
Chapter 5
Files, Directories, and the File System
The logical and physical implementations of file systems are covered in this chapter. The logical view of a file system is the organizational units of files, directories, and partitions. The physical implementation is the translation from the logical view to the physical location on disk storage of the file components. File systems of both DOS/Windows and Linux are presented including the top level directories and the implementation of block indexing. The chapter concludes with a section that explores how to navigate through the file systems using command line instructions.
The learning objectives of this chapter are to
- Describe the elements of the file system from both the logical and physical viewpoint.
- Describe how files are physically stored and accessed.
- Present the use of the top level directories in both Windows and Linux.
- Illustrate through example Linux and DOS commands to navigate around a file system.
In this chapter, we will examine the components of a file system and look specifically at both the Windows file system and the Unix/Linux file system.
Files and Directories
A file system exists at two levels of abstraction. There is the physical nature of the file system—the data storage devices, the file index, and the mapping process of taking a name and identifying its physical location within the hard disks (and other storage media). There is also the logical nature of the file system—how the physical system is partitioned into independently named entities. As both users and system administrators, we are mostly interested in the logical file system. The details for how the files and directories are distributed only becomes of interest when we must troubleshoot our file system (e.g., corrupt files, the need to defragment the file system). We will take a brief look at the physical nature of file systems later in this chapter, but for now, we will concentrate on the logical side.
In a file system, you have three types of entities:
- Partitions
- Directories
- Files
A partition is a logical division within the file system. In Windows, a partition is denoted using a letter, for instance C: versus D: might both refer to parts of the hard disk, but to two separate partitions. In Linux, a partition refers to a separate logical disk drive although, in fact, several partitions may reside on a single disk. We place certain directories in a partition, thus keeping some of the directories separated. For instance, the swap space will be placed on one partition, the users’ home directories on a second, and quite likely the Linux operating system (OS) on a third. You usually set up a partition when you first install the OS. Once established, it is awkward to change the size or number of partitions because that might cause an existing partition’s space to be diminished and thereby require that some of the files in that partition be moved or deleted. Partitions are not that interesting, and it is likely that once you set up your OS, you will not have to worry about the individual partitions again.
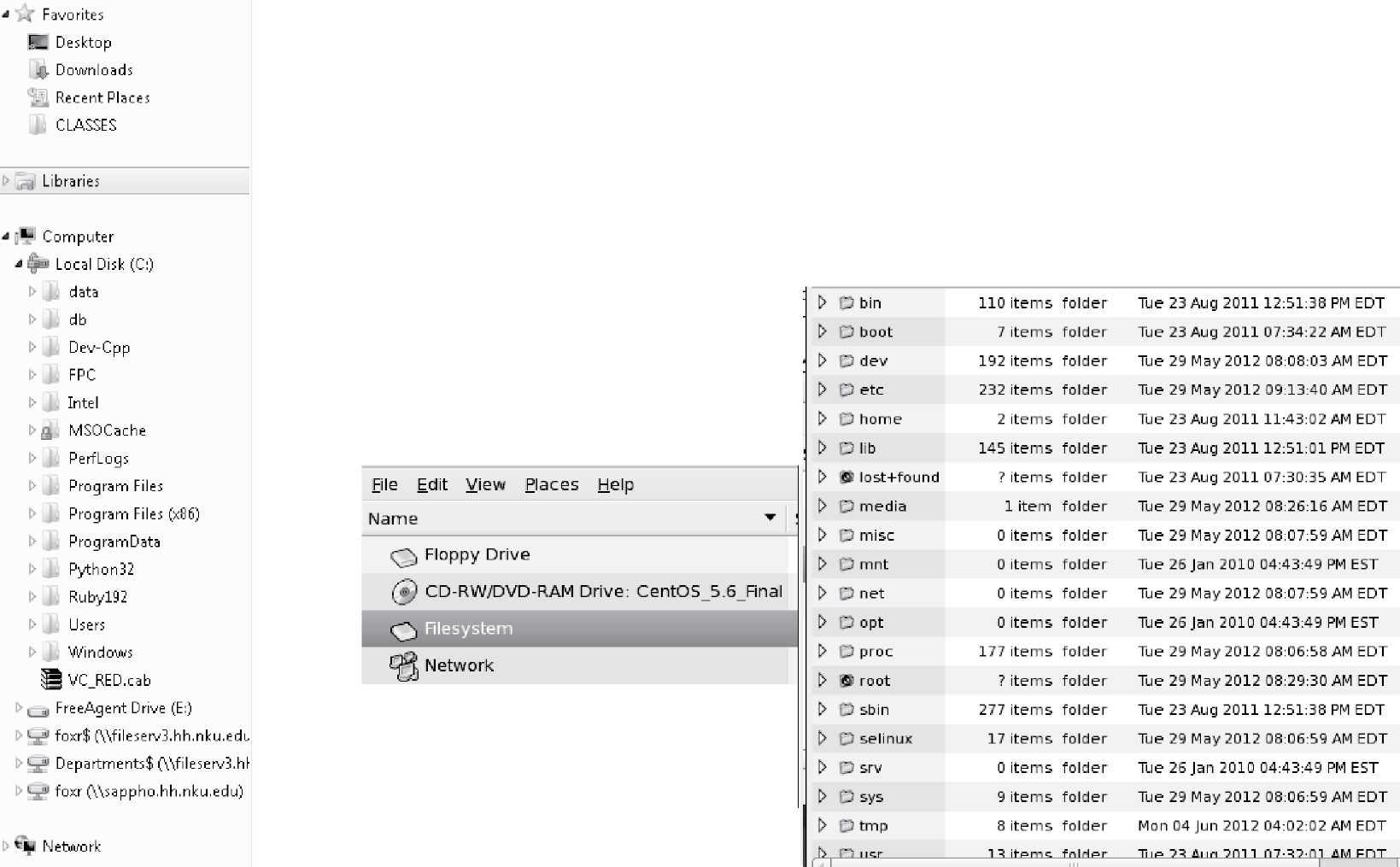
Directories, also known as folders, allow the user to coordinate where files are placed. Unlike partitions, which are few in number, you can create as many directories as desired. Directories can be placed inside of directories giving the user the ability to create a hierarchical file space. Such a directory is usually referred to as a subdirectory. The hierarchical file space is often presented in a “tree” shape. At the top, or root, of the tree are the partitions. Underneath are the top level directories. Underneath those are files and subdirectories. The tree branches out so that the leaves are at the bottom. File manager programs often illustrate the tree in a left to right manner (the left side has the root of the tree); as you move toward the right, you have subdirectories branching out, and the leaves (which are individual files) are at the right end of any branch. Figure 5.1 illustrates typical file spaces as viewed in file manager software: Windows on the left-hand side and Linux on the right. In both OSs, the topmost level is the computer itself, which has underneath it the various file spaces or drives. In modern computers, it is common to have the hard disk drive (C:) and an optical drive (D:). There may be additional drives listed, such as an external hard disk, floppy disk, USB flash drive, file server available by network, or partitions within the internal hard disk itself. In this latter case, in Linux, they may all still appear underneath Filesystem, as shown in Figure 5.1. The top level of the Linux file system contains a number of preestablished directories. In Windows, the file system is typically limited to initial directories of Program Files (two directories in Windows 7 to denote the 32-bit programs from the 64-bit programs), Users (the user home directories), and Windows (the OS). In Linux, the directory structure is more defined. We will explore the use of the various directories in detail later in this chapter.
Files are the meaningful units of storage in a file system. They comprise data and programs, although we can think of programs as being special types of data files. Data files come in all sizes and types. Data files might be text files, formatted text files using special escape or control characters, or binary files. In Linux, text files are very common. In Windows, data files are more commonly those produced from software such as Word documents (docx) and Excel files (xlsx). Data files may also be multimedia files such as music or sound files (wav, mp3), image files (gif, jpg, bmp), and movie files (mpg, avi, mov).
Files have names. In older OSs, file names were limited to up to eight characters followed by an optional extension that could be up to three characters. Separating the name from the extension is a period. In much older OSs, the characters used in file names were limited to alphabetical, numeric, underscore, and hyphen characters only. Today, file names can include spaces and some other forms of punctuation although not every character is allowable. Longer names are often useful because the name should be very descriptive. Some users ignore extensions but extensions are important because they tell the user what type of file it is (i.e., what software created it). File extensions are often used by the OS to determine how a file should be opened. For instance, if you were to double click on a data file’s icon, the OS could automatically open that file in the proper software if the file has an extension, and the extension is mapped to the proper software.
Aside from file types and names, files have other properties of note. Their logical location in the file system is denoted by a pointer. That is, the descriptor of the file will also contain its location within the file system space. For instance C:UsersfoxrMy Documentscit130 otesch7.docx describes the file’s logical position in the file system but not its physical location. An additional process must convert from the logical to physical location. The file’s size, last modification time and date, and owner are also useful properties. Depending on the OS, the creation time and date and the group that owns the file may also be recorded. You can find these properties in Windows by right clicking on any file name from the Windows Explorer and selecting Properties. In Linux, you can see these properties when you do an ls –l command.
Files are not necessarily stored in one contiguous block of disk space. Instead, files are broken into fixed sized units known as blocks. A file’s blocks may not be distributed on a disk such that they are in the same track or sector or even on the same surface. Instead, the blocks could be distributed across multiple disk surfaces. This will be covered in more detail later in the chapter.
Many older OSs’ commands were oriented toward managing the file system. The DOS operating system for instance stands for Disk Operating System. There were few commands other than disk operations that a user would need. This is not to say that the OS only performed operations on the file system, but that the user commands permitted few other types of operations. Common commands in both MS-DOS and Linux are listed below. Similarly, Windows mouse operations are provided. We will explore the Linux and DOS commands in more detail in Moving around the File System.
Linux:
- ls—list the files and subdirectories of the given directory
- mv—move or rename a file or directory
- cp—copy a file or directory to a new location
- rm—remove (delete) a file
- cat, more, less—display the contents of a file to the screen
- mkdir—create a new (sub)directory
- rmdir—remove a directory; the directory must be empty for this to work
DOS:
- dir—list the files and subdirectories of the given directory
- move—move a file to a new location, or rename the file
- copy—copy a file to a new location
- del—remove (delete) a file
- type—display the contents of a file to the screen
- mkdir—create a new (sub)directory
- rmdir—remove a directory; the directory must be empty for this to work
Windows (using Windows Explorer; see Figure 5.2):
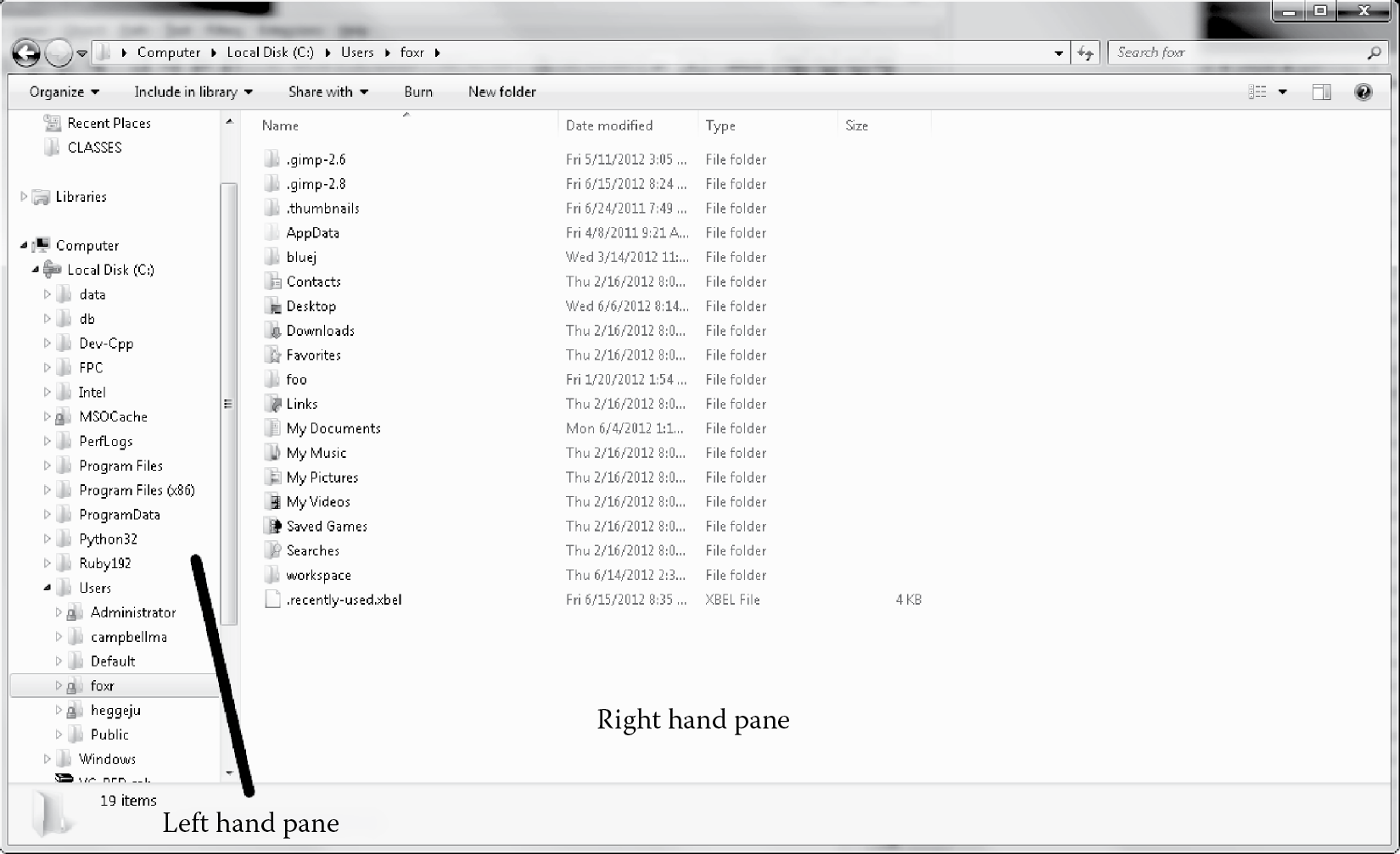
- To view a directory’s contents, click on the directory’s name in the left-hand pane; its contents are shown in the right-hand pane—if the directory is not at the top level, you will have to expand its ancestor directories from the top of the file system until you reach the sought directory.
- To move a file, drag the file’s icon from the right-hand pane in its current directory to a directory in the left-hand pane.
- To copy a file, right click on the file’s icon, select copy, move to the new directory by clicking on that directory in the left-hand pane, and then in the right-hand pane, right click and select paste.
- To rename a file, right click on the file’s icon, select rename (or click in the file’s name in the icon twice slowly), and then type the new name.
- To delete a file (or folder), drag the icon into the recycle bin (or right click on the icon and select delete or left click on the icon and press the delete key) —you will have to separately empty the recycle bin to permanently delete the file.
- To create a new directory (folder), click on the button New Folder. Or, right click in the right-hand pane and select new and then folder, then name the folder once it appears.
- To display the contents of a file, you can double click on the file icon and it should launch in whatever software is associated with the file’s extensions.
Note that in Windows, file extensions may not appear in the file manager, so you would have to set it up so that file extensions appear (if you want to see them).
In order to reduce the impact that large files have on the available space in a file system, the user can perform file compression. There are two forms of file compression. In lossless file compression, a file is reduced in size such that, when it is uncompressed to its original form, no data are lost. There are many algorithms for performing lossless file compression, and they will work especially well on text files. With lossless file compression, you usually have to uncompress the file before you can access it (there are exceptions such as the FLAC audio compression algorithm). The advantage of lossless file compression is that files that are not currently in use can be stored in greatly reduced sizes. The primary disadvantage is that compressing and uncompressing the file is time consuming.
Lossy file compression actually discards some of the data in order to reduce the file’s size. Most forms of streaming audio and video files are lossy. These include .avi, .mpg, .mov (video) and .wav and .mp3 (audio). Most forms of image storage also use lossy file compression, such as .jpg. If you were to compare a bitmap (.bmp) file to a .jpg, you would see that the .bmp has greater (perhaps much greater) clarity. The .jpg file saves space by “blurring” neighboring pixels. The .gif format instead discards some of the colors so that if the image uses only the standard palette of colors, you would not see any loss in clarity. However, if the .gif uses different colors, the image, while having the same clarity, would not have the correct colors.
When you have a collection of files, another useful action is to bundle them together into an archive. This permits easy movement of the files as a group whether you are placing them in backup storage or uploading/downloading them over the Internet. File archiving is common when a programmer wants to share open source programs. The source code probably includes many files, perhaps dozens or hundreds. By archiving the collection, the entire set of source code can be downloaded with one action rather than requiring that a user download files in a piecemeal fashion. One very common form of archiving is through the zip file format, which performs both file compression and archiving. To retrieve from a zipped file, one must unzip the file. There are numerous popular software packages for performing zip and unzip including winzip and winrar in Windows, and gzip and gunzip in Linux. Linux also has an older means for archiving called tar. The tar program (tape archive) was originally used to collect files together into a bundle and save them to tape storage. Today, tar is used to archive files primarily for transmission over the Internet. The tar program does not compress, so one must compress the tar file to reduce its size.
Lossy compression is primarily used on image, sound, and movie files, whereas lossless compression is used on text files and software source files. The amount of compression, that is, the reduction in file size, depends on the compression algorithm applied and the data itself. Text files often can be greatly reduced through compression, by as much as 88%. Lossy audio compression typically can compress data files down to 10% or 20% of their original version, whereas lossless audio compression only reduces files to as much as 50% of their original size.
File Systems and Disks
The file system is the hierarchical structure that comprises the physical and logical file space. The file system includes an index to map from a logical file name to a physical location. A file system also includes the capability of growing or shrinking the file space by adding and deleting media. This is sometimes referred to as mounting. A mounted file space is one that can later be removed (unmounted). The file system is physically composed of secondary storage devices, most predominantly an internal hard disk drive, an internal optical drive, and possibly external hard disk drives. Additionally, users may mount flash drives and tape drives. For a networked computer, the file space may include remote drive units (often called file servers).
The OS maintains the file space at two levels: logical and physical. Our view of the file space is the logical view—partitions, directories, and files. In order to access a file, the OS must map from the logical location to the physical location. This is done by recording the physical location of a file in its directory information. The location is commonly referenced by means of a pointer. Let us assume that we are dealing with files stored only on hard disk. The pointer indicates a particular file system block. This must itself be translated from a single integer number into a drive unit, a surface (if we are dealing with a multiplatter disk drive), a sector, and a track on the disk (Figure 5.3). The term cylinder is used to express the same track and sector numbers across all platters of a spinning disk. We might reference a cylinder when we want to access the same tracks and sectors on each surface simultaneously.
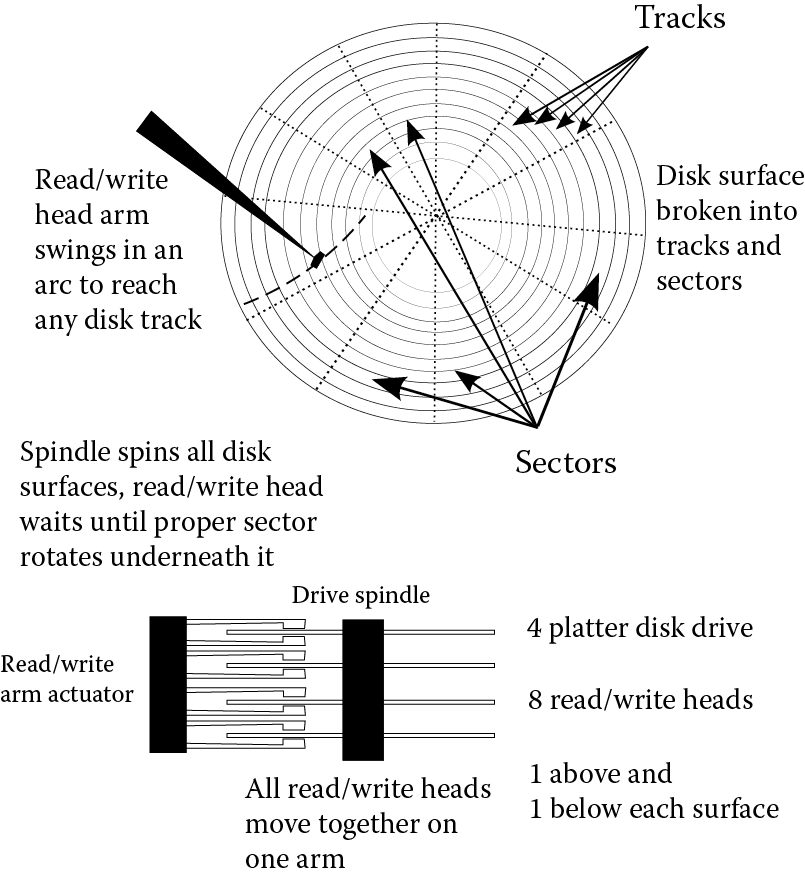
Hard disk layout. (Adapted in part from the public domain image by LionKimbro at http://commons.wikimedia.org/wiki/File:Cylinder_Head_Sector.svg .)
As an example, imagine file f1.txt is located at block 381551. Our file system consists of one hard disk with four platters or eight surfaces. Furthermore, each surface has 64 sectors and 2048 tracks. We would locate this block on surface 381551/(64 * 2048) = surface 2 (starting our count at surface 0). Surface 2 would in fact contain blocks 262144 through 393216. We would find block 381551 in sector 58 (again, starting our count at sector 0) since (381551 – 262144)/2048 = 58.3. Finally, we would find the block on track 623 (381551 – 262144) – 2048 * 58 = 623. So, fl.txt, located at block 381551, is found on surface 2, sector 58, track 623.
As shown in Figure 5.3, hard disk drives contain multiple platters. The platters rotate in unison as a motorized spindle reaches up through the holes in each platter. The rotation rate of the disks depends on the type of disk, but hard disk drives rotate at a rate of between 5400 and 15,000 revolutions/min. Each platter will have two read/write heads assigned to it (so that both surfaces of the platter can be used). All of the read/write heads of the hard disk drive move in unison. The arms of the read/write heads are controlled by an actuator that moves them across the surface of the disks, whereas the disks are spun by the spindle. The read/write heads do not actually touch the surface of the disk, but hover slightly above/below the surface on a cushion of air created by the rapid rotation rate of the disks. It is important that the read/write heads do not touch the surface of the disk because they could damage the surface (scratch or dent it) and destroy data stored there. For this reason, it is important to “park” the read/write head arm before moving a computer so that you do not risk damaging the drive. The read/write head arm is parked when you shut down the computer. Many modern laptop computers use motion sensors to detect rapid movements so that the read/write head arm can be parked quickly in case of a jerking motion or if the entire laptop is dropped.
The data stored on hard disk is in the form of positive and negative magnetic charges. The read/write head is able to read a charge from the surface or write a new charge (load/open and store/save operations, respectively). An example of a read/write head arm for eight platters (sixteen heads, only the top head is visible) is shown in Figure 5.4.

Read/write head arm. (Courtesy of Hubert Berberich, http://commons.wikimedia.org/wiki/File:Seagate-ST4702N-03.jpg .)
Files are not stored consecutively across the surface of the disk. Instead, a file is broken into fixed size units called blocks, and the blocks of a file are distributed across the disk’s surface, possibly across multiple surfaces. Figure 5.5 illustrates this idea, where a file of 6 blocks (numbered 0 through 5) are located in various disk block locations, scattered throughout the hard disk. Note that since every block is the same size, the last block may not be filled to capacity. The dotted line in disk block 683 indicates a fragment—that is, the end of the file does not fill up the entire disk block, so a portion of it goes unused.
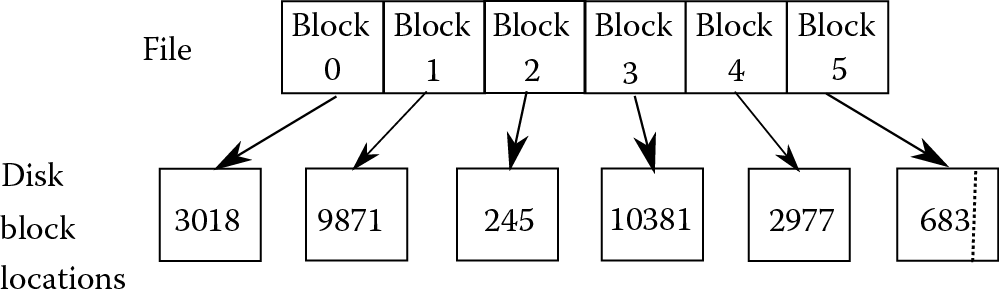
There are several reasons for scattering the file blocks across the disk surface(s). First, because of the speed by which a disk is spun, if the read/write head had to access multiple consecutive disk blocks, it is likely that the time it takes to transfer a block’s worth of content to memory would be longer than the time it would take for the disk to move the next block under the read/write head. The result would be that the read/write head would be out of position for the next access and therefore the access would have to wait until the proper block spun underneath the read/write head, that is, another rotation of the disk. One way to combat this problem is to space disk blocks out, in the same general location but not adjacent. For instance, disk blocks might be saved on every other sector of a given track and then onto the next adjacent track (e.g., sector 0/track 53, sector 2/track 53, sector 4/track 53, sector 6/track 53, sector 8/track 53, sector 0/track 54, sector 2/track 54).
Second, this alleviates the problem of fragmentation. As shown in Figure 5.5, only the last disk block of a file might contain a fragment. Consider what might happen if disk files are placed in consecutive locations. Imagine a file is stored in 3 consecutive blocks. A second file is stored in 2 consecutive blocks immediately afterward. A third file is stored in 4 consecutive blocks after the second file. The second file is edited and enlarged. It no longer fits in the 2 blocks, and so is saved after the third file. Now, we have file 1 (3 blocks), freed space (2 blocks), file 3 (4 blocks), and file 2 (3 blocks). Unfortunately, that free space of 2 blocks may not be usable because new files might need more storage space. Thus, we have a 2-block fragment. It is possible that at some point, we would need the 2-block space to reuse that freed-up space, but it could remain unused for quite a long time. This is similar to what happens if you record several items on video or cassette tape and decide you no longer want one of the earlier items. You may or may not be able to fill in the space of the item you no longer want. Since we often edit and resave files, using consecutive disk blocks would likely create dozens or hundreds of unusable fragments across the file system. Thus, by distributing blocks, we can use any free block any time we need a new block.
Third, it is easier to maintain a description of the available free space in the file system by using the same mechanism to track disk blocks of a file. The free space consists of those disk blocks that either have not yet been used, or are of deleted files. Therefore, monitoring and recording what is free and what is used will not take extra disk space.
This leads to a natural question: if a disk file is broken into blocks that are scattered around the file system, how does the OS find a given block (for instance, the third block of a file)? Recall that the OS maintains a listing of the first disk block of each file. Each disk block contains as part of its storage the location of the next disk block in the file. The storage is a pointer. This creates what is known as a linked list. See Figure 5.6, where the OS stores a file pointer to the first block and each block stores a pointer to the next block in the file.
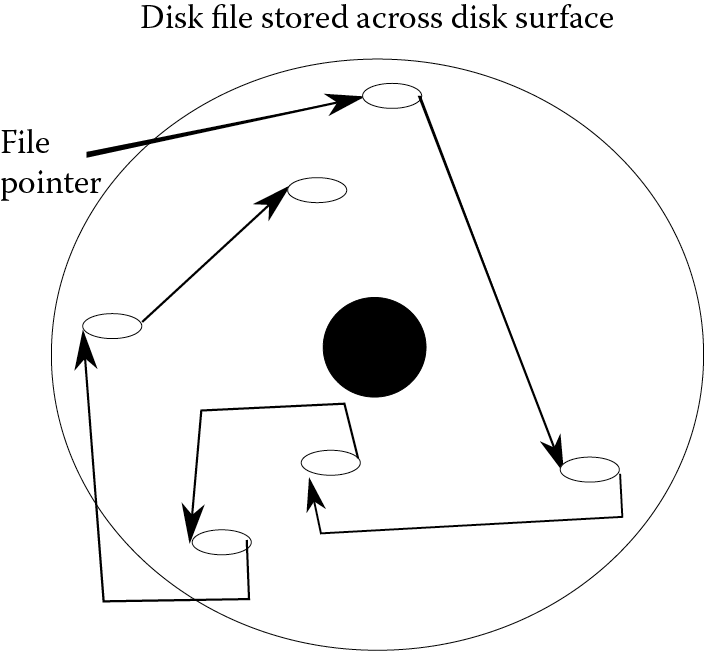
To load a particular disk block, the OS first examines the directory listing to obtain the file’s first pointer. The first block has a pointer to the second block, which has a pointer to the third block, and so forth. To reach block n, you must first go through n – 1 previous blocks, following those pointers. Following the linked list is inefficient because each block requires a separate disk access, which as noted previously, is one of the slower aspects of any computer. For a sequential file—that is, one that must be accessed in order from start to finish—accessing the file in this manner is not a drawback because the file is loaded, block by block, in order.
Disk Utilities
You might recall from Chapter 4 that part of the OS is made up of utility software. This software includes antiviral programs, for instance. Another class of utility programs is the disk utilities. Disk utilities can help a user or system administrator manage and maintain the file system by performing tasks that are otherwise not available. Below is a list of common disk utilities.
Disk defragmentation: although the use of disk blocks, scattered around the file system, prevents the creation of fragments, fragments can still arise. Disk defragmentation moves disk blocks across the disk surfaces in order to move them together and remove free blocks from between used blocks. This can make disk performance more efficient because it moves blocks of a file closer together so that, when the file is accessed wholly, the access time is reduced because all blocks are within the same general area on a surface. Whereas a Windows file system may occasionally benefit from defragmentation, supposedly the Linux file system will not become inefficient over time.
File recovery: if you delete a file and then empty the recycle bin, that file is gone, right? Not so. File recovery programs can try to piece together a file and restore it—as long as the disk blocks that made up the file have not been written over with a new file.
Data backup: many users do not back up their file system, and so when a catastrophic error arises, their data (possibly going back years) get lost. Backups are extremely important, but they are sometimes difficult to manage—do you back up everything or just what has changed since the last backup? A backup utility can help you manage the backup process.
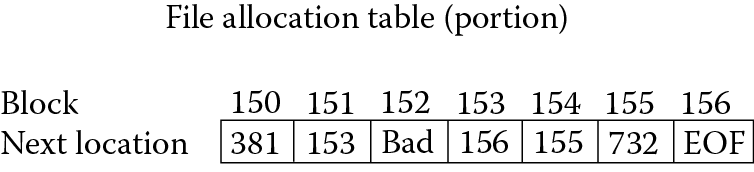
Many files can be accessed randomly—that is, any block might be accessed at any time. To accommodate this, some OSs, including Windows, use a file allocation table (FAT). The FAT accumulates all of the pointers of every disk block into a single file, stored at the beginning of the disk. Then, this file is loaded into memory so that the OS need only search memory to find the location of a given block, rather than searching the disk itself. Searching memory for the proper block’s disk location is far more efficient than searching disk. Figure 5.7 illustrates a portion of the FAT. Notice that each disk block is stored in the FAT, with its successor block. So, in this case, we see that the file that contains block 150 has a next block at location 381, whereas the file that contains block 151 has a next location at 153 and after 153, the next location is 156, which is the last location in the file. Block 152 is a bad sector and block 154, 155, and 732 are part of another file. EOF stands for “end of file”.
Free space can also be stored using a linked list where the first free block is pointed to by a special pointer in the file system’s partition, and then each consecutive free block is pointed at by the previous free block. To delete a file, one need only change a couple of pointers. The last free space pointer will point to the first block in the deleted file, and the entry in the directory is changed from a pointer to the first block, to null (to indicate that the file no longer exists). Notice that you can easily reclaim a deleted file (undelete a file) if the deleted files’ blocks have not been reused. This is because file deletion does not physically delete a file from the disk but instead adds the file’s disk blocks to the list of free blocks. See the discussion of file recovery in the side bar on the previous page.
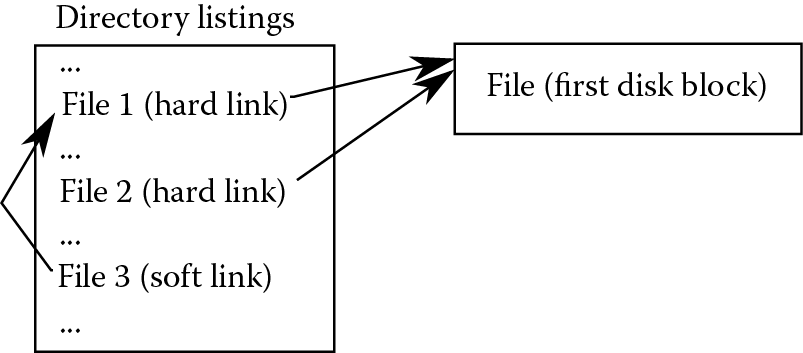
The pointers from the file system (directory) to the physical location in the disk drive are sometimes referred to as hard links. That is, the linking of the file name to location is a hard link. Linux lets you have multiple hard link pointers to a file. Some OSs also offer soft links. In a soft link, the pointer from the file system points not to the physical location of the file, but to another entry in the directory structure. The soft link, also known as a symbolic link in Linux and a shortcut in Windows, points to the original entry. For instance, if you create file f1.txt in directory /home/foxr, and later set up a soft link called f2.txt in /home/foxr/cit130/stuff, then the directory /home/foxr/cit130/stuff has an entry f2.txt whose pointer points to /home/foxr/f1.txt, and not to the first block of the file itself. See Figure 5.8 for an example where two hard links, called File1 and File2, point to the first block of the file, whereas a soft link, called File3, points at the hard link File2.
With either kind of link, aliases are created. An alias means that a particular entity (file in this case) can be referenced through multiple names. Aliases can be dangerous because someone might change an item without realizing that they are changing another item. For instance, if I were to alter f1.txt, then f2.txt changes as well since f2.txt is merely a pointer to f1.txt. The situation is worse when the original file is deleted. The OS does not necessarily check to see if there are soft links pointing to a file that is being deleted. The result is that the file no longer exists and yet a soft link points to it. In this case, following the soft link yields an error. One can delete the soft link without deleting the physical file itself or causing a problem, but deleting the original file without deleting the soft link can lead to errors.
Disk access is a great deal slower than CPU speed or access to main memory. Disk access time is a combination of several different factors. The address must be mapped from a logical position to a disk block through the FAT followed by mapping to the physical location in terms of surface, sector, and track. This is relatively quick as this mapping is done by the CPU accessing memory instead of disk. Now, the read/write must be positioned over the proper location on the disk. This requires moving the read/write head to the proper track (known as seek time) and waiting for the proper sector to be spun underneath the read/write head (known as rotational delay or rotational latency). Now, the read/write head can begin reading or writing the magnetic charges on the disk. This action is more time consuming that the access performed in DRAM (dynamic RAM). As the bits are being read or written, information must be transferred between disk and memory. This is known as transfer time. The combination of mapping (usually negligible), seek time, rotational delay, and transfer time is on the order of several milliseconds (perhaps 5 to 30 ms). A millisecond is a thousandth of a second. Recall that our processors and static RAM (SRAM) operate at the nanosecond rate (a billionth of a second) and DRAM is perhaps 25 to 100 times slower, but still in the dozens of nanosecond range. Therefore, the disk access time is a factor of millions of times slower than CPU and memory response rates!
Linux File System
Linux File Space
The Linux file space is set up with default root-level directories, which are populated with basic files when you install Linux. This allows you to know where to find certain types of files. These default directories are:
- /bin: common operating system programs such as ls, grep, cp, mv.
- /sbin: similar to /bin, but the programs stored here are of Linux commands that are intended for the system administrator, although many may be available to normal users as well. Note: /sbin is often not part of a user’s path, so the user may need to type the full path name in for the command, e.g., /sbin/ifconfig.
- /etc: configuration files specific to the machine (details are provided later in this section).
- /root: the home directory for user root. This is usually not accessible to other users on the system.
- /lib: shared libraries used during dynamic linking; these files are similar to dll files in Windows.
- /dev: device files. These are special files that help the user interface with the various devices on the system. Some of the important devices are listed below.
- /dev/fd0—floppy disk (if available)
- /dev/hda0—master IDE drive on the primary IDE controller
- /dev/ht0—first IDE tape drive
- /dev/lp0—first parallel printer device
- /dev/null—not a device but instead a destination for program output that you do not want to appear on the monitor—in essence, sending anything to /dev/null makes it disappear
- /dev/pcd0—first parallel port CD ROM drive
- /dev/pt0—first parallel port tape
- /dev/random and /dev/urandom—random number generators (urandom has potential problems if used to generate random numbers for a cryptography algorithm)
- /dev/sda0—the first SCSI drive on the first SCSI bus
- /dev/zero—this is a simple way of getting many 0s
Note: for devices ending in 0, if you have other devices of the same type, you would just increase the number, for instance, lp1, lp2 for two additional printers, or pcd1 for a second CD ROM drive.
- /tmp: temporary file storage for running programs that need to create and use temporary files.
- /boot: files used by a bootstrap loader, e.g., LILO (Linux Loader) or GRUB (Grand Unified Boot loader).
- /mnt: mount point used for temporarily partitions as mounted by the system administrator (not regularly mounted partitions).
- /usr, /var, /home: mount points for the other file systems.
- /home—the users’ file space
- /var—run-time data stored by various programs including log files, e-mail files, printer spool files, and locked files
- /usr—various system and user applications software, with subdirectories:
- /usr/bin: many Linux user commands are stored here although some are also stored in /bin or /usr/local/bin.
- /usr/sbin: system administration commands are stored here.
- /usr/share/man, /usr/share/info, /usr/share/doc: various manual and documentation pages.
- /usr/include: header files for the C programming language.
- /usr/lib: unchanging data files for programs and systems.
- /usr/local: applications software and other files.
- /proc: this is a peculiar entry as it is not actually a physical directory stored in the file system but instead is kept in memory by the OS, storing useful process information such as the list of device drivers configured for the system, what interrupts are currently in use, information about the processor, and the active processes.
There are numerous important system administration files in /etc. Some of the more significant files are listed here:
- Startup scripts
- /etc/inittab: the initial startup script that establishes the run-level and invokes other scripts (in newer versions of Linux, this script has been replaced with the program /etc/init)
- /etc/rc.d/rc0.d, /etc/rc.d/rc1.d, /etc/rc.d/rc2.d, etc: directories of symbolic links that point to startup scripts for services, the listings in each directory dictate which services start up and which do not start up at system initialization time based on the run-level (See the section Forms of Process Management in Chapter 4 and Chapter 11 for additional details)
- /etc/init.d: the directory that stores many of the startup scripts
- These startup scripts are discussed in Chapter 11.
- User account files
- /etc/passwd: the user account database, with fields storing the username, real name, home directory, log in shell, and other information. Although it is called the password file, passwords are no longer stored there because this file is readable by anyone, and placing passwords there constituted a security risk; so the passwords are now stored in the shadow file.
- /etc/shadow: stores user passwords in an encrypted form.
- /etc/group: similar to /etc/passwd, but describes groups instead of users.
- /etc/sudoers: list of users and access rights who are granted some privileges beyond normal user access rights.
- These files are discussed in Chapter 6.
- Network configuration files
- /etc/resolv.conf: the listing of the local machine’s DNS server (domain name system servers).
- /etc/hosts: stores lists of common used machines’ host names and their IP addresses so that a DNS search is not required.
- /etc/hosts.allow, /etc/hosts.deny: stores lists of IP addresses of machines that are either allowed or disallowed log in access.
- /etc/sysconfig/iptables-config: the Linux firewall configuration file, set rules here for what types of messages, ports, and IP addresses are permissible and impermissible.
- /etc/xinetd: the Internet service configuration file, maps services to servers, for instance, mapping telnet to 23/tcp where telnet is a service and 23/tcp is the port number and server that handles telnet; this is a replacement for the less secure inetd configuration file.
- Some of these files are discussed in more detail in Chapters 11 and 12.
- File system files
- /etc/fstab: defines the file systems mounted at system initialization time (also invoked by the command mount –a).
- /etc/mtab: list of currently mounted file systems, updated automatically by the mount and umount commands, and used by commands such as df.
- /etc/mime.types: defines file types; it is the configuration file for the file and more commands so that these commands know how to treat the given file type.
- Message files
- /etc/issue: contains a short description or welcoming message to the system, the contents are up to the system administrator.
- /etc/motd: the message of the day, automatically output after a successful login, contents are up to the system administrator and is often used for getting information to every user, such as warnings about planned downtimes.
- User startup scripts
- /etc/profile, /etc/bash.rc, /etc/csh.cshrc: files executed at login or startup time by the Bourne, BASH, or C shells. These allow the system administrator to set global defaults for all users. Users can also create individual copies of these in their home directory to personalize their environment.
- Some of these files are discussed in more detail in Chapter 11.
- /etc/profile, /etc/bash.rc, /etc/csh.cshrc: files executed at login or startup time by the Bourne, BASH, or C shells. These allow the system administrator to set global defaults for all users. Users can also create individual copies of these in their home directory to personalize their environment.
- /etc/syslog.conf: the configuration file that dictates what events are logged and where they are logged to (we cover this in detail in Chapter 11).
- /etc/gdm: directory containing configuration and initialization files for the Gnome Display Manager (one of the Linux GUI systems).
- /etc/securetty: identifies secure terminals, i.e., the terminals from which root is allowed to log in, typically only virtual consoles are listed so that it is not possible to gain superuser privileges by breaking into a system over a modem or a network.
- /etc/shells: lists trusted shells, used by the chsh command, which allows users to change their login shell from the command line.
Although different Linux implementations will vary in specific ways such as startup scripts, types of GUIs, and the types and names of services, most Linux dialects have the above directories and files, or similar directories and files. See Figure 5.9, which shows the typical arrangement of directories along with some of the initial subdirectories. The /home directory, of course, will differ based on the population of users. The commonality behind the Linux file system structure helps system administrators move from one version of Linux to another. However, with each new release of a version of Linux, changes are made and so the system administrator must keep up with these changes.

The Linux file system consists not only of the hard disk but also mountable (removable) devices. In order to access a device, it must be physically attached, but it must also be logically mounted through the mount command. Some mounting is done for you at the time you boot your system by having a mount file called /etc/fstab (file system table). To unmount something from the file system, use umount. To mount everything in the fstab file, use mountall. Note: you will not be able to edit fstab or execute mount, umount, or mountall unless you are root. Another file, /etc/mtab, stores a table of those partitions that are currently mounted.
Linux Partitions
In order to ensure that the various directories have sufficient room, system administrators will typically partition the hard disk into three or more areas, each storing a different section of the file system. This allows specific areas of the file space to be dedicated for different uses such as the kernel, the swap space, and the user directory space. Partitions provide a degree of data security in that damage to one partition may not impact other partitions (depending on the source of the damage). It is also possible in Linux to establish different access controls on different partitions. For instance, one partition might be set as read-only to ensure that no one could write to or delete files from that partition. One can establish disk quotas by partition as well so that some partitions will enforce quotas, whereas others do not. Partitions also allow for easy mounting and unmounting of additional file spaces as needed or desired.
The root partition (/) will store the Linux /boot directory that contains the boot programs, and enough space for root data (such as the root’s e-mail). The largest partition will most likely be used for the /home directory, which contains all of the users’ directories and subdirectories. Other directories such as /var and /usr may be given separate partitions, or they may be part of / or /home. The swap partition is used for virtual memory. It serves as an extension to main (DRAM) memory so that only currently and recently used portions of processes and data need to reside in DRAM. This partition should be big enough to store the executable code of all currently executing processes (including their data). It is common to establish a swap space that is twice the size of DRAM. Swap spaces can also be distributed across two (or more) disks. If the swap space was itself divided among two hard disk drives, it could provide additional efficiency as it would be possible to handle two page swappings at a time (refer back to page swapping in Chapter 4).
Partitioning the file space is accomplished at OS installation time, and therefore, once completed, the partitions and their sizes are fixed. This is unfortunate as you perform the installation well before you have users to fill up the user’s partition, and therefore you must make an educated guess in terms of how large this partition should be. At a later point, if you want to alter the partition sizes you may have to reinstall the OS, which would mean that all user accounts and directories would be deleted. You could, if necessary, back up all OS files and user accounts/directories, reinstall the OS, change the partition size, and then restore the OS files and user accounts/directories. This would be time consuming (probably take several hours at a minimum) and should only be done if your original partitioning was inappropriate. Fortunately, Linux and Unix do offer another solution, the use of a dynamic partition resizer. However, using one is not something to do lightly. For instance, if a power outage or disk crash occurs during resizing, data may be permanently destroyed. On the other hand, it is much simpler than saving the file system, reinstalling the OS, and restoring the file system.
There are a number of Linux commands that deal with the file system. The df command (display file system) will show you all of the partitions and how full they are in both bytes and percentage of usage. As mentioned above, the mount and umount commands allow you to mount and unmount partitions from the file system.
The quotaon and quotaoff commands allow you to control whether disk quotas are actively monitored or not. The system administrator can establish disk quotas for users and groups. If disk quotas are on for a given file system, then the OS will ensure that those users/groups using that file system are limited to the established quotas.
The file command will attempt to guess at what type of file the given file is. For instance, it might return that a file is a text file, a directory, an image file, or a Open Office document. The find instruction performs a search of the file system for a file of the given name. Although find is a very useful Linux instruction, it is not discussed further because it is a rather complicated instruction.
The utility fsck (file system check) examines the file system for inconsistent files. This utility can find bad sectors, files that have been corrupted because they were still open when the system was last shut down, or files whose error correction information indicates that the file has a problem (such as a virus). The fsck utility not only finds bad files and blocks, but attempts to repair them as well. It will search for both logical and physical errors in the file system. It can run in a mode to find errors only, or to find and try to fix errors. The fsck program is usually run at boot time to ensure a safe and correct file system. If errors are found, the boot process is suspended, allowing fsck to find and attempt to fix any corruption found.
Linux Inodes
Inodes are the Unix/Linux term for a file system component. An inode is not a file, but is a data structure that stores information about a file. Upon installing Linux and partitioning the file system, the OS generates a number of inodes (approximately 1% of the total file system space is reserved for inodes). Notice that there is a preset number of inodes for a system, but it is unlikely that the system will ever run out of available inodes. An inode will store information about a single file; therefore, there is one inode for each file in the system. An inode for a created file will store that file’s user and group ownership, permissions, type of file, and a pointer to where the file is physically stored, but the inode does not store the file’s name, and is not the file itself. Instead, in the directory listing, a file’s name has a pointer to the inode on disk and the inode itself points to the file on disk. If a file has a hard link, then both the file name and the hard link point to the inode. If a file has a soft link, the file name points to the inode whereas the soft link points to the file name.
In order to obtain an inode’s number, the ls (list) command provides an option, –i. So, ls –i filename returns that file’s inode number. You can obtain the file’s information, via the inode, by using ls –l.
Files are not stored in one contiguous block on a disk, as explained earlier in this chapter, but instead are broken into blocks that are scattered around the file system. Every file is given an initial number of blocks to start. The inode, aside from storing information about the file, contains a number of pointers to point to these initial blocks. The first pointer points at the first disk block, the second pointer points at the second disk block where the first disk block stores the first part of the file, the second disk block stores the second part of the file, etc.
If a file needs additional blocks, later inode pointers can be created so that the inode pointer points to a block of pointers, each of which point to the additional disk blocks. Such a pointer block is called an indirect block. There can be any number of levels added, for instance, an inode pointer might point to an indirect block, which itself points to an indirect block that has pointers to actual disk blocks. Figure 5.10 illustrates this concept, showing the hierarchical structure of disk blocks, inodes, and pointers in Linux. The inode frees the Linux OS from having to maintain a FAT (as used in Windows).

Aside from storing information about files, inodes are used to store information on directories and symbolic links. A symbolic link is merely an alternate path to reach a file. You often set up symbolic links if you wish to be able to specify access to a given file from multiple starting points. To create a symbolic link, use ln –s filename1 filename2. Here, filename1 is the preexisting file and filename2 is the symbolic link. Typically, one of these two file names contains a path so that the file and symbolic link exist in two separate directories (it makes little sense to have a symbolic link in the same directory as the file you are linking to). For instance, if there is an important executable program in the directory /usr/share/progs called foo and you want to easily access this from your home directory, you might change to your home directory and then issue the command ln –s /usr/shar/progs/foo foo. This creates the symbolic link, foo, in your home directory that references the file /usr/shar/progs/foo.
One must be careful when dealing with symbolic links because if someone deletes or moves the original file, the link is no longer valid. If the file foo were deleted from /usr/shar/progs, then typing ~/foo would result in an error.
Computer Viruses
Any discussion of the file system would be incomplete without discussing computer viruses and their dangers. A computer virus is a program that can replicate itself. Most commonly, a computer virus is also a malicious program in that its true purpose is to damage the computer on which it is stored, or spy on the users of that computer.
How do you get infected? A virus hides inside another executable program. When that program is executed, the virus code executes. The virus code typically comes in two parts, the first is to replicate itself and store its own executable code inside other programs or data files. The second part is the malicious part.
Often a virus waits for a certain condition to arise (older viruses might wait for a certain day such as Friday the 13th, or a time, or an action such as the user attempting to delete a given file) before the malicious portion executes. The malicious part of the virus might delete data or copy data and send it to a third party (this data might include information stored in cookies such as your browser history and/or credit card numbers).
Today, the word “virus” applies to many different types of malicious software: spyware, adware, Trojan horses, worms, rootkits. However, the term virus really should only apply to self-replicating software, which would not include spyware, adware, or Trojan horses. The group of software combined is now called malware.
How do you protect yourself? The best way is to avoid the Internet (including e-mail)! But this is impractical. Instead, having an up-to-date antiviral/antimalware program is essential. Disabling cookies can also help. Also, avoid opening attachments from people you do not know. It is also helpful to have some disaster recovery plan. One approach is to create backups of your file system—in the case of a bad infection, you can reinstall the OS and restore your files. If you are a Linux or Mac user, you might feel safe from malware. Most malware targets Windows machines because Windows is the most common OS platform, but in fact malware can affect any platform.
A hard link, created by the ln command without the –s parameter, is a pointer to the file’s inode, just as the original name in the directory points to the file’s inode, unlike the symbolic link that merely points to the file’s name in the directory. Hard links can only be used to link to files within the same file system. A link across mounted file systems (partitions) must be a symbolic link. This limits hard link usefulness. Hard links are uncommon, but symbolic links are very common. If you do an ls –l, you will see symbolic links listed with a file type (the first letter in the listing) of ‘l’ to indicate soft link, and with the name filename -> true location. The filename is the name you provided to the link, whereas true location is the path and file name of the item being pointed to by the link.
Windows File System
The Windows file system layout is simpler than that of Linux, which makes it more complicated when you have to find something because you will find far more files in any one directory than you tend to find in Linux. The Windows layout has been fairly stable since Windows 95. The C: partition is roughly equivalent to Linux’ / root directory. A: and B: are names reserved for floppy disks (which typically are not available in computers purchased in recent years) and D: is commonly assigned to the computer’s optical drive. Other partitions can be added (or the main hard disk can be partitioned into several “drives”, each with its own letter).
Underneath the root of the file system (C:), the file system is divided into at least three directories. The OS is stored under the Windows folder. This directory’s subfolder System32 contains system libraries and shared files, similar to Linux’ /usr/lib. Most of the application software is located under Program Files. In Windows 7, there is a separate directory C:Program Files (x86) to separate 64-bit software (Program Files) from older 32-bit software (Program Files (x86)). In Linux, most of the application software is under /usr. User directories are commonly stored under C:Users (whereas in Linux, these directories are underneath /home). There may be a C:Temp directory that is similar to Linux’ /tmp.
A large departure between Windows and Linux takes place with the user directories. Under C:Users, default folders are set up for various types of files, Desktop, Downloads, Favorites, Links, My Documents, My Music, My Pictures, My Videos, Searches. In Linux, for the most part, the user decides where to place these items. In Windows, the specific folders are established by the software, unless overridden by the user. There are also soft links so that “My Documents” actually refers to C:UsersyouraccountMy Documents. By providing these default directories and soft links, it helps shelter the user from having to remember where files have been stored, or from having to understand the file space.
Many of the Windows operations dealing with the file system are available through GUI programs. Some of these are found through the Control Panel, others are available through OS utilities such as Norton Utilities and McAfee tools. The Control Panel includes tools for system restoration (which primarily restores system settings but can also restore file system components), backup and restore for the file system, and folder options to control what is displayed when you view folder contents. And, of course, the default file manager program is Windows Explorer. There are also DOS commands available. The most significant DOS command is chkdsk, a utility that serves a similar purpose as fsck does in Linux. Other commands include defrag (disk defragmentation utility), diskpart that allows you to repartition a disk or perform related administrative services on the disk (such as assigning it a drive letter or attributes), and find, similar to the Linux find program.
When considering the Windows file system, one might feel that it is intuitively easy to use. On the other hand, the Windows approach might feel overly restrictive. For instance, if a user wishes to create a CIT 130 folder to collect the various data files related to that course, a Linux user might create /home/foxr/cit130. Underneath this directory, the user might place all of the files in a flat space, or might create subdirectories, for instance, Pictures, Documents, Searches, and Videos. In Windows, the user would have to create cit130 folders underneath each of the established folders in order to organize all material that relates to CIT 130, but the material is distributed across numerous folders. Only if the user is wise enough to override the default would the user be able to establish a cit130 folder under which all items could be placed.
Moving around the File System
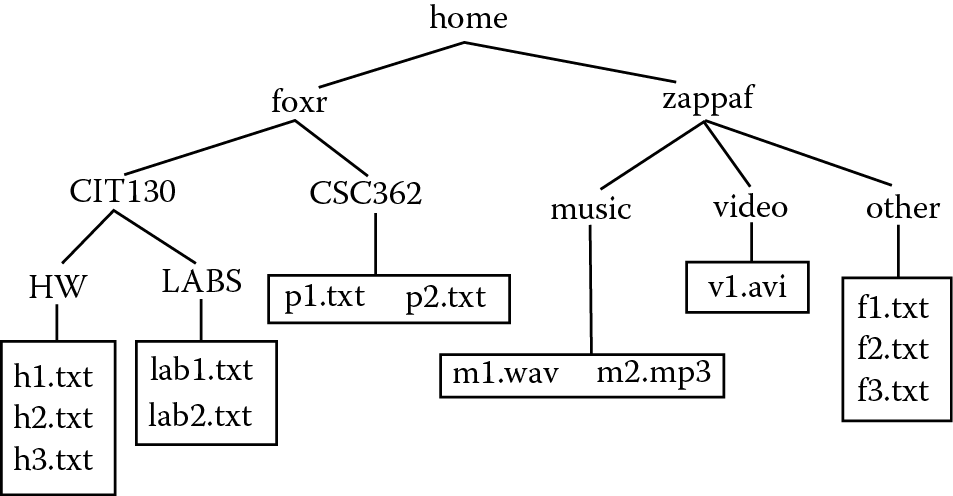
Here, we look at specific Linux and DOS commands for moving around their respective file systems. In the following examples, we see the OS commands, the results of those commands and some comments describing what the operations are doing. We will focus first on Linux, which is slightly more complicated. Mastering Linux will make it easier to master DOS. Assume that we have the structure of directories, subdirectories, and files in Figure 5.11. Items in boxes are files, and all other items are directories. For DOS, replace home with Users.
Linux
What follows is a Linux shell session (commands entered in a Linux shell and the results), along with explanations of the commands. Comments are given beneath some of the commands. Linux commands appear after $ symbols, which we will assume is the Linux prompt.
|
Command/Result |
Explanation |
|
$ pwd |
print working directory |
|
/home/foxr |
|
$ cd CIT130 |
change to the CIT130 subdirectory |
|
$ ls |
list the contents |
|
HW LABS |
There are two items in this directory; both are printed
|
$ ls –l |
perform a long listing of the contents |
|
drwxr-xr-x 2 foxr foxr 1024 Jan 20 03:41 HW |
|
|
drwxr-xr-x 4 foxr foxr 4096 Jan 21 17:22 LABS |
The long listing provides more details including the creation date and time (in military time, thus 17:22 instead of 5:22 p.m.). For now, we concentrate only on the first item, which looks like a random sequence of characters. The initial ‘d’ describes that the item is a directory. The remaining letters and hyphens provide the access rights (permissions). We will cover that topic in Chapter 6.
|
$ cd HW |
change to the HW directory |
|
$ cp h1.txt /home/foxr/CIT130/LABS |
copy the h1.txt file to the LABS directory |
This instruction uses an absolute path, that is, to specify the directory LABS, we start at the root level of Linux (the first /).
|
$ cd .. |
move up one level (/home/foxr/CIT130) |
|
$ mv LABS/lab1.txt . |
move lab1.txt to here |
The . means “this directory”. Notice that the specification of the LABS subdirectory is made as a relative path, that is starting at this point.
|
$ ls ../../CSC362 |
list the contents of the CSC362 directory |
|
p1.txt p2.txt |
The ../../CSC362 is a relative path starting at this point, but moving up two levels (../..) and down one level (CSC362).
|
$ cd ~/CSC362 |
change to your CSC362 directory |
|
$ rm *.* |
delete everything here |
The ~ symbol represents the current user’s home directory. So in this case, ~ means /home/foxr. The * as used in rm is a wildcard symbol. The wildcard * means “anything”. Using *.* means “anything that contains a period”. This command then will delete all files that have a period in their name (files with extensions, as in p1.txt, a file such as foo would not be selected because it lacks a period).
The rm command is set up to execute rm –i, which means “interactive mode”. This will list each item and ask you if you are sure you want to delete it, one at a time, for example:
rm: remove regular file ‘p1.txt’? y
rm: remove regular file ‘p2.txt’? y
rm: remove regular file ‘lab1.txt’? n
The responses provided by the user, in this case, will cause rm to delete p1.txt and p2.txt but not lab1.txt (which was moved here from the CIT130/LABS directory).
|
$ cd .. |
move up to foxr |
|
$ rmdir CSC362 |
delete the entire CSC362 directory |
|
rmdir: CSC362: Directory not empty |
Because the directory is not empty, it cannot be deleted. We could delete the directory if we first deleted the remaining item, lab1.txt.
Alternatively, we could issue the command rm –r CSC362. The –r option means “recursive delete”. A recursive delete deletes all of the contents of the directory before deleting the directory, recursively (so that if the directory had a subdirectory, the contents of the subdirectory are deleted first, followed by the contents of the directory including the subdirectory itself). So, for instance, if we issued rm –r ~foxr/CIT130, the pattern of deletions would operate as follows: h1.txt, h2.txt, h3.txt, HW (the directory), h1.txt, lab2.txt (recall that we previously copied h1.txt from the HW directory to here and that we moved the lab1.txt file to another directory), LABS (the directory), and finally the CIT130 directory.
The –r option can be very powerful but also very dangerous. It is best to never use rm –r unless you do rm –ir. The –i portion of the option forces rm to seek confirmation before deleting anything. It is especially important never to use rm –r as system administrator unless you are absolutely sure of what you are doing. Imagine that you did cd / (move to the top of the file system) followed by rm –r *.*. You would delete everything (including the rm program itself)!
Note: cp also has a recursive mode, cp –r, to recursively copy any subdirectories of a directory but mv does not have a recursive mode.
|
$ cd / |
move to the top of the file system |
|
$ cd home |
move down to the home directory |
|
$ ls |
list the contents |
|
foxr zappaf |
|
|
$ cd zappaf |
move to zappaf’s directory |
|
$ cp music/*.* ~ |
copy files in music to your directory |
Again, the *.* means “everything with a period”. So, this command copies all files in zappaf’s music directory that have a period in their name to ~, which denotes your home directory.
|
$ mv videos/*.* ~ |
move everything |
|
mv: cannot move ‘/home/zappaf/videos/v1.avi’ to ‘./v1.avi’: Permission denied |
Although you might have permission to access zappaf’s directory and the contents, you do not have access to move because move in essence deletes files from that user’s directory. We will explore permissions in Chapter 6.
|
$ cd ~ |
return to your home directory |
|
$ mkdir STUFF |
create a directory called STUFF |
|
$ ln –s videos/v1.avi STUFF/video |
create a symbolic link |
The symbolic link is stored in the subdirectory STUFF (/home/foxr/STUFF), and the link is called video. The link points to or links to /home/zappaf/videos/v1.avi.
|
$ ls STUFF |
list contents of the STUFF directory |
|
video |
The ls command merely lists items by name, without providing any detail. If we want greater detail, we must use the –l option of ls (for “long listing”).
$ ls –l STUFF
lrwxrwxrwx 1 foxr foxr 16 Jan 21 17:13 video -> /home/zappaf/videos/v1.avi
With the long listing, we see that video is a link to the location /home/zappaf/videos/v1.avi. The “l” character at the beginning of the line is the file type (link) and the -> on the right indicates where the link is pointing to.
DOS
We limit our look at the DOS commands because they are similar and because there are fewer options. Here we step through only a portion of the previous example.
|
Command/Result |
Explanation |
|
C: |
switch to C: partition/drive |
|
C:> cd Usersfoxr |
move to foxr directory |
|
C:Usersfoxr> dir |
list the contents |
Notice that when you switch directories, your prompt changes. There is no equivalent of the pwd Linux command to list your current directory. The dir command provides the contents of the directory. This is excerpted below. Some details are omitted.
Wed 11/23/2011 10:53 AM <DIR> .
Wed 11/23/2011 10:53 AM <DIR> ..
Wed 11/23/2011 10:55 AM <DIR> Desktop
Wed 11/23/2011 10:55 AM <DIR> Documents
Wed 11/23/2011 10:55 AM <DIR> Downloads
...
0 File(s)
15 Dir(s)
|
C:Usersfoxr> cd Documents |
change to Documents directory |
|
C:UsersfoxrDocuments> copy *.* Userszappaf |
copy everything to zappaf’s directory |
|
C:UsersfoxrDocuments> cd .. |
move up 1 level |
|
C:Usersfoxr> cd Downloads |
move down to Downloads |
|
C:UsersfoxrDownloads> move *.* Userszappaf |
move instead of copy |
|
C:Usersfoxr> cd Userszappaf |
switch to zappaf’s directory |
Notice that there is no equivalent of ~ in DOS, so you have to specify either a relative or absolute path to get to zappaf. From UsersfoxrDownloads to zappaf, you could use this relative path: cd ....zappaf.
|
C:Userszappaf> dir |
list zappaf’s directory contents |
This should now include all of the files found under foxr’s Documents and Downloads. The listing is omitted here.
C:Userszappaf> del *.*
C:Userszappaf>
Notice that the deletion took place. You were not prevented from deleting zappaf’s files. This is because proper permissions to protect zappaf’s directory and files was not set up!
We conclude this example with these comments. As in Linux, to create and delete directories, you have the commands mkdir and rmdir. You can also create hard and soft links using the command mklink. As you may have noticed, the * wildcard symbol also works in DOS. DOS commands also permit options. The del command can be forced to prompt the user by using del /P and to delete without prompting using /Q (quiet mode). Unlike Linux, del does not have a recursive mode.
File System and System Administration Tasks
Although it is up to individual users to maintain their own file system space, there are numerous tasks that a system administrator might manage. The first and most important task of course is to make sure that the file system is available. This will require mounting the system as needed. The Linux commands mount and umount are used to mount a new partition to the file system and unmount it. The commands require that you specify both the file system and its mount point. A mount point is the name by which users will reference it. For instance, if you do a df –k, you will see the various mount points including /var and /home. The command mount –a will mount all of the file system components as listed in the special file /etc/fstab (file system table). This command is performed automatically at system initialization time, but if you have to unmount some partitions, you can issue this command (as root) to remount everything. The /etc/fstab file includes additional information that might be useful, such as disk quotas, and whether a given file space is read-only or readable and writable. All currently mounted partitions are also indicated in the file /etc/mtab.
Setting up disk quotas is a complex operation but might be useful in organizations where there are a lot of users and limited disk space. You might establish a disk usage policy (perhaps with management) and implement it by setting quotas on the users.
Another usage policy might include whether files should be encrypted or not. Linux has a number of open source encryption tools, and there are a number of public domain tools available for Windows as well.
Remote storage means that a portion of the file system is not local to this computer, but accessible over a network instead. In order to support remote storage, you must expand your file system to be a network file system. NFS is perhaps the most common form of this, and it is available in Unix/Linux systems. NFS is very complex. You can find details on NFS in some of the texts listed in Further Reading.
These last topics, although useful, will not be covered in this text but should be covered in a Linux system administration text.
Further Reading
Many of the same texts referenced in Further Reading in Chapter 4 cover material specific to Linux, Unix, Windows, and Mac OS file systems. Additionally, the OS concepts books from the same section all have chapters on file systems. More detailed material on Windows, Unix, and Linux file systems can be found in these texts.
- Bar, M. Linux File Systems. New York: McGraw Hill, 2001.
- Callaghan, B. NFS Illustrated. Reading, MA: Addison Wesley, 2000.
- Custer, H. Inside the Windows NT File System. Redmond, WA: Microsoft Press, 1994.
- Kouti, S. Inside Active Directory: A System Administrator’s Guide. Boston: Addison Wesley, 2004.
- Leach, R. Advanced Topics in UNIX: Processes, Files and Systems. Somerset, NJ: Wiley and Sons, 1994.
- Moshe, B. Linux File Systems. New York: McGraw Hill, 2001.
- Nagar, R. Windows NT File System Internals. Amherst, NH: OSR Press, 2006.
- Pate, S. UNIX Filesystems: Evolution, Design and Implementation. New Jersey: Wiley and Sons, 1988.
- Von Hagen, W. Linux Filesystems. Indianapolis, IN: Sams, 2002.
On the other hand, these texts describe file systems from a design and troubleshooting perspective, which might be more suitable for programmers, particularly OS engineers.
- Carrier, B. File System Forensic Analysis. Reading, MA: Addison Wesley, 2005.
- Giampaola, D. Practical File System Design. San Francisco: Morgan Kaufmann, 1998.
- Harbron, T. File Systems: Structure and Algorithms. Upper Saddle River, NJ: Prentice Hall, 1988.
- Kerrisk, M. The Linux Programming Interface: A Linux and UNIX System Programming Handbook. San Francisco: No Starch Press, 2010.
- Pate, S. and Pate, S. UNIX Filesystems: Evolution, Design and Implementation. Hoboken, NJ: Wiley and Sons, 2003.
- Tharp, A. File Organization and Processing. New York: Wiley and Sons, 1998.
Review Terms
Terminology introduced in this chapter:
Absolute path File system
Alias Folder
Archive Fragment
Block Hard link
Cylinder Indirect block
Defragmentation inode
Directory Lossless compression
FAT Lossy compression
File Mounting
Mount point Rotational delay
NFS Sector
Partition Seek time
Platter Soft link
Pointer Spindle
Read/write head Surface
Recursive delete Track
Relative path Transfer time
Review Questions
- How does a file differ from a directory?
- What makes the file space hierarchical?
- Why are disk files broken up into blocks and scattered across the disk surface(s)?
- Imagine that a file block is located at disk block 581132. What does this information tell you?
- What is a pointer and what is a linked list?
- What is a FAT? Where is the FAT stored?
- Why is the FAT loaded into memory?
- How much slower is disk access than the CPU?
- The Linux operating system does not maintain a FAT, so how are disk blocks accessed?
- What is an indirect block inode?
- What would happen if your Linux file system were to run out of inodes?
- How does the Linux file system differ from the Windows file system?
- In the Linux file system, where do you find most of the system configuration files?
- In the Linux file system, where do you find the system administration commands (programs)? The general Linux commands? The user (applications) programs?
- Which of the Linux items listed under /dev are not physical devices?
- If a disk partition is not mounted, what are the consequences to the user?
- What do each of these Linux commands do? cd, cp, ln, ls, mkdir, pwd, rm, rmdir
- What do each of these DOS commands do? cd, copy, del, dir, mklink, move
- What is the difference between ls and ls –l in Linux?
- What is the difference between rm –i, rm –f, and rm –r in Linux?
- Why does DOS not need a pwd command?
- What must be true about a directory in Linux before rmdir can be applied?
- If you set up a symbolic link to a file in another user’s directory, what happens if the user deletes that file without you knowing about it? What happens if you delete your symbolic link?
- What does ~ mean in Linux? Is there a similar symbol in DOS?
- What does .. mean in both Linux and DOS?
- What is the difference between an absolute path and a relative path?
- Refer back to Figure 5.11. Write an absolute path to the file p1.txt.
- Refer back to Figure 5.11. Write an absolute path to the file m2.mp3.
- Refer back to Figure 5.11. Assuming that you are in the subdirectory LABS, write a relative path to the file v1.avi. Write an absolute path to the file v1.avi.
- Refer back to Figure 5.11. Assuming that you are in the subdirectory CSC362, write a Linux copy to copy the file p1.txt to the directory HW.
- Refer back to Figure 5.11. Assuming that you are in the subdirectory CSC362, write a Linux move command to move the file p1.txt to the directory other (under zappaf).
Discussion Questions
- In the Windows operating system, the structure of the file system is often hidden from the user by using default storage locations such as My Documents and Desktop. Is this a good or bad approach for an end user who is not very knowledgeable about computers? What about a computer user who is very familiar with the idea of a file system?
- Do you find the finer breakdown of the Linux file system’s directory structure to be easier or harder to work with than Windows? Why?
- What are some advantages to separating the file system into partitions? Do you find the Windows approach or the Linux approach to partitions to be more understandable?
- Now that you have interacted with a file system through both command line and GUI, which do you find more appealing? Are there situations where you find one approach to be easier than the other? To be more expressive?
- The discussion of the FAT (in Windows) and inodes (in Linux) no doubt can be confusing. Is it important for an IT person to have such a detailed understanding of a file system? Explain.
- A hard disk failure can be catastrophic because it is the primary storage media that contains all of our files and work. Yet the hard disk is probably the one item most apt to fail in the computer because of its moving parts. Research different ways to backup or otherwise safeguard your hard disk storage. Describe some of the approaches that you found and rank them in terms of cheapest to most expensive cost.
- Within your lifetime, we have seen a shift in technology from using magnetic tape to floppy disk as storage to hard disk, and in between, the rise and fall of optical disks. Although we still use optical disks, they are not nearly as common today for data storage as they were 10 years ago. Research the shift that has taken place and attempt to put into perspective the enormous storage capacity now available in our computers and how that has changed the way we use computers and store files.