
2
Data Fusion Perspectives and Its Role in Information Processing
Otto Kessler and Frank White*
CONTENTS
2.1 Operational Perspective of Fusion
2.1.1 Introduction: Fusion in Command and Control and Decision Processes
2.1.2 History of Fusion in Operations
2.1.3 Automation of Fusion Processes in Operation
2.1.3.1 Automation of Fusion in Operations, the SOSUS Experience
2.1.3.2 Operational Fusion Perspectives
2.1.4 Fusion as an Element of Information Process
2.2 Data Fusion in the Information-Processing Cycle
2.2.1 Functional Model of Data Fusion
2.2.1.1 Joint Directors of Laboratories
2.2.1.2 JDL Data Fusion Subpanel and the JDL Model
2.2.2 Information-Processing Cycle
2.2.2.1 Data Fusion in the Information-Processing Cycle
2.2.2.2 Resource Management in the Information-Processing Cycle
2.2.2.3 Data Mining in the Information-Processing Cycle
2.3 Challenges of Net-Centricity
2.4 Control Paradigm: TRIP Model Implications for Resource Management and Data Fusion
2.4.1 Resource-Management Model
2.4.2 Coupling Resource Management with Data Fusion
2.1 Operational Perspective of Fusion
In the past decade, the word fusion has become familiar in most households. There is “Fusion,” the car; “Fusion,” the cuisine; bottled “Fusion” drinks, cold “Fusion,” and a multitude of other uses of the word, including its being occasionally associated with data and information.* It is this latter domain where fusion may be the most important. The immense changes in the nature of the information environment, driven by rapid evolution in communications technology and the Internet, have made raw data and processed information available to individual humans at a rate and in volumes that are unprecedented. But why is fusion important? Why do we fuse? We fuse because fusion is a means to deal with this glut of readily available data and information that we might organize and present information in ways which are accessible and capable of supporting decisions, even decisions as simple as where to go for dinner.
2.1.1 Introduction: Fusion in Command and Control and Decision Processes
In the context of the information domain, fusion is not a thing or a technology but a way of thinking about the world and the environment that focuses on data and information content relevant to a human and the decisions that must be made. In traditional military usage, it is the means by which data from one or a multiplicity of sensors, along with data or information from a variety of nonsensor sources, can be combined and presented to satisfy a broad range of operational goals. At the simplest level, a sensor system may detect and report aspects of a target or the environment, which when correlated over time may be sufficient to support a decision. For example, a radar system detecting an approaching aircraft can trigger a decision to fire on the aircraft when it is within range. However, even this simple example requires the fusion of a time-series analysis of observations that can then be associated unambiguously with a single object and by some other data (visual observation, lack of an identification-friend or foe [IFF] transponder, additional related and fused data) can be identified as an enemy.
The essence of command and control (C2)1 is humans making timely decisions in the face of uncertainty, and acting on those decisions. This essence has changed little over history, though the information domain and the possibilities for mission success and failure have changed dramatically. Today, with greater dependence on technology, the military goal of detecting, identifying, and tracking targets in support of a decision process involves taking some type of action, which may not be achievable with only a single sensor system. Most tactical decision processes and virtually all operational and strategic C2 decisions require a wide range of sensors and sources. Reaching a decision or an execution objective is unachievable without the benefit of a disciplined fusion process. The role of fusion extends to many diverse nonmilitary domains as well. Data fusion has the highest priority in many homeland security domains (such as maritime domain awareness and border security among others). Medical equipment is reaching a degree of sophistication that diagnosis (traditionally a human fusion process) is based on standard fusion processes to provide quality levels of automation. The growth of fusion awareness across the civil sector is a boon and a challenge to the data fusion community.
2.1.2 History of Fusion in Operations
The modern concept of fusion as a key enabler of C2 decision-making dates to the period between World War I and II. It received recognition and emphasis just before the outbreak of World War II. The Royal Navy, the Admiralty of the United Kingdom, had a worldwide collection process consisting of agents, ship sightings, merchant ship crew debriefing, and other means to attain information,2 all of which had served them well over the span of the empire. However, in the run-up to World War II, the British Admiralty recognized that “no single type of information could, without integration of data from many other sources, provide a sufficiently authoritative picture of what to expect from their enemies”2 and subsequently set up an all-source fusion center, the Operational Intelligence Center (OIC). Many other similar intelligence centers dedicated to multisource fusion followed, including the U.S. Tenth Fleet and R.V. Jones’s Scientific Intelligence apparatus.3 Historically, fusion has been associated with the intelligence cycle and the production of “actionable” intelligence. In fact fusion has often been synonymous with intelligence production. Intelligence “fusion centers” with access to data at multiple levels of security have been and continue to be producers of all-source or, more accurately, multisource intelligence products. This association has been so strong that a cultural conflict has developed over the ownership of the fusion process. Characterizing fusion as the exclusive domain of the intelligence process is too narrow and the continuing political battles are not useful, particularly in today’s environment. The reality is that fusion is fundamental to the way human beings deal with their environment and essential to both intelligence and C2 processes. This essential quality was recognized early in World War II by the British who moved the Convoy Routing section, a C2 component, into the OIC (Intel) to further integrate and fuse intelligence with operational information in support of strategic and tactical planning. This move produced such positive outcomes in the Battle of the Atlantic that even today it is held up as an example of the right way to do fusion. The need to fuse many sources of data in the right way is even more imperative in our modern multilateral environment with the primacy of the global war on terror and homeland security concerns extant not just in the United States but in all the nations of the civilized world. Former special assistant to the director of Central Intelligence Agency (CIA) and vice chairman of the CIA’s National Intelligence Council, Herbert E. Meyer,4 describes intelligence as organized information in his book Real World Intelligence. His definition is very useful in a world where C2 and intelligence distinctions are blurring and the demand for organized information, while at an all time high, continues to increase. It is critical that individuals, government, and military organizations not allow dated patterns of thinking or personal and cultural biases to get in the way of managing information to support fusion and decision processes.
The OIC, the Battle of the Atlantic, and the Battle of Britain are success stories that attest to the value of multisensor/multisource data and information, as is the decades-long struggle against Soviet and Bloc submarine forces during the cold war. Using the OIC as a model, the U.S. and Allied navies established a network of fusion centers that successfully fused traditional intelligence data with operational data, effectively countering a dangerous threat for many years.
Along with the successes, however, military history is replete with examples of the failure of intelligence to provide commanders with the information needed to conduct military operations effectively. In many cases, such as the Japanese attack on Hawaii’s Pearl Harbor and the World War II Battle of the Bulge, the failures began with a breakdown of data and information distribution as well as access. The data and information needed to anticipate the attacks were arguably available from a wide variety of sources but were dispersed over organizational hierarchies, times, and locations, and thus the information was not fused and made available to the total intelligence community and the responsible commanders. In the case of the Battle of the Bulge, for example, ULTRA intercepts and information from other highly sensitive sources—in particular, human intelligence (HUMINT)—were provided to senior echelons of intelligence organizations but not passed to the lower echelons, principally for security reasons (protection of sources and means). At the same time, information obtained by patrols behind enemy lines, through interrogation of prisoners of war, from line-crossers, and via direct observation from frontline U.S. and Allied forces often remained at the local level or was distorted by a lower echelon intelligence officer’s personal bias or judgment. On many of the occasions when locally collected data and information were reported up the chain, the multiple analysts from different commands participating in the chain of fusion and analysis introduced many opportunities for bias, distortion, or simple omission in the intelligence summaries and situation reports delivered to higher headquarters. When these reports were consolidated and forwarded to upper echelon intelligence organizations and command headquarters to be fused with the very sensitive, decoded messages from ULTRA, there was no way to identify the potential errors, biases, or completeness of the reports. In some cases, individuals along the chain simply did not believe the information or intelligence. The process also required too much time to support the evolving tactical situation and resulted in devastating surprises for our forces. These examples illustrate some of the many ways fusion processes can break down and thereby fail to adequately support the decision process. The consequences of these failures are well known to history.
Admiral William O. Studeman, former Deputy Director of Central Intelligence and a strong yet discerning voice for fusion, once told a meeting of the Joint Directors of Laboratories/Data Fusion Subpanel (JDL/DFS) that “the purpose of this fusion capability is to allow some predictive work on what the enemy is doing. The job of the intelligence officer is not to write great history, it is to be as predictive as possible in support of decision making for command.”5 To be predictive requires urgency and speed, and unfortunately much of the fusion production in the past has been forensic or constituted historical documentation. The reasons are complex, as illustrated in the example. Often key data is not accessible and much of what is accessible is not in a form that is readily understood. Sometimes the human analysts simply lack the time or the ability to sort and identify relevant data from a wide variety of sources and fuse it into a useful intelligence product that will be predictive as early in the cycle as possible. While fusion is difficult, making predictions is also risky, which leads to a propensity to “write great history” among risk averse analysts and intelligence officers. Very often failures of both command and intelligence are failures of fusion, and are not confined to the distant past, as reports from the 9/11 Commission6 and the Commission on Weapons of Mass Destruction7 make abundantly clear.
2.1.3 Automation of Fusion Processes in Operation
It is important to remember that fusion is a fundamental human process, as anyone crossing a busy street will quickly become aware. In stepping from the curb, a person must integrate and fuse the input from two visual sensors (roughly 170° of coverage), omni-directional acoustic sensors, olfactory sensors, and tactile as well as vibration sensors. Humans do this very well and most street crossings have happy outcomes because a lot of fusion is occurring. The human mind remains the premier fusion processor; from the emergence of modern humans as a species up to the past 35 years, all fusion was performed exclusively by the human mind, aided occasionally by simple tools such as calculators and overlays. However, in the modern era, a period Daniel Boorstin has characterized as the age of the mechanized observer, raw data is available totally unprocessed and not yet interpreted by a human: “Where before the age of the mechanized observer, there was a tendency for meaning to outrun data, the modern tendency is quite the contrary as we see data outrun meaning.”8 This is a recent phenomenon and, with the amount of data from mechanized observers increasing exponentially, the sheer volume of data and information is overwhelming the human capacity to even sort the incoming flow, much less to organize and fuse it.
The terms data and information are often used interchangeably. This is not surprising particularly since the terms are used this way in operational practice, still it can be disconcerting. It is wise to avoid becoming embroiled in circular semantic arguments on this matter, for very often, one person’s information is another’s data and there is no absolute definition of either term. Knowledge is another loaded word in military and fusion parlance. Several definitions of data and information have been used over the years, such as information is data with context or information is data that is relevant over some definable period of time. Both of these provide useful distinctions (relevance, time, and context). In addition, the business community has developed a set of definitions that are practical:
Data is a set of discrete, objective facts—often about events.
Information is a message that is intended to inform someone. Information is built from data through a value-adding transformation. This may be, for example, categorizing or placing in context.
Knowledge is a fluid mix of framed experience, values, contextual information, and expert insight that provides a framework for evaluating and incorporating new experiences and information. It originates and is applied in the knowers’ minds. It is built from information through a value-adding transformation. This may be, for example, comparison with other situations, consideration of consequences and connections, or discussion with others.9
The automation of fusion functions is imperative but at the same time is very new and proving to be difficult, even though the concept of fusion is a very ancient capability. Conversely the automation of sensors has been relatively easy and there is no indication this trend will be slowing with the introduction of micro- and nanotechnologies and swarms of sensors. The automation of fusion processes is falling further behind.
The process of automating some fusion functions began in late 1960s with the operational introduction of automated radar processing and track formation algorithms, and the introduction of localization algorithms into sound surveillance system (SOSUS) and the high frequency direction finding (HFDF) systems. The first tracker/correlator (a Kalman filter) was introduced into operational use in 1970. These first introductions were followed with rapid improvement and automation of basic correlation and tracking functions in many systems; their impact has been widespread and substantial. Automation has greatly speeded up the ingestion, processing, and production of all types of time-series sensor system data and provided timely reporting of what have become vast volumes of sensor reports.
2.1.3.1 Automation of Fusion in Operations, the SOSUS Experience
As every problem solved creates a new problem, the introduction of automated functions has added new dimensions of difficulty to the fusion equation. Analysts may no longer have to spend as much time sorting raw data but they now receive automated reports from trackers where the underlying fusion processes are not explicit and the analysts and operators are not trained to understand how the processes work. Thus, they may not be able to recognize and correct clear errors nor are they able to apply variable confidence metrics to the output products. For example, the SOSUS multisensor localizer (MSL) algorithms provided a statistically significant localization and confidence ellipse with the use of concurrent bearing and time-measurement reports from multiple sensors. This was demonstrably faster and better than the manual methods, creating a statistically significant confidence ellipse. The localization ellipse was an improvement over the manual process that generated an awkward polygon with a variable number of sides that prosecuting forces had to search. The automated product was simpler to understand and reduced the size of the search area the forces had to deal with. However, the humans generating the report still associated measurement reports with a new or existing submarine contact, basing the association on the contact’s previous location and acoustic signature. The automated function made it much more difficult to identify mis-associations and thus the SOSUS products contained more association errors. Still, the benefits of automation outweighed the problems by a wide margin.
Upon its introduction into SOSUS, the multisensor tracker (MST) greatly improved the use of the confidence values from individual sensor reports of bearing and time than did the occasional individual localizations, even though they were generated from the identical series of reports. In addition, the many nonconcurrent measurements could be used to maintain and even improve a continuous track. The error ellipses of the same statistical significance were often orders of magnitude smaller than those of the individual localizations, a great boon to the prosecuting forces. On the downside, mis-associations had a disastrous effect on the tracker that was difficult to identify initially. Further, when a submarine or surface contact maneuvered, the tracker’s motion model assumptions drove the tracker for some period with increasing residual error until it began to catch up with the maneuver. Compounding the difficulty, a submarine on patrol, maneuvering randomly, deviated so far from the underlying motion model that the MST was rendered useless.
Nevertheless, the value of automation in this case was so profound that developers and operators worked together diligently to resolve the problems. The developers modified the software to expose the residual errors for every measurement association that greatly facilitated finding and correcting mis-associations. The developers also introduced alternate motion models and built in the ability to interrupt the tracker and run multiple recursive iterations when required. This ability became an additional analysis tool for predicting submarine behavior. The analysts and operators, for their part, took courses to learn the underlying theory and mathematics of the combinatoric algorithms and the Kalman filter tracker. This training armed them to recognize problems with the automation and further allowed them to recognize anomalies that were not problems with automated tools but interesting behaviors of submarines and other target vessels.
This automation good news story did not last, however. The next developer (new contract) did not expose residual errors and took the algorithm “tuning” and iteration controls away from the operator/analysts. At the same time the operators and analysts stopped receiving any training on the automated tools beyond simple buttonology. In short order, the automation became a fully trusted but not understood “black box” with the tracker output generated and disseminated with little or no oversight from the human. Informal studies and observation of operational practice revealed that obvious errors of mis-association and model violation were unrecognized by the operators and that error-full reports were routinely generated and promulgated. Despite obstacles and set-backs in the incorporation of automation, when used under the oversight of trained humans, automation produces much better results at an exponentially faster and more accurate rate than human analysis alone. Better integration of the automated processes with the human is a continual requirement for improving overall fusion performance.
2.1.3.2 Operational Fusion Perspectives
The SOSUS experience illustrates the potential advantages and disadvantages of introducing automated fusion processes into operational use. The operators and analysts—in fact, all users—must be fully cognizant of what automation can do for and, perhaps most importantly, to an individual or project. Captain W. Walls, the first Commander of the PACOM Joint Intelligence Center and a fusion-savvy individual, once stated that to develop a successful fusion process (automated or manual) all of the following are required:10
Knowledge and understanding of the physics of the sensor/collector and the phenomena being observed
Knowledge and understanding of data fusion processes in general and the approaches being applied to this problem
Knowledge and understanding of the warfare mission area
Knowledge and understanding of the customer/user, his/her information needs, decision processes, etc.
Although it is impossible for any individual to possess all the requisite knowledge and understanding, it is important to have it available to the process. In the past, this was accomplished by colocating as much of the expertise and resources as possible, the OIC being an excellent example. Modern information technology offers promising ways to accomplish colocation within a networked enterprise, and the potential impact of new information concepts on fusion will be a consistent theme throughout this chapter.
Historical examples of fusion automation are instructive, many of them illustrating great success or great failure, some even wonderfully amusing. The overwhelming message is that while automating multisensor fusion processes is essential, it is difficult and must be undertaken with care. It is important to remember Captain Wall’s four elements. They provide a good high-level checklist for any fusion endeavor, particularly one that intends to automate a functional component of a fusion process. Approaches that are purely technical or exclusively engineering will likely fail.
2.1.4 Fusion as an Element of Information Process
An additional lesson to be taken from the operational experience of fusion and attempts to automate its processes is that the notion that somehow a fully automated system will “solve” the data fusion problem must be abandoned. Data fusion is an integral part of all our systems, from the simplest sensor and weapons systems to the most complicated, large-scale information-processing systems. No single fusion algorithm, process capability, system or system of systems will “solve” the problem. Operational experience, experimentation, and testing all confirm that there is no “golden algorithm”—it is an expensive myth. Further, we should desist from building fusion systems and rather focus on building fusion capabilities into systems or, better still, developing fusion capabilities as services in a networked enterprise that presents new challenges and opportunities.
The examples presented and the lessons of operational fusion experience, while confirming the importance and central role of fusion processes, also make clear that fusion is only part of an overall information process that includes data strategy issues, and data mining and resource management. Fusion is first and foremost dependent on the existence of data and information of known quality from sensors and multiple sources. Fusion processes must then have the ability to access the data and information whether from data streams themselves, from various databases and repositories, or through network subscriptions. The precise mechanisms for access are less important than the fact that mechanisms exist and are known or can be discovered. Means of gaining access to and defining known quality of data and information are important and complex issues, and they constitute the subject of many current research efforts. Although many sensors and sources are potential contributors to fusion, their ability to contribute depends on how they exploit the phenomena, what they are able to measure, what and how they report, and how capable they are of operating in a collaborative network environment.
Also, data fusion is essentially a deductive process dependent on a priori models (even if only in the analyst’s mind) that form the basis for deducing the presence of an object or relationship from the data. In the World War II examples, analysts had to rapidly develop models of U-boat behavior and communications patterns; in cold war operations, an immense set of models evolved through collection and observation of our principal opponents over many years. However, in the post–cold war era, very few models exist on opponent behavior or even basic characteristics and performance of opponent’s equipment; because such behavior is dynamic and unpredictable, pattern discovery and rapid model development, and validation (a process called data mining) are essential. The fusion process provides a measure of what we know and, by extension, what we do not know. Therefore, a properly structured information environment would couple fusion with resource management to provide specific collection guidance to sensing assets and information sources, with the aim of reducing levels of ignorance and uncertainty. All these processes—data and information access, fusion, mining and resource management—are mutually dependent. Fusion is no more or less important than any other, although it can be argued that access to data is the sine qua non for all higher-level information processes. The remaining sections of this chapter explore these processes, their functionality, their relationships, and the emerging information issues.
2.2 Data Fusion in the Information-Processing Cycle
Information, by any definition, represents the set of collated facts about a topic, object, or event. For military activity, as for business and routine human interactions, information is an essential commodity to support decision making at every level of command and every aspect of activity planning, monitoring, and execution. Data fusion, as we shall soon see, has been described as a process that continuously transforms data from multiple sources into information concerning individual objects and events; current and potential future situations; and vulnerabilities and opportunities to friendly, enemy, and neutral forces.11 The JDL defines data fusion as follows:
Data fusion. A process dealing with the association, correlation, and combination of data and information from single and multiple sources to achieve refined position and identity estimates, and complete and timely assessments of situations and threats, and their significance. The process is characterized by continuous refinements of estimates, assessments and the evaluation for the need of additional sources, or modification of the process itself, to achieve improved results.
Definitions continue to evolve and, although the original has been legitimately criticized as too long and not just a definition but a definition and a modifier, it still captures the essence of fusion as a purposeful, iterative estimation process. Indeed, data fusion is an essential, enabling process to organize, combine, and interpret data and information from various sensors and sources (e.g., databases, reports) that may contain a number of objects and events, conflicting reports, cluttered backgrounds, degrees of error, deception, and ambiguities about events or behaviors. The significance of data fusion as a process to minimize uncertainty in information content can be measured in department of defense (DoD) circles by the large number of research and acquisition programs devoted to building fusion capability for specific platform and sensor combinations to achieve specified mission goals. A survey conducted in 2000 identified over 60 data fusion algorithms in operational usage alone.12
Despite the attention, and investment, devoted to the data fusion process, it is important to keep in mind that fusion is only one element of a set of enabling processes all of which are necessary to produce information relevant to a particular problem or decision. Fusion, along with the other elements—resource management, data mining, and an enabling information environment—are all essential elements in an overall cycle we call the information-processing cycle (IPC). How these elements have been identified and characterized and the importance of ensuring their integration will constitute the bulk of this chapter.
2.2.1 Functional Model of Data Fusion
The thinking that led to the recognition of the IPC and its elements grew out of a progression of functional models, beginning with the JDL data fusion model. Functional models have proven useful in systems engineering by providing visualization of a framework for partitioning and relating functions and serving as a checklist for functions a system should provide. In systems engineering, they are only a single step in a many step process. In this progression, a functional model lays out functions and relationships in a generic context whereas a process or process flow model performs a selection and mapping of functions, including inputs and outputs in a specific way to meet a particular goal. A design model goes deeper, utilizing the process model then taking the additional step of specifying what methods and techniques will be used. It is important to be cautious when using these models and to understand the limitations of each model type; in particular, using a functional model as a design specification is inappropriate. Process flows, system design models, and specifications are developed for application to a specific problem or set of problems.
2.2.1.1 Joint Directors of Laboratories
This chapter introduces fusion from an operational perspective and addresses its place as a central function in a broader information-processing structure, supporting decision making at all levels. As also discussed, data and information fusion are immature and complex disciplines. The level of immaturity did not become widely recognized until the early and mid-1980s when many acquisition programs and research projects throughout DoD and the broader intelligence community were established to perform sensor, fusion, data fusion, correlation, association, etc. The JDL model and surveys contributed to this awareness and led to a unification of the fusion community through the creation of the JDL.*
2.2.1.2 JDL Data Fusion Subpanel and the JDL Model
Upon the establishment of the JDL/DFS by the JDL in 1984, the growing recognition of the central role of fusion in intelligence and C2 processes had led to a broad but unstructured collection of individuals, programs, and projects with interest in fusion matters but no mechanisms for finding each other or establishing common ground. The Data Fusion Subpanel, later renamed the Data Fusion Group (DFG), recognized the immaturity of the fusion discipline and suggested that the creation of a community with common interests would help speed the maturation process. To begin, the DFS established a common frame of reference by developing a taxonomy and lexicon to bring discipline to the definition of terms and usage. The definition presented in Section 2.2 was from the original lexicon and captures the essence of fusion as a purposeful, iterative estimation process. The DFS also created a visual representation of the fusion process, a functional model of the data, and an information fusion domain to develop a framework for a common understanding of fusion processes. The original JDL model, shown in Figure 2.1, provided a common understanding of fusion that facilitated the creation of a fusion community providing guidance to theoreticians, field users, and developers. The model also made possible the partitioning of functions for organizing surveys of community development practices, research programs, and system development. Surveys based on the original JDL model, for example, exposed the lack of fielded level 2/3 fusion capability and a corresponding paucity of research in the domain leading to a redirection of critical research and development (R&D) resources. The model has been accepted nationally and internationally and is still in widespread use. Evolved versions and extensions of the model are having continuing utility as fusion, resource management and data mining functionality advances, and the implications of modern information services, architectures, and network-enabled environments are being appreciated.
The JDL/DFG has organized fusion into five levels as follows:
Level 0: Source preprocessing/subobject refinement. Preconditioning data to correct biases, perform spatial and temporal alignment, and standardize inputs.

FIGURE 2.1
Joint Directors of Laboratories data fusion model.
Level 1: Object refinement. Association of data (including products of prior fusion) to estimate an object or entity’s position, kinematics, or attributes (including identity).
Level 2: Situation refinement. Aggregation of objects/events to perform relational analysis and estimation of their relationships in the context of the operational environment (e.g., force structure, network participation, and dependencies).
Level 3: Impact assessment. Projection of the current situation to perform event prediction, threat intent estimation, own force vulnerability, and consequence analysis. Routinely used as the basis for actionable information.
Level 4: Process refinement. Evaluation of the ongoing fusion process to provide user advisories and adaptive fusion control or to request additional sensor/source data.
2.2.1.3 Use of JDL Model
The JDL model as it is currently represented focuses exclusively on the fusion domain and thus has contributed to the misperception that fusion could be an independent process. Practically speaking, in operations, fusion never stands alone nor does it theoretically make sense from an information-processing perspective. Another shortcoming of the JDL model is that the human role in the process is not represented except as an interface. These two aspects have had unintended consequences, including inter alia army and navy attempts to build centralized fusion processes as monolithic, stand-alone systems, attempts which have been largely, and not surprisingly, unsuccessful. With regard to the human role, The Technical Cooperation Program’s (TTCP) technical panel for information fusion, in particular, Lambert, Wark, Bosse, and Roy have pointed out that the JDL model provides no way of explicitly tying automated data fusion processes to the perceptual and cognitive needs of the decision-makers, the individuals the automation is expected to support. This is a serious deficiency in the model, one that needs to be addressed. More valuable discussion on this topic is available in Bosse et al.’s 2007 book Concepts, Models, and Tools for Information Fusion.13
As the model is applied, useful modifications, iterations, and implications continue to be debated in numerous fusion community forums. One area of discussion concerns whether the model usefully represents a potential system design. The model’s creators never intended for the model to be used in this way. The diagrammatic arrangement of the levels and the nomenclature used were not intended to imply a hierarchy, a linearity of processes, or even a process flow. The term level may have been a poor choice because it can be seen to imply a sequential nature of this process. Although a hierarchical sequence often emerges, parallel processing of these subprocesses and level skipping can and does take place. The model is still useful, for the levels serve as a convenient categorization of data fusion functions and it does provide a framework for understanding technological capability, the role fusion plays, and the stages of support for human decision making. In information or decision support applications, the model can serve to partition functions and as a checklist for identifying fusion capabilities that are essential to the implementation of mechanisms for aiding decision makers in military or complex civil environments.
Automation of fusion solutions must account for complexity not illustrated in the model and address the issues of incorporating the human as an integral part of the fusion process. In developing a system design for the automation of fusion functions or subfunctions, process flows and design specifications must be selected and engineered by the systems design engineers. The model should serve only as a checklist.
Many chapters in this edition of the Handbook of Multisensor Data Fusion will reference the JDL model, taxonomy, and lexicon, including the model’s utility or deficiencies in system design. Much of the evolution of the model, taxonomy, and lexicon will be discussed and the healthy controversies that have accompanied the evolutionary process will be exposed in the succeeding chapters.
2.2.2 Information-Processing Cycle
To reiterate from Section 2.1, fusion is a fundamental human process and, as an automated or manual process, occurs in some form at all echelons from rudimentary sensor processing to the highest levels of decision making. Fusion is such a foundational process that it is linked or integrated to myriad other processes involved in decision making. Fusion by itself makes no sense; it is a tool, an enabler that is useful only as an element of a larger information process, an IPC.
In its most basic form, an IPC must transform a decision-maker’s information needs through the processes and mechanisms that will create information to satisfy those needs. Elements of the IPC include (a) resource management to translate decision-maker information needs to the real-world devices (sensors, databases, etc.) that will produce data relevant to the stated needs and (b) data fusion to aggregate that data in a way that satisfies the decision maker. These relationships are illustrated in Figure 2.2. The benefits of coupling these elements and the related issues will be discussed in Section 2.4.
Since the raw material for fusion processes is data from sensors and information from multiple sources, we must recognize that orchestrating the collection of required data with appropriate sensing modalities, or data and information from appropriate (possibly archival) sources, is an essential element of the larger information process. Such orchestration of sensors and identification of sources to produce relevant input for a given fusion process is often referred to as resource management. The resources are the technical means (e.g., sensors, platforms, raw signal processing) as well as archived data and human reporting employed to gather essential data. The function of resource management is fundamentally one of control, and should be distinguished from the essential role of data fusion, which is to perform estimation. In control theory, the mathematical relationship between control and estimation is understood and expressed mathematically as a duality. In more general information processes that are the means to develop relevant information of significance for human decision making, a comparable complementary relationship of data fusion and resource management can be recognized in achieving the goal of decision quality information. This relationship is neither well understood nor does it have the mathematical underpinnings of a duality. The resource-management process, like fusion, has been a manual process traditionally broken into collection requirements management (coupled to decision-maker’s needs) and a collection-management process that plans and executes sensor and source collection. In practice, the processes are often only loosely coupled and too often completely independent of the fusion process. Like fusion, the exponential increase in the number of sensors, sensor data, and information sources requires some level of automation in the resource-management process.

FIGURE 2.2
Basic information-processing cycle.
For environments in which behavior of the sensing resources, their interaction with the real world, and the interpretation of observations is well understood, these elements are sufficient. Such understanding provides the basis for modeling the underlying resource-management and fusion processes with sufficient fidelity to produce satisfying results. Under conditions where real-world behaviors, or the related observations, are not understood, an additional information-processing element is required. That element is a data mining process to discover previously unknown models of activity or behavior. Data mining complements resource-management and data fusion processes by monitoring available data to identify new models of activity. Those newly derived models are used to update fusion and resource-management processes and to maintain their validity. Such a process of discovery, model creation, update, and validation is necessary for processes and algorithms that operate under conditions of incomplete understanding or problem space dynamics.
The following sections provide an overview of the roles of the three major information-processing elements: data fusion, resource management, and data mining. The overviews discuss the elements in relation to each other and in the context of the driving concept underlying the transformation of military and commercial information technology—network-centric operations.
A consideration of emerging notions of net-centricity and enterprise concepts is important because, independent of the particulars of enterprise implementation, future fusion algorithms will have access to increasing volumes and diversity of data, and in turn, increasing numbers and types of users will have access to algorithmic products. Net-centric enterprises must become sensitive to both appropriate use and aversion to misuse of data and products. Arbitrary access to sensor and source data, and to algorithmic products, requires a discipline for characterizing data and products in a manner that is transferable among machines and usable by humans. The characterization of sensors and algorithms provides the context necessary to support proper interpretation by downstream processes and users. Such context was naturally built into traditional platform-based systems as a result of systems engineering and integration activity, which typically entailed years of effort, and resulted in highly constrained and tightly coupled (albeit effective) solutions. In net-centric enterprise environments the necessary discipline will likely be captured in metadata (sensor/source characterization) and pedigree (process characterization and traceability) as an integral part of the IPC. The discipline for executing that role has not yet been established but is being addressed within a number of developmental efforts; some of these issues are further discussed in Section 2.3.
2.2.2.1 Data Fusion in the Information-Processing Cycle
As noted in the preceding text, the role of data fusion in information processing is to aggregate raw data in a way that satisfies the decision-maker’s information needs, that is, to minimize the user’s uncertainty of information. Data fusion is a composition process that leverages multiple sources of data to derive optimal estimates of objects, situations, and threats. The process involves continual refinement of hypotheses or inferences about real-world events. The sources of data may be quite diverse, including sensor observations, data regarding capability (e.g., forces, individuals, equipment), physical environment (e.g., topography, weather, trafficability, roads, structures), cultural environment (e.g., familial, social, political, religious connections), informational environment (e.g., financial, communications, economic networks), and doctrine as well as policy. Data fusion provides the means to reason about such data with the objective of deriving information about objects, events, behaviors, and intentions that are relevant to each decision-maker’s operational context. Users or decision-makers’ need can be characterized in many ways; this chapter often addresses operational and tactical decision makers. The fusion process applies at all echelons, however, and information needs can be long-standing requirements established by strategic, intelligence, or National Command Authority (NCA) components. In the modern environment, multiple decision makers must be satisfied in near-simultaneous, asynchronous fashion. Fusion processes that perform these functions are described in detail throughout this handbook.
Section 2.2.1.1 introduced a functional model of fusion that provides a framework for partitioning more detailed fusion roles and technology solutions. The current practice in algorithm development is to incorporate models of phenomenology and behavior as the basis for accumulating evidence (e.g., observational data) to confirm or discount objective hypotheses. Representation of the model basis for each fusion algorithm (along with key design assumptions that are not currently exposed) will need to be a part of the algorithm characterization. Capturing such meta-information in the form of metadata or pedigree will provide the basis for net-centric enterprise management of information processing that will likely engage combinations of similar and diverse algorithms. Section 2.3 describes related net-centric implications that will drive the need for stronger, more robust fusion algorithm development. It is apparent that the net-centric environment will enhance sharing of common contextual information (e.g., models, metrics, assumptions), given the interdependence of data fusion and resource-management processes in the IPC.
2.2.2.2 Resource Management in the Information-Processing Cycle
Automated resource management has been addressed in military and commercial environments with considerable effectiveness. Credit for success in the field is more a consequence of well-structured manual procedures than of automation technology.14 The scale of investment (judged qualitatively) has not matched that underpinning data fusion development. As a result, representation of resource-management processes and functionality is less mature than equivalent data fusion representations. The following section provides a summary discussion of current perceptions and practices within the discipline.
The role of resource management is to transform decision-maker’s information needs to affect real-world actions in a manner that produces data and information that will satisfy those needs—in short, to maximize the value of data and information that is gathered. Resource management is a decomposition process that breaks down information needs (or requests) into constituent parts that include method selection, task definition, and plan development. These stages correspond to the levels of fusion as identified in the JDL data fusion model (Section 2.2.1) and are shown in an extension of the functional model in Figure 2.3. This extension illustrates fusion in a much broader and more realistic information framework, a representation that is instructive because it reveals mutual dependencies. The extended model can also serve as a checklist for identifying and partitioning functions required in specifying process flows and design parameters in engineering a specific application. Also evident in the figure is the central importance of context in capturing attributes of the processing cycle that must be shared among all process elements to achieve consistency across the IPC.
Attributes of the IPC that provide context for maintaining performance include the models that underpin algorithm design, the metadata required to characterize sensors and sources, and the pedigree needed to explain (and couple) data collection purposes to the exploitation processes invoked to transform that data into usable information. Other attributes, such as metrics, may also be identified as enablers of processing cycle consistency. Notions of models include representations of the platforms, the sensors, and the real-world phenomenology they observe. Algorithms designed for all stages of decomposition (resource management) and composition (data fusion) functions are based on such models. It is clear that shared model can be used and understanding is required to “close the loop” in the IPC and maintain focus on meeting decision-maker’s needs. Similarly the use of pedigree and metadata provide mechanisms for relating resource-management goals to sensor characteristics and, in turn, the exploitation required of data fusion processes. Proper use of pedigree and metadata can inform downstream processes of their role, provide traceability or accountability of system performance, and support explanation of automated results as needed by decision makers.

FIGURE 2.3
An information framework.
This model also highlights the issues of information access, the need for a unifying information infrastructure discipline, the parallelism of the composition and decomposition processes, the information content management, and the retention of context throughout the process.
Section 2.4 provides a more detailed discussion of the parallels between data fusion and resource-management functionality. The following provides a brief discussion of the functional role and significance of the resource-management stages. As with the fusion model, the discussion describes functional relationships and is not intended to constrain architectural or design options.
Information needs. Reflects the commander’s intent in the context of mission goals and priorities, through a statement of the situation and conditions that are expected to provide key indicators of adversary actions or own force progress. Such needs are generally characterized by coarse specification of space and time constraints on objects, events, and activities deemed to be of particular importance. Indicators are generally expressed in operational terms, independent of phenomenology.
Collection objectives. Defines focused goals for collection of data relevant to the indicators (entities, events, activities) determined to be important for mission success. These objectives reflect offensive and defensive mission goals, priorities, and external influences that may impact mission accomplishment. Space and time constraints identified by commander’s information needs are made more specific to meet mission coordination needs.
Observables. Derives the set of possible observables that may be available from specified indicators to meet the collection objectives. In some cases more than one sensor, or sensing modality, will be required to achieve the necessary performance. Provides options for meeting objectives among available sensors as a function of sensing phenomenology, associated signatures, and quality of measurement for the expected conditions.
Tasks and plans. Selects the most suitable sensor or source (or combination if appropriate) for collection of desired observables by location, geometry, time, and time interval. This also provides executable tasks for specified sensors/sources, and includes development of plans for optimized allocation of tasks to designated platforms to maximize value of data collected, while minimizing cost and risk.
2.2.2.3 Data Mining in the Information-Processing Cycle
Successful fusion processing, and particularly automated fusion, depends on the existence of a priori information, patterns, and models of behavior, without which it is difficult to predict potential hostile courses of action with any degree of confidence. Regardless of how well or poorly we have performed data fusion and resource management in the past, it is clear that we no longer have the long-term observation and analysis of our opponents on which to base the models underlying fusion and collection processes. For example, current homeland security operations lack patterns for counterterror and counternarcotics activities and the troops in Iraq and Afghanistan face an insurgency for which there are no preexisting models. Our level of success is correspondingly low in these situations. This will remain a problem, for in these domains complete knowledge of a comprehensive set of threatening entities, behaviors, and activities, which are always changing, will elude us. One of the central challenges associated with future operations of all types, from combat operations to humanitarian operations, is to discover previously unknown behaviors based on signatures, and indicators buried in immense volumes of data. A new set of functions will be required that enable behavior and pattern discovery as well as rapid model construction and validation. Data mining is becoming the focus of research on many fronts.
As an automated process, data mining is relatively immature, although the practice, particularly in the hands of analysts, has a long history. Data mining has been described as Discovery of previously unrecognized patterns in data (new knowledge about characteristics of an unknown pattern class) by searching for patterns (relationships in data) that are in some sense interesting.15
As we have noted earlier, current data fusion and resource-management practice are model-based. Data mining provides the means for maintaining the currency of those models in dynamic or poorly understood environments. Its role therefore is to identify new models of activity or relationships, or significant variation in existing models. These updates serve to alert users, to provide resource management with new objective opportunity for data collection, and to update the models employed in data fusion processes. This extension of the basic IPC is represented in Figure 2.4.
From the perspective of the evolving functional model it is important to distinguish between the terms data fusion and data mining. Unfortunately, the terms are often used interchangeably or to describe similar processes. In reality, they represent two distinct, complementary processes. Data fusion focuses on the detection of entities and relationships by deductive reasoning using previously known models. Data mining, however, focuses on the discovery of new models that represent meaningful entities and relationships; it does this by using abductive and inductive reasoning to discover previously unknown patterns. The process then uses inductive generalization from particular cases observed in the data to create new models. Since data mining is a complementary function, to fusion it is also part of the broader IPC and can be included in the functional model as shown in Figure 2.5. Some stages of data mining appear to parallel the levels identified in data fusion and resource management: multidimensional analyses, entity relationships, and behavior models.
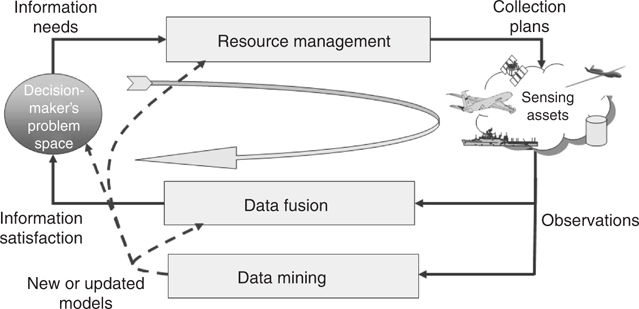
FIGURE 2.4
Extended information-processing cycle.

FIGURE 2.5
Extended information environment.
The addition of the data mining functionality provides additional insight into the overall information process, reinforcing the dependencies of resource-management and fusion processes, and calling attention to the importance of the integration of data fusion and data mining for future applications since they are mutually dependent. This representation of data mining also reinforces the centrality of common context (including models, pedigree, etc.) and emphasizes the fact that these critical functions are necessary for effective performance of an integrated information infrastructure optimized to support all aspects of the IPC. The development of such an integrated information infrastructure will be very complex but is within the realm of possibility in today’s modern information environment and the promise of net-centric operations.
2.2.3 Human Role
The implication of net-centric operations involves the need for a high degree of automation to perform a large number of functions now performed by humans (e.g., platform/sensor routing, sensor scheduling, mode control, data tagging, low-level analysis). The complexity envisioned for any network enterprise and the obvious requirement for parallel processing, speed of response, and rapid adjudication of needs across multiple nodes and users suggest that processing by humans will be inappropriate for many roles in a fully evolved net-centric environment. Humans will have to interact with automated capabilities to provide supervision and confirmation of critical information products. The difficulty of assessing the appropriate degree of automation and the appropriate mechanisms to interface automated products with humans (i.e., to achieve human–machine collaboration), creates a challenge that calls for implementation of a coevolutionary process (interactive development of technology with tactics, techniques, and procedures) with an emphasis on experimentation to properly introduce and integrate technology that enhances rather than inhibits the human user and creates an advanced and integrated capability.
2.3 Challenges of Net-Centricity
Net-centric environments hold great potential to provide an enabling infrastructure for implementing the information process flow and related algorithms, which are needed to support decision makers at distributed nodes of the military or commercial enterprises. The movement to net-centric operations, built on an underlying service-oriented architecture (SOA), is mandated for the military by DoD16 and could provide distinct advantages for fielding an improved information-processing capability. This section addresses some of the implications of net-centricity for fusion (and other) algorithm design and implementation.
It is recognized by analysts in the field that the state of net-centric development and fielding, particularly for military environments, is very much in the embryonic state. Much of the effort to date has addressed net-centric infrastructure issues, including the difficult challenges of security and transport in the wireless environments that dominate military situations. Infrastructure development has focused on addressing enterprise services (see for instance net-centric enterprise services (NCES) description of required services17), service architectures and types, computing, and enterprise service bus issues. These efforts are concerned with how the volume of data will be moved timely across the network, and with the general functions necessary to manage that data flow. Less attention has been paid to content and management of information to support specific mission goals, independent of time and location. The details of what data and information will be moved and processed lie above the infrastructure layers and grouped into what is often referred to as application services. The issue for fusion algorithm designers is to anticipate the unique demands that net-centricity will place on design practice and to take advantage of the opportunities created by a new and different system engineering environment, so that fusion algorithms are properly configured to operate in net-centric environments. Given the immature state of net-centric development it is important to anticipate the implications for algorithm design practice and to participate in the evolution of net-centric system engineering practices.
2.3.1 Motivation
In the DoD, the issuance of a mandate for net-centricity signals a recognition of the importance of information as the foundation for successful military activities and missions. The mandate is driven by a desire to achieve multiple key benefits, which include increased affordability, reduced manpower, improved interoperability, and ease of integration, adaptability, and composability. The goals stated for enabling these gains are to make data and information visible, accessible, and understandable. Clearly, to attain these goals will require significant effort beyond the scope of fusion algorithm design but will nevertheless benefit from also considering the impact that current fusion algorithms provide in support of this endeavor. For any existing fusion algorithm we might ask, “Does it satisfy the goal of making its data and information visible, accessible, and understandable?” Taking the perspective of an average user, and without quibbling over the definition of terms, we might attempt to answer the following sample questions: Is the algorithm product understandable without knowledge of the context for which it was specifically designed? Are the constraints or assumptions under which the algorithm performs visible or accessible? Are the sensor data types, for which the algorithm was designed, made obvious (visible, accessible, or understandable)? Is the error representation of the information product either accessible or understandable? Is the error model of the data input (whether provided by the source or assumed) visible, accessible, or understandable? Given appropriate connectivity, could a remote user (with no prior involvement) invoke it and understand its capability, limitations, and performance? Can the algorithm’s information product (for specific areas or entities) be compared with a competitive algorithm’s product without ambiguity? Does the algorithm provide an indication (visible or understandable) when it is broken? For the preponderance of extant fusion algorithms, the answers to these questions will be negative. One or more negative answers provide a clear indication that algorithm design must evolve to satisfy net-centric goals.
2.3.2 Net-Centric Environment
The implementation of algorithms in net-centric environments includes benefits of modularity, and common information-processing discipline. Modularity is a natural consequence of the vision of net-centric operations. Net-centricity incorporates a SOA framework, with open standards and common data strategy (e.g., data model, data store control, information flow) accompanying a defined enterprise infrastructure and enterprise services (e.g., security, discovery, messaging) that provide the high-level functional management of a layered enterprise structure. The technical view of this layered enterprise infrastructure provides a plug-and-play environment for various applications, as shown in Figure 2.6. The figure suggests that the infrastructure, in combination with selected applications, will support desired mission capability; it also suggests that a common infrastructure will enable selection of a set of applications to support execution of multiple missions.

FIGURE 2.6
Technical view of net-centric enterprise structure.

FIGURE 2.7
Layered technical view of functionality within a networked enterprise.
A functional view of the overall enterprise is provided in Figure 2.7. The layers correspond to significant functional partitions such as sensors, transport, security, enterprise services, applications, and others. Within the application layer, fusion algorithms of various types, as well as other elements of the IPC (e.g., resource-management and data mining algorithms), may be provided as building blocks or modules. Analysis functions that currently remain largely as manual functions are shown as a separate layer within the application area. The figure also includes the notion of information services; these services are intended to capture those functions believed to be common to a broad set of algorithms or applications and which are needed to manage detailed information content. These information services are necessary to maintain an IPC, as discussed in Section 2.2. Design and development of such services are a challenge that should, logically, be met by the algorithm-development community. It is likely that as the design and performance of such information services becomes better understood, their implementation will migrate to become part of the infrastructure. The algorithm-development community could be quite influential in this role. This modularity supports both developmental growth and operational adaptability—attractive features for enabling spiral development of overall enterprise capability.
Developmental growth is enabled with the implementation of a robust SOA that provides common services, data layer (e.g., access, storage), and visualization support for plug-and-play of disciplined applications. Because of the modular approach, operational capability can be achieved in incremental stages, through an efficient coevolutionary process that integrates engineering and operational test and evaluation while reducing development (nonrecurring) cost and time. Operational adaptability results from modularity because the building blocks may be logically connected in a variety of ways to achieve changing mission goals. An additional benefit comes from the fact that the approach does not require long periods of engineering integration (typically 2 years or more) resulting in lower cost solutions. As a result there are very few negative consequences of discarding older applications when they become outmoded by advancing technology or by changing requirements.
2.3.3 Implications for Fusion
The implementation of automated techniques in net-centric operations requires a degree of implementation commonality, or disciplined algorithm development that will enhance both user (decision maker) ability to select among like algorithms, and enterprise ability to couple necessary processing stages to create a goal-driven IPC. This requirement that a common discipline be developed and invoked across the network enterprise (all nodes, all users) arises from the need to ensure consistent use and interpretation of data and information among machines and humans. Algorithmic functions must adhere to a common set of standards (e.g., data strategy) and expose significant internal functions (e.g., models, constraints, assumptions) to ensure consistent data and information processing (fusion, etc.) across the enterprise. This imposition on algorithms in net-centric operations is consistent with the dictum underpinning SOA design—that all services must be self-describing and usable without any prior background or knowledge.
The discipline suggested here has not been part of traditional algorithm design. Current algorithms (fusion and others) have always performed in systems that are engineered to provide selected information functions; these algorithms operate within the confines of specific systems, with known underlying but generally hidden assumptions. In net-centric environments, where machine-to-machine data passing is needed to meet data volume and speed requirements, such hidden assumptions must be exposed to ensure that all processes are mathematically and logically consistent with source sensing and context characteristics, and intermediate processing updates. Furthermore, in current practice, information requirements (and information flow) have been designed to support specific (generally local) requirements—in net-centric operations algorithmic products will be called on to support multiple distributed nodes, for multiple distributed users with differing roles and perspectives. Such environments will require standards and discipline for implementing algorithms, and for sharing sufficient descriptive information, so that the information products are usable by machines and humans across the enterprise.
The implementation of algorithms for net-centric operations is likely to require new practices in exposing previously internal functions, and in aggregating functions that are common to large classes of algorithms. Such implications for net-centric algorithm design are not well-understood. Research to identify best practices for either decomposing algorithmic functions or exposing needed internal data is being conducted by organizations such as the Office of Naval Research.18 The expectation is that, in addition to exposing algorithmic functions needed for efficient net-centric operation, a number of enabling functions that are common to a range of algorithms will be identified as items for enterprise control and monitoring. Candidate functions include the following:
Models that capture and share knowledge of phenomenology, platforms, sensors, and processes—insofar as these form the basis for algorithmic computation and inform algorithm usage and human interpretation, it may be advisable to maintain and distribute such models from a common (and authoritative) enterprise source. Issue: Can algorithms be decoupled from the model they employ?
Metadata and pedigrees to identify sensor or source characteristics and intermediate processing actions, including time—needed to avoid redundant usage (especially data contamination), to enable validation and provide explanation of information products, and to support error correction when necessary. Issue: Can a standard for metadata and pedigree representation be developed and promulgated for all enterprise participants including platforms, sensors, data sources, and processors?
Metrics to qualify data and processing stages on some normative scale for consistent and (mathematically) proper usage—provides enterprise awareness of algorithm health and readiness, and to support product usage as a function of enterprise operating conditions and operational goals. Issue: Can metrics that reflect operational effectiveness (as opposed to engineering measures) be developed and accepted for broad classes of algorithms?
Although the modern information environment and the notions of network-centric or network-enabled operations offer great promise for fusion and the related IPC functionality, the potential remains to be demonstrated. Information technology advances at an almost unimaginable pace and predicting when or if some breakthrough will occur that may render all things possible is only an exciting exercise. The difficulties with realizing the potential of net-centricity for operational use lie not with the technology but rather with the adaptation of cultural practice in intelligence, operations, research, and, most importantly, in the acquisition process. Moving into a new networked information era will mean dramatic change in the way we conduct operations, acquire capabilities, and allocate resources, particularly our funds. Whether all these nontechnical barriers can be socialized and overcome presents the greatest challenge to advancing network centric operations.
2.4 Control Paradigm: TRIP Model Implications for Resource Management and Data Fusion
The IPC, as described in Section 2.3, consists of two basic elements: resource management and data fusion. If the benefit of coupling these elements is significant, as asserted, one might ask why it is not done routinely. In fact there are a number of examples of colocated or platform-based systems that include both collection of essential data and processing in a timely, tightly coupled manner. Fire control systems provide one such example.* In retrospect, it is apparent that data fusion and resource-management business and technology practices have developed independently. The result, as we move toward greater degrees of automation (as demanded by net-centricity), is that we need to identify and capture the common context and dependencies that enable a functional understanding (and implementation) of coupled decomposition and composition processes and the potential benefit that might be gained. This section will provide a high-level description of a model developed under defense advanced research projects agency (DARPA) advanced ISR management program (concluded in 2002) to explore the functional relationships between resource management and data fusion and to identify the common functions necessary to enable coupling in an IPC. This discussion will outline a functional model of a coupled process and identify the drivers and constraints for linking the control and estimation elements.
2.4.1 Resource-Management Model
Resource management (or collection management, in military parlance) is a transformation process that starts with understanding mission objectives and mapping the information needed by decision-makers to clarify desired objectives, the observables that are expected to satisfy those objectives, and the tasks required to gather those observables. This control process includes the articulation of discrete tasks in a form that can be understood by real-world actors, and the execution of those tasks by designated platforms, sensors, and agents of various types. This resource-management process serves to decompose information needed to satisfy mission objectives into one or more tasks that, in sum, are expected to answer the decision-maker’s queries. The tasks are articulated in terms that can be executed by a designated sensor type or agent; that is, it contains specific, appropriate requirements for the observations (e.g., time, location, geometry, accuracy, signatures) expected to satisfy the information need. A functional description of the stages of this process appears in Figure 2.8. The relevance of resource management for data fusion purposes is apparent—fusion processes are employed to take the observations (or data) that result from the resource-management process, and compose them into information abstractions that satisfy the stated need. This is seldom a static process. Most environments are inherently dynamic, requiring ongoing adjustments in the collection-management process—and therefore a continuing process of data fusion refinement.
2.4.1.1 TRIP Model
Transformations of “requirements for information” process (TRIP) model was developed under a DARPA program addressing collection-management technology. The model shown in Figure 2.8 portrays a framework that relates the process stages for decomposing mission objectives into information needs, and for selecting the appropriate sensors and task assignments to meet those information expectations. The TRIP model19 describes the information transformation needed to identify the observation set and associated tasking, necessary to satisfy the user’s needs. The transformation refers to what literally is a translation of information needs (generally expressed in operational and linguistic terms) to the specific direction (e.g., location, time, geometry, conditions) required for control of technical means or database searches. The model captures the significant stages of the control paradigm including the information elements, the operational influences, and the underlying assumptions (or dependencies) used in effecting control. The reference provides a very detailed discussion of TRIP and its relation to fusion processes in satisfying information needs. A functional representation of the resource-management process, which provides and abstracts the decomposition stages captured by TRIP, is illustrated in Figure 2.8.

FIGURE 2.8
Resource-management functions.
Operational decision makers are not focused on the details of which resources are needed to gather information, much less the process for decomposing their needs into executable tasks. Decision makers are interested in understanding some aspect of the environment or situation, for which they believe sensor observations (or archived data) can provide explanatory evidence. This desire for evidence is expressed as a user requirement (UR). The decomposition of URs from a high-level statement of information needs is represented in multiple functional levels including articulation of specific objectives, related observables, and the tasks and plans to gather the needed data.
UR Level 3: Information needs. The need for information about environments or situations is generally expressed as a request for information about the location, behavior, or condition of key indicators (e.g., objects, events, or entities) at a given space and time. Such requests are agnostic to the means of gathering the data, but may include implications for accuracy and timeliness. UR Level 3 functions provide articulation of the situation indicators believed necessary to confirm or discount hypotheses that will guide courses of action, and the constraints under which the indicators will be relevant or useful.
UR Level 2: Collection objectives. URs are driven by the understanding of overall mission goals and the contribution of specific objectives for attaining those goals. The objectives may be partitioned into separable mission tasks, but the dependencies must be understood and captured as context for the stated objectives or tasks, in the form of relationship, priority, and value. Such context is necessary to adjudicate conflicting demands for resources, which is generally the case for environments that are characterized by some combination of cost, risk, and supply factors. Briefly, all resources are consumable and so there is a cost (including opportunity cost) associated with allocating a resource to perform a given task; the use of resources entails risk that it will fail or become unavailable; and, in most cases, the supply-to-demand ratio is a fractional number. These factors combine to dictate that planned usage of assets be managed in a way that maximizes the expected value of collected information. The UR Level 2 function provides motivation, in the form of high-level goals, and necessary context to drive the resource-management process.
UR Level 1: Observables. For each key indicator, one or more sensing modalities, or archival sources, may be adequate to provide the set of measurements necessary to support estimation of the requested information. Assessing which sources are adequate for the desired measurement requires knowledge of sensing phenomenology and parametrics, along with expected background conditions, to determine the sensor type (or combination), parametrics, and conditions that will enable observation of a given indicator with the required quality. The UR Level 1 function provides options specifying alternative mechanisms for observation, which include sensing modality, relevant parameters, and constraining physical conditions, required to observe (and ultimately estimate) the desired measurements or signatures.
UR Level 0: Tasks and plans. Once the observability options and associated constraints have been specified it is possible to apply specific knowledge of the performance and behavior of each platform, sensor, or archival source to determine which combination is capable of providing the required measurement set. The UR Level 0 function specifies one or more collection tasks to a selected platform/sensor/source combination and the constraints (including time, location, geometry, or other variables) under which the task is to be accomplished.
And to provide the basis for replanning in response to situation dynamics:
UR Level 4: Dynamic replanning. Given the nature of planning in even minimally dynamic environments, it is imperative that a response to contingencies be available. Causes for contingencies may range from natural causes (e.g., weather effects, equipment failure), to adverse action (e.g., cyber attack, unforeseen threat), or to meet the need for additional data from a user (or algorithm) to resolve an ambiguity or refine an estimate. UR Level 4 functions provide control and updates for UR Levels 3 through 0, appropriate to the priority and constraints associated with the contingency. The response must include consideration for the nature of the immediate response and for longer-term ripple effects that may result.
Although in general we seek to automate the resource-management process, the identification of these functional elements is not intended to imply that full or even partial automation is feasible for each of them. The state-of-the-art for the higher-level URs is often a manual capability depending on the complexity of the domain. It should also be noted that this functional description is not intended to imply a process or design hierarchy. Depending on domain or information need particulars, a variety of process flows or design configurations might be envisioned. The functional breakout is intended to identify relationships and to partition activities as an aid to understanding applicable techniques (manual or automated) and to recognizing the utility of new technology as a solution option.
Throughout this discussion there have been references to implicit information (e.g., “knowledge of …”) and to background influences (e.g., context). The former are intended as references to the models, or metadata, which underpin both human- and machine-based interpretive and inferential activity. The functional capabilities discussed here rely on embedded knowledge (or models) of the entities from which they intend to interact or control (e.g., platforms, sensors, phenomenology, data archives). To the extent that such knowledge is absent or in error, the results of the control or interaction will fail to achieve the desired goal.
The reference to influences or context is intended to emphasize the point that, to the extent the functions discussed here are aligned to form a process (as will almost always be the case), the assumptions made, and dependencies identified, in earlier process stages must be carried forward to inform successive stages. These assumptions and dependencies have explanatory power for motivation, purpose, focus of attention, and semantic relationships. They are, in fact, the pedigree for the decision process that the functional elements will support. Pedigree captures the context under which decisions in the process chain are made. Pedigree must be linked and accessible in a manner that informs all stages of the process so that decisions across the processing chain can be made in a consistent manner. Humans fulfill this role (often in unstructured fashion) through explanation, discussion, or training sessions. In automated environments the discipline for generating and maintaining pedigree will become essential to provide machines with the appropriate constraints for algorithms of virtually any type to perform as intended. Pedigree also becomes the mechanism for machine-based processes to adapt to changing conditions, since the constraints under which they operate (and therefore the process goals) can be changed in a uniform and consistent manner. The TRIP model paper19 provides considerable discussion on the significance of pedigree and the errors that can occur if it is absent or ignored.
The inclusion of metadata and pedigree in the functional breakout of Figure 2.8 is meant as a reminder that these functions have an essential enabling role in the implementation of any resource-management process. Their inclusion here is not meant to imply a unique resource-management role. Indeed the utility of metadata and pedigree extends to every part of the IPC.
2.4.2 Coupling Resource Management with Data Fusion
The duality between resource management and data fusion is discussed in Section 2.2. The complementary relationship can be noted with the recognition that resource management seeks to maximize the total value of collected information, whereas data fusion seeks to minimize the uncertainty of its estimates. The essence of resource management, then, is large-scale optimization and the essence of data fusion is uncertainty management. The complementary nature of the two can be illustrated by juxtaposing the well-known levels of fusion with the UR levels. Table 2.1 provides a summary representation of these levels.
TABLE 2.1
Juxtaposition of Data Fusion and Resource-Management Functionality

As a follow-up to the discussion of metadata and pedigree it is also apparent that these functions enable consistency across the IPC. The data fusion community understands the use of metadata and pedigree, although it has not always been employed in a disciplined fashion. As with resource management, metadata provides pointers to the models, or aspects thereof, that characterize the data sources and conditions under which the data were collected. Pedigree provides the traceability across the processing chain and the explanation of what processing was performed, and when. In a coupled environment, as discussed in Section 2.2, resource-management pedigree can inform data fusion processes about information objectives, effectively setting goals for the estimation process and enabling adaptivity (within limits) by impacting processing goals and architecture. Similarly, data fusion pedigree can inform resource-management processes with near real-time feedback on the adequacy of collection: requesting more or different data when needed to meet information objectives, and indicating when specific collection can be terminated, releasing scarce assets to perform another task.
Metadata and pedigree, along with models of the underlying sensors, platforms, phenomenology, and the processes themselves, provide the context that describes the IPC. Clearly this context needs to be shared to assure consistency across the total IPC. The separate functional breakouts of resource management and data fusion, and the shared use of context are illustrated in Figure 2.9.
The data mining functions discussed in Section 2.2 and illustrated in Figure 2.4 could also be shown to relate to the shared context in a similar fashion.
2.4.3 Motivational Note
It is worth observing that the emergence of net-centric enterprises, and the potential for coupling information processes with shared context over distributed sensing and processing nodes, gives rise to significant new possibilities. In the past, algorithms were designed to fit into static environments and produce results that were independent of decision-makers’ needs. For example, trackers were designed to ingest data from the sensor it was engineered to work with, and to keep processing target tracks independent of situation dynamics or changing information needs. It performed a single function with no significant operational adaptivity. The future vision, enabled by a net-centric composability environment, is that different algorithms or algorithmic functions can be invoked as needed, in response to changing information needs that are communicated via common access to pedigree. In this vision, pedigree is employed both to explain decision choices and to inform or coordinate dependent processing stages (control and estimation) of changing mission objectives as well as information needs to manage the details of what data to collect, and what fusion processes to invoke to best satisfy mission needs.
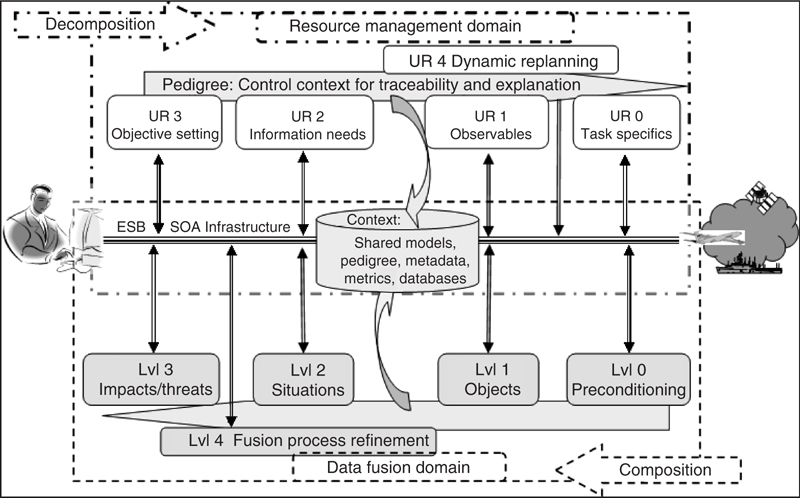
FIGURE 2.9
Functional relationships in the information-processing cycle.
The end result is common awareness of information needs across all processes, better use of available resources and the data they generate, and improved satisfaction for users. The aim is an IPC that is responsive to dynamic changes in mission goals and the environment.
References
1. JCS-Joint Pub 1-02. Department of Defense Dictionary of Military and Associated Terms-12, April 2001.
2. Ford, C.A. and Rosenberg, D.A. The Admirals Advantage, Naval Institute Press, Annapolis, MD, 2005.
3. Jones, R.V. Most Secret War, Harnish, Hamilton Ltd, London, 1978.
4. Meyer, H.E. Real World Intelligence, Weidenfield and Nicolson, New York, 1987.
5. Studeman, W.O. RADM. Keynote Address to Data Fusion Symposium DFS 88, November, 1988.
6. The 9/11 Commission Report, U.S. Government Printing Office, 2004.
7. Report of the Commission on the Intelligence Capabilities of the United States Regarding Weapons of Mass Destruction. Report to the President of the United States, March 31, 2005.
8. Boorstin, D. Cleopatra’s Nose: Essays on the Unexpected, Vintage Books, New York, NY, 1994.
9. Davenport, T.H. and Prusek, L. Working Knowledge: How Organizations Manage What They Know, Harvard Business School Press, Boston, MA, 2000.
10. Captain William Walls, personal communication.
11. Kessler, O. Functional Description of the Data Fusion Process, Office of Naval Technology, Naval Air Development Center, Warminster, PA, 1991.
12. Nichols, M. A Survey of the Current State of Data Fusion Systems, Joint C4ISR Decision Support Center, OSD, 30 September 2000.
13. Bosse, E., Roy, J., and Wark, S. Concepts, Models, and Tools for Information Fusion, Artech House Inc., 2007.
14. JCS-Joint Publication 2-01. Joint and National Intelligence Support to Military Operations, Washington, DC, October 7, 2004.
15. Ed Waltz. Information Warfare Principles and Operations, Artech House, Boston, MA, 1998.
16. Department of Defense Directive. Data Sharing in a Net-Centric Department of Defense, 8320.2, Washington, DC, Dated December 2, 2004.
17. DISA. Net-Centric Enterprise Services (NCES) User Guide, Version 1.1/ECB 1.2, April 20, 2007.
18. BAA 05-015. Combat ID: Information Management of Coordinated Electronic Surveillance, Office of Naval Research, May 2004.
19. Fabian, B.E. and Eveleigh, T.J. Estimation and ISR Process Integration, National Symposium on Sensor and Data Fusion, Proceedings, June 2001.
* The authors’ affiliation with the MITRE Corporation are provided only for identification purposes and is not intended to convey or imply MITRE’s concurrence with, or support for, the positions, opinions, or viewpoints expressed by the authors.
* The terms data and information will appear throughout this handbook and often will appear to be used interchangeably. Their definitions and distinctions are discussed at greater length in Section 2.1.3.
* The original need for the JDL arose from a 1982 Defense Science Board study that found that
• The three services’ research and technology bases were not coordinated at the headquarters level
• The various service laboratory investigators had no direct path to each other without bureaucratic permission
• There was no coherent and coordinated program of C2 research anywhere in DoD
As a result of these deficiencies, the Assistant Secretary of Defense for Command, Control Communications and Intelligence (ASDC3I) directed the Services to work together and develop a solution. In response to this direction, the navy, the army, and the air force created a new organization the JDL so that they could work as a team and respond specifically to these and other deficiencies that might arise. ASDC3I accepted this proposal and chartered the JDL to address the above deficiencies. JDL did this by conducting a survey of managerial and structural weaknesses and then creating processes to remedy them. They established a basic research group (BRG), a technology applications and demonstration group (TAD), and four subpanels corresponding to what were considered to be the driving initiatives in C3. They were
• Data fusion subpanel
• Networks and distributed processing subpanel
• Decision aids subpanel
• Dynamic spectrum management subpanel
Although the JDL as a specific organization has been replaced, the infrastructure and collaborative processes they created remain active under the Deputy Secretary of Defense for Research and Engineering (DDR&E).
* Many of these systems are designed for operation in tactical environments where sensors are applied to search areas of suspected hostile activity and to respond when objects are detected in a manner consistent with mission goals that could vary from signature collection to weapon deployment. The issue of note for extant examples of such closed systems is that, in general, they operate within a larger framework that formulates the “big picture” in a manner that exploits independent (largely uncoupled) system products. For example, the decision to deploy a particular weapon-bearing platform to a specific area in a given time period, to find and engage threat vehicles, is the product of an independent information process. How was selection made of platform type, weapon type, area, and time period? This section contends that such decision making can be improved through closer coupling of the supporting IPC and, further, that the movement toward net-centricity can be leveraged positively to aid that improvement. Further, virtually all of these systems were the product of separate, highly structured, system engineering processes that tuned each system to perform well against a limited set of mission goals. Although those systems perform well in the roles for which they were designed, they have little adaptivity to changing missions, and have great difficulty being interoperable with new partners—without costly (time and dollars) re-engineering. This provides another argument for net-centricity.