
Speech Summarization for Tamil Language
A. NithyaKalyani⁎; S. Jothilakshmi† ⁎ Department of Computer Science and Engineering, Annamalai University, Chidambaram, India
† Department of Information Technology, Annamalai University, Chidambaram, India
Abstract
In the education field, the amount of information in the form of audio and video recordings is available for every topic of interest and has gained a lot of research interest in summarization. Summarization is defined as a series of actions performed to express information in a concise form that can help users review the information available from a huge quantity of multimedia content in a shorter span of time. Summarization of speech files can be an effective mechanism to manage the large volume of information available in audio recordings. Summarization of a speech document usually addresses the following problems: generating a transcript from the input speech data, summarization, and rendering the output. The output can be in the form of either speech or text. In case of speech, prosodic information such as emotion of speakers that is conveyed only by speech can be presented and in case of text, hearing impaired people will benefit.
This chapter discusses certain approaches that have been developed so far for extractive and abstractive speech summarization, and investigates speech summarization in the Indian language, a domain that has not been explored thus far. Also, this chapter discusses various speech recognition techniques, and their performance on recognizing Tamil speech data is analyzed. Various features used in the summarization of a spoken document are described, and related work on summarizing Tamil documents is presented.
Keywords
Tamil language; Speech data; Summarization; Speech recognition; Evaluation metrics
7.1 Introduction
Speech recognition is the methodology, in which a computer recognizes the speech that is given as input to the computer program, and provides the textual output of the speech. It has a few more applications like speaker identification, structure identification, speech analysis (recognizing the emotion, nature of speech), etc. Speech summarization is the process of retrieving the essential information from speech files and producing the extracted data in a concise form to benefit the end users. Speech summarization uses the speech recognition technique and applies natural language processing algorithms to summarize the textual results obtained from the recognition system. Approaches for summarization can be either extractive or abstractive. Extractive summarization aims at identifying the salient information that is then extracted and grouped together to form a concise summary. Abstractive summary generation rewrites the entire document by building internal semantic representation, and then a summary is created using natural language processing. Other dimensions of summarization [1] include:
- • Indicative versus informative—An indicative summary contains only the description of the spoken document and not the informative content. For example, the title page of books or reports. An informative summary contains the informative part of the original document. For example, research articles where the essential part of research is discussed.
- • Generic versus query-driven—In the query-driven approach, based on the given query, the information that is closely connected to the query is extracted. In the generic approach, the overall concept discussed in the document is presented.
- • Single versus multidocument—The summary can be generated from a single source document (or) from the multiple sources of a document.
- • Single versus multiple speakers—The summary is generated from the information presented by a single speaker or from multiple speakers where the speaker’s details are also incorporated in the summary.
- • Text-only versus multimodal—The summarization result can be presented either as text or as a speech.
Based on number of speakers and speaking style, there are various forms of speech from which a summary can be generated. They include:
- • Broadcast news
- • Lecture
- • Public speaking
- • Interview
- • Telephone conversation
- • Meeting
7.2 Extractive Summarization
Summarization using extractive approaches have demonstrated a growing popularity in the past decades. Both unsupervised and supervised approaches have been explored for speech summarization.
7.2.1 Supervised Summarization Methods
The summarization problem, in general, is handled as a two-class, sentence-classification problem by the supervised machine learning algorithms. Here, the sentences are classified as summary class and nonsummary class [2]. To characterize a spoken sentence, say Si, a set of indicators such as structural features, relevance features, acoustic features, lexical features, and discourse features were used. The classifier takes the corresponding feature vector say Xi of Si as input, and based on the output classification score, the sentence will be selected as either part of the summary or not. Thus by constructing a ranking model that is used to allot a classification score to each sentence included in a summary, the most relevant and salient sentences are ranked and preferred based on the scores. The summarizer iteratively concatenates the sentences to the summary until the desired summarization ratio is achieved. The higher the score, the more the performance of the summarizer will be improved. While training the summarizer, it gives many errors of classifying sentences incorrectly; this is bridged using heuristic methods like sampling and resampling [3].
Supervised methods require a huge amount of spoken dataset and their equivalent manual summaries for training purposes and to prepare the classifiers. Creating the summaries manually for all available spoken data requires more number of human resources, and also it consumes more time. The main problem with supervised summarizers is that they restrict their abstraction skill, and so it may not be easily applicable for a new task or domain. In addition, the supervised summarizers suspect that the content or the information provided by each sentence in the spoken document does not depend on each other. Hence, the sentences are treated as individual sentences and are classified, accordingly. Supervised summarizers do not rely on the dependence relationship among every sentence [4]. There are different machine learning algorithms such as Gaussian mixture model [5], Bayesian classifiers [6], support vector machines (SVM) [7], conditional random fields [8], ranking SVM [9], global conditional log-linear model [9], deep neural network [9], and perceptron [10].
7.2.2 Unsupervised Summarization Methods
Unsupervised summarization methods depend on some statistical evidence such as number of occurrences of words in each and every sentence as well as in the entire document. Unsupervised methods do not depend on manual annotations of training data. They conceptualize the sentences based on their weight of importance and weight of relationship with the document. This is done by classifying the sentences as the nodes and the link between them as their lexical relationships. Since the scores are based on probability, the results of unsupervised summarizers are worse than supervised. However, they are domain-independent and easy to implement.
In the vector space model (VSM), the complete document, including every sentence, is represented using a vector format [11]. Here, each dimension represents a collection of quantitative data. For example, the term frequency score (tf) and inverse document frequency score (idf) are multiplied and the resultant score will be associated with a word or a sentence in the document. The statements with the prominent relevance scores to the entire spoken document are considered to be incorporated in the summary generation process [12].
Latent semantic analysis (LSA) [13] makes use of vectors to represent every statement in a spoken document. Singular value decomposition (SVD) is implemented on a set of matrices representing the words and sentences of a spoken document, and so vectors are created. The more dominant latent semantic concepts are represented by wide-ranging singular values in the right singular vectors. Thus the values in right singular vectors are treated as salient sentences and those sentences are given more preference for summary generation.
Dimension reduction (DIM) is another LSA-based technique [14] where the relevance score of each sentence is calculated, and it depends on the normalized vector in a lower m-dimensional latent semantic space. Then the sentences with higher scores are identified and considered for inclusion in the summary generation.
In case of maximum margin relevance (MMR) [15], sentences are selected iteratively based on two rules: (1) whether the sentence is better related to the context of the complete speech transcript compared with other sentences, and (2) whether the sentence is less similar than other sentences to the already selected set of sentences [16]. Thus in addition to selecting suitable sentences for the summary, it also considers more concepts to be covered in the summary.
Graph-based techniques, including LexRank [17], TextRank [18], Markov random walk [19], consider spoken content to be condensed as a network of sentences. Here, the node and the edges between each node, represent a sentence and a relationship between each sentence. The weight or values associated with the edges represent the lexical similarity relationship between each sentence. Document summarization in general, not only considers the local features of each sentence, but also considers the global structural information present in a conceptualized network. Daumé et. al. [20] explored the use of probabilistic models to collect the similarity details among sentences in the speech transcript.
Chen et al. [21] conducted a summarization task in a completely unsupervised manner by utilizing the framework of probabilistic ranking for summarizing speech files. In this framework, the length of space between a statement and a document model is determined and most salient statements are selected based on either the computed scores or the likelihood of a model generating the summary of a spoken content. Unsupervised summarization approach is independent of domain and is effective in terms of effortless execution compared to supervised summarization approach.
7.3 Abstractive Summarization
Abstractive summary generation rewrites the entire document by building internal semantic representation, and then uses natural language generation to create a summary. Table 7.1 depicts the broad classification of abstractive summarization techniques [22].
Table 7.1
| Structured approach | Tree based technique |
| Template based technique | |
| Ontology based technique | |
| Lead and body phrase technique | |
| Rule based method | |
| Approach based on semantics | Multimodal semantic technique |
| Information item based technique | |
| Semantic graph based technique |

7.3.1 Structured Approach
The structured approach converts the essential facts available in the spoken report into a particular form through subjective strategy [23]. The categories of structure-based approaches are described below.
7.3.1.1 Tree-Based Technique
In this approach, the information in the document is represented using a dependency tree. Several algorithms such as theme intersection algorithm, or one that makes use of local alignment across pair of parsed sentences are used to select the important information from the document for summary generation. Related literature using this method shall be referred in [24, 25].
7.3.1.2 Template-Based Technique
Here, the document is represented using a template. The framework of linguistic patterns is used to locate a piece of information from the text document and they are mapped to a template slot. The identified piece of information acts as an indicator for the content selection to generate summary. Related literature using this method shall be referred in [26].
7.3.1.3 Ontology-Based Technique
Research on summarization has been improved by making use of the ontology concept. Data available on the Internet are grouped based on their similarity, so it is domain related. The way of organizing the knowledge is domain dependent and ontology helps in describing it in a better way. Detailed study on this technique shall be referred in [27].
7.3.1.4 Lead and Body Phrase Technique
In this technique, operations on phrases such as insertion and substitution form the base where the head and body of the sentences are analyzed for same syntactic head piece. The sentences are searched for triggers, and using the similarity metric, the sentences with maximum phrase are recognized. If rich information is available in the body phrase, and if it has its equivalent phrase, then substitution is performed. If the body phrase has no correspondent, then insertion is performed. Substitution and insertion into the body phrase has information rich context in the summary. Related literature using this method shall be referred in [28].
7.3.1.5 Rule-Based Technique
In this technique, a rule-based information extraction module along with selection heuristics is used to select a sentence for summary generation. The extraction rules are formed using verbs and nouns that have similar meaning. The summary generation module makes use of several candidate rules to provide the best summary. Related literature using this method shall be referred in [29].
7.3.2 Semantic-Based Approach
In this approach, the linguistic data is utilized to identify the phrases of nouns and verbs [30]. The techniques under this approach include.
7.3.2.1 Multimodal Semantic Technique
In this method, a semantic model is used to identify the relationships among the content of the document. The content of the document can be either text or images. The important information identified in the document is rated and based on some measures, the informative sentences are expressed to form a summary. The summary generated using this technique has better quality, because all the graphical and salient information is covered in the summary. Related literature using this method shall be referred in [31].
7.3.2.2 Information Item-Based Technique
In this method, the information required for summary generation is selected from the overall representation of source file rather than from the original document. Information item is the abstract way of representation, and it is the smallest unit of logical information present in the text document. Information item is extracted through syntactic analysis and the sentences are ranked using the average document frequency score. Then a summary is generated, which includes all the characteristics of date and location. Finally, a logical and information rich summary is generated. Related literature using this method shall be referred in [32].
7.3.2.3 Semantic Graph-Based Technique
This technique makes use of a rich semantic graph, which is used to represent the verbs and nouns in the document as graph nodes, and the edges between the nodes represent the semantic relationship, and the topological relationship between the verbs and nouns. Later, some heuristic rules are applied to reduce the rich semantic graph so as to generate an abstractive summary. The advantage of this technique is that the summary sentences are grammatically corrected, scalable, and less redundant. Related literature using this method shall be referred in [33].
7.4 Need for Speech Summarization
The natural way of information exchange among human beings is speech, where the message along with the prosodic information, such as emotion, is also conveyed. When the speech (e.g., lectures, presentations, news) is recorded as an audio signal, the complete information is conveyed to the listener, but it is difficult for the listener to quickly recall the information delivered. Therefore transcribing speech became the mandatory part, and the speech recognition system played a vital role to generate a transcript for the given speech documents. Though the speech recognition system provided accurate results for the input speech that is read from a text (broadcast news read by an anchor), the efficiency of transcribing continuous speech is still minimal.
Spontaneous speech varies from the written text and it includes redundant information due to the presence of breaks and irregularities in the speech. The transcripts of spontaneous speech may include redundant and irrelevant information due to the fillers, word fragments, and recognition errors. Therefore the transcripts for spontaneous speech alone will not provide the efficient information that is required by the end user. Instead, the most important and relevant information shall be extracted from the spontaneous speech transcripts. and it can be rendered in the form of summary of the speech files. The summary of recorded speech saves time to review and recall the information present in the speech and thus improves the efficiency of document retrieval. The summary, in turn, can be in the form of either speech or text.
7.5 Issues in the Summarization of a Spoken Document
- - Identify utterances: An utterance is a way of conveying information and it differs by speaker and language, but it has no effect on the content.
- - Human variations: Different people tend to choose different sentences and this will not lead to quality in the generation of a summary.
- - Semantic equivalence: One or more sentences may convey the same information, thus it is not advisable to use only the sentences as the selection unit for summary generation. For example, news and multidocument summarization.
- - Another issue for automatic speech summarization is how to deal with recognition results, including word errors. Handling word errors is a fundamental aspect for successfully summarizing transcribed speech. In addition, since most approaches extract information based on each word, approaches based on a longer phrase, or compressed sentences are required for extracting messages in speech.
- - The major issue in speech recognition is that the transcripts generated by the recognition module may not be linguistically correct, and it is due to the recognition errors. Hence, it is necessary to develop a technique to automatically summarize the speech to cope with such problems.
7.6 Tamil Language
Tamil language is a classical Indian language and is extensively spoken in Tamilnadu, which is the southern state of India. Tamil language is based on syllables. It includes 18 consonants (மெய்யெழுத்து; meyyeḻuttu), 12 vowels (உயிரெழுத்து; uyireḻuttu) and one another unique letters “aytham (அக்கு ஃ)”. The vowels are categorized as five short vowels and seven long vowels that include two diphthongs. The 18 consonants are grouped as hard, soft, and medium with 6 consonants in each group. The categorization of consonants depends on the point of articulation, and the vowels are produced by varying the position of the tongue in different parts of the mouth. The combination of both consonants and vowels produce a syllable. The consonants in general are represented with a dot on top of the symbol (க் /k/), and it is mingled with a vowel (அ /a/) to form a syllable (க /ka/) [34, 35].
One of the unique features in the Tamil language is a prosodic syllable (asai) [36], and the pronunciations are based on the prosodic syllable. The representation of the prosodic syllable in Tamil language is categorized as Ner Asai and Nirai Asai. The rules for the prosodic syllable constitute eight patterns and are described in Table 7.2.
Table 7.2
| Pattern | Example |
|---|---|
| Short vowel + long vowel + consonant(s) | கனா (Kaṉā) |
| Short vowel + long vowel | விழா (Viḻā) |
| Short vowel + short vowel + consonant(s) | களம் (Kaḷam) |
| Short vowel + short vowel | கல (Kala) |
| Short vowel + consonant(s) | பல் (Pal) |
| Long vowel + consonant(s) | கால் (Kāl) |
| Long vowel | வா (Vā) |
| Short vowel | க (Ka) |
7.6.1 Tamil Unicode
A universal character encoding scheme is said to be a Unicode and it is available for written characters and text. For English language, ASCII characters are used and in the same way, for Tamil language. Unicode characters are used. The effectiveness of using Unicode is that it is platform independent and program independent. It can be used to encode multilingual text, and acts as a basis for global software. The Tamil Unicode range is U + 0B80 to U + 0BFF and its decimal value range from 2944 to 3071. The Unicode characters are comprised of 2 bytes in nature. For example, consider the word வணக்கம். Its corresponding Unicode and decimal value is presented in the Table 7.3.
Table 7.3
| Tamil Letter | Unicode | Decimal Value |
|---|---|---|
| வ (VA) | U + 0BB5 TAMIL LETTER VA | 2997 |
| ண (NNA) | U + 0BA3 TAMIL LETTER NNA | 2979 |
| க (KA) | U + 0B95 TAMIL LETTER KA | 2965 |
| ் (puḷḷi—tamil sign virama) | U + 0BCD TAMIL SIGN VIRAMA | 3021 |
| க (KA) | U + 0B95 TAMIL LETTER KA | 2965 |
| ம (MA) | U + 0BAE TAMIL LETTER MA | 2990 |
| ் (puḷḷi—tamil sign virama) | U + 0BCD TAMIL SIGN VIRAMA | 3021 |
7.7 System Design for Summarization of Speech Data in Tamil Language
Exhaustive research on text summarization has already been done for English and other foreign languages, whereas it is still lacking for Indian languages. Text summarization for Indian language has evolved and research work is in progress. Speech summarization for Tamil language is a domain that is not explored so far, and it has to be studied to help people who are hearing impaired. Fig. 7.1 describes the overview of steps involved in summarization of a spoken document for Tamil language.
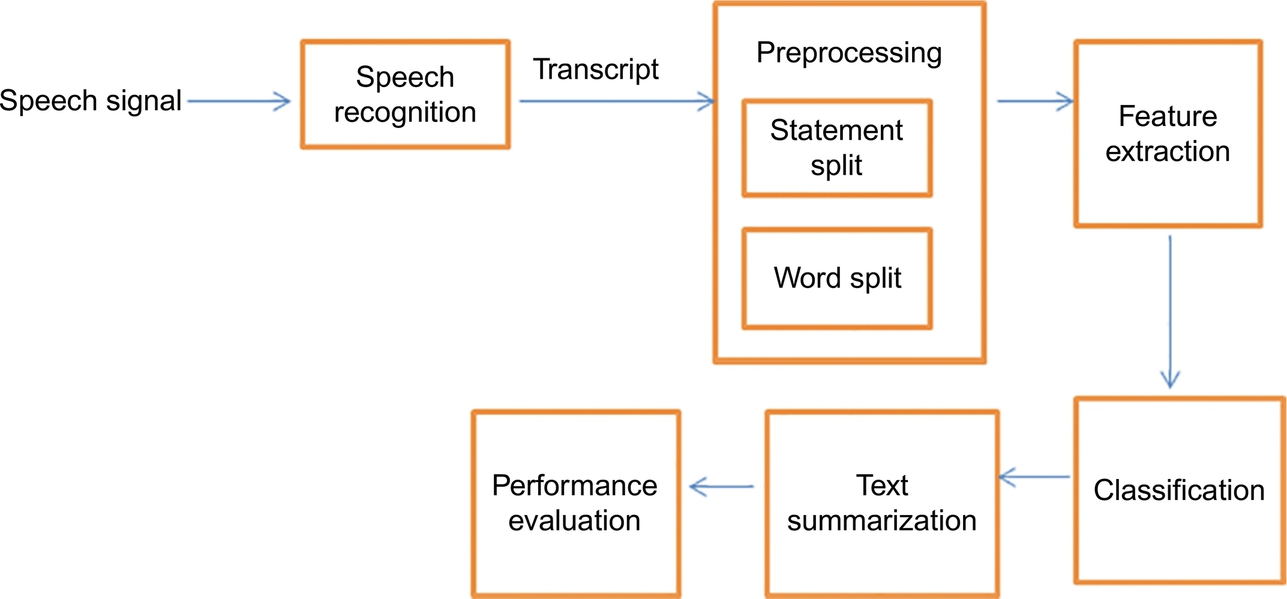
The major steps involved are: speech recognition, feature extraction from the speech transcript, classification, summarization, and performance evaluation.
7.7.1 Speech Recognition Techniques
Speech recognition is the way to translate the input speech signal into its corresponding transcript [37]. Generations of transcripts from the input speech signal is a challenging task when it comes to native languages like Tamil, because of the variations in accents and dialects. Research is ongoing in Tamil speech recognition to solve issues and challenges to develop an effective recognition system Fig. 7.2 shows the speech signal of a sample WAV file obtained from the Linguistic Data Consortium for Tamil language. Fig. 7.3 shows its corresponding transcript.

The classical speech recognition system consists of two phases [38]; preprocessing and postprocessing. The preprocessing step focuses on the feature extraction part, where the features are extracted from the input speech signal. The purpose of feature extraction from input speech waveform is to characterize it at a lower information rate for further exploration. The widely used feature extraction techniques are [39]: mel-frequency cepstral coefficients (MFCC), linear predicting coding (LPC), linear predictive cepstral coefficients (LPCC), perceptual linear predictive coefficients (PLP), wavelet features, auditory features, and relative spectra filtering of log domain coefficients (RASTA).
The components in the postprocessing step are: acoustic models, a pronunciation dictionary and language model. The statistical way of representing the feature vector generated from a speech signal is referred to as acoustic modeling. Acoustic modeling is used to explore the representation of words and sentences, which is considered a relatively larger speech unit in a spoken document. The pronunciation dictionary is a resource that is language dependent, and it includes all possible words that the speech recognition module can understand. Also, the dictionary contains the details about the different ways of pronouncing the words. The language model is used to explore the possibilities of word sequence and how frequently they occur together. The language model is also used to regulate the searching process for the identification of a word. Table 7.4 shows the advantages and disadvantages of each speech recognition technique [40].
Table 7.4
| Techniques | Advantage | Disadvantage |
|---|---|---|
| Dynamic time warping | Execution is made easy, and also random time warping can be modeled. | A rule-based approach is used to measure distances and the warping paths. The best solution or the convergence is not guaranteed. When the size of the vocabulary grows, it doesn’t scale well and shows poor performance when the environment changes. |
| Hidden Markov model | HMM makes use of positive data and so, it is easily extendable. Though the vocabulary size grows, the time taken for the recognition process is minimal. | It requires large number of parameters and the data required for training is also large. The likelihood of examining data instances from other classes is reduced. |
| Gaussian mixture model | The probability estimation is perfect and the classification yields the best solution. | Time taken for complete recognition process is not reduced comparatively. |
| Multilayer perceptron | Based on the discriminative criteria, learning is performed. Continuous functions shall be approximated using a basic structure. The complete idea about the type of input is not required, and it produces some reasonable recognition results for the test case input that has not been taught before. | For a continuous speech recognition task, the performance is not good. Though the recurrent structures are defined, MLP lacks in building a speech model. |
| Support vector machine | Robustness is increased and the training process is easy. In the case of high dimensional data, scaling is relatively high and it does not require local optimality. | SVM requires a good kernel function. |
| Decision trees | It is easy to understand and manipulate. Also, it will work along with other decision techniques. | The complexity increases when the data size is increased. |
7.7.2 Isolated Tamil Speech Recognition
As an initial stage in Tamil speech recognition, a sample set of 15 Tamil words are uttered by 4 different people (1 male and 3 female). Each word is repeated 10 times to have 10 different utterances. Therefore the total size of the dataset is 600 (15 × 4 × 10). Audacity software is used to record the utterances and MATLAB software is used to perform the experiment. Here, 60% of the spoken data is used for training purpose and the remaining 40% of the spoken data is used for testing purposes. The state-of-the-art speech recognition techniques were used to recognize the same speech samples and their performance is compared based on the word error rate, word recognition rate and real-time factor [40]. Fig. 7.4 shows the word level accuracy and average time taken during the training and testing process.
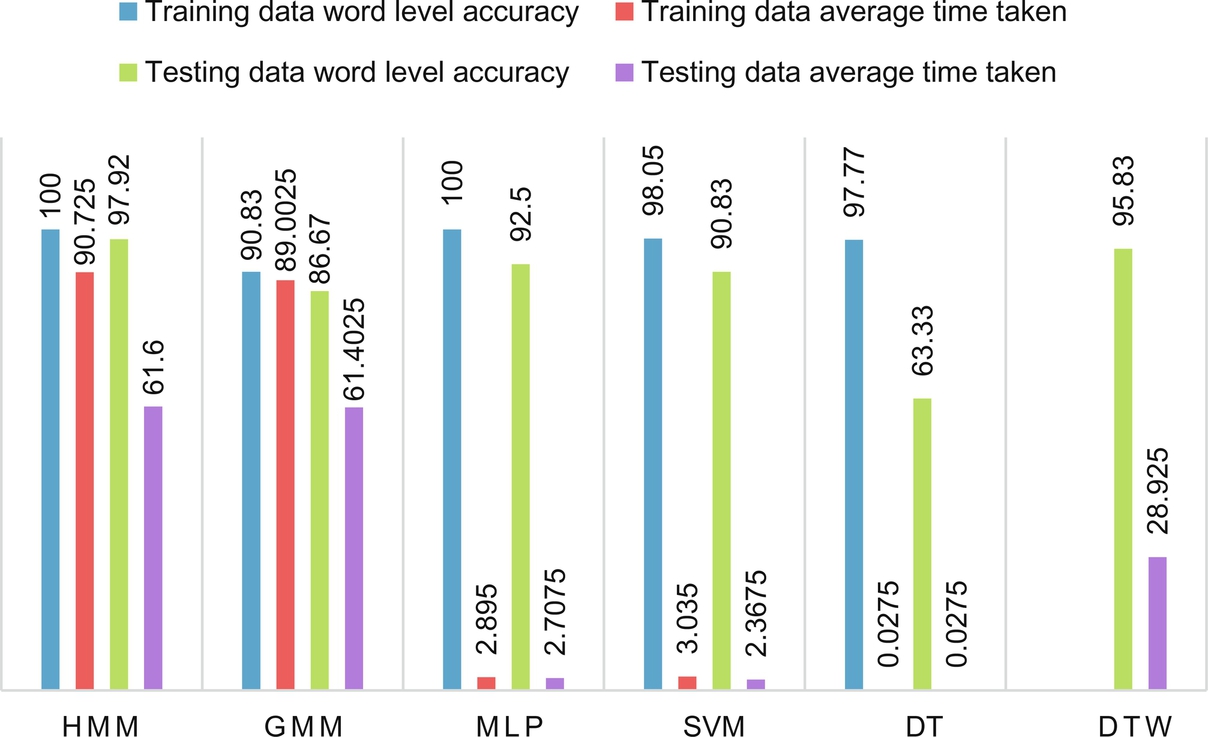
From Fig. 7.4, it is proven that HMM and DTW techniques provide better results in comparison to other state-of-the-art methods. Also, it is shown that the statistical approaches works better for isolated word recognition, and in the case of speaker independent applications, machine learning approaches perform better.
7.7.2.1 Related Work on Tamil Speech Recognition
Lakshmi et al. [41] proposed the syllable-based continuous speech recognition system. Here, the group delay-based segmentation algorithm is used to segment the speech signal in both training and the testing process and the syllable boundaries are identified. In the training process, a rule-based text segmentation method is used to divide the transcripts into syllables. The syllabified text and signal are used further to annotate the spoken data. In the testing phase, the syllable boundary information is collected and mapped with the trained features. The error rate is reduced by 20% while using the group delay based syllable segmentation approach, and so the recognition accuracy is improvised.
Radha et al. [42] proposes the automatic the Tamil speech recognition system by utilizing the multilayer feed-forward neural network to increase the recognition rate. The author-introduced system, eliminates the noise present in the input audio signal by applying the preemphasis, median, average, and Butterworth filter. Then the linear predictive cepstral coefficients features are identified and extracted from the preprocessed signal. The extracted features are classified by applying the multilayer feed-forward network, which classifies the Tamil language efficiently. The performance of the system is analyzed with the help of the experimental results, which reduces the error rate and increases the recognition accuracy.
Alex Graves et al. [43] recognize the speech features by applying the deep neural network because it works well for sequential data. The network works are based on the long- and short-term memory process to analyze the interconnection between the speech features. The extracted features are classified in terms of the connectionist temporal classification process. The implemented system reduces the error rate up to 17.7%, which is analyzed using the TIMIT phoneme recognition database.
Gales and Young [44] implement the large vocabulary continuous speech recognition system for improving the recognition rate. The authors reduce the assumptions about the particular speech features, which are classified by applying the hidden Markov model. This model uses the various process like feature projection, discriminative parameter estimation, covariance modeling, adaption, normalization, multipass, and noise compensation process while detecting the speech feature. The proposed system reduces the error rate, and so the recognition rate is increased in an effective manner. Table 7.5 describes the performance of various speech recognition techniques and it demonstrates that the modified global delay function with the Gammatone wavelet coefficient approach yields the better recognition, comparatively.
Table 7.5
| Recognition Technique | Recognition Accuracy in Percentages |
|---|---|
| MFCC with HMM [45] | 85 |
| Mel-frequency cepstral coefficients (MFCC) with deep neural network (DNN) [46] | 82.2 |
| Gammatone cepstral coefficients (GTCC) with hidden Markov model (HMM) [47] | 85.6 |
| Gammatone cepstral coefficients (GTCC) with Deep Neural Network (DNN) [48] | 88.32 |
| Modified global delay function (MGDF) with Gammatone wavelet coefficient approach [49] | 98.3 |
| Syllable-based continuous approach [41] | 80 |
7.7.3 Features Used for Summarization
Here, the feature classes such as lexical, structural, acoustic/prosodic, discourse, and relevance features are discussed [50]. They are used to predict sentences that will be extracted to generate a summary for the spoken document. Table 7.6 shows the comparison results of different features that are used to characterize a spoken document.
Table 7.6
| Features Used | Tested On | Observations |
|---|---|---|
| Lexical, structural [53] | Text and speech | Good performance for text compared to speech |
| Acoustic, prosodic, lexical, structural, discourse features [54, 55] | Broadcast news | Together, the acoustic, lexical, structural and discursive give the best performance. Acoustic and structural perform well when speech transcription is not available. An acoustic feature is useful in retrieving important sentences from the abstract of English broadcast news. |
| Lexical, acoustic, prosodic [56] | Lecture speech | Lexical contributes more than acoustic. Acoustic and prosodic permit representation of rhetorical information to improvise the performance of summarization. |
| Lexical, prosodic, structural, acoustic [51] | Broadcast news, lecture speeches | The manner of speaking by anchors and reporters is the same over time in the news domain, but it varies with lecture speakers. Structural and acoustic features perform well even without a lexical feature for broadcast news. A lexical feature performs well for lecture speeches. |
| Acoustic, lexical [57] | Meetings | Normalization of acoustic features improves summarization performance compared to lexical. |
| Acoustic feature [58] | Lecture speech | Speaker normalized acoustic feature improves performance. |
| Acoustic, lexical, structural [59] | Presentation speech | Acoustic and structural property produce a good performance and propose that the quality of speech summarization can be improvised without the extreme need of accurate results in speech recognition. |
| 16 indicative features including lexical, prosodic, relevance and structural feature. [60] | Broadcast news | Relevance feature in isolation can achieve the best performance. Performance of prosodic feature is superior to lexical feature since it is less sensitive to the effect of imperfect speech recognition. |
| Acoustic, lexical, and structural features [61] | Broadcast news along with transcription obtained from LDC [62] | Performance of lexical feature is best compared to acoustic and structural feature. Also, the performance of ROUGE metric is better while using full feature set. |
7.7.3.1 Acoustic/Prosodic Feature
Features that are extracted from raw speech signal are denoted as acoustic or prosodic features. They describes more about how things are said, than what is said. Table 7.7 shows the various forms of acoustic features. F0 features include first formant, second formant, and third formant features. For each feature, the maximum, minimum, difference, and average value of a spoken sentence are extracted. A change in pitch may be a topic shift. The RMS energy feature (maximum, minimum, difference, and average) is used to illustrate the higher amplitude that probably means a stress on the phrases. Duration represents the length of the sentence in seconds (end time–start time); a short or long sentence might not be important for summary. The speaker rate indicates how fast the speaker is speaking; the slower rate may mean more emphasis in a particular sentence.
Table 7.7
| Feature Name | Feature Description |
|---|---|
| Duration I, Duration II | Time and average phoneme duration of a sentence |
| Speaking rate | The average syllable duration |
| Energy value EI, EII, EIII, EIV, EV | The minimum and maximum energy value, then its difference, mean, and slope of the energy |
| F0 formants F0I, F0II, F0III, F0IV, F0V | The minimum and maximum F0’s value, then its difference, mean and slope of F0 |
7.7.3.2 Lexical Feature
It is used to represent the linguistic characteristics. Some of the lexical features include: Named entities in a sentence such as person, people, organization, total count of named entities, number of stop words in a sentence, number of words in previous and next sentence, bigram language model scores, and normalized bigram scores [51]. A lexical feature set contains eight features. These features are reported in Table 7.8. All lexical features are extracted from the manual transcriptions or ASR transcriptions.
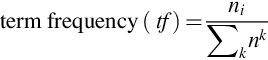
where the numerator ni refers to the number of occurrences of the examined words, and the denominator represents the number of occurrences of all words in a spoken document.

Here, | D | refers to the total count of sentences in the spoken document to be considered and (di ⊃ ti) refers to the number of sentences where the word ti occurs.
Table 7.8
| Feature Name | Feature Description |
|---|---|
| LenI | Total count of named entities |
| LenII | Count of words in previous sentence |
| LenIII | Count of words in next sentence |
| LenIV | Count of stop words in a sentence |
| LenV | Score of a bigram language model |
| LenVI | Score of a normalized bigram |
| TFIDF | Term frequency inverse document frequency estimated using tf⁎idf as mentioned in Eqs. (7.1) and (7.2) |
| Cosine | Cosine similarity measure |
7.7.3.3 Part-of-Speech Tagging
Part-of-speech (POS) tagging [52] is a technique to label every word in a sentence. It is similar to replacing essential data with a unique identification symbol to retain its security to make sure the meaning of the data is not compromised. POS tagging serves its applications in the information retrieval system, the natural language parsing system and in machine translation. The following are the major POS classes in Tamil: nouns, verbs, adjectives, adverbs, determiners, post positions, conjunctions, and quantifiers.
7.7.3.4 Stop Word Removal
Stop words are the most commonly used words that are found in any natural language. They do not contribute much to the semantic representation of a sentence. Instead, they are used for a syntactic representation in the sentence formation. In the speech processing task, the stop word removal acts as a preliminary processing phase to enhance the efficiency of recognition and summarization. Table 7.9 gives the sample list of stop words in Tamil language.
7.7.3.5 Structural Feature
It is used to describe the length of time or the duration of facts provided in a spoken sentence. The structural features include the position of a sentence in the story, speaker type (reporter or not), previous and next speaker type, and the change in speaker type.
7.7.3.6 Discourse Feature
The discourse feature is used to show the listener how to interpret what the speaker is saying without affecting the literal meaning (well, oh, like, of course, yeah).
7.7.3.7 Relevance Feature
The relevance feature evaluates the suitability of each sentence with its document. The relevance feature will be determined using vector space model score, latent semantic analysis score, and the Markov random walk score.
7.7.4 Related Work on Tamil Text Summarization
Kumar and Devi [63] made use of the graph theoretic scoring technique to assign a score to sentences. Based on that, summary sentences are chosen. To assign a score to the sentences, a term positional and weight-age calculation is inferred in addition to analyzing the frequency of words.
Banu et al. [64] made use of the semantic graph technique to summarize the Tamil documents where the subject, object and predicates are identified from all sentences in the document. Then the summary for the source document is formed by human experts. Here, a triple of subject, object, and predicate semantic normalization is employed to reduce the number of occurrences of nodes in the semantic graph. The triples of subject, object and predicate from the semantic graph is identified by using a leaning technique that is taught using a support vector machine classifier. Then, the summary sentences are extracted from the spoken test documents using the classifier.
Keyan [65] proposed a neural network based multidocument and multilingual (Tamil and English) summarization. Here, individual lines in the document are converted to vector representations, and based on the sentence features, the vector is assigned with a weight score. Then, summarization is performed by selecting summary sentences based on the weight score assigned. In case of multidocument summarization, the summary sentences chosen by a single document summarization module is taken as the input. By making use of similarity and dissimilarity measures, the resultant summary for multidocument is generated. This technique shall be used for both Tamil and English online newspapers summary generation.
7.8 Evaluation Metrics
In the research field, it is necessary to evaluate the performance of summarization results, to benefit the end user by providing a summarizer with better quality. Approaches for evaluating the results of spoken document summarization can be classified as either intrinsic or extrinsic. In case of intrinsic evaluation, the summaries generated by the automatic summary generation system are compared with the summaries generated by human beings manually, and the performance of resultant summaries is analyzed. In case of extrinsic evaluation, the effectiveness of summing up a task or a document is tested and analyzed.
Some aspects of evaluating the summarization results depend on the performer of the evaluation. The summarization evaluation can be performed either manually by human or the evaluation can be done automatically. Evaluations performed by humans can be carried out to match the content of the document, checked for the degree of excellence, grammaticality, usage of less redundant words, and the inclusion of the most important information in the content of the summary. Compared to the human evaluation, the summary that is automatically generated is neutral and it can help minimize human efforts and increase the rate of system development.
7.8.1 ROUGE
Recall-Oriented Understudy for Gisting Evaluation [66] is the commonly employed evaluation metric to analyze the summarization results. It can be in various forms that are discussed below:
7.8.1.1 ROUGE-n
Based on the similarity results of n-grams, a series of 2-grams, 3-grams, and 4-grams is extracted from a summary that is considered as a reference, and is the automatically generated summary. Consider “a” as “the number of common n-grams between candidate and reference summary”, and “b’” as “the number of n-grams extracted from the reference summary only.” The score is calculated using:
7.8.1.2 ROUGE-L
This metric makes use of the idea of longest common subsequence (LCS) between the two successions of sentences in the document. The longer the LCS, the two sentences that are chosen for summary generation are said to be more similar. Though this measure is more flexible, it requires all n-grams to be consecutive.
7.8.1.3 ROUGE-SU
This measure is also called as skip bigram and unigram ROUGE. Here, the words can be inserted in between the words of bigrams. Therefore it is not required for the sequence of words to be consecutive.
7.8.2 Precision, Recall, and F-Measure
The summarization systems in general choose the most informative sentences from the spoken document and then generate an extractive summary. The informative sentences that are extracted are simply concatenated together to form a summary, and no changes are made in the original words used in the document. In this scenario, the most commonly used measures such as precision and recall can be used.
In case of precision (P), the sentences that are considered to be the most informative are selected manually by the human and also automatically generated by the system. They are compared with the sentences that are selected automatically by a system. In case of recall (R), the sentences that are considered to be the most informative are selected manually by the human and also automatically generated by the system. They are compared against the human-generated summaries.


F-score is defined as the harmonic average of precision and recall.
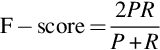
7.8.3 Word Error Rate
The performance of generating transcripts from the speech waveform can be measured using the word error rate (WER) and is defined as the ratio of number of misclassified words to the total number of words in the spoken content.
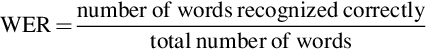
7.8.4 Word Recognition Rate
The performance of transcript generation from a spoken data can also be measured using word recognition rate and it is defined as:
7.9 Speech Corpora for Tamil Language
A corpus for any language contains a huge volume of structured data. It can be in the form of either written or spoken or in a machine-readable form [67]. In the field of research, there is a great necessity for a language corpus. The speech corpus for other foreign languages are more widely available compared with Indian language. Since Indian languages vary in diversity, accent and dialects, the development of a corpus for Indian language is a time consuming process. However, there are some corpora developed for Indian language and made available for education and research purposes.
The speech data for the database is collected by the joint effort of all the consortium members. The consortium members include IIT Madras, IIIT Hyderabad, IIT Kharagpur, IISc Bangalore, CDAC Mumbai, CDAC Thiruvananthapuram, IIT Guwahati, CDAC Kolkata, SSNCE Chennai, DA-IICT Gujarat, IIT Mandi, and PESIT Bangalore. For speech recording, two voice talents are identified (one male and one female) for each language. Text in each language is identified for reading and is read in an anechoic chamber. A total of 40 h of speech data is collected for a language—20 h of native (mono) data (10 h each of male and female data) and 20 h of English data recorded by these native speakers (10 h each of male and female data).
The Central Institute of Indian Language (CIIL) corpus is a collection of a vast amount of text documents in Tamil language. It contains 2.6 million words that are based on various domains such as cooking tips, news articles, biographies, and agriculture.
The Linguistic Data Consortium (LDC) corpus includes a collection of news text that is recorded in a noisy environment and a stereo recording is used to record the news read by different people. The news text is read by a group of people, and they are categorized based on age, gender, and a different environment. The entire speech file is saved as a .ZIP file, and it includes the corresponding transcripts of speech data labeled at sentence level.
The Indian Language Technology Proliferation and Technology Centre corpus contains more than 62,000 audio files in Tamil language of 1000 speakers. The dataset size is around 5.7 GB and the content is prepared for the agricultural domain. The dataset collection includes a .doc file with the list of words and their corresponding phonetic representations, along with the transcripts for each audio file.
7.10 Conclusion
Although speech-to-text conversion (STT) machines aim at providing benefits for the deaf or people who can’t speak, it is difficult to review, retrieve and reuse speech transcripts. Hence, when the speech to text conversion module is combined with the summarization, the applications further increase in educational fields as well. This chapter discussed the need for speech summarization, various issues in the summarization of a spoken document, supervised, and unsupervised summarization algorithms. Isolated Tamil speech recognition was performed using a sample set of Tamil spoken words. In addition, state-of-the-art recognition techniques were used, and analysis was performed. Also, the summarization of speech data in Tamil language is explored, along with related work on text summarization. The features used in the summarization of a spoken document are analyzed and compared, based on the various forms of input into the spoken document.