figure 4.20. In this code, you rely on the functionality of the spaCy’s visualization tool displacy to visualize dependencies over the input text, where setting the argument jupyter= False tells the program to store the output to an external file, and jupyter=True to display it within the notebook. If you select to store the output to an external file, you’ll need to import Path, which will help you define the location for the file to store the visualization. As the code in listing 4.6 shows, the file the output is stored to simply uses the words from the sentence in its name (e.g., On-Friday-board-...svg); however, you can change the file naming in the code. Alternatively, if you want to display the output directly in the Jupyter Notebook, you set jupyter=True and you don’t need the last three lines of code.
Listing 4.6 Code to visualize the dependency information
from spacy import displacy ❶ from pathlib import Path ❷ svg = displacy.render(doc, style='dep', jupyter=False) ❸ file_name = '-'.join([w.text for w in doc if not w.is_punct]) + ".svg" output_path = Path(file_name) ❹ output_path.open("w", encoding="utf-8").write(svg) ❺
❶ Import spaCy’s visualization tool displaCy.
❷ Path helps you define the location for the file to store the visualization.
❸ Use displaCy to visualize dependencies over the input text with appropriate arguments.
❹ The file the output is stored to simply uses the words from the sentence in its name.
❺ This line writes the output to the specified file.
Note To find out more about the displaCy tool, see https://spacy.io/usage/visualizers.
Why is it useful to know about the noun phrases and the way they are related to the rest of the sentence? It is because this way your algorithm learns about the groups of words, including nouns and attached attributes (i.e., noun phrases), that are potential participants in the action, and it also learns what these noun phrases are themselves attached to. For instance, note that “board members” is linked to “meet” directly—it is the main participant of the action, the subject. “Senior managers” is connected to the preposition “with,” which itself is directly linked to the action verb “meet,” so it would be possible to detect that “senior managers” is the second participant in the action within one small step.
Before we put these components together and identify the participants of the meeting action, let’s iterate through the sentence and print out the relevant information about each word in this sentence. We print the word itself using token.text, the relation that links this word to its head using token.dep_, the head the word depends on using token.head.text, its head’s part of speech using token.head.pos_, and finally all the dependents of the word iterating through the list of dependents extracted using token.children. The code in the following listing shows how you can do this.
Listing 4.7 Code to print out the information about head and dependents for each word
for token in doc:
print(token.text, token.dep_,
token.head.text, token.head.pos_,
[child for child in token.children]) ❶❶ This code assumes that spaCy is imported and input text is already fed into the pipeline.
This code will produce the following output for the sentence “On Friday board members meet with senior managers to discuss future development of the company.”
On prep meet VERB [Friday] Friday pobj On ADP [] , punct meet VERB [] board compound members NOUN [] members nsubj meet VERB [board] meet ROOT meet VERB [On, ,, members, with, discuss, .] ...
This output shows that Friday is the prepositional object of On, which itself has an adposition (ADP) POS tag. Friday doesn’t have any dependents, so an empty list [] is returned. Board is dependent on noun members, but it also has no further dependencies itself. Members is a subject of the verb meet and has board as a single dependent. Meet, in its turn, doesn’t depend on any other word—it’s the ROOT of the whole sentence, and it has a number of dependents, including On (time reference, On Friday), members (head of the subject board members, which is the main participant of the action expressed with the verb meet), with (introducing second participant with senior members), and discuss (indicating the purpose of the meeting, “to discuss the future developments . . .”).
4.5 Building your own information extraction algorithm
Now let’s put all these components together and run your information extractor on a list of sentences to extract only the information about who met with whom. Based on what you’ve done so far, you need to implement the steps outlined in figure 4.21.

Figure 4.21 Extraction of participant1 and participant2 if the action verb is meet.
To summarize, this means that you need to
-
Identify sentences where “meet” is the main verb (i.e., the ROOT of the sentence).
-
Identify participant1 of the action. It will be a noun linked to the verb with nsubj relation.
-
Add all the attributes this noun has (e.g., “board” for “members”) to build a noun phrase (NP). This is participant1.
-
If the verb has a dependent preposition “with” (e.g., “meet with managers”), extract the noun dependent on “with” together with all its attributes. These will constitute participant2.
-
Otherwise, if the verb doesn’t have a preposition “with” attached to it but has a directly related noun (as in “meet managers”), extract this noun and its attributes as participant2. The directly related noun will be attached to the verb with dobj relation.
Now, let’s implement this in Python and apply the code to the sentence “On Friday, board members meet with senior managers to discuss future development of the company.” Note that if you are working in the same notebook and used this sentence as input before, all the processing outputs are stored in container Doc, and you don’t need to redefine it. Since this sentence contains preposition “with,” let’s start with implementing the approach that extracts the noun dependent on “with” together with its attributes and identifies this noun phrase as participant2. Listing 4.8 shows this implementation. The code shown here assumes that spaCy is imported and input text is already fed into the pipeline. First, you check that the ROOT of the sentence is a verb with the base form (lemma) “meet”—this verb expresses the action itself. Next, you extract the list of all dependents of this verb using token.children. To identify participant1 of the action, you look for a noun that is the subject of the action verb linked to it with nsubj relation. This noun, together with its attributes (children), expresses participant1. After that, you check if the verb has preposition “with” as one of its dependents and extract the noun that is dependent on this preposition together with its attributes. This is participant2 of the action. Finally, you print out the results.
Listing 4.8 Code to extract participants of the action
for token in doc: ❶ if (token.lemma_=="meet" and token.pos_=="VERB" and token.dep_=="ROOT"): ❷ action = token.text ❸ children = [child for child in token.children] ❹ participant1 = "" participant2 = "" for child1 in children: if child1.dep_=="nsubj": participant1 = " ".join( [attr.text for attr in child1.children] ) + " " + child1.text ❺ elif child1.text=="with": ❻ action += " " + child1.text child1_children = [child for child in child1.children] for child2 in child1_children: if child2.pos_ == "NOUN": participant2 = " ".join( [attr.text for attr in child2.children] ) + " " + child2.text ❼ print (f"Participant1 = {participant1}") print (f"Action = {action}") print (f"Participant2 = {participant2}") ❽
❶ This code assumes that spaCy is imported and input text is already fed into the pipeline.
❷ Check that the ROOT of the sentence is a verb with the base form (lemma) “meet.”
❸ This verb expresses the action itself.
❹ Extract the list of all dependents of this verb using token.children.
❺ Find the noun that is the subject of the action verb using nsubj relation.
❻ Check if the verb has preposition “with” as one of its dependents.
❼ Extract the noun that is dependent on this preposition together with its attributes.
For the input text “On Friday, board members meet with senior managers to discuss future development of the company,” this code will correctly return the following output:
Participant1 = board members Action = meet with Participant2 = senior managers
However, what if we provide it with more diverse sentences? For example:
-
“Boris Johnson met with the Queen last week.” “Queen” is a proper noun, so its tag is PROPN rather than NOUN. Let’s make sure that proper nouns are also covered by the code. Note that met is the past form of “meet,” and since your algorithm uses lemma (base form) of the word, it will be correctly identified here.
-
“Donald Trump meets the Queen at Buckingham Palace.” Note that “the Queen” is attached to the verb “meet” as dobj. Let’s make sure your code covers this case too.
Listing 4.9 shows how to add these two modifications to the algorithm. First, you provide your code with a diverse set of sentences. Note that all but the last sentence contain the verb “meet” and are relevant for your information extraction algorithm. Then you define a function extract_information to apply all the steps in the information extraction algorithm. Note that the code within this function is very similar to listing 4.8. One of the differences is that it applies to participants expressed with proper nouns (PROPN), as well as common nouns (NOUN). Another modification is that it adds the elif branch that covers the direct object (dobj) case. In the end, you apply extract_information function to each sentence and print out the actions and their participants.
Listing 4.9 Code for information extractor
sentences = ["On Friday, board members meet with senior managers " +
"to discuss future development of the company.",
"Boris Johnson met with the Queen last week.",
"Donald Trump meets the Queen at Buckingham Palace.",
"The two leaders also posed for photographs and " +
"the President talked to reporters."] ❶
def extract_information(doc): ❷
action=""
participant1 = ""
participant2 = ""
for token in doc:
if (token.lemma_=="meet" and token.pos_=="VERB"
and token.dep_=="ROOT"):
action = token.text
children = [child for child in token.children]
for child1 in children:
if child1.dep_=="nsubj":
participant1 = " ".join(
[attr.text for attr in child1.children]
) + " " + child1.text
elif child1.text=="with":
action += " " + child1.text
child1_children = [child for child in child1.children]
for child2 in child1_children:
if (child2.pos_ == "NOUN"
or child2.pos_ == "PROPN"): ❸
participant2 = " ".join(
[attr.text for attr in child2.children]
) + " " + child2.text
elif (child1.dep_=="dobj"
and (child1.pos_ == "NOUN"
or child1.pos_ == "PROPN")): ❹
participant2 = " ".join(
[attr.text for attr in child1.children]
) + " " + child1.text
print (f"Participant1 = {participant1}")
print (f"Action = {action}")
print (f"Participant2 = {participant2}")
for sent in sentences:
print(f"
Sentence = {sent}")
doc = nlp(sent)
extract_information(doc) ❺❶ Provide your code with a diverse set of sentences.
❷ Define a function to apply all the steps in the information extraction algorithm.
❸ Extract participants expressed with proper nouns (PROPN) and common nouns (NOUN).
❹ Add the elif branch that covers the direct object (dobj) case.
❺ Apply extract_information function to each sentence and print out the actions and participants.
The preceding code will identify the following actions and participants in each sentence from the set:
Sentence = On Friday, board members [...] Participant1 = board members Action = meet with Participant2 = senior managers Sentence = Boris Johnson met with [...] Participant1 = Boris Johnson Action = met with Participant2 = the Queen Sentence = Donald Trump meets [...] Participant1 = Donald Trump Action = meets Participant2 = the Queen Sentence = The two leaders also [...] Participant1 = Action = Participant2 =
Note that the code correctly identifies the participants of the meeting event in each case and returns nothing for the last sentence that doesn’t describe a meeting event.
Congratulations! You have built your first information extraction algorithm. Now try to use it in practice.
Summary
-
Information extraction is a useful NLP task that helps you impose structure on fully unstructured information or partially structured information. There are multiple scenarios where this is useful, including answering specific questions based on the information provided in the text, filling in a database with the relevant details extracted from text, extracting structured data for further applications, and so on.
-
To extract the information from raw text, you need to know which bits are relevant to your information need and how they are related to each other. Bits that are relevant for the description of an event consist of the words defining the action and the words defining its participants.
-
Actions, occurrences, and states are typically defined by verbs, and participants are typically defined by nouns. The types of words defined by their typical roles are called parts of speech, and the task addressing identification of word types is called part-of-speech tagging (or POS tagging).
-
Since POS tagging is an essential component of many NLP tasks, NLP libraries and toolkits usually include a POS tagger. An industrial-strength NLP library called spaCy performs many processing operations at once and packs all the tools under a single NLP pipeline.
-
Nouns tend to attach further attributes (e.g., “fast car”). Such groups of nouns with all related attributes are called noun phrases. In addition, nouns that name personalities are called proper nouns, and they often come as a sequence of nouns rather than a single one. Such sequences are also called noun phrases. When you are trying to identify participants of events, it is noun phrases rather than single nouns that you are looking for.
-
Parser helps you identify relations between all words in a sentence. It is an NLP tradition to consider that the core—the root—of the sentence is the verb that denotes the main action the sentence is talking about. Other components of the sentence depend on the verb. Therefore, this approach is called dependency parsing.
-
Within dependency parsing, we are talking about the main words, heads of the expression, and their dependents.
Solutions to miscellaneous exercises
These are quite well-known examples that are widely used in NLP courses to exemplify ambiguity in language and its effect on interpretation.
-
“I” certainly denotes a person, and “can” certainly denotes an action. However, “can” as an action has two potential meanings. It can denote ability “I can” = “I am able to” or the action of putting something in cans (when a word has several meanings, it is called lexical ambiguity). “Fish” can denote an animal as in “freshwater fish” (or a product as in “fish and chips”), or it can denote an action as in “learn to fish.” In combination with the two meanings of can, these can produce two completely different readings of the same sentence: either “I can fish” means “I am able/I know how to fish” or “I put fish in cans.”
-
“I” is a person and “saw” is an action, and “duck” may mean an animal or an action of ducking. In the first case, the sentence means that I saw a duck that belongs to her, while in the second it means that I witnessed how she ducked—once again, completely different meanings of what seems to be the same sentence (figure 4.22)!
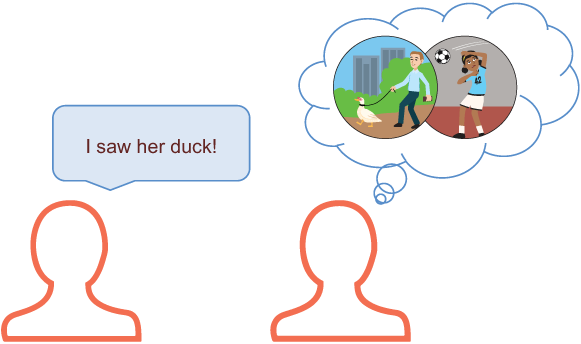
Figure 4.22 Ambiguity might result in some serious misunderstanding.
Try working on your own solution before checking the code on the book’s GitHub page (https://github.com/ekochmar/Getting-Started-with-NLP).
-
In “senior managers,” “managers” is the main bit and “senior” provides further clarification. We ask “What type of managers?” ® “senior,” so “managers” is the head and “senior” is the dependent.
-
In “recently met,” “met” is the main bit and “recently” provides further information about the action. We can ask “Met when?” ® “recently,” so “met” is the head and “recently” is the dependent.
-
In “the government,” “government” is the main bit and “the” tells us that it is some particular government identifiable from the context. “Government” is the head and “the” is the dependent.
-
In “talk to the government,” the overall head is “talk”—this is the action that we start with. “Talk” directly attaches “to,” so “to” is dependent on the head “talk.” “To” in its turn attaches “government,” so “to” is the head and “government” is the dependent in this pair. Finally, as before, “the” is the dependent of the head “government” within the pair of words “the government.” Figure 4.23 visualizes this chain of heads and dependents where the arrows explicitly show the direction of relation as before.

Figure 4.23 The full chain of dependencies in “talk to the government.” Arrows show the direction of the dependency, from the head to the dependent.