
Data preprocessing usually takes a lot of time to set up, because you have to take care of lot of different formats or sources. In this chapter, we will introduce the basic options to not only read and generate data but also to reshape them. Changing values is also a common task, and we will cover that too.
It is a good practice to keep checking certain constraints especially if you have volatile input sources. This is also important in KNIME. Finally, we will go through an example of workflow from import to preprocessing. In this chapter, we will cover the following topics:
- Data import
- From database
- From files
- From web services
- Regular expressions
- Transforming tables
- Transforming values
- Generating data
- Constraints
- Case studies
Your data can be from multiple sources, such as databases, Internet/intranet, or files. This section will give a short introduction to the various options.
In this section, we will use the Java DB (http://www.oracle.com/technetwork/java/javadb/index.html) to create a local database because it is supported by Oracle, bundled with JDKs, cross-platform, and easy to set up. The database we use is described on eclipse's BIRT Sample Database page (http://www.eclipse.org/birt/phoenix/db/#schema).
Once you have Java DB installed (unzipped the binary distribution from Derby (http://db.apache.org/derby/derby_downloads.html) or located your JDK), you should also download the BirtSample.jar file from this book's website (originally from http://mirror-fpt-telecom.fpt.net/eclipse/birt/update-site/3.7-interim/plugins/org.eclipse.birt.report.data.oda.sampledb_3.7.2.v20120213.jar.pack.gz). Unzip the content to the database server's install folder.
You should start a terminal from the database server's home folder, using the following command:
bin/startNetworkServer
Locate the database server's lib/derbyclient.jar file. You should install this driver as described in the previous chapter (File | Preferences | KNIME | Database Driver).
You can import the DatabaseConnection.zip file, downloaded from this book's website, as a KNIME workflow. This time, we were not using workflow credentials as it would always be asked for on load, and it might be hard to remember the ClassicModels password.
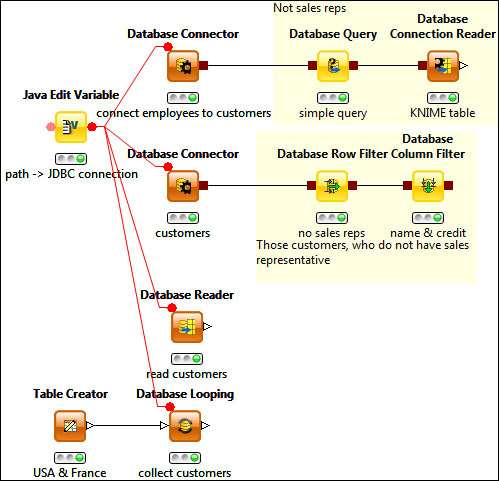
The previous screenshot reads different tables and filter some of the results. The Java Edit Variable node provides the JDBC connection string as a flow variable.
There is a workflow variable named database location (default value: BirtSample), in case you want to specify an absolute path to the database you want to use. The Java Edit Variable node appends this path to the default local database connection, so you can use the Derby JDBC connection variable in the subsequent nodes. You should start with executing this node to configure the other nodes.
The Database Connector node can connect to the database and give a stub for further processing (you can inspect it using the port viewer, though, once you execute).
The Database Query can be used to express complex conditions in the table. Please be careful. You should name the #table#, like we did in the following query:
SELECT * FROM #table# customerTable where customernumber < 300 or customernumber is nullTip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
If you have simpler (single column) conditions, you can also use the Database Row Filter node. Removal of a few columns (projection) can be performed with the Database Column Filter node.
If you want to process or visualize the data in KNIME, you have to convert the database connection port type to regular data tables using the Database Connection Reader node. If you do not need post-processing of the database tables, you can simply specify the connection and the query with the Database Reader node.
An interesting option to read data is by using the Database Looping node. It can read the values from one of the input table's columns and select only the values that match a subset of the column for one of the database columns' values.
You also have the option to modify the database, such as deleting rows, updating certain rows, creating tables, and appending records. For details, check the Database Delete, Database Update, and Database Writer nodes. While replacing/creating a table for an existing database, the connection can be performed using the Database Connection Writer node.
This time, for example, we will load a simple comma-separated file. For this purpose, you can use the File Reader node and the following link:
http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
KNIME will automatically set the parameters, although you have to specify the column names (the http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.names file gives a description of the dataset).
In the configuration dialog, you can refine the columns in the preview area by clicking on its header.
Naturally, you can open the local files too, if you specify the URL using the Browse... button.
If you have the data in the Excel format, you might need the KNIME XLS Support extension from the standard KNIME update site. This way, you will be able to read (with the XLS Reader node) and also write the xls files (with the XLS Writer node).
Just like the File Reader node, XLS Reader can load the files from the Internet too. (If you have the data in the ods format, you have to convert/export it to either the xls(x) or the csv file to be able to load from KNIME.)
The CSV Reader node is less important if you prefer to use the KNIME Desktop product; however, with the batch mode, you might find this node useful (less options for configuration, but it can provide the file name as a flow variable).
Attribute-Relation File Format (ARFF) is also tabular (http://weka.wikispaces.com/ARFF). You can read them with the ARFF Reader node. Exporting to ARFF can be done with ARFF Writer.
For Web Services Description Language (WSDL) web services, you can use the KNIME Webservice Client standard extension. It provides the Generic Webservice Client node.
Note
This node gives many advanced features to access WSDL services, but you should test it to see whether or not it is compatible with your service interface before implementing a new one. It is based on Apache CXF (http://cxf.apache.org/), so any limitation of that project is a limitation of this node too.
Unfortunately, not much WSDL web services are available for free without registration, but you can try it out at http://www.webservicex.com/globalweather.asmx?wsdl. Naturally, if you are registered for another service, or you have an own in the intranet, you can give it a try.
Nowadays, the REST (Representational State Transfer) services has gathered momentum, so it is always nice if you can use it too. In this regard, I would recommend the next section where we introduce the XML Reader node. You can use the KREST (http://tech.knime.org/book/krest-rest-nodes-for-knime) nodes to handle the JSON or XML REST queries.
You need the KNIME XML-Processing extension from the standard KNIME update site. The XML Reader node can parse either local or external files, which you can further analyze or transform.
Once you have a model, you might want to save it (Model Writer or PMML Writer) to use it later in other workflows. In those workflows, you can use the Model Reader or PMML Reader nodes to bring these models to the new workflow.
Some extensions also provide reader nodes to certain data types. The standard KNIME update site contains multiple chemical extensions supporting different formats of chemical compounds.
The KNIME Labs Update Site extensions support text processing, graphs, and logfile analyzing, and they contain readers for these tasks.
Most probably you are already familiar with the available data sources for your area of research/work, although a short list of generic data collections might interest you in order to improve the results of your data analysis.
Here are some of them:
- Open data (http://en.wikipedia.org/wiki/Open_data) members, such as DATA.GOV (http://www.data.gov/) and European Union Open Data Portal (http://open-data.europa.eu/)
- Freebase (http://www.freebase.com/)
- WIKIDATA (http://www.wikidata.org/wiki/Wikidata:Main_Page)
- DBpedia (http://dbpedia.org/)
- YAGO2 (http://www.mpi-inf.mpg.de/yago-naga/yago/)
- Windows Azure Marketplace (http://datamarket.azure.com/)
This was just a short list; you can find many more of these, and the list of data sources for specific areas would be even longer.