
10
Official statistics
10.1 Introduction
Official statistics are produced by a variety of organizations including central bureaus of statistics, regulatory healthcare agencies, educational systems, and national banks. Official statistics are designed to be used, and increasing their utility is one of the overarching concepts in official statistics. An issue that can lead to misconception is that many of the terms used in official statistics have specific meanings not identical to their everyday usage. Forbes and Brown (2012) state: “All staff producing statistics must understand that the conceptual frameworks underlying their work translate the real world into models that interpret reality and make it measurable for statistical purposes…. The first step in conceptual framework development is to define the issue or question(s) that statistical information is needed to inform. That is, to define the objectives for the framework, and then work through those to create its structure and definitions. An important element of conceptual thinking is understanding the relationship between the issues and questions to be informed and the definitions themselves.”
In an interview‐based study of 58 educators and policymakers, Hambleton (2002) found that the majority misinterpreted the official statistics reports on reading proficiency that compare results across school grades and across years. This finding was particularly distressing since policymakers rely on such reports for funding appropriations and for making other key decisions. In terms of information quality (InfoQ), the quality of the information provided by the reports was low. The translation from statistics to the domain of education policy was faulty.
The US Environmental Protection Agency, together with the Department of Defense and Department of Energy, launched the Quality Assurance Project Plan (see EPA, 2005), which presents “steps … to ensure that environmental data collected are of the correct type and quality required for a specific decision or use.” They used the term data quality objectives to describe “statements that express the project objectives (or decisions) that the data will be expected to inform or support.” These statements relate to descriptive goals, such as “Determine with greater than 95% confidence that contaminated surface soil will not pose a human exposure hazard.” These statements are used to guide the data collection process. They are also used for assessing the resulting data quality.
Central bureaus of statistics are now combining survey data with administrative data in dynamically updated studies that have replaced the traditional census approach, so that proper integration of data sources is becoming a critical requirement. We suggest in this chapter and related papers that evaluating InfoQ can significantly contribute to the range of examples described earlier (Kenett and Shmueli, 2016).
The chapter proceeds as follows: Section 10.2 reviews the InfoQ dimensions in the context of official statistics research studies. Section 10.3 presents quality standards applicable to official statistics and their relationship with InfoQ dimensions, and Section 10.4 describes standards used in customer surveys and their relationship to InfoQ. We conclude with a chapter summary in Section 10.5.
10.2 Information quality and official statistics
We revisit here the eight InfoQ dimensions with guiding questions that can be used in planning, designing, and evaluating official statistics reports. We accompany these with examples from official statistics studies.
10.2.1 Data resolution
Data resolution refers to the measurement scale and aggregation level of the data. The measurement scale of the data should be carefully evaluated in terms of its suitability to the goal (g), the analysis methods used (f), and the required resolution of the utility (U). Questions one should ask to determine the strength of this dimension include the following:
- Is the data scale used aligned with the stated goal of the study?
- How reliable and precise are the data sources and data collection instruments used in the study?
- Is the data analysis suitable for the data aggregation level?
A low rating on data resolution can be indicative of low trust in the usefulness of the study’s findings. An example of data resolution, in the context of official statistics, is the Google Flu Trends (www.google.org/flutrends) case. The goal of the original application by Google was to forecast the prevalence of influenza on the basis of the type and extent of Internet search queries. These forecasts were shown to strongly correlate with the official figures published by the Centers for Disease Control and Prevention (CDC) (Ginsberg et al., 2009). The advantage of Google’s tracking system over the CDC system is that data is available immediately and forecasts have only a day’s delay, compared to the week or more that it takes for the CDC to assemble a picture based on reports from confirmed laboratory cases. Google is faster because it tracks the outbreak by finding a correlation between what users search for online and whether they have flu symptoms. In other words, it uses immediately available data on searches that correlate with symptoms. Although Google initially claimed very high forecast accuracy, it turned out that there were extreme mispredictions and other challenges (David et al., 2014; Lazer et al., 2014). Following the criticism, Google has reconfigured Flu Trends to include data from the CDC to better forecast the flu season (Marbury, 2014). Integrating the two required special attention to the different resolutions of the two data sources.
10.2.2 Data structure
Data structure refers to the type(s) of data and data characteristics such as corrupted and missing values due to the study design or data collection mechanism. As discussed in Chapter 3, data types include structured, numerical data in different forms (e.g., cross‐sectional, time series, and network data) as well as unstructured, nonnumerical data (e.g., text, text with hyperlinks, audio, video, and semantic data). Another type of data generated by official statistics surveys, called paradata, is related to the process by which the survey data was collected. Examples of paradata include the times of day on which the survey interviews were conducted, how long the interviews took, how many times there were contacts with each interviewee or attempts to contact the interviewee, the reluctance of the interviewee and the mode of communication (phone, Web, email, or in person). These attributes affect the costs and management of a survey, the findings of a survey, evaluations of interviewers, and analysis of nonresponders.
Questions one should ask to determine the data structure include the following:
- What types of variables and measurements does the data have?
- Are there missing or corrupted values? Is the reason for such values apparent?
- What paradata or metadata are available?
10.2.3 Data integration
With the variety of data sources and data types available today, studies sometimes integrate data from multiple sources and/or types to create new knowledge regarding the goal at hand. Such integration can increase InfoQ, but in other cases, it can reduce InfoQ, for example, by creating privacy breaches.
Questions that help assess data integration levels include the following:
- Is the dataset from a single source or multiple sources? What are these sources?
- How was the integration performed? What was the common key?
- Does the integrated data pose any privacy or confidentiality concerns?
One example of data integration and integrated analysis is the calibration of data from a company survey with official statistics data (Dalla Valle and Kenett, 2015) where Bayesian networks (BNs) were used to match the relation between variables in the official and the administrative data sets by conditioning. Another example of data integration between official data and company data is the Google Flu Trends case described in Section 10.2.1, which now integrates data from the CDC. For further examples of data integration in official statistics, see also Penny and Reale (2004), Figini et al. (2010), and Vicard and Scanu (2012).
10.2.4 Temporal relevance
The process of deriving knowledge from data can be put on a timeline that includes data collection, data analysis, and results’ usage periods as well as the temporal gaps between these three stages. The different durations and gaps can each affect InfoQ. The data collection duration can increase or decrease InfoQ, depending on the study goal, for example, studying longitudinal effects versus a cross‐sectional goal. Similarly, if the collection period includes uncontrollable transitions, this can be useful or disruptive, depending on the study goal.
Questions that help assess temporal relevance include the following:
- What is the gap between data collection and use?
- How sensitive are the results to the data collection duration and to the lag‐time between collection and use? Are these durations and gaps acceptable?
- Will the data collection be repeated, and if so, is the frequency of collection adequate for users’ goals?
A low rating on temporal relevance can be indicative of an analysis with low relevance to decision makers due to data collected in a different contextual condition. This can happen in economic studies, with policy implications based on old data. The Google Flu Trends application, which now integrates CDC data, is a case where temporal relevance is key. The original motivation for using Google search of flu‐related keywords in place of the official CDC data of confirmed cases was the delay in obtaining laboratory data. The time gap between data collection and its availability is not an issue with Google search, as opposed to CDC data. Yet, in the new Google Flu Trends application, a way was found to integrate CDC data while avoiding long delays in forecasts. In this case, data collection, data analysis, and deployment (generating forecasts) are extremely time sensitive, and this time sensitivity was the motivation for multiple studies exploring alternative data sources and algorithms for detecting influenza and other disease outbreaks (see Goldenberg et al. (2002) and Shmueli and Burkom (2010)).
10.2.5 Chronology of data and goal
The choice of variables to collect, the temporal relationship between them, and their meaning in the context of the goal at hand affect InfoQ. This is especially critical in predictive goals and in inferring causality (e.g., impact studies).
Questions that help assess this dimension include the following:
- For a predictive goal, will the needed input variables be available at the time of prediction?
- For a causal explanatory goal, do the variables measuring the causes temporally precede the measured outcomes? Is there a risk of reverse causality?
A low rating on chronology of data and goal can be indicative of low relevance of a specific data analysis due to misaligned timing. For example, consider the reporting of the consumer price index (CPI). This index measures changes in the price level of a market basket of consumer goods and services purchased by households and is used as a measure of inflation with impact on wages, salaries, and pensions. A delayed reporting of CPI will have a huge economic impact which affects temporal relevance. In terms of chronology of data and goal, we must make sure that the household data on consumer goods and services, from which the CPI index is computed, is available sufficiently early for producing the CPI index.
10.2.6 Generalizability
The utility of f (X | g) is dependent on the ability to generalize to the appropriate population. Official statistics are mostly concerned with statistical generalizability. Statistical generalizability refers to inferring f from a sample to a target population. Scientific generalizability refers to generalizing an estimated population pattern/model f to other populations or applying f estimated from one population to predict individual observations in other populations.
While census data are, by design, general to the entire population of a country, they can be used to estimate a model which can be compared with models in other countries or used to predict outcomes in another country, thereby invoking scientific generalizability. In addition, using census data to forecast future values is also a generalization issue, where forecasts are made to a yet unknown context.
Questions that help assess the generalization type and aspects include the following:
- What population does the sample represent?
- Are estimates accompanied with standard errors or statistical significance? This would imply interest in statistical generalizability of f.
- Is out‐of‐sample predictive power reported? This would imply an interest in generalizing the model by predicting new individual observations.
10.2.7 Operationalization
We consider two types of operationalization: construct operationalization and action operationalization. Constructs are abstractions that describe a phenomenon of theoretical interest. Official statistics are often collected by organizations and governments to study constructs such as poverty, well‐being, and unemployment. These constructs are carefully defined and economic or other measures as well as survey questions are crafted to operationalize the constructs for different purposes. Construct operationalization questions include the following:
- Is there an unmeasurable construct or abstraction that we are trying to capture?
- How is each construct operationalized? What theories and methods were used?
- Have the measures of the construct changed over the years? How?
Action operationalizing refers to the following three questions posed by W. Edwards Deming (1982):
- What do you want to accomplish?
- By what method will you accomplish it?
- How will you know when you have accomplished it?
A low rating on operationalization indicates that the study might have academic value but, in fact, has no practical impact. In fact, many statistical agencies see their role only as data providers, leaving the dimension of action operationalization to others. In contrast, Forbes and Brown (2012) clearly state that official statistics “need to be used to be useful” and utility is one of the overarching concepts in official statistics. With this approach, operationalization is a key dimension in the InfoQ of official statistics.
10.2.8 Communication
Effective communication of the analysis and its utility directly impacts InfoQ. Communicating official statistics is especially sensitive, since they are usually intended for a broad nontechnical audience. Moreover, such statistics can have important implications, so communicating the methodology used to reach such results can be critical. An example is reporting of agricultural yield forecasts generated by government agencies such as the National Agricultural Statistics Service (NASS) at the US Department of Agriculture (USDA), where such forecasts can be seen as political, leading to funding and other important policies and decisions:
NASS has provided detailed descriptions of their crop estimating and forecasting procedures. Still, market participants continue to demonstrate a lack of understanding of NASS methodology for making acreage, yield, and production forecasts and/or a lack of trust in the objectives of the forecasts… Beyond misunderstanding, some market participants continue to express the belief that the USDA has a hidden agenda associated with producing the estimates and forecasts. This “agenda” centers on price manipulation for a variety of purposes, including such things as managing farm program costs and influencing food prices
(Good and Irwin, 2011).
In education, a study of how decision makers understand National Assessment of Educational Progress (NAEP) reports was conducted by Hambleton (2002) and Goodman and Hambleton (2004). Among other things, the study shows that a table presenting the level of advanced proficiency of grade 4 students was misunderstood by 53% of the respondents who read the report. These readers assumed that the number represented the percentage of students in that category when, in fact, it represented the percentage in all categories, up to advanced proficiency, that is, basic, proficient, and advanced proficiency. The implication is that the report showed a much gloomier situation than the one understood by more than half of the readers.
Questions that help assess the level of communication include the following:
- Who is the intended audience?
- What presentation methods are used?
- What modes of dissemination are being used?
- Do datasets for dissemination include proper descriptions?
- How easily can users find and obtain (e.g., download) the data and results?
10.3 Quality standards for official statistics
A concept of Quality of Statistical Data was developed and used in European official statistics and international organizations such as the International Monetary Fund (IMF) and the Organization for Economic Cooperation and Development (OECD). This concept refers to the usefulness of summary statistics produced by national statistics agencies and other producers of official statistics. Quality is evaluated, in this context, in terms of the usefulness of the statistics for a particular goal. The OECD uses seven dimensions for quality assessment: relevance, accuracy, timeliness and punctuality, accessibility, interpretability, coherence, and credibility (see Chapter 5 in Giovanini, 2008). Eurostat’s quality dimensions are relevance of statistical concepts, accuracy of estimates, timeliness and punctuality in disseminating results, accessibility and clarity of the information, comparability, coherence, and completeness. See also Biemer and Lyberg (2003), Biemer et al. (2012), and Eurostat (2003, 2009).
In the United States, the National Center for Science and Engineering Statistics (NCSES), formerly the Division of Science Resources Statistics, was established within the National Science Foundation with a general responsibility for statistical data. Part of its mandate is to provide information that is useful to practitioners, researchers, policymakers, and the public. NCSES prepares about 30 reports per year based on surveys.
The purpose of survey standards is to set a framework for assuring data and reporting quality. Guidance documents are meant to help (i) increase the reliability and validity of data, (ii) promote common understanding of desired methodology and processes, (iii) avoid duplication and promote the efficient transfer of ideas, and (iv) remove ambiguities and inconsistencies. The goal is to provide the clearest possible presentations of data and its analysis. Guidelines typically focus on technical issues involved in the work rather than issues of contract management or publication formats.
Specifically, NCSES aims to adhere to the ideals set forth in “Principles and Practices for a Federal Statistical Agency.” As a US federal statistical agency, NCSES surveys must follow guidelines and policies as set forth in the Paperwork Reduction Act and other legislations related to surveys. For example, NCSES surveys must follow the implementation guidance, survey clearance policies, response rate requirements, and related orders prepared by the Office of Management and Budget (OMB). The following standards are based on US government standards for statistical surveys (see www.nsf.gov/statistics/). We list them with an annotation mapping to InfoQ dimensions, when relevant (Table 10.1 summarizes these relationships) See also Office for National Statistics (2007).
Table 10.1 Relationship between NCSES standards and InfoQ dimensions. Shaded cells indicate an existing relationship.


10.3.1 Development of concepts, methods, and designs
10.3.1.1 Survey planning
Standard 1.1: Agencies initiating a new survey or major revision of an existing survey must develop a written plan that sets forth a justification, including goals and objectives, potential users, the decisions the survey is designed to inform, key survey estimates, the precision required of the estimates (e.g., the size of differences that need to be detected), the tabulations and analytic results that will inform decisions and other uses, related and previous surveys, steps taken to prevent unnecessary duplication with other sources of information, when and how frequently users need the data and the level of detail needed in tabulations, confidential microdata, and public‐use data files.
This standard requires explicit declaration of goals and methods for communicating results. It also raises the issue of data resolution in terms of dissemination and generalization (estimate precision).
10.3.1.2 Survey design
Standard 1.2: Agencies must develop a survey design, including defining the target population, designing the sampling plan, specifying the data collection instruments and methods, developing a realistic timetable and cost estimate, and selecting samples using generally accepted statistical methods (e.g., probabilistic methods that can provide estimates of sampling error). Any use of nonprobability sampling methods (e.g., cutoff or model‐based samples) must be justified statistically and be able to measure estimation error. The size and design of the sample must reflect the level of detail needed in tabulations and other data products and the precision required of key estimates. Documentation of each of these activities and resulting decisions must be maintained in the project files for use in documentation (see Standards 7.3 and 7.4).
This standard advises on data resolution, data structure, and data integration. The questionnaire design addresses the issue of construct operationalization, and estimation error relates to generalizability.
10.3.1.3 Survey response rates
Standard 1.3: Agencies must design the survey to achieve the highest practical rates of response, commensurate with the importance of survey uses, respondent burden, and data collection costs, to ensure that survey results are representative of the target population so that they can be used with confidence to inform decisions. Nonresponse bias analyses must be conducted when unit or item response rates or other factors suggest the potential for bias to occur.
The main focus here is on statistical generalization, but this standard also deals with action operationalization. The survey must be designed and conducted in a way that encourages respondents to take action and respond.
10.3.1.4 Pretesting survey systems
Standard 1.4: Agencies must ensure that all components of a survey function as intended when implemented in the full‐scale survey and that measurement error is controlled by conducting a pretest of the survey components or by having successfully fielded the survey components on a previous occasion.
Pretesting is related to data resolution and to the question of whether the collection instrument is sufficiently reliable and precise.
10.3.2 Collection of data
10.3.2.1 Developing sampling frames
Standard 2.1: Agencies must ensure that the frames for the planned sample survey or census are appropriate for the study design and are evaluated against the target population for quality.
Sampling frame development is crucial for statistical generalization. Here we also ensure chronology of data and goal in terms of the survey deployment.
10.3.2.2 Required notifications to potential survey respondents
Standard 2.2: Agencies must ensure that each collection of information instrument clearly states the reasons why the information is planned to be collected, the way such information is planned to be used to further the proper performance of the functions of the agency, whether responses to the collection of information are voluntary or mandatory (citing authority), the nature and extent of confidentiality to be provided, if any (citing authority), an estimate of the average respondent burden together with a request that the public direct to the agency any comments concerning the accuracy of this burden estimate and any suggestions for reducing this burden, the OMB control number, and a statement that an agency may not conduct and a person is not required to respond to an information collection request unless it displays a currently valid OMB control number.
This is another aspect of action operationalization.
10.3.2.3 Data collection methodology
Standard 2.3: Agencies must design and administer their data collection instruments and methods in a manner that achieves the best balance between maximizing data quality and controlling measurement error while minimizing respondent burden and cost.
10.3.3 Processing and editing of data
The standards in Section 10.3.3 are focused on the data component and, in particular, assuring data quality and confidentiality.
10.3.3.1 Data editing
Standard 3.1: Agencies must edit data appropriately, based on available information, to mitigate or correct detectable errors.
10.3.3.2 Nonresponse analysis and response rate calculation
Standard 3.2: Agencies must appropriately measure, adjust for, report, and analyze unit and item nonresponse to assess their effects on data quality and to inform users. Response rates must be computed using standard formulas to measure the proportion of the eligible sample that is represented by the responding units in each study, as an indicator of potential nonresponse bias.
This relates to generalizability.
10.3.3.3 Coding
Standard 3.3: Agencies must add codes to the collected data to identify aspects of data quality from the collection (e.g., missing data) in order to allow users to appropriately analyze the data. Codes added to convert information collected as text into a form that permits immediate analysis must use standardized codes, when available, to enhance comparability.
10.3.3.4 Data protection
Standard 3.4: Agencies must implement safeguards throughout the production process to ensure that survey data are handled confidentially to avoid disclosure.
10.3.3.5 Evaluation
Standard 3.5: Agencies must evaluate the quality of the data and make the evaluation public (through technical notes and documentation included in reports of results or through a separate report) to allow users to interpret results of analyses and to help designers of recurring surveys focus improvement efforts.
This is related to communication.
10.3.4 Production of estimates and projections
10.3.4.1 Developing estimates and projections
Standard 4.1: Agencies must use accepted theory and methods when deriving direct survey‐based estimates, as well as model‐based estimates and projections that use survey data. Error estimates must be calculated and disseminated to support assessment of the appropriateness of the uses of the estimates or projections. Agencies must plan and implement evaluations to assess the quality of the estimates and projections.
This standard is aimed at statistical generalizability and focuses on the quality of the data analysis (deriving estimates can be considered part of the data analysis component).
10.3.5 Data analysis
10.3.5.1 Analysis and report planning
Standard 5.1: Agencies must develop a plan for the analysis of survey data prior to the start of a specific analysis to ensure that statistical tests are used appropriately and that adequate resources are available to complete the analysis.
This standard is again focused on analysis quality.
10.3.5.2 Inference and comparisons
Standard 5.2: Agencies must base statements of comparisons and other statistical conclusions derived from survey data on acceptable statistical practice.
10.3.6 Review procedures
10.3.6.1 Review of information products
Standard 6.1: Agencies are responsible for the quality of information that they disseminate and must institute appropriate content/subject matter, statistical, and methodological review procedures to comply with OMB and agency InfoQ guidelines.
10.3.7 Dissemination of information products
10.3.7.1 Releasing information
Standard 7.1: Agencies must release information intended for the general public according to a dissemination plan that provides for equivalent, timely access to all users and provides information to the public about the agencies’ dissemination policies and procedures including those related to any planned or unanticipated data revisions.
This standard touches on chronology of data and goal and communication. It can also affect temporal relevance of studies that rely on the dissemination schedule.
10.3.7.2 Data protection and disclosure avoidance for dissemination
Standard 7.2: When releasing information products, agencies must ensure strict compliance with any confidentiality pledge to the respondents and all applicable federal legislation and regulations.
10.3.7.3 Survey documentation
Standard 7.3: Agencies must produce survey documentation that includes those materials necessary to understand how to properly analyze data from each survey, as well as the information necessary to replicate and evaluate each survey’s results (see also Standard 1.2). Survey documentation must be readily accessible to users, unless it is necessary to restrict access to protect confidentiality. Proper documentation is essential for proper communication.
10.3.7.4 Documentation and release of public‐use microdata
Standard 7.4: Agencies that release microdata to the public must include documentation clearly describing how the information is constructed and provide the metadata necessary for users to access and manipulate the data (see also Standard 1.2). Public‐use microdata documentation and metadata must be readily accessible to users. This standard is aimed at adequate communication of the data (not the results).
These standards provide a comprehensive framework for the various activities involved in planning and implementing official statistics surveys. Section 10.4 is focused on customer satisfaction surveys such as the surveys on service of general interest (SGI) conducted within the European Union (EU).
10.4 Standards for customer surveys
Customer satisfaction, according to the ISO 10004:2010 standards of the International Organization for Standardization (ISO), is the “customer’s perception of the degree to which the customer’s requirements have been fulfilled.” It is “determined by the gap between the customer’s expectations and the customer’s perception of the product [or service] as delivered by the organization”.
ISO describes the importance of standards on their website: “ISO is a nongovernmental organization that forms a bridge between the public and private sectors. Standards ensure desirable characteristics of products and services such as quality, environmental friendliness, safety, reliability, efficiency, and interchangeability—and at an economical cost.”
ISO’s work program ranges from standards for traditional activities such as agriculture and construction, to mechanical engineering, manufacturing, and distribution, to transport, medical devices, information and communication technologies, and standards for good management practice and for services. Its primary aim is to share concepts, definitions, and tools to guarantee that products and services meet expectations. When standards are absent, products may turn out to be of poor quality, they may be incompatible with available equipment or they could be unreliable or even dangerous
The goals and objectives of customer satisfaction surveys are clearly described in ISO 10004. “The information obtained from monitoring and measuring customer satisfaction can help identify opportunities for improvement of the organization’s strategies, products, processes, and characteristics that are valued by customers, and serve the organization’s objectives. Such improvements can strengthen customer confidence and result in commercial and other benefits.”
We now provide a brief description of the ISO 10004 standard which provides guidelines for monitoring and measuring customer satisfaction. The rationale of the ISO 10004 standard—as reported in Clause 1—is to provide “guidance in defining and implementing processes to monitor and measure customer satisfaction.” It is intended for use “by organizations regardless of type, size, or product provided,” but it is related only “to customers external to the organization.”
The ISO approach outlines three phases in the processes of measuring and monitoring customer satisfaction: planning (Clause 6), operation (Clause 7), and maintenance and improvement (Clause 8). We examine each of these three and their relation to InfoQ. Table 10.2 summarizes these relationships.
Table 10.2 Relationship between ISO 10004 guidelines and InfoQ dimensions. Shaded cells indicate an existing relationship.
| ISO 10004 phase | Data resolution | Data structure | Data integration | Temporal relevance | Data–goal chronology | Generalizability | Operationalization | Communication |
| Planning | ||||||||
| Operation | ||||||||
| Maintenance and improvement |
10.4.1 Planning
The planning phase refers to “the definition of the purposes and objectives of measuring customer satisfaction and the determination of the frequency of data gathering (regularly, on an occasional basis, dictated by business needs or specific events).” For example, an organization might be interested in investigating reasons for customer complaints after the release of a new product or for the loss of market share. Alternatively it might want to regularly compare its position relative to other organizations. Moreover, “Information regarding customer satisfaction might be obtained indirectly from the organization’s internal processes (e.g., customer complaints handling) or from external sources (e.g., reported in the media) or directly from customers.” In determining the frequency of data collection, this clause is related to chronology of data and goal as well as to temporal relevance. The “definition of … customer satisfaction” concerns construct operationalization. The collection of data from different sources indirectly touches on data structure and resolution. Yet, the use of “or” for choice of data source indicates no intention of data integration.
10.4.2 Operation
The operation phase represents the core of the standard and introduces operational steps an organization should follow in order to meet the requirements of ISO 10004. These steps are as follows:
- identify the customers (current or potential) and their expectations
- gather customer satisfaction data directly from customers by a survey and/or indirectly examining existing sources of information, after having identified the main characteristics related to customer satisfaction (product, delivery, or organizational characteristic)
- analyze customer satisfaction data after having chosen the appropriate method of analysis
- communicate customer satisfaction information
- monitor customer satisfaction at defined intervals to control that “the customer satisfaction information is consistent with, or validated by, other relevant business performance indicators” (Clause 7.6.5)
Statistical issues mentioned in ISO 10004 relate to the number of customers to be surveyed (sample size), the method of sampling (Clause 7.3.3.3 and Annex C.3.1, C3.2), and the choice of the scale of measurement (Clause 7.3.3.4 and Annex C.4). Identifying the population of interest and sample design is related to generalization. Communication is central to step (d). Step (e) refers to data integration and the choice of measurement scale is related to data resolution.
10.4.3 Maintenance and improvement
The maintenance and improvement phase includes periodic review, evaluation, and continual improvement of processes for monitoring and measuring customer satisfaction. This phase is aimed at maintaining generalizability and temporal relevance as well as the appropriateness of construct operationalization (“reviewing the indirect indicators of customer satisfaction”). Data integration is used to validate the information against other sources. Communication and actionable operationalization are also mentioned (See Table 10.2).
10.5 Integrating official statistics with administrative data for enhanced InfoQ
As mentioned in the introduction to this chapter, official statistics are produced by a variety of organizations including central bureaus of statistics, regulatory healthcare agencies, educational systems, and national banks. A common trend is the integration of official statistics and organizational data to derive insights at the local and global levels. An example is provided by the Intesa Sanpaolo Bank in Italy that maintains an integrated database for supporting analytic research requests by management and various decision makers (Forsti et al., 2012). The bank uses regression models applied to internal data integrated with data from a range of official statistics providers such as:
- Financial statements (CEBI)
- EPO patents (Thomson Scientific)
- Foreign direct investment (Reprint)
- ISO certificates (ACCREDIA)
- Trademarks (UIBM, OIHM, USPTO, and WIPO)
- Credit ratings (CEBI and Intesa Sanpaolo)
- Corporate group charts (Intesa Sanpaolo)
In this example, the competitiveness of an enterprise was assessed using factors such as innovation and R&D; intangibles (e.g., human capital, brands, quality, and environmental awareness); and foreign direct investment. Some of the challenges encountered in order to obtain a coherent integrated database included incomplete matching using “tax ID No.” as the key since patent, certification, and trademark archives contain only the business name and address of the enterprise. As a result, an algorithm was developed for matching a business name and address to other databases containing both the same information and the tax ID No. With this approach different business names and addresses may appear for the same enterprise (for instance, abbreviated names, acronyms with or without full stops, presence of the abbreviated legal form, etc.). The tax ID No. of an enterprise may also change over the years. Handling these issues properly is key to the quality of information generated by regression analysis. For more details, see Forsti et al. (2012).
This section is about information derived from an analysis of official statistics data integrated with administrative datasets such as the Intesa bank example. We describe the use of graphical models for performing the integration. The objective is to provide decision makers with high‐quality information. We use the InfoQ concept framework for evaluating the quality of such information to decision makers or other stakeholders. We refer here to two case studies analyzed in Dalla Valle and Kenett (2015), one from the field of education and the other from accident reporting. The case studies demonstrate a calibration methodology developed by Dalla Valle and Kenett (2015) for calibrating official statistics with administrative data. For other examples, see Dalla Valle (2014).
10.5.1 Bayesian networks
BNs are directed acyclic graphs (DAGs) whose nodes represent variables and the edges represent causal relationships between the variables. These variables are associated with conditional probability functions that, together with the DAG, are able to provide a compact representation of high‐dimensional distributions. For an introduction and for more details about the definitions and main properties of BNs, see Chapters 7 and 8. These models were applied in official statistics data analysis by Penny and Reale (2004) who used graphical models to identify relevant components in a saturated structural VAR model of the quarterly gross domestic product that aggregates a large number of economic time series. More recently, Vicard and Scanu (2012) also applied BNs to official statistics, showing that the use of poststratification allows integration and missing data imputation. For general applications of BNs, see Kenett and Salini (2009), Kenett and Salini (2012), and Kenett (2016). For an application of BNs in healthcare, see Section 8.4.
10.5.2 Calibration methodology
The methodology proposed by Dalla Valle and Kenett (2015) increases InfoQ via data integration of official and administrative information, thus enhancing temporal relevance and chronology of data and goal. The idea is in the same spirit of external benchmarking used in small area estimation (Pfeffermann, 2013). In small area estimation, benchmarking robustifies the inference by forcing the model‐based predictors to agree with a design‐based estimator. Similarly, the calibration methodology by Dalla Valle and Kenett (2015) is based on qualitative data calibration performed via conditionalizing graphical models, where official statistics estimates are updated to agree with more timely administrative data estimates. The calibration methodology is structured in three phases:
- Phase 1: Data structure modeling. This phase consists of conducting a multivariate data analysis of the official statistics and administrative datasets, using graphical models such as vines and BNs. Vines are a flexible class of multivariate copulas based on the decomposition of a multivariate copula using bivariate (conditional) copulas as building blocks. Vines are employed to model the dependence structure among the variables, and the results are used to construct the causal relationships with a BN.
- Phase 2: Identification of the calibration link. In the second phase, a calibration link, in the form of common correlated variables, is identified between the official statistics and the administrative data.
- Phase 3: Performing calibration. In the last phase, the BNs of both datasets are conditioned on specific “target” variables in order to perform calibration, taking into account the causal relationship among the variables.
These phases are applied to each of the datasets to be integrated. In Sections 10.5.3 and 10.5.4, we demonstrate the application of these three phases using case studies from education and transportation.
10.5.3 The Stella education case study
10.5.3.1 Stella dataset
The dataset used here was collected by the Italian Stella association in 2009. Stella is an interuniversity initiative aiming at cooperation and coordination of the activities of supervision, statistical analysis, and evaluation of the graduate and postgraduate paths. The initiative includes universities from the north and the center of Italy. The Stella dataset contains information about postdoctoral placements after 12 months for graduates who obtained a PhD in 2005, 2006, and 2007. The dataset includes 665 observations and eight variables.
The variables are as follows:
- yPhD: year of PhD completion
- ybirth: year of birth
- unistart: starting year of university degree
- hweek: working hours per week
- begsal: initial net monthly salary in euro
- lastsal: last net monthly salary in euro
- emp: number of employees
- estgrow: estimate of net salary rise in 2011 by percent
10.5.3.2 Graduates dataset
The second dataset contains information collected through an internal small survey conducted locally in a few universities of Lombardy, in Northern Italy, and in Rome. The sample survey on university graduates’ vocational integration is based on interviews with graduates who attained the university degree in 2004. The survey aims at detecting graduates’ employment conditions about four years after graduation. From the initial sample, the researchers only considered those individuals who concluded their PhD and are currently employed. After removing the missing values, they obtained a total of 52 observations. The variables in this dataset are as follows:
- mdipl: diploma final mark
- nemp: number of employees
- msalary: monthly net salary in euros
- ystjob: starting year of employment
10.5.3.3 Combining the Stella and Graduates datasets
We now describe the approach taken by Dalla Valle and Kenett (2015) for integrating the Stella data with the Graduates data for the purpose of updating the 2004 survey data with 2009 data from the Stella data.
Operations on Stella dataset:
- Data structure modeling. A vine copula was applied to the Stella dataset in order to explore the dependence structure of the marginal distributions. The strongest dependencies were between begsal and lastsal. Moreover, the last salary (lastsal) is associated with the estimate of salary growth (estgrow) and with the number of employees of the company (emp). We notice two groups of variables: one group includes variables regarding the company (begsal, lastsal, estgrow, and emp) and the other group includes variables regarding the individual (yPhD, ybirth, and unistart). The variable hweek is only dependent on lastsal conditional on emp. The vine model will help to determine the conditional rank correlations, which are necessary to define the corresponding BN. The BN represented in Figure 10.1 is the best network obtained by model validation, where statistical tests support the validity of the BN.
- Identification of the calibration link. The calibration link used here is the lastsal variable. This decision was reached by discussion with education experts and is therefore subjective and context related.
- Performing calibration. For calibration purposes, the Stella dataset is conditioned on a lower value of lastsal, similar to the average salary value of the Graduates dataset. In order to reach this lower value of salary, begsal, estgrow, and emp had to be decreased, as shown in Figure 10.2.
Furthermore, the Stella dataset is conditioned on a low value of begsal and emp and for a high value of yPhD. The variable yPhD is considered as a proxy of the starting year of employment, used in the Graduates dataset. In this case, the average salary decreases to a figure similar to the average value of the Graduates dataset, as in Figure 10.3.
Operations on Graduates dataset:
- Data structure modeling. The researchers applied a vine copula to the Graduates dataset to explore the dependence structure of the marginals. Here the monthly salary is associated with the diploma final mark. The monthly salary is also associated with the number of employees only conditionally on the diploma final. They then applied the BN to the Graduates data, and the network in Figure 10.4 is the best one obtained by model validation.
- Identification of the calibration link. The calibration link is the msalary variable, which is analogous to lastsal in the official dataset.
- Performing calibration. For calibration purposes, the Graduates dataset is conditioned on a high value of msalary, similar to the average salary value of the Stella dataset. In order to reach this higher value of salary, both mdipl and nemp need to be increased, as in Figure 10.5. Finally, the Graduates dataset is conditioned on a high value of mdipl and nemp and for a low value of ystjob. In this case, the average salary increases, as in Figure 10.6.
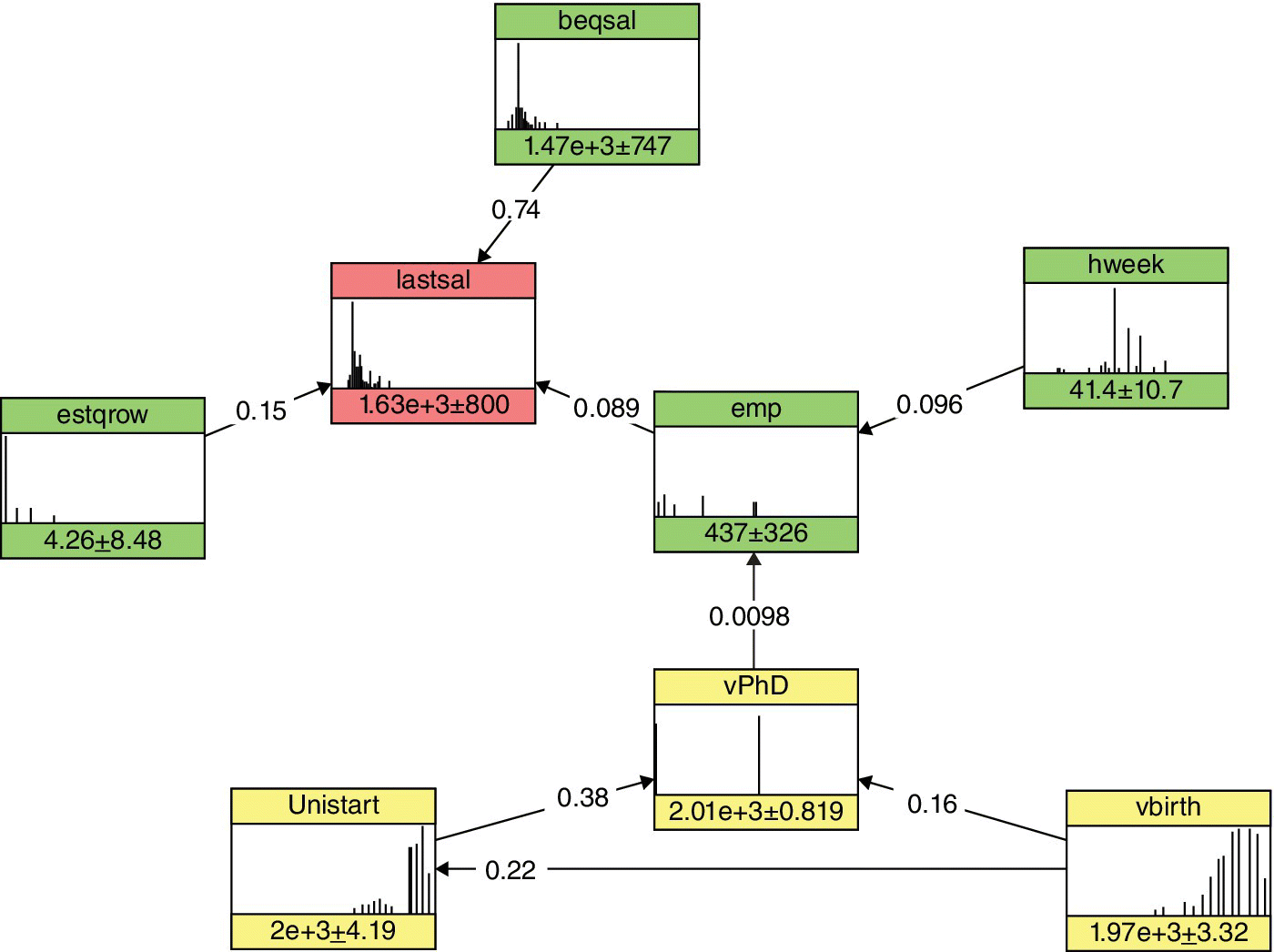
Figure 10.1 BN for the Stella dataset.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.
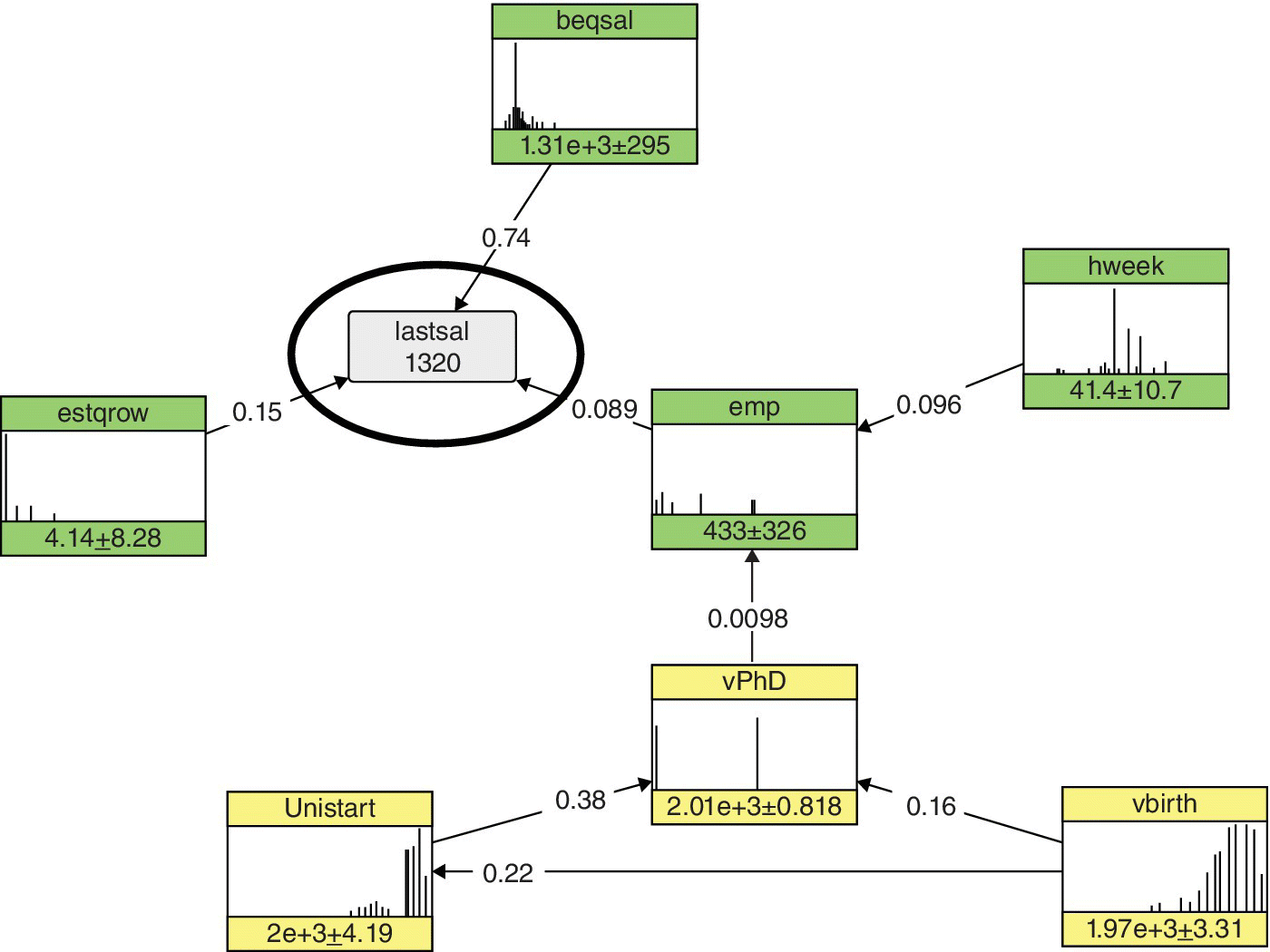
Figure 10.2 BN is conditioned on a value of lastsal which is similar to the salary value of the Graduates dataset.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.

Figure 10.3 BN is conditioned on a low value of begsal and emp and for a high value of yPhD.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.
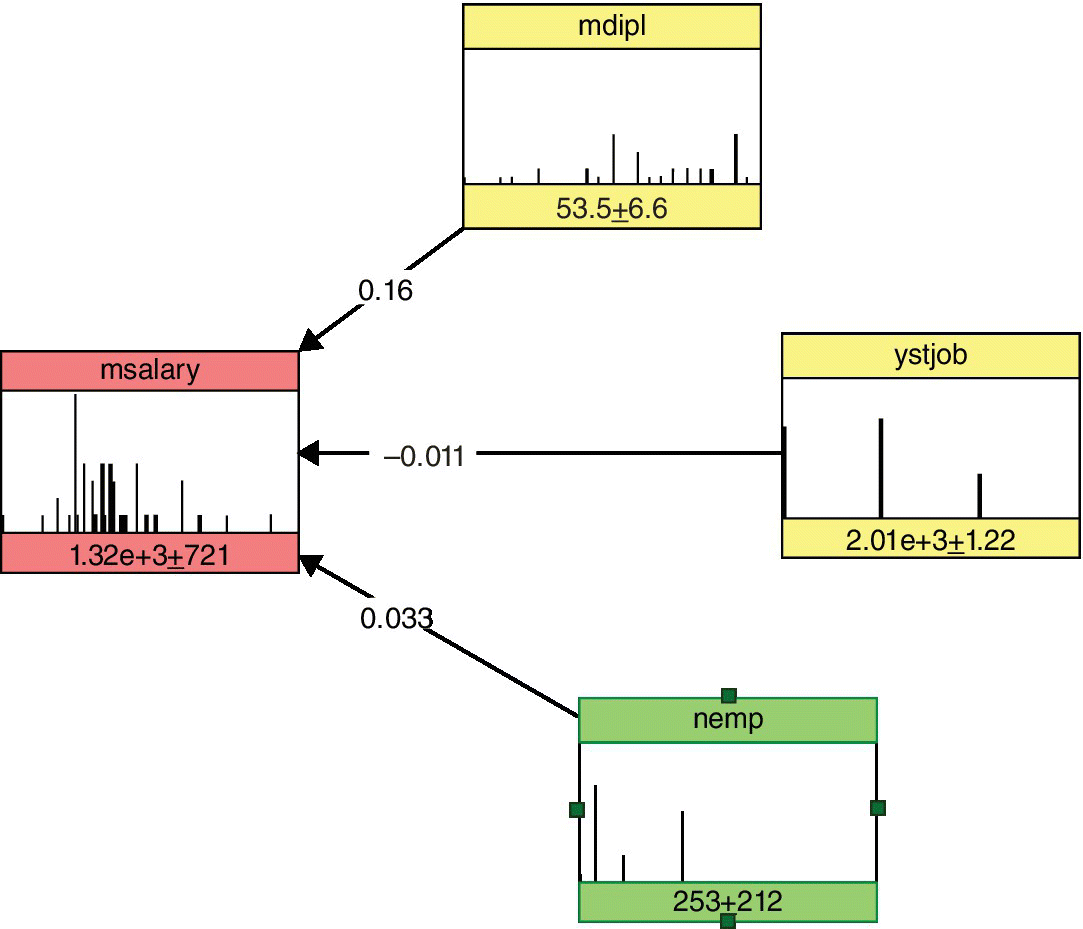
Figure 10.4 BN for the Graduates dataset.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.

Figure 10.5 BN is conditioned on a high value of msalary.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.
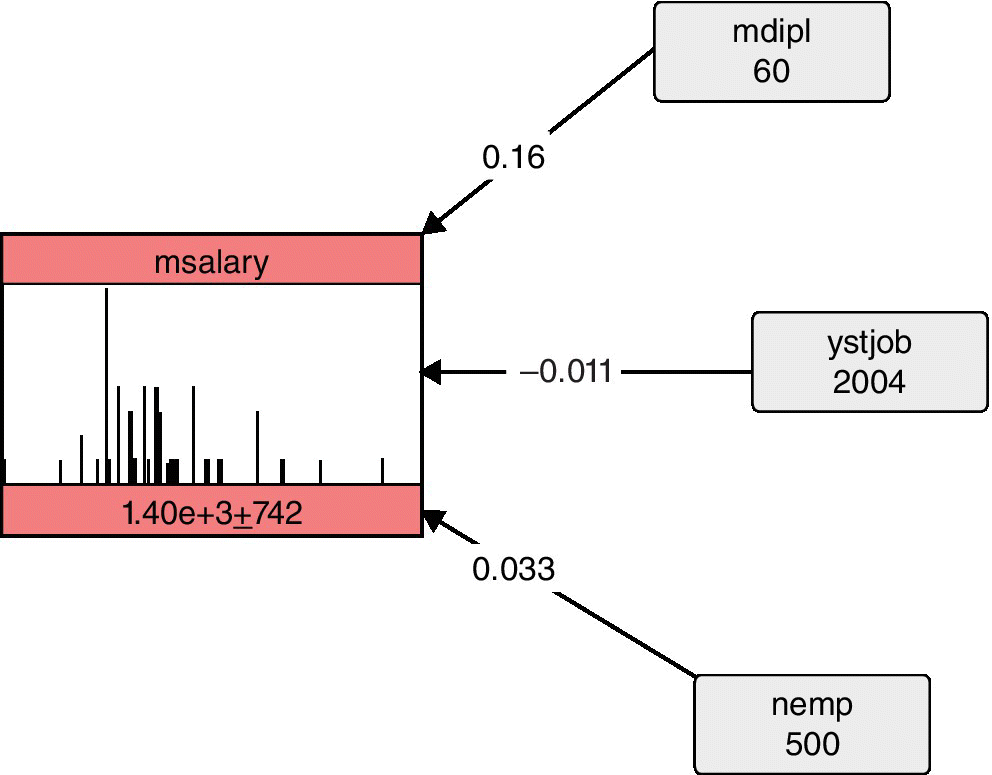
Figure 10.6 BN is conditioned on a high value of mdipl and nemp and for a low value of ystjob.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.
10.5.3.4 Stella education case study: InfoQ components
- Goal (g): Evaluating the working performance of graduates and understanding the influence on the salary of company‐related variables and individual‐related variables.
- Data (X): Combined survey data with official statistics on education.
- Analysis (f): Use of vines and BNs to model the dependence structure of the variables in the data set and to calculate the conditional rank correlations.
- Utility (U): Assisting policymakers to monitor the relationship between education and the labor market, identifying trends and methods of improvement.
10.5.3.5 Stella education case study: InfoQ dimensions
- Data resolution. Concerning the aggregation level, the data is collected at the individual level in the Graduates and Stella datasets, aligned with the study goal. The Graduates dataset contains information collected through an internal small survey conducted locally in a few Italian universities. Although the data collection should comply with a good standard of accuracy, detailed information about the data collection is not available for this dataset. Stella data is monitored by the authority of a consortium of a large number of universities, guaranteeing the reliability and precision of the data produced. The Graduates survey was produced for a specific study conducted internally by a few universities and data is not collected on a regular basis, while Stella produces periodic annual reports about education at a large number of Italian institutions. Considering the analysis goal of regularly monitoring the performance of the graduates in the labor market, there is still room for improvement for the level of InfoQ generated by this dimension, especially on the data resolution of the Graduates dataset.
- Data structure. The type and structure of education data of both datasets are perfectly aligned with the goal of understanding the influence of different factors on the graduates’ salary. Both datasets include continuous and categorical information based on self‐reporting. Although the Stella data integrity is guaranteed by educational institution authorities, the dataset contained a small percentage of missing data, which was removed before implementing the methodology. The Graduates dataset contained a certain number of missing data, which was removed from the dataset. Information describing the corruptness of the data is unavailable. The level of InfoQ could be improved, especially for the Graduates dataset.
- Data integration. This methodology allows the integration of multiple sources of information, that is, official statistics and survey data. The methodology performs integration through data calibration, incorporating the dependence structure of the variables using vines and BNs. Multiple dataset integration creates new knowledge regarding the goal of understating the influence of company and individual variables on graduates’ salary, thereby enhancing InfoQ.
- Temporal relevance. To make the analysis effective for its goals, the time gaps between the collection, analysis, and deployment of this data should be of short duration, and the time horizon from the first to the last phase should not exceed one year. Stella data is updated annually and made available within a few months, while for the Graduates data, we do not have specific information about the time period between the data collection and deployment. Considering the goal of assisting policymakers to annually monitor the labor market and to allocate education resources, this dimension produces a reasonably good level of InfoQ, which could be increased by a more timely availability of the Graduates survey data. Moreover, the analysis of year 2009 could be made relevant to recent years (e.g., 2014) by calibrating the data with dynamic variables, which would enable updating the study information and in turn enhancing InfoQ.
- Chronology of data and goal. Vines allow calculating associations among variables and identifying clusters of variables. Moreover, nonparametric BNs allow predictive and diagnostic reasoning through the conditioning of the output. Therefore, the methodology is highly effective for obtaining the goal of identifying and understanding the causal structure between variables.
- Generalizability. The diagnostic and predictive capabilities of BNs provide generalizability to population subsets. The Graduates survey is generalized by calibration with the Stella dataset to a large population including several universities. However, we could still improve InfoQ by calibrating the data with variables referring to other institutions in order to make the study fully generalizable at a national level.
- Operationalization. The methodology allows monitoring the performance on the labor market of graduates, describing the causal relationships between the salary and variables related to individuals and companies. Moreover, via conditioning, it allows us to calibrate the results on education obtained by small surveys with the results obtained by official sources. Therefore, the outputs provided from the model are highly useful to policymakers. The use of a model with conditioning capabilities provides an effective tool to set up improvement goals and to detect weaknesses in the education system and in its relationship with industries.
- Communication. The graphical representations of vines and BN are particularly effective for communicating to technical and non‐technical audiences. The visual display of a BN makes it particularly appealing to decision makers who feel uneasy with mathematical or other nontransparent models.
Based on this analysis, we summarize the InfoQ scores for each dimension as shown in Table 10.3. The overall InfoQ score for this study is 74%.
Table 10.3 Scores for InfoQ dimensions for Stella education case study.
| InfoQ dimension | Score |
| Data resolution | 3 |
| Data structure | 3 |
| Data integration | 5 |
| Temporal relevance | 3 |
| Chronology of data and goal | 5 |
| Generalizability | 4 |
| Operationalization | 5 |
| Communication | 5 |
Scores are on a 5‐point scale.
10.5.4 NHTSA transport safety case study
The second case study is based on the Vehicle Safety dataset. The National Highway Traffic Safety Administration (NHTSA), under the US Department of Transportation, was established by the Highway Safety Act of 1970, as the successor to the National Highway Safety Bureau, to carry out safety programs under the National Traffic and Motor Vehicle Safety Act of 1966 and the Highway Safety Act of 1966. NHTSA also carries out consumer programs established by the Motor Vehicle Information and Cost Savings Act of 1972 (www.nhtsa.gov). NHTSA is responsible for reducing deaths, injuries, and economic losses resulting from motor vehicle crashes. This is accomplished by setting and enforcing safety performance standards for motor vehicles and motor vehicle equipment and through grants to state and local governments to enable them to conduct effective local highway safety programs. NHTSA investigates safety defects in motor vehicles; sets and enforces fuel economy standards; helps states and local communities to reduce the threat of drunk drivers; promotes the use of safety belts, child safety seats, and air bags; investigates odometer fraud; establishes and enforces vehicle anti‐theft regulations; and provides consumer information on motor vehicle safety topics. NHTSA also conducts research on driver behavior and traffic safety to develop the most efficient and effective means of bringing about safety improvements.
10.5.4.1 Vehicle Safety dataset
The Vehicle Safety data represents official statistics. After removing the missing data, we obtain a final dataset with 1241 observations, where each observation includes 14 variables on a car manufacturer, between the late 1980s and the early 1990s. The variables are as follows:
- HIC: Head Injury, based on the resultant acceleration pulse for the head centre of gravity
- T1: Lower Boundary of the time interval over which the HIC was computed
- T2: Upper Boundary of the time interval over which the HIC was computed
- CLIP3M: Thorax Region Peak Acceleration, the maximum three‐millisecond “clip” value of the chest resultant acceleration
- LFEM: Left Femur Peak Load Measurement, the maximum compression load for the left femur
- RFEM: Right Femur Peak Load Measurement, the maximum compression load for the right femur
- CSI: Chest Severity Index
- LBELT: Lap Belt Peak Load Measurement, the maximum tension load on the lap belt
- SBELT: Shoulder Belt Peak Load Measurement, the maximum tension load on the shoulder belt
- TTI: Thoracic Trauma Index, computed on a dummy from the maximum rib and lower spine peak accelerations
- PELVG: Pelvis Injury Criterion, the peak lateral acceleration on the pelvis
- VC: Viscous Criterion
- CMAX: Maximum Chest Compression
- NIJ: Neck Injury Criterion
10.5.4.2 Crash Test dataset
The Crash Test dataset contains information about vehicle crash tests collected by a car manufacturer company for marketing purposes. The data contains variables measuring injuries of actual crash tests and is collected following good accuracy standards. We consider this data as administrative or organizational data.
The dataset is a small sample of 176 observations about vehicle crash tests. A range of US‐made vehicles containing dummies in the driver and front passenger seats were crashed into a test wall at 35 miles/hour and information was collected, recording how each crash affected the dummies. The injury variables describe the extent of head injuries, chest deceleration, and left and right femur load. The data file also contains information on the type and safety features of each vehicle. A brief description of the variables within the data is provided as follows:
- Head_IC: Head injury criterion
- Chest_decel: Chest deceleration
- L_Leg: Left femur load
- R_Leg: Right femur load
- Doors: Number of car doors in the car
- Year: Year of manufacture
- Wt: Vehicle weight in pounds
10.5.4.3 Combining the Vehicle Safety and Crash Test datasets
We now describe the graphical approach for combining the official and administrative datasets.
Operations on Vehicle Safety dataset
- Data structure modeling. Dalla Valle and Kenett (2015) applied a Gaussian regular vine copula to the Vehicle Safety dataset to explore the dependence structure of the marginal distributions. There are strong dependencies among most of the variables, for example, between CMAX and CSI. The variable CLIP3M is only dependent on CMAX conditional on LBELT. The vine model helps determine the conditional rank correlations, necessary for defining the corresponding BN. The researchers then applied a BN to the Vehicle Safety data. Figure 10.7 represents the BN for the Vehicle Safety data, where the nodes RFEM, HIC, LFEM, and CSI represent the variables also present in the Crash Test dataset. The BN in Figure 10.7 is the best network obtained by model validation.
- Identification of the calibration link. The calibration links are the HIC, CSI, LFEM, and RFEM variables, which are analogous, respectively, to Head_IC, Chest_decel, L_Leg, and R_Leg in the Crash Test dataset.
- Performing calibration. For calibration purposes, the Vehicle Safety dataset is conditioned on a low value of RFEM, similar to the average values of the Crash Test dataset, and a slightly higher value of CLIP3M. When changing the right femur and thorax region load values, HIC decreases, while CSI increases, becoming very similar to the corresponding values of the Crash Test dataset, as in Figure 10.7. Furthermore, the Vehicle Safety dataset is conditioned on a high value of CSI and for a low value of HIC, similar to the corresponding values of the Crash Test dataset (Figure 10.7). In this case, the left and right femur loads decrease, becoming closer to the corresponding average values of the Crash Test dataset.
Operations on Crash Test dataset
- Data structure modeling. The researchers applied a vine copula to the Crash Test dataset to explore the dependence structure of the marginal distributions. Here the chest deceleration is associated with the head injury criterion and with the vehicle weight. The chest deceleration is associated with the left femur load only conditionally on the head injury criterion.
- Identification of the calibration link. The researchers applied the BN to the Crash Test data. Figure 10.8 displays the best network obtained by model validation for the Crash Test data. The nodes Year, Doors, and Wt denote car type variables, and the other nodes denote injury variables.
- Performing calibration. For calibration purposes, the Crash Test dataset is conditioned on a high value of Wt and Year (diagnostic reasoning). We notice from the changes in Chest.decel and Head.IC that a recent and lighter vehicle is safer and causes less severe injuries (Figure 10.9). Finally, the Crash Test dataset is conditioned on a low value of Wt and Year. An older and heavier vehicle is less safe and causes more severe injuries (Figure 10.10).
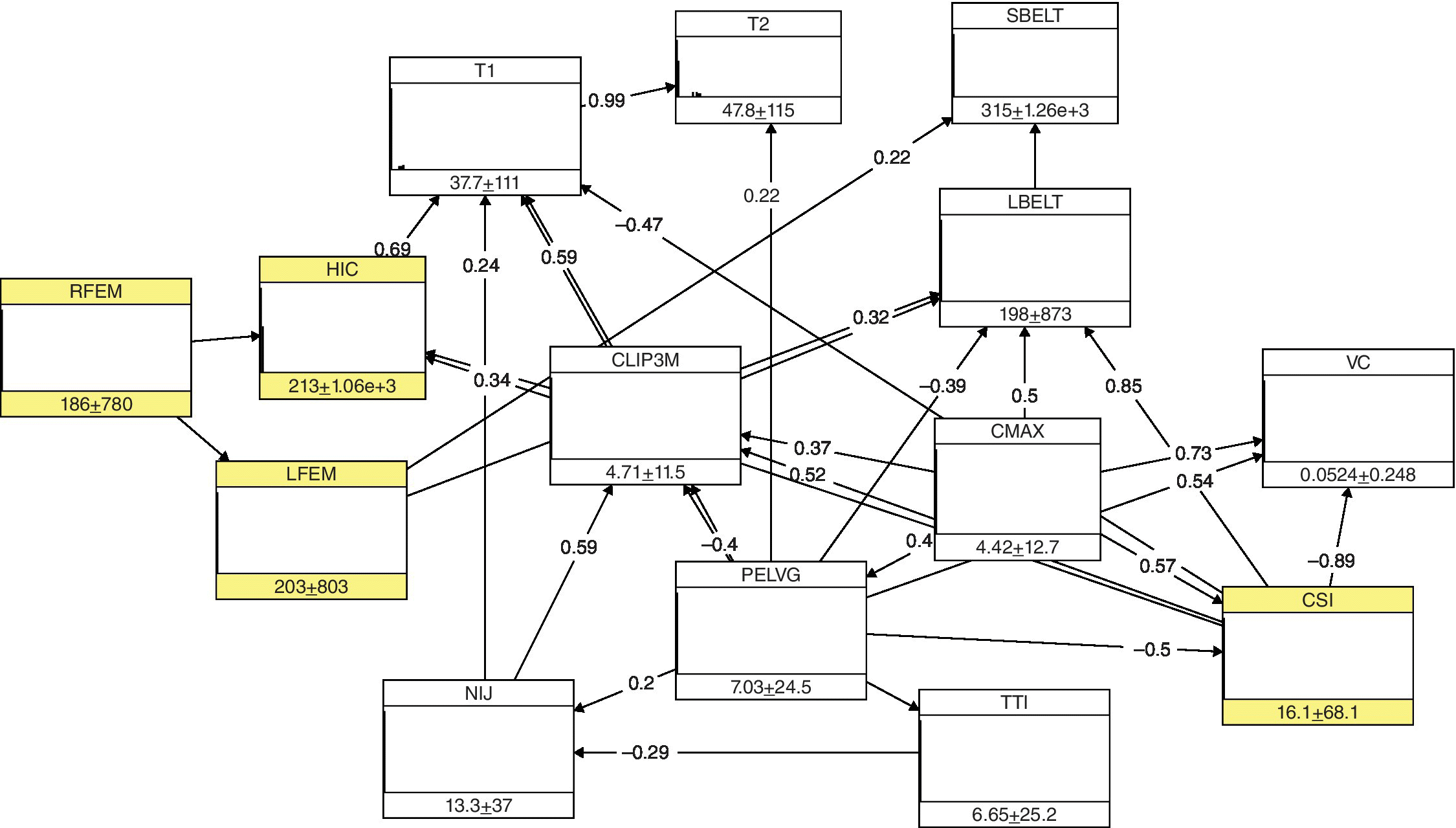
Figure 10.7 BN for the Vehicle Safety dataset.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.
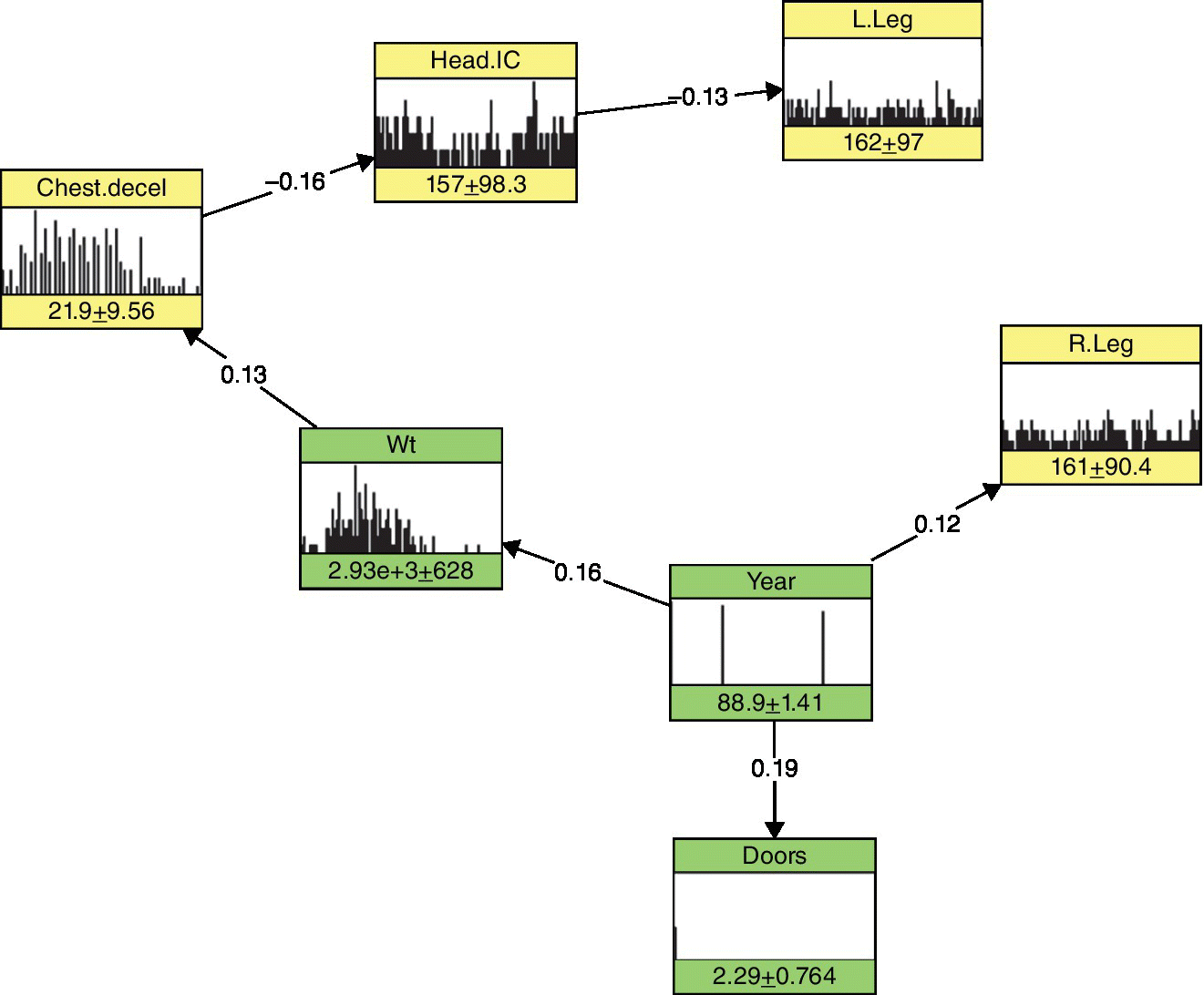
Figure 10.8 BN for the Crash Test dataset.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.

Figure 10.9 BN for the Crash Test dataset is conditioned on a high value of Wt and Year.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.
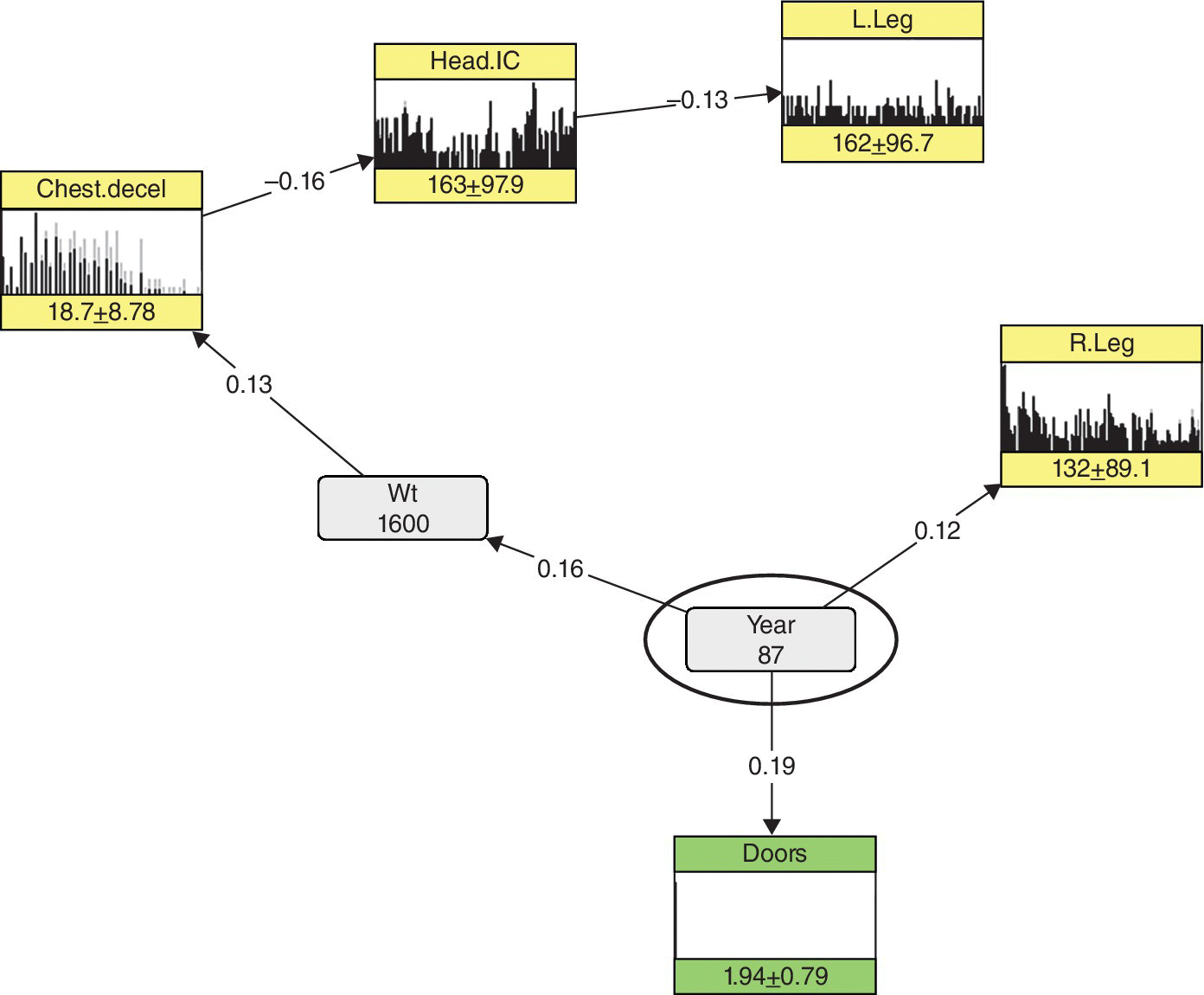
Figure 10.10 BN for the Crash Test dataset is conditioned on a low value of Wt and Year.
Source: Dalla Valle and Kenett (2015). Reproduced with permission of John Wiley & Sons, Inc.
10.5.4.4 NHTSA safety case study: InfoQ components
- Goal (g): Assessing motor vehicle’s safety and evaluating the severities of injuries resulting from motor vehicle crashes.
- Data (X): Combined small sample of Crash Test data with motor vehicle’s safety official statistics.
- Analysis (f): Use of vines and BNs to model the dependence structure of the variables in the data set and to calculate the conditional rank correlations.
- Utility (U): Assisting policymakers to set safety performance standards for motor vehicles and motor vehicle equipment, aiming at improving the overall safety of vehicles and therefore reducing deaths, injuries, and economic losses resulting from motor vehicle crashes.
10.5.4.5 NHTSA transport safety case study: InfoQ dimensions
- Data Resolution. Concerning the aggregation level, the data is collected at crash test level in the Vehicle Safety as well as in the Crash Test dataset, aligned with the study goal. The Crash Test dataset contains information about vehicle crash tests collected by a car manufacturer company for marketing purposes. The data contains variables measuring injuries of actual crash tests and is collected following good accuracy standards. The Vehicle Safety data is monitored by the US NHTSA, guaranteeing the reliability and precision of the data. The Crash Test dataset was produced for a specific study conducted internally by a car company and the data is not collected on a regular basis, while the NHTSA produces periodic reports about transport safety of a large range of motor vehicles. Considering the analysis goal of regularly evaluating motor vehicle safety, there is still room for improvement for the level of InfoQ generated by this dimension, especially on the data resolution of the Crash Test dataset.
- Data structure. The type and structure of car safety data of both datasets are perfectly aligned with the goal of assessing motor vehicle safety and evaluating the severities of injuries resulting from motor vehicle crashes. The data includes continuous and categorical variables. Although the Vehicle Safety data integrity is guaranteed by the NHTSA, the dataset contained a small percentage of missing data, which was removed before implementing the methodology. The Crash Test dataset did not contain missing data and an exploratory data analysis revealed no corruptness in the data. The level of InfoQ for this dimension is therefore high.
- Data integration. The calibration methodology allows the integration of multiple sources of information, that is, official statistics and marketing data. The methodology performs integration though data calibration, incorporating the dependence structure of the variables using vines and BNs. Multiple dataset integration creates new knowledge regarding the goal of assessing motor vehicle safety and evaluating the severities of injuries resulting from motor vehicle crashes, thereby enhancing InfoQ.
- Temporal relevance. The time gaps between the collection, analysis, and deployment of this data should be of short duration, to make the analysis effective for its goals. Vehicle Safety data is updated quarterly and made available within a few months, while for the Crash Test data we do not have specific information about the time period between the data collection and deployment. Considering the goal of assisting policymakers to set safety performance standards for motor vehicles and motor vehicle equipment, this dimension produces a reasonably good level of InfoQ, which could be increased by a more timely availability of the Crash Test data. Moreover, the analysis of the 1987–1992 cars could be easily made relevant to recent years (e.g., 2014) by updating the data to include more recent vehicle models, thereby enhancing InfoQ.
- Chronology of data and goal. Vines allow calculating associations among variables and identifying clusters of variables. Moreover, nonparametric BNs allow predictive and diagnostic reasoning though the conditioning of the output. Therefore, the methodology is highly effective for obtaining the goal of identifying and understanding the causal structure between variables.
- Generalizability. The diagnostic and predictive capabilities of BNs provide generalizability to population subsets. The Crash Test survey is generalized by calibration with the Vehicle Safety dataset to a large range of motor vehicles population, enhancing InfoQ.
- Operationalization. The construct safety is operationalized in both datasets using similar measurements. The methodology allows assessing motor vehicle safety and evaluating the severities of injuries resulting from motor vehicle crashes, describing the causal relationships between injuries in various parts of the body, in case of an accident, and the type of vehicle. Moreover, via conditioning, it allows us to calibrate the results on vehicle safety obtained by small datasets with the results obtained by official sources. Therefore, the outputs provided from the model are highly useful to policymakers, to set guidelines aiming at improving the overall safety of vehicles. The use of a model with conditioning capabilities provides an effective tool to set up improvement goals and to detect weaknesses in transport safety.
- Communication. The graphical representations of vines and BNs are particularly effective for communicating with technical as well as non‐technical audiences. The visual display of a BN makes it particularly appealing to decision makers who feel uneasy with mathematical or other nontransparent models.
Based on this analysis, we summarize the InfoQ scores for each dimension as shown in Table 10.4. The overall InfoQ score for this study is 81%.
Table 10.4 Scores for InfoQ dimensions for the NHTSA safety case study.
| InfoQ dimension | Score |
| Data resolution | 3 |
| Data structure | 4 |
| Data integration | 5 |
| Temporal relevance | 3 |
| Chronology of data and goal | 5 |
| Generalizability | 5 |
| Operationalization | 5 |
| Communication | 5 |
Scores are on a 5‐point scale.
10.6 Summary
With the increased availability of data sources and ubiquity of analytic technologies, the challenge of transforming data to information and knowledge is growing in importance (Kenett, 2008). Official statistics play a critical role in this context and applied research, using official statistics, needs to ensure the generation of high InfoQ (Kenett and Shmueli, 2014, 2016). In this chapter, we discussed the various elements that determine the quality of such information and described several proposed approaches for achieving it. We compared the InfoQ concept with NCSES and ISO standards and also discussed examples of how official statistics data and data from internal sources are integrated to generate higher InfoQ.
The sections on quality standards in official statistics and ISO standards related to customer surveys discuss aspects related to five of the InfoQ dimensions: data resolution, data structure, data integration, temporal relevance, and chronology of data and goal. Considering each of these InfoQ dimensions with their associated questions can help in increasing InfoQ. The chapter ends with two examples where official statistics datasets are combined with organizational data in order to derive, through analysis, information of higher quality. An analysis using BNs permits the calibration of the data, thus strengthening the quality of the information derived from the official data. As before, the InfoQ dimensions involved in such calibration include data resolution, data structure, data integration, temporal relevance, and chronology of data and goal. These two case studies demonstrate how concern for the quality of the information derived from an analysis of a given data set requires attention to several dimensions, beyond the quality of the analysis method used. The eight InfoQ dimensions provide a general template for identifying and evaluating such challenges.
References
- Biemer, P. and Lyberg, L. (2003) Introduction to Survey Quality. John Wiley & Sons, Inc., Hoboken.
- Biemer, P.P., Trewin, D., Bergdahl, H., Japec, L. and Pettersson, Å. (2012) A Tool for Managing Product Quality. European Conference on Quality in Official Statistics, Athens.
- Dalla Valle, L. (2014) Official statistics data integration using copulas. Quality Technology and Quantitative Management, 11(1), pp. 111–131.
- Dalla Valle, L. and Kenett, R.S. (2015) Official statistics data integration to enhance information quality. Quality and Reliability Engineering International. 10.1002/qre.1859.
- David, L., Kennedy, R., King, G. and Vespignani, A. (2014) The parable of Google Flu: traps in big data analysis. Science, 343(14), pp. 1203–1205.
- Deming, W.E. (1982) Out of the Crisis. MIT Press, Cambridge, MA.
- EPA (2005) Uniform Federal Policy for Quality Assurance Project Plans: Evaluating, Assessing, and Documenting Environmental Data Collection and Use Programs. https://www.epa.gov/sites/production/files/documents/ufp_qapp_v1_0305.pdf (accessed May 20, 2016).
- Eurostat (2003) Standard Quality Report. Eurostat, Luxembourg.
- Eurostat (2009) Handbook for Quality Reports. Eurostat, Luxembourg.
- Figini, S., Kenett, R.S. and Salini, S. (2010) Integrating operational and financial risk assessments. Quality and Reliability Engineering International, 26, pp. 887–897.
- Forbes, S. and Brown, D. (2012) Conceptual thinking in national statistics offices. Statistical Journal of the IAOS, 28, pp. 89–98.
- Forsti, G., Guelpa, F. and Trenti, S. (2012) Enterprise in a Globalised Context and Public and Private Statistical Setups. Proceedings of the 46th Scientific Meeting of the Italian Statistical Society (SIS), Rome.
- Ginsberg, J., Mohebbi, M.H., Patel, R.S., Brammer, L., Smolinski, M.S. and Brilliant, L (2009) Detecting influenza epidemics using search engine query. Nature, 457, pp. 1012–1014.
- Giovanini, E. (2008) Understanding Economic Statistics. OECD Publishing, Paris, France.
- Goldenberg, A., Shmueli, G., Caruana, R.A. and Fienberg, S.E. (2002) Early statistical detection of anthrax outbreaks by tracking over‐the‐counter medication sales. Proceedings of the National Academy of Sciences, 99 (8), pp. 5237–5240.
- Good, D. and Irwin, S. (2011) USDA Corn and Soybean Acreage Estimates and Yield Forecasts: Dispelling Myths and Misunderstandings, Marketing and Outlook Briefs, Farmdoc, http://farmdoc.illinois.edu/marketing/mobr/mobr_11‐02/mobr_11‐02.html (accessed May 20, 2016).
- Goodman, D. and Hambleton, R.K. (2004) Student test score reports and interpretive guides: review of current practices and suggestions for future research. Applied Measurement in Education, 17(2), pp. 145–220.
- Hambleton, R.K. (2002) How Can We Make NAEP and State Test Score Reporting Scales and Reports More Understandable?, in Assessment in Educational Reform, Lissitz, R.W. and Schafer, W.D. (editors), Allyn & Bacon, Boston, MA, pp. 192–205.
- Kenett, R.S. (2008) From data to information to knowledge. Six Sigma Forum Magazine, November 2008, pp. 32–33.
- Kenett, R.S. (2016) On generating high InfoQ with Bayesian networks. Quality Technology and Quantitative Management, http://www.tandfonline.com/doi/abs/10.1080/16843703.2016.1189182?journalCode=ttqm20 (accessed May 5, 2016).
- Kenett, R.S. and Salini, S. (2009) New Frontiers: Bayesian networks give insight into survey‐data analysis. Quality Progress, August, pp. 31–36.
- Kenett, R.S. and Salini, S. (2012) Modern Analysis of Customer Satisfaction Surveys: With Applications Using R. John Wiley & Sons, Ltd, Chichester, UK.
- Kenett, R.S. and Shmueli, G. (2014) On information quality (with discussion). Journal of the Royal Statistical Society, Series A, 177(1), pp. 3–38.
- Kenett, R.S. and Shmueli, G. (2016) From quality to information quality in official statistics, Journal of Official Statistics, in press.
- Lazer, D., Kennedy, R., King, G. and Vespignan, A. (2014) The parable of Google flu: traps in big data analysis. Science, 343, pp. 1203–1205.
- Marbury, D. (2014) Google Flu Trends collaborates with CDC for more accurate predictions. Medical Economics, November 5, http://medicaleconomics.modernmedicine.com/medical‐economics/news/google‐flu‐trends‐collaborates‐cdc‐more‐accurate‐predictions (accessed May 20, 2016).
- Office for National Statistics (2007) Guidelines for Measuring Statistical Quality. Office for National Statistics, London.
- Penny, R.N. and Reale, M. (2004) Using graphical modelling in official statistics. Quaderni di Statistica, 6, pp. 31–48.
- Pfeffermann, D. (2013) New important developments in small area estimation. Statistical Science, 28 (1), pp. 40–68.
- Shmueli, G. and Burkom, H (2010) Statistical challenges facing early outbreak detection in biosurveillance. Technometrics, 52(1), 39–51.
- Vicard, P. and Scanu, M. (2012) Applications of Bayesian Networks in Official Statistics, in Advanced Statistical Methods for the Analysis of Large Data‐Sets, Di Ciaccio, A., Coli, M. and Angulo Ibanez, J.M. (editors), Springer, Heidelberg, Germany, pp. 113–123.