
Chapter 13
Software
This chapter begins with an introduction to software classifications and terminology. However, the emphasis of this chapter is on software management, specifically software installation in both Windows and Linux. In Linux, the discussion concentrates on the use of package managers and the installation of open source software. The chapter ends with an examination of server software with particular attention paid to installing and configuring the Apache web server at an introductory level.
The learning objectives of this chapter are to
- Discuss types of software and classification of proprietary and free software.
- Describe the process of software installation from an installation wizard and package manager.
- Illustrate through example how to install open source software in Linux using configure, make, and make install.
- Describe the function of popular server software.
- Introduce Apache web server installation and configuration.
Here, we look at the various types of software and consider what an IT specialist might have to know about. Aside from introducing software concepts and terminology, we will focus on software maintenance and installation. We end the chapter with an examination of servers, server installation, and maintenance.
Types of Software
The term software refers to the programs that we run on a computer. We use the term software because programs do not exist in any physical, tangible form. When stored in memory, they exist as electrical current, and when stored on disk, they exist as magnetic charges. Thus, we differentiate software from hardware, whose components we can point to, or pick up and touch.
This distinction may seem straightforward; however, it is actually not as simple as it sounds. Our computers are general purpose, meaning that they can run any program. The earliest computers from the 1930s and 1940s were not general purpose but instead only could run specific types of programs, such as integral calculus computations or code breaking processes. We see today that some of our devices, although having processors and memory, are also special purpose (e.g., navigation systems, mp3 players, game consoles). But aside from these exceptions, computers can run any program that can be compiled for that platform. On the other hand, anything that we can write as software can also be implemented using circuits. Recall that at its lowest level, a computer is merely a collection of AND, OR, NOT, and XOR circuits (along with wires to move data around). We could therefore bypass the rest of the computer and implement the given program at the circuit level. Capturing a program directly in hardware is often referred to as firmware (or a hardwired implementation). Similarly, any program that can be built directly into circuits can also be written in some programming language and run on a general purpose computer.
This concept is known as the equivalence of hardware and software. Thus, by calling one entity software and another hardware, we are differentiating how they were implemented, but not how they must be implemented. We typically capture our programs in software form rather than implement them as hardware because software is flexible. We can alter it at a later point. In addition, the creation of firmware is often far more expensive than the equivalent software. On the other hand, the fetch–execute process of the CPU adds time onto the execution of a program. A program implemented into firmware will execute faster, possibly a good deal faster, than one written as software. Therefore, any program could conceivably be implemented as software or firmware. The decision comes down to whether there is a great need for speed or a desire for flexibility and a cheaper production cost. Today, most programs exist as software. Those captured in firmware include computer boot programs and programs found inside of other devices, such as the antilock brake system or the fuel-injection system in a car.
We prefer to store our programs as software because software can be altered. Most software today is released and then revised and revised again. We have developed a nomenclature to reflect software releases. Most software titles have two sets of numbers listed after the title. The first number is the major release version and the second is the minor release version. For instance, Mozilla Firefox 5.2 would be the fifth major version of Firefox and the second minor release of version 5. A minor release typically means that errors were fixed and security holes were plugged. A major release usually means that the software contains many new features likely including a new graphical user interface (GUI). It is also possible that a major release is rewritten with entirely new code. Minor releases might appear every month or two, whereas major releases might appear every year or two. Service packs are another means of performing minor releases; however, service packs are primarily used to release operating system updates.
We generally categorize software as either system software or application software. Application software consists of programs that end users run to accomplish some task(s). The types of application software are as varied as there are careers because each career has its own support software. Productivity software consists of the applications that are useful to just about everyone. Productivity software includes the word processor, presentation software (e.g., PowerPoint), spreadsheet program, database management systems, calendar program, address book, and data organizer. Drawing software may also be grouped here although drawing software is more specific toward artists and graphic designers. Another type of application software is that based around Internet usage. Software in this class includes the e-mail client, web browser, and FTP client. There are also computer games and entertainment software (e.g., video players, DVD players, CD players); although not considered productivity software, they are used by just about everyone.
A Brief History of Productivity Software
1963—IBM developed GUAM, the first database management system, for IBM mainframes intended for use by the National Aeronautics and Space Administration.
1963—Based on a doctoral thesis, an MIT student released Sketchpad, a real-time computer drawing system using a light pen for input.
1964—IBM released MT/ST, the first word processor; I/O was performed on a Selectric keyboard, not directly with the computer.
Early 1970s—INGRES, the first relational database software, released by Relational Technology, followed shortly thereafter by Oracle.
1972—Lexitron and Linolex both introduced machines capable of displaying word process text on a screen (rather than operated on remotely).
1976—Electric Pencil, the first PC word processor, was released.
1979—VisiCalc, the first spreadsheet program, was released for the Apple II.
1979—The WordStar word processor was developed and would become very popular.
1982—Lotus 1-2-3 was released, which combined spreadsheets, graphics, and data retrieval in one software.
1984—Apple released Appleworks, the first office suite.
1985—PageMaker, for Macintosh, was released, a GUI-based word processor making desktop publishing available for personal computers.
Productivity software is sometimes referred to as horizontal software because the software can be used across all divisions in an organization. Vertical software applies instead to software used by select groups with an organization or to a specific discipline. For instance, there are classes of software used by musicians such as music sequencers, samplers, and digital recorders. Programmers use development platforms that provide not only a language compiler but also programming support in the form of debugging assistance, code libraries, tracking changes, and code visualization. Filmmakers and artists use video editing, photographic editing and manipulation, and sound editing software. There is a large variety of accounting software available from specialized tax software to digital ledgers.
System software consists of programs that make up the operating system. System software is software that directly supports the computer system itself. Such software is often started automatically rather than by request of the end user. Some pieces of the operating system run in the background all of the time. These are often known as daemons or services. They wait for an event to arise before they take action. Other pieces of the operating system are executed based on a scheduler. For instance, your antiviral software might run every 24 hours, and a program that checks a website for any updates might run once per week. Yet other pieces, often called utilities, are run on demand of the user. For instance, the user might run a disk defragmentation utility to improve hard disk performance. Antiviral software is another utility, although as stated above, it may be executed based on a scheduler.
The various layers of the operating system, and their relationship with the hardware, the application software and the user, are shown in Figure 13.1. The figure conveys the layering that takes place in a computer system where the hardware operates at the bottommost level and the user at the top. Each action of the user is decomposed into more and more primitive operations as you move down the layer.

The core components of the operating system are referred to as the kernel. The kernel is loaded when the computer is first booted. Included in the kernel are the components that handle process management, resource management, and memory management. Without these, you would not be able to start a new program or have that program run efficiently. The kernel sits on top of the hardware and is the interface between hardware and software.
Another piece of the operating system is the collection of device drivers. A device driver is a critical piece of software. The user and applications software will view hardware devices generically—for instance, an input device might respond to commands such as provide input, check status, reboot. But every device requires unique commands. Therefore, the operating system translates from the more generic commands to more specific commands. The translation is performed by the device driver software. Although a few device drivers are captured in the ROM BIOS as firmware, most device drivers are software. Many popular device drivers are preloaded into the operating system, whereas others must be loaded off of the Internet or CD-ROM when a new hardware device has been purchased. In either case, the device driver must be installed before the new hardware device can be used. There are literally hundreds of thousands of drivers available (according to driverguide.com, more than 1.5 million), and there is no need to fill a user’s hard disk drive with all of them when most will never be used.
Other system software components sit “on top” of the kernel (again, refer to Figure 13.1). Components that are on top of the kernel include the tailored user environment (shells or the user desktop), system utility programs, and services/daemons. As discussed in Chapter 9, Linux shells permit users to establish their own aliases and variables. Desktop elements include shortcut icons, the theme of the windows, menus and background, the appearance of toolbars and programs on the start menu, and with Windows 7, desktop gadgets.
System utilities are programs that allow the user to monitor and improve system performance. We discussed some of these when we talked about processes. To improve system performance, utilities exist to defragment the hard disk and to scan files for viruses and other forms of malware. Usually, system utilities must be installed separately as they may not come with the operating system (often, these require purchasing and so many users may ignore their availability).
Services, or daemons, are operating system programs that are usually started when the operating system is loaded and initialized, but run in the background. This means that the program, while it is active, does not take up any CPU time until it is called upon. The operating system will, when a particular event arises, invoke the needed service or daemon to handle the event. There are numerous services in any operating system. We covered services in Chapter 11, Services, Configuring Sevices, and Establishing Services at Boot Time.
Aside from the system software and the application software, there is also server software. Servers include web servers, e-mail servers, and database servers, to name a few. We will examine servers in Services and Servers, with an emphasis on the Apache web server.
OLE!
One of the key components found in many forms of Windows-based productivity software today is the ability to link and embed objects created from one piece of software into another. OLE stands for Object Linking and Embedding. It was developed in 1990 as a successor to dynamic data exchange, made available in Windows 2.0, so that data could be transferred between two running applications. This allowed, for instance, for a Microsoft Access record to be copied or embedded into a Microsoft Excel spreadsheet. Modifying the record in Access would automatically update the values stored in Excel. This capability was implemented through tables of pointers whereby one application’s data would point at data stored in other applications.
However, data exchange was limited. With OLE, improvements include the ability to capture an object as a bitmap to be transferred pictorially into another application through the clipboard. Also, the table of pointers was replaced through the Component Object Model (COM). In addition, the user’s means to copy or embed objects was simplified through simple mouse operations.
OLE is a proprietary piece of technology owned by Microsoft. Today, Microsoft requires that any application software be able to utilize OLE if that piece of software is to be certified as compatible with the Windows operating system.
Software-Related Terminology
In this section, we briefly examine additional terms that help us understand software.
Compatibility describes the platforms that a piece of software can execute on. Most software that our computers run requires that the software be compiled for that computer platform. There are three issues here. First, the software must be compiled for the class of processor of the given computer. Intel Pentium processors, for instance, have different instruction sets than MIPS processors. If someone were to write a program and compile it for the Pentium processor, the compiled program would not run on a MIPS processor. Because of the close nature between the hardware and the operating system, the compilation process must also be for a given operating system platform. A computer with a Pentium processor running Linux rather than Windows could not execute programs compiled for Windows in spite of having the same processor. Therefore, software must be compiled for both the processor and the operating system. Finally, the software might have additional requirements to run, or at least to run effectively, such as a minimum amount of RAM or hard disk space or a specific type of video card.
Backward compatibility means that a piece of software is capable of reading and using data files from older versions of the software. Most software vendors ensure backward compatibility so that a customer is able to upgrade the software without fear of losing older data. Without maintaining backward compatibility, a customer may not wish to upgrade at all. Maintaining backward compatibility can be a significant challenge though because many features in the older versions may be outdated and therefore not worth retaining, or may conflict with newer features. Backward compatibility also refers to newer processors that can run older software. Recall that software is compiled for a particular processor. If a new version of the processor is released, does it maintain backward compatibility? If not, a computer user who owns an older computer may have to purchase new software for the newer processor. Intel has maintained backward compatibility in their x86 line of processors, starting with the 8086 and up through the most recent Pentium. Apple Macintosh has not always maintained backward compatibility with their processors.
Upgrades occur when the company produces a new major or minor release of the software. Today, most upgrades will happen automatically when your software queries the company’s website for a new release. If one is found, it is downloaded and installed without requiring user authorization. You can set this feature in just about any software so that the software first asks you permission to perform the upgrade so that you could disallow the upgrade if desired. However, upgrades often fix errors and security holes. It is to your advantage to upgrade whenever the company recommends it.
Patches are releases of code that will help fix immediate problems with a piece of software. These are typically not considered upgrades, and may be numbered themselves separately from the version number of the software. Patches may be released at any time and may be released often or infrequently depending on the stability of the software.
Beta-release (or beta-test) is an expression used to describe a new version of software that is being released before the next major release. The beta-release is often sent to a select list of users who are trusted to test out the software and report errors and provide feedback on the features of the software. The company collates the errors and feedback and uses this to fix problems and enhance the software before the next major release. A beta-release might appear a few months or a full year before the intended full release.
Installation is the process of obtaining new software and placing it on your computer. The installation process is not merely a matter of copying code onto the hard disk. Typically, installation requires testing files for errors, testing the operating system for shared files, placing files into a variety of directories, and modifying system variables such as the path variable. Installation is made easy today with the use of an installation wizard. However, some software installation requires more effort. This will be addressed in Software Management. A user might install software from a prepackaged CD-ROM* or off of the Internet. In the latter case, the install is often referred to as a download. The term download also refers to the action of copying files from some server on the Internet, such as a music download. Installation from the Internet is quite common today because most people have fast Internet access.
There are several categories to describe the availability of software. Proprietary, or commercial, software is purchased from a vendor. Such software may be produced by a company that commercially markets software (usually referred to as a software house), or by a company that produces its own in-house software, or by a consultant (or consultant company) hired to produce software. Purchasing software provides you with two or three things. First, you receive the software itself, in executable form. If you have purchased the software from a store or over the Internet, the software is installed via an installation program. If you have purchased it from a consultant, they may perform the installation themselves. Second, you are provided a license to use the software. It is often the case that the software purchase merely gives you the right to use the software but it is not yours to own. Third, it is likely that the purchase gives you access to helpful resources, whether they exist as user manuals, technical support, online help, or some combination.
The other categories of software all describe free software, that is, software that you can obtain for free. Free does not necessarily mean that you can use the software indefinitely or any way you like, but means that you can use it for now without paying for it. One of the more common forms of software made available on the Internet is under a category called shareware. Shareware usually provides you a trial version of the software. Companies provide shareware as a way to entice users to purchase the software. The trial version will usually have some limitation(s) such as a set number of uses, a set number of days, or restrictions on the features. If you install shareware, you can often easily upgrade it to the full version by purchasing a registration license. This is usually some combination of characters that serves to “unlock” the software. The process is that you download the shareware. You use it. You go to the website and purchase it (usually through credit card purchase), and you receive the license. You enter the license and now the software moves from shareware to commercial software.
On the other hand, some software is truly free. These fall into a few categories. First, there is freeware. Such software is free from purchase, but not necessarily free in how you use it. Freeware is usually software that has become obsolete because a newer software has replaced it, or is software that the original producer (whether an individual or a company) no longer wishes to maintain and provide support for. You are bound by some agreements when you install it, but otherwise you are free to use it as if you purchased it. Public domain software, on the other hand, is software that has been moved into the public domain. Like freeware, this is software that no one wishes to make money off of or support. Anything found in the public domain can be used however you feel; no one is claiming any rights for it. Both freeware and public domain software are made available as executables. Finally, there is open source software. As discussed in Chapter 8, this software was created in the Open Source Community and made freely available as source code. You may obtain the software for free; you may enhance the software; you may distribute the software. However, you have to abide by the copyright provided with the software. Most open source software is made available using the GNUs Public License, and some are made available with what is known as a copyleft instead of a copyright.
Software Management
Software management is the process of installing, updating, maintaining, troubleshooting, and removing software. Most software today comprises a number of distinct programs including the main executable, data files, help files, shared library files, and configuration files. Installation involves obtaining the software as a bundle or package. Once downloaded or saved to disk, the process requires uncompressing the bundled files, creating directories, moving files, getting proper paths set up, and cleaning up after the installation process. In the case of installing from source code, an added step in the process is compiling the code. Today, the installation process has been greatly simplified thanks to installation wizards and management packages. In Linux, for instance, users often install from yum or rpm. Here, we look at the details of the installation process, upgrading the software, and removing the software.
A software installation package is a single file that contains all of the files needed to install a given software title. The package has been created by a software developer and includes the proper instructions on how to install and place the various files within the package. You might perform the installation from an optical disk, or just as likely, by downloading the software from the Internet. Installation wizards require little of the user other than perhaps specifying the directory for the software, agreeing to the license, and answering whether shortcuts should be created.
Because the Windows end user is often not as knowledgeable about the operating system as the typical Linux end user, Windows installs have been simplified through the use of the Windows Installer program, an installation wizard. The Installer program is typically stored as an .msi file (MicroSoft Installer) and is bundled with the files necessary for installation (or is programmed to download the files from a website). The installation files are structured using the same linkages that make OLE possible (see the sidebar earlier in this chapter), COM files. The installer, although typically very easy to use, will require some user interaction. At a minimum, the user is asked to accept the software’s licensing agreement. In addition, the installer will usually ask where the software should be installed. Typically, a default location such as C:Program Files (x86)softwarename is chosen, where softwarename is the name of the software. The user may also be asked whether a custom or standard installation should be performed. Most installers limit the number of questions in the standard install in order to keep matters as simple as possible. Figure 13.2 shows four installation windows that may appear during a standard installation. Note that these four windows are from four different software installations, in this case all open source.
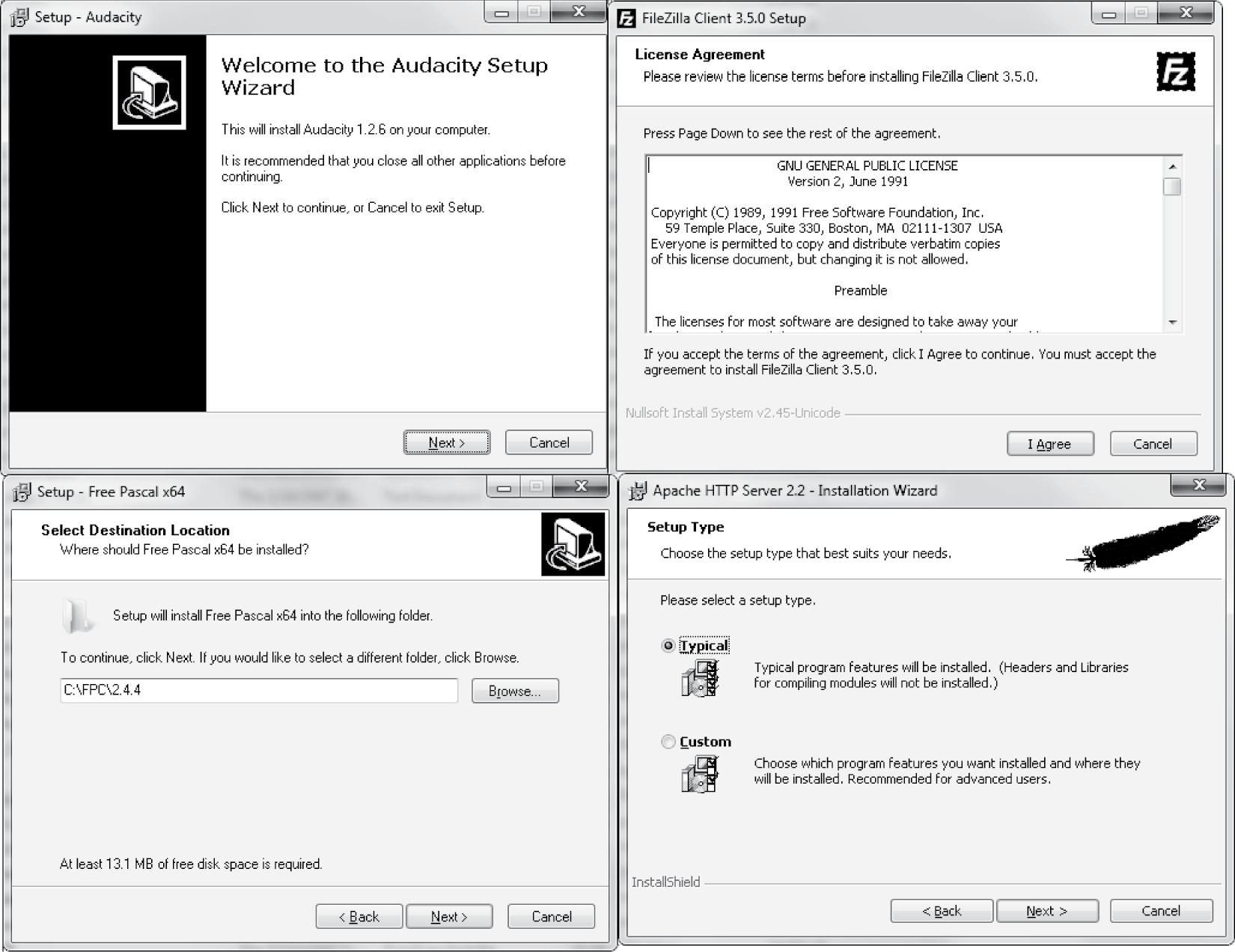
In spite of the ease of installation through Windows Installers, there are still things the user should know. The most important concern is whether you have the resources needed to run the software. The most critical resources are sufficient hard disk space, fast enough processor, and sufficient RAM. Before installing the software, you may want to check out the installation requirements. You also must make sure that you are installing the right version of the software—that is, the version compiled for your particular hardware and operating system platform. You will also need to make sure that you have sufficient access rights to install the software. Are you an administrator? Have you logged in as an administrator to perform the installation? Or, as a user, has your administrator permitted you access to install new software?
In Linux, there are several different ways to install software. First, there is the simplified approach using an installation wizard from downloaded software, just as you do in Windows. A second approach, also like Windows, is to install software from CD-ROM (or DVD). One difference here is that much software is available on the Linux operating system installation CD. To install from the CD, you must retrieve your installation CD and use the Add or Remove Programs feature (found under the Applications menu).
Another option in Linux is to install software packages from the command line. There are multiple approaches that one can take. The easiest command-line approach is through a package manager program. In Red Hat, there are two, yum (Yellow dog Updater, Modified) and rpm (Red Hat Package manager). The rpm program operates on rpm files. An rpm file is a package: an archive of compressed files that include the executable program(s) and related files as well as a description of the dependencies needed to run the files. Dependencies are the files that these files rely on. The rpm program will test these dependencies and alert the user of any missing files. The yum program uses rpm but handles dependencies for you, making it far easier.
To install software using rpm, the instruction is rpm –i packagename.rpm. To uninstall software, use –e (for erase) as in rpm –e packagename. To upgrade a package, use –u. Finally, you can also use –q to query the rpm database to find more information on either already installed packages, or packages that have yet to be installed (as long as the rpm files are present). You can combine the –q and –l options to get a listing of the files in a given package or the –q and –a options to get a list of all already installed packages. There are rpm repositories available at many locations on the Internet, such as http://centos.karan.org/el4/extras/stable/i386/RPMS/. Aside from using rpm from the command line prompt, you can also run GUI package managers.
Yum is a product from Duke University for Linux users. Yum calls upon rpm to perform the installation; however, it has the ability to track down dependencies and install any dependent packages as needed. As with rpm, yum can install or update software, including the Linux kernel itself. It makes it easier to maintain groups of machines without having to manually update each one using rpm. Using yum is very simple; it does most of the work by itself (although it can be time consuming to update packages and install new ones). A simple yum command is yum install title, where title is the name of the software package. Other yum commands (in place of install) include list (which lists packages that have a given name in them as in yum list “foobar”), chkconfig yum on (which schedules yum to perform an upgrade every night), yum remove title (to uninstall the titled package, removing all dependencies), and yum –y install title (which does the install, answering “yes” to any yes/no question so that the install can be done without human intervention).
The more challenging form of installation in Linux is installation of software from source code. Source code is the program code written in a high level language (e.g., C++ or Java). Such a program cannot be executed directly on a computer and therefore must be compiled first (we discuss compilation in the next chapter). Because so much of the software available in Linux is open source software, it is likely that a Linux user will need to understand how to install software from source code. Before attempting to install software from the source code, you might still look to see if the software is available in an executable format, either through an installation wizard or as an rpm package.
Installation from source code first requires manually unpackaging the software bundle. Most open source software is bundled into an archive. There are several mechanisms for archiving files, but the most common approach is through the Unix-based tape archive program called tar. The tar program was originally intended for archiving files to be saved onto tape. However, it is convenient and fairly easy to use, so many programmers use it to bundle their software together.
A tar file will have .tar as an extension. In addition, once tarred together, the bundle may be compressed to save space and allow faster transmission of the bundle across the Internet. Today, GNU’s Zip program, gzip, is often used. This will add a .gz extension to the filename. For instance, a bundled and zipped archive might appear as bundle.tar.gz. The user must first unzip the compressed file using gunzip. This restores the archive, or bundle. To unbundle it, the next step is to untar the bundle, using tar.
When creating a tar file, you must specify both the source file(s) and the name of the tar file along with the options that indicate that you are creating a tar file (c) and that the destination is a file (f) instead of tape. This command could look like: tar –cf bundle1.tar *.txt or it might look like: tar –cf bundle2.tar /temp. The former case would take all.txt files and tar them into an archive, whereas the latter example takes all files in the directory /temp, including the directory itself, and places them in the archive. To untar the file, the command is tar –xf bundle2.tar. The x parameter stands for extract, for file extraction. If you were to untar bundle2.tar, it would create the directory /temp first and then place the contents that were stored in the original /temp directory into this new /temp directory.
Once the software has been unbundled, you must compile it. Most open source programs are written in either C or C++. The compilers most commonly used in Linux for C and C++ are gcc (GNU’s C/C++ compiler) and g++ (gcc running specific c++ settings). Unfortunately, in the case of compiling C or C++ programs, it is likely that there are numerous files to deal with including header files (.h), source code files (.c or .cpp), and object files (.o). Without a good deal of instruction, a user trying to compile and install software may be utterly lost. Linux, however, has three very useful commands that make the process simple. These are the commands configure, make, and make install. These commands run shell scripts, written by the programmer, to perform the variety of tasks necessary to successfully compile and install the software.
The configure command is used to create or modify a Makefile script. The Makefile script is the programmer’s instructions on how to compile the source code. The configure command might, for instance, be used by the system administrator to specify the directories to house the various software files and to specify modules that should be compiled and included in the software. If no Makefile exists, the configure command must be executed. If a Makefile already exists, the configure command is sometimes optional. The configure command is actually a script, also set up by the programmer. To run the configure script, one enters ./configure (rather than configure). The ./ means “execute this shell script”. Once completed, there is now a Makefile.
The command make executes the Makefile script (NOTE: make will execute either Makefile or makefile, whichever it finds). The Makefile script contains all of the commands to compile the software. The Makefile script may also contain other sections aside from compilation instructions. These include an install section to perform the installation steps (if the software is to be installed into one or more directories), a clean section to clean up any temporarily created files that are no longer needed, and a tar section so that the combined files can be archived. If everything goes smoothly, all the user has to do is enter the commands ./configure, make, make install. A good Makefile will call make clean itself after performing the installation steps. These steps may take from a few seconds to several minutes depending on the amount of code that requires compilation.
Before trying to perform the compilation and installation of software, the administrator should first read the README text file that comes with the distribution. Like the Makefile script, README is written by the programmer to explain installation instructions. Reading the README file will help an administrator perform the compilation and installation steps especially if there are specific steps that the programmer expects the administrator to carry out in advance because the programmer has made certain assumptions of the target Linux system. For instance, the programmer might assume that gcc is installed in a specific location or that /usr/bin is available. The README file may also include hints to the administrator for correcting errors in case the Makefile script does not work.
Figure 13.3 provides an example Makefile script. This is a short example. Many Makefile scripts are quite large. The example Makefile script from Figure 13.3, although short, shows that the contents of a Makefile are not necessarily easy to understand. The first four lines of this script define variables to be used in the Makefile file. In this example, there are three program files: file1.c, file2.c, and file3.c. These are stored in the variable FILES. The next three lines define variables for use in the compilation steps. These variables define the name of the compiler (gcc, the GNU’s C compiler), compiler flags for use during compilation, and linker flags for use during the linking stage of compilation. Note that the items on the right-hand side of the file are comments (indicated by being preceded by the // charac ters). Comments are ignored by the bash interpreter when the script executes.

The next six lines represent the commands to execute when the make command is issued. The idea behind these six lines is that each first defines a label, possibly with arguments (e.g., $(FILES)), and on the next line, indented, a command to carry out. The all: label has no arguments, and its sole command is to execute the command under the files: label. This is often used in a Makefile for the command make all. The files label iterates through all of the files in the variable $(FILES) (i.e., the three C files) and issues the gcc linking command on each. Beneath this is the line .c, which is used to actually compile each C program. The compilation and linking steps can be done together, but are often separated for convenience. The last four lines pertain to the instructions that will execute if the user issues either make clean or make tar. The former cleans up any temporary files from the current directory, and the latter creates a tar file of all relevant program files. Because this was such a simple compilation process, there is no need for an install section.
The programmer(s) writes the Makefile file and packages it with all source code and any other necessary files (such as documentation). The administrator then installs the software by relying on the Makefile script. It is not uncommon that you might have to examine the script and make changes. For instance, imagine that the Makefile moved the resulting files to the directory /usr/local/bin but you wanted to move it to /usr/bin instead, requiring that you make a minor adjustment in the script, or if you wanted to change the settings for the compiler from –g and –Wall to something else.
With the use of package management facilities such as rpm and yum, why are configure, make, and make install important? They may not be if you are happy using the executable code available through the rpm repository websites. However, there are two situations where they become essential. First, some open source software does not come in an executable form and therefore you have no choice but to compile it yourself. Second, if you or someone in your organization wanted to modify the source code, you would still have to install it using the configure, make, and make install commands. We will briefly look at the use of configure in the next section.
Services and Servers
The term server may be used to refer to three different things. The first is a dedicated computer used to provide a service. Servers are typically high-performance computers with large hard disk drives. In some cases, servers are built into cabinets so that several or even dozens of hard disk drives can be inserted. The server is commonly a stand-alone computer. That is, it is not someone’s desktop machine, nor will users typically log directly into the server unless they happen to be the administrator of the server.
The second use of the term server is of the software that is run on the machine. Server software includes print service, ftp server, webserver, e-mail server, database server, and file server. The software server must be installed, configured, and managed. These steps may be involved. For instance, configuring and managing the Apache web server could potentially be a job by itself rather than one left up to either a system administrator or web developer.
The third usage for server is the collection of hardware, software, and data that together constitutes the server. For instance, we might refer to a web server as hardware, software, and the documents stored there.
In this section, we look at a few types of software servers. We emphasize the Apache web server with a look at installation and minimal configuration. Below is a list of the most common types of servers.
Web Server
The role of a web server is to respond to HTTP requests. HTTP requests most typically come from web browsers, but other software and users can also submit requests. HTTP is the hypertext transfer protocol. Most HTTP requests are for HTML documents (or variants of html), but could include just about any web-accessible resource. HTTP is similar to FTP in that a file is transferred using the service, but unlike FTP, the typical request is made by clicking on a link in a web browser—and thus, the user does not have to know the name of the server or the name or path of the resource. These are all combined into an entity known as a URL. The open source Apache server is the most popular web server used today. Aside from servicing requests, Apache can execute scripts to generate dynamic pages, use security mechanisms to ensure that requests are not forms of attacks, log requests so that analysts can find trends in the public’s browser behavior of the website, and numerous other tasks. We look at Apache in more detail below. Internet Information Server (also called Internet Information Services), or IIS, is a Microsoft web server, first made available for Windows XP operating systems and also comes with Windows Vista and Windows 7.
Proxy Server
A proxy server is used in an organization to act as a giant cache of web pages that anyone in the organization has recently retrieved. The idea is that if many people within the organization tend to view the same pages, caching these pages locally permits future accesses to obtain the page locally rather than remotely. Another function of the proxy server is to provide a degree of anonymity since the IP address recorded by the web server in response to the request is that of the proxy server and not the individual client. Proxy servers can also be used to block certain content from being returned, for instance, rejecting requests going out to specific servers (e.g., Facebook) and reject responses that contain certain content (e.g., the word “porn”). Squid is the most commonly used proxy server although Apache can also serve as a proxy server. Squid, like Apache, is open source. Among the types of things a system administrator or web administrator might configure with Squid are the number and size of the caches, and the Squid firewall to permit or prohibit access of various types.
Database Server
A database is a structured data repository. A database management system is software that responds to user queries to create, manipulate, and retrieve records from the database. There are numerous database management system packages available. A database server permits database access across a network. The database server will perform such tasks as data analysis, data manipulation, security, and archiving. The database server may or may not store the database itself. By separating the server from the database, one can use different mechanisms to store the database, for instance a storage area network to support load balancing. MySQL is a very popular, open source database server. MySQL is actually an umbrella name for a number of different database products. MySQL Community is the database server. There is also a proxy server for a MySQL database, a cluster server for high-speed transactional database interaction, and a tool to support GUI construction.
FTP Server
An FTP server is like a webserver in that it hosts files and allows clients to access those files. However, with FTP, access is in the form of uploading files and downloading files. Any files downloaded are saved to disk unlike the web service where most files are loaded directly into the client’s web browser. FTP access either requires that the user have an account (unlike HTTP), or requires that the user log in as an anonymous user. The anonymous user has access to public files (often in a special directory called /pub). FTP is an older protocol than HTTP and has largely been replaced by HTTP with the exception of file uploading. An FTP server is available in Linux, ftpd. This service is text-based. An extension to FTP is FTPS, a secure form of FTP. Although SFTP is another secure way to handle file transfer, it is not based on the FTP protocol. One can also run ssh and then use ftp from inside of ssh. Popular FTP client tools for performing FTP include WS-FTP and FileZilla, both of which are GUI programs that send commands to an FTP server. FileZilla can also operate as an FTP server, as can Apache.
File Server
A file server is in essence a computer with a large hard disk storing files that any or many users of the network may wish to access. The more complex file servers are used to not only store data files but also to store software to be run over the network. File servers used to be very prominent in computer networks because hard disk storage was prohibitively expensive. Today, with 1 TB of hard disk space costing $100, many organizations have forgone the use of file servers. The file server is still advantageous for most organizations because it supports file sharing, permits easy backup of user files, allows for encryption of data storage, and allows remote access to files. There are many different file servers available with NFS (the Network File System) being the most popular in the Unix/Linux world.
E-mail Server
An e-mail server provides e-mail service. Its job is to accept e-mail requests from clients and send messages out to other e-mail servers, and to receive e-mails from other servers and alert the user that e-mail has arrived. The Linux and Unix operating systems have a built-in e-mail service, sendmail. Clients are free to use any number of different programs to access their e-mail. In Windows, there are a large variety of e-mail servers available including Eudora, CleanMail, and Microsoft Windows Server. Unlike FTP and Web servers, which have a limited number of protocols to handle (primarily ftp, ftps, http, and https), there are more e-mail protocols that servers have to handle: IMAP, POP3, SMTP, HTTP, MAPI, and MIME.
Domain Name System
For convenience, people tend to use IP aliases when accessing web servers, FTP servers, and e-mail servers. The aliases are easier to remember than actual IP addresses. But IP aliases cannot be used by routers, so a translation is required from IP alias to IP address. This is typically performed by a domain name system (DNS). The DNS consists of mapping information as well as pointers to other DNSs so that, if a request cannot be successfully mapped, the request can be forwarded to another DNS. In Linux, a common DNS program is bind. The dnsmasq program is a forwarder program often used on small Linux (and MacOS) networks. For Windows, Microsoft DNS is a component of Windows Server. Cisco also offers a DNS server, Cisco Network Registrar (CNR).
We conclude this chapter by looking at how to install and configure the Apache webserver in Linux. Because much software in Linux is open source, we will look at how to install Apache using the configure, make, and make install steps.
The first step is to download Apache. You can obtain Apache from httpd.apache.org. Although Apache is available for both Linux/Unix and Windows, we will only look at installing it in Linux because the Windows version has several limitations. From the above-mentioned website, you would select Download from the most recent stable version (there is no need to download and install a Beta version because Apache receives regular updates and so any new features will be woven into a stable version before too long). Apache is available in both source code and binary (executable) format for Windows, but source code only in Linux. Select one of the Unix Source selections. There are encrypted and nonencrypted versions available. For instance, selecting http-2.4.1.tar.gz selects Apache version 2.4.1, tarred and zipped. Once downloaded, you must unzip and untar it. You can accomplish this with a single command:
tar -xzf httpd-2.4.1.tar.gz
The options x, z, and f stand for “extract”, “unzip”, and “the file given as an argument”, respectively. The result of this command will be a new directory, httpd-2.4.1, in the current directory. If you perform an ls on this directory, you will see the listing as shown in Figure 13.4.
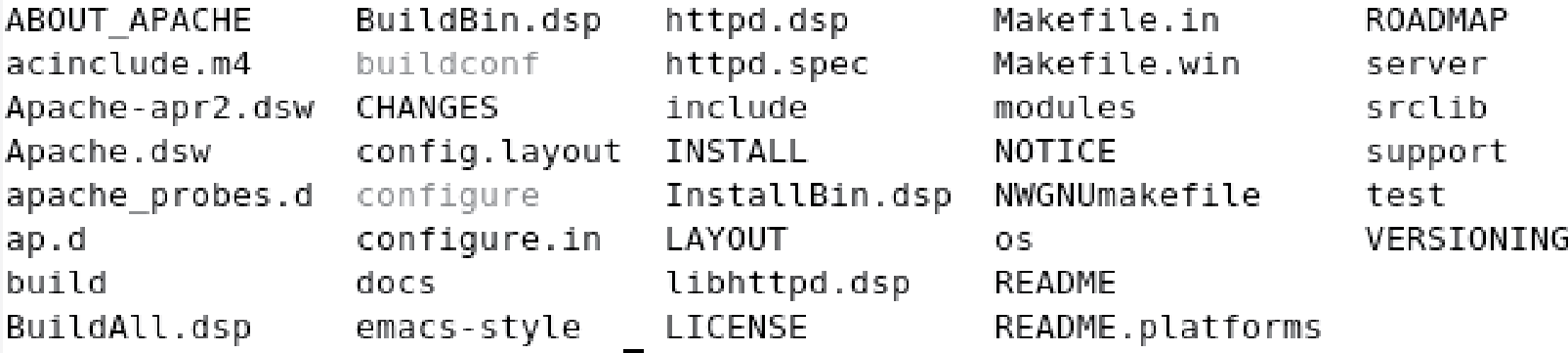
The directory contains several subdirectories. The most important of these subdirectories are server, which contains all of the C source code; include, which contains the various C header files; and modules, which contains the code required to build the various modules that come with Apache. There are several scripts in this directory as well. The buildconf and configure scripts help configure Apache by altering the Makefile script to fit the user specifications. The Makefile.in and Makefile.win scripts are used to actually perform the compilation steps.
The next step for the system administrator is to perform the configure step. The usage of this command is ./configure [OPTION]… [VAR = VALUE]… If you do ./configure –h, you will receive help on what the options, variables, and values are. There are few options available and largely will be unused except possibly –h to obtain the help file and –q to operate in “quiet mode” to avoid lengthy printouts of messages. The more common arguments for configure are establishing a number of environment variables. Many of these are used to either alter the default directories or to specify modules that should be installed. Here are some examples:
--bindir=DIR —replace the default executable directory with DIR
-- sbindir=DIR —replace the default system administration executable directory with DIR
-- sysconfidir=DIR —replace the default configuration directory with DIR
-- datadir=DIR —replace the default data directory (usually/var/www/html) with DIR
--prefix=DIR —replace all default directories with DIR
--enable-load-all-modules —load all available modules
--enable-modules=MODULE-LIST —load all modules listed here
-- enable-authn-file —load the module dealing with authentication control
-- enable-include —enable server side includes module (to run CGI script)
--enable-proxy —enable proxy server module
--enable-ssl —enable SSL/TLS support module
A typical command at this point might be:
./configure --prefix=/usr/local/ --enable-modules=…
Where you will fill in the desired modules in place of …, or omit –enable-modules= entirely if there are no initial modules that you want to install. The configure command will most likely take several minutes to execute. Once completed, your Makefile is available. Type the command make, which itself will take several more minutes to complete. Finally, when done, type make install. You will now have an installed version of Apache, but it is not yet running.
There are other means of installing Apache. For instance, an executable version is available via the CentOS installation disk. You can install this using the Add/Remove Software command under the Applications menu. This does require that you have the installation disk available. An even simpler approach is to use yum by entering yum install httpd. However, these two approaches restrict you to default options and the version of Apache made available in their respective repositories (the one on the disk and the one in the RPM website) and not the most recent version as found on the Apache website.
Now that Apache is installed, we can look at how to use it. To run Apache, you must start the Apache service. Find the binary directory, in this case it would be /usr/local/apache2/bin. In this subdirectory is the script apachectl. You will want to start this by executing ./apachectl start. Your server should now be functional.
Using the above configuration, all of your configuration files will be stored under /usr/local/apache2/conf. The main conf file is httpd.conf. You edit this file to further configure and tailor your server to your specific needs. This file is not the only configuration file. Instead, it is common to break up configuration commands into multiple files. The Include directive is used to load other configuration files. You might find in the httpd.conf file that many of the Include statements have been commented out.
Let us consider what you might do to configure your server. You might want to establish additional IP addresses or ports that Apache will respond to. You might want to alter the location of log files and what is being logged. You might want to utilize a variety of modules that you specified in the ./configure command. You might want to alter the number of children that Apache will spawn and keep running in the background to handle HTTP requests. Additionally, you can add a variety of containers. Containers describe how to specifically treat a subdirectory of the file space, a group of files that share the same name, or a specific URL. Any time you change your configuration file, you must restart apache to have those changes take effect. You can either issue the commands ./apachectl stop and ./apachectl start or ./apachectl restart (the latter command will only work if Apache is currently running).
The location of your “web space”, as stored in your Linux computer, should be /usr/local/apache2/web. This is where you will place most of your web documents. However, you might wish to create subdirectories to better organize the file space. You can also better control access to individual subdirectories so that you could, for instance, place certain restricted files under https access that requires an authorized log in, by using directory containers.
The Apache configuration file is composed of comments and directives. Comments are English descriptions of the directives in the file along with helpful suggestions for making modifications. The directives are broken into three types. First, server directives impact the entire server. Second, container directives impact how the server treats specific directories and files. Finally, Include statements are used to load other configuration files.
The server directives impact the entire server. The following are examples of seven server directives.
ServerName www.myserver.com
User apache
Group apache
TimeOut 120
MaxKeepAliveRequests 100
Listen 80
DocumentRoot “/usr/local/apache2/web”
ServerName is the IP alias by which this machine will respond. User and Group define the name by which this process will appear when running in Linux (e.g., when you do a ps command). TimeOut denotes the number of seconds that the server should try to communicate with a client before issuing a time out command. MaxKeepAliveRequests establishes the number of requests that a single connection can send before the connection is closed and a new connection must be established between a client and the server. Listen identifies the port number(s) that the server will listen to. Listen also permits IP addresses if the server runs on a computer that has multiple IP addresses. DocumentRoot stores the directory location on the server of the web pages. The default for this address typically /var/www/html; however, we overrode this during the ./configure step when we specified the location in the file system for all of Apache.
The Include directive allows you to specify other configuration files. For instance,
Include conf.d/*.conf
would load all other.conf files found in the conf.d subdirectory at the time Apache is started. This allows you to separate directives into numerous files, keeping each file short and concise. This also allows the web server administrator to group directives into categories and decide which directives should be loaded and which should not be loaded by simply commenting out some of the Include statements. In the CentOS version of Linux, there are two .conf files found in this subdirectory: one to configure a proxy service and a welcome .conf file.
The last type of directive is actually a class of directives called containers. A container describes a location for which the directives should be applied. There are multiple types of containers. The most common type are <Directory> to specify directives for a particular directory (and its subdirectories), <Location> to specify directives for a URL, and <Files> to specify directives for all files of the given name no matter where those files are stored (e.g., index.html).
The container allows the website administrator to fine-tune how Apache will perform for different directories and files. The directives used in containers can control who can access files specified by the container. For instance, a pay website will have some free pages and some pages that can only be viewed if the user has paid for admittance. By placing all of the “pay” pages into one directory, a directory container can be applied to that directory that specifies that authentication is required. Files outside of the directory are not impacted and therefore authentication is not required for those.
Aside from authentication, numerous other controls are available for containers. For instance, encryption can also be specified so that any file within the directory must be transmitted using some form of encryption. Symbolic links out of the directory can be allowed or disallowed. Another form of control is whether scripts can be executed from a given directory. The administrator can also control access to the contents of a container based on the client’s IP address.
What follows are two very different directory containers. In the first, the container defines access capabilities for the entire website. Everything under the web directory will obey these rules unless overridden. These rules first permit two options, Indexes and FollowSymLinks. Indexes means that if a URL does not include a filename, use index.html or one of its variants like index.php or index.cgi. FollowSymLinks allows a developer to place a symbolic link in the directory to another location in the Linux file system. AllowOverride is used to explicitly list if an option can be overridden lower in the file space through a means known as htaccess. We will skip that topic. Finally, the last two lines are a pair: the first states that access will be defined first by the Allow rule and then the Deny rule; however, because there is no Deny rule, “Allow from all” is used, and so everyone is allowed access.
<Directory “/usr/local/apache2/web”>
Options Indexes FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
The following directory container is far more complex and might be used to define a subdirectory whose contents should only be accessible for users who have an authorized access, that is, who have logged in through some login mechanism. Notice that this is a subdirectory of the directory described above. Presumably, any files that were intended for an authorized audience would be placed here and not in the parent (or other) directory. If a user specifies a URL of a file in this subdirectory, first basic authentication is used. In the pop-up log in window, the user is shown that they are logging into the domain called “my store”. They must enter an account name and password that match an entry in the file /usr/localapache2/accounts/file1.passwd. Access is given to anyone who satisfies one of two constraints. First, they are a valid user as authenticated by the password file, or second, they are accessing the website from IP address 10.11.12.13. If neither of those is true, the user is given a 401 error message (unauthorized access). Finally, we alter the options for this subdirectory so that only “ExecCGI” is available, which allows server-side CGI scripts stored in this directory to execute on the server. Notice that Indexes and FollowSymLinks are not available.
<Directory “/usr/local/apache2/web/payfiles”>
AuthType Basic
AuthName “my store”
AuthUserFile/usr/local/apache2/accounts/file1.passwd
Require valid-user
Order deny,allow
Deny from all
Allow from 10.11.12.13
Satisfy any
Options ExecCGI
</Directory>
There is much more to explore in Apache, but we will save that for another textbook!
Further Reading
As with previous chapters, the best references for further reading are those detailing specific operating systems (see Further Reading section in Chapter 4, particularly texts pertaining to Linux and Windows). Understanding software categories and licenses can be found in the following texts:
- Classen, H. Practical Guide to Software Licensing: For Licensees and Licensors. Chicago, IL: American Bar Association, 2012.
- Gorden, J. Software Licensing Handbook. North Carolina: Lulu.com, 2008.
- Laurent, A. Understanding Open Source and Free Software Licensing. Cambridge, MA: O’Reilly, 2004.
- Overly, M. and Kalyvas, J. Software Agreements Line by Line: A Detailed Look at Software Contracts and Licenses & How to Change Them to Fit Your Needs. Massachusetts: Aspatore Books, 2004.
- Tollen, D. The Tech Contracts Handbook: Software Licenses and Technology Services Agreement for Lawyers and Businesspeople. Chicago, IL: American Bar Association, 2011.
Installing software varies from software title to software title and operating system to operating system. The best references are found on websites that detail installation steps. These websites are worth investigating when you face “how to” questions or when you need to troubleshoot problems:
- http://centos.karan.org/
- http://support.microsoft.com/ph/14019
- http://wiki.debian.org/Apt
- http://www.yellowdoglinux.com/
The following texts provide details on various servers that you might wish to explore:
- Cabral, S. and Murphy, K. MySQL Administrator’s Bible. Hoboken, NJ: Wiley and Sons, 2009.
- Costales, B., Assmann, C., Jansen, G., and Shapiro, G. sendmail. Massachusetts: O’Reilly, 2007.
- Eisley, M., Labiaga, R., and Stern, H. Managing NFS and NIS. Massachusetts: O’Reilly, 2001.
- McBee, J. Microsoft Exchange Server 2003 Advanced Administration. New Jersey: Sybex, 2006.
- Mueller, J. Microsoft IIS 7 Implementation and Administration. New Jersey: Sybex, 2007.
- Powell, G., and McCullough-Dieter, C. Oracle 10g Database Administrator: Implementation and Administration. Boston, MA: Thomson, 2007.
- Sawicki, E. Guide to Apache. Boston, MA: Thomson, 2008.
- Schneller, D. and Schwedt, Ul., MySQL Admin Cookbook. Birmingham: Packt Publishing, 2010.
- Silva, S. Web Server Administration. Boston, MA: Thomson Course Technology, 2008.
- Wessels, D. Squid: The Definitive Guide. Massachusetts: O’Reilly, 2005.
Finally, the following two-page article contains a mathematical proof of the equivalence of hardware and software:
- Tan, R. Hardware and software equivalence. International Journal of Electronics, 47(6), 621–622, 1979.
Review terms
Terminology introduced in this chapter:
Apache E-mail server
Application software Equivalence of hardware and software
Background File extraction
Backward compatibility File server
Beta-release software Firmware
Compatibility Freeware
Compilation FTP server
Configure (Linux) Horizontal software
Container (Apache) Installation
Daemon Kernel
Database server Make (Linux)
Device driver Makefile (Linux)
Directive (Apache) Make install (Linux)
Download Package manager program
Patch Source code
Productivity software System software
Proprietary software Tape archive (tar)
Proxy server Upgrade
Public domain software Utility
Server Yum (Linux)
Service Shareware Version
Shell Vertical software
Software Web server
Software release Windows installer
Review Questions
- What are the advantages of firmware over software?
- What are the advantages of software over firmware?
- Is it true that anything implemented in software can also be implemented in hardware?
- What is the difference between application software and system software?
- Why are device drivers not necessarily a permanent part of the operating system?
- When do you need to install device drivers?
- What is the difference between the kernel and an operating system utility?
- What types of things can a user do to tailor the operating system in a shell?
- A service (daemon) is said to run in the background. What does this mean?
- Why might a software company work to maintain backward compatibility when releasing new software versions?
- What is a patch and why might one be needed?
- When looking at the name of a software title, you might see a notation like Title 5.3. What do the 5 and 3 represent?
- What does it mean to manage software?
- What is rpm? What can you use it for? Why is yum simpler to use than rpm?
- What is the Linux tar program used for? What does tar –xzf mean?
- What does the Linux command configure do? What does the Linux command make do? What does the Linux command make install do?
- What are gcc and g++?
- What is the difference between a web server and a proxy server? Between a web server and an FTP server?
Discussion Questions
- We receive automated updates of software over the Internet. How important is it to keep up with the upgrades? What might be some consequences of either turning this feature off or of ignoring update announcements?
- Intel has always maintained backward compatibility of their processors whenever a new generation is released, but this has not always been the case with Apple Macintosh. From a user’s perspective, what is the significance of maintaining (or not maintaining) backward compatibility? From a computer architect’s perspective, what is the significance of maintaining backward compatibility?
- Explore the software on your computer. Can you identify which software is commercial, which is free but proprietary under some type of license, and which is free without license?
- Have you read the software licensing agreement that comes with installed software? If so, paraphrase what it says. If not, why not?
- What are some ways that you could violate a software licensing agreement? What are some of the consequences of violating the agreement?
- Assume that you are a system administrator for a small organization that uses Linux on at least some of their computers. You are asked to install some open source software. Provide arguments for and against installing the software using an installation program, using the yum package manager, using the rpm package manager, and using configure/make/make install.
* Prior to optical disks, installation was often performed from floppy disks. Since floppy disks could only store about 1.5 MB, software installation may have required the use of several individual disks, perhaps as many as a dozen. The user would be asked to insert disk 1, followed by disk 2, followed by disk 3, etc.; however, it was also common to be asked to reinsert a previous disk. This was often called disk juggling.