
5
InfoQ at the postdata collection stage
5.1 Introduction
In Chapter 4, we examined factors affecting the predata collection study design stage, which yield low InfoQ and dataset X that is related to the target dataset X*. That chapter presented a range of methods to increase the InfoQ at the predata collection stage.
In this chapter, we turn to the later stage of an empirical study, after the data has been collected. The data may have been collected by the researcher for the purpose of the study (primary data) or otherwise (secondary and semisecondary data). The data may be observational or experimental. Moreover, the study may have revised goals or even revised utility. These changes affect the way the data is analyzed in order to derive high InfoQ of the study.
We begin by laying out key points about primary, secondary, and semisecondary data, as well as revised goals and revised utility. We then move to a discussion of existing methods and approaches designed to increase information quality at the postdata collection stage. The methods range from “fixing” the data to combining data from multiple studies to imputing missing data. In some cases we can directly model the distortion between X and X*. For the different methods discussed here, we examine the relationship between the target dataset X* and the actual dataset X as a function of both a priori causes, η1, and a posteriori causes, η2, through the relationship X = η2{η1(X*)}. Each approach is designed to increase InfoQ of the study by tackling a specific a posteriori cause.
5.2 Postdata collection data
In Chapter 4 we described the terms primary data and secondary data and the difference between them. Recall that the distinction is based on the relationship between the researcher or team collecting the data and the one analyzing it. Hence, the same dataset can be primary data in one analysis and secondary data in another (Boslaugh, 2007). Primary data refers to data collected by the researcher for a particular analysis goal. Secondary data refers to data collected by someone other than the researcher or collected previously by the researcher for a different goal. Finally, there exist hybrids. In Chapter 4 we looked at computer experiments, which generate primary data (simulations) based on secondary data (from physical models).
In the next sections, we look at existing methods and approaches for increasing InfoQ at the postdata collection stage for data that arise from either primary, secondary, or hybrid sources. While primary data is designed to contain high InfoQ due to the researcher’s involvement in the study design, the reality of data collection is that the resulting X is almost always not exactly as intended, due to a posteriori causes. “Unexpected problems may arise when the experiment is carried out. For example, experiments can produce non‐quantifiable results or experimental points may generate ‘outliers’, observations whose values appear quite incompatible with the overall pattern in the data” (Kenett et al., 2006). Therefore, methods for increasing InfoQ at the postdata collection stage can be aimed at secondary data, for example, adjusting for selection bias; at semisecondary data, for example, meta‐analysis; and even at primary data, for example, handling missing values.
Primary data can become secondary data if the goal or utility of the study is revised or when secondary goals are addressed. A context which is popular in practice, yet hardly discussed in the statistics or data mining literature from the perspective of information quality, is the case of primary data with revised goals. Cox (2009) notes, “Objectives may be redefined, hopefully improved, and sometimes radically altered as one proceeds.”
Similarly, Friedman et al. (2015, p. 182) comment that in clinical trials, “One would like answers to several questions, but the study should be designed with only one major question in mind.” Therefore, often multiple questions will be answered using data that was collected through a design for answering a single primary question. In particular, the evaluation of adverse effects is important, yet not the primary goal of a clinical trial. The result is that “clinical trials have inherent methodological limitations in the evaluation of adverse effects. These include inadequate size, duration of follow‐up, and restricted participant selection.”
In another example discussed in Chapter 4, Engel et al. (2016) consider robust design methods when degradation agents affect performance over time. In this case, specifying targets that do not account for a change in requirements, if realized, will induce failures. Since this change in goal has not been anticipated at the design stage, the a posteriori analysis needs to consider changes in design specifications.
Another common situation where revised goals arise is in the process of journal article reviewing. In the social sciences and in economics, it is common for reviewers to request authors to answer additional research questions. In some cases, it is impossible to collect additional data that would directly have high InfoQ for these new questions, and the authors are forced to use the existing data in answering the new questions. For more on the review process and the information quality it is supposed to ensure, see Chapter 12.
A dramatic practical example of primary data collected through simulations with revised goals is linked to the Columbia shuttle disaster. The Columbia Accident Investigation Board reported that a simulation program called CRATER was used to analyze the impact of foam debris on the shuttle protective tiles. The simulation modeled impact of debris smaller by a factor of 400 than the ones affecting the shuttle at lift‐off. The engineers who had developed CRATER had left, and the replacement engineer who used it did not realize the impact of the scale. The analysis he conducted showed that the shuttle was safe. This mistaken information, with obvious low InfoQ, had tragic consequences (see www.nasa.gov/columbia/caib).
The methods and approaches described in the following sections are therefore relevant to a variety of data–goal–utility scenarios. However, their implementation is specific to the goal and utility of interest.
5.3 Data cleaning and preprocessing
Data “cleanliness” has long been recognized by statisticians as a serious challenge. Hand (2008) commented that “it is rare to meet a data set which does not have quality problems of some kind.” Godfrey (2008) noted that “Data quality is a critically important subject. Unfortunately, it is one of the least understood subjects in quality management and, far too often, is simply ignored.”
Consider a measured dataset X and a target dataset X* ≠ X. The data quality literature includes methods for “cleaning” X to achieve X* and guidelines for data collection, transfer, and storage that reduce the distance between X and X*.
Denote data quality procedures (cleaning, avoiding errors, etc.) by h(·). We distinguish between two general types of procedures h(X) and h(X|g). The first, h(X), focuses on procedures that generate or clean X to minimize its distance from X*, without considering anything except the dataset itself.
Advanced data recording devices, such as scanners and radio‐frequency identification (RFID) readers, data validation methods, data transfer and verification technologies, and robust data storage, as well as more advanced measurement instruments, have produced “cleaner” data (Redman, 2007) in terms of the distance between X and X*. Management information systems (MIS)‐type data quality (see Chapter 3) focuses on h(X) operations.
In contrast, h(X|g) focuses on quality procedures that generate or clean X conditional on the goal g. One example is classic statistical data imputation (Little and Rubin, 2002; Fuchs and Kenett, 2007), where the type of imputation is based on the assumed missing data generation mechanism and conditional on the purpose of minimizing bias (which is important in explanatory and descriptive studies). Another example is a method for handling missing predictor values in studies with a predictive goal by Saar‐Tsechansky and Provost (2007). Their approach builds on multiple predictive models using different subsets of the predictors and then applies, for each new observation, the model that excludes predictors missing for that observation. A third example is a data acquisition algorithm that was developed by Saar‐Tsechansky et al. (2009) for data with missing response labels. The algorithm chooses the predictor values or missing response labels to collect, taking into consideration a predictive goal (by considering the cost and contribution to predictive accuracy).
Rounding up recorded values is another type of data cleaning, common in the pharmaceutical industry. Such rounding up is used in order to overcome low‐resolution measurements and improve clarity of reporting. We distinguish the difference between rounding up and truncation, which is treated in Section 5.7. There are different variations on rounding up. For example, double rounding is performed when a number is rounded twice, first from n0 digits to n1 digits and then from n1 digits to n2 digits (where n0 > n1 > n2.) Calculations may be conducted on the number between the first and second instances of rounding. Another example is intermediate rounding, where values used during a calculation are rounded prior to the derivation of the final result. Rounding of continuous data is performed to obtain a value that is easier to report and communicate than the original. It is also used to avoid reporting measurements or estimates with a number of decimal places that do not reflect the measurement capability or have no practical meaning, a concept known as false precision.
The US Pharmacopeial (USP) Convention state that “Numbers should not be rounded until the final calculations for the reportable value have been completed.” Boreman and Chatfield (2015) show with very convincing examples that, from a purely technical point of view, it is always better to work with unrounded data. They recommend that data should only be rounded when required for formal or final reporting purposes, which is usually driven by a specification limit format, that is, the number of decimals quoted in the specification limit. This recommendation implicitly refers to the InfoQ dimension of communication and demonstrates the importance of distinguishing between the need of statistical computations and presentation of outcomes.
Another h(X|g) “data cleaning” strategy is the detection and handling of outliers and influential observations. The choice between removing such observations, including them in the analysis, and otherwise modifying them is goal dependent.
Does data cleaning always increase InfoQ? For X ≠ X* we expect InfoQ(f,X,g,U) ≠ InfoQ(f,X*,g,U). In most cases, data quality issues degrade the ability to extract knowledge, thereby leading to InfoQ(f,X,g,U) < InfoQ(f,X*,g,U).
Missing values and incorrect values often add noise to our limited sample signal. Yet, sometimes X* is just as informative as or even more informative than X when conditioning on the goal, and, hence, choosing h(X) = X is optimal. For example, when the goal is to predict the outcome of new observations given a set of predictors, missing predictor values can be a blessing if they are sufficiently informative of the outcome (Ding and Simonoff, 2010). An example is the occurrence of missing data in financial statements, which can be useful for predicting fraudulent reporting. Respondents that refuse to divulge data on their earnings might be more trustworthy (i.e., missing data), so that focusing on covariates in these missing data entries differentiates between reporting types.
5.4 Reweighting and bias adjustment
Selection bias is an a posteriori cause that makes a sample not representative of the population of interest. In surveys, one cause for selection bias is nonresponse. This causes some groups to be over‐ or underrepresented in the sample.
Another problem is self‐selection, where individuals select whether to undergo a treatment or to respond to a survey. Self‐selection bias poses a serious challenge for evaluating a treatment effect with observational data. In nonexperimental studies, observations are not randomly assigned to treatment and control groups. Hence, there is always the possibility that people (or animals, firms, or other entities) will select the treatment or control group based on their preference or anticipated outcome. The two main approaches for addressing self‐selection bias are the Heckman econometric approach (Heckman, 1979) and the statistical propensity score matching approach (Rosenbaum and Rubin, 1983). Both methods attempt to match the self‐selected treatment group with a control group that has the same propensity (or probability) to select the intervention. In propensity score matching, a propensity score is computed for each observation, and then the scores are used to create matched samples. Thus h(X) is a subset of the original data which includes a set of matched treated and control observations. Unmatched observations are removed from further analysis. The matched samples are then analyzed using an analysis method f of interest, such as t‐test or a linear regression.
Selection bias due to nonresponse or self‐selection also poses a challenge in descriptive studies where the goal is to estimate some parameter (e.g., the proportion of voters for a political party or the average household income). A common approach aimed at correcting data for selection bias, especially in survey data, is reweighting or adjustment. Weights are computed based on under‐ or overrepresentation, so that underrepresented observations in the sample get a weight larger than 1 and overrepresented observations get a weight smaller than 1. Weight calculation requires knowledge of relevant population ratios (or their estimates). For example, if our sample contains 80% men and 20% woman, whereas the population has an equal number of men and women, then each man in the sample gets a weight of 0.5/0.8 = 0.625 and each woman gets a weight of 0.5/0.2 = 2.5. Estimating the average income of the population is now done by using the weighted average of the people in the sample. For tests detecting nonresponse bias, see Kenett et al. (2012).
Using weights is aimed at reducing bias at the expense of increased variance, in an effort to maximize the mean squared error (MSE) of the estimator of interest. In other words, h(X) is chosen to maximize U[f{h(X|g)}] = MSE. Yet, there is disagreement between survey statisticians regarding the usefulness of reweighting data, because “weighted estimators can do very badly, particularly in small samples” (Little, 2009). When the analysis goal is estimating a population parameter and f is equivalent to estimation, adjusting for estimator bias is common. A comprehensive methodology for handling such issues is called small area estimation (Pfeffermann, 2013).
In the eBay consumer surplus example (Section 1.4), Bapna et al. proposed a bias‐corrected estimator of consumer surplus in common value auctions (where the auctioned item has the same value to all bidders), which is based on the highest bid.
5.5 Meta‐analysis
Meta‐analysis is a statistical methodology that has been developed in order to summarize and compare results across studies. It consists of a large battery of tools where the individual study is the experimental unit. In meta‐analysis, “data” refers to statistical results of a set of previous studies investigating the same research question. Statistical methodology is then used to combine the results from the disparate studies for obtaining more precise and reliable results, that is, for increasing InfoQ. A posteriori causes that decrease InfoQ include “file drawer” bias, where studies that do not find effects remain unpublished and do not become factored into the meta‐analysis; agenda‐driven bias, where the researcher intentionally chooses a nonrepresentative set of studies to include in the analysis; and unawareness of Simpson’s paradox, which arises due to the aggregation of studies. Meta‐analysis consists of identifying all the evidence on a given topic and combining the results of the single studies in order to provide a summary quantitative estimate of the association of interest, which is generally a weighted average of the estimates from individual studies. Quantification and investigation of sources of heterogeneity are also part of the process. Meta‐analysis was first developed for the purpose of summarizing results from clinical trials in order to assess the efficacy/effectiveness of a given treatment. Its use has however extended to observational epidemiology and other settings, and meta‐analysis of qualitative data has also been proposed (Dixon‐Woods et al., 2005).
The choice of the effect measure that represents the results for each individual study depends on which data is available in these studies, the research question investigated, and the properties of the possible measures evaluated in the context of the specific study setting. The methods for obtaining a summary estimate are broadly divided into fixed‐effects models and random‐effects models. The former assume that all studies measure the same effect, while the latter assume that studies measure different effects and take between‐study variation into account. Among the most widely used fixed‐effects methods are the inverse variance method and, for binary outcomes, the Mantel–Haenszel and the Peto method. A fundamental component in meta‐analysis is quantifying heterogeneity across studies by investigating its sources. This can be accomplished by forming groups of studies according to some given characteristic and comparing the variance within and between groups. Meta‐regression investigates whether a linear relationship exists between the outcome measure and one or more covariates (Negri, 2012).
When conducting a meta‐analysis, the objective is not merely computing of a combined estimate. In order to achieve information quality, additional aspects of the evidence available for evaluation should be considered, such as the quality of the studies included and hence their adequacy to provide information on the investigated issue, the consistency of results across studies, and the evidence of publication bias.
Once the studies have been identified and retrieved, the data needed to perform the meta‐analysis must be extracted from the publications. This may include information on the study design, the study population, number of subjects in categories of exposure/outcome, statistical methods, and so on. Obviously, the data extracted depend on the chosen measure of effect. Other characteristics that are to be used in the analysis of subgroups of studies, as well as indicators of study quality and other variables that may be important to describe the study (e.g., location, response rate) need also to be recorded. The extraction of data from the individual studies is another important step, where unexpected problems often arise. Errors in published articles are quite common, and sometimes a study that meets the inclusion criteria must be excluded because the data in the tables is inconsistent. Data extraction in meta‐analysis is an example of a posteriori analysis of secondary data.
5.6 Retrospective experimental design analysis
Designed experiments typically consist of balanced arrays of experimental runs that allow for efficient estimation of factor effects and their interactions (see Chapter 3). However, in running designed experiments, one often meets anticipated and unanticipated problems with the result that the collected data X differs from the target data that was experimental design planned to collect X*.
In designing experiments, we try to account for anticipated constraints and limitations. For example, the potential impact of raw materials or operating conditions can be accounted for by running the experiment in separate blocks. Practical constraints may dictate that some factors will be “nested” within others or that there will be limitations on the run order. In other examples, there may be some experimental points that we know ahead of time as impossible to execute because of logistical or technological requirements. Nevertheless, unexpected problems may arise when the experiment is carried out. For example, experiments can produce nonquantifiable results, or experimental points may generate “outliers,” observations whose values appear quite incompatible with the overall pattern in the data. In analyzing data an underlying model is fitted to the data. For example, two‐level factorial experiments are used to estimate parameters of a linear model that, in turn, depends on the estimability properties of the experimental design.
To handle these a posteriori issues and bridge the gap between X and X*, Kenett et al. (2006) proposed applying bootstrapping methods to handle missing data and validate models used in fitting the data.
When a model is misspecified, an error of the third kind is said to have occurred. Bootstrapping can be used to flag errors of the third kind or, alternatively, validate a specific model. The use of an inadequate model will often lead to an overestimation of the residual variance and to inflated standard errors for the model parameters. Comparison of bootstrap standard errors to those from a regression model analysis is thus a valuable diagnostic. If the bootstrap standard errors are clearly smaller than those from fitting a regression model to the experimental data, it is likely that the model is inadequate.
The general experimentation data analysis strategy with bootstrapping proposed by Kenett et al. (2006) involves six steps:
- Evaluation of experimental conditions including the identification of experimental constraints and a posteriori constraints not planned in the original experimental design. These constraints are reflected by missing or extra experimental runs, constraints on the setting of factor levels or randomization and run‐order issues.
- Design of bootstrap strategy. This involves specifying the underlying mathematical model used in the data analysis and the bootstrapping algorithm that matches the experimental setup.
- Bootstrap analysis. This is an iterative step where an initial pilot run of resampled data is evaluated using mostly graphical displays to validate the bootstrapping algorithm accuracy.
- Fit of the data using regression is followed by computation of standard errors from the regression model and the empirically bootstrapped distribution.
- A diagnostic check is performed by comparing standard errors of regression coefficients and bootstrapped standard errors.
- Iterative fitting. Gaps are interpreted through a second iterative cycle until the analysis is completed. The iteration involves sequential adaptation of regression models until a match is achieved with bootstrapping results.
These six steps are an example of how information quality can be enhanced by a posteriori analysis.
5.7 Models that account for data “loss”: Censoring and truncation
In fields where the measurement of interest is a duration, a common a posteriori cause is data censoring. Medicine and reliability engineering are two such fields where researchers are interested in survival or time to failure. Telecom providers are interested in customer lifetime (before moving to a different carrier or churn), educators are tracking reasons for student dropout, and risk managers try to identify defaulting loan payment patterns. In all cases, one deals with survival‐ and censored‐type data.
A censored observation is one where we observe only part of the duration of interest—for example, if we are measuring time to failure (survival) of a component, then a censored component is one where we did not observe its time of failure. We therefore have partial information X instead of X*: we only know that the component survived for at least the data collection duration. If we observe the “birth” but not the “death” of the observation, it is called right censoring, since we do not observe the event of interest (failure) by the end of the data collection period. Right censoring occurs most commonly when the study has a predetermined end‐of‐collection time, at which point all observations that did not fail are right censored. Another data collection scenario that leads to right‐censored data is when the researcher sets a number of “failed” observations to collect and stops collection when the sample size is reached. At that point, any remaining observations are right‐censored.
Two other types of censoring are left censoring and interval censoring. In left censoring, the observation does fail during the data collection period, but the duration of interest starts before the start of the data collection, for example, when we do not know when the component under observation started working. In interval censoring, we do not observe the start or end time of the observation, but we know that during the data collection period, the observation did not fail. This occurs, for example, when we track software system components on a weekly basis with failures aggregated, without information on their failure time. Figure 5.1 illustrates these three types of censoring.
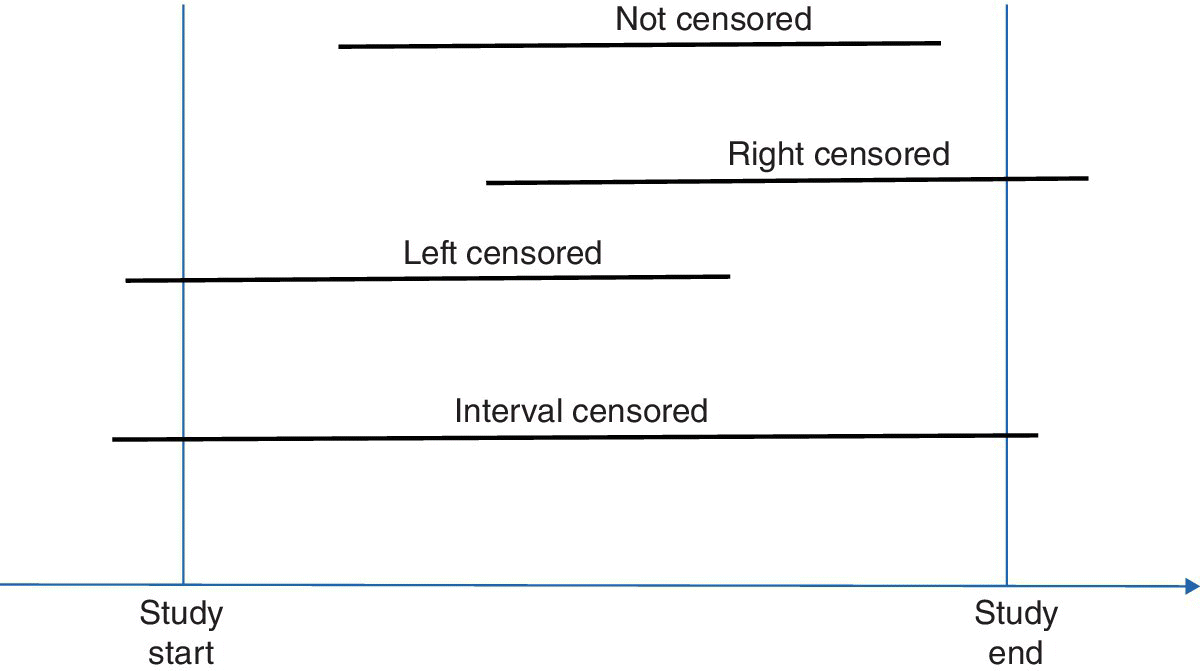
Figure 5.1 Illustration of right, left, and interval censoring. Each line denotes the lifetime of the observation.
Another, different, type of partial data is the result of truncation. Truncation occurs when we cannot observe measurements that exceed or are below a threshold (or interval). For example, one cannot measure body temperature lower or higher than available in a thermometer. In the pharmaceutical industry, one finds many examples of measurements affected by a limit of quantification (LoQ) of the measurement system. Unlike censoring, which represents a form of limit of detection (LoD), we have no information about observations that exceed the threshold(s). In other words, while censoring operates on the duration (observations that exceed the data collection duration are censored), truncating affects the magnitude of the measurements (magnitudes that exceed or are before the possible range/value are not observed). In some sense, censoring is a missing data problem, while truncation can potentially introduce bias in statistical estimators. In general, the detection limit of an individual analytical procedure is the lowest amount of analyte in a sample which can be detected but not necessarily quantitated as an exact value so that LoD represents a type of censoring. In contrast, the quantification limit of an individual analytical procedure is the lowest amount of analyte in a sample which can be quantitatively determined with suitable precision and accuracy. The LoQ is a parameter of quantitative assays for low levels of compounds in sample matrices and is used particularly for the determination of impurities and/or degradation products. In practice it is a form of truncation.
A range of statistical models exists for censored and truncated data. Because the a posteriori cause is different in censoring and in truncation, the statistical approaches are different. In models for censored data, both the complete and the censored data are modeled together, using a cumulative distribution function F(t) = P(T ≤ t), or the survival function S(t) = 1 − F(t) = P(T > t), where t denotes time. Popular models for censored data are the nonparametric Kaplan–Meier estimator, the Cox semiparametric regression model and the parametric Weibull regression model. For more on this topic, see Mandel (2007).
We note that the choice of censored model (f) must be goal dependent. For example, while the Cox semiparametric model can be useful for a descriptive model, such as estimating the survival rate in a population of interest, it is not useful for predicting the survival of new observations whose survival times are longer than the data collection period from which the model was estimated (Yahav and Shmueli, 2014). In contrast, for truncated data one uses a parametric model that is conditional on the truncation range.
5.8 Summary
In this chapter we describe several common a posteriori causes that potentially deteriorate InfoQ, due to challenges in the data collection stage. We also discuss key statistical approaches for addressing such causes. The approaches range from using the data alone to account for the corruption (MIS‐type operations, simple data imputation) to methods that combine information from multiple sources (meta‐analysis) or external sources (weights) to incorporating stochastic models (e.g., survival models) to “recover” the original process generating the data. Table 5.1 summarizes the main points. Taking an InfoQ approach helps the researcher or analyst choose the right method among the different possibilities. While reweighting may be useful for some goals and analyses, it might not be for other goals (or analysis methods). Similarly, whether and how to impute data should closely depend on the goal of the study and on the intended method of analysis f.
Table 5.1 Statistical strategies for increasing InfoQ given a posteriori causes at the postdata collection stage and approaches for increasing InfoQ.
| Strategies for increasing InfoQ | A posteriori causes | |
| Missing data | Imputation; observation or measurement deletion; building multiple separate models; other handling of missing values; advanced technologies for data collection, transfer, and storage; detecting and handling outliers and influential observations | Data entry errors, measurement error, and intentional data manipulation; faulty collection instrument; nonresponse |
| Reweighting | Attach weights to observations; create matched treatment–control samples | Selection bias (self‐selection, nonresponse) |
| Meta‐analysis | Reducing nonsampling errors (e.g., pretesting questionnaire, reducing nonresponse) and sampling errors (e.g., randomization, stratification, identifying target and sampled populations) | “File drawer” bias, agenda‐driven bias, Simpson’s paradox |
| Retrospective DOE | Randomization; blocking; replication; linking data collection protocol with appropriate design; space filling designs | Nonfeasible experimental runs, hard‐to‐change factors that do not permit randomization, outlying observations, unexpected constraints |
| Censoring and truncation | Parametric, semiparametric, and nonparametric models for censored data; parametric models for truncated data | Data collection time constraints; limitations of collection instrument |
References
- Boreman, P. and Chatfield, M. (2015) Avoid the perils of using rounded data. Journal of Pharmaceutical and Biomedical Analysis, 115, pp. 502–508.
- Boslaugh, S. (2007) Secondary Data Sources for Public Health: A Practical Guide. Cambridge University Press, Cambridge, UK.
- Cox, D.R. (2009) Randomization in the design of experiments. International Statistical Review, 77, 415–429.
- Ding, Y. and Simonoff, J. (2010) An investigation of missing data methods for classification trees applied to binary response data. Journal of Machine Learning Research, 11, pp. 131–170.
- Dixon‐Woods, M., Agarwal, S., Jones, D., Sutton, A., Young, B., Dixon‐Woods, M., Agarwal, S., Jones, D. and Young, B. (2005) Synthesising qualitative and quantitative evidence: a review of possible methods. Journal of Health Services Research & Policy, 10, pp. 45–53.
- Engel, A., Kenett, R.S., Shahar, S. and Reich, Y. (2016) Optimizing System Design Under Degrading Failure Agents. Proceedings of the International Symposium on Stochastic Models in Reliability Engineering, Life Sciences and Operations Management (SMRLO16), Beer Sheva, Israel.
- Friedman, L.M., Furberg, C.D., DeMets, D., Reboussin, D.M. and Granger, C.B. (2015) Fundamentals of Clinical Trials, 5th edition. Springer International Publishing, Cham.
- Fuchs, C. and Kenett, R.S. (2007) Missing Data and Imputation, in Encyclopedia of Statistics in Quality and Reliability, Ruggeri, F., Kenett, R.S. and Faltin, F. (editors in chief), John Wiley & Sons, Ltd, Chichester, UK.
- Godfrey, A.B. (2008) Eye on data quality. Six Sigma Forum Magazine, 8, pp. 5–6.
- Hand, D.J. (2008) Statistics: A Very Short Introduction. Oxford University Press, Oxford.
- Heckman, J.J. (1979) Sample selection bias as a specification error. Econometrica: Journal of the Econometric Society, 47, pp. 153–161.
- Kenett, R.S., Rahav, E. and Steinberg, D. (2006) Bootstrap analysis of designed experiments. Quality and Reliability Engineering International, 22, pp. 659–667.
- Kenett, R.S., Deldossi, L. and Zappa, D. (2012) Quality Standards and Control Charts Applied to Customer Surveys, in Modern Analysis of Customer Satisfaction Surveys, Kenett, R.S. and Salini, S. (editors), John Wiley & Sons, Ltd, Chichester, UK.
- Little, R. (2009) Weighting and Prediction in Sample Surveys. Working Paper 81. Department of Biostatistics, University of Michigan, Ann Arbor.
- Little, R.J.A. and Rubin, D.B. (2002) Statistical Analysis with Missing Data. John Wiley & Sons, Inc., New York.
- Mandel, M. (2007) Censoring and truncation – highlighting the differences. The American Statistician, 61(4), pp. 321–324.
- Negri, E. (2012) Meta‐Analysis, in Statistical Methods in Healthcare, Faltin, F., Kenett, R.S. and Ruggeri, F. (editors), John Wiley & Sons, Ltd, Chichester, UK.
- Pfeffermann, D. (2013). New important developments in small area estimation. Statistical Science, 28, pp. 40–68.
- Redman, T. (2007) Statistics in Data and Information Quality, in Encyclopedia of Statistics in Quality and Reliability, Ruggeri, F., Kenett, R.S. and Faltin, F. (editors in chief), John Wiley & Sons, Ltd, Chichester, UK.
- Rosenbaum, P.R., and Rubin, D.B. (1983) The central role of the propensity score in observational studies for causal effects. Biometrika, 70 (1), pp. 41–55.
- Saar‐Tsechansky, M. and Provost, F. (2007) Handling missing features when applying classification models. Journal of Machine Learning Research, 8, pp. 1625–1657.
- Saar‐Tsechansky, M., Melville, P. and Provost, F. (2009) Active feature‐value acquisition. Management Science, 55, pp. 664–684.
- Yahav, I. and Shmueli, G. (2014) Outcomes matter: estimating pre‐transplant survival rates of kidney‐transplant patients using simulator‐based propensity scores. Annals of Operations Research, 216(1), pp. 101–128.