
A Framework for Artificially Intelligent Customized Voice Response System Design using Speech Synthesis Markup Language
Sajal Saha; Mazid Alam; Smita Dey Department of CSE, Kaziranga University, Jorhat, India
Abstract
The idea of integrating a voice response system to control IoT applications is creating a new dimension in human-computer interaction. Google Assistant, Apple's Siri, Microsoft's Cortana, Amazon Alexa are the key players in the market that provide generalized response services. These services are restricted to specific devices and OS platforms, and cannot be modified, as per user requirement. This work presents a low-cost, artificially intelligent voice response system driven by AWS (Amazon Web Services) IoT cloud platform and Raspberry Pi. We used Alexa voice service (AVS) in Raspberry Pi and a microphone for speech reception. AVS is an integral part of AWS IoT that enables our device to act as Alexa voice client. It receives a speech signal, recognizes and interprets the speech signal, and responds to the user, accordingly. This device will serve as Alexa voice client, as well as Eclipse Paho MQTT (Message Queuing Telemetry Transport), simultaneously. This low-cost, voice response system can replace Amazon Echo, Google Home, and Apple HomePod. Moreover, users can customize the response of their query using speech synthesis markup language (SSML) in AVS. This design successfully integrates various Platform as a Service (PAAS) services like, AWS Lambda, Alexa Voice Service (AVS), and AWS IoT.
Keywords
Artificially intelligent; Voice response system; Speech system markup language; Human-computer interaction; Amazon web server; AWS Lambda
10.1 Introduction
The idea of the Internet of Things (IoT) [1–5] came into the picture to control and monitor the connected devices over the Internet, which is increasing day by day. Earlier IoT enabled devices were controlled and monitored by smartphone apps, which are platform dependent (Android, iOS, Windows). An artificially intelligent voice response system is a better solution in this context to control the IoT devices. The primary objective in developing a voice response system is to build a human-computer interaction system that enables the system to recognize the human voice in the form of instruction. Every speech recognition system [6–8] filters out noises and identifies human voices, especially one that uses its wake word. Each voice response system has its own wake word. Amazon Echo's [9] wake word is “Alexa,” which can be replaced by “Echo” or “Amazon.” Google Home is equipped with wake word, “Hey Google” or “Ok Google.” Apple HomePod is equipped with wake word “Hey Siri,” etc. The wake word is a single word [10–12] or a phrase that when uttered, the voice response system circuits are activated and reject all other words, phrases, noises and other external acoustic events with virtually 100 percent accuracy. Alexa Voice Service and Google Assistant recognize and respond only to the designated user apart from the wake word. This feature provides added security to the voice response system.
One of the key limitations in the available voice response systems (Amazon Echo, Google Home, Apple HomePod) is that they respond to generic queries. This limitation motivated us to design and develop a customized artificially intelligent, low-cost voice response system that responds to user-centered queries.
The rest of the chapter is organized as follows: Section 10.2 summarizes the survey of the related work done by the researchers worldwide. We provide an overview of the challenges faced by the app-controlled, IoT enabled devices and how the voice-controlled, IoT enabled devices are being introduced to overcome those challenges. We summarize the pros and cons of the available AI-based voice response systems for background information.
Sections 10.3–10.5 introduce the basics of the AWS IoT paradigm and its components: Alexa voice service (AVS) and AWS Lambda. Section 10.6 describes how message passing is done in a secure communication channel through Message Queuing Telemetry Transport (MQTT) protocol in our system. Section 10.7 describes the proposed architecture of the system and its workflow. Section 10.8 concludes the chapter.
10.2 Literature Survey
The author [13] connected home appliances such as lights and fans with AWS IoT and controlled it through Alexa Voice Service. These devices require frequent firmware updates, which are being done through Node-RED, an IBM developed visual wiring tool. The author uses Raspberry Pi and Intel Edison Board as the Alexa voice client device. Veton et al. [14, 15] have made a comparative analysis of various available speech recognition systems like Microsoft API, CMUSphinx, and Google API. Sphinx 4 is an open source speech recognition system developed by Carnegie Mellon University. Authors have used audio recordings as input and calculated the word error rate to make the comparison, and found that Google API outperformed the other speech recognition systems. Authors excluded Alexa voice service from the test. In our test, we saw that Alexa voice service performed better than Google API in a noisy environment. The authors [14] designed a virtual personal assistant system for human-computer interaction in a multimodal environment where given inputs are speech, image, video, manual gesture, gaze, and body movement. IBM Watson Analytics also provides a development environment like Alexa voice service. IBM Watson provides speech to text, text to speech, conversation, tone analyzer, and visual recognition services to the user. The authors [14] have used IBM Watson with Node-RED and Python to connect the IoT enabled devices through API.
10.3 AWS IoT
Amazon Web Services Internet of Things (AWS IoT) is a cloud-based Platform as a Service (PAAS) that enables users to connect, control, and monitor IoT devices from a remote location. It is a subscription-based service. Users are charged based on the number of devices enabled in AWS IoT. The user can easily enable/disable a device from the AWS management console. AWS IoT provides Amazon voice services (AVS) to the Amazon voice client.
10.4 Amazon Voice Service (AVS)
AVS helps the developer to connect voice-enabled IoT devices that have a microphone connectivity. We call this voice-enabled device Alexa Voice Client. After the integration of AVS with Alexa Voice Client, it will have access all the relevant API's that Alexa voice client receives as an instruction from the user. Middleware APIs convert the request to a response. AVS has the access to the entire built-in API available in AWS IoT. The users can build their own API uploading Alexa Skills Kit in AWS IoT to make the voice response system (Alexa voice client) feature user-friendly and able to reach. AVS creates an interface with Alexa voice client and enables three functionalities: speech recognition, voice control, and audio playback. Each interface function is driven by two types of messages: either through message directives or message events. Directives are the messages sent from the cloud to take action, and events are messages sent by the client device to cloud to show what action is being taken. Directives and event messages are generated through AWS Lambda, speech synthesis markup language, and Alexa skills kit.
10.5 AWS Lambda
AWS Lambda is another PaaS services that enable stateless development environment to the user. The user writes the piece of code in AWS Lambda function to control the connected device. Alexa voice service recognizes the speech recognition from Alexa voice client and converts it into an input to AWS Lambda function. Speech recognition to input instruction conversion is done through an API Speech Recognizer. Recognize available in Alexa voice service as shown in Fig. 10.1. AWS Lambda function processes the input and generates customized output in the form of event messages as shown in Fig. 10.1. Event messages synthesize speech signals through another API called Speech Synthesizer. Speak as shown in Fig. 10.1.
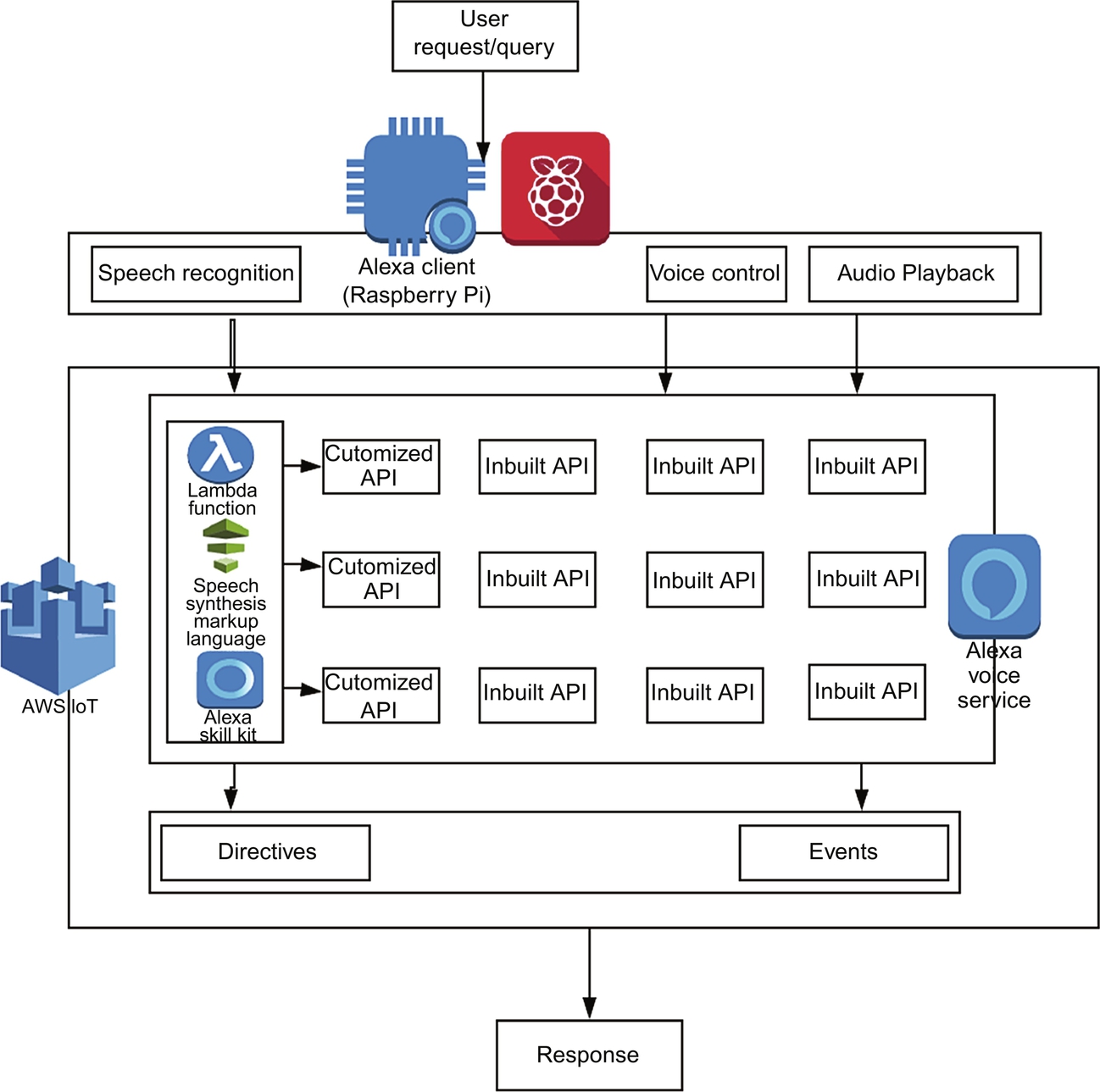
10.6 Message Queuing Telemetry Transport (MQTT)
Message Queuing Telemetry Transport (MQTT) is a message passing protocol [16, 17] like TCP and UDP. MQTT uses low bandwidth and low latency during message transmission. It is a machine to machine communication protocol. There are three components in MQTT: publisher, broker, and subscriber. The subscriber/user sends a request to the publisher via the broker as shown in Fig. 10.2. The publisher responds to the request from the subscriber via the broker in a secure communication channel. The broker acts like a filter allowing only those data requested by the subscriber. We have implemented MQTT configuration using Eclipse Paho. Eclipse Paho is an open source MQTT client implementation platform. The Paho Java Client is an MQTT client library written in Java for developing applications that run on the JVM or other Java compatible platforms such as Android.

10.7 Proposed Architecture
We have designed the customized voice response system using Raspberry Pi as Alexa voice client. Raspberry Pi will be used as an MQTT client, and for message passing between the user and Alexa voice service (AVS). The hardware and software requirement are shown in Tables 10.1 and 10.2, respectively.
Table 10.1
| S. No | Material | Quantity |
|---|---|---|
| 1 | Raspberry Pi 3 model B + | 1 |
| 2 | Relay (generic) | 4 |
| 3 | Jumper wires | 30 |
| 4 | Soundcard or microphone | 1 |
| 5 | Speakers | 1 |
Table 10.2
| S. No | Software Applications and Online Services |
|---|---|
| 1 | Amazon Alexa/Alexa skills kit |
| 2 | Amazon Alexa/Alexa voice service |
| 3 | Amazon web services/AWS IoT |
| 4 | Amazon web services/AWS Lambda |
The architecture of the proposed system is shown in Fig. 10.3. We have used the relay switch to enable home appliances such as lights and fans. We connect the relay module to the Raspberry Pi using jumper wires. We use the following gpio pins to connect the relay to our Pi:
- For the kitchen light, Pin No. 23 is used (P1 header pin 16),
- For the bedroom light, Pin No. 10 is used (P1 header pin 19),
- For the bedroom fan, Pin No. 11 is used (P1 header pin 23), and
- For the bathroom light, Pin No. 22 is used (P1 header pin 15).
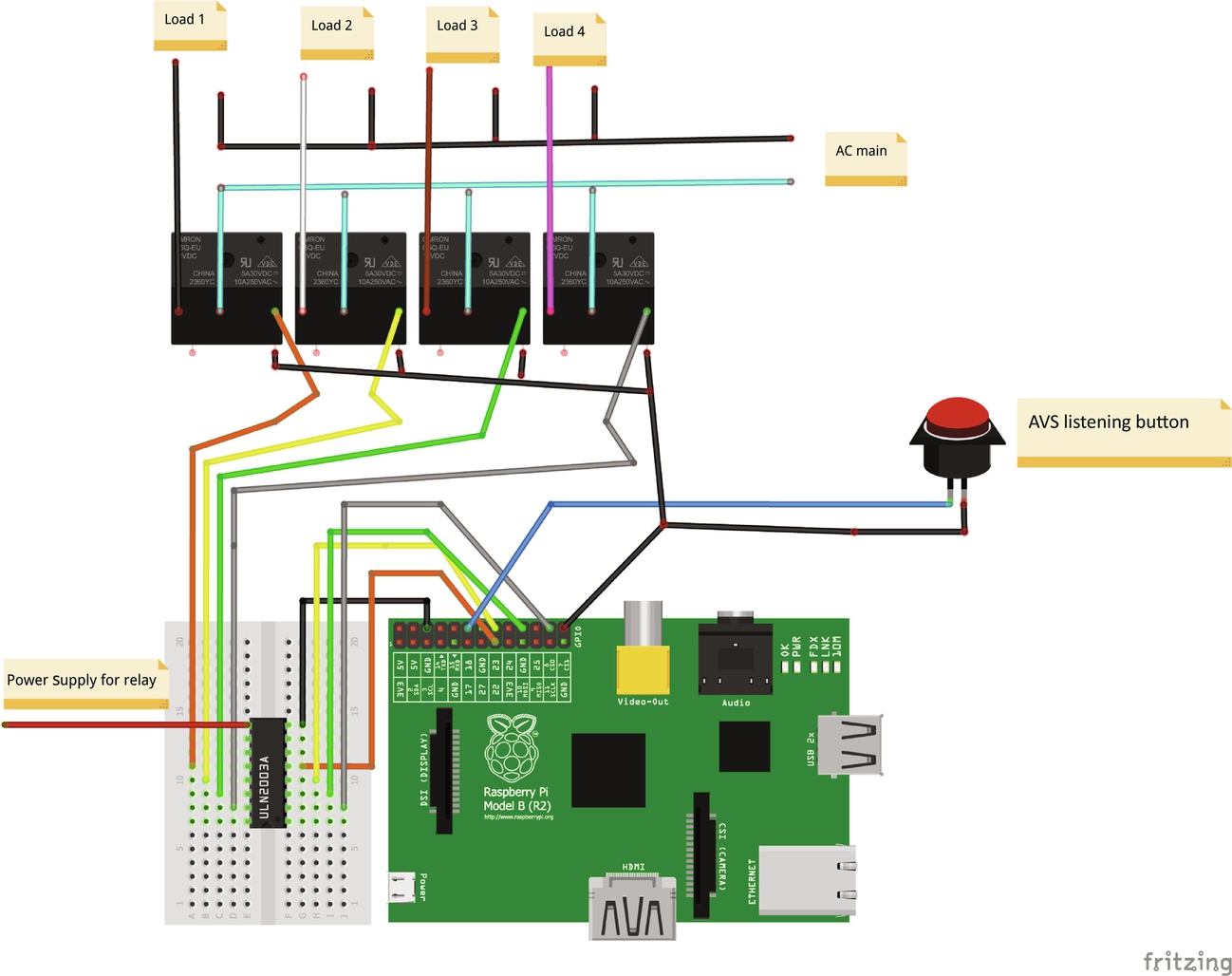
We have used gpio pins for power supply and ground, respectively. Also, we have used a button to connect to the Pi so we can activate Alexa by pressing the button. We can alternatively activate Alexa by even giving a wake word signal.
Fig. 10.4 gives a brief overview of the system. The entire workflow of the system is shown in a flowchart in Fig. 10.5.

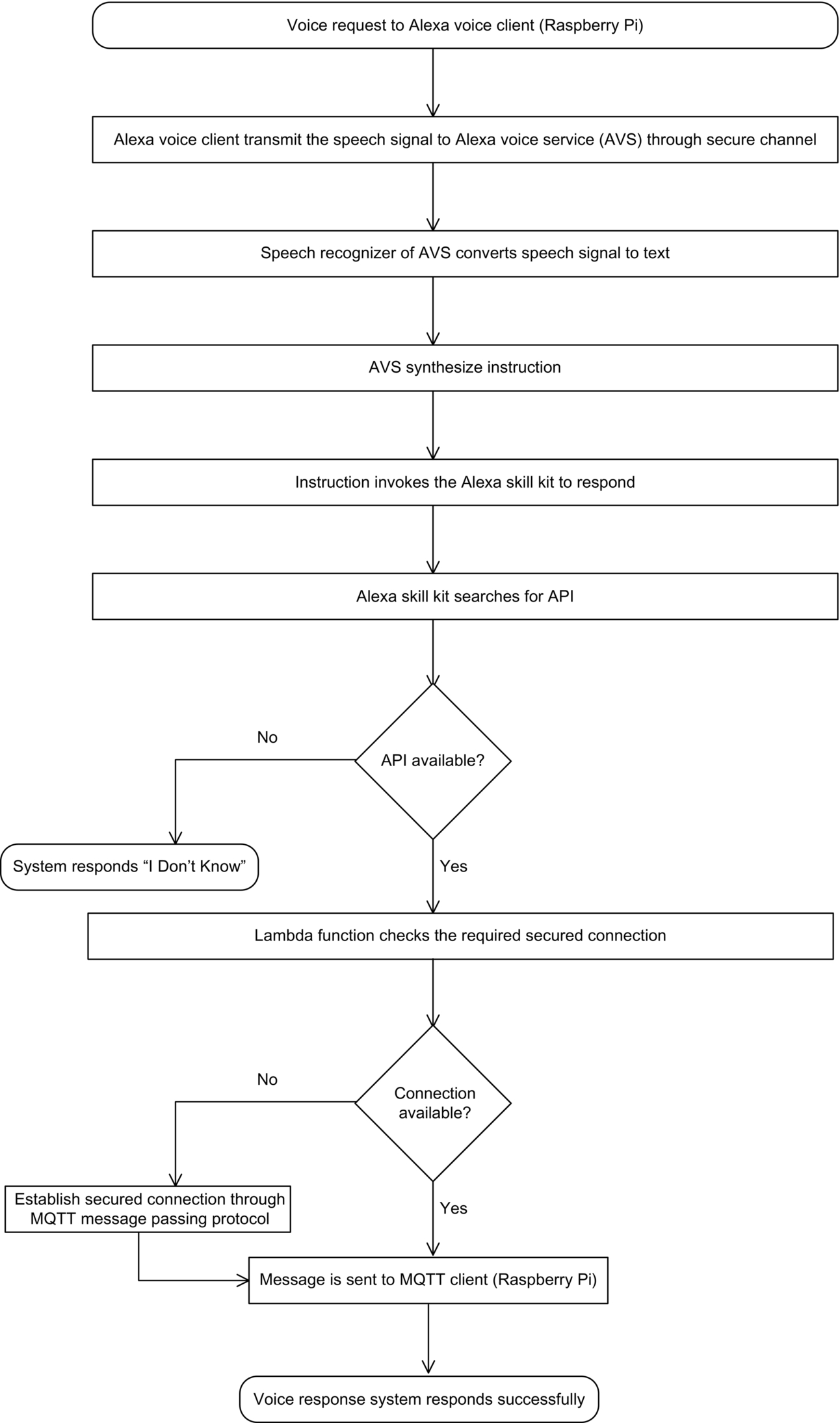
The user sends a voice request to Raspberry Pi. Raspberry Pi acts here as Alexa voice client. Raspberry Pi transmits the speech signal to Alexa voice service (AVS). AVS eliminates noise from the speech signal and converts it to text. The text is synthesized as an instruction that invokes the Alexa skills kit, which will accept user command, and then searches for the suitable API using AWS Lambda. Few built-in APIs are present in Alexa skills kit.
When the voice response system is asked a query, Alexa voice service invokes three APIs namely:
- a. SpeechRecognizer.Recognize
- b. Speech Synthesizer.Speech Started
- c. Speech Synthesizer.Speak
For example,
- User: “Alexa, How are you?”
- Alexa: “I am feeling like the top of the world.”
- Invoked API's code are as follows:
- API: SpeechRecognizer.Recognize
{ "event": { "header": { "dialogRequestId": "dialogRequestId-7b155828-6eb7-4859-870f-ca7431bcd66d", "namespace": "SpeechRecognizer", "name": "Recognize", "messageId": "b28c0283-2a3b-420d-98ab-5833196fa90d" }, "payload": { "profile": "CLOSE_TALK", "format": "AUDIO_L16_RATE_16000_CHANNELS_1" } }, "context": [ { "header": { "namespace": "AudioPlayer", "name": "PlaybackState" },
"payload": { "token": "", "playerActivity": "IDLE", "offsetInMilliseconds": "0" } } ] }
- API: Speech Synthesizer.Speech Started
{ "event": { "header": { "namespace": "SpeechSynthesizer", "name": "SpeechStarted", "messageId": "8e18c39a-f900-47ca-bc70-0686680ba902" }, "payload": { "token": "amzn1.as-ct.v1.Domain:Application:Knowledge#ACRI#f42592cf-a445-4485-99c5-36cf36e18d17" } }, "context": [] }
- API: SpeechSynthesizer.Speak
{ "directive": { "header": { "dialogRequestId": "dialogRequestId-7b155828-6eb7-4859-870f-ca7431bcd66d", "namespace": "SpeechSynthesizer", "name": "Speak", "messageId": "ad6a54bd-ad9c-4a23-ae56-9eb3da8d8dc8" }, "payload": { "url": "cid:f42592cf-a445-4485-99c5-36cf36e18d17_1932182893", "token": "amzn1.as-ct.v1.Domain:Application:Knowledge#ACRI#f42592cf-a445-4485-99c5-36cf36e18d17", "format": "AUDIO_MPEG" } } }
If we identify that our system fails to respond to a certain query, we write our own instruction using AWS Lambda function and speech synthesis markup language (SSML) and upload it as a customized API in Alexa skills kit. After the identification of a suitable API, the Lambda function requests AVS to check the existence of the required connection and sends the response to Raspberry Pi. Raspberry Pi now acts as the MQTT client and gives the response back to the user.
10.8 Conclusion
The human-computer interaction system has traversed a long path. It initiated its journey through keyboard-mouse, apps and, now, it is voice. Today, all electronic devices are connected through the Internet. These devices are controlled through apps that are platform dependent (Android, iOS, Windows) and requires frequent firmware updates. Our proposed system eliminates platform dependency, and it recognizes and responds only to the designated user. This feature provides added security to our voice response system. Moreover, this system costs around 3,400 INR ($42), which is cheaper than the available voice response systems in the market (Amazon Echo, Google Home, Apple HomePod).
It is a well-known controversy that Amazon Echo stores user's private conversations [18] in AWS cloud server, although Amazon denies the fact. Our proposed framework stores AVS collected data in an individual user's account. So, there is no risk of the user's data leakage or exposure.
During testing and validation of the proposed system, we observed the following: The proposed voice response system replies with 100% accuracy for a general query like, “Who is the prime minister of India,” but fails to reply to a user-specific query like ”Where is Dr. Sajal Saha right now?” We are working on integrating all the Google apps (except Gmail), such as Google Maps, Google Calendar, Google Find my Phone, and Google Classroom through custom API, so that proposed voice response system can give a precise answer to the user-specific query.